基于知識蒸餾和定位引導的Pointpillars點云檢測網絡
2024-01-31 06:13:36趙晶李少博郭杰龍俞輝張劍鋒李杰
液晶與顯示 2024年1期
趙晶, 李少博, 郭杰龍, 俞輝, 張劍鋒, 李杰
(1.廈門理工學院 電氣工程與自動化學院, 福建 廈門 361024;2.中國科學院 福建物質結構研究所, 福建 福州 350108;3.中國科學院 海西研究院 泉州裝備制造研究中心, 福建 泉州 362000;4.廈門市高端電力裝備及智能控制重點實驗室, 福建 廈門 361024)
1 引言
激光點云是一種直觀、靈活和存儲效率高的三維數據表示方法,在三維視覺中已變得不可或缺。大規模激光雷達數據集的出現和端到端3D表示學習的巨大進步推動了基于點云的分割、生成和檢測任務的發展。
不論是單階段還是兩階段檢測方法,點云的特征提取質量影響著算法的檢測精度。Qi Charles R等[1]首次提出以端到端的方式通過多層感知來提取點的特征。隨后,作者進一步提出PointNet++[2],以分層方式捕獲局部結構,采用密度自適應采樣和分組的方式提取點云特征。Point和Point++實現了直接對點云數據的處理和特征提取,被廣泛應用到其他算法模型中。Zhou Y等人提出了VoxelNet[3],這是一種單級檢測網絡,可將點云劃分為等間距的三維體素,并使用體素特征編碼層進行處理,但是其采用了3D子流形稀疏卷積作為特征提取模塊,致使網絡推理速度相對較慢。Lang A H等人提出了Pointpillars[4]網絡模型,提議將點云劃分為幾個體柱,將其轉換為偽圖像,可以使用2D卷積層進一步處理。此方法極大提高了網絡模型的運算速度,使其能夠滿足自動駕駛實時性的要求,但其點云編碼方式影響了特征提取的質量。Point R-CNN[5]和Pillar RCNN[6]是一種兩階段檢測方法,首先基于原始點云生成自底向上的3D提案,然后對其進行細化以獲得最終檢測結果。隨后,Fast point R-CNN[7]和PV-RCN[8]方法出現,利用體素表示和原始點云來發揮各自的優勢。圖神經網絡是點云檢測領域新興的點云結構表示和特征提取方法。如為避免點云中心偏移和比例變化的3D-GCN[9],根據學習的特征生成自適應卷積核的AD-GCN[10]等。盡管點云的結構表示和特征提取方法多種多樣,但復雜精細的結構設計可能會降低網絡模型的推理速度。
早期的知識蒸餾方法主要是訓練學生網絡模仿教師網絡預測的分類概率分布。近年來,以設計特定的知識提取方法用于提高目標檢測的效率和準確性已成為一個新興的熱門話題。Chen等人首先提出將樸素預測和基于特征的知識提取方法應用于目標檢測[11]。Wang等人證明前景對象和背景對象之間的不平衡阻礙了知識提取在目標檢測中實現更好的性能[12]。為了解決這個問題,豐富的知識提取方法試圖基于檢測結果[13]、基于查詢的注意力[14]和梯度[15]找到待提取區域。此外,最近還提出了提取教師與學生之間像素級和對象級關系的方法[16]。除了用于2D檢測的知識蒸餾外,還引入了一些跨模態知識蒸餾,以將知識從基于RGB的教師檢測網絡轉移到基于激光雷達的學生檢測網絡。然而,這些方法大多側重于學生和教師在多模態框架中的選擇,而基于純點云數據三維檢測的特定知識提取優化方法尚未得到很好的探索。
在Pointpillars的檢測網絡部分,其分類預測和回歸框預測存在低相關性。低相關性主要是由于在訓練階段分類預測和回歸預測使用各自獨立的目標函數進行訓練,因此正樣本的回歸框預測和分類置信度之間會存在不對齊的情況[17],影響置信度分數預測,最終影響網絡模型的檢測精度。
針對上述問題,本文做了如下工作:
(1)依據單階段網絡設計一組Teacher-Student模型框架對回歸框尺度進行知識蒸餾。回歸框尺度在數據類型上可以從連續表示轉到離散表示,將教師網絡的輸出視為附加的回歸框尺度目標,對教師網絡和學生網絡的回歸框尺度輸出進行連續值離散化,再做兩組概率值擬合,制定蒸餾損失優化學生網絡,提升物體的檢測精度。
(2)設計定位引導分類項,將鳥瞰圖視角下的正樣本預測框與真實框的IoU值作為引導分數,以軟化相應正樣本硬類別標簽,增加分類預測和回歸預測的相關性,提高模型檢測精度。定位引導分類項沒有額外的網絡嵌入,不影響網絡模型的推理時間,使其保持高效性。
2 網絡模型
2.1 總體框架
圖1顯示了本文的目標檢測網絡框架:(1)包含一個教師檢測網絡和一個學生檢測網絡,其中教師網絡和學生網絡的特征提取模塊使用相同的網絡結構。先訓練教師網絡模型,隨后凍結教師網絡參數,在訓練學生網絡模型時教師網絡模型進行預加載,對輸入學生網絡的點云數據做增廣,使學生網絡探索更大的數據空間,并利用教師網絡預測的軟目標進行更好的優化。本文所用回歸框蒸餾(Regression Box Distillation,RBD)策略作用于檢測頭的回歸分支,而不是深層特征。(2)最終的檢測網絡是學生網絡和其檢測模塊,為了增加分類預測與回歸預測間的相關性而無需額外的網絡嵌入,設計了定位引導分類(Positioning Guidance Classification,PGC)項作用于學生網絡的分類預測,并改造分類損失函數。
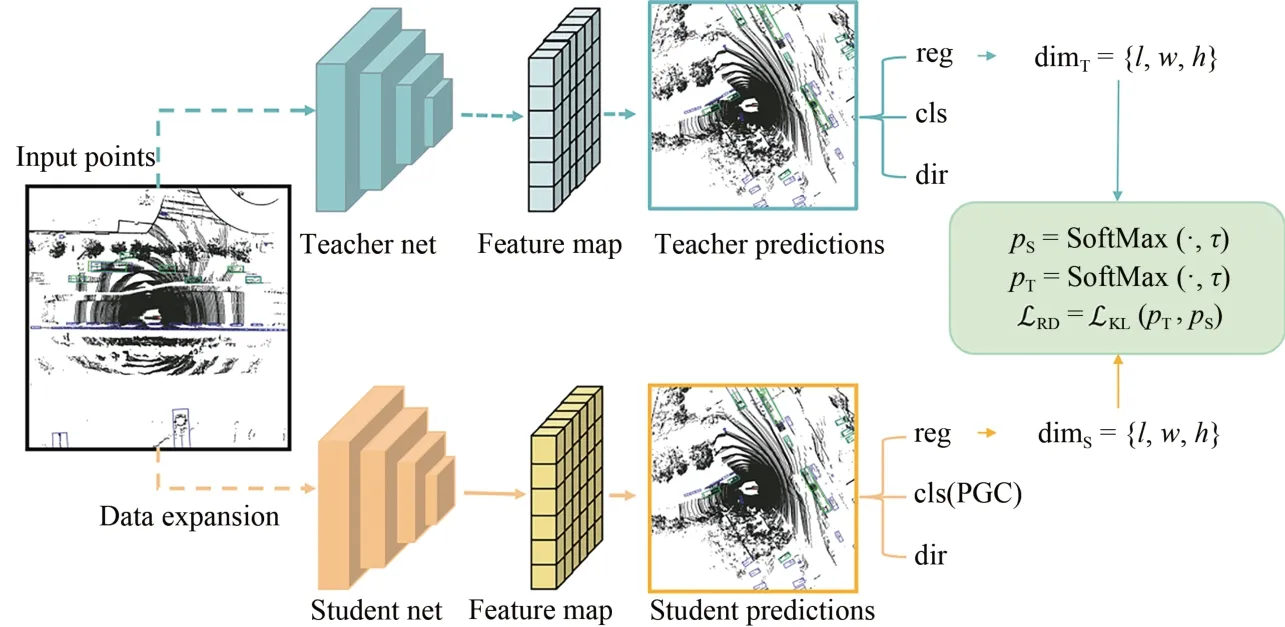
圖1 網絡框圖Fig.1 Network block diagram
2.2 點云編碼與特征提取
網絡的點云編碼和特征提取依照Pointpillars[4]進行設置。將點云在x-y平面上設置柱體,每個非空柱構成一組子點云Sx∈W,y∈H={Pi,i=1,2,…,nx,y},其中每個點Pi用一個向量(x,y,z,r)表示,nx,y是對應集合中的點的數量。將一幀點云編碼成一個維度為(D,P,N)的稠密張量。對集合中的每個點用線性層+BatchNorm+ReLU激活函數處理,生成維度為(C,P,N)的張量,其中C是特征通道。再通過每個點的體柱索引值重新放回到原來對應的體柱的x,y位置上生成(C,H,W)維度的偽圖像。特征提取網絡由下采樣網絡和上采樣網絡組成。下采樣網絡塊表示為ConvBlock(Cin,Cout,Sd,Nb),其中C是特征通道數,Sd是下采樣因子,Nb是每個網絡塊中卷積層的數量。上采樣網絡塊表示為DeconvBlock(Cin,Cout,Su),其中Su是2D反卷積的上采樣因子。
2.3 回歸框蒸餾
與只傳遞語義知識的分類蒸餾不同,回歸框蒸餾能夠傳遞目標物體的位置和尺度信息,來自教師模型的回歸框尺度用作學生模型的額外回歸目標,以幫助學生模型收斂到更好的優化點。此策略能夠讓學生網絡模型的回歸預測更為穩健,并實現更好的泛化能力,提升檢測效果。
激光點云的三維目標檢測中,網絡模型的回歸框預測輸出為(x,y,z,l,w,h,θ),共7個維度的數據。本方法中,只對預測輸出的回歸框尺度(l,w,h)進行蒸餾處理。在二維圖像目標檢測中,其邊界框的表示通常有(x,y,w,h)(中心點坐標,長和寬)、(xmin,ymin,xmax,ymax)(回歸框左上角點和右下角點)和(t,b,l,r)(采樣點到回歸框的上、下、左和右的距離)表示方式。其中(x,y,w,h)和(xmin,ymin,xmax,ymax)可以直接互相轉換,這兩種表示方法進一步用其采樣點(xs,ys)和相匹配的真實框(xgt,ygt,wgt,hgt)計算出采樣點到真實框上、下、左和右的距離,也就是(t,b,l,r)。不論是Anchor-Base類型的檢測網絡還是Anchor-Free類型的檢測網絡,以上回歸框的3種表示形式可以依據其相匹配的真實框進行互相轉換,從離散值轉換到連續值,從連續值轉換到離散值。但是在帶有旋轉角的三維目標檢測回歸框中,其中心點、回歸框尺寸和旋轉角互相獨立,本文的回歸框蒸餾其思想是針對連續域上回歸的變量先離散化處理,最后進行概率擬合。
本文所提的回歸框蒸餾方法選擇對正樣本回歸框的尺度Dim=(l,w,h)(回歸框的長、寬、高)進行處理,(l,w,h)的每個變量的物理意義都是一致的,記每條邊為e。設D為網絡預測的3個回歸框尺寸,分別由教師網絡的DT和學生網絡的DS表示,使用廣義的SoftMax函數S(· ,τ)=SoftMax(· ,τ)將DT和DS轉換為概率表示pT和pS。當τ=1時,它等價于原始的SoftMax函數;當τ>1時,輸入的參數會攜帶更多的信息。
LRD用于衡量兩組概率相似度的蒸餾損失,其定義如公式(1)所示:
其中:LKL表示KL發散損失,τ表示溫度系數,S和T分別為教師網絡和學生網絡,p為概率值,D代表回歸框尺度的集合。回歸框尺寸S的3個維度的蒸餾可以化為公式(2),其中e代表回歸框的邊:
2.4 定位引導分類
為了增加分類預測和回歸預測的相關性,設計了定位引導分類項,過程示意圖如圖2所示。物體在點云的BEV空間中有一個關鍵優勢是位置不重疊,因此在BEV空間中真實物體的定位效果和定位質量較好。將網絡的正樣本回歸預測和真實框在BEV空間下做IoU值計算,將計算得到的IoU值作為引導分數,分配給正樣本對應的硬類別標簽(One-hot),分配后的硬類別標簽變為軟標簽(Soft Label)。整個過程中,具有高IoU的正樣本在分類時被自適應地向上加權,正樣本的回歸預測質量引導對應的類別標簽。定位引導項g定義如式(3)所示:
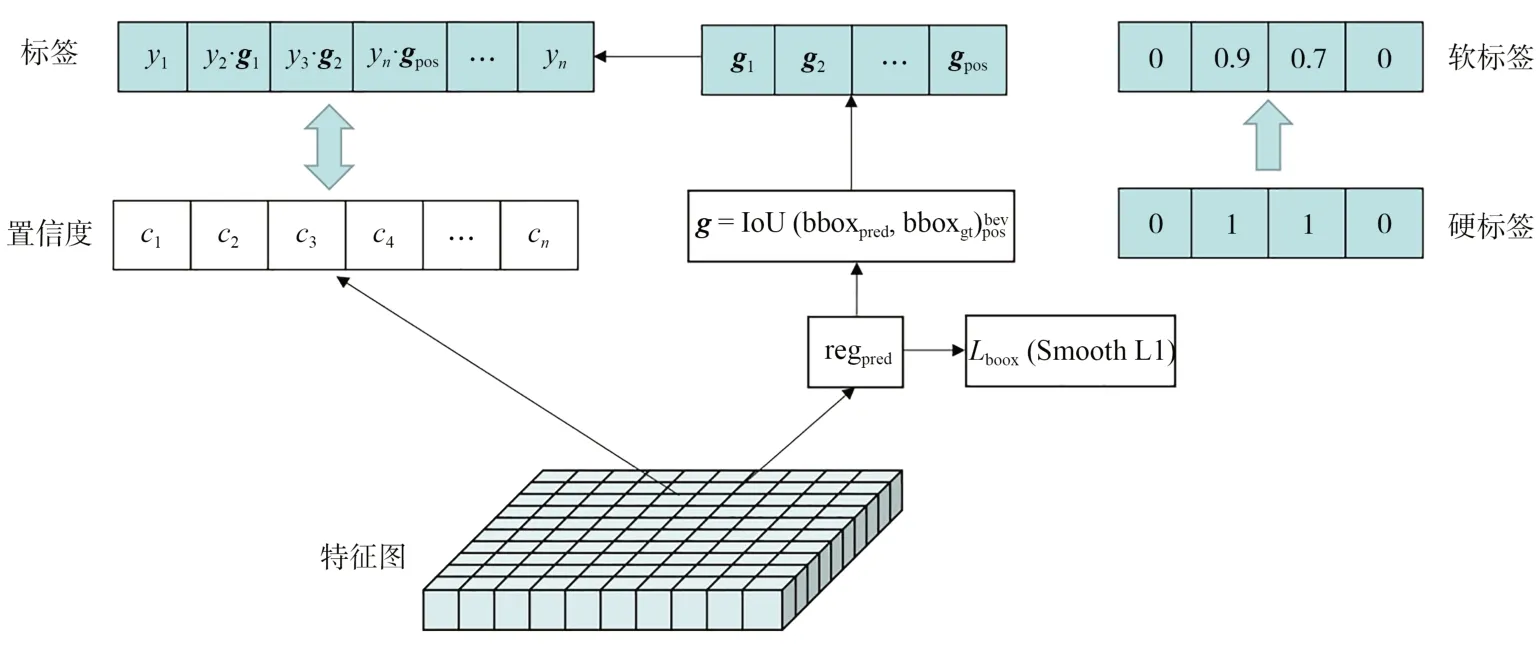
圖2 定位引導分類Fig.2 Positioning guidance classification
目標監督值為:
其中:i是預測框和真實框的IoU值;pos代表正樣本;bev是在BEV空間中邊界框的維度表示;regpred表示預測框偏差值,通過預測框偏差值與先驗框anchor解碼,得出預測框bboxpred,將其與樣本所匹配的真實框bboxgt做BEV視角下的IoU值計算,最終得到定位引導分類向量是用one-hot向量表示的真實標簽;f是引入定位引導項的soft label表示形式的正樣本標簽。
目前Pointpillars網絡的分類損失是焦點損失(Focal Loss,FL)損失函數,其一般形式如式(5)所示:
其中:y∈{0,1}是真實值的類別,p∈[0,1]是當真實標簽y=1時模型預測的類別概率,γ是可調節焦點參數。焦點損失(FL)是由標準交叉熵-logpt和一個調節因子(1-pt)γ兩部分組成。引入定位引導項g后,正樣本真實標簽從原本的y=0代表負樣本和y=1代表正樣本,變為f=0代表負樣本和0<f≤1代表正樣本的soft label表示形式。原本的焦點損失不能滿足引入定位引導項后的計算要求,需要進行改造。焦點損失采用sigmoid算子α(· )的多二進制分類實現多分類,把sigmoid的輸出標記為α,對焦點損失的兩部分進行擴展,將交叉熵部分-logpt擴展為完整的表示形式-((1-y)log(1-α)+ylogα),代入定位引導項g后,交叉熵部分變為-((1-f)log(1-α)+flogα)。比例因子部分(1-pt)γ廣義化擴展為估計α與其連續標簽之間的距離絕對值,即表示為|f-α|β(β≥0),其中|· |保證了非負性。最后,將擴展的兩部分組合起來,形成完整的分類損失函數,其定義如式(6)所示:
2.5 網絡總損失函數
本文的損失函數中,回歸損失選用與SECOND[18]相同的回歸損失。每個真實目標或者其先驗框的3D表示由一個七維向量來表示:(x,y,z,l,w,h,θ)。其中x、y、z表示3D邊界框的中心點坐標,l、w、h分別表示3D邊界框的長、寬和高,θ表示3D邊界框的朝向角。在邊界框定位回歸任務中,真實邊界框和先驗框之間的殘差定義為:
其中:xgt和xa分別表示真實邊界框和先驗框。da=邊界框回歸損失采用Smooth L1函數表示:
采用Softmax分類損失用于學習目標的朝向,朝向損失記為Ldir。
對于分類損失,使用改造過的焦點損失函數,即:
回歸蒸餾損失為:
最終網絡模型的總損失可表示為:
其中:Npos是正概率錨數;各項損失值的系數λ0=2.0,λ1=1.0,λ2=0.2,λ3=0.2。
3 實驗結果分析
使用三維目標檢測數據集KITTI對本文算法進行驗證,在KITTI數據集上進行多種算法對比實驗、模型推理速度比較和消融實驗。
3.1 實驗環境和優化器設置
本文實驗環境操作系統為CentOS 7.6,硬件顯卡型號為NVIDIA GeForce RTX 2080 TI,Intel(R) Xeon(R) 5220 CPU@2.20 GHz。深度學習框架為Pytorch 1.7,Python環境為3.7,使用CUDA 10.1用于GPU加速。
網絡訓練設置Batch Size為6,訓練80個epochs。采用AdamW優化器,使用0.01的衰減權重。使用周期性重啟學習率調整策略,初始學習率設置為0.001,最高學習率和最低學習率分別為10和0.000 1,訓練期間循環次數為1次,學習率增加過程在整個循環中的比率為0.4。
3.2 數據集設置
在KITTI數據集上評估本文所提出的3D檢測網絡模型的性能。KITTI數據集中包含7 481個訓練樣本和7 518個測試樣本。根據通用協議,將KITTI訓練集分為3 712個樣本的訓練集和3 769個樣本的驗證集。對Car類、Cyclist類和Pedestrian類進行評估,其IoU閾值分別為0.7、0.5、0.5。此外,該基準在評估中有3個難度級別:簡單、中等和困難,評估基于目標對象的遮擋和截斷水平。按照官方KITTI評估指標,使用40個召回位置計算,以平均精度均值(mean Average Precision, mAP)評價檢測結果。
在實驗中將范圍[0,69.12]、[-39.68,39.68]和[-3,1]米內的所有點分別沿著x、y和z軸體柱化,體柱的分辨率為[0.16,0.16,4],整個體柱網格大小為496×432×1。最大柱數(P)為16 000個,柱內最大點數(N)為100個。每個類的錨點由寬度、長度、高度和z中心來描述,具有0°和90°兩個方向。在訓練階段,對輸入的點云數據做數據增強處理,在x軸方向以0.5的概率隨機翻轉點云;將全局點云在z軸方向按照[-π/4,π/4]均勻分布的角度范圍進行隨機旋轉,對全局點云按照[0.95,1.05]的范圍進行隨機縮放。
3.3 對比評估
為了評估所提模型方法的性能,在KITTI數據集與其他算法進行3D檢測和BEV檢測對比實驗,結果如表1和表2所示。
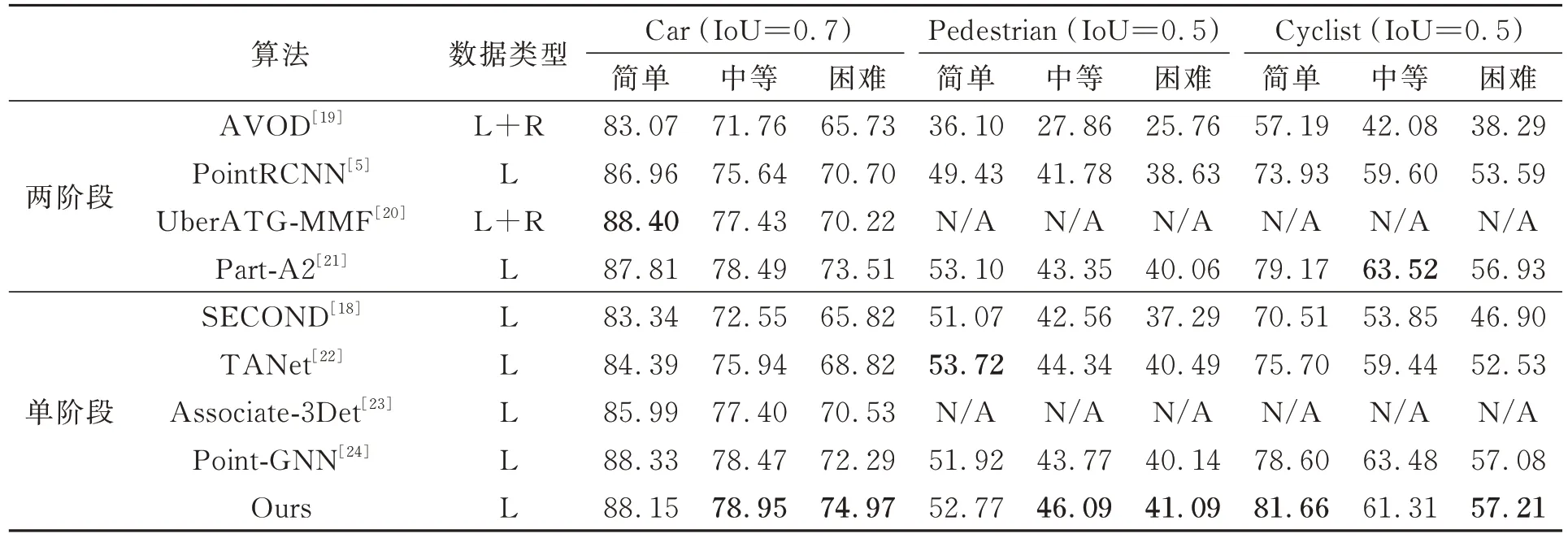
表1 KITTI數據集不同算法3D檢測精度(3DR40)對比Tab.1 Comparison of 3D detection accuracy (3DR40) of different algorithms in KITTI dataset %
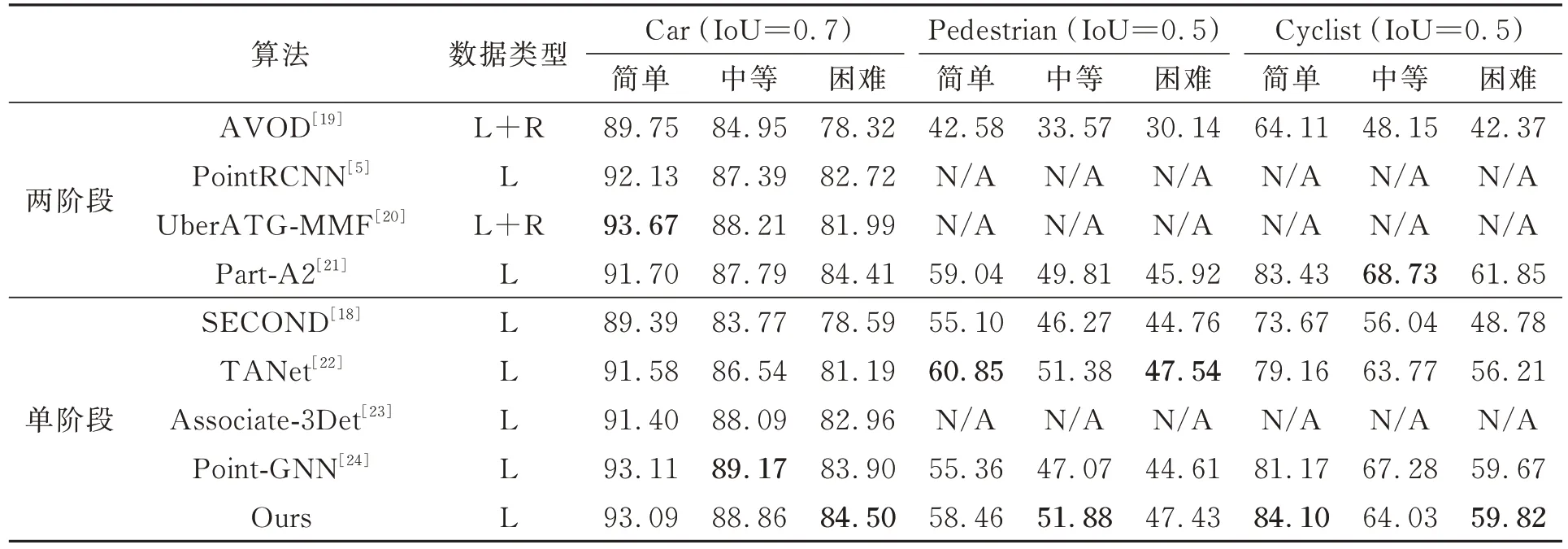
表2 KITTI數據集不同算法BEV檢測精度(BEVR40)對比Tab.2 Comparison of BEV detection accuracy (BEVR40) of different algorithms in KITTI dataset %
在3D檢測對比中,與經典的單階段檢測方法TANet[22]和SECOND[18]相比,在中等難度級別上,Car類和Cyclist類分別高3.01%、1.87%和6.4%、7.46%;與先進的單階段檢測方法Point-GNN[24]相比,Car類和Pedsetrian類在中等難度級別分別高了0.48%和2.32%。與兩階段檢測方法PointRCNN[5]相比,3種類別的中等難度分別高出3.31%、4.31%和1.71%;與Part-A2[21]相比,Car類中等難度高出0.46%,本文模型優于多數兩階段模型方法。在BEV檢測中,本文模型與TANet[22]和SECOND[18]相比,在Car類中等難度分別高出2.32%和5.09%。結果顯示,本文的模型在所有3個難度級別的3D和BEV檢測中與其他先進方法相比具有競爭力,驗證了本文方法的有效性。回歸框蒸餾能夠傳遞目標物體的位置和尺度信息,幫助網絡收斂到更好的優化點,使回歸模型更為穩健;定位引導分類建立了預測框和分類預測間的相關性,提升模型分類效果,最終提升了模型檢測精度。
本文方法采用體柱特征編碼的方式,點云經過編碼后,其分辨率顯著低于體素特征編碼和基于點的特征形式,所以其小目標如Pedestrian類的檢測精度會低于部分基于體素特征編碼和基于點的模型方法。
本文的回歸框尺度蒸餾中引入溫度系數τ,表3中顯示了KITTI數據集中不同溫度系數下的蒸餾結果,在溫度系數τ=2時模型獲得最好的效果。
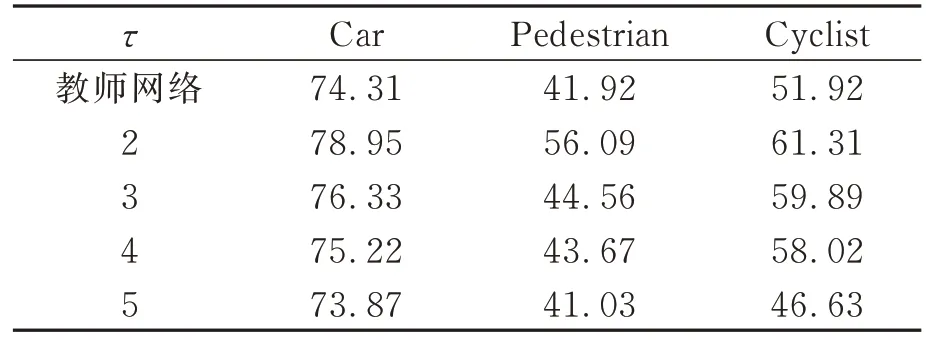
表3 蒸餾中溫度系數在ModR40模式下對模型探測精度的影響Tab.3 Influence of temperature coefficient on model detection accuracy in distillation under ModR40 %
為了驗證本文方法的檢測效率,選擇主流算法進行模型推理速度對比,結果如圖3所示。在模型推理速度方面,本文模型方法是兩階段網絡AVOD[19]和PointRCNN[5]的3~4倍;與單階段網絡SECOND[18]和TANet[22]相比,推理速度提高了大約2倍,達到45 FPS。雖然檢測精度與Point-GNN[24]基本持平,但Point-GNN由于需要對點云構建“圖”結構以及圖卷積等操作,需要消耗大量算力,因此模型推理速度慢了許多,不符合實時性要求。與單階段網絡相比,本文網絡模型具有檢測精度優勢;與兩階段網絡相比,本文網絡模型能夠在檢測精度上持平,但在推理速度上遠高于兩階段網絡。
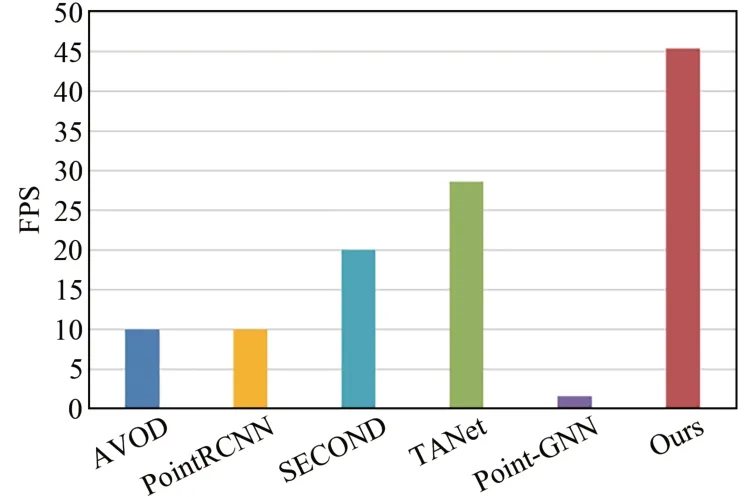
圖3 網絡模型推理速度對比Fig.3 Comparison of network model reasoning speed
如圖4所示,將本文針對點云的蒸餾策略與其他蒸餾方法如Zagoruyko[25]、Zheng[26]、 Tian[27]、Heo等[28]、Zhang[16]等方法對比,以Pointpillars為基準網絡,在KITTI數據集上進行Car類和3種難度級別的3D檢測。可以觀察到本文方法在Car類平均檢測精度方面比所列蒸餾方法都要高。如圖5所示,在3D檢測難度級別為中等和困難難度級別中,本文的蒸餾策略比上述蒸餾方法效果提升更明顯。
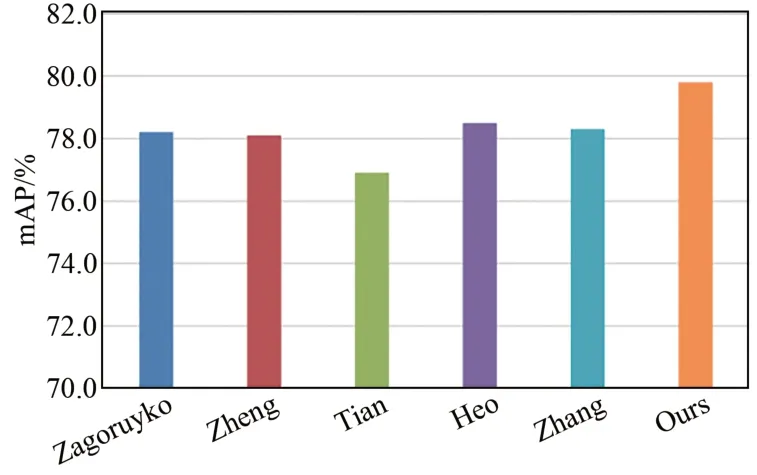
圖4 Car類的平均精度均值對比Fig.4 Comparison of average precision of car class
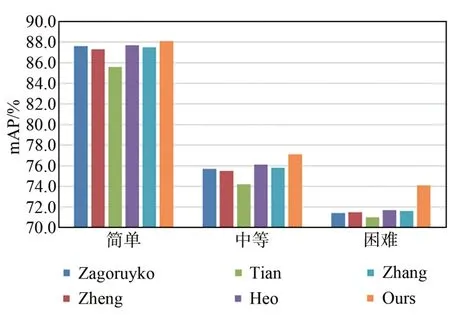
圖5 3種難度級別的平均精度均值對比Fig.5 Comparison of average accuracy of three difficulty levels
3.4 消融實驗
消融實驗可以評估本文所提方法各個模塊對檢測結果的貢獻。所有評估測試都在KITTI訓練集上進行訓練,在驗證集上進行評估。基準網絡為Pointpillars[4]網絡模型,消融實驗的設置以單獨和總體結合的形式展示本文方法的有效性。其中“回歸框蒸餾”記作RBD,“定位引導分類”記作PGC,使用40個召回位置計算平均精度均值(mAP),結果如表4所示。
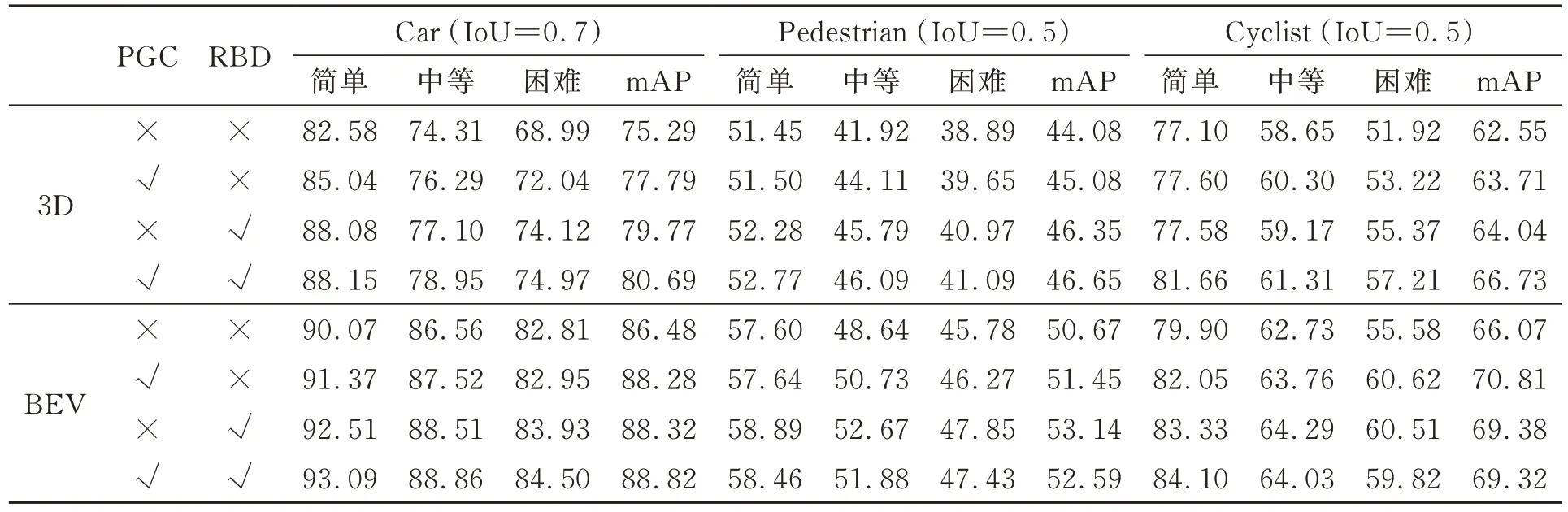
表4 回歸框蒸餾和定位引導分類在KITTI數據集上的消融實驗Tab.4 Ablation experiments of regression frame distillation and location-guided classification in KITTI dataset %
只增加RBD方法時,網絡模型在3D檢測中簡單、中等、困難3類的平均均值精度提升了4.48%、2.27%和1.49%,表明給預測框的尺度增加額外的回歸目標可以更好地優化模型,同時教師網絡產生的軟目標攜帶更多的信息,讓學生網絡在訓練過程中學習到更多的信息熵,提升模型特征提取的質量,從而提高物體檢測精度。只增加PGC方法時,3D檢測中簡單、中等、困難3類的平均均值精度提升了2.5%、1.0%和1.16%。定位引導分類項增加了回歸預測和分類預測之間的相關性,具有高IoU的正樣本在分類時被自適應地向上加權。最終綜合評估,本文所提出的兩種方法組合使用時,其檢測效果提升最大。
4 結論
本文受圖像目標檢測中知識蒸餾思想的啟發,針對激光點云數據的3D目標檢測任務設計了預測框的尺度作為約束訓練的蒸餾方法。此方法可以為檢測網絡在訓練中提供更多的信息熵,使網絡模型擁有更好的泛化能力,提升特征提取質量,提高模型檢測效果。針對Pointpillars網絡中回歸預測和分類預測間的低相關性,設計了定位引導分類項,同時改造了分類損失函數,將正樣本回歸預測質量引導類別標簽,以提升檢測效果。在KITTI數據集中,本文算法模型比基準網絡在Car類提升了5.4%mAP,在一眾算法模型中具有競爭力。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
