基于可遷移注意力和動態卷積的滾動軸承跨工況故障診斷方法
2024-02-20 06:38:12王煜偉朱靜史曜煒鄧艾東
軸承 2024年2期
王煜偉,朱靜,史曜煒,鄧艾東
(1.國家能源集團 諫壁發電廠,江蘇 鎮江 212006;2.河南科技大學 車輛與交通工程學院,河南 洛陽 471000;3.東南大學 能源與環境學院,南京 210000)
旋轉機械在現代工業中扮演著重要的角色,其健康狀態對設備的穩定運行具有十分重要的影響[1]。建立可靠的故障診斷方法對于早期預警和預測維修,保障機組安全運行,提高機組運行效率,避免事故發生具有重要的現實意義[2]。近些年涌現出的智能故障診斷方法中,以深度學習為代表的基于數據驅動的方法由于具有優化簡單,對專家經驗依賴少等優點被廣泛關注。常見的有卷積神經網絡(CNN)[3]、長短期記憶網絡[4]和自編碼網絡[5]等。基于傳統深度學習的診斷方法總是依賴于訓練數據和測試數據服從相同分布的假設,即使數據是相似的,在一個領域數據(源域)上訓練的模型也無法很好地應用在其他領域數據(目標域),如滾動軸承不同運行工況(轉速、載荷)下的振動數據。
領域自適應(Domain Adaptation,DA)是遷移學習的分支,其利用有監督的源域數據和無監督的目標域數據學習具有領域不變性的特征,使得在源域建立的診斷模型可以有效應用于目標域的故障識別[6?9]。文獻[7]利用Wasserstein 距離構造了深度對抗DA 網絡,將源域學習到的故障知識遷移到目標域進行診斷;文獻[8]提出了多源域分解網絡,從多個源域中學習更豐富的診斷知識,同時考慮了每個領域的私有特征對知識遷移的影響。
為降低領域之間的分布差異,現有方法開發了多種特征對齊策略,但其對特征學習過程的關注不夠,尤其是忽略了不同領域特征的尺度特性差異,學到的特征雖然具有較好的可遷移性,但攜帶的故障信息卻不全面,從而限制了模型性能的提升及其適用性。滾動軸承的振動信號通常表現出多尺度特性且在多個時間尺度上包含復雜的模式[10],為此一些研究者提出了多尺度學習框架[11?12],利用多個尺度并行提取特征并加以融合以獲取豐富的故障信息,如文獻[11]通過設置不同尺度的卷積核建立了并行的多尺度特征提取分支,試圖學習振動信號中故障特征多樣的表征模式。此外,還有一些研究從動態特征提取的層面展開[13?14],通過構造動態卷積網絡并根據不同的輸入數據自適應地改變網絡參數以實現差異化的特征學習方式。然而,由于軸承的運行工況多變,跨工況下的故障特征尺度的特性差異不僅存在于每個領域內,領域之間的差異同樣存在且更為復雜。
綜上,本文提出基于可遷移注意力的領域自適應網絡(Transferable Attention Based Domain Adap?tation Network,TADAN),用于滾動軸承的跨工況故障診斷,通過學習包含豐富故障信息的領域不變特征,在無監督目標域實現高性能的故障診斷。
1 理論分析
1.1 領域自適應
本文的研究目的是從有監督的源域和無監督的目標域中學習具有領域不變性和故障類別判別性的特征表示,從而識別目標數據的故障類型。
設DS=為有nS個樣本?標簽對的有監督源域,DT={DT,train,DT,test}為目標域。分別為用于訓練的無監督目標數據和用于測試的有監督目標數據。YS,PS分別為源域的標簽空間和數據分布;YT,PT分別為目標域的標簽空間和數據分布;它們具有相同的標簽空間但數據分布不同,即YS=YT,PS≠PT。則本文的目的是從DS和DT,train中學習一個共享的函數映射,使其能夠在DT,test上實現高性能的診斷。
1.2 領域對抗訓練
領域對抗訓練被廣泛地應用在遷移學習中,用于消除不同領域數據間的分布差異[15],其核心思想是在訓練分類器C 識別來自源域特征對應故障類別的同時,構造一個領域判別器D 和特征提取器G 進行最小化?最大化對抗訓練[16],使G 可以從源域和目標域中提取領域不變的特征表示f。
令θG,θC和θD分別為子網絡G,C,D 的參數,則對抗訓練的優化目標為
式中:Lc,Ld分別為分類損失和領域判別損失;λ為折中系數,用于平衡2 個損失,λ>0;yi,di分別為樣本xi的類別標簽和領域標簽。
基于(1)式,網絡的參數可優化為
1.3 動態卷積
傳統的靜態網絡對所有輸入數據采用相同的網絡結構和參數,面對多樣化的輸入時,其特征學習能力會受到削弱。動態卷積[17]在每次執行卷積的過程中,隨機生成的卷積核不再單一,而是M個子卷積核的加權累加,因此可以根據不同的輸入數據自適應地調整卷積核,針對性地提取有效特征,從而強化網絡學習能力。動態卷積的結構如圖1所示,子卷積核(convm)享有相同的尺寸和輸入輸出維度,其權重系數(πm)由輸入數據動態決定,權重系數的生成采用squeeze?and?excitation方法。
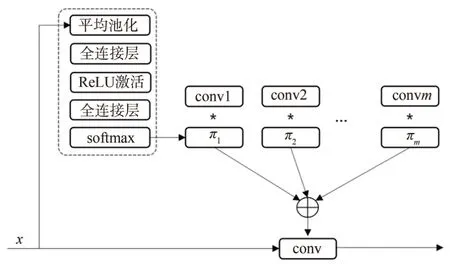
圖1 動態卷積結構示意圖Fig.1 Structure diagram of dynamic convolution
2 TADAN故障診斷方法
2.1 網絡架構
基于可遷移注意力的領域自適應網絡的架構如圖2 所示,由包含K個尺度分支的特征提取器G ={Gk}K k=1,可遷移性計算模塊,領域判別器D 和分類器C 構成。每個特征提取分支由多個卷積層構成,可通過設置不同的卷積核感受野實現不同尺度特征的提取。為降低模型復雜度并減少訓練參數,只在最后一個卷積層采用動態卷積。具體的數據流動為:來自源域和目標域的原始振動信號被送入網絡,經多個尺度特征提取分支獲得不同尺度的特征表示;可遷移計算模塊對這些特征的可遷移性進行評估并分配權重,加權后的多尺度特征被進一步融合去冗,從而獲得高等級的抽象特征表示fh;一方面,來自源域和目標域的fh被送入D進行對抗訓練,促使其領域不變;另一方面,來自源域的fh被送入C 并映射到故障類別,學習判別性的診斷信息。當網絡訓練完備后,特征提取器最終獲取的特征表示fh應當是攜帶大量故障識別信息且對分布差異不敏感,可以應用于無監督目標域的診斷任務。
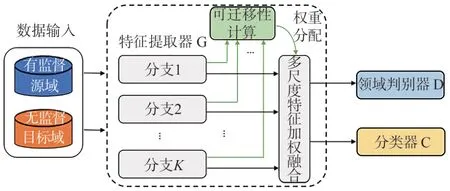
圖2 TADAN網絡架構Fig.2 Architecture of TADAN
2.2 可遷移計算模塊
可遷移計算模塊的作用是計算不同尺度特征在2個領域之間的可遷移性,從而給予可遷移性高的尺度特征以更高的關注度,促進知識的有效遷移。可遷移計算模塊中包含K個尺度領域判別器,分別對應K個特征提取分支。判別器的輸出為該尺度特征屬于源域或目標域的概率,應用熵函數H(p) =?∑pilogpi即可量化特征的可遷移性。特征越不容易被判別來源,越容易被混淆,則表示該特征越適合遷移。可遷移計算模塊最終輸出不同尺度特征的權重集合,可表示為
2.3 網絡訓練
式中:ε為學習率。
2.4 故障診斷流程
具體的模型訓練與診斷流程如下:
1)獲取數據。以工況A 下的有監督數據作為源域,其他工況(如工況B)下的無監督數據作為目標域。
2)將源域與目標域數據同時輸入TADAN 網絡中,經過特征提取器G 得到分別屬于源域和目標域的多個尺度特征。
3)將源域和目標域的同尺度特征分別送入可遷移計算模塊,計算不同尺度特征的可遷移性以獲取尺度權重= 1。
4)利用尺度權重對多尺度特征進行加權融合,獲取高等級的抽象特征表示fh。
5)將特征表示fh送入領域判別器和分類器計算領域判別損失和分類損失。
6)將得到損失之和進行反向傳播,并更新模型參數。
7)重復上述步驟,直至損失值趨于穩定,訓練收斂,模型訓練結束。
8)將工況B 下的數據輸入訓練完成的診斷模型,輸出變工況下的故障類型識別結果。
3 試驗分析
3.1 數據集介紹
本文使用2 個公開的軸承數據集構造試驗以驗證所提方法的有效性。
3.1.1 帕德伯恩大學滾動軸承數據集
帕德伯恩大學(Paderborn University,PB)滾動軸承公開數據集[18]的試驗軸承為6203型深溝球軸承,內、外徑分別為24.0 ,33.1 mm,鋼球數量為8,球徑為6.75 mm。試驗數據包含6 種軸承狀態,分別是正常狀態N,3 種不同損傷程度的內圈故障(IR1,IR2,IR3)以及2種不同損傷程度的外圈故障(OR1,OR2),其類別標簽依次被標記為0~5。軸承故障的具體描述見表1,損傷程度根據損傷表面在滾動方向上的長度進行分類,損傷等級1,2,3代表的損傷長度分別為0~2,2.0~4.5,4.5~13.5 mm。故障軸承振動信號的時域波形如圖3所示,除幅值略有區別外,很難通過肉眼分辨不同故障。
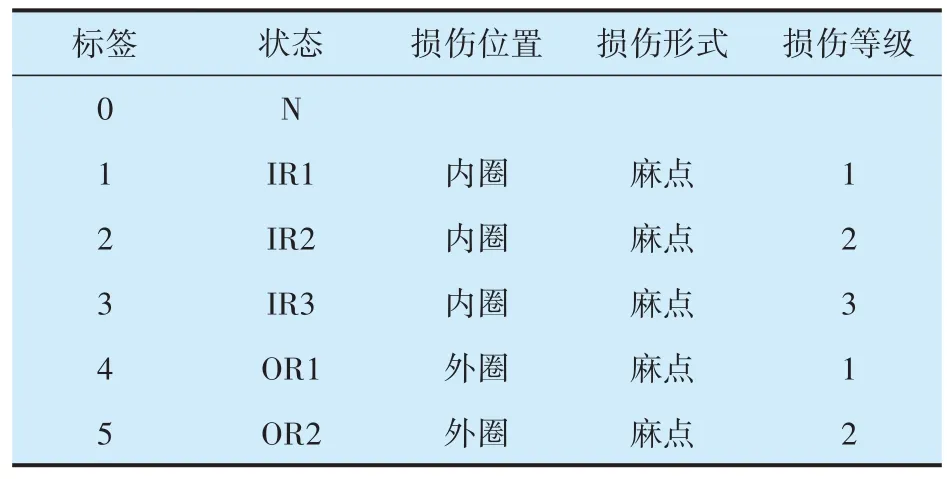
表1 PB數據集軸承故障描述Tab.1 Description of bearing faults in PB dataset
圖3 PB數據集中故障軸承振動信號時域波形Fig.3 Time domain waveform of faulty bearing vibration signals in PB dataset
振動數據收集自4 種運行工況,采樣頻率為64 kHz。根據工況將數據分割為4 個獨立域A,B,C,D,每個域的細節信息見表2。在原始振動信號上執行滑動窗分割以獲取數據樣本,每個樣本包含2400個數據點。以某一個領域為源域,剩余3個領域為目標域,共建立了12 個跨域診斷任務(表3)。對于每個診斷任務,所有源域樣本(有監督)和70%的目標域樣本(無監督)用于訓練,剩下的30%目標域樣本(有監督)用于測試。

表2 PB數據集領域信息Tab.2 Domain information in PB dataset
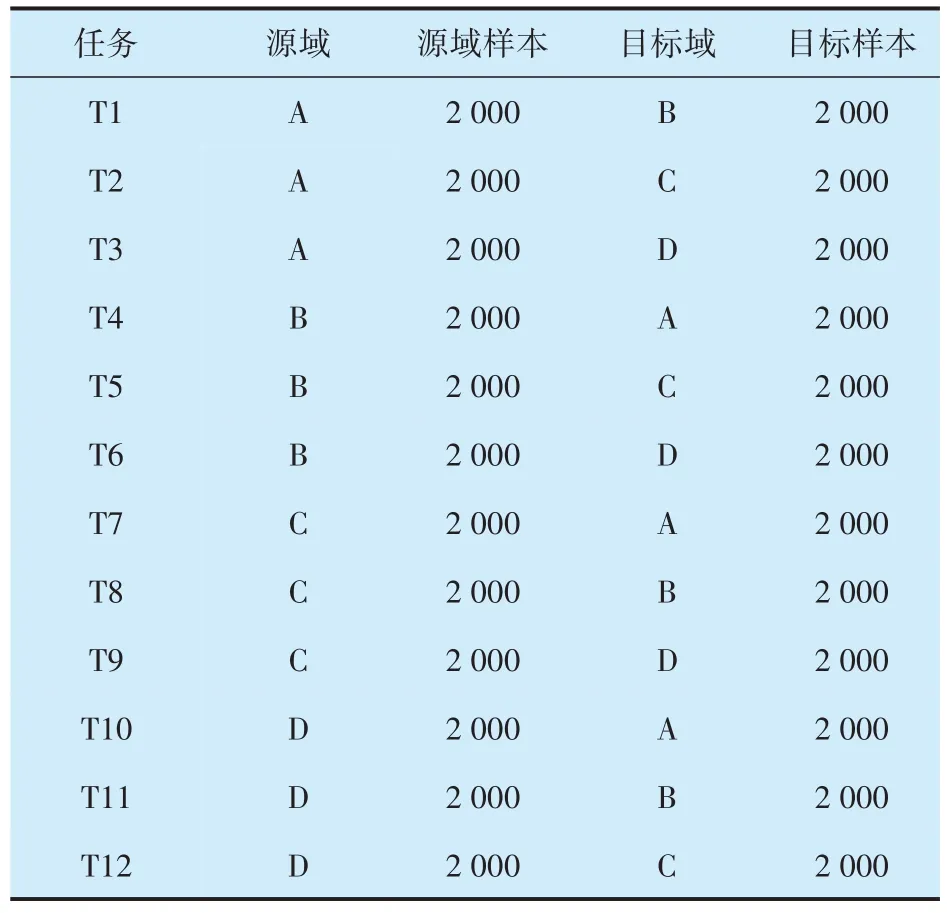
表3 PB數據集診斷任務Tab.3 Diagnostic tasks in PB dataset
3.1.2 江南大學軸承數據集
江南大學軸承數據集[19]的軸承狀態包括正常(N)、外圈損傷(OR)、內圈損傷(IR)和滾子損傷(RE)。損傷軸承通過線切割得到,內、外圈損傷尺寸(寬×深)均為0.30 mm×0.25 mm,滾子損傷尺寸為0.50 mm×0.15 mm。內圈損傷軸承型號為NU205,其他狀態軸承的型號為N205,N205 和NU205 型軸承的內徑均為25 mm,外徑均為52 mm,滾子直徑均為7 mm,滾子數分別為10,11。
振動數據收集自600,800,1000 r/min 工況,采樣頻率為50 kHz。領域分割和數據集劃分方式與PB數據集相同,分為E,F,G三個域,共建立6個跨域診斷任務,見表4。
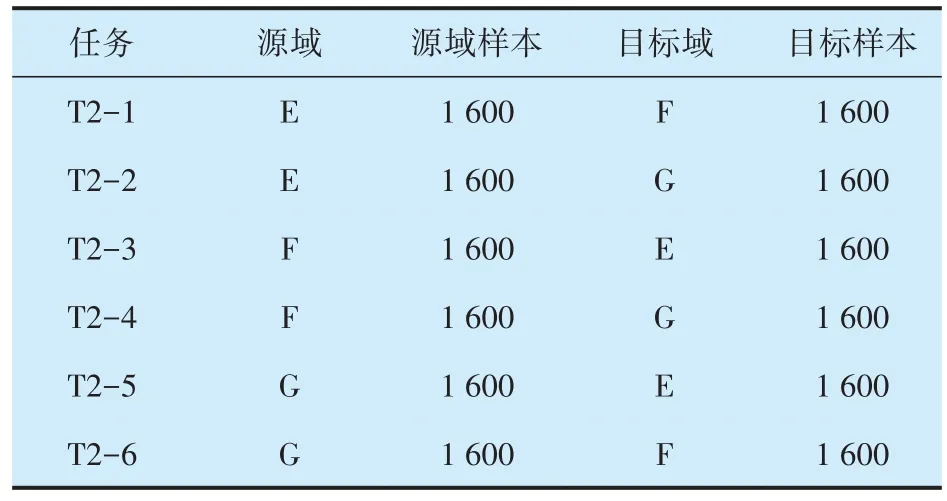
表4 江南大學數據集診斷任務Tab.4 Diagnostic tasks in Jiangnan University dataset
3.2 試驗設置
TADAN 的網絡結構見表5,尺度分支K設置為3,卷積?池化的參數為(卷積核數量,卷積核尺寸)?(池化尺寸,池化步長),動態卷積均應用在特征提取分支的最后一個卷積層,其子卷積核數M設置為4。此外,可遷移計算模塊中的K個尺度領域判別器與網絡最后的領域判別器結構相同。
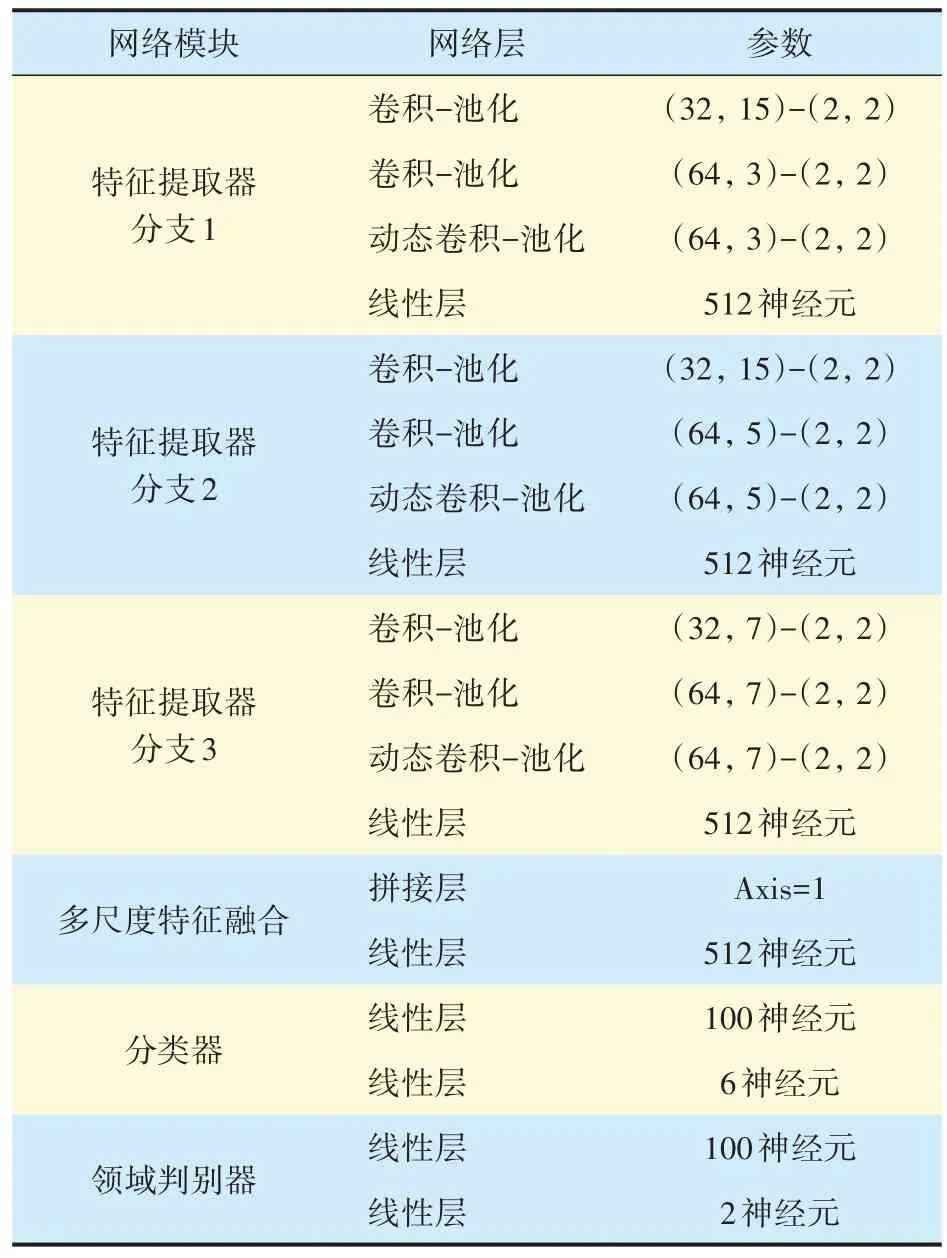
表5 TADAN的網絡拓撲與參數Tab.5 Topology and parameters of TADAN
網絡訓練過程中,使用Kaiming 初始化方法初始化網絡參數,折中參數λ設置為0.1;采用隨機梯度下降優化器,動量為0.9,學習率衰減為5×10?4;初始學習率為0.01;總訓練次數為120次。每次試驗重復5次后記錄其平均值。
3.3 對比方法
為驗證所提方法的有效性和優越性,構建多個不同的模型用于對比分析:
1) SCNN。標準的單尺度卷積神經網絡模型,其特征提取器采用TADAN 中的特征提取分支3。SCNN 不涉及領域自適應(移除了領域判別器和可遷移計算模塊),僅采用傳統的有監督學習方式,即訓練樣本中不包含無監督的目標域數據。此外,SCNN特征提取器不采用動態卷積。
2) MCNN。多尺度卷積神經網絡模型,與TADAN 具有相同的網絡結構(未使用動態卷積),訓練方式與SCNN相同,為傳統的有監督訓練。
3) DAN。與MCNN 相比,DAN 方法增加了領域判別器,遵循標準的對抗訓練方式。
4) TA?DC。TADAN不采用動態卷積的版本。
3.4 結果分析
2個試驗案例的測試結果見表6,以PB數據集為例進行說明:
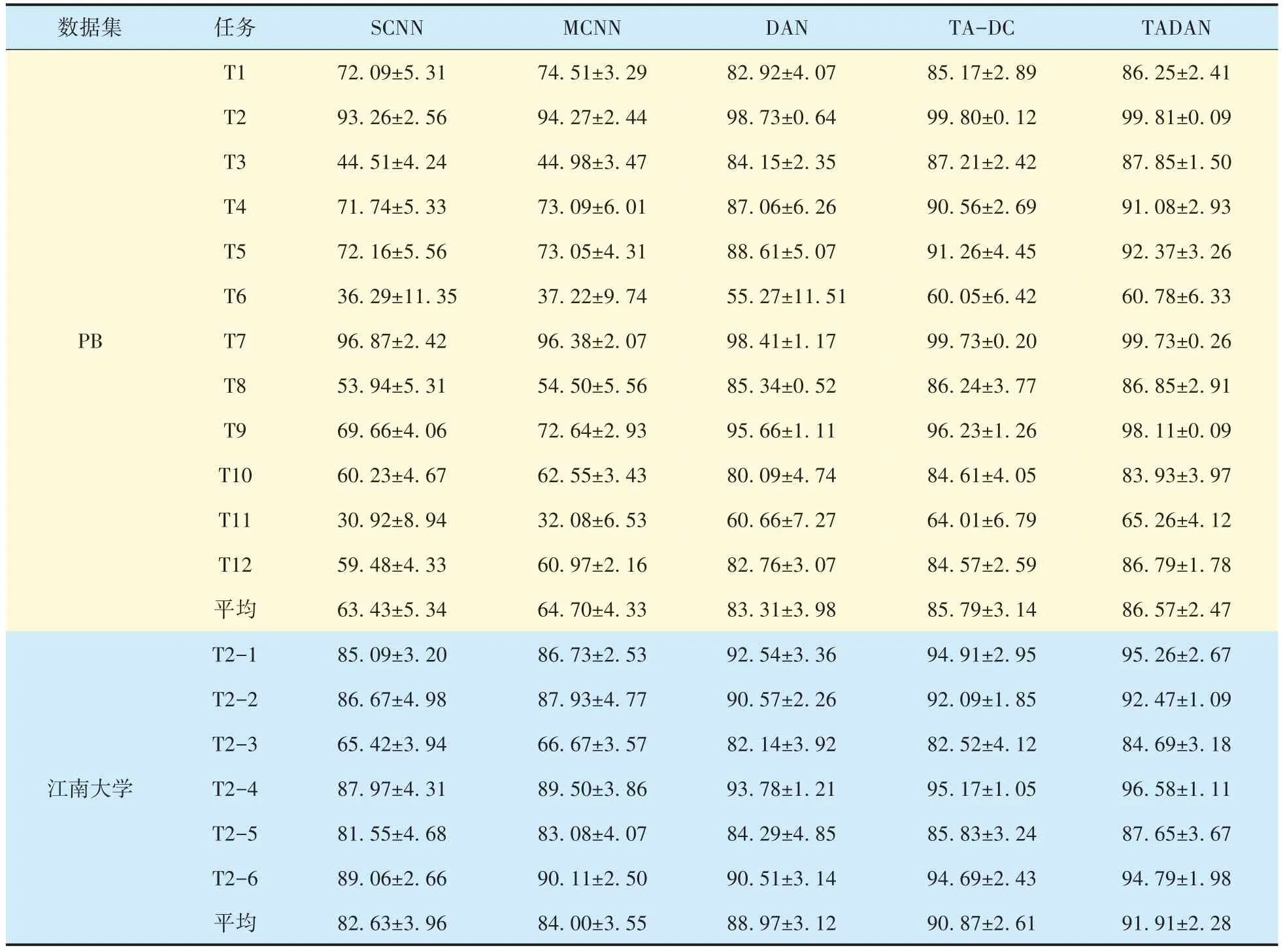
表6 各模型對不同軸承數據集的測試準確率Tab.6 Test accuracy of each model for different bearing datasets%
1)SCNN 的診斷性能在所有對比方法中最差,平均準確率只有63.43%;MSCNN的診斷準確率在SCNN 的基礎上提高了4.61%,證明了多尺度學習策略能夠通過學習更豐富的故障特征提高模型診斷性能,但SCNN 和MSCNN 的準確率均低于70%,遠不能滿足高性能的診斷需求,這也是訓練數據與測試數據之間的分布差異所導致的結果,在源域上訓練的模型很難泛化到目標域的診斷任務中。
2)DAN方法對12個診斷任務的平均準確率達到了83.31%,比MCNN 高15.27%,而且在多個跨域診斷任務上的準確率超過95%,表明領域自適應策略對于處理存在分布差異的診斷問題十分有效。
3)在DAN 的基礎上,TA?DC 和TADAN 又將平均準確率分別提高了2.48%和3.26%,在任務T2 和T7 上的測試準確率甚至超過99.5%,說明可遷移注意力策略和動態卷積的應用對促進模型遷移,提高跨域診斷性能積極且有益。
4)TADAN 幾乎在所有診斷任務上均獲得了最好的診斷性能,在PB 數據集和江南大學數據集中的平均診斷準確率分別為86.57%和91.91%,具有較好的穩定性。
為深入探究樣本誤分類和所提方法有效的原因,將所有模型在任務T9 上的一次測試結果以混淆矩陣的形式展現,結果如圖4 所示:SCNN 和MCNN 診斷準確率低的原因主要是無法準確識別IR2(標簽2)和OR2(標簽5),總將OR2 誤分類為OR1;相比之下,TADAN 對各類別樣本的識別準確率有大幅提升,除將少數OR2誤分類為OR1之外,在其他類型故障的分類上幾乎達到了100%的準確率,再一次證明了TADAN 優秀的故障特征學習能力和知識遷移能力。
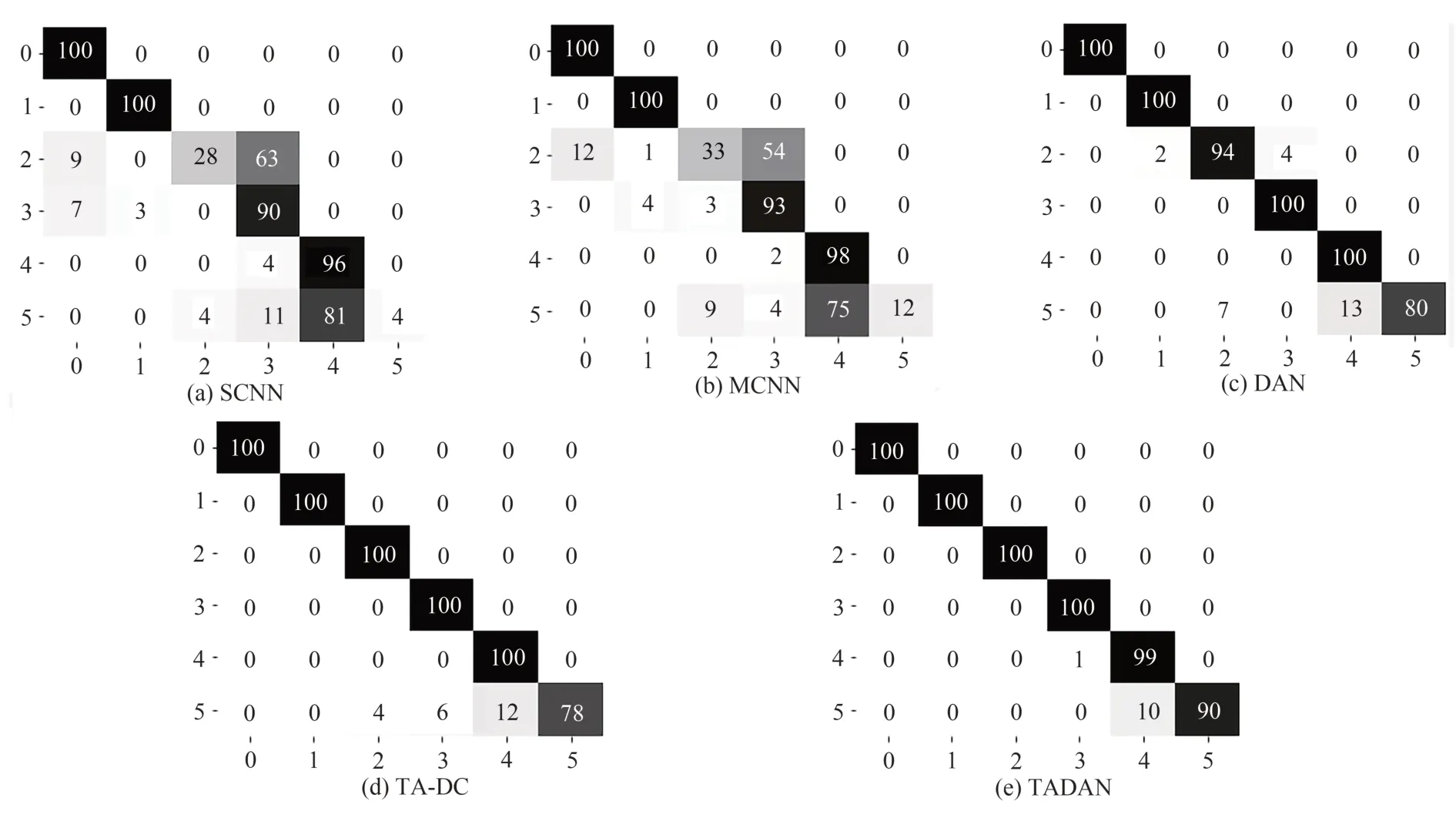
圖4 不同方法在任務T9上測試結果的混淆矩陣Fig.4 Confusion matrices of results tested by different methods on task T9
4 結論
為強化跨工況故障診斷模型的特征學習能力和領域適應能力,本文提出了一種基于可遷移注意力和動態卷積的旋轉機械故障診斷方法TADAN,通過試驗對比可得出以下結論:
1)基于動態卷積的多尺度特征提取器可以提取更豐富的特征并提高模型的自適應能力,使模型在面對不同數據集任務時更具魯棒性。
2)可遷移計算模塊可進一步量化多尺度特征的可遷移性并在特征制度層面強化其整體差異化,促進領域不變特征的學習,降低負遷移風險。
3)TADAN 在2個跨域診斷任務案例上的平均測試準確率分別達到了86.57%和91.91%,高出傳統有監督學習方法23.14%和9.28%,高出標準領域自適應方法3.26%和2.94%,具有較好的穩定性,適用于滾動軸承跨域診斷任務并具有較好的應用前景。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
