改進(jìn)YOLOv5的影響駕乘舒適性目標(biāo)檢測(cè)
2024-02-21 06:00:32李澍祺劉堂友
軟件導(dǎo)刊 2024年1期
李澍祺,劉堂友
(東華大學(xué) 信息科學(xué)與技術(shù)學(xué)院,上海 201620)
0 引言
目前,自動(dòng)駕駛領(lǐng)域目標(biāo)檢測(cè)算法的主要檢測(cè)對(duì)象為行人、機(jī)動(dòng)車、非機(jī)動(dòng)車等,汽車在檢測(cè)到潛在的碰撞可能性后通過前向碰撞預(yù)警系統(tǒng)(Forward Collision Warning,F(xiàn)CW)、行人碰撞預(yù)警系統(tǒng)(Pedestrian Collision Warning,PCW)等發(fā)出預(yù)警以告知駕駛員前方出現(xiàn)影響行車安全的目標(biāo)需要避讓,或者通過自動(dòng)緊急剎(Autonomous Emergency Braking,AEB)等功能緊急制動(dòng)以避免碰撞發(fā)生。此外,對(duì)車道線的檢測(cè)可以通過車道保持系統(tǒng)(Lane Keeping Assist Systems,LKAS)使車輛不偏離行駛車道,對(duì)交通標(biāo)志、信號(hào)燈等目標(biāo)的檢測(cè)同樣是為了駕駛安全性。總而言之,目標(biāo)檢測(cè)在自動(dòng)駕駛領(lǐng)域的應(yīng)用主要是為了保證駕乘安全性。隨著自動(dòng)駕駛技術(shù)的逐漸成熟,舒適性成為這項(xiàng)技術(shù)中不可忽視的一個(gè)重要因素,而當(dāng)前對(duì)于行駛過程中影響駕乘舒適性的目標(biāo)檢測(cè)研究尚較少。自動(dòng)駕駛的核心目標(biāo)是提高駕駛的安全性及效率,但如果這些過程中駕駛員與乘客無(wú)法感受到足夠的舒適性,這項(xiàng)技術(shù)就很難得到廣泛應(yīng)用。
行駛過程中影響駕乘舒適性的目標(biāo)主要有路面修繕不及時(shí)的坑洼、隆起的減速帶、路面上的石塊等,車輛若以較高速度駛過此類目標(biāo)會(huì)造成較大顛簸,突然的變道也可能使駕乘人員感到不適甚至導(dǎo)致事故發(fā)生。Dhiman 等[1]提出一種基于深度學(xué)習(xí)和立體視覺的坑洼檢測(cè)方法,取得不錯(cuò)的效果。針對(duì)路面減速帶的檢測(cè),Chen 等[2]提出一種通過放置于車輛前方的攝像裝置獲得的圖像檢測(cè)減速帶從而避免顛簸的方法,對(duì)此類影響駕乘舒適性的目標(biāo)進(jìn)行檢測(cè),可以方便汽車通過提前避讓、減緩行車速度等方法提升駕乘舒適性,具有一定的工程應(yīng)用價(jià)值。
自動(dòng)駕駛領(lǐng)域目標(biāo)檢測(cè)所使用的傳感器主要有相機(jī)、超聲波雷達(dá)、激光雷達(dá)、毫米波雷達(dá)等。純視覺算法相較于其他傳感器實(shí)現(xiàn)目標(biāo)檢測(cè)功能成本更低且更接近人類駕駛,自動(dòng)駕駛領(lǐng)域使用純視覺算法的汽車企業(yè)主要有特斯拉、百度、極氪等。
在深度學(xué)習(xí)應(yīng)用于目標(biāo)檢測(cè)領(lǐng)域之前,屬于傳統(tǒng)的目標(biāo)檢測(cè)時(shí)期。傳統(tǒng)目標(biāo)檢測(cè)算法使用滑動(dòng)窗口對(duì)待檢測(cè)圖像進(jìn)行遍歷,產(chǎn)生一定數(shù)量的候選區(qū)域,并對(duì)候選區(qū)域進(jìn)行特征提取;之后,所提取到的特征由Adaboost 或支持向量機(jī)(Support Vector Ma-chine,SVM)等方法進(jìn)行分類進(jìn)而得到最終檢測(cè)結(jié)果。該時(shí)期主要檢測(cè)方法有:Viola Jones 檢測(cè)器[3]、方向梯度直方圖(Histogram of Oriented Gradient,HOG)[4]、基于形變部件模型(Deformable Part Model,DPM)[5]等。實(shí)際場(chǎng)景下,傳統(tǒng)目標(biāo)檢測(cè)算法通常由于目標(biāo)相對(duì)體積較小及光照、遮擋等問題而無(wú)法提取有效特征,經(jīng)常出現(xiàn)漏檢等情況,并且計(jì)算量大、速度慢、魯棒性不強(qiáng)。
2012 年,ImageNet 競(jìng)賽中應(yīng)用卷積神經(jīng)網(wǎng)絡(luò)的AlexNet[6]的表現(xiàn)超越了一眾傳統(tǒng)目標(biāo)檢測(cè)方法,卷積神經(jīng)網(wǎng)絡(luò)的廣泛應(yīng)用使得基于深度學(xué)習(xí)方法的目標(biāo)檢測(cè)算法迅速發(fā)展。深度學(xué)習(xí)時(shí)期,主流的目標(biāo)檢測(cè)算法有兩類:①基于候選框推薦的雙階段(Two-stage)目標(biāo)檢測(cè)算法,代表作有R-CNN[7]、Faster R-CNN[8]、FPN[9]等;②基于回歸的單階段(One-stage)目標(biāo)檢測(cè)算法,如YOLO 系列[10]、SSD[11]系列等。雙階段目標(biāo)檢測(cè)算法先對(duì)待檢測(cè)圖像進(jìn)行候選框提取,再對(duì)得到的候選框進(jìn)行二次檢測(cè)從而得到檢測(cè)結(jié)果。雙階段目標(biāo)檢測(cè)算法檢測(cè)精度高,但由于網(wǎng)絡(luò)結(jié)構(gòu)導(dǎo)致檢測(cè)速度較慢,且由于檢測(cè)思路導(dǎo)致其對(duì)于全局的學(xué)習(xí)能力較差。單階段目標(biāo)檢測(cè)算法沒有候選框推薦階段,訓(xùn)練過程相較于雙階段算法更加簡(jiǎn)單,可以端到端地確定目標(biāo)位置與類別,該類算法檢測(cè)速度快,但檢測(cè)精度比雙階段算法低。
對(duì)實(shí)際駕駛場(chǎng)景進(jìn)行分析,影響駕乘舒適性的目標(biāo)檢測(cè)任務(wù)具有如下特點(diǎn):①路面坑洼、磚塊等目標(biāo)體積較小,檢測(cè)難度較大;②路面坑洼與路面背景非常相似,這也會(huì)給檢測(cè)準(zhǔn)確性帶來影響;③由于外部環(huán)境影響,如天氣變化、光照變化、場(chǎng)景遮擋等這些因素也會(huì)使得對(duì)此類目標(biāo)檢測(cè)的難度變大。為提高對(duì)此類目標(biāo)的檢測(cè)精度,本文提出了一種改進(jìn)的YOLOv5 目標(biāo)檢測(cè)方法,在提升對(duì)此類目標(biāo)檢測(cè)精度的同時(shí),保證了檢測(cè)實(shí)時(shí)性[12]。
1 YOLOv5結(jié)構(gòu)
YOLOv5 是一種單階段目標(biāo)檢測(cè)算法,已廣泛應(yīng)用于學(xué)術(shù)界和工業(yè)界,其在車輛檢測(cè)[13]、自動(dòng)駕駛環(huán)境感知[14]領(lǐng)域的應(yīng)用相對(duì)較多。YOLOv5 在YOLOv4[15]基礎(chǔ)上作了許多改進(jìn),使得檢測(cè)精度與速度得到了很大提升。其結(jié)構(gòu)由輸入端、Backbone、Neck、Head 4部分組成,如圖1所示。
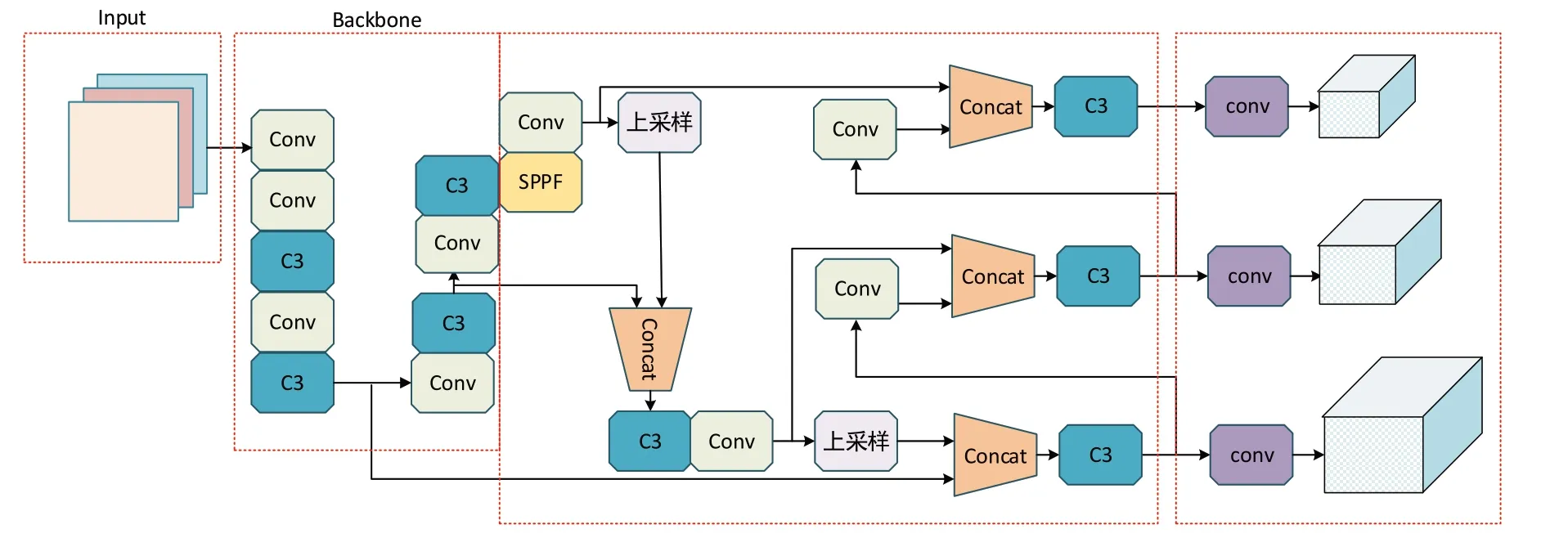
Fig.1 Construction of YOLOv5圖1 YOLOv5結(jié)構(gòu)
YOLOv5 在輸入端增加了Mosaic 數(shù)據(jù)增強(qiáng)、自適應(yīng)錨框、自適應(yīng)圖片縮放等操作。Mosaic 數(shù)據(jù)增強(qiáng)操作提高了小目標(biāo)的檢測(cè)效果并且提升了模型泛化性;自適應(yīng)錨框有利于提升檢測(cè)速度并縮短訓(xùn)練所需時(shí)間;自適應(yīng)圖片縮放可以使網(wǎng)絡(luò)接受不同尺寸的圖像并減少了圖片信息丟失。
YOLOv5 新版本將Backbone 中的CSP 模塊替換為C3模塊,其結(jié)構(gòu)如圖2 所示。C3 相較于CSP 模塊的不同之處是移除殘差輸出后的Conv 模塊,Concat 操作后的標(biāo)準(zhǔn)卷積模塊中的激活函數(shù)也由LeakyRelu 激活函數(shù)替換為SiLU 激活函數(shù)。相比于CSP 模塊,C3 模塊可以得到相似的表現(xiàn)卻更加簡(jiǎn)單、輕量和快速。
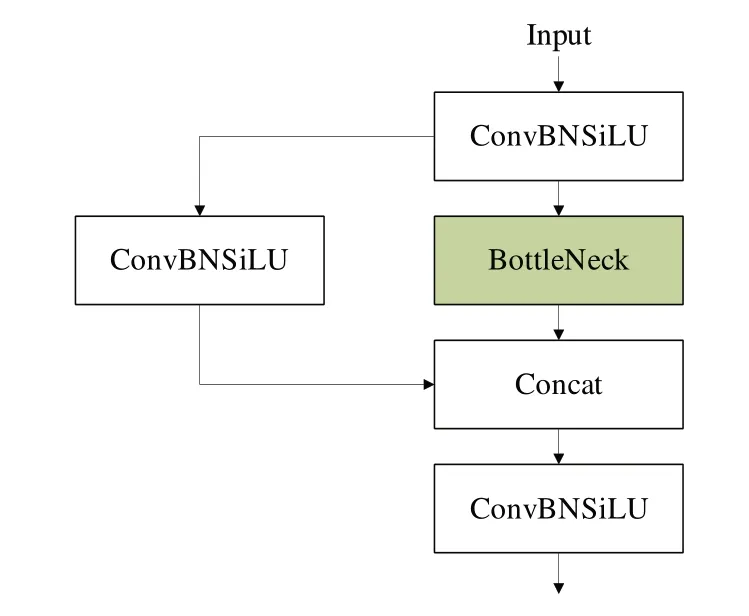
Fig.2 Construction of C3 module圖2 C3模塊結(jié)構(gòu)
Neck 中增加了FPN+PAN 結(jié)構(gòu),如圖3 所示。引入此結(jié)構(gòu)后,模型可以在融合不同尺度下目標(biāo)語(yǔ)義特征的同時(shí)融合定位特征,從而提高了對(duì)目標(biāo)的檢測(cè)精度。

Fig.3 Construction of FPN+PAN圖3 FPN+PAN結(jié)構(gòu)
Head 部分對(duì)3 種不同尺度的特征圖進(jìn)行處理,針對(duì)得到的各尺度特征圖在待檢測(cè)圖像上生成預(yù)測(cè)框,之后對(duì)預(yù)測(cè)框進(jìn)行非極大值抑(Non-Maximum Suppression,NMS)處理,去除重復(fù)預(yù)測(cè)框,從而實(shí)現(xiàn)對(duì)小、中、大不同尺度目標(biāo)的檢測(cè)。
2 改進(jìn)YOLOv5算法
2.1 C3模塊改進(jìn)
注意力機(jī)制如今廣泛應(yīng)用于目標(biāo)檢測(cè)任務(wù)中,通過模仿人類的感知特性,加入注意力機(jī)制的模型會(huì)有選擇性地更加關(guān)注某些信息。坐標(biāo)注意力(Coordinate Attention,CA)機(jī)制是一種綜合考慮空間與通道維度的輕量化注意力機(jī)制[16],可以輕松融合到不同的網(wǎng)絡(luò)中,同時(shí)也保持了模型輕量化。CA 注意力結(jié)構(gòu)如圖4 所示,相較于同樣綜合考慮了通道維度和空間維度的卷積塊注意力模塊(Convolutional Block Attention Module,CBAM)[17],CA 注意力機(jī)制解決了缺乏長(zhǎng)距離關(guān)系提取能力的問題。

Fig.4 Construction of coordinate attention mechanism圖4 CA注意力機(jī)制結(jié)構(gòu)
CA 注意力機(jī)制主要包括以下兩個(gè)步驟:
(1)信息嵌入操作。對(duì)于輸入特征圖,分別對(duì)特征圖水平方向和垂直方向進(jìn)行全局平均池化池化操作,得到兩個(gè)嵌入后的信息特征圖,此過程如圖5所示。
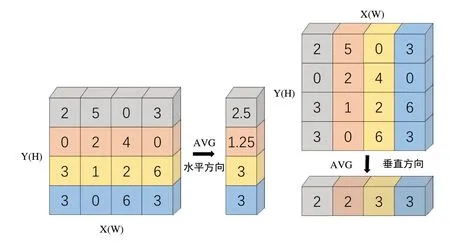
Fig.5 Information embedding operation圖5 信息嵌入操作
使用H×1 的池化核沿著水平方向即X 方向進(jìn)行全局平均池化操作,H×W×C 的輸入特征圖經(jīng)此得到H×1×C 的信息特征圖,計(jì)算方式如式(1)所示。
使用1×W 的池化核沿著垂直方向即Y 方向進(jìn)行全局平均池化操作,H×W×C 的輸入特征圖經(jīng)此得到1×W×C 的信息特征圖,計(jì)算方式如式(2)所示。
上述操作分別沿兩個(gè)空間方向聚合特征,得到一對(duì)方向感知征圖,允許注意力模塊捕捉到沿著一個(gè)空間方向的長(zhǎng)期依賴關(guān)系,并保存沿著另一個(gè)空間方向的精確位置信息,有助于網(wǎng)絡(luò)更準(zhǔn)確地定位感興趣的目標(biāo)。
(2)注意力生成操作。將上一步得到的兩個(gè)方向特征圖與沿空間維度拼接后進(jìn)行卷積操作,再經(jīng)過BatchNorm 和激活函數(shù),隨后沿空間維度進(jìn)行分片后得到兩個(gè)特征圖,之后分別對(duì)兩個(gè)特征圖進(jìn)行卷積操作和使用激活函數(shù),得到兩個(gè)注意力向量gh和gw,如式(3)所示。
其中,f為包含橫向和縱向空間信息的中間特征,r 為縮減因子。其中:
將得到兩個(gè)注意力向量gh與gw進(jìn)行廣播變換為C×H×W 維度,之后與經(jīng)過殘差操作的輸入特征圖Xc進(jìn)行對(duì)應(yīng)位置相乘操作后即可得到最后的注意力特征yc,如式(8)所示。
本文將CA 注意力機(jī)制引入C3 模塊的BottleNeck 部分中得到C3CA 模塊,BottleNeck 與修改后的CA-BottleNeck如圖6 所示。修改后的模型在3×3 卷積后增加了CA 注意力模塊。注意力機(jī)制的引入可以提升模型對(duì)重點(diǎn)信息的關(guān)注度。
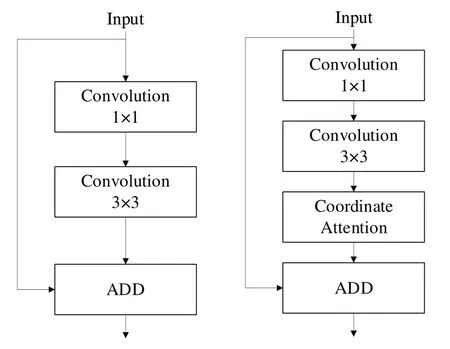
Fig.6 Comparison of BottleNeck before and after modification圖 6 BottleNeck修改前后對(duì)比
2.2 損失函數(shù)改進(jìn)
YOLOv5 所使用的LossCIoU損失函數(shù)綜合考慮了真實(shí)框與預(yù)測(cè)框之間重疊面積的IoU 損失、預(yù)測(cè)框與真實(shí)框中心位置之間歸一化后的距離損失、預(yù)測(cè)框與真實(shí)框之間的寬高縱橫比損失。LossCIoU計(jì)算如式(9)所示。
其中,b表示預(yù)測(cè)框,bgt表示真實(shí)框,ρ2(b,bgt)表示預(yù)測(cè)框與真實(shí)框中心點(diǎn)的歐氏距離,c表示能夠同時(shí)包圍預(yù)測(cè)框與真實(shí)框的最小閉包區(qū)域的對(duì)角線距離,β為平衡比例參數(shù),其計(jì)算如式(10)所示,v表示預(yù)測(cè)框與真實(shí)框的寬與高之間的比例是否接近,其計(jì)算如式(11)所示。
LossCIoU在邊界框損失函數(shù)中加入了作為懲罰項(xiàng)的寬高比,加速了預(yù)測(cè)框的回歸收斂過程。可以看出,LossCIoU所使用的是真實(shí)框和預(yù)測(cè)框的高與寬的相對(duì)比例,并不是高和寬的值,根據(jù)v的定義,若預(yù)測(cè)框的寬與高和真實(shí)框的寬與高比例滿足 {(w=kwgt,h=khgt)|k∈R+}時(shí),LossCIoU中的相對(duì)比例懲罰項(xiàng)目無(wú)法起作用。預(yù)測(cè)框的寬與高相對(duì)于v偏導(dǎo)的計(jì)算如式(12)所示。
為了緩解上述問題,引入Lossα-IoU[18]加以改進(jìn)。Lossα-IoU保留了原本LossCIoU損失函數(shù)的特性,同時(shí)可以幫助模型更加關(guān)注高IoU 目標(biāo)。Lossα-CIoU在原有的LossCIoU基礎(chǔ)上每一項(xiàng)增加了一個(gè)α指數(shù),當(dāng)α>1 時(shí),α增加了絕對(duì)損失量,提高了對(duì)不同層次目標(biāo)的優(yōu)化空間。改進(jìn)后的Lossα-CIoU計(jì)算公式如式(13)所示。
2.3 卷積模塊改進(jìn)
Conv 模塊作為YOLOv5 最基礎(chǔ)的組件,由卷積、Batchnormalization、激活函數(shù)組成,具體結(jié)構(gòu)如圖7所示。

Fig.7 Construction of Conv module圖7 Conv模塊結(jié)構(gòu)
其中,卷積操作用于提取特征;,Batchnormalization 操作用于調(diào)整數(shù)據(jù)使其重新分布,防止大量數(shù)據(jù)分布在飽和區(qū)造成梯度消失問題;激活函數(shù)用于引入非線性因素,提高模型擬合能力。
為了減少運(yùn)算量并保留特征信息,本文提出了一種新的卷積模塊,其結(jié)構(gòu)如圖8 所示,并將Neck 部分的Conv 模塊替換為新的卷積模塊。新的卷積模塊包括以下步驟:
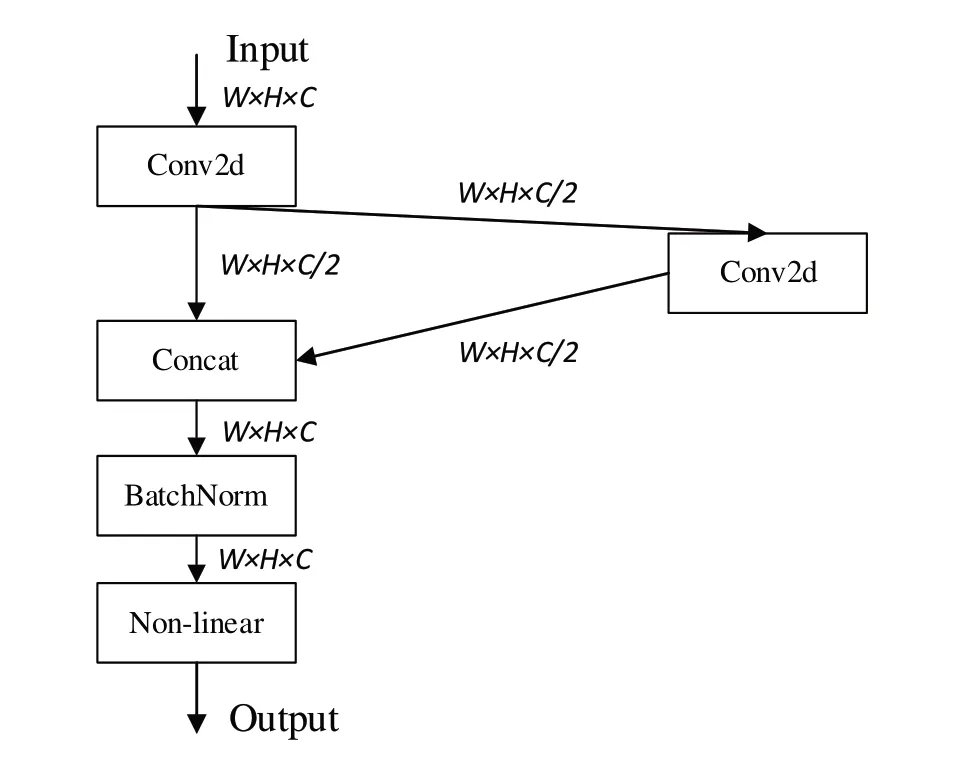
Fig.8 Construction of new conv module圖8 新卷積模塊結(jié)構(gòu)
Step 1:用1×1 大小的卷積核對(duì)輸入為W×H×C 的特征圖進(jìn)行通道壓縮,獲得大小為W×H×C/2 的特征圖,這一步操作主要在減少通道數(shù)的基礎(chǔ)上保留原有的特征信息。
Step2:用3×3 大小的卷積核對(duì)Step1 獲得的降維后的特征圖進(jìn)行遍歷,保持卷積操作后特征圖的尺寸不變,獲得大小為W×H×C/2 的特征圖。這一步驟旨在保證提取通道數(shù)減半后保留原有信息特征圖的更深層次特征。
Step3:將通道數(shù)壓縮后的W×H×C/2 特征圖與其經(jīng)過卷積特征提取后的W×H×C/2 特征圖沿著通道維度進(jìn)項(xiàng)Contact 操作,獲得大小為W×H×C 的特征圖。此特征圖既保留了卷積前特征圖的信息,也獲得了更深層的信息。由于使用降維后通道數(shù)減半的特征圖參與了3×3 的卷積操作進(jìn)行特征提取,故相比于直接使用3×3 卷積對(duì)原特征圖進(jìn)行特征提取,參數(shù)量和GFLOPS 都有了一定減少。
Step4:經(jīng)由BN 層和SiLu 激活函數(shù)加入非線性特征后傳遞至下一層。
改進(jìn)后的YOLOv5 算法結(jié)構(gòu)如圖9 所示,其中改進(jìn)后的C3 模塊稱為C3CA 模塊,新的卷積模塊稱為N-Conv 模塊,將Backbone 部分的所有C3 模塊替換為C3CA 模塊,將Neck 部分中的Conv模塊替換為N-Con 模塊。
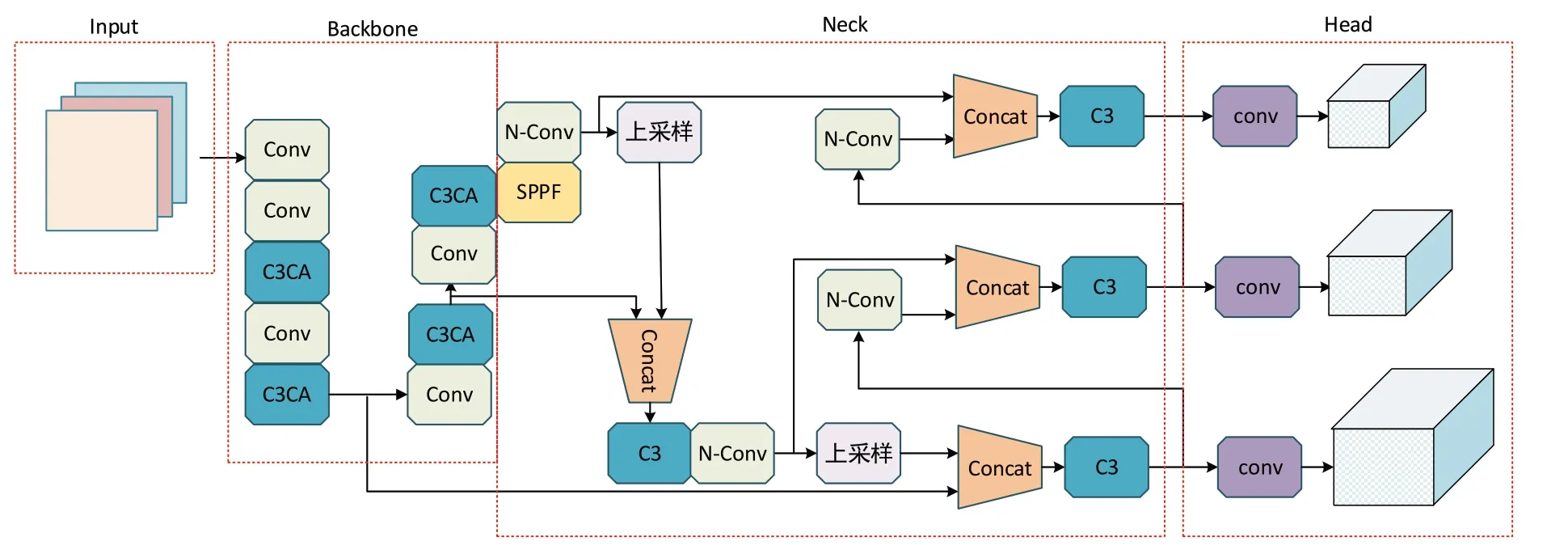
Fig.9 Comparison of YOLOv5 before and after modification圖9 改進(jìn)后的YOLOv5結(jié)構(gòu)
3 實(shí)驗(yàn)結(jié)果分析
3.1 數(shù)據(jù)集獲取與處理
本文實(shí)驗(yàn)所用數(shù)據(jù)集來源之一為Stellenbosch University 搜集并公開的路面坑洼數(shù)據(jù)集[19],該數(shù)據(jù)集共有1 784張圖片,包含可以影響到駕駛舒適性的路面坑洼目標(biāo)。高速或低速行駛過減速帶時(shí)也會(huì)給車輛帶來較大顛簸,故本文采用的另一數(shù)據(jù)集為發(fā)表在Mendeley Data 的減速帶數(shù)據(jù)集[20],包括有標(biāo)記的減速帶和無(wú)標(biāo)記的減速帶共543 張圖片。行駛過程中體積較大的石塊、磚塊等也會(huì)對(duì)駕駛舒適性帶來影響,現(xiàn)有公開數(shù)據(jù)集暫無(wú)此類圖片,因此在校園道路中使用Allied Vision 工業(yè)攝像機(jī)置于車頂模擬拍攝,共拍攝到含有磚塊、石塊等目標(biāo)的圖片共544 張。此外,拍攝不含有任何識(shí)別目標(biāo)的負(fù)樣本300 張,用于提高模型對(duì)目標(biāo)與背景的分辨能力。通過工業(yè)相機(jī)獲得的圖片為單通道Bayer格式,經(jīng)過插值算法獲得RGB 彩色圖像。
將圖片進(jìn)行匯總得到3 171 張圖片,按照8∶1∶1 的比例分為數(shù)據(jù)集、驗(yàn)證集和測(cè)試集。使用Labelimg 標(biāo)注工具進(jìn)行標(biāo)注,將有標(biāo)記的減速帶和無(wú)標(biāo)記的減速帶歸為一類,統(tǒng)一標(biāo)注為Speedbump,將路面石塊與磚塊歸為一類,統(tǒng)一標(biāo)注為Block、將路面坑洼標(biāo)注為Pothole。部分?jǐn)?shù)據(jù)集如圖10所示。

Fig.10 Part of the dataset images圖10 部分?jǐn)?shù)據(jù)集圖片
3.2 實(shí)驗(yàn)平臺(tái)
本文實(shí)驗(yàn)的操作系統(tǒng)為Ubuntu 20.04.4 LTS,CPU 型號(hào)為Intel? Xeon? Platinum 8255C CPU @ 2.50 GHz,內(nèi)存大小為43 GB。GPU 型號(hào)為NVIDIA RTX 3080,顯存大小為10 GB。Pytorch 版本為1.11.0,使 用CUDA11.3 配 合CUDNN8.2.0 版本的神經(jīng)網(wǎng)絡(luò)加速庫(kù),訓(xùn)練時(shí)參數(shù)設(shè)置如表1所示。

Table 1 Training parameter settings表1 訓(xùn)練參數(shù)設(shè)置
3.3 實(shí)驗(yàn)結(jié)果
為了驗(yàn)證本文所提出的改進(jìn)策略的有效性,對(duì)各改進(jìn)策略進(jìn)行評(píng)估,在數(shù)據(jù)集開展消融實(shí)驗(yàn),以判斷各改進(jìn)部分是否有效。YOLOv5_1、YOLOv5_2、YOLOv5_3 依次在YOLOv5s 模型的基礎(chǔ)上分別替換了引入注意力機(jī)制的C3模塊、Lossα-CIoU、改進(jìn)的卷積模塊,“√”表示應(yīng)用該策略,“-”表示未使用該策略。訓(xùn)練過程使用同一參數(shù)配置,各模型在測(cè)試集上的檢測(cè)結(jié)果如表2 所示,各模型參數(shù)量、GFLOPs、檢測(cè)速度如表3所示,訓(xùn)練過程如圖11所示。

Table 2 Improved YOLOv5 ablation test表2 改進(jìn)的YOLOv5消融實(shí)驗(yàn)
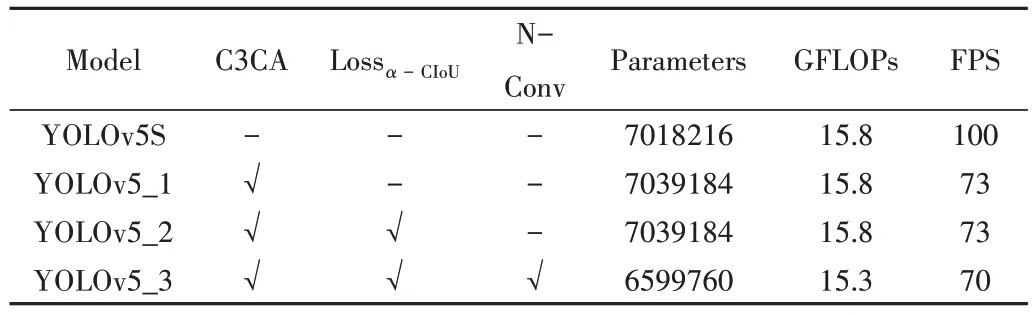
Table 3 Comparison of the parameters,calculation amount,and frame number of each model表3 各模型參數(shù)量、計(jì)算量、幀數(shù)比較

Fig.11 Comparison of mAP@0.5 value between YOLOv5 and improved model圖11 YOLOv5與改進(jìn)模型mAP@0.5值比較
可以看出,改進(jìn)后的模型相比于原有模型在數(shù)據(jù)集上獲得了更好的精度,在替換引入CA 注意力機(jī)制的C3 模塊后mAP 提高了1.4 個(gè)百分點(diǎn),相比于使用LossCIoU的YOLOv5_1 模型,替換為L(zhǎng)ossα-CIoU的YOLOv5_2 模型mAP 提升了0.2 個(gè)百分點(diǎn),在使用新的卷積模塊后mAP 提高了0.5個(gè)百分點(diǎn)。分析認(rèn)為,C3 模塊在引入CA 注意力機(jī)制后增強(qiáng)了對(duì)障礙目標(biāo)顯著特征的提取能力,提高了對(duì)重點(diǎn)信息的關(guān)注度,表現(xiàn)在檢測(cè)精度提升較為明顯,損失函數(shù)的改進(jìn)增加了對(duì)不同層次目標(biāo)的優(yōu)化空間,提高了回歸精度,使得mAP 小幅提升,新的卷積模塊的加入使得在保留原有特征信息的同時(shí)融合了深層抽象信息,使得mAP 有了一定程度的提升。從表3 可以看出,相比于原始的YOLOv5 算法或引入了CA 注意力和Lossα-CIoU的改進(jìn)算法,使用了新的卷積模塊后參數(shù)量和GFLOPs 都產(chǎn)生了下降。所提出的改進(jìn)算法每秒可以處理70 張圖片,保證了檢測(cè)實(shí)時(shí)性,具有一定的工程價(jià)值。
部分實(shí)驗(yàn)結(jié)果如圖12 所示,從第一幅待檢測(cè)圖片可以看出,相較于原始YOLOv5 算法,改進(jìn)后的算法檢測(cè)到了距離更遠(yuǎn)的坑洼,有利于駕駛員或自動(dòng)駕駛系統(tǒng)更早作出避讓動(dòng)作以避免顛簸發(fā)生;第二行待檢測(cè)圖片可以看出,改進(jìn)后的算法檢測(cè)到了原始算法未能檢測(cè)到的減速帶,并且檢測(cè)到的物體擁有更高的置信度;改進(jìn)算法在第三幅待檢測(cè)圖像中檢測(cè)出了更多坑洼;從第四幅圖待檢測(cè)圖片可以看出,改進(jìn)后的算法檢測(cè)到距離更遠(yuǎn)和左下角與背景相似的坑洼,原始YOLOv5 算法卻沒有檢測(cè)出。可以看出,改進(jìn)后的YOLOv5 算法對(duì)此類影響駕乘舒適性的目標(biāo)具有更好的檢測(cè)效果。

Fig.12 Comparison of improved test results圖12 改進(jìn)試驗(yàn)結(jié)果比較
為了進(jìn)一步評(píng)價(jià)改進(jìn)后算法的檢測(cè)性能,將本文的改進(jìn)算法與YOLOv5 對(duì)比的同時(shí),與現(xiàn)今常用深度學(xué)習(xí)目標(biāo)檢測(cè)算法SSD、YOLOv3、YOLOv4 進(jìn)行比較,結(jié)果如表4 所示,可以看出,本文提出的改進(jìn)方法保證了實(shí)時(shí)性的同時(shí),檢測(cè)精度獲得了更加優(yōu)異的表現(xiàn)。
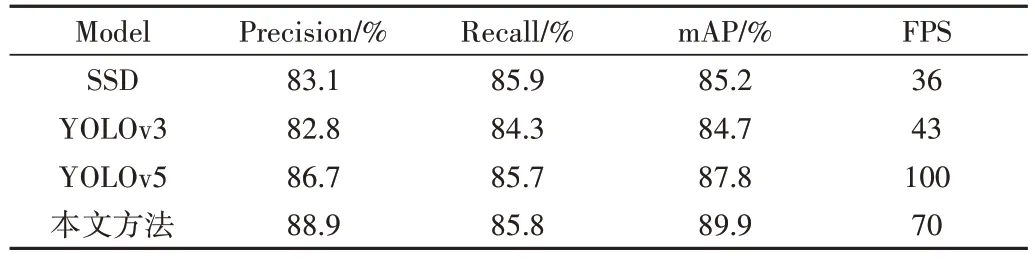
Table 4 Comparison of detection results of different models表4 不同模型檢測(cè)效果比較
4 結(jié)語(yǔ)
本文針對(duì)影響駕乘舒適性的目標(biāo)檢測(cè)難度大的問題,結(jié)合CA 注意力機(jī)制、Lossα-CIoU、新的卷積模塊,提出了一種改進(jìn)YOLOv5模型的目標(biāo)檢測(cè)算法。相較于其他主流的目標(biāo)檢測(cè)算法,該方法擁有更好的檢測(cè)精度和更快的檢測(cè)速度,且最終獲得的模型參數(shù)量更小,更加有助于未來在嵌入式端進(jìn)行算法的移植部署。在后續(xù)研究中,將更多地考慮影響駕乘舒適性體驗(yàn)的目標(biāo)類型,在目標(biāo)類別更加多樣化的同時(shí)保證模型檢測(cè)精度和識(shí)別速度。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
建筑熱能通風(fēng)空調(diào)(2018年5期)2018-07-09 03:16:38
池州學(xué)院學(xué)報(bào)(2017年3期)2017-10-16 01:38:35
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
消費(fèi)者報(bào)道(2016年3期)2016-02-28 19:07:32
