期刊論文支撐數據FAIR原則的應用評估與案例分析
2024-02-18 14:07:58劉桂鋒王清炫韓牧哲
現代情報 2024年2期
劉桂鋒 王清炫 韓牧哲










關鍵詞:FAIR原則;期刊論文;支撐數據;數據管理;數據科學;應用評估;案例分析
隨著大數據時代的到來,科學研究模式也發生改變,除了傳統的實驗科學、理論科學和計算科學,現在還出現了被稱為“數據密集型科學”的第4種科學發現模式。海量的科學數據對多個學科領域的科研活動產生了深遠的影響和顯著的推動作用。隨著科技創新的不斷發展,系統化、可靠性高的科學數據支持變得越來越關鍵。如何對這些數據進行高效地管理和利用,成為促進各研究領域向好發展的重要因素。隨著開放科學運動向縱深發展,科學數據逐漸占據與學術論文同等甚至更為重要的位置。科學數據是科研成果的重要產出,支撐學術論文的科學數據在科學研究活動中的地位越來越重要。
支撐論文結論的研究數據(Supporting Data,論文支撐數據或稱為論文關聯數據),是論文研究不可或缺的部分,是論文結論的驗證基礎,只有通過開放共享,才能保證論文結論得到客觀檢驗、重復驗證和可靠應用的保障。國務院辦公廳印發《科學數據管理辦法》、中國科學院的《科學數據管理與開放共享辦法》等倡議作者將論文支撐數據開放共享。國外,許多期刊強烈鼓勵或要求作者把論文支撐數據提交到公共平臺共享。如SpringNature、Elsevier、Wiley等國際大型學術期刊出版商均推薦符合FAIR原則的存儲平臺,根據數據出版流程提出相應政策。期刊論文支撐數據的開放,必將對推動科學數據共享重用、數據引用和科研評價具有重要作用,也是治理學術環境和學術評價機制的重要策略。中國科學院文獻情報中心主辦的中文核心期刊《數據分析與知識發現》是我國圖書情報學乃至社會科學領域實現研究論文支撐數據開放共享的先行者,該期刊出臺了《論文支撐數據公共保存與共享暫行辦法》,保障論文支撐數據的可靠檢驗、嚴謹和高質量,規范科研人員提交和引用數據的行為。通過初步調研發現,《數據分析與知識發現》期刊的支撐數據公共保存與共享策略與國際通用的促進科學數據共享和重用的FAIR原則有高度的領域契合性。因此,本文嘗試結合FAIR原則構建指標體系,以《數據分析與知識發現》期刊的論文支撐數據為樣例,對相關科學數據的開放共享模式進行分析和評價,并為社科類中文學術期刊的科學數據的共享和重用前景提出合理化建議與優化策略。
1相關研究現狀
1.1FAIR原則研究概述
隨著數據密集型時代的到來,開放共享和管理科學數據逐漸成為開放科學建設的核心。為解決科研數據領域的數據發現、訪問、集成分析等問題,FAIR原則于2014年在荷蘭萊頓的洛倫茲研討會上被首次提出,并于2016年由FORCE11小組正式發布。此后,FAIR原則逐漸受到科研領域,尤其是科學數據開放共享和管理領域的關注。FAIR原則作為一套促進和確保科學數據可發現(Findable)、可訪問(Accessible)、可互操作(Interoperable)和可重用(Reusable)的原則,推進其實施,對保障科學數據充分共享與重用,以及最大限度地發揮科學數據的價值具有重要意義。FAIR原則自被提出以來就成為國內外研究的熱點,當前可將FAIR原則的相關研究歸為FAIR原則理論研究和實踐應用兩個方面。
理論上,國內外主要對FAIR原則內容進行分析解析。邢文明等對FAIR原則進行解讀,提出背景、內容、實施路徑以及相關案例分析。邱春艷對歐盟推動FAIR原則的內容、實踐路徑進行調查。Boeckhout M等對FAIR原則在數據管理實踐中面臨的問題進行了闡述。Juty N等單獨對FAIR原則中的F(可發現性)原則進行了詳細分析。陳書賢等對國內外FAIR原則研究成果及應用現狀進行了梳理。
實踐應用上,我國FAIR原則的應用已拓展到科學數據管理平臺、資源及領域數據庫中。在現狀調研方面,李楠楠等、李騏安等分別調研了國內外科學數據中心和科學數據資源的FAIR應用情況。戚筠等、李春秋等分別調研了生物信息學領域和醫學領域數據平臺的FAIR應用情況。在基于FAIR原則的出版控制方面,國內成果較少,目前僅見雷雪、孔麗華等在FAIR原則背景下分別對科技期刊數據出版現狀、政策所做的分析。國際上FAIR原則的實踐應用則更加廣泛,目前,國外已有相關組織構建了FAIR數據評估的模型和方法,如FAIR Metrics Group制定14條指標評估FAIR化程度;研究數據聯盟(RDA)設置FAIR成熟度模型,也制定一套通用的FAIR評估指標。同時,FAIR原則已充分應用到醫學、生物科學、農業等多個學科領域并成立基于FAIR原則的數據管理項目,如Arefolov A等為臨床實驗生物標志物數據FAIR化開發數據管理方法:RDA在生物科學、農業領域分別成立專門的BDIIG和IGAD數據研究小組,促進生物、農業領域數據共享管理,確保數據可訪問和可重用;Lannom L等將FAIR原則應用到生物科學和地球科學中,數字化處理生物/地球標本數據,實現無縫統一訪問。
1.2FAIR原則評估框架現狀
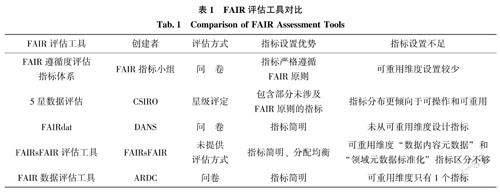
FAIR提供了通用的原則和指導,以確保數據達到最佳的發現和重用狀態。在數據建設和管理過程中,要不斷了解數據與FAIR原則的符合度,以便明確需要改進的方向。因此,建立明確、可識別、可測量且有通用性的評估指標非常關鍵。目前,國外已有研究機構開發出了FAIR指標評估體系,其中較具代表性的為:由FAIR原則的提出者等自主成立的FAIR指標小組在2018年提出的FAIR遵循度評估指標體系:澳大利亞研究數據共享組織(ARDC)提出的FAIR數據評估工具,從FAIR 4個維度進行了問題設計:荷蘭數據存檔與網絡服務(The Dutch Data Archiving and Networked Services,DANS)于2017年發布FAIRdat評估工具,從可發現性、可訪問性、可操作性3個維度設置指標;由澳大利亞聯邦科學與工業研究組織(Common-wealth Scientific and Industrial Research Organisation,CSIRO)基于數據評級系統開發的5星數據評估工具,在所有問題完成后,會給出FAIR 4個維度的星級表示:基于成熟度理論的評估工具以研究數據聯盟的FAIR數據成熟度模型(FAIR Data Ma-turity Model)為代表,并在此基礎上衍生出FAIRs-FAIR數據對象評估指標。目前,我國尚無被廣泛應用的成熟的FAIR指標評價體系。
綜上所述,國內外對于FAIR原則的解讀研究充分,在不同領域的實踐也進行積極探索。隨著FAIR原則不斷推廣,國內外期刊出版商發布論文支撐數據開放共享政策來促進數據FAIR化,期刊論文支撐數據是FAIR原則應用的重要領域,但相關研究不足,因此,為進一步掌握社科類中文學術期刊論文支撐數據的開放重用水平,本文以在實踐領域有代表性的《數據分析與知識發現》期刊為例,結合已有的代表性FAIR評估模型,針對中文期刊論文支撐數據的獨特屬性,提出了針對中文期刊論文支撐數據開放性評估的FAIR指標評價體系。
2中文期刊論文支撐數據FAIR指標評價體系的構建
FAIR由可發現(Findable)、可訪問(Accessi-ble)、可互操作(Interoperable)和可重用(Reusable)4個維度和15條具體細則構成,各細則相互獨立、相互關聯。經過預調研,發現期刊論文支撐數據集具有獨特的屬性。因此,需要根據數據集的特征,從FAIR的4個維度完善相關細則,設計新的評估指標體系。已有的代表性FAIR評估模型對于構建期刊論文支撐數據的FAIR指標評價體系有一定的借鑒作用。本文通過對FAIR遵循度評估指標體系、5星數據評估、FAIRdat、FAIRsFAIR評估指標和FAIR數據評估工具進行對比分析,綜合考慮各評估工具的優勢和指標設計特點。同時,針對《數據分析與知識發現》已公開的期刊論文支撐數據的相關特征以及自身對指標的理解,從各評估工具中選取部分指標,并對指標進行增加和調整,以確保指標的科學性和適用性,構建一個面向中文期刊論文支撐數據開放性評估的FAIR指標評價體系。
2.1FAIR原則評估框架對比
通過比較發現,除FAIRdat外,其余評估模型均從FAIR原則的4個維度設計了詳細的評價指標:各工具沒有對指標分配具體的權重,而是對FAIR原則進行了細化,主要差異是指標設計和評估方法。不同工具所提出的指標及評估方法各具特色,且有一定的互補性,如表1所示。雖然5個評估工具都提出了各自的FAIR指標評價方法,但是它們僅僅是評估模板,而不是固定標準。實施FAIR評估既要根據學科領域的發展情況、研究對象的特征,也要根據評估實施者對指標的理解來確定。為了更準確地評估期刊論文相關數據的FAIR應用情況,應根據自身對FAIR指標的理解以及數據特征,結合各評估工具的優勢和特點,綜合考慮評估方法、指標數量和分布等因素,構建一個新的評估指標體系。
2.2中文期刊論文支撐數據FAIR評價指標設計
在綜合已有的FAIR指標評估框架的優勢和特征的基礎上,本文結合前期的案例調研,針對中文學術期刊論文支撐數據的相關特征,構建了期刊論文支撐數據FAIR指標評價體系,如表2所示。該體系以FAIR原則的四大維度延展,為提高可操作性將其細化至三級,設計過程中充分考慮了指標設計的規范性、適用性等要求。結合前期對中文期刊論文支撐數據的調研狀況,對指標體系持續調整和完善,最終在可發現、可訪問、可互操作、可重用4個一級指標下設計了10個二級指標和18個三級指標的多層次、多維度指標群。其中,從實際需求出發,在二級指標“標識符”下創設了三級指標“標識符能否正常解析”條目,在一級指標“可訪問性”下創設了二級指標“訪問時限”及其延展的三級指標“訪問是否有時間限制”條目,使其在吻合FAIR原則的前提下,能夠滿足對中文學術期刊論文支撐數據的特色性評價需求。其余二級指標根據樣本數據的特征,從已有的FAIR指標框架中進行抽取。而部分三級指標是在不影響原有含義的基礎上,對指標進行微調或修改,把需要調研的內容更加貼合期刊論文支撐數據集的特征。比如將合規引用下的三級指標調整為關聯到期刊論文和關聯到相關數據集。表2列出了該評價體系對5個評估框架的借鑒情況,借鑒與否的決策主要基于對數據集調研結果和FAIR實施情況的綜合考慮。
3數據來源與存儲方式概況
3.1數據來源
從2022年3月20日起,《數據分析與知識發現》期刊要求所有被錄用論文的論文支撐數據在稿件被錄用后進行公共保存,并鼓勵在此前被錄用的作者參照《論文支撐數據公共保存與共享暫行辦法》執行。目前,該刊是社會科學領域唯一對論文支撐數據開放明確要求且有一定數據儲備的中文核心期刊,本文所研究的論文支撐數據樣本就從該刊2022-2023年發表的論文中獲取。
在本研究中,采用描述性和詳細研究的方法,人工審查每一篇論文及其相關的數據集。發現該刊從2022年至今共發表195篇論文,其中16篇(8%)沒有提供支撐數據;127篇(65%)論文將數據存儲在私人空間中,并提供了作者郵箱:53篇(27%)論文公開保存了支撐數據。本文分析的樣本即為這53篇執行了支撐數據開放共享的論文。
3.2期刊論文支撐數據的存儲方式
經調研發現,在53篇論文中,5篇論文的支撐數據為公開的專業數據集:兩個由明尼蘇達大學Grouplens小組公開的影評數據集、1個為TREC臨床決策支持跟蹤數據集、1個由斯坦福大學公開收錄的亞馬遜數據集、1個是由清華大學公開的THUCNews新聞文本數據。4篇論文直接將支撐數據附錄在論文最后。其余44篇論文將數據集存儲在不同的數據共享平臺中(有4篇論文涉及多個支撐數據集,其中3篇論文將部分數據集存儲在科學數據銀行,其余部分上傳至Github,而另1篇論文則將其中一個數據集存儲于Github,另一個數據集存儲于百度網盤中,因此,表4中的以單條支撐數據統計的論文總數將超過44篇)。如表4所示,用于存儲論文支撐數據的平臺可分為4類,分別為科學數據存儲平臺(如科學數據銀行),代碼托管平臺(如Github、Gitee),具有數據托管功能的社交網絡平臺(如CSDN),云存儲平臺(如百度網盤)。該期刊選擇的數據存儲平臺應當滿足數據長期保存、開放獲取、規范管理利益相關者權益以及系統安全運行等要求,并遵循認證的國內國際規范,得到國家教育科研權威機構或國家科研與教育管理部門認可的國內公共保存平臺,這些標準與FAIR原則的可發現性、可訪問性、可操作性和可重用性相對應,如表3所示。然而,一些科研人員沒有嚴格執行期刊要求,未將其論文支撐數據存儲在符合期刊要求的平臺中。
4期刊論文支撐數據FAIR原則應用現狀分析
4.1可發現性
數據的可發現性是影響數據發揮其價值的重要因素,數據只有被用戶發現,才有被使用、分析、組織的可能。支撐數據可發現性的兩個重要指標特征包括唯一永久性標識符和元數據豐富程度。
4.1.1標識符
為數據(元數據)分配全球唯一永久性標識符是FAIR原則的重要部分。數字對象標識符(DOI)能夠永久訪問且有利于數據集的定位。如表5所示,科學數據銀行采用了全球永久、唯一標識符標識數據集,其余平臺均沒有為數據集分配唯一永久性標識符,只提供URL,其中存儲在Github的5個數據集已無法訪問,用戶點擊URL卻無法找到數據集所在的位置。
標識符能否正常解析也影響著數據的可發現性。由表5可知,科學數據銀行中的DOI不能正常解析。通過DOI只能跳轉到平臺首頁,卻無法直接到達數據集的位置,需要在平臺檢索框內輸人數據集名稱、作者等元數據才可以找到該數據集。其余平臺的URL在不失效的前提下可以正常解析。
4.1.2元數據豐富度
從表5中可以發現,5個存儲平臺中,只有1個(科學數據銀行)自定義元數據元素且元數據較豐富,從標題、摘要、關鍵詞、作者、學科、許可、關聯出版論文等多個方面描述數據集.1個平臺(CSDN)提供的元數據元素較少,主要從作者、標題、數據內容等方面描述數據集,Gitee平臺為數據集提供數據貢獻者、數據集名稱、數據集簡介等描述性元數據,Github平臺上的數據集主要包含作者和標題兩個元數據。Github和Gitee作為代碼托管平臺,所存儲的數據集通常包含Readme說明文件,給數據集提供詳細的介紹。而百度網盤主要用于個人存儲和備份,無需提供豐富的元數據。
由此可見,科學數據銀行作為專業的科學數據存儲平臺,賦予唯一持久性標識符(DOI),科研人員也為數據集提供豐富的元數據。相比之下,Github、Gitee和CSDN都是面向廣泛的開發者、研發團隊和企業的平臺,主要用于版本控制、協作開發和代碼共享等方面。盡管這些平臺也支持數據集的存儲和共享,但其定位并不是專門的科學數據存儲平臺,缺乏標識符申請的意識和動力。此外,數據集的元數據需要經過規范化和標準化處理,而這些平臺的用戶缺乏專業的數據管理知識和經驗,因此在元數據描述方面有一定局限性。
4.2可訪問性
當用戶需要獲取數據時,他們會考慮如何訪問這些數據。為了保證數據的可訪問性,需要在遵守訪問協議的前提下,確保用戶能夠輕松地獲取(元)數據。值得注意的是,可訪問性并不意味著所有數據都必須公開,而是根據數據的性質確定公開的內容和時間。
由于存儲在期刊網絡版的科學數據、公共標準數據集和云存儲平臺(百度網盤)中的數據集可以直接訪問,沒有訪問權限設置,因此,只對科學數據銀行、Github.Gitee、CSDN 4個平臺進行分析。
4.2.1訪問協議
3類平臺均支持HTTP協議訪問和數據下載,如表6所示。HTTP是TCP/IP協議棧中的一種應用層協議,所有WWW文件都必須遵守其標準,而且各種技術信息都是公開且免費的。從這個方面來說,FAIR所要求的標準化訪問協議環境已經得到了滿足。此外,為了讓用戶更加方便地下載大數據文件,科學數據銀行還提供了FTP協議服務。
4.2.2訪問權限
訪問權限既包括平臺對用戶的審核,也包括上傳者對用戶的審核。如表7所示,CSDN未提供用戶審核機制,但需要用戶注冊賬號并申請會員才可訪問下載,對于營利性平臺,其商業模式可能會對數據訪問產生一定的影響,這可能會導致數據的訪問受到限制或者需要付費,從而影響數據的開放訪問。其余3個平臺均提供用戶注冊審核機制,其中Github平臺提供數據集的開放訪問,用戶無需注冊即可免費訪問數據集,科學數據銀行聲明用戶注冊賬號后才能使用全部服務。而Gitee平臺需要用戶注冊才能訪問、下載數據集。除平臺對用戶的審核外,上傳者可自定義獲取條件并自行決定是否授予用戶數據訪問權限。對于存儲在科學數據銀行上的數據,用戶若想下載此類數據文件須先填寫《數據訪問申請表》,作者通過該申請后,才可以訪問下載數據文件。Github和Gitee平臺具有訪問權限設置,可以幫助用戶控制代碼和倉庫的訪問權限,數據上傳者自行決定數據集是否允許其他用戶訪問。
4.2.3訪問時限
科學數據銀行為每個數據集分配了DOI標識符,旨在確保對科研數據的永久訪問。但是,存儲在科學數據銀行中的6個數據集處于保護期,在此期間,數據集無法對外公開,只有在保護期結束后,用戶才能訪問該數據集。相比之下,其他平臺和數據提交者并沒有為數據集設置這種保護期。
4.2.4元數據的保存
隨著時間的推移,數據集往往會消失或失去利用價值,即使數據不可再用,元數據也可以訪問,因此元數據應保存到可靠、穩定且專業的存儲平臺中,并且提供元數據保存聲明。目前有將近一半的數據保存在非專業的科學數據存儲平臺中,存儲在代碼托管平臺中的數據最多,因此,下文分析科研人員將數據存儲在代碼托管平臺和科學數據存儲庫中的原因及元數據保存聲明,如表8所示。
3個平臺都沒有提供(元)數據保存聲明。結合調研數據的內容及各類存儲平臺的服務特點發現,53篇論文中,有14篇論文的支撐數據含有代碼,Github和Gitee是專門的代碼托管平臺,能夠保證代碼的安全,同時可以將代碼和數據一起存儲在同一個倉庫中,并且可以與他人協作開發代碼,而科學數據銀行雖聲明可以存放代碼類型的數據,但在代碼迭代、協作開發上有一定局限性。代碼托管平臺中有豐富的項目和技術支持,可提供給開發人員(包括科研人員)更多的資源和工具。此外,將代碼或其他類型的數據存儲到該類平臺中有提升個人影響力的機會,數據點贊數/下載數越多,個人影響力越高。
4.3可操作性
可操作性指讓機器在訪問、關聯、集成不同來源的數據時,能夠更加準確、順暢地理解,從而為用戶方便獲取數據奠定基礎。此外,可操作性還強調人類和機器對數據的交互與理解,以便更好地實現數據的利用和重用。
4.3.1合規引用
數據引用旨在建立數據與數據之間以及數據與文獻之間的關聯,進而促進數據的廣泛交互。如表9所示,Github、Gitee、CSDN平臺都沒有提供明確的數據引用方式,只要求用戶在遵守相應服務條款的前提下使用或引用數據,在一定情況下,經上傳者同意后才能使用數據集。科學數據銀行支持多種數據引用標準(如GB/T 7714-2015),用戶可自行選擇,并且提供了比較完整的引用信息,包括數據貢獻者、數據集名稱、上傳時間、DOI等豐富的元數據信息。此外,公開標準數據集也提供引用方式,如明尼蘇達大學Grouplens小組聲明,在出版物中使用該數據集時,應當引用指定的論文。
在數據關聯方面,科學數據銀行以超鏈接方式將數據集關聯至相關數據,包括數據集推薦閱讀、數據參考資源,平臺還將數據關聯至外部數據,如關聯出版論文。CSDN網站上存儲的數據也具有數據集相關推薦。在Github和Gitee平臺中,部分數據集中的Readme或txt說明文件含有相關數據集的URL。其中,Github、Gitee和CSDN平臺并未將數據集關聯至期刊論文,可能的原因是這些平臺主要面向的是國內外的開發人員,而非專業的科研人員或科研組織,受眾群體不僅限于科研領域,還包括其他行業領域人員。
4.3.2格式
文件格式會影響當前和未來軟件“導人”數據集的能力,進而影響數據集的解釋和理解。論文支撐數據基本存儲于科學數據存儲庫和代碼托管平臺中,因此下文主要對科學數據銀行、Github和Gitee平臺上的數據進行分析。如表10所示,科學數據銀行有明確的數據文件格式聲明,為用戶提供了一個表格,其中包括任何文件類型的“首選格式”,即用于長期保存數據的最佳文件格式及非首選格式。數據集以純文本(txt)、數據表(CSV、xlsx)、文本文檔(pdf、docx)、圖片(jpg、png)和程序文件json等為主,txt、csv、json、xlsx文件中的數據多為用于計算分析生成論文直接結果的數據、用于結果分析的樣本數據和原始數據,其中,一些xlsx文件中含有描述性統計分析后的結果數據和參數數據,pdf文件主要內容是統計分析后的結果數據,docx主要為說明文件。此外,1個支撐數據集包括原始圖片類型數據集和經處理后的pickle文件,而pickle是Python中的序列文件,只能在Python中調用。根據數據文件格式推薦,docx并不是首選格式,pickle文件也不是開放數據格式,作者并沒有完全按照“優先推薦格式”上傳數據。
代碼托管平臺的本質是存儲代碼,而代碼文件的格式通常是標準的格式,數據文件格式多種多樣,因此,該類平臺可能為了方便用戶上傳數據,未對數據格式有具體限制,論文支撐數據主要包括數據文件(純文本(txt)、數據表(csv、xlsx)和圖片(png))、Python語言的代碼文件。其中,部分txt文件為說明文件。由此可見,不同類型的平臺,即使所存儲的數據格式相同,內容上卻有所不同。
4.4可重用性
可重用是FAIR原則的目標,為了實現這一目標,需要充分描述數據,并在重用過程中明確知識產權,確保數據的可重用性。
4.4.1許可
如果數據使用規定不夠明確,將會限制組織和個人對數據進行再利用。由表11可知,4個平臺均提供數據使用許可。科學數據銀行和Github均提供標準許可協議和自定義文本許可,Gitee和CS-DN主要為文本自定義許可,兩種使用許可各有其特點。科學數據銀行目前提供多種標準數據許可協議,包括CC(Creative Commons)通用許可協議、ODbl(Open Database License)等兩種數據庫許可協議,MIT(Massachusetts Institute of Technology)等12種軟件許可協議,27個論文支撐數據集主要使用了CC通用許可協議。這類許可協議的特點在于,其條款內容嚴謹、清晰、應用范圍廣泛,既可用于整體數據的使用說明,也可應用到每個獨立數據集上。該平臺還自定義限制性獲取許可協議,作者自定義數據獲取條件。
Github提供MIT等標準軟件許可協議,主要用于開源軟件的管理,平臺也自定義服務條款、免責聲明、個人信息保護等使用條款,聲明數據提交者可根據條款授予用戶相關內容許可。相比之下,Gitee和CSDN是提供自定義免責聲明、個人信息保護等使用條款,Gitee要求對于本站數據的任何使用請遵守數據集內容所附帶的授權協議,以確保數據的合法使用。對于公開獲取的數據集,如明尼蘇達大學Grouplens小組也是自定義數據許可條款。自定義文本許可的優點是能根據平臺、數據和數據提交者的需求制定具體內容。
值得注意的是,對于存儲在代碼托管平臺上的論文支撐數據,作者將倉庫公開后并未提供或申請使用許可,但通過瀏覽平臺上的其他數據,發現大部分開發人員會為所提交的數據聲明使用許可或申請標準許可協議,以維護數據產權。這種情況出現的原因可能有兩個方面:首先,代碼托管平臺并非專業的科學數據存儲平臺,科研人員并未充分查看平臺上的使用許可條款及內容;其次,科研人員對于軟件等其他類型的標準許可協議可能不夠清楚,而開發人員則可能會更加熟悉這些協議。
在限制聲明方面,科學數據銀行指出,數據提交者可自定義數據獲取條件并自行決定是否授予用戶數據獲取權限,存儲于科學數據銀行的5個數據集處于保護期,并說明保護期限,但未提供具體的限制原因。Github和Gitee平臺聲明限制原因(將機密數據存儲于私有倉儲庫中),平臺允許數據上傳者設置數據集為限制狀態。可見樣本平臺對數據使用限制的聲明一般是由數據提交者或平臺限定。
4.4.2數據溯源
數據溯源為數據質量的評估提供了解決思路,數據溯源信息主要來自于數據上傳者所發布的元數據。數據溯源信息一般包括數據發布和更新時間、數據提交者和聯系信息,以及數據集訪問地址、版本、元數據標準等。根據調研結果,科學數據銀行為樣本提供發布和更新日寸間、版本信息、作者和聯系信息、訪問地址,已具備了較完善的溯源信息。其余平臺或網站僅提供數據提交時間和數據上傳者及其聯系信息。此外,平臺均未聲明使用標準溯源格式。由此可見,溯源信息和標準溯源格式未得到充分應用。
5中文期刊論文支撐數據FAIR原則推廣策略
通過上述分析發現,FAIR原則在中文期刊論文支撐數據的應用仍需進一步完善,科研人員的數據共享意識及對于FAIR原則的認知度還遠遠不夠。因此,本文從宏觀和微觀兩個層面提出相應的對策與建議,旨在推進數據FAIR化,促進數據共享與重用。
5.1宏觀層面的FAIR推進策略
基于本調研結果,有65%的支撐數據存儲在個人空間。在27%的公開數據中,作者并未完全按照政策要求上傳數據,可見科研人員對FAIR認知度不夠,也不愿花時間根據FAIR原則描述數據。FAIR原則需要被推廣、認可、接受和應用。因此,從宏觀層面提出以下4點FAIR推進策略。
5.1.1宣傳推廣FAIR原則
雖然歐美國家(地區)的許多研究機構對FAIR原則進行了宣傳和應用,但迄今為止,大多數科研人員對該原則并沒有清晰的認識。一項由洛桑聯邦理工學院研究團隊于2019年進行的調查顯示,受訪的學術界人士中,有62%的人表示對于FAIR數據的期望程度不確定或不了解。應充分利用社交媒體、舉辦主題講座或研討會等多種形式進行宣傳,針對不同群體制定不同的推廣策略,如對于科研人員,重點宣傳FAIR原則理念及如何遵循該理念管理提交數據等,可以邀請研究FAIR原則的知名學者通過線上或線下的方式開展培訓課程和研討會議,科研人員要積極參與,學習如何處理、存儲、共享、規范使用數據,從而提高其在科研數據管理、發布、共享和重用方面的能力和素養。
5.1.2建立激勵機制
我國的《科學數據管理辦法》中明確提出“誰開放,誰受益”的理念,政策制定者應該建立激勵機制,鼓勵研究人員將數據存儲在符合FAIR標準的受信任的專業存儲庫中,并使用現有的符合FAIR標準的數據資源。此外,FAIR數據也應該被視為核心研究成果,將其納入職業發展評估和研究貢獻中。這將有助于提高科學數據共享的意識和重要性,進一步推動科學研究的可持續性發展。為了支持FAIR數據,提供基礎設施和服務的機構與人員也應該得到認可和獎勵。
5.1.3FAIR原則融人數據政策
目前,我國已開始高度重視科學數據管理與共享領域的政策的制定和完善,但仍缺乏國家層面對于FAIR原則開展的政策支持。我國政策制定者應根據當前數據資源的發展態勢,適當增加FAIR原則的相關內容,培養用戶將數據FAIR化的意識和素養。宏觀上,可將FAIR原則增加至《科學數據管理辦法》等國家層面的政策,將其貫穿數據政策的全流程,強制要求科學數據在提交、存儲、開放過程中保證可發現、可訪問、可操作和可重用。微觀上,期刊出版機構等利益相關者可以制定FAIR數據政策,以確保數據共享和重用,也可以根據FAIR原則的各個要素以及機構的發展規劃來制定并及時調整數據政策,以促進數據的管理、共享、標準化、可視化和溯源。
5.1.4凝聚FAIR利益相關者
FAIRsharing是一個由社區驅動的數據資源平臺,聚集了眾多的利益相關者群體。該平臺為不同的利益相關者群體制定了不同的FAIR原則實施策略。在國內尚未出現類似的平臺,相關社會組織應積極聯系利益相關者,一方面為數據消費者提供指導,幫助其發現、選擇和使用所需的資源;另一方面,幫助數據生產者使其資源易于被發現并得到廣泛使用。
5.2微觀層面的FAIR應用建議
5.2.1可發現維度的建議
1)制定標準元數據框架
根據調研結果,科學數據銀行的元數據豐富度較高,大大提升了數據被發現效率,因此與我國科技期刊合作的數據存儲平臺應繼續豐富元數據元素,如數據采集目的、數據分析處理說明、數據提交者、創建過程等,提供從數據格式等基本信息到描述信息、關聯期刊論文信息、溯源信息等元數據,促進數據發現,輔助數據使用者理解數據集的背景及數據集的創建過程。元數據元素應基于標準元數據框架并結合學科和數據集特點設計,并以RDF格式來標識元數據。對于非專業存儲平臺,雖然不以存儲數據為主,但也支持數據集的儲存和共享,平臺可以面向用戶和管理人員增設數據管理知識培訓板塊,便于用戶提交豐富的元數據。
2)確保數據標識符可正常解析
擁有DOI標識符并不能保證順利找到數據集,只有在成功解析DOI后才能夠找到數據集所在的位置。基于本調研結果,科學數據銀行存儲平臺中的DOI不能正常解析,因此,存儲論文相關數據集的平臺應確保用戶能動態解析數據標識符,從而獲取數據集的URL,減少數據集無法找到的可能。為了保證標識符的可靠性與準確性,應定期對DOI進行更新與維護。此外,即使是非專業的數據存儲平臺,也可以加強其DOI的申請意識,確保數據可永久發現。
5.2.2可訪問維度的建議
1)將數據提交于專業的存儲平臺
存儲方式影響(元)數據的長期訪問。基于調研結果,將近一半的數據存儲于非專業的平臺。建議研究人員將數據存儲于符合FAIR標準并經過認證的通用數據存儲庫或特定領域的數據存儲庫中,避免將數據上傳于非專業存儲平臺。科學數據銀行(www.scidb.cn)已進行了很好的實踐,通過國際認可并提供了優質的數據共享平臺。期刊出版商也可以采取獎懲措施,例如,對于正確上傳數據的作者,期刊可以提供額外的獎勵,優先發表或者優秀論文評比將優先考慮。這樣的做法可以激發作者上傳于專業平臺的積極性,同時也可以提高數據共享的質量和訪問效率。
2)制定元數據保存政策和實施方案
數據平臺能夠長期穩定發展的重要因素是數據長期保存政策的發布與實施,這意味著已經建立了較為完善的數據保存體系。科學數據銀行僅簡單說明數據可長期保存,并未提供(元)數據保存政策與聲明。相比之下,國外數據存儲庫更傾向于發布更為清晰明確的數據長期保存政策。因此,建議未來期刊和科學數據存儲庫均制定更明確的(元)數據保存政策和施方案,借鑒國外的數據保存政策條款,優化數據保存體系。
3)完善平臺服務功能
基于調研結果發現,用戶的學科領域、專業技能、行為習慣是影響選取數據存儲平臺的可能原因。因此,數據存儲平臺可針對不同領域的用戶進行細分,從而提高針對性的數據服務,比如科學數據銀行可為計算機領域的科研人員設置代碼協作開發功能,也可以提供相關的技術支持與指導,或增添第三方鏈接,將其關聯至代碼托管平臺,以滿足用戶協作開發代碼的需求。
5.2.3可操作維度的建議
1)規范數據生產使用行為
目前,科研人員并沒有完全按照平臺中的“優先推薦格式”上傳數據,而非專業存儲平臺只要求用戶遵守相應服務條款并在某些情況下獲得上傳者的同意來使用數據集。科研人員既是論文支撐數據的生產者,亦是數據的消費者。因此,研究人員應規范數據管理流程,明確并使用相關的數據標準和學科標準。在數據生產提交過程中,要按照相關標準提交相應數據,無論在哪個存儲平臺使用他人研究數據集,都要注意引用的規范。當涉及隱私或機密數據時,應及時與相關人員聯系,征詢許可。期刊可以優化作者投稿的數據準則,發布數據可用性聲明提高數據的透明度,使科研人員更易遵守數據管理要求。
2)使用開放數據格式
數據平臺應當采用國際認可的可靠數據文件開放格式,以支持集成異構數據集的需求。相比于專有格式數據文件,開放格式文件具有更好的用戶支持、可讀性和兼容性,能夠更好地支持機器互操作和數據集成。根據本調研結果,上傳于科學數據銀行中的數據格式并非都是開放數據格式,并且對于不同類型的平臺,即使所存儲的數據格式相同,但內容上卻有所不同。因此,平臺應繼續完善開放數據格式的設置,并加強用戶上傳數據的限制,對上傳數據格式進行驗證,以提高數據的質量和可用性,也可以考慮提供數據文件格式轉換的功能,此外,其余平臺可借鑒科學數據銀行中的數據文件預覽功能,方便用戶快速查看數據文件的格式和內容。不同類型或領域的平臺應根據自身特點提供合適的開放數據格式推薦表。
3)開發關聯技術和FAIR基礎設施
基于本研究調研結果,科學數據銀行的數據關聯能力較強。為了更好地實現科學數據的被理解和使用,我國專業的科學數據存儲平臺應加強關聯技術的開發與應用,通過使用關聯數據發布元數據來促進互操作性。為了促進數據的語義化表達和提升機器可處理能力,平臺應以開放的、機器可理解的方式發布數據,例如考慮應用RDF詞表來發布關聯數據。存儲平臺、社會組織也可以邀請技術方面專家和其他利益相關者進行指導,積極參與FAIR基礎設施的開發,如開發出符合FAIR原則的規范數據管理軟件,增強數據的可理解性。
5.2.4可重用維度的建議
1)明確數據許可聲明
若數據集的訪問和重用聲明不明確,將會限制用戶合理使用該平臺的數據集,從而阻礙數據的重用。因此,為了方便機器和用戶的理解和解釋,使用標準的、機器可讀的許可證非常重要。科學數據銀行為數據提交者提供多種類型的標準許可協議,以確保數據的合法使用和重用。基于本調研結果,數據平臺需高度重視參考標準的、機器可讀的重用許可聲明,在元數據中包含使用適當元數據元素表示的許可信息,在必要時設置保護期限并說明原因,對數據進行分級分類,明確不同數據的使用權限,并做出詳細說明,幫助用戶更好地理解數據使用的權利和義務,減少因數據權導致的數據重用糾紛。
2)采用機器可讀的溯源格式
根據調研結果顯示,數據存儲平臺的標準溯源格式和溯源信息未得到充分應用。溯源信息對于評估數據集在特定應用情境中的適用性具有重要作用。提供準確、豐富且機器可讀的溯源信息可以為科研人員或機器評估數據集提供必要的憑證和支持。科學數據存儲平臺應提供機器可讀的溯源信息,使用標準的溯源格式,進一步豐富數據集的工作流程、數據處理說明、數據生成設備等信息。非專業存儲平臺也應該完善數據溯源信息,以幫助不同類型的用戶了解各類數據集的特征,從而更好地理解和使用數據。
6結語與展望
本文在國外FAIR原則評估模型的基礎上,結合《數據分析與知識發現》期刊論文相關的科學數據特征,構建FAIR原則評估指標體系,基于該體系從4個維度分析調研結果,最后從宏觀和微觀兩個層面提出FAIR原則應用建議。本研究局限于調研樣本數量,調研結果對于反映中文社科類期刊論文支撐數據FAIR應用的總體情況有一定局限。但是本研究構建的中文期刊論文支撐數據FAIR指標評價體系及基于該調研結果提出的FAIR應用建議對我國期刊論文支撐數據的共享重用有一定借鑒意義。未來,關于FAIR原則的應用需針對FAIR實施中存在的問題提出具體措施。此外,我國期刊論文支撐數據FAIR應用需結合數據生命周期進行管理,繼續完善相關政策制度和標準體系,進一步推動數據FAIR化。
