用于冷啟動推薦的用戶偏好跨域轉移框架
2024-02-15 01:53:16劉玉芳王紹卿鄭順張麗杰孫福振
山東理工大學學報(自然科學版) 2024年1期
劉玉芳,王紹卿,鄭順,張麗杰,孫福振
(山東理工大學 計算機科學與技術學院,山東 淄博 255049)
在Web和移動應用程序中,個性化推薦系統(RS)在緩解信息過載,促進用戶體驗方面扮演著越來越重要的角色。近年來,深度學習在RS中得到了廣泛的應用,以克服傳統推薦技術的障礙。其中,跨領域推薦(CDR)[1-2]和冷啟動推薦[3]問題引起了廣泛關注。跨域推薦系統的目標是將其他領域(稱為源域)中可用的知識轉移到用戶交互數據稀疏的目標領域(稱為目標域)。通常選擇重疊用戶來學習兩個域之間的映射關系,以便將源域中的模式應用于目標域[2]的冷啟動用戶。CDR的核心任務是連接用戶在源域和目標域中的偏好,也稱為偏好轉移。現有的CDR方法大都是將目標域中用戶(或項目)的特性利用學習到的映射函數直接替換為源域中相似用戶(或項目)的特性,然而這種方法假設所有用戶在源域和目標域之間共享相同的關系,并學習所有用戶共享的映射函數。
在實際場景中,源域和目標域的用戶偏好之間的關系復雜多變,單個映射函數很難準確地捕獲所有的用戶關系。為了緩解這一缺點,本文使用個性化的映射函數來建模不同域中用戶偏好之間的復雜關系。也就是說,用戶偏好的轉移應該是個性化的。此外,在冷啟動場景下,重疊用戶的數量非常少。因此,有限的重疊用戶嚴重影響了用戶的偏好轉移,導致泛化能力不足,降低了模型在目標域冷啟動用戶上的性能。
近年來,元學習在推薦系統中的應用得到快速發展[4-6]。元學習[6]主要針對小樣本學習問題,通過在大量的訓練任務上對模型進行訓練及參數更新,能夠很好地解決傳統神經網絡模型泛化能力不足、對新任務適應性較差的問題。元學習訓練和測試過程以任務為基本單元,每個任務都有訓練數據集和測試數據集,又稱為支持集和查詢集。元學習中要準備許多任務來進行學習,第一層訓練單位是任務,第二層訓練單位是每個任務對應的數據。本文提出了一個用于冷啟動推薦的用戶偏好跨域轉移框架(UPCTFCR)。首先,設計了一個自注意力編碼器來有效提取用戶偏好,考慮對不同的項目施加不同的權重,計算注意力分數,對項目加權求和。然后,學習一個元學習器,即元網絡,用戶在源域中的特征嵌入作為該網絡的輸入,為每個用戶生成個性化映射函數,該函數能夠捕獲不同域之間的每個用戶之間的偏好關系。經過訓練后,將元學習器得到的參數和用戶在源域中的嵌入進行矩陣相乘,得到轉換后的嵌入。最后,將該嵌入作為用戶在目標域的初始嵌入,對用戶偏好的項目進行預測。
在實踐中,元網絡的優化是另一個挑戰。現有的面向映射的優化過程,直接最小化源域中轉換后的用戶嵌入和目標域中用戶嵌入之間的距離。然而,這樣的優化過程容易導致映射函數對用戶嵌入不準確。而在實際的推薦系統中,很難學習到用戶準確的嵌入,這就限制了學習到的映射函數的性能。此外,面向映射的優化方法難以訓練元學習器。因此,本文采用面向任務的優化方法來訓練元學習器,利用用戶對項目的評分任務作為優化目標。
1 相關概念
1.1 跨域推薦
在傳統的推薦系統中,通過分析單一域內的用戶歷史交互行為來進行用戶興趣的預測,從而進行推薦,比如說通過用戶在抖音App上的歷史觀看記錄來為用戶進行后續的視頻推薦。而跨域推薦旨在結合多個領域的數據,利用其他領域(源域)的豐富信息,使得在目標域上能進行更好推薦。跨域推薦能夠實施的假設是:用戶的興趣偏好或項目特征在領域之間存在一致性或相關性。跨域推薦利用的正是領域間的一致性或相關性,如用戶或項目的交集,用戶興趣或項目特征的相似程度,潛在因子的相互關系等進行知識遷移,從而彌補目標域所面臨的信息不足的問題,改善推薦性能。近年來,研究者提出了許多基于深度學習的模型來增強知識遷移。CoNet通過使用前饋神經網絡之間的交叉連接來轉移知識。MINDTL將目標域的CF信息和源域中的評分矩陣結合起來。DDTCDR開發了一種新的潛在正交映射來提取用戶在多個域上的偏好,同時保留了在不同潛在空間上用戶之間的關系。與多任務方法類似,這些方法側重于提出一個設計良好的深層結構。本文設計了一個能夠顯式地建模不同域之間知識遷移的框架,而不是采用特殊的深層結構來隱式地轉移知識。
1.2 冷啟動推薦
為新用戶或新項目提供推薦具有極大的挑戰,也稱為冷啟動問題[7]。以協同過濾的推薦系統為例,假設每個用戶(或項目)都有評分,可以推斷出相似用戶(或項目)的評分。但是,對于新注冊的用戶(或項目)難以實現,因為沒有相關的瀏覽、點擊或下載等數據,也就沒辦法使用矩陣分解技術進行推薦。解決冷啟動問題的方法主要有兩種:第一種方法通過設計決策策略來解決冷啟動問題,例如使用上下文賭博機[8],通過向用戶推薦感興趣的物品來探索用戶偏好;第二種是利用輔助信息來緩解冷啟動問題,常用的輔助信息包括用戶屬性[3]、項目屬性[9-10]、知識圖[11]、輔助域[12]的樣本等。本文提出的框架屬于第二種,在輔助域樣本的幫助下,CDR方法能夠得到更好的結果。
1.3 冷啟動推薦中的元學習
元學習(meta-learning),含義為學會學習(learn to learn),旨在訓練一個參數化模型,能夠快速適應在訓練中沒有使用的新任務。元學習希望模型獲取一種“學會學習”的能力,使其可以在獲取已有知識的基礎上快速學習新的任務。近年來,元學習已經引起了推薦系統領域研究者的關注。這些工作大多集中在很少有訓練樣本的推薦場景上[13]。例如,MLRS-CCE提出了一種動態元學習模型,利用歷史和當前的用戶-項目交互,將用戶的偏好動態地分解為特定時間和時間演變的表示來預測用戶的評分[14]。LLAE將冷啟動推薦制定為具有用戶信息的少樣本學習任務[3]。PTUPCDR通過使用元網絡來生成個性化的橋函數,實現用戶的偏好轉移[15]。本文提出的UPCTFCR利用元學習器來學習映射函數的參數,將用戶的交互序列劃分為支持集和查詢集來訓練模型,通過在大量任務上進行訓練,來提高模型的泛化能力。
1.4 自注意力機制
自注意力機制是注意力機制的變體,其減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性。在深度學習推薦模型中,注意力機制能夠幫助模型抓住最具信息量的特征,推薦最具代表性的物品。自注意力機制能夠為用戶歷史序列數據分配不同的權重,以動態捕捉重點信息,反映了用戶反饋數據之間的相互依賴,并且自注意力機制在長序列的數據上表現出色。
2 UPCTFCR模型
2.1 符號定義
本文研究的CDR問題,包含一個源域和一個目標域。每個域都有一個用戶集U={u1,u2,…},一個項目集V={v1,v2,…}和一個評分矩陣R。rij∈R表示用戶ui和項目vj之間的交互。為了區分這兩個域,將源域的用戶集、項目集和評分矩陣分別表示為Us、Vs、Rs,目標域的表示為Ut、Vt、Rt。將這兩個域之間的重疊用戶定義為Uo=Us∩Ut。對于項目而言,Vs和Vt是不相交的,這意味著這兩個域之間沒有重疊項目。
2.2 自注意力編碼器
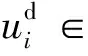
生成映射函數的第一步是從交互的項目中獲取用戶的個性化可轉移特征。但是,在目標域中冷啟動用戶沒有交互項,因此,利用源域中的交互序列S找到有助于知識遷移的可轉移特征是非常有必要的。直覺上,不同的項目對知識轉移有不同的貢獻。自注意力機制能夠捕捉輸入序列中不同項目之間的相關性,并為它們分配不同的權重。通過加權和來獲得用戶的可轉移特征:
(1)
(2)
式中:Q,K,V由單層線性網絡生成;dk等于隱藏層的維數除以注意力的頭數,本文取5;pui∈k為用戶ui的可轉移特征嵌入;αj為vj項的注意力得分,可以解釋為vj在預測用戶個性化偏好中的重要性。
2.3 元學習器
不同域的用戶偏好之間的關系因用戶而異,因此,偏好轉移的過程需要是個性化的。直覺上,偏好關系和用戶特征之間存在一定的聯系。基于這種直覺,提出了一個元學習器,它以用戶的可轉移特征作為輸入,然后根據源域和目標域中的用戶嵌入訓練一個因用戶而異的個性化參數。所提出的元學習器的表述為
θ=g(pui;φ),
(3)
式中g(·)是一種兩層前饋網絡的元學習器,它是由φ參數化的網絡。將訓練得到的個性化參數θ作為映射函數f(·)的初始參數,映射函數可以定義為任何結構。本文使用簡單的矩陣相乘函數作為映射函數,并將θ作為映射函數的參數而不是輸入。生成的映射函數因用戶而異,并取決于用戶的特征。
將用戶在源域中的嵌入表示輸入映射函數中,得到轉換后的用戶嵌入表示。將轉換后的嵌入表示看作用戶在目標域中的初始嵌入。通過映射函數,可以得到轉換后的個性化用戶嵌入:
(4)
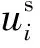
2.4 面向任務的元網絡優化
受基于優化的元學習概念的啟發,將這個概念放入UPCTFCR中,以反映只有少量交互的個性化用戶偏好。本文的模型考慮了用戶的項目消費歷史記錄,構建M(M>10)組訓練任務,隨機選取序列中的10個項目作為查詢集,其余為支持集。為了反映用戶的興趣,該模型會根據用戶唯一的項目消費歷史來更新元學習器中的參數。此外,與MAML[13]不同,本文擴展了匹配網絡的思想,不限制項目消費歷史的長度(即支持集的長度不是固定的)。
為了訓練元學習器,面向任務的訓練過程直接利用最終推薦任務的評分作為優化目標。具體可以表述為
(5)
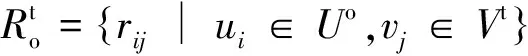
與面向映射的過程相比,面向任務的優化過程有兩個優勢:
1)面向任務的優化過程可以減輕不合理嵌入的影響。它直接使用真實的評分數據,而不是利用近似的中間結果優化模型。
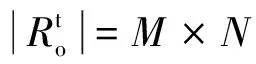
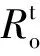
算法1 元學習器的偽代碼

輸入: 超參數α,β,元學習器g·()輸出: 模型參數θ1.初始化參數θ2.while not converge do3.Sampling a batch of users B~p(B)4.For user i in B do5.計算θlifθ()6.θ'i=θ-αθlifθ()7.End for8.Update θ←θ-βθ∑i∈Blifθ'i()9.End while
2.5 整體程序
UPCTFCR的模型框架如圖1所示。訓練過程可分為4個階段:預訓練階段、自注意力編碼階段、元學習階段和測試階段。
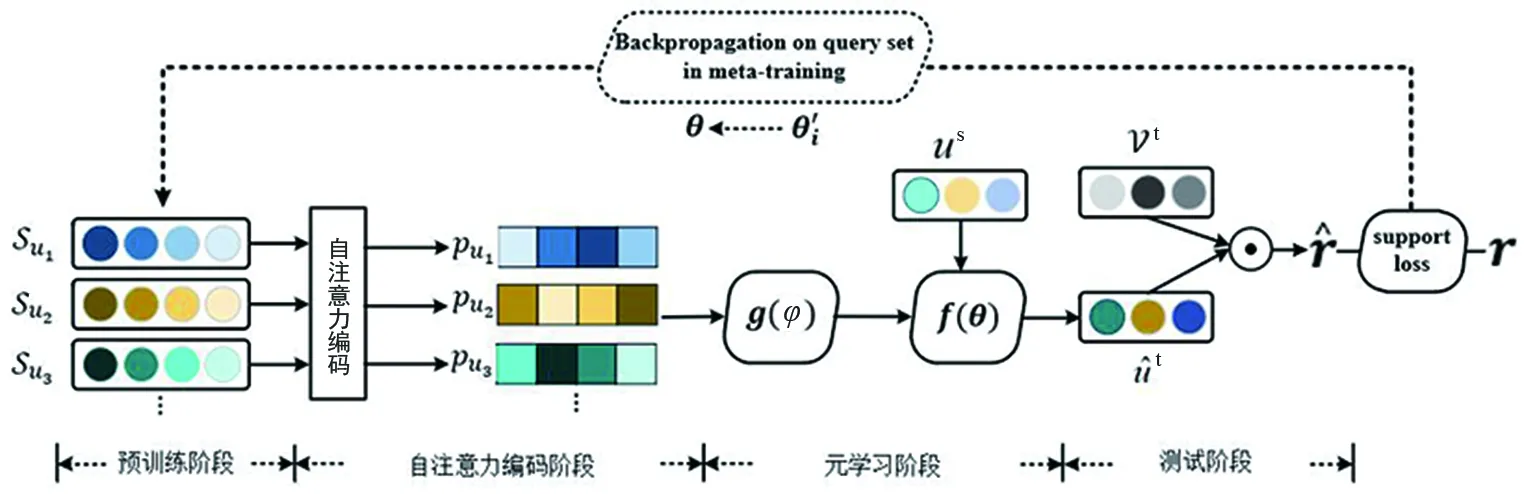
圖1 UPCTFCR的模型框架
預訓練階段:分別學習源域和目標域的用戶和項目的隱式向量。損失函數表示為
(6)
式中|R|表示評分數量,經過預訓練步驟后,可以得到預訓練的嵌入數據us、ut、vs、vt。
自注意力編碼階段:從源域的交互序列中提取有助于知識遷移的可轉移特征是非常關鍵的。自注意力機制能夠為用戶交互項目分配不同的權重,以捕捉序列中不同項目之間的相關性,從而獲得用戶可轉移特征pui。
元學習階段:現有的方法直接訓練一個共同的映射函數,而UPCTFCR訓練自編碼器和元學習器。利用式(5)對特征編碼器和元網絡進行優化。
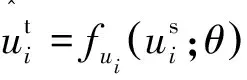
3 實驗
3.1 實驗設置
3.1.1 數據集概述
亞馬遜評論數據集是使用最廣泛的電子商務推薦公共數據集之一,本文使用Amazon-5核心數據集,每個用戶或項目至少有5個評分。該數據集包含24個不同的項目域。本文選擇了3個流行的類別:movies_and_tv(電影)、cds_and_vinyl(音樂)、books(書籍)。然后,將3個CDR任務定義為任務1:電影→音樂,任務2:書籍→電影,任務3:書籍→音樂。由表 1可知,源域的評分數量明顯大于目標域中的評分數量。不同于許多現有的工作只選擇了數據集的一部分來進行評估,本文直接使用所有數據來模擬真實世界的應用程序。
3.1.2 評估指標
Amazon審查數據集包含評分數據(0分—5分)。采用平均絕對誤差(MAE)和均方根誤差(RMSE)作為評價指標。
3.1.3 基線模型
基線模型可以分為單域和跨域兩組。在第一組中,將源域和目標域分別視為單域,并利用MF方法訓練單域模型。第二組包括針對冷啟動用戶的最先進的CDR方法,由于UPCTFCR屬于基于映射的CDR方法,本文主要將UPCTFCR與基于映射的方法進行比較。因此,選擇以下方法作為比較的基線。
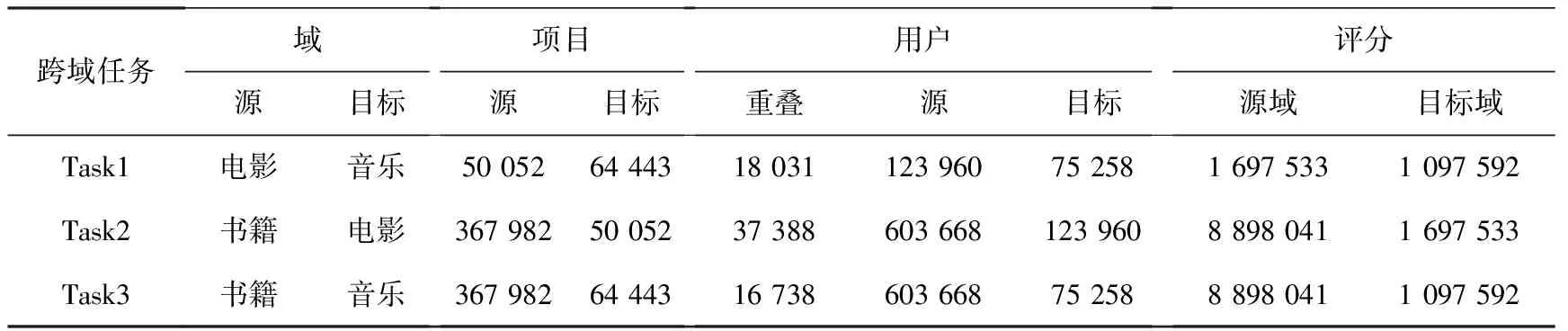
表1 跨域任務信息
單域:
1)TGT,TGT[16]是MF模型,僅使用目標域數據進行訓練。
2)CMF,CMF是MF的延伸。在CMF中,用戶的嵌入向量可以跨源域和目標域進行共享。
跨域:
1)SSCDR,SSCDR[17]是一種基于半監督的橋接的方法。
2)DCDCSR,DCDCSR[18]屬于基于橋的方法,它考慮了個體用戶在不同領域的評分稀疏程度。
3)EMCDR,EMCDR[12]是一種常用的冷啟動CDR方法。首先采用矩陣分解(MF)學習嵌入,然后利用網絡將用戶嵌入從輔助域連接到目標域。
4)PTUPCDR,PTUPCDR[15]屬于基于橋的冷啟動CDR方法,它通過使用用戶特征嵌入的元網絡來生成個性化的橋接功能,以實現每個用戶的個性化偏好轉移。
3.1.4 實施細節
使用PyTorch實現本文提出的框架。對于每個任務和方法,Adam優化器初始學習率通過在{0.001、0.005、0.01、0.02、0.1}范圍內的網格搜索進行調整。另外,將嵌入的維度設置為10。對于所有的方法,將小批量大小設置為512。采用了相同的全連接層,以方便比較EMCDR、DCDCSR、SSCDR、PTUPCDR和UPCTFCR。其中,UPCTFCR的映射函數是由元學習器生成的。該元學習器是一個隱藏單元為2×k的兩層線性模型,其中k表示嵌入維數,該元學習器的輸出維數為k×k。
為了評估本文UPCTFCR的性能,在目標域中隨機刪除一部分重疊用戶,把他們作為測試用戶,其他的重疊用戶樣本用來訓練元學習器。實驗中,將測試(冷啟動)用戶β的比例設置為總重疊用戶的20%。在訓練數據中篩選項目消費歷史長度在13到100之間的重疊用戶。對于訓練數據中的每個重疊用戶,使用項目序列中的10個隨機項目作為查詢集,其余的項目作為支持集,即項目消費歷史長度在3到90之間,即使支持集的長度(即項目消費歷史的長度)不是固定的,也能夠表現出良好的性能。
3.2 對比實驗
表2顯示了UPCTFCR在3個跨域推薦任務上的性能,從實驗結果可以觀察到以下幾點:
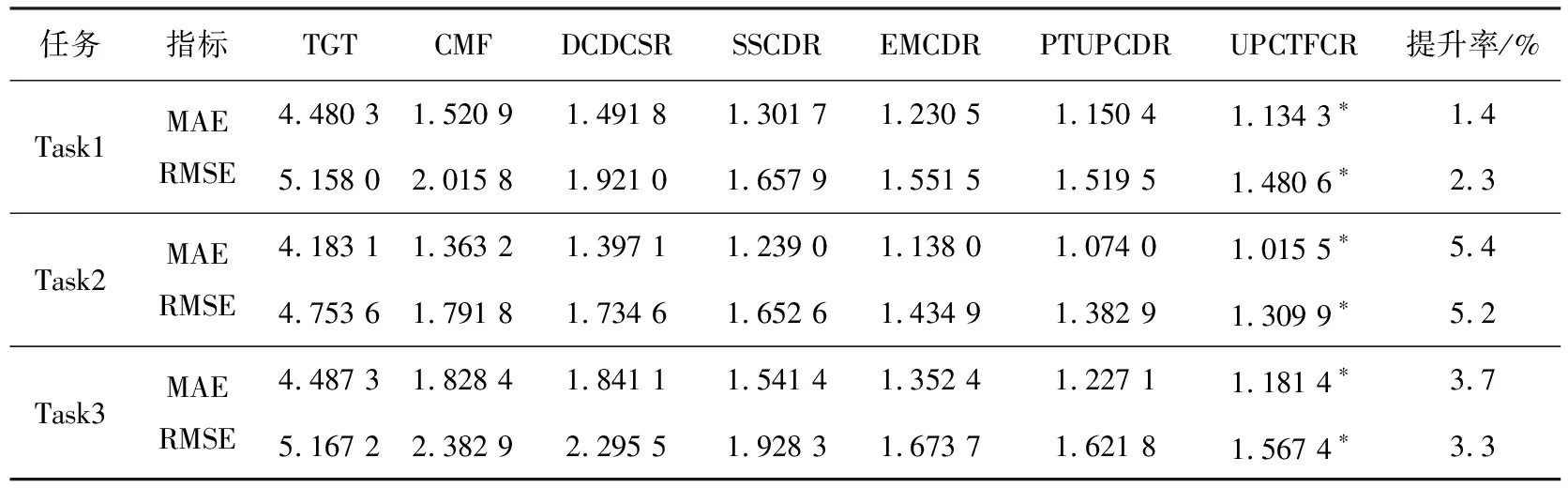
表2 不同模型在3個跨域任務上的性能比較
1)TGT性能并不理想。與GT相比,所有其他跨域方法都可以利用來自源域的數據,從而獲得更好的效果。因此,利用來自輔助域的數據是緩解數據稀疏性、提高目標域推薦性能的有效方法。
2)CDR方法在大多數任務中性能都可以優于CMF。這是因為CMF通過將來自兩個域的數據看作是相同的而忽略了潛在的域轉移。相反,映射函數可以將源嵌入轉換到目標特征空間中,有效地減輕了域位移的影響。因此,通過更有效地利用輔助域來研究CDR是非常必要的。
3)通過觀察置信度為95%的t檢驗的結果,可以發現UPCTFCR在大多數情況下都能顯著優于PTUPCDR,這表明UPCTFCR是冷啟動推薦的有效解決方案。
3.3 消融實驗
消融實驗進一步探索所提出的UPCTFCR模型的各個組成部分對性能的影響。
1)UPCTFCR-1:將模型中自編碼器去掉,保留元學習部分。
2)UPCTFCR-2:將模型中元學習器和基于參數優化的元學習去掉,僅保留2.2節中自注意力編碼器。
3)UPCTFCR-3:去掉模型中的參數優化部分,在自編碼器中引入2.3節中介紹的元學習器。
4)UPCTFCR:本文提出的模型框架。
表3顯示了引入的變體在3個跨域推薦任務上的消融測試結果。在之前的模型上逐步增加新的子模塊或特征時,可以觀察到整體推薦性能的改善,這說明元學習對于冷啟動跨域推薦的有效性。
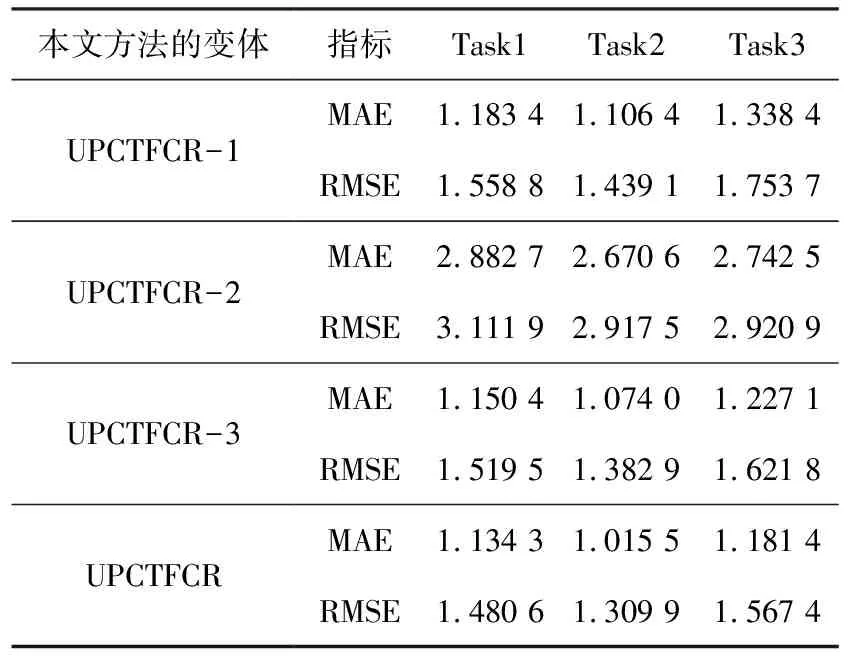
表3 在3個跨域任務上的消融測試結果
3.4 泛化實驗
對比實驗主要將其方法應用于MF進行實驗評價。然而,MF是一個非神經網絡模型,在基于用戶行為的推薦算法里,矩陣分解算法是效果較好方法之一。因此,為了證明UPCTFCR和其他基于映射的方法的兼容性,將EMCDR、PTUPCDR和UPCTFCR應用到兩個更復雜的神經網絡模型:GMF和YouTube DNN。GMF在點積預測函數中為不同的維度分配不同的權值,這可以看作是普通MF的一種推廣。YouTube DNN是一個雙塔模型。對于GMF,通過元學習訓練的參數可以直接將用戶嵌入映射到目標域。對于YouTube DNN,映射函數將轉換用戶塔的輸出。在非神經網絡模型(MF)和神經網絡模型(GMF,YouTube DNN)上進行了泛化實驗。從圖2所示的結果,可以得到以下結論:

(a)MF
1)基于映射的CDR方法可以應用于各種基礎模型。對于不同的基線模型,EMCDR、PTUPCDR和UPCTFCR都有效地提高了在目標域中對冷啟動用戶的推薦性能。由于GMF和YouTube DNN是兩種在大規模的現實世界推薦中流行且設計良好的模型,它們實現了比普通MF更好的性能。
2)廣義的UPCTFCR可以達到令人滿意的性能。一方面,通過各種基礎模型,廣義的UPCTFCR可以不斷地取得較好的結果;另一方面,冷啟動問題具有很高的挑戰性,MAE的結果足以證明廣義UPCTFCR在冷啟動場景中的有效性。
4 結束語
為了更好地將用戶偏好從源域轉移到目標域,將元學習引入冷啟動跨域推薦中,針對每個用戶的歷史交互項目,使用元網絡為每個用戶訓練一個元學習參數,從而實現用戶的個性化推薦。具體來說,學習了一個包含用戶特征嵌入的元網絡,得到因用戶而異的個性化參數,通過映射函數來初始化用戶嵌入,以實現用戶偏好的個性化轉移。在真實數據集上進行了實驗來評估所提出的模型,結果驗證了所提出的模型在冷啟動跨域推薦的有效性。在未來,可以將更多的內容信息集成到本文的框架中,以進一步緩解冷啟動問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
