
以對比學習與時序遞推提升摘要泛化性的方法
2024-03-19 11:47:28湯文亮陳帝佑桂玉杰劉杰明徐軍亮
重慶理工大學學報(自然科學) 2024年2期
湯文亮,陳帝佑,桂玉杰,劉杰明,徐軍亮
(華東交通大學信息工程學院,南昌 330013)
0 引言
生成式文本摘要領域如今已有很多大型的Se-q2Seq模型,從最初循環(huán)神經(jīng)網(wǎng)絡的提出標志著生成式摘要模型雛形的誕生[1],到LSTM[2]和GRU[3]等模型的出現(xiàn),緩解了數(shù)據(jù)時序性對于文本長度的依賴問題。后來有指針網(wǎng)絡(PN)[4]和指針生成網(wǎng)絡(PGN)[5]的提出,有效解決了OOV(out-of-vocabul-ary)問題,又隨著基于注意力機制的Transformer[6]問世,模型對于文本特征提取達到了一個前所未有的高度,使得自然語言處理領域的模型進入了一個新紀元。隨后對于通用的自然語言任務場景的特征提取誕生了不少大參數(shù)量的模型,如基于Transformer編碼器結(jié)構(gòu)的BERT[7]能夠充分獲取文本的上下文信息,也對文本生成任務提供了巨大幫助;X-LNet[8]在大量無標簽數(shù)據(jù)中訓練,從而能夠有效避免訓練過程中的偏差問題;基于Transformer解碼器結(jié)構(gòu)的GPT模型[9],其解碼器的特點使得GPT能夠在文本生成類任務上有著極佳的表現(xiàn)。
以上提到的諸多模型都是基于傳統(tǒng)神經(jīng)網(wǎng)絡模型構(gòu)建和訓練的,通過模型的輸出結(jié)果與標簽以極大似然估計的方式來構(gòu)建損失函數(shù)。同時,對于傳統(tǒng)深度神經(jīng)網(wǎng)絡模型的改進方法都已十分成熟,因此想從優(yōu)化模型本身結(jié)構(gòu)的方式入手來優(yōu)化文本信息的特征提取不是一件容易的事情。
但傳統(tǒng)訓練方式往往會導致模型的泛化性無法達到最佳,SimCLS[10]和BRIO[11]通過構(gòu)建多個候選摘要的方式,將候選摘要按照某種分數(shù)排序[12],利用候選摘要的句間信息構(gòu)建對比損失函數(shù)[13],使得模型的泛化性得到提升,從而在測試集上取得更好的效果。
通過候選摘要間對比損失的訓練方式(每一個候選摘要都會以分數(shù)高于自身的摘要為正樣本,分數(shù)較低的作為負樣本)雖然能讓模型的泛化性得到提升,但當分數(shù)較高的正樣本與參考摘要內(nèi)容差距較大或者與負樣本內(nèi)容差距較小時就會“誤導”模型在文本生成中g(shù)(ci|D;θ)→ci+1的能力,從而導致生成的文本準確性降低,其中g(shù)表示模型,D表示原文檔,θ表示模型的參數(shù),ci表示任意一個候選摘要的第i個詞元。
為了緩解上述訓練方式的“誤導”問題,提出了3種解決方式使得模型在提高泛化性的同時,能夠提升解碼器輸出的候選摘要與其對應候選標簽的文本相似度。
方法1:通過構(gòu)建反語意文本,替換候選集中的原文本來增大正樣本與負樣本間的距離,將分數(shù)越低的樣本以更大概率“反語意”化,達到負樣本“更負”的效果。
方法2:從候選集句間的關(guān)系層面控制準確度,在Seq2Seq模型輸出的概率分布中,不僅是選取候選集中每一個句子對應的標簽概率來計算句子之間的對比損失值,還以貪心搜索的方式計算每一句摘要輸出的最大概率值的詞元來計算對比損失值,從而進一步提升泛化性。
方法3:從每一候選摘要句內(nèi)詞元層面細粒度控制準確度,使每一個候選摘要的時序概率最大化。與傳統(tǒng)極大似然估計不同的是,該方法通過構(gòu)建遞推關(guān)系式xi=f(xi-1),降低對當前詞元本身概率值的關(guān)心度,更在意對于任意摘要的第i個詞元,在前i-1個詞元推理正確的情況下,使第i個詞元的分數(shù)最大化,從而保證在推理過程中每一個時間步的準確性。
1 基線模型與訓練方式
無論是基于Transformer結(jié)構(gòu)的模型、圖神經(jīng)網(wǎng)絡模型[14]或者文本卷積模型[15],其核心應用都是以不同的方式提取文本特征[16]。
從基礎模型的角度來說,基于Transformer的大模型結(jié)構(gòu)在文本生成任務中的效果遠遠優(yōu)于現(xiàn)有的圖結(jié)構(gòu)和卷積網(wǎng)絡結(jié)構(gòu)。因此,本文選擇的2個基礎模型正是基于Transformer結(jié)構(gòu)的較大體量的模型。
1.1 基線模型
選取以雙向自回歸方式訓練的BART[17]和以掩蓋式語言建模MLM(mask languagemodel)訓練的PEGASUS模型[18]作為基礎模型。
其中,BART是FaceBook在CNN/DailyMail數(shù)據(jù)上微調(diào)的BART-LARGE(406.29 M參數(shù)量)和Google在Xsum數(shù)據(jù)上微調(diào)的PEGASUS(569.75 M參數(shù)量),并且以Rouge[19]分數(shù)作為主要評價指標。
表1所示的是多種結(jié)合Transformer結(jié)構(gòu)的模型分別在CNN/DailyMail(CNNDM)和Xsum數(shù)據(jù)集上的Rouge分數(shù),其中R-1、R-2、R-L分別表示Rouge-1、Rouge-2、Rouge-Lsum。
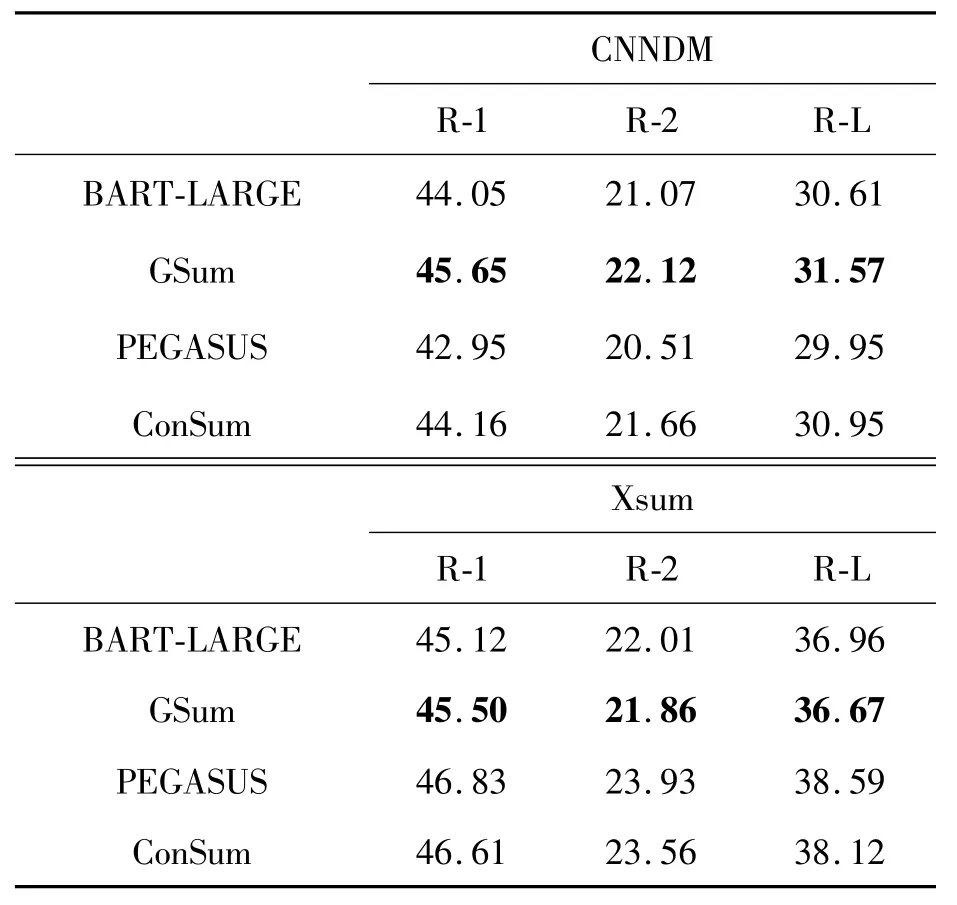
表1 基線模型的Rouge分數(shù)(采用F1分數(shù)作為指標)
1.2 訓練方式
1.2.1 訓練流程
如圖1所示的是本次實驗的整體訓練流程①本次實驗的源代碼、模型和實驗結(jié)果提供在https://github.com/cq-cdy/ecjtu-brio-improved。,首先將CNNDM和Xsum數(shù)據(jù)集分別經(jīng)過基礎模型BART-LARGE和PEGASUS,以beamwidth=N和隨機采樣等方式生成候選摘要,并且與參考摘要一同并為候選集標簽,即整個候選集的摘要數(shù)目為1+N。
將候選集輸入解碼器得到整個候選集的概率分布,圖1中wi表示每一個詞元級別的概率分數(shù)值,pi表示每一句摘要的評估分數(shù),將在后文從每一個候選摘要輸出的概率分數(shù)入手,對整個候選集的輸出進行約束。
1.2.2 數(shù)據(jù)增強
此前,Gao等[20]在SimCSE中提出了一種僅對原文檔做Dropout的數(shù)據(jù)增強方式來構(gòu)建對比學習的正負樣本,但此方法對于增大正負樣本的距離有一定的局限性。
由于本文在與基線模型相同的數(shù)據(jù)集上微調(diào),因此在進行訓練時需要對數(shù)據(jù)加入噪聲,盡量增大負樣本與正樣本的距離。將候選集從解碼器輸入時,都會在給定原文檔D的情況下,輸入標簽詞元ci來預測下一個標簽詞元。
當候選集數(shù)量足夠多時,那么候選集間的詞元在隨機采樣和beamseach的驅(qū)使下就有著足夠的相異性,但所有候選摘要的語意方向卻趨于一致,因此采用前文所提到的方法1以反語意替換的方式進行數(shù)據(jù)增強,使得文本生成存在2種輸出方式:
其中,c*表示反語意樣本,且按照候選摘要與參考摘要的某種分數(shù)對整個候選集進行排序的情況下,排序越靠后的摘要與參考摘要的分數(shù)差距越大。
將分數(shù)排名越靠后的候選摘要以更大的概率進行反語意文本替換(如圖2所示),從而更加體現(xiàn)出分數(shù)較低的候選摘要作為負樣本出現(xiàn)的作用。且圖中的n表示該摘要的排名,N表示候選集總數(shù),p(n)表示第n個摘要進行反語意替換的概率。
2 損失函數(shù)設計
大多數(shù)Seq2Seq模型都使用模型預測的詞元和標簽詞元來構(gòu)建基于最大似然估計的損失函數(shù)。然而,傳統(tǒng)的訓練方法仍然存在過擬合問題,為了提高模型的泛化性,可以通過生成更廣泛概率分布的候選集來擴展詞元空間。
圖3所示的是整個候選集輸出的概率分布圖,其中紅色輪廓代表某一個時間步的概率值最大的詞元,綠色填充表示該摘要的候選標簽對應的概率值,縱向?qū)嵕€表示損失函數(shù),縱向虛線表示損失函數(shù)(將在后文對和進行介紹)。
將兩兩相異但語意相近的摘要作為標簽輸入模型進行訓練,同時將候選集按照Rouge分數(shù)降序排序,建立摘要間的對比損失函數(shù)來提高模型的泛化性,并建立對于候選摘要的時序信息的遞推損失函數(shù)來保證整個候選集輸出的準確性。
對于某一句文本長度為l的候選摘要C(c1,c2,…,cl),其中ci(0<i≤l)是模型中每一個詞元在全連接層輸出的詞典大小的對應標簽概率值,且對每一個候選摘要的詞元取得概率分數(shù):
2.1 對比損失函數(shù)
在候選集中,取Rouge分數(shù)較大的作為正樣本,較小的作為負樣本構(gòu)建對比損失,第i和j個摘要的概率分布中所對應的候選標簽概率分數(shù)均表示為β(α1,α2,…,αl),于是兩句摘要的對比損失函數(shù)為[21]:
式中:表示第j個候選摘要中所對應的候選標簽概率分數(shù),λij=(j-i)*ε,ε為超參數(shù)。式(2)中僅僅考慮了每一個候選摘要的標簽概率分數(shù),但在原有的模型輸出中,并非所有的預測詞元概率分布和標簽一致。預測的最大概率分數(shù)和標簽分布不一致的詞元,在對比損失函數(shù)中計算正負樣本的距離會有所偏差,因此以方法2的方式在模型預測的概率分數(shù)上也加以約束,即對于候選集C,有γi=argmax(Ci),1≤i≤N,對于每一個候選摘要γ(α1,α2,…,αl)的概率分數(shù)構(gòu)建損失函數(shù)為
則取得整體候選集的對比損失函數(shù):
其中,對于每一個摘要的概率評分函數(shù)有:
式中:q是對摘要長度進行獎懲的超參數(shù);|C|是摘要長度。需要注意的是:在計算摘要間的對比損失時,更在意的是候選摘要間的整體分數(shù)關(guān)系,而沒有在意生成詞元的時序關(guān)系,并對每一個長短不一的候選摘要都給予了固定的懲罰參數(shù)。
2.2 詞元時序遞推函數(shù)
在對候選摘要進行細粒度控制的同時,仍需要將原始參考摘要作為重點,因此保留對于原始參考摘要的基于傳統(tǒng)極大似然估計的損失函數(shù)[22]:
其中:
式中:R(C)表示候選摘要的Rouge分數(shù);η是固定的常數(shù)值,且0<η<1,BRIO中采用的損失函數(shù)為
僅采用式(8)損失函數(shù)面對的問題,在計算候選摘要間損失函數(shù)時以式(5)作為評分函數(shù),單個摘要的分數(shù)僅為每個詞元的概率分數(shù)之和,這樣的計算方式在句內(nèi)缺失時序信息的同時,若相鄰或相近的候選摘要詞元差別過大,則會導致候選摘要之間的錯誤引導而降低模型生成文本的準確性。
在N個已排序摘要中,以1號和2號候選摘要為例,有ROUGE(C1,Cref)>ROUGE(C2,Cref),希望的是在計算排序相近或相鄰摘要的對比損失時,同時滿足和
但h(C)函數(shù)并沒有計算各自候選摘要句內(nèi)的時序信息,在不同摘要間計算對比損失的同時,可能會導致出現(xiàn)不同候選摘要間標簽的錯位引導,尤其是當C1和C2文本內(nèi)容差異較大時。
為了解決此問題,前文中所提到的方法3設計出應用于每個候選摘要句內(nèi)的遞推關(guān)系式,使得每一時間步t的概率分數(shù)都來自于前t-1時刻的所有概率分數(shù)的遞推數(shù)值:
式中:f(x)為單調(diào)函數(shù),且,同時為了保證t時刻的遞推數(shù)值[1,t-1]時間段的適度影響,應滿足,保證f(x)在x>0時為單調(diào)遞增的凸函數(shù)。
通過beamsearch和隨機采樣所生成的候選集文本長度不一,并且在推理過程中時序遞推函數(shù)并不在意當前詞元本身概率分數(shù)的大小,因此在以mini-batch形式對整個摘要進行時序遞推時,不適合如式(5)那種直接加入長度獎懲的超參數(shù)q,而應該在t時刻的預測正確的情況下,鼓勵后續(xù)時刻的正確的遞推數(shù)值。
因此,在句子長為l的摘要中,當不加入長度懲罰項時整體的遞推值,即對于f(x)滿足x >0時,對于每一個時間步t,當時,會對每一個獨立摘要t+1時刻的詞元生成做出鼓勵;當時,會對每一個獨立摘要t+1時刻的詞元生成做出懲罰。
如圖4所示,有區(qū)域S={Ⅰ,Ⅱ,Ⅲ,Ⅳ,K},f1(x)和f2(x)表示不同遞推函數(shù),從圖像面積與時序t的關(guān)系來看,以的值來控制每一時刻的長度獎懲效果。
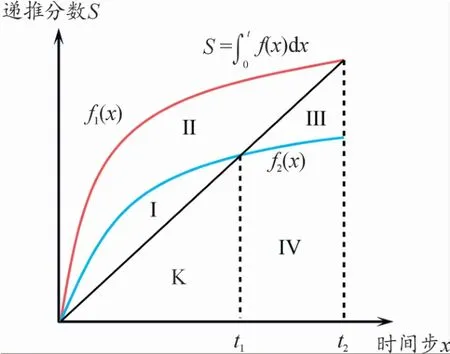
圖4 候選集在時序遞推函數(shù)損失L lp對生成文本的長度獎懲變化示意圖
例如,F(xiàn)(K∪Ⅲ∪Ⅳ,t2)表示無長度獎懲的遞推值;F(Ⅰ∪Ⅱ,t1)表示在當前時刻會對下一時刻的詞元生成帶來獎勵效果;F(K∪Ⅳ,t2)會對下一時刻的詞元生成帶來懲罰效果。
在本次實驗中,對于不同抽象程度的數(shù)據(jù)集應用了2種不同的詞元損失函數(shù)形式,其中對于格式較為規(guī)整的數(shù)據(jù)集采用:
對于文本內(nèi)容較為抽象的數(shù)據(jù)集則采用:
算法1對候選集的正負樣本進行循環(huán)計算。
輸入:[原文檔D,候選集C(C1,C2…CN),候選集對應標簽在字典中的索引index,基礎模型g,超參數(shù)margin:ε]。
輸出:對比損失與時序遞推函數(shù)數(shù)值。
符號說明:

3 實驗細節(jié)
本次實驗采用的顯卡為NVIDIA Tesla A40,且BART-LARGE與PEGASUS的預訓練模型均來自transformers庫。
3.1 數(shù)據(jù)集處理
CNNDM和Xsum都是來自datasets庫的公共英文新聞數(shù)據(jù)集,且Xsum更偏向于抽象的文本極限壓縮摘要。
通過BART-LARGE和PEGASUS模型分別對CNNDM 和Xsum 的訓練集生成候選摘要,以beamwidth=16生成的候選集預存入文本中,數(shù)據(jù)集的數(shù)量如表2所示。
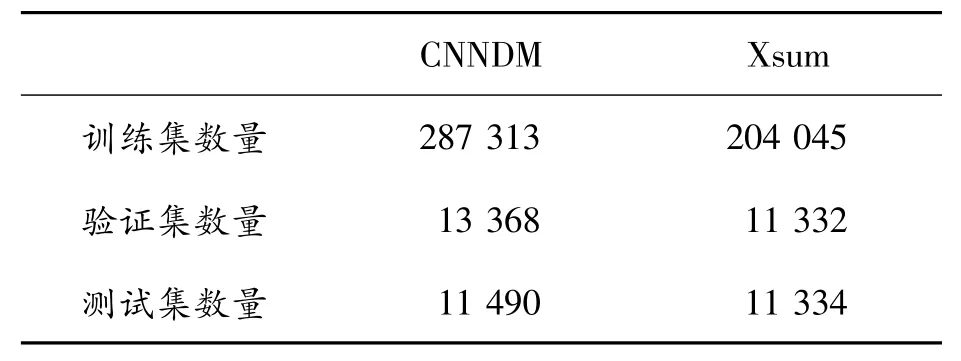
表2 數(shù)據(jù)集詳細數(shù)量
3.2 參數(shù)設置
由于CNNDM和Xsum數(shù)據(jù)集及各自基礎模型的參數(shù)量不同,因此提供如表3中不同的參數(shù)來達到本次實驗的效果。
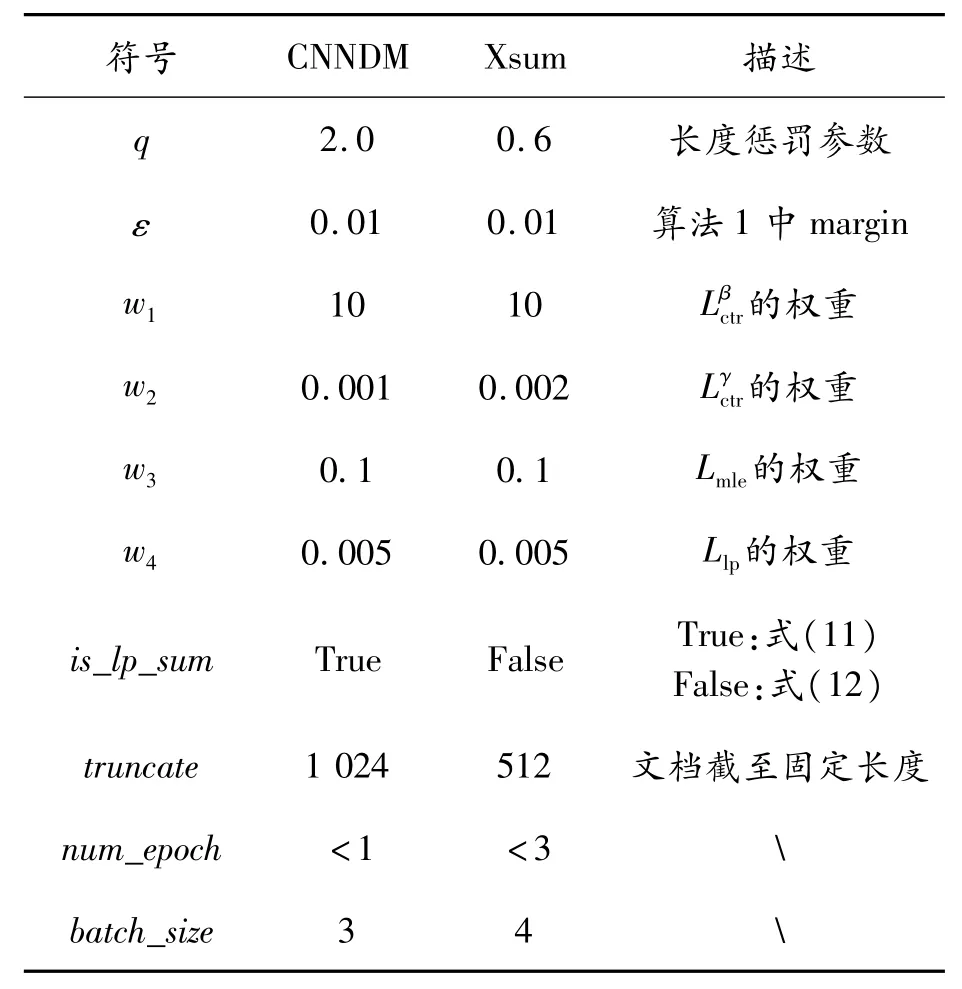
表3 實驗中的各項參數(shù)設置
3.3 實驗結(jié)果
將本文的訓練方式Lctr+Lmle+Llp與BRIO的訓練方式+Lmle進行對比,并從 Rouge、BertScore、余弦相似度3個指標進行評估。
3.3.1 Rouge分數(shù)評估
如表4所示,式(13)的訓練方式在式(8)的基礎上有了明顯提升,同時為了更加體現(xiàn)出模型泛化性能的提升,如表5所示,本文通過不同的beam width在測試集上對生成的文本Rouge分數(shù)進行評估。
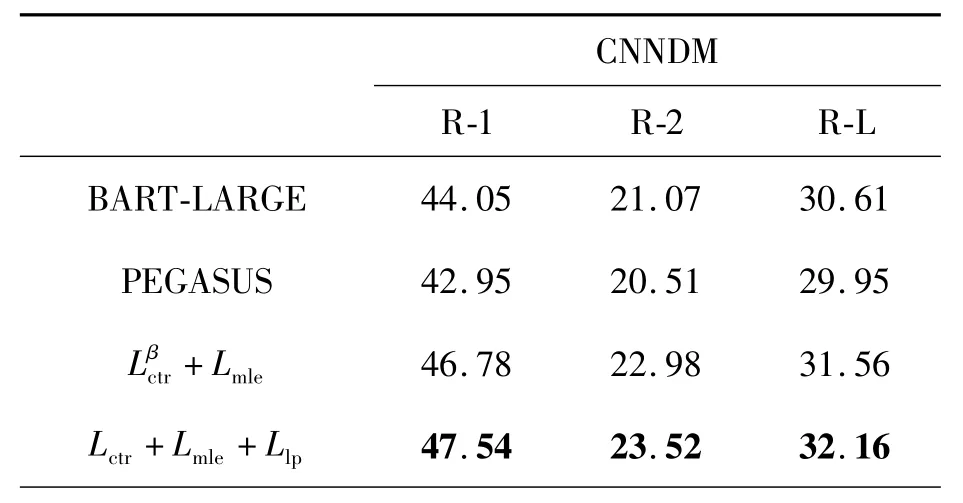
表4 式(13)訓練方式在不同模型與數(shù)據(jù)集上的Rouge分數(shù)
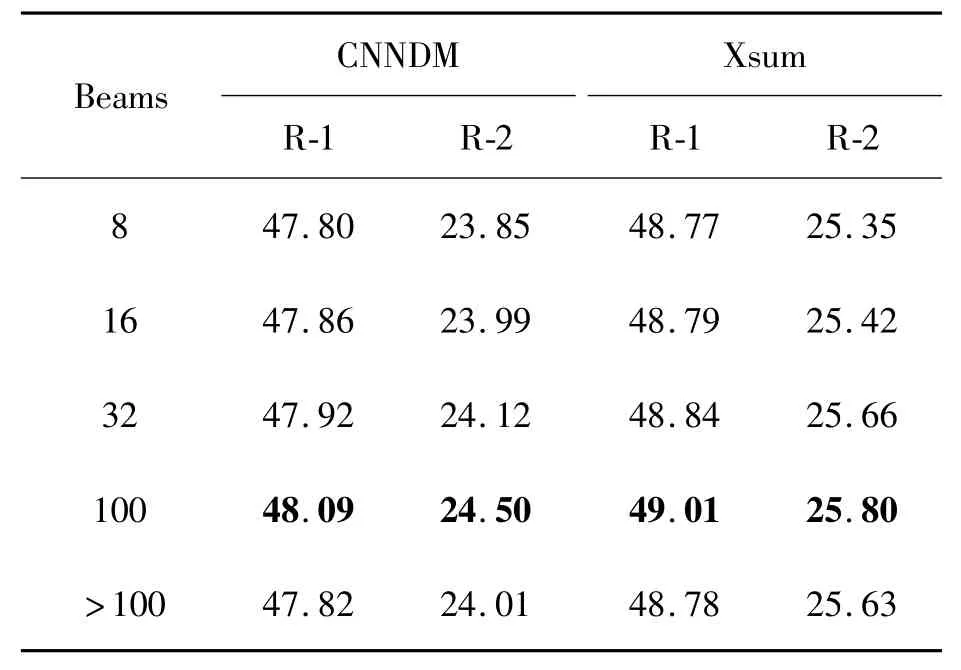
表5 式(13)訓練的模型以不同beamwidth在測試集上的表現(xiàn)
3.3.2 BertScore與余弦相似度
Rouge分數(shù)并不是評價文本生成質(zhì)量的唯一標準,Rouge更在意的是生成的文本與參考文本n-gram的重合度,使用Rouge分數(shù)評價生成文本質(zhì)量的同時,引入BertScore[21]和余弦相似度來評估文本的語意分數(shù)和文本相似度,文本余弦相似度的計算方法為
式中:hyp表示訓練后的模型生成的摘要;Cref表示參考摘要;l表示摘要長度。
如表6所示,體現(xiàn)本文提供的訓練方法不僅僅是在意每一個詞元及其時序上的準確性(COSSIM),還要能在提升泛化性的同時,保證語意的完整性(BertScore)。
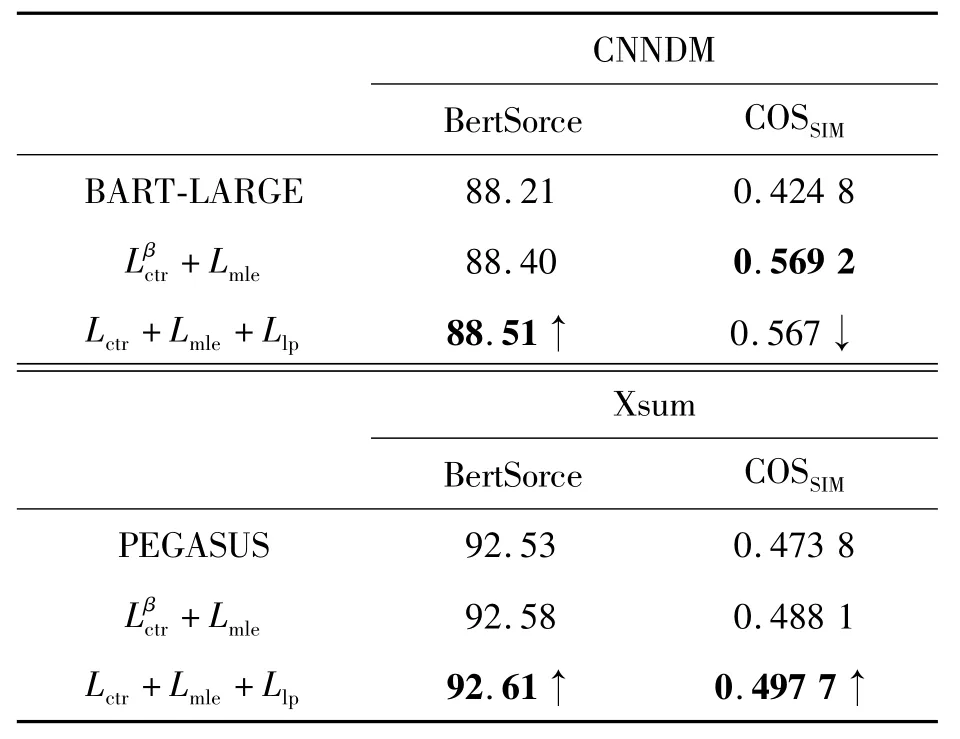
表6 采用BertScore和余弦相似度(COSSIM)對生成文本進行語意和文本相似度的評估
針對式(13)和式(8)的訓練方法,在圖5中給出生成文本與參考摘要之間的余弦相似度[22]和Rouge分數(shù)之間的對比,COS表示文本余弦相似度,OURS表示以式(13)訓練后的模型,對于模型生成的文本T有:當ROUGE(TOURS<TBRIO)在y=x軸的上方時,其TCOS值變化較為平緩,且部分COS(TOURS>TBRIO);當ROUGE(TOURS>TBRIO)在y=x軸的下方時,其TCOS值變化較為明顯,且有不少樣本跨越了1~2個虛線跨度。即本文的訓練方式使得模型在提升泛化性的同時是按照標簽詞元準確性和標簽的時序準確性方向提升Rouge分數(shù)的,且在抽象數(shù)據(jù)集中的摘要關(guān)鍵字提取效果更佳。式(8)和式(13)訓練出的模型生成的文本各1 000條,橫軸和縱軸分別表示從式(13)和式(8)生成的文本Rouge和余弦相似度數(shù)值(數(shù)值范圍均∈(0,1))。
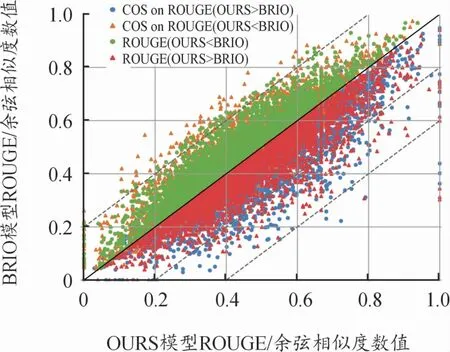
圖5 Rouge和余弦相似度值示意圖
3.4 損失函數(shù)變化分析
本文的主要方法是構(gòu)建不同的對比損失函數(shù),通過對整個候選集的概率分布的約束提高模型的泛化性,因此在式(8)和式(13)的訓練過程中,其損失函數(shù)的變化趨勢能夠反映出模型在訓練前后泛化性上的差異。
圖6是在CNNDM數(shù)據(jù)集采用Lctr+Lmle+Llp情況下訓練過程的損失函數(shù)變化曲線,且訓練的規(guī)模在1個epoch以內(nèi),由于該數(shù)據(jù)集的文本格式相對長且規(guī)整,因此Llp采用式(11)的形式,可以看出相較于抽象的Xsum數(shù)據(jù)集,整體候選摘要的Llp損失函數(shù)有明顯下降的趨勢。

圖6 CNNDM損失函數(shù)曲線
圖7是Xsum采用Lctr+Lmle+Llp情況下訓練損失函數(shù)變化曲線,訓練規(guī)模在3個epoch以內(nèi),因為在Xsum數(shù)據(jù)集中的文本具有較高的抽象程度,因此在選擇Llp損失函數(shù)的形式時選擇式(12)的形式。
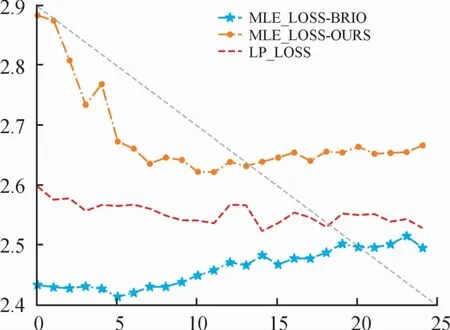
圖7 Xsum損失函數(shù)曲線
在以式(13)的訓練過程中,對比采用式(8)訓練過程中參考摘要的Lmle損失,加入、Llp損失之后,參考摘要的Lmle損失在整個訓練階段明顯增高,但整體候選集的Llp時序損失值下降,即降低模型在訓練過程中對于參考摘要的依賴性,更在意整個候選集的時序準確性,使得模型的泛化能力提升的同時保持與候選標簽之間的相似度。
如表7所示的是以本文訓練方式的模型在部分測試集上所生成的摘要對比,可以看出,加入Llp進行訓練后,有效緩解了文本生成過程中曝光偏差問題。
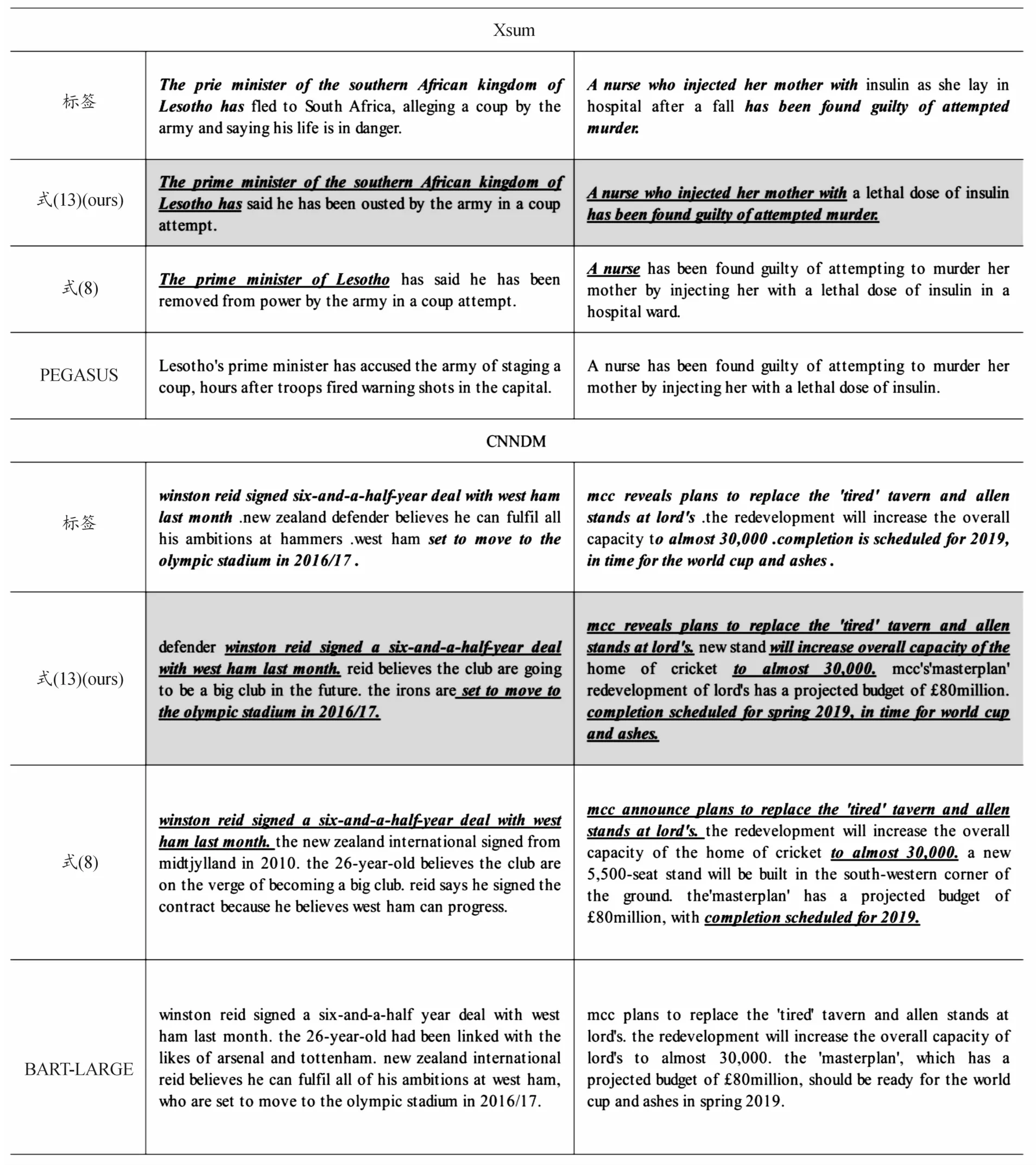
表7 式(8)和式(13)訓練的模型與BART-LARGE/PEGASUS在CNNDM和Xsum測試集上生成的文本效果對比
4 結(jié)論
提出了一種新穎的訓練方法,基本思想是通過構(gòu)建候選集來擴展神經(jīng)網(wǎng)絡輸出的詞元概率分布。針對每個候選摘要,計算其概率分數(shù),充分利用整個候選集語義空間中的概率分布構(gòu)建摘要的正負樣本,并采用對比學習的方式,使模型在相似的語義空間中能夠更好地擬合不同的文本序列,從而提高模型的泛化性能。同時,本文中提出的時序遞推函數(shù)確保候選集在推理過程中每個時間步的預測準確性。
從Rouge、BertScore等多個評估角度進行驗證,證明了該方法在提升模型的泛化性能和準確性方面的有效性,并在對摘要內(nèi)容和標簽準確度要求較高的應用場景中有著積極作用。也為大模型時代的研究者提供了一種有效且可靠的模型訓練方法。
對于此課題后續(xù)的研究,可以選擇非Transformer結(jié)構(gòu)的模型(如GNN和文本卷積網(wǎng)絡等)作為基礎模型,采用本文中的方法進行訓練,并與結(jié)果進行比較。此外,本文中對于候選集的生成方式相對單一,可以嘗試使用不同的模型(如T5、RoBERTa模型等)來生成候選摘要;候選集排序方式也可以不僅僅依賴于Rouge分數(shù),還可以根據(jù)不同的應用場景和數(shù)據(jù)集,嘗試設計不同形式的時序遞推函數(shù),控制整個候選集在推理過程中概率分數(shù)的變化趨勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
