基于多智能體深度強(qiáng)化學(xué)習(xí)的無人艇集群博弈對抗研究
2024-03-14 03:42:38于長東劉新陽劉殿勇
水下無人系統(tǒng)學(xué)報 2024年1期
于長東 ,劉新陽 ,陳 聰 ,劉殿勇 ,梁 霄 *
(1.大連海事大學(xué) 人工智能學(xué)院,遼寧 大連,116026;2.哈爾濱工程大學(xué) 智能海洋航行器技術(shù)全國重點(diǎn)實(shí)驗(yàn)室,黑龍江 哈爾濱,150001;3.大連海事大學(xué) 船舶與海洋工程學(xué)院,遼寧 大連,116026)
0 引言
在現(xiàn)代軍事研究領(lǐng)域,隨著高新技術(shù)的快速發(fā)展,催化了戰(zhàn)場中作戰(zhàn)思想、理論和模式等方面的迅速變革,戰(zhàn)爭形態(tài)逐漸趨于信息化和智能化[1-3]。人工智能和無人系統(tǒng)技術(shù)為未來戰(zhàn)爭中的決策分析、指揮控制和博弈對抗等應(yīng)用提供了更多智能決策和自主作戰(zhàn)能力,逐漸扮演著更加重要的角色。其中,無人艇作為一種全自動小型水面機(jī)器人,具有體型小、機(jī)動靈活以及活動范圍廣等優(yōu)勢,在情報偵查、海上巡邏以及環(huán)境檢測等領(lǐng)域發(fā)揮著重要作用[4]。
強(qiáng)化學(xué)習(xí)作為人工智能技術(shù)的重要分支,目前在無人艇、無人機(jī)等多智能體博弈對抗問題中具有重要的應(yīng)用價值[5-7]。李波等[8]將多智能體深度確定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)算法應(yīng)用于多無人機(jī)的協(xié)同任務(wù)研究,可以解決簡單的任務(wù)決策問題。劉菁等[9]提出了博弈理論與Q-Learning 相結(jié)合的無人機(jī)集群協(xié)同圍捕方法,結(jié)果表明該方法可以完成對單目標(biāo)的有效圍捕。Zhan 等[10]提出了多智能體近端策略優(yōu)化(multi-agent proximal policy optimization,MAPPO)算法,用于實(shí)現(xiàn)異構(gòu)無人機(jī)的分布式?jīng)Q策和協(xié)作任務(wù)完成。趙偉等[11]對無人機(jī)智能決策的發(fā)展現(xiàn)狀和未來挑戰(zhàn)進(jìn)行了討論和分析。相比之下,目前國內(nèi)外對于無人艇的博弈對抗研究工作相對較少,仍處于發(fā)展階段。蘇震等[12]開展了關(guān)于無人艇集群動態(tài)博弈對抗的研究,提出利用深度確定性策略梯度(deep deterministic policy gradient,DDPG)算法來設(shè)計策略求解方法,訓(xùn)練得到的智能體可以較好地完成協(xié)同圍捕任務(wù)。夏家偉等[13]則使用MAPPO 算法完成對單一無人艇的協(xié)同圍捕任務(wù),通過結(jié)合圍捕任務(wù)背景,建立了伸縮性和排列不變性的狀態(tài)空間,最后利用課程式學(xué)習(xí)訓(xùn)練技巧完成對圍捕策略的訓(xùn)練,結(jié)果表明所提方法在圍捕成功率上相較于其他算法具有一定優(yōu)勢。
無人艇集群博弈對抗的研究工作仍處于起步階段,存在較大的提升空間: 目前的研究中,無人艇博弈對抗中的敵方通常采用傳統(tǒng)算法躲避我方的攔截圍捕,缺乏智能化決策能力;其次,海上目標(biāo)行為動作較為復(fù)雜,雙方博弈過程中的當(dāng)前決策需要充分考慮前后階段產(chǎn)生的影響結(jié)果;此外,除需要圍捕的動態(tài)目標(biāo)外,海上還存在島礁等障礙物,在博弈對抗中還需要考慮躲避島礁障礙物等問題。
受到以上啟發(fā),文中以無人艇集群對敵方入侵島礁目標(biāo)進(jìn)行圍捕攔截為背景,開展基于多智能體深度強(qiáng)化學(xué)習(xí)的無人艇集群協(xié)同圍捕研究。首先基于現(xiàn)代式作戰(zhàn)需求,合理設(shè)計作戰(zhàn)假想,建模相應(yīng)的圍捕環(huán)境;其次,采用MADDPG 算法求解策略方法,根據(jù)不同的圍捕任務(wù)設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)、獎勵函數(shù)和訓(xùn)練方法;最后通過仿真實(shí)驗(yàn)表明,訓(xùn)練得到的我方無人艇經(jīng)過博弈后能夠有效完成對敵方的圍捕攔截任務(wù)。
1 任務(wù)場景描述
海上無人艇集群協(xié)同圍捕任務(wù)是一種典型的集群作戰(zhàn)模式,如圖1 所示,文中主要針對海上島礁防衛(wèi)任務(wù)場景展開研究。不同于離散化任務(wù)環(huán)境的方案,文中從實(shí)際作戰(zhàn)角度出發(fā),設(shè)計了連續(xù)的海上作戰(zhàn)地圖作為無人艇集群博弈對抗問題中的任務(wù)環(huán)境,即采用連續(xù)的空間坐標(biāo)位置來表示敵我雙方的位置信息。若干敵方無人艇會隨機(jī)出現(xiàn)在某海域位置,對目標(biāo)島礁進(jìn)行入侵進(jìn)攻。而我方無人艇集群在島礁周圍進(jìn)行常態(tài)化巡邏,當(dāng)發(fā)現(xiàn)入侵?jǐn)撤胶?會迅速調(diào)整狀態(tài)去攔截圍捕敵方。

圖1 無人艇圍捕場景示意圖Fig.1 Round-up scene of unmanned surface vehicles
無人艇的簡化運(yùn)動模型定義為
式中,(,)和 (,)分別表示2 艘艇的坐標(biāo)位置。此外,我方無人艇在圍捕敵方的過程中,考慮到實(shí)際無人艇發(fā)生碰撞的可能性,當(dāng)我方各無人艇距離敵方目標(biāo)點(diǎn)距離l小于圍捕半徑r時,則視為完成圍捕任務(wù)。
2 博弈算法與訓(xùn)練策略設(shè)計
文中考慮深度強(qiáng)化學(xué)習(xí)在無人艇集群的博弈對抗策略上的應(yīng)用。強(qiáng)化學(xué)習(xí)下無人艇與戰(zhàn)場環(huán)境的交互過程如圖2 所示: 無人艇根據(jù)戰(zhàn)場環(huán)境的即時狀態(tài)St,執(zhí)行可以獲得最大回報的行為動作At,以使得獎勵Rt達(dá)到最大值。在選擇行為At后,環(huán)境會給予無人艇Rt的獎勵,同時環(huán)境進(jìn)行到下一狀態(tài)St+1。然后無人艇根據(jù)下一狀態(tài)St+1和獎勵的反饋Rt+1,選擇執(zhí)行下一個行為動作,進(jìn)入下一輪的動態(tài)交互。
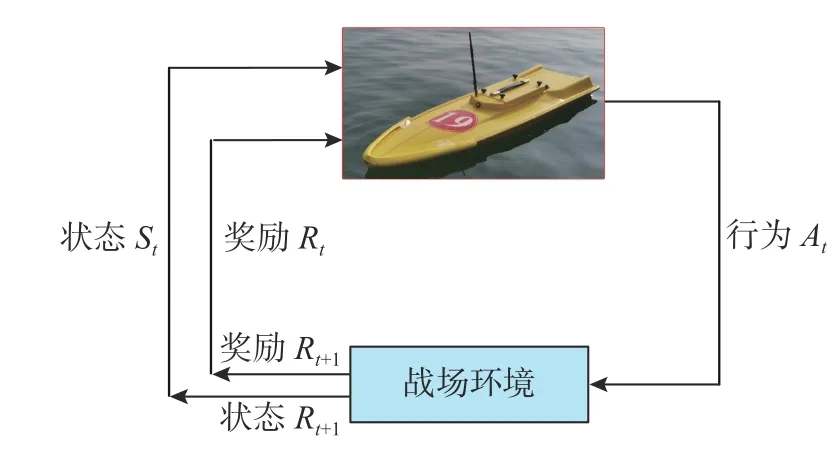
圖2 無人艇與環(huán)境交互過程示意圖Fig.2 Schematic diagram of the interaction process between the USV and environment
基于實(shí)際作戰(zhàn)思想,在敵我雙方的無人艇博弈對抗中,若一方的各無人艇處于協(xié)同合作關(guān)系,則對方的無人艇處于競爭博弈關(guān)系。針對該問題,文中選擇了主流的群智能體強(qiáng)化學(xué)習(xí)算法——MADDPG 算法[14]。MADDPG 算法由DDPG 算法[15]發(fā)展而來,可有效緩解訓(xùn)練中的非平穩(wěn)問題,提高學(xué)習(xí)效率。
2.1 DDPG 算法
DDPG 算法在網(wǎng)絡(luò)結(jié)構(gòu)上采用了基于“行動者-評論家” (actor-critic,AC)的框架形式[15],Actor網(wǎng)絡(luò)基于當(dāng)前智能體的狀態(tài)信息,給出確定性動作策略,讓智能體執(zhí)行最優(yōu)動作,同時通過策略梯度算法不斷優(yōu)化策略網(wǎng)絡(luò)參數(shù);而Critic 網(wǎng)絡(luò)則對智能體基于當(dāng)前狀態(tài)的動作進(jìn)行Q值評估,并根據(jù)智能體的實(shí)際收益,更新目標(biāo)價值和網(wǎng)絡(luò)參數(shù),提高估計的準(zhǔn)確性。
DDPG 算法的AC 網(wǎng)絡(luò)受到深度Q學(xué)習(xí)的在線-目標(biāo)雙網(wǎng)絡(luò)結(jié)構(gòu)的啟發(fā),將在線訓(xùn)練方式轉(zhuǎn)向離線訓(xùn)練方式,簡化了許多復(fù)雜操作,同時也提高了數(shù)據(jù)的有效利用。AC 網(wǎng)絡(luò)結(jié)構(gòu)分別由2 個完全相同的深度神經(jīng)網(wǎng)絡(luò)組成,這2 個網(wǎng)絡(luò)的作用是將輸入的狀態(tài)信息和輸出的動作信息進(jìn)行連續(xù)化處理,同時還能夠?qū)⒌途S度的離散信息映射到高維度的連續(xù)信息空間中。圖3 展示了 DDPG 算法的數(shù)據(jù)傳遞結(jié)構(gòu)示意圖[16],結(jié)構(gòu)左側(cè)為Actor 策略網(wǎng)絡(luò),通過策略梯度優(yōu)化對網(wǎng)絡(luò)參數(shù)進(jìn)行優(yōu)化,從而將狀態(tài)信息映射到最優(yōu)策略;然后網(wǎng)絡(luò)根據(jù)策略輸出確定性動作,并將其送入右側(cè)的在線價值網(wǎng)絡(luò)來預(yù)測狀態(tài)-動作價值;在線價值網(wǎng)絡(luò)則采用價值梯度來更新優(yōu)化網(wǎng)絡(luò)參數(shù),將狀態(tài)-動作組映射為價值函數(shù);最后,采用滑動平均更新法對目標(biāo)網(wǎng)絡(luò)參數(shù)進(jìn)行更新。

圖3 DDPG 算法數(shù)據(jù)傳遞結(jié)構(gòu)示意圖Fig.3 Structure of data transfer of DDPG algorithm
2.2 MADDPG 算法
在多無人艇系統(tǒng)中,每個無人艇都是獨(dú)立的智能體,由于各智能體同時受到環(huán)境和其他智能體的影響,使用單智能體強(qiáng)化學(xué)習(xí)算法無法有效處理復(fù)雜多變的多智能體環(huán)境,從而導(dǎo)致訓(xùn)練效果通常不理想。因此,文中采用了多智能體強(qiáng)化學(xué)習(xí)算法MADDPG 作為無人艇集群協(xié)同圍捕方法。MADDPG 算法通過經(jīng)驗(yàn)回放、目標(biāo)網(wǎng)絡(luò)和通信機(jī)制等方式來考慮前后階段產(chǎn)生的影響問題,從而處理多智能體系統(tǒng)中的長時間依賴性和協(xié)作競爭問題。
MADDPG 在訓(xùn)練多智能體過程中使用了集中式訓(xùn)練和分布式執(zhí)行方案,即訓(xùn)練中一方的所有智能體都共享全局信息,同時智能體可以并行地執(zhí)行策略,從而加速學(xué)習(xí)過程。該方案可以使多智能體系統(tǒng)能夠更好地協(xié)同學(xué)習(xí)和協(xié)調(diào)策略,提高訓(xùn)練效率和穩(wěn)定性。MADDPG 網(wǎng)絡(luò)中的數(shù)據(jù)傳遞如圖4 所示,在更新網(wǎng)絡(luò)的訓(xùn)練過程中,中心化的評價函數(shù)Critic 使用經(jīng)驗(yàn)池中的聯(lián)合經(jīng)驗(yàn)數(shù)據(jù)來更新網(wǎng)絡(luò)參數(shù),而Actor 函數(shù)會依據(jù) Critic 給出的Q值更新策略。當(dāng)更新完成后,在實(shí)際執(zhí)行階段用更新后的 Actor 決策函數(shù)進(jìn)行去中心化決策,即執(zhí)行階段僅使用自身的局部觀察得到策略,這樣能夠有效減少復(fù)雜度和計算量。
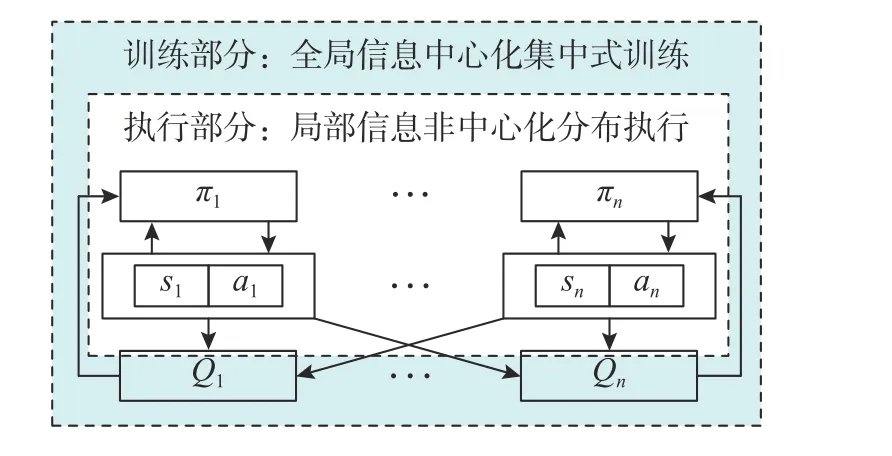
圖4 MADDPG 算法數(shù)據(jù)傳遞結(jié)構(gòu)示意圖Fig.4 Structure of data transfer of MADDPG algorithm
MADDPG 算法的具體執(zhí)行流程[16]如圖5 所示。

圖5 MADDPG 算法具體執(zhí)行流程Fig.5 Execution process of MADDPG algorithm
2.3 任務(wù)決策與獎勵函數(shù)設(shè)計
文中基于海上島礁防衛(wèi)任務(wù)展開研究。假設(shè)無人艇分別為USV1,USV2,…,USVk,每艘無人艇的自身狀態(tài)空間Susv中不僅包括當(dāng)前時刻的速度信息 (uk,vk),還包括在海洋環(huán)境中的坐標(biāo)位置信息(xk,yk)。此外,環(huán)境狀態(tài)Senv則包含了島嶼的坐標(biāo)位置 (Dx,Dy),該島嶼位置既是我方保衛(wèi)目標(biāo)位置,也是敵方進(jìn)攻目標(biāo)位置。
文中的敵方艇也采用了智能化逃跑策略,因此文中敵我雙方都采用了基于MADDPG 算法的博弈策略。在文中設(shè)計的 MADDPG 算法中,每艘無人艇的狀態(tài)包括了環(huán)境狀態(tài)、自身狀態(tài)以及其他無人艇的狀態(tài)。每艘無人艇在t時刻的狀態(tài)定義為
此外,無人艇集群的友方之間可以獲取角度信息 φi,該角度為我方2 個無人艇靠近敵方無人艇形成的夾角。無人艇的動作范圍是二維的連續(xù)空間,采取確定性動作策略后,會在每一時刻輸出瞬時速度 (ux,vy),無人艇經(jīng)過 Δt時刻后的位置更新為,即
文中主要從以下2 方面來設(shè)計獎勵函數(shù)。
敵方獎勵函數(shù)設(shè)計如下:
敵方在運(yùn)動過程中的獎勵目標(biāo)函數(shù)為Rr=其中di為第i艘敵方無人艇與目標(biāo)的最近距離,距離越近獎勵值越大;此外給與碰撞懲罰,當(dāng)敵方碰撞到船只或島嶼時,懲罰為-5。
我方獎勵函數(shù)設(shè)計如下:
3 實(shí)驗(yàn)結(jié)果與分析
3.1 模型參數(shù)設(shè)計
文中應(yīng)用的MADDPG 算法模型使用了確定性動作策略,即a=πθ(s)。網(wǎng)絡(luò)結(jié)構(gòu)具體設(shè)計如下:當(dāng)我方與敵方無人艇數(shù)量為3 對1 時,策略網(wǎng)絡(luò)結(jié)構(gòu)為[14;64;64;2]的全連接神經(jīng)網(wǎng)絡(luò),價值網(wǎng)絡(luò)結(jié)構(gòu)為[14;64;64;1]的全連接神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)表示輸入層、隱藏層和輸出層對應(yīng)的節(jié)點(diǎn)數(shù);當(dāng)無人艇數(shù)量為6 對2 時,策略網(wǎng)絡(luò)結(jié)構(gòu)為[26;64;64;2],價值網(wǎng)絡(luò)的結(jié)構(gòu)則為[26;64;64;1]。在訓(xùn)練時的最小批尺寸為512;訓(xùn)練3 對1 時最大回合數(shù)為5 000,訓(xùn)練6 對2 時最大回合數(shù)為10 000,價值網(wǎng)絡(luò)的學(xué)習(xí)率為0.001,策略網(wǎng)絡(luò)的學(xué)習(xí)率為0.001,2 個網(wǎng)絡(luò)都采用了Adam 優(yōu)化器進(jìn)行訓(xùn)練網(wǎng)絡(luò),經(jīng)驗(yàn)池的大小為5×105。
3.2 結(jié)果分析
文中分別進(jìn)行了保衛(wèi)島嶼場景下的無人艇3 對1 和6 對2 的博弈對抗實(shí)驗(yàn)。
1) 3 對1 實(shí)驗(yàn)
雙方無人艇回報曲線如圖6 所示。可以看出,雙方回報值都呈現(xiàn)整體上升并增至最大值,然后趨于穩(wěn)定。這說明雙方處于一種互相競爭的狀態(tài),最終達(dá)到一種博弈平衡。從后期的回報曲線可以看出,我方無人艇的曲線分布一致且相對穩(wěn)定,每艘無人艇均可完成圍捕任務(wù)。
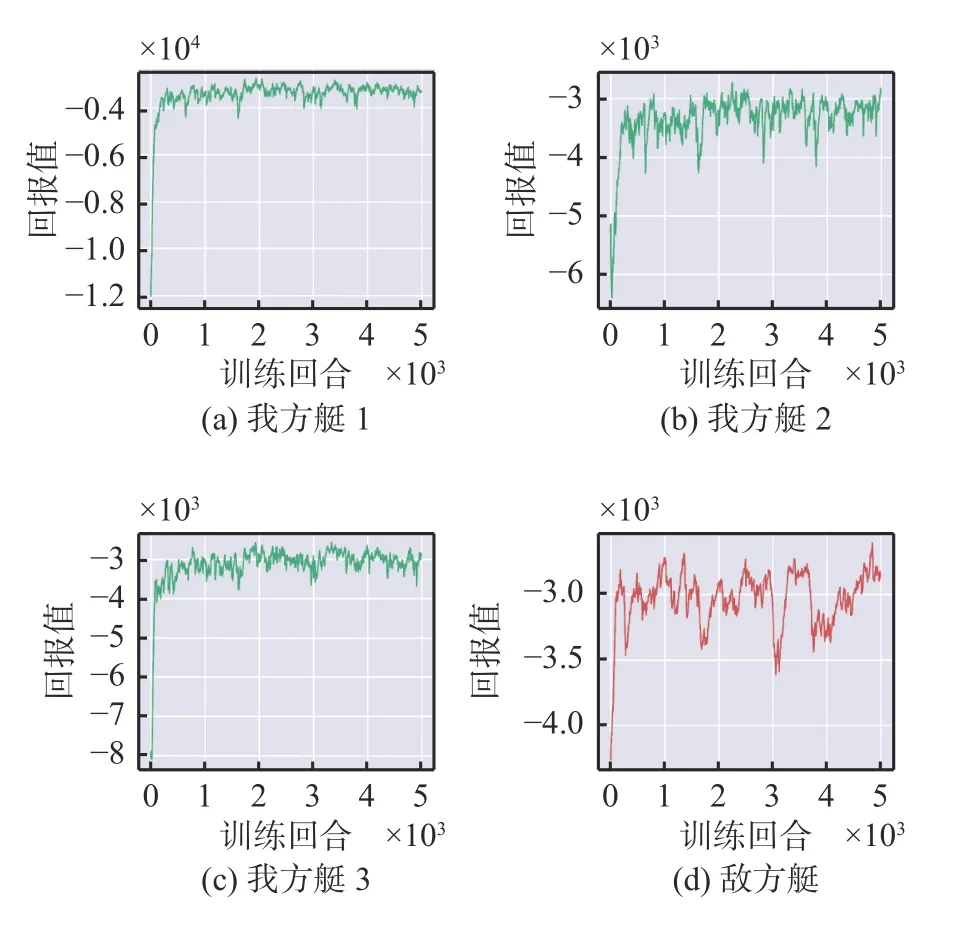
圖6 3 對1 時各艇回報值Fig.6 Return values of the USVs at 3 vs 1
圖7 展示了3 對1 時不同時刻的仿真結(jié)果。在初始時刻,我方無人艇圍繞在島嶼周圍進(jìn)行巡邏,敵方無人艇隨機(jī)出現(xiàn)在某一位置(見圖7(a));隨后,敵方無人艇對目標(biāo)島嶼進(jìn)行進(jìn)攻,我方發(fā)現(xiàn)目標(biāo)后,選擇繞開島嶼障礙物,并對敵方進(jìn)行圍捕攔截(見圖7(b)和(c));最后,我方無人艇對敵方無人艇進(jìn)行包圍,分散在其周圍,并保持跟隨,視為圍捕成功(見圖7(d))。
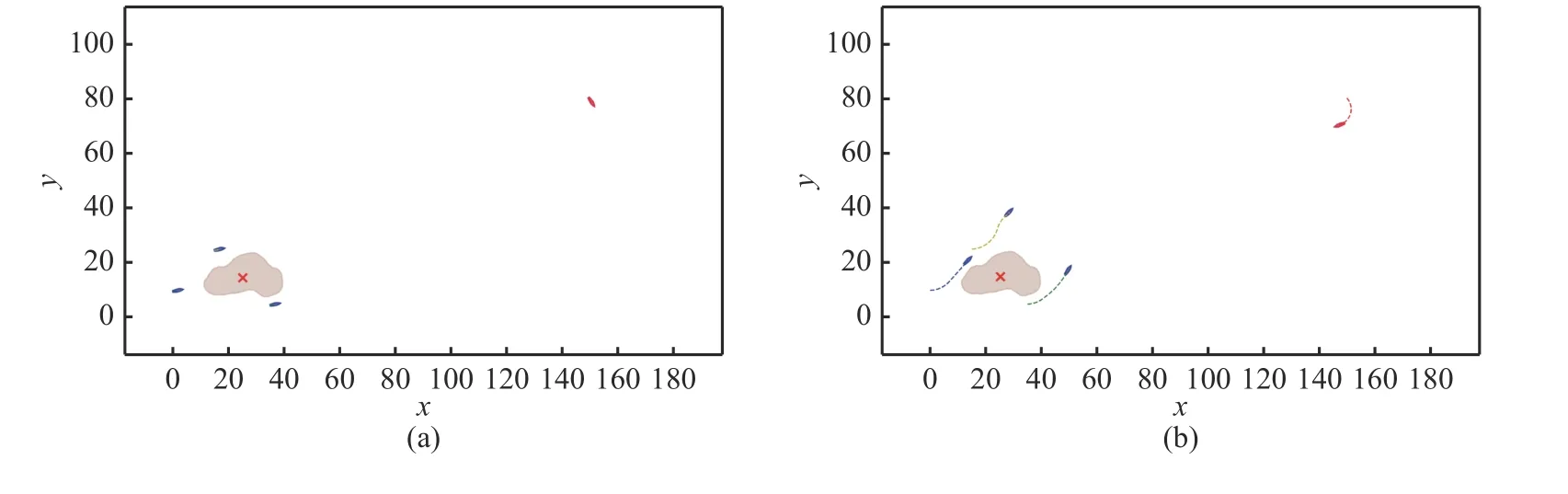
圖7 3 對1 仿真結(jié)果示意圖Fig.7 Simulation results of 3 vs 1
2) 6 對2 實(shí)驗(yàn)
我方6 艘無人艇所獲得的回報曲線如圖8 所示。可以看出,我方無人艇回報值均呈現(xiàn)上升趨勢并最終趨于穩(wěn)定狀態(tài)。這說明無人艇集群在訓(xùn)練中得到了良好的收益,有效完成了任務(wù)目標(biāo)。相比之下,敵方無人艇的回報曲線則先上升,之后出現(xiàn)了嚴(yán)重的波動,呈現(xiàn)不穩(wěn)定現(xiàn)象,如圖9所示。

圖9 6 對2 時敵方各艇回報值Fig.9 Return values of enemy USVs at 6 vs 2
圖10 展示了6 對2 時不同時刻的仿真結(jié)果。在初始時刻,我方6 艘無人艇分散在島嶼周圍,敵方2 艘無人艇隨機(jī)出現(xiàn)在不同區(qū)域(見圖10(a));當(dāng)發(fā)現(xiàn)敵方無人艇后,我方無人艇首先繞過島嶼,然后去圍捕攔截敵方無人艇(見圖10(b));敵方無人艇不斷進(jìn)行智能躲避,而我方充分考慮了敵方目前位置以及下一階段的運(yùn)動趨勢,并在其周圍展開圍捕(見圖10(c)~(e));最后,我方無人艇成功完成對敵方的圍捕,以持續(xù)的圍捕狀態(tài)伴隨在敵方周圍(見圖10(f))。

圖10 6 對2 仿真結(jié)果示意圖Fig.10 Simulation results of 6 vs 2
4 結(jié)束語
基于實(shí)際的海上作戰(zhàn)背景,文中提出了基于多智能體深度強(qiáng)化學(xué)習(xí)方法MADDPG,用以解決無人艇群動態(tài)博弈對抗中的協(xié)同圍捕決策問題。通過搭建模型,設(shè)計獎勵函數(shù)和訓(xùn)練函數(shù),完成實(shí)驗(yàn)。通過3 對1 和6 對2 的仿真實(shí)驗(yàn),結(jié)果表明我方無人艇可以有效完成對敵方無人艇的圍捕攔截,證明了所搭建模型系統(tǒng)的有效性,為未來實(shí)戰(zhàn)的應(yīng)用提供了技術(shù)支撐和理論參考。在未來的研究工作中,將會考慮采用更加高效的狀態(tài)信息處理手段,例如文獻(xiàn)[13]中的伸縮和排列不變性設(shè)計,以使同一個網(wǎng)絡(luò)結(jié)構(gòu)可以適用于不同數(shù)量無人艇的博弈對抗場景。
猜你喜歡
教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52
中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
