基于核主成分分析和食肉植物算法優(yōu)化隨機森林的風電功率短期預測
2024-02-01 07:26:34陳曉華吳杰康龍泳丞王志平蔡錦健
山東電力技術(shù) 2024年1期
陳曉華,吳杰康,龍泳丞,王志平,蔡錦健
(1.廣東電網(wǎng)有限責任公司湛江供電局,廣東 湛江 524005;2.廣東工業(yè)大學自動化學院,廣東 廣州 510006;3.東莞理工學院電子工程與智能化學院,廣東 東莞 523808)
0 引言
風力發(fā)電作為低成本、可再生的清潔能源受到了廣泛的重視,越來越多風力發(fā)電設備接入電網(wǎng)中[1]。風力發(fā)電能在一定程度上緩解能源危機,但由于風電功率受氣象因素影響較大,所以風電功率具有隨機性和間歇性等特點,進而給風電功率的準確預測帶來技術(shù)上的難度。風電功率短期預測一般指對未來3 天之內(nèi)的風電輸出功率進行預測,高精度的短期預測有助于促進風電的利用以及電網(wǎng)的安全穩(wěn)定運行[2]。
目前對于風電功率短期預測的研究方法主要包括物理方法和基于數(shù)據(jù)驅(qū)動的預測方法。物理方法主要通過利用數(shù)值天氣預報數(shù)據(jù)等信息,建立復雜的數(shù)學模型并對其求解得出預測結(jié)果,但該方法計算復雜且精度不高,不適用于風電功率短期預測[3]。基于數(shù)據(jù)驅(qū)動的預測方法主要通過利用機器學習或深度學習方法對風速、風向、溫度和海拔高度等數(shù)據(jù)進行訓練和回歸預測,進而實現(xiàn)風電功率的短期預測。常見的機器學習方法有支持向量機[4]、梯度提升樹[5]、鄰域KNN 算法[6]和隨機森林(random forest,RF)[7]等。常見的深度學習方法有卷積神經(jīng)網(wǎng)絡[8]、深度置信網(wǎng)絡[9]、雙向門控循環(huán)單元網(wǎng)絡[10]、Elman網(wǎng)絡[11]、長短期記憶網(wǎng)絡(long short-term memory,LSTM)[12]、門控循環(huán)單元網(wǎng)絡[13]、生成對抗網(wǎng)絡[14]和極限學習機[15]等,利用深度學習方法可以獲得一定的預測效果,但需要大量樣本數(shù)據(jù)并且消耗的時間比較長,不適用于風電功率短期預測。李國全等人利用改進烏鴉搜索算法優(yōu)化支持向量機參數(shù)獲得精度更高的預測模型[4],但改進的算法會增加運算時間。孫川永等人利用數(shù)值天氣預報和梯度提升樹算法相結(jié)合的方法對風電功率進行短期預測,獲得滿意的效果[5],但梯度提升樹需要調(diào)參,人為隨機設置的參數(shù)有時會導致預測效果不理想。RF 在處理非線性的風電功率數(shù)據(jù)方面具有明顯的優(yōu)勢,可以快速獲得較好的預測效果,然而RF 和支持向量機一樣,超參數(shù)設置不同的數(shù)值會影響預測效果。因此,采用尋優(yōu)精度高、收斂速度快的食肉植物算法(carnivorous plant algorithm,CPA)優(yōu)化RF 建立風電功率短期預測模型可以克服RF 預測模型預測精度不夠高的問題。
針對以往研究的不足,提出一種基于核主成分分析和CPA 優(yōu)化RF 的風電功率短期預測方法。利用核主成分分析選出8 個氣象因素作為預測模型的輸入,然后,通過CPA 優(yōu)化RF 構(gòu)建CPA-RF 預測模型克服RF 預測模型預測效果比較差的缺點。
1 基于核主成分分析的特征提取
與主成分分析方法相比,核主成分分析利用核函數(shù)把非線性的樣本數(shù)據(jù)映射到高維空間中,并在高維空間對樣本數(shù)據(jù)進行線性處理,該方法可以有效解決主成分分析方法只能處理線性數(shù)據(jù)等問題,并且方差貢獻率更加集中,樣本數(shù)據(jù)降維效果更好。由于論文篇幅有限,核主成成分分析的數(shù)學原理不再贅述,具體推導可參考文獻[16-17]。
核主成分分析算法的具體步驟如下[16-17]:
1)輸入樣本數(shù)據(jù),并在MATLAB 中調(diào)用zscore函數(shù)對數(shù)據(jù)進行標準化處理,消除數(shù)據(jù)不同量綱的影響;
2)設置徑向基參數(shù)為2.5,并利用徑向基核函數(shù)計算核矩陣G;
3)對核矩陣G進行中心化處理,可得矩陣G′;
4)求出矩陣G′的特征值和特征向量;
5)對矩陣G′的特征值進行降序排列,并找出對應順序的特征向量;
6)計算核主成分的數(shù)值、方差貢獻率和累計貢獻率。
2 CPA-RF風電功率短期預測模型
2.1 CPA
CPA 通過模擬食肉植物的吸引、捕獲、消化以及繁殖的過程來達到尋優(yōu)的目的[18]。CPA 的數(shù)學模型如下所示:
1)初始化階段。
按照式(1)對CPA 的種群個體進行初始化。
式中:xi,j為第i個個體在第j維度上的位置;i=1,2,…,N,N為Nplant棵食肉植物和Nprey個獵物個體的和,即N=Nplant+Nprey;j=1,2,…,d,d為待求解優(yōu)化問題的維數(shù);μj、分別為第j維變量的下限和上限;ηi,j為第i行第j列上產(chǎn)生的隨機數(shù),取值范圍為[0,1]。
對食肉植物算法的種群個體進行初始化后可得種群的初始位置為
對于第i個個體,也就是式(2)的第i行所有變量,它代表優(yōu)化問題的一個可行解。
為了確定可行解是否是最優(yōu)的,需要將第i個個體代入適應度函數(shù)f(·)中求解適應度函數(shù)值來判斷,將結(jié)果存儲到矩陣中,可得
對于最小化問題來說,適應度函數(shù)值越小,則該可行解越接近最優(yōu)解。
2)分類與分組階段。
算法的分類過程為:將式(3)計算得到的適應度函數(shù)值從小到大進行排序,把前面Nplant個個體作為食肉植物,剩下的Nprey個個體作為獵物。
算法的分組過程為:把Nplant棵食肉植物和Nprey個獵物分別從小到大依次排序,并將第1 個獵物分配給第1 棵食肉植物,將第2 個獵物分配給第2 棵食肉植物,以此類推,將第Nplant個獵物分配給第Nplant棵食肉植物。由于算法中獵物的個數(shù)大于食肉植物的數(shù)量,所以將第Nplant+1 個獵物分配給第1 棵食肉植物,依次類推,直到第Nprey個獵物分配給第Nplant棵食肉植物為止,并且滿足關系式k=Nprey/Nplant≥2。算法的分組過程如圖1 所示。

圖1 CPA分組過程Fig.1 Grouping process of carnivorous plant algorithm
3)生長階段。
由于土壤的營養(yǎng)成分不足,食肉植物會通過吸引、捕獲和消化獵物的方式來獲得營養(yǎng),從而促進自身的生長。食肉植物會散發(fā)香味吸引獵物,但獵物也有可能從逃脫食肉植物的魔爪。因此,在算法中引入吸引率,在圖1 中,每一棵食肉植物都隨機選取一個獵物,若吸引率大于隨機產(chǎn)生的一個數(shù)字,則食肉植物會被捕到該獵物并且消化它,進而促進食肉植物的生長。此時,食肉植物的生長數(shù)學模型為:
式 中:xi′,j為在第j維度上的第i′ 棵食肉植物,i′=1,2,…,Nplant;為生長率預設的數(shù)值;為用隨機數(shù)更新后的生長率;為在第j維度上對應食肉植物的那一組隨機選擇的第v個獵物;ηi′,j為第i′行第j列上產(chǎn)生的隨機數(shù),取值范圍為[0,1]。
若吸引率小于隨機產(chǎn)生的一個數(shù)字,則獵物可以逃脫食肉植物的魔爪并且繼續(xù)生長。此時,對應該行為的數(shù)學模型為:
食肉植物和獵物的生長過程一直在不斷地重復,直到達到預設的生長迭代次數(shù)Tgrowth為止。
4)繁殖階段。
食肉植物通過消耗獵物進行繁殖,并且算法中只允許第1 棵食肉植物可以繁殖。食肉植物繁殖過程的數(shù)學模型為:
式中:i′ ≠v′ ≠1;x1,j為算法的最優(yōu)解;為繁殖率;xv′,j為在第j維度上的第v′棵食肉植物;為計算參數(shù)。
在繁殖的過程中,無論維度如何,都會重新選擇第v′棵食肉植物,并且該過程會重復Nplant次。
5)更新適應度和組合階段。
將新生成的所有食肉植物以及獵物個體均添加到初始的種群中,并計算所有個體的適應度函數(shù)值,按從小到大的順序重新排序,把排在前N名的個體作為進入新的初始種群并進行下一輪的迭代更新。
6)算法的終止階段。
重復步驟2)—步驟5),直到滿足最大迭代次數(shù)Tmax為止。
2.2 RF回歸
RF 可以看作是由多棵彼此之間無關聯(lián)、相互獨立的決策樹組成的一種算法,該算法首先采用Bootstrap 采樣方法,從原始的樣本數(shù)據(jù)中提取多個樣本,根據(jù)每一個Bootstrap 樣本數(shù)據(jù)建立對應的決策樹模型,然后對多棵決策樹的預測結(jié)果進行相加并求取平均值,最后可得出RF 的預測效果[19]。
RF 回歸模型采用均方誤差最小的原則對樣本數(shù)據(jù)進行劃分,在抽樣樣本數(shù)據(jù)對應的節(jié)點處劃分為兩個樣本數(shù)據(jù)集并分別計算它們的均方誤差,將兩個樣本數(shù)據(jù)集各自均方誤差最小且兩個樣本數(shù)據(jù)集的均方誤差之和最小的點作為分裂節(jié)點。
在RF 算法中,設置不同決策樹的數(shù)量ntree和分裂節(jié)點處特征變量的數(shù)量mtry會對預測結(jié)果產(chǎn)生較大的影響。因此,選擇利用食肉植物算法對RF 算法中的ntree和mtry這兩個參數(shù)進行優(yōu)化,從而獲得預測性能更好的CPA-RF 預測模型。
2.3 構(gòu)建CPA-RF的風電功率短期預測模型
構(gòu)建CPA-RF 風電功率短期預測模型步驟如下:
1)對采集到與風電功率有關的多個影響因子進行核主成分分析,將貢獻率較高的幾個影響因子作為預測模型的輸入。
2)對貢獻率較高的幾個影響因子和風電功率數(shù)據(jù)的訓練集和測試集的比例設置為7∶3,將貢獻率較高的幾個影響因子和訓練集數(shù)據(jù)歸一化后一起訓練CPA-RF 預測模型,其中歸一化的計算表達式為[20-23]
式中:H為原始數(shù)據(jù);Hmin為原始數(shù)據(jù)最小值;Hmax為原始數(shù)據(jù)最大值。
3)設置食肉植物算法種群數(shù)量N=40,其中食肉植物的棵數(shù)Nplant=10,獵物個體的數(shù)量Nprey=30;最大迭代次數(shù)Tmax=20;待求解優(yōu)化問題的維數(shù)d=2;搜索空間變量的下限μ1=μ2=0.1 和上限;生長率;吸引率為0.8;生長迭代次數(shù)Tgrowth=2;繁殖率
4)初始化種群個體。
5)以平均絕對百分比誤差作為種群個體的適應度函數(shù),計算表達式為
式中:Treal(t) 為t時刻實際的風力發(fā)電功率;Tpred(t)為t時刻預測的風力發(fā)電功率;h為訓練集樣本數(shù)。
6)將食肉植物和獵物進行分類和分組。
7)判斷吸引率是否大于隨機數(shù)。如果條件成立,食肉植物將會成長;否則,獵物會掙脫并成長。
8)第一棵食肉植物進行繁殖。
9)更新適應度并組合新種群。
10)判斷算法是否已達到最大迭代次數(shù),如果是,那么停止迭代,輸出RF 的最優(yōu)參數(shù),得到CPARF 預測模型;否則,返回步驟5),直到滿足終止條件為止。
將貢獻率較高的幾個影響因子和測試集數(shù)據(jù)歸一化后一起輸入到訓練好的CPA-RF 預測模型中,從而獲得風電功率的預測結(jié)果。
基于核主成分分析和食肉植物算法優(yōu)化RF 的風電功率預測流程如圖2 所示。
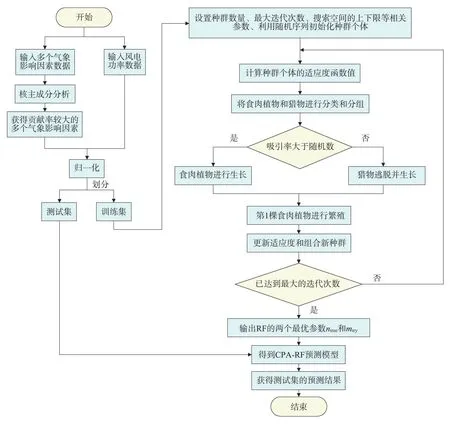
圖2 基于核主成分分析和食肉植物算法優(yōu)化RF的風電功率預測流程Fig.2 Wind power prediction flow chart based on random forest optimized by kernel principal component analysis and carnivorous plant algorithm
3 仿真分析
對某地風力發(fā)電功率進行短期預測,選取某地區(qū)2019 年1 月1 日—12 日的13 個氣象因素以及風電功率數(shù)據(jù)進行研究。這13 個氣象因素包括測風塔10 m 風速、測風塔30 m 風速、測風塔50 m 風速、測風塔70 m 風速、輪轂高度風速、測風塔10 m 風向、測風塔30 m 風向、測風塔50 m 風向、測風塔70 m風向、輪轂高度風向、溫度、氣壓、濕度。選取1 月前10 天的氣象數(shù)據(jù)和風電功率數(shù)據(jù)作為訓練集,其中1 月前10 天的風力發(fā)電功率歷史數(shù)據(jù)如圖3 所示,所選取的風電功率數(shù)據(jù)的每次采樣時間為15 min,一共采樣960 個數(shù)據(jù)點。選取1 月11 日和12 日的氣象數(shù)據(jù)和風電功率數(shù)據(jù)作為測試集,即選取1 月11 日和12 日作為待預測日期,其中預測時間間隔為15 min,一共輸出192 個風力發(fā)電功率預測數(shù)據(jù)。

圖3 1月前12天的風力發(fā)電功率Fig.3 Wind power in the first 12 days of January
3.1 選出合適的氣象因素
風電功率受風向、風速、溫度、氣壓和濕度等影響。若將所有的氣象因素都輸入到預測模型中,則會增加預測模型的訓練難度和時間。由于這13 個氣象因素和風電功率之間呈現(xiàn)非線性關系,因此,相比較于主成分分析算法,采用核主成分分析算法提取出與風電功率有著很強相關性的氣象因素具有明顯的優(yōu)勢。基于核主成分分析的方差貢獻率和累計貢獻率如圖4 所示。

圖4 基于核主成分分析的方差貢獻率和累計貢獻率Fig.4 Variance contribution rate and cumulative contribution rate based on kernel principal component analysis
由圖4 可知,前8 個主成分的累計貢獻率達到99.98%,說明這8 個氣象因素與風力發(fā)電功率的輸出有著很大的關系。因此,選擇這8 個氣象因素作為預測模型的輸入變量。
3.2 風電功率預測仿真結(jié)果及其分析
為了突出利用核主成分分析方法提取前8 個與風力發(fā)電功率有關氣象因素的合理性和有效性,分別選擇前8 個氣象因素和13 個氣象因素作為輸入變量,對1 月11 日和12 日的風電功率進行預測,基于LSTM 預測模型、雙向長短期記憶神經(jīng)網(wǎng)絡(bidirectional long short-term memory,BiLSTM)預測模型、RF 預測模型和CPA-RF 預測模型的仿真結(jié)果如圖5 所示。

圖5 4種預測模型預測效果的對比Fig.5 Comparison of prediction effect of four prediction models
從圖5 中可以看出,LSTM 預測模型和BiLSTM預測模型的預測值均會出現(xiàn)負數(shù)的情況,這顯然不符合實際情況,而RF 預測模型和CPA-RF 預測模型的預測值都沒有出現(xiàn)負數(shù)的情況,證明此時使用RF預測模型和CPA-RF 預測模型對風電功率進行短期預測的準確性和合理性。并且從圖中可以看出,當輸入8 個氣象因素時,基于CPA-RF 預測模型的預測值最接近于風力發(fā)電功率真實值,證明利用核主成分分析方法提取8 個氣象因素作為輸入要比單純直接輸入13 個氣象因素的效果要好,多余的5 個氣象因素會影響到預測模型的預測精度。
3.3 風電功率預測模型結(jié)果的評價指標
采用均方根誤差TRMSE、平均絕對誤差TMAE以及絕對誤差TAE這3 種誤差指標對1 月11 日和12 日的風電功率預測結(jié)果進行評價,計算表達式分別為[23-24]:
式中:m為預測樣本數(shù)據(jù)的數(shù)量。
1)均方根誤差和平均絕對誤差的比較。
分別輸入8 個氣象因素和13 個氣象因素時,基于LSTM 預測模型、BiLSTM 預測模型、RF 預測模型和CPA-RF 預測模型的均方根誤差和平均絕對誤差的結(jié)果分別如表1 和表2 所示。

表1 輸8個氣象因素時不同方法預測誤差分析Table 1 Prediction error analysis of different methods when inputting 8 meteorological factors 單位:MW

表2 輸入13個氣象因素時不同方法預測誤差分析Table 2 Prediction error analysis of different methods when inputting 13 meteorological factors 單位:MW
從表1 和表2 中可以看出,對于同一種預測方法,當分別輸入8 個氣象因素和13 個氣象因素時,除了BiLSTM 預測模型的均方根誤差和平均絕對誤差一樣之外,其余的預測方法都是輸入8 個氣象因素的預測效果要比輸入13 個氣象因素好,證明利用核主成分分析方法提取8 個氣象因素作為輸入的有效性,比直接輸入13 個氣象因素更加合理和可靠。另外,當輸入8 個氣象因素時,基于CPA-RF 預測模型的均方根誤差和平均絕對誤差是所有預測方法中最小的,證明把核主成分分析和利用食肉植物算法優(yōu)化RF 這兩種方法相結(jié)合可以提高預測模型的預測精度。
2)絕對誤差的比較。
絕對誤差可以描述單個預測值與實際風電功率數(shù)值之間差異的大小。分別輸入8 個氣象因素和13個氣象因素時,基于LSTM 預測模型、BiLSTM 預測模型、RF 預測模型和CPA-RF 預測模型的絕對誤差如圖6 所示。
從圖6 中可以看出,在所有預測方法中,當輸入8 個氣象因素時,基于CPA-RF 預測模型的絕對誤差在大部分樣本數(shù)據(jù)點是最小的,進一步證明結(jié)合核主成分分析方法和CPA-RF 預測模型對風力發(fā)電功率進行預測的可靠性和準確性,其預測結(jié)果更準確,有助于解決風電功率短期預測精度不夠高的問題。
3)4 種預測模型耗時的比較。
分別輸入8 個氣象因素和13 個氣象因素時,基于LSTM 預測模型、BiLSTM 預測模型、RF 預測模型和CPA-RF 預測模型的耗時結(jié)果如表3 所示。
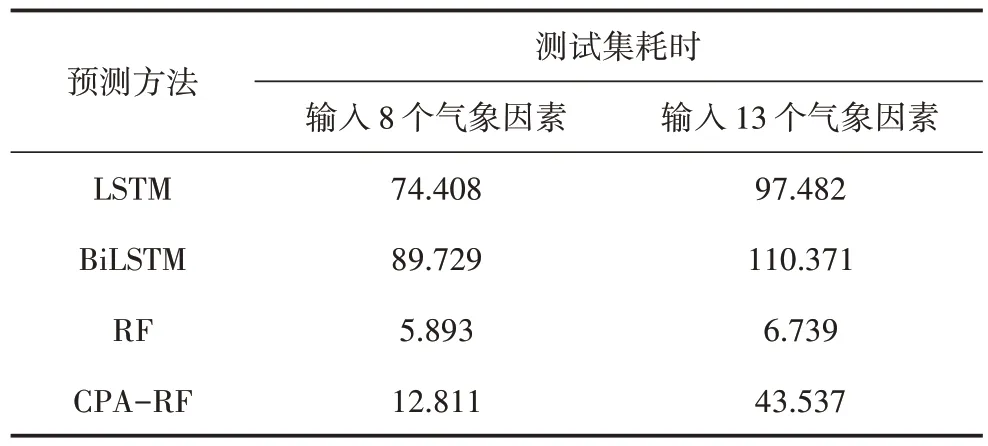
表3 不同預測方法的耗時Table 3 Time consuming for different prediction methods 單位:s
從表3 種可以看出,對于同一種預測方法,輸入13 個氣象因素的耗時均比輸入8 個氣象因素要長,這是因為輸入氣象因素比較多從而導致預測模型耗時長。另外,當輸入8 個氣象因素時,LSTM 預測模型和BiLSTM 預測模型的耗時均達到70 s 以上,而RF 預測模型的耗時只有5.893 s,CPA-RF 預測模型的耗時為12.811 s,證明使用LSTM 預測模型和BiLSTM 預測模型的耗時遠遠多于RF 預測模型,而CPA-RF 預測模型的耗時僅比RF 預測模型多6.918 s。
綜合預測精度和耗時這兩個方面,CPA-RF 預測模型是最好的選擇。
4 結(jié)論
針對風電功率短期預測精度不夠高的問題,提出一種基于核主成分分析和CPA-RF 的風電功率短期預測方法,并選取某地區(qū)在2019 年1 月1 日—12日的數(shù)據(jù)進行研究,可以得出以下結(jié)論:
1)若選取13 個氣象因素作為風電功率短期預測的輸入,結(jié)果往往不夠準確。而利用核主成分分析選出8 個重要氣象因素作為預測模型的輸入可以很好地解決輸入全部氣象因素所造成的精度不高問題,驗證了核主成分分析方法選出主成分的合理性和準確性。
2)利用食肉植物算法優(yōu)化RF 中決策樹的數(shù)量和分裂節(jié)點處特征變量的數(shù)量可以獲得比RF 預測精度更高的CPA-RF 預測模型,證明方法的可行性,為提升風電功率短期預測精度提供思路。
3)LSTM 預測模型和BiLSTM 預測模型的耗時比RF 預測模型和CPA-RF 預測模型都要多得多,并且預測數(shù)值出現(xiàn)了負數(shù)情況,不符合實際。而在輸入8 個氣象因素時,CPA-RF 預測模型僅比RF 預測模型多6.918s,但預測精度有所提升。因此,在兼顧用時和預測精度這兩個方面,CPA-RF 預測模型是最優(yōu)的選擇。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
少兒科學周刊·兒童版(2017年5期)2017-06-29 22:24:28
少兒科學周刊·兒童版(2017年5期)2017-06-29 16:46:33
紅領巾·萌芽(2017年5期)2017-06-23 10:35:59
爆笑show(2016年7期)2017-02-09 09:36:13
光學精密工程(2016年6期)2016-11-07 09:07:19
少兒科學周刊·兒童版(2015年10期)2015-11-07 03:42:03
核科學與工程(2015年4期)2015-09-26 11:59:03
