黃河下游河道懸沙與床沙粒徑智能預測研究
2024-02-19 18:05:06董慶豪孫龍飛王遠見趙萬杰
人民黃河 2024年2期
關鍵詞:機器學習
董慶豪 孫龍飛 王遠見 趙萬杰

關鍵詞:泥沙粒徑;變量篩選;機器學習;智能預測;黃河下游河道
0引言
懸沙和床沙顆粒級配是影響泥沙運動的重要因素,黃河下游河道的淤積,不僅取決于來白中游泥沙的數量,而且受來沙顆粒級配的影響。探究黃河下游河道懸沙和床沙顆粒級配變化,有助于分析泥沙整體淤積情況,同時能夠反饋指導優化水庫運用方式,為水庫的調度提供重要依據。
目前,針對黃河下游河道懸沙和床沙顆粒級配的研究,主要集中于小浪底水庫運行前后懸沙和床沙粒徑的時空變化特征和規律。其中:孫維婷等通過各水文站多年泥沙數據.分析了黃河懸移質泥沙粒徑的時空變化特征,得到各水文站懸移質年平均中數粒徑變化趨勢不一致的結論:Hou等分析了黃河下游典型斷面2004-2015年河道床沙和懸沙年平均中數粒徑沿河道方向的變化趨勢:陳建國等統計1999年和2009年黃河下游各河段床沙中數粒徑的平均值,得出10a來黃河下游河床表面泥沙粒徑普遍增大1倍以上的結論;付春蘭等分析小浪底水庫運用前后黃河下游水沙條件的變化,結果表明自2002年調水調沙后,河床質中數粒徑逐漸粗化:薛博文等研究了不同時期黃河下游泥沙粒徑變化情況,分析了其對小浪底水庫調水調沙的響應規律。上述研究雖然很好地分析了懸沙和床沙粒徑的時空變化規律,但由于影響泥沙粒徑變化的因素較多,因此根據時空變化規律仍難以準確預測懸沙和床沙粒徑。此外,在泥沙粒徑變化預測方面,現有研究多采用理論公式進行床沙粒徑的分析,這些理論方法計算過程復雜或有特殊適用條件,具有一定局限性。
機器學習作為人工智能中的一項重要技術,可從大量數據中挖掘變量間存在的復雜映射關系,已廣泛應用于各個科學領域,且取得了良好的應用效果。其中,在水利預測方面,Aires等使用機器學習算法預測多西河流域泥沙濃度,采用變量選擇算法對變量進行篩選,取得良好的預測效果:鮑振鑫等耦合VIC模型和8種機器學習算法構建了輸沙量模擬模型,能夠較好地模擬月輸沙量過程;Han等提出一種結合輸入層和隱藏層兩種注意力機制的LSTM模型AT-LSTM,用于宜昌站和屏山站的長期徑流預測;Yang等提出了基于小樣本學習的LSTM-原型網絡融合模型預測長期徑流,并在兩個數據稀缺地區驗證了模型的有效性。目前,機器學習算法在預測泥沙濃度、輸沙量、徑流量等方面應用較多,但尚缺乏針對懸沙和床沙粒徑預測的相關研究。
筆者利用黃河下游河道花園口等6個斷面的水沙系列數據,進行懸沙和床沙粒徑主要影響因子的篩選,并基于機器學習算法構建黃河下游不同斷面的懸沙和床沙粒徑的預測模型,以期為實現泥沙粒徑的準確預測提供新的思路。
1研究區域及數據來源
黃河下游以桃花峪為起點至人海口,河長786km,流域面積占黃河流域總面積的3%.河道坡降小,水流平緩,泥沙淤積嚴重,河床升高形成地上“懸河”。本文選取下游花園口、夾河灘、高村、孫口、濼口、利津6個斷面(水文站),開展不同斷面泥沙粒徑預測研究。收集整理2006-2020年黃河小浪底水庫月均出庫流量、出庫含沙量數據,下游花園口等6個水文站月均流量、含沙量、流速、河寬、水深、比降、水位以及懸沙和床沙中數粒徑、平均粒徑等數據,數據均來源于黃河水利委員會編制的《黃河流域水文資料》。
2研究方法
首先選取泥沙粒徑主要影響因子,并通過變量篩選算法確定機器學習模型輸入的變量組合:然后基于不同機器學習算法建立預測模型:最后對模型預測結果進行分析評估。
2.1主要變量篩選
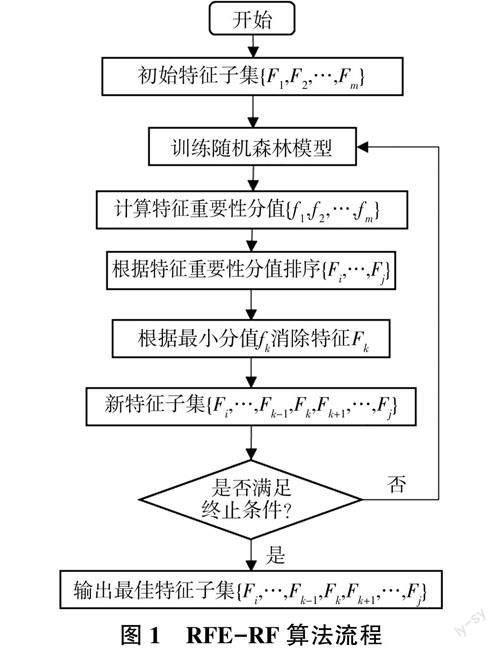
黃河下游河道懸沙和床沙粒徑變化主要受來水來沙條件(流量、流速、含沙量)、河道邊界條件(河寬、水深、比降)等多種因素的影響。為有效提取機器學習模型最佳輸入變量組合,采用遞歸特征消除算法結合隨機森林(RFE-RF)算法進行變量篩選,消除冗余變量,確定變量組合。RFE-RF算法把需要的特征集合初始化為數據集,采用R軟件Caret包中的varlmp函數計算影響因子的重要性分值并進行排序,每次剔除一個重要性分值最低的特征,直到所有特征都被剔除,并通過模型對不同個數特征的子集進行評估,輸出最佳特征子集。RFE-RF算法流程如圖1所示。
2.2算法原理
本文采用K最鄰近(KNN)、隨機森林(RF)、支持向量回歸(SVR)3種機器學習算法建立預測模型,各算法的原理如下。
1)KNN算法的核心思想是數據庫模式匹配,即從歷史數據庫中提取數據特征,根據合理的狀態向量找到與當前實時觀測數據相匹配的k個近鄰數據,將其作為輸入變量以預測后續狀態數據值。
2)RF算法是一種通過集成學習思想將多棵樹集成的算法,其基本單元是決策樹,并利用多棵決策樹對樣本進行訓練及預測。
3)SVR算法是運用支持向量機(SVM)解決回歸問題的算法。與傳統的回歸算法不同,SVR不僅考慮了數據的擬合程度,而且考慮了模型的泛化能力,能夠有效地處理高維數據和非線性數據。SVR算法的基本思想是將數據映射到高維空間中,通過尋找最優的超平面來實現回歸。
2.3模型構建
綜合考慮水沙、河道邊界等條件,懸沙和床沙粒徑的主要影響因子包括小浪底水庫出庫流量、出庫含沙量,以及下游6個水文站的流量、含沙量、平均流速、最大流速、河寬、平均水深、最大水深、河床比降、水面比降和水位等共12個變量。
各斷面不同粒徑預測模型建立的主要步驟如下:1)選擇2006-2019年月均數據集進行變量篩選,使用篩選后的影響因子作為模型輸入變量,其中懸沙粒徑影響因子選取當月月均數據:床沙粒徑影響因子篩選考慮滯后性,通過相關性分析,確定其滯后時間,并采用滑動平均法計算各影響因子的月均數據。2)將2006-2019年月均數據集按照4:1的比例劃分成訓練集和測試集。3)將訓練集代人3種不同機器學習算法分別進行訓練并建立預測模型。4)將測試集代入模型中,通過決定系數R2、均方根誤差RMSE、平均絕對誤差MAE指標評估不同算法模型的預測效果,并選出各斷面預測效果最好的模型。5)將2020年數據集分別代入選出的各斷面最優模型,通過R2值和顯著性檢驗進一步驗證所建模型的性能。
3實例結果分析
3.1泥沙粒徑關鍵影響因子提取
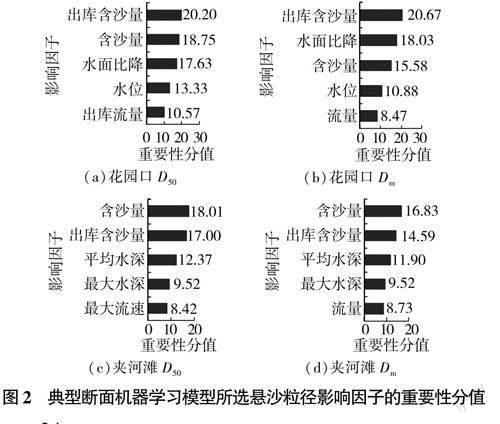
采用變量篩選方法,得到各斷面懸沙和床沙粒徑重要性分值排序前5的影響因子,以花園口、夾河灘斷面為例,其結果分別如圖2和圖3所示(D5o表示中數粒徑,D表示平均粒徑)。
各斷面經篩選后變量的數量為6~9個,有效減少了初始變量的數量,有利于提取主要影響因子。由圖2和圖3可見,對于黃河下游懸沙粒徑預測,大部分斷面的來沙條件因素重要性分值較高,對粒徑變化的影響較大,且不同斷面及同一斷面不同粒徑所選取的影響因子之間存在差異;而對于黃河下游床沙粒徑預測,同一斷面不同粒徑重要性分值排序前5的影響因子基本相同,但不同斷面之間影響因子重要性分值差異較為顯著。
3.2預測結果分析
3.2.1懸沙粒徑預測結果
根據各斷面不同粒徑影響因子的篩選結果,采用篩選后的變量作為模型的輸入變量構建預測模型,最終所得不同機器學習算法模型在測試集上的評估指標,見表1。
由表1可知,對于下游河道懸沙粒徑,機器學習模型在各斷面測試集預測方面的整體適用性較好,預測值誤差較小。不同機器學習算法預測結果的誤差存在差異,其中KNN模型的RMSE均在0.0095mm以下、MAE均在0.0079mm以下,RF模型的RMSE均在0.0085mm以下、MAE均在0.0068mm以下,SVR模型的RMSE均在0.0115mm以下、MAE均在0.0086mm以下。相比之下,RF算法建立的模型在懸沙粒徑預測方面對于各斷面預測結果的誤差均較小,各斷面優選模型均為RF算法建立的模型。
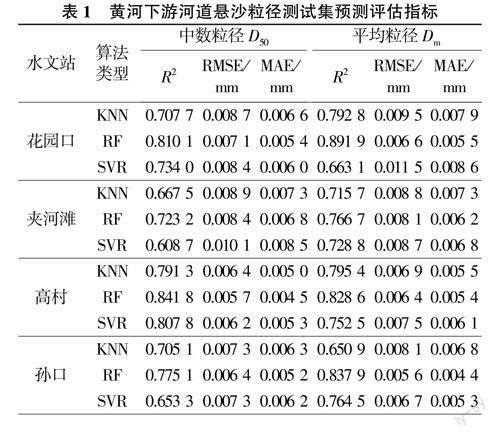
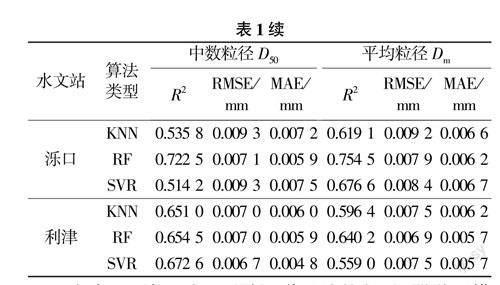
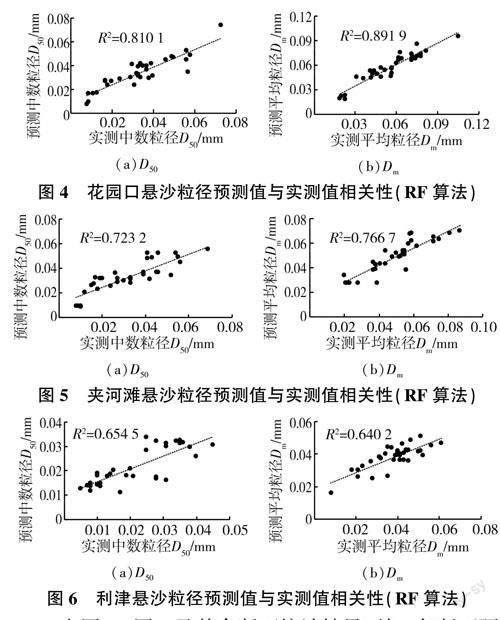
此外,統計由表1選出的各斷面在測試集上綜合效果最好的模型,得到預測值與實測值之間的相關性,以花園口、夾河灘、利津斷面為例,其懸沙粒徑預測值與實測值之間相關性如圖4~圖6所示。
由圖4~圖6及其余斷面統計結果可知,各斷面預測值與實測值R2均在0.64~0.89之間,相關性良好,模型擬合程度較高。
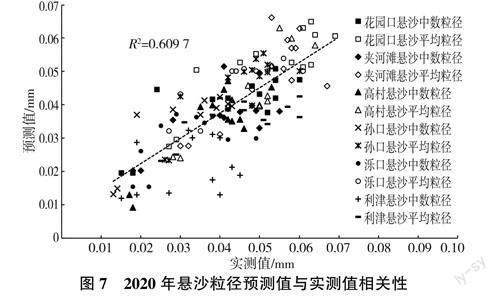
為進一步驗證所建立模型的效果,選取各斷面優選模型分別對2020年懸沙月均粒徑進行預測,各斷面2020年懸沙粒徑實測值與預測值綜合相關性如圖7所示。由圖7可見,所得實測值與預測值之間R2達0.6097,進一步表明模型對于懸沙粒徑具有良好的預測準確性。
3.2.2床沙粒徑預測結果
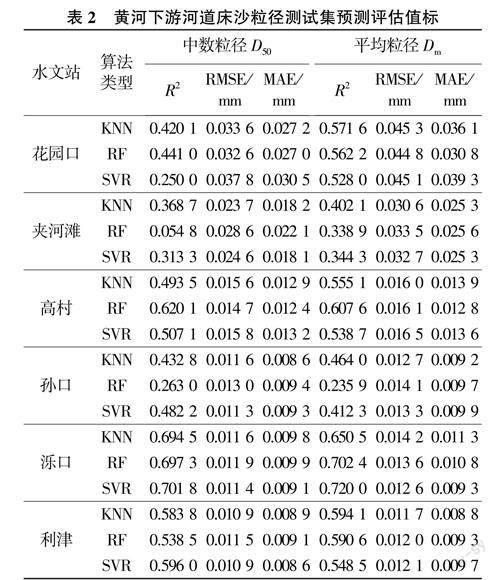
與懸沙粒徑類似,對于床沙不同機器學習算法模型在測試集上的評估指標見表2。
由表2可知,對于下游河道床沙粒徑,機器學習模型在不同斷面測試集上的預測誤差存在較大差異,考慮其與床沙粒徑空間分布不均有關,但整體上各斷面優選模型的RMSE最高為0.0448mm、最低為0.0109mm,MAE最高為0.0308mm、最低為0.0086mm,3種機器學習算法在不同斷面床沙預測中具有較好的適用性。
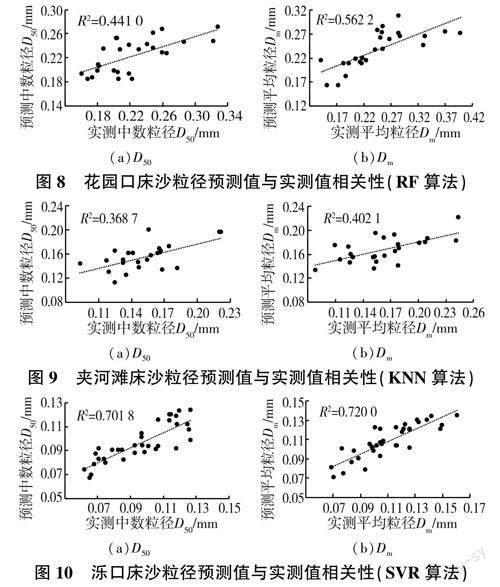
統計由表2選出的各斷面在測試集上綜合效果最好的模型,得到預測值與實測值之間的相關性,花園口、夾河灘、濼口斷面床沙粒徑預測值與實測值之間相關性如圖8~圖10所示。
由圖8~圖10及其余斷面統計結果可知,各斷面預測值與實測值R2均在0.37~0.72之間,不同斷面之間存在顯著差異。花園口斷面中數粒徑,夾河灘斷面、孫口斷面粒徑R2在0.5以下,其余斷面粒徑R2在0.5以上,而濼口斷面粒徑R2達0.7,表明模型預測值與實測值的相關性及擬合效果整體上較好。
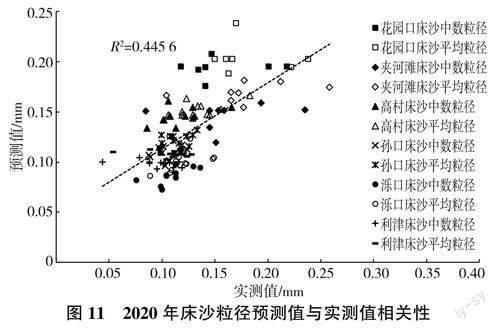
進一步驗證所建立模型的效果,由各斷面的優選模型分別對2020年床沙月均粒徑進行預測,各斷面2020年床沙粒徑實測值與預測值綜合相關性如圖11所示。
由圖11可見,預測值與實測值之間R2達0.4456,預測結果偏小,其原因可能是床沙組成的調整是一個緩慢過程,是下泄水沙過程與床面邊界之間長期相互作用的結果,影響因素和涉及信息遠較懸沙的復雜。盡管從結果上看床沙粒徑預測精度較懸沙的差,但整體上預測值與實測值仍較為接近,結果可以接受。
4結論
為系統掌握黃河下游河道懸沙和床沙粒徑的分布規律,克服泥沙粒徑預測理論方法復雜或有特殊適用條件的局限性問題,本文綜合考慮不同影響因素,采用變量篩選算法進行變量篩選,并基于機器學習算法進行泥沙粒徑預測。實例分析結果表明,變量篩選算法能夠減少冗余及不相關變量,構建最優特征子集。優選模型對懸沙粒徑預測效果良好,在測試集上各斷面預測值與實測值R2在0.64~0.89之間:床沙粒徑預測精度較懸沙相對偏低,在測試集上各斷面預測值與實測值R2在0.37~0.72之間。進一步驗證優選模型效果,在對2020年月均泥沙粒徑進行預測時,懸沙粒徑R2可達0.6097,模型擬合相對較好;床沙粒徑R2為0.4456,總體上結果可以接受。
整體而言,應用機器學習算法構建預測模型能夠較好實現黃河下游河道泥沙粒徑的準確預測,可以為黃河調水調沙提供參考。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
