基于異構(gòu)圖表示的中醫(yī)電子病歷分類方法
2024-03-21 02:25:06王楷天程春雷
計算機應用 2024年2期
王楷天,葉 青,2*,程春雷,2
(1.江西中醫(yī)藥大學 計算機學院,南昌 330004;2.江西省中醫(yī)人工智能重點研究室(江西中醫(yī)藥大學),南昌 330004)
0 引言
電子病歷是醫(yī)療資源的一種,隨著醫(yī)療水平不斷提高,它的重要性愈發(fā)明顯。在數(shù)字醫(yī)療高速發(fā)展時代,電子病歷在醫(yī)療信息化中占據(jù)重要地位。2022 年11 月25 日,國家中醫(yī)藥管理局發(fā)布《“十四五”中醫(yī)藥信息化發(fā)展規(guī)劃》,并提出將加強中醫(yī)藥數(shù)據(jù)資源治理作為主要任務之一。醫(yī)學領(lǐng)域的數(shù)據(jù)資源中,最重要的就是電子病歷數(shù)據(jù)。依靠數(shù)字化方式,電子病歷不僅幫助醫(yī)生高效有序地記錄和存儲患者的臨床診療信息,還為醫(yī)院提供足夠的信息載體以歸納總結(jié)患者數(shù)據(jù),從而提高醫(yī)院診療水平。目前,中醫(yī)(Traditional Chinese Medicine,TCM)領(lǐng)域已經(jīng)廣泛推廣使用電子病歷,旨在促進中醫(yī)藥信息化、智能化的發(fā)展,并提高臨床服務水平和醫(yī)療質(zhì)量。
由于西醫(yī)診療階段的數(shù)字化程度較高,同時儀器設(shè)備較先進,因此西醫(yī)的電子病歷結(jié)構(gòu)完整、內(nèi)容豐富,在醫(yī)療領(lǐng)域已成為研究者的重要關(guān)注點,并且西醫(yī)基于電子病歷的輔助決策模型已經(jīng)得到廣泛的發(fā)展和應用,如圍手術(shù)期智能臨床輔助決策系統(tǒng)[1]、慢性疾病個性化輔助決策[2]和多元數(shù)據(jù)融合的臨床輔助決策系統(tǒng)[3]等。但是西醫(yī)的臨床決策系統(tǒng)基于患者身體狀況的理化數(shù)據(jù)支持,無法直接應用于中醫(yī)。
在TCM 領(lǐng)域,Yang 等[4]提出的中醫(yī)證候診斷決策系統(tǒng)基于中醫(yī)知識圖譜預測患者證候,但由于中醫(yī)證候復雜多樣,該研究沒有涉及從證候到患者疾病的過程;Ruan 等[5]的SaGCN(Semantic-aware Graph Convolutional Network)模型通過大規(guī)模非結(jié)構(gòu)化的中文病歷數(shù)據(jù)構(gòu)建訓練預料,挖掘從癥到藥的關(guān)系,但并未深入研究癥與病的聯(lián)系;張玉潔等[6]以糖尿病為例,設(shè)計了一種輔助診療系統(tǒng)實現(xiàn)對糖尿病的病情量化評估、病癥類型判別等功能。雖然該系統(tǒng)對單一疾病的功能已經(jīng)較為全面,但是只針對了糖尿病一種病情,并未拓展延伸。上述工作是利用中醫(yī)電子病歷的先進研究成果,為中醫(yī)提供了優(yōu)秀的輔助診療工具,但由于中醫(yī)電子病歷數(shù)據(jù)難以利用,大部分研究都未完全利用病歷的特征數(shù)據(jù),在患者疾病的輔助決策方面缺少更進一步的研究。中醫(yī)臨床決策階段也需要電子病歷這種寶貴醫(yī)療資源的支持,優(yōu)秀的輔助決策手段不僅讓中醫(yī)診療有直觀的數(shù)據(jù)支持,更能提高中醫(yī)的可信力,并且有研究表明,在推廣輔助決策系統(tǒng)后,病歷的質(zhì)量顯著提高,急診中醫(yī)生的診療速度也得到了提高[7]。
由于中醫(yī)電子病歷剛剛起步,它的數(shù)據(jù)結(jié)構(gòu)差異較大、診療術(shù)語不規(guī)范、癥狀描述復雜多樣等特點導致難以利用。因此,對中醫(yī)電子病歷的研究充滿了挑戰(zhàn)。如果能夠利用好中醫(yī)電子病歷數(shù)據(jù),實現(xiàn)對患者疾病的診斷推薦或預測,將不僅會提升中醫(yī)臨床診療質(zhì)量,還可以推進中醫(yī)診療數(shù)字化進程。在中醫(yī)電子病歷剛剛起步的當下,它的研究對于推動中醫(yī)信息化的發(fā)展有著重要意義。
本文的主要工作如下:
1)使用 LERT(Linguistically-motivated bidirectional Encoder Representation from Transformer)[8]詞嵌入方式獲取句向量以表達病歷整體文本語義特征,將句向量作為節(jié)點的特征向量保存在異構(gòu)圖中彌補異構(gòu)圖結(jié)構(gòu)對病歷整體語義信息的忽視,并通過回傳的方法在訓練過程對該特征向量也進行同步更新。
2)使用 BW25 與點間互信息(Pointwise Mutual Information,PMI)算法構(gòu)造文本異構(gòu)圖的邊,能夠有效緩解中醫(yī)電子病歷數(shù)據(jù)難以利用的問題,克服傳統(tǒng)分詞方法對中醫(yī)術(shù)語錯誤拆分造成的不良影響,成功捕獲并存儲數(shù)據(jù)中隱含的結(jié)構(gòu)特征。
3)驗證了TCM-GCN(TCM-Graph Convolutional Network)模型在中醫(yī)電子病歷數(shù)據(jù)上的特征識別效果與分類能力,并通過消融實驗證明了異構(gòu)圖各部分在特征提取上的有效性。
1 相關(guān)工作
應用中醫(yī)電子病歷數(shù)據(jù)進行臨床輔助決策本質(zhì)上屬于一種文本分類任務。目前,淺層機器學習分類算法有樸素貝葉斯、K 近鄰算法、支持向量機(Support Vector Machine,SVM)、決策樹算法等。中醫(yī)電子病歷中,病歷數(shù)據(jù)由于結(jié)構(gòu)差異大、實體不連續(xù)的特點,用淺層機器學習算法效果較差,且在許多領(lǐng)域已經(jīng)被深度學習與基于神經(jīng)網(wǎng)絡(luò)的分類算法超過[9]。
在深度學習類的文本分類模型中,TextCNN(Text Convolutional Neural Network)[10]因為網(wǎng)絡(luò)結(jié)構(gòu)簡單、占用內(nèi)存小、運算快、準確率高的優(yōu)點成為熱門的神經(jīng)網(wǎng)絡(luò),在短文本分類領(lǐng)域有出色的表現(xiàn),但可解釋性不強;BERT(Bidirectional Encoder Representations for Transformers)[11]的注意力(Attention)機制和靜態(tài)mask 方法由于在文本分類領(lǐng)域有極佳的性能,也被廣泛使用。Kipf 等[12]提出了圖卷積網(wǎng)絡(luò)(Graph Convolution Network,GCN)模型用于數(shù)據(jù)集的分類任務,GCN 是一種能夠直接作用于圖并且利用它的結(jié)構(gòu)信息的卷積神經(jīng)網(wǎng)絡(luò)。Yao 等[13]在GCN 的基礎(chǔ)上提出了TextGCN(Text Graph Convolutional Network)用于文本分類工作,TextGCN 使用將document 通過word 進行表達的思想構(gòu)圖;但TextGCN 的構(gòu)圖過程只利用了結(jié)構(gòu)特征,未能很好地利用文本的語義特征。Lin 等[14]提出了BertGCN,結(jié)合預訓練模型BERT 與圖注意力網(wǎng)絡(luò)(Graph ATtention network,GAT)用于文本分類,采用預測插值、記憶存儲和小學習率等技術(shù),在通用數(shù)據(jù)集上取得了顯著的效果提升。
上述深度學習模型雖然在通用數(shù)據(jù)集上有著出色的表現(xiàn),但因為中醫(yī)電子病歷結(jié)構(gòu)的特殊性,深度學習模型捕捉中醫(yī)電子病歷的有效特征的效果較差。有不少研究者開始針對中醫(yī)醫(yī)案信息難以利用的問題展開研究,李明浩等[15]基于長短期記憶-條件隨機場(Long Short-Term Memory -Conditional Random Field,LSTM-CRF)網(wǎng)絡(luò)提出了癥狀術(shù)語識別方法,通過添加基于癥狀的字符級別的特征,該特征作為字嵌入的擴展為模型進行中醫(yī)術(shù)語識別提供更具體有效的信息。杜琳等[16]提出BERT+Bi-LSTM+Attention 融合模型用于病歷文本抽取與分類的工作,該模型使用BERT 轉(zhuǎn)化分詞后的中醫(yī)文本到詞向量的方式捕捉有效特征,再將詞向量拼接為句向量,最終句向量通過Bi-LSTM 與注意力層完成分類任務。
從目前已有的中醫(yī)醫(yī)案數(shù)據(jù)研究來看,中醫(yī)電子病歷數(shù)據(jù)集難以利用主要有兩方面原因:
1)診療術(shù)語不規(guī)范。中醫(yī)對于癥狀描述缺少統(tǒng)一的度量方法,診斷階段也缺少精密儀器的支持,數(shù)據(jù)質(zhì)量參差不齊。
2)電子病歷表述具有多樣性。中醫(yī)電子病歷的記述有著結(jié)構(gòu)差異大、關(guān)鍵詞多、語義不可分割、實體不連續(xù)等特點,普通的數(shù)據(jù)分析方法效果不佳。
面對中醫(yī)數(shù)據(jù)集問題,先前的工作大都是將病歷進行拆分,從病歷分詞后的字向量與詞向量出發(fā),以更好地發(fā)掘病歷中的隱藏信息。但是這種方式通常忽略了病歷本身的整體語義,并且過于依靠預處理階段分詞的準確率,而中醫(yī)病歷又由于其自身特點,分詞方式需與一般文本不同,所以詞向量與句向量的特征提取方式也較難發(fā)揮應有的作用。
基于上述討論,本文提出一種基于異構(gòu)圖表示的中醫(yī)電子病歷文本分類模型TCM-GCN,用于中醫(yī)輔助決策任務。TCM-GCN 將病歷的關(guān)鍵詞與病歷一同構(gòu)建異構(gòu)圖,在異構(gòu)圖中建立“關(guān)鍵詞-關(guān)鍵詞”“病歷-關(guān)鍵詞”邊以提取中醫(yī)病歷中隱含的語義特征。通過該方法,模型能夠更好地在中醫(yī)電子病歷中提取語義特征,實現(xiàn)中醫(yī)電子病歷分類,改善電子病歷數(shù)據(jù)自身問題對數(shù)據(jù)分析工作的影響。
2 模型設(shè)計
2.1 模型架構(gòu)
TCM-GCN 模型結(jié)構(gòu)如圖1 所示,主要分為4 個部分:數(shù)據(jù)預處理、LERT 特征傳遞、異構(gòu)圖構(gòu)建和模型輸出。
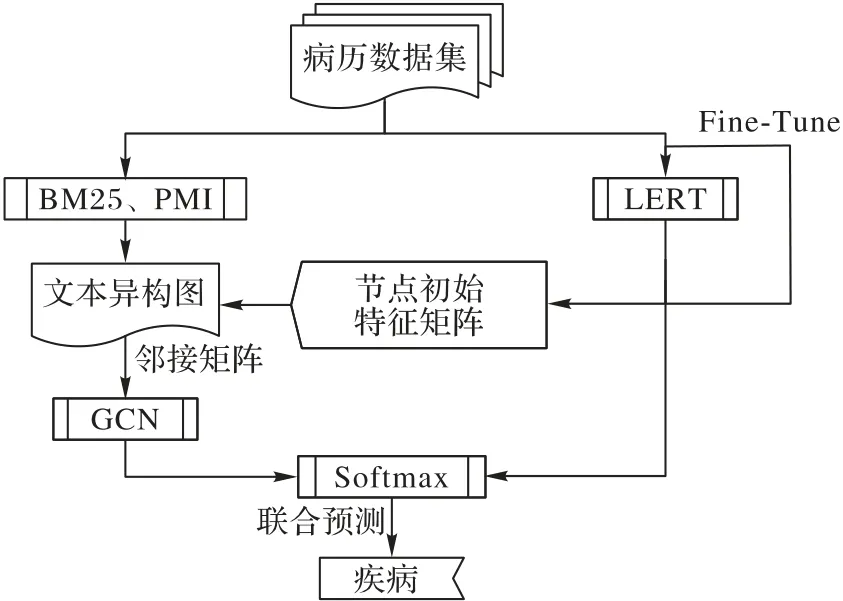
圖1 TCM-GCN模型的結(jié)構(gòu)Fig.1 Structure of TCM-GCN model
1)數(shù)據(jù)預處理。中醫(yī)電子病歷數(shù)據(jù)作為原始數(shù)據(jù)集,提取病歷中的性別、四診與主訴信息并進行數(shù)據(jù)清洗、分詞等預處理操作,患者所患疾病為每一條病歷的標簽。
2)LERT 特征傳遞。針對圖結(jié)構(gòu)數(shù)據(jù)會忽略病歷語義特征的問題,使用LERT 對病歷進行處理,LERT 是哈爾濱工業(yè)大學與科大訊飛一同研發(fā)的多任務預訓練模型,實驗表明相較于BERT 等預訓練模型,LERT 在多個數(shù)據(jù)集上有著更優(yōu)異的性能。LERT 利用讀取的中醫(yī)電子病歷數(shù)據(jù)進行微調(diào)(Fine-tune)操作,能提高預訓練模型在中醫(yī)電子病歷領(lǐng)域的適應度。TCM-GCN 把病歷輸入微調(diào)后LERT 的Token Embedding 層,轉(zhuǎn)換成記錄病歷特征的[CLS]向量,將[CLS]向量保存至文本異構(gòu)圖作為初始特征向量使用,該向量存放于異構(gòu)圖的節(jié)點,保存了病歷整體的語義特征。
3)異構(gòu)圖構(gòu)建。為了改善中醫(yī)電子病歷結(jié)構(gòu)復雜多樣、實體不連續(xù)等問題對特征提取的影響,預處理后的數(shù)據(jù)集使用改進的BM25、PMI 等方法,構(gòu)建病歷信息為數(shù)據(jù)的文本異構(gòu)圖。該異構(gòu)圖將關(guān)鍵詞與病歷一同作為節(jié)點,將病歷拆分成關(guān)鍵詞以加強病歷的結(jié)構(gòu)特征表達,改善了模型對病歷特征進行聚合與抽取的效果。
4)模型輸出。最后在分類輸出層中,利用GCN 層與LERT 層得到的句子表示輸入至全連接層,將二者以一定權(quán)值相加,通過Softmax 函數(shù)生成每個類別的概率值,并根據(jù)概率的最大值分類文本的類別。應用交叉熵作為模型訓練的損失函數(shù),在每一個Epoch 結(jié)束后,不僅進行Adam 優(yōu)化,還會使用LERT 重新對病歷數(shù)據(jù)Token Embedding,更新異構(gòu)圖中病歷節(jié)點的[CLS]特征,該特征會隨模型訓練進行更新以更加契合數(shù)據(jù)。
綜上所述,TCM-GCN 模型使用預處理后的中醫(yī)電子病歷數(shù)據(jù),運用LERT-BM25-PMI 方法構(gòu)造將病歷與關(guān)鍵詞作為節(jié)點的能夠反映病歷間特征關(guān)系的異構(gòu)文本圖,LERT 層與GCN 層聯(lián)合對病歷進行分類。
2.2 病歷文本異構(gòu)圖
GCN 通過圖中節(jié)點間的關(guān)系作為每一個節(jié)點的特征表示,節(jié)點間關(guān)系的權(quán)重反映節(jié)點間不同的關(guān)系。以病歷為數(shù)據(jù)構(gòu)建異構(gòu)圖不僅可以建立病歷和病歷之間的聯(lián)系,也可以獲取到每一個病歷中的非連續(xù)共現(xiàn)信息,豐富文本的特征。
中醫(yī)病歷中包含了中醫(yī)對患者的脈診、舌診、望診、查體和對患者狀態(tài)的詳細觀察所獲得的數(shù)據(jù)。即使電子病歷已經(jīng)按照檢查內(nèi)容分類,但病歷信息還是具有關(guān)鍵詞多、語義不可分割等特點,難以利用大部分深度學習模型。為了解決該問題,TCM-GCN 將病歷中的關(guān)鍵詞與病歷一同作為圖的節(jié)點,通過在病歷節(jié)點與關(guān)鍵詞節(jié)點、關(guān)鍵詞節(jié)點與關(guān)鍵詞節(jié)點構(gòu)建邊的方式,盡可能地利用病歷與關(guān)鍵詞的包含關(guān)系完整表示病歷間的特征信息。比如兩個病歷是否同時含有該關(guān)鍵詞,該關(guān)鍵詞與其他關(guān)鍵詞的同時出現(xiàn)頻率等都會被異構(gòu)圖作為特征關(guān)系保存。
異構(gòu)圖由病歷與關(guān)鍵詞兩個節(jié)點組成。對篩選后的病歷信息運用改進的BM25 算法,評估該關(guān)鍵詞對病歷的重要程度。BM25 是詞頻-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)的優(yōu)化版本,是信息索引領(lǐng)域用來計算query 與文檔相似度得分的經(jīng)典算法,標準的BM25算法計算的每個詞和d的相關(guān)性加權(quán)和Score(Q,d),如式(1)所示:
其中:Q表示一條query;qi表示query 中的單詞;d表示整個文檔;wi表示詞qi的權(quán)重,R(qi,d)表示詞與文檔的相關(guān)性。
中醫(yī)電子病歷數(shù)據(jù)中,由于只要出現(xiàn)在病歷中的詞語都不可忽視,詞頻反而不是很重要。而主訴是患者對自身病情的描述,難以避免對一些癥狀出現(xiàn)反復訴說導致TF 值偏大。所以傳統(tǒng)的TF-IDF 算法在中醫(yī)電子病歷這類文檔長度不一,且高頻詞語特別多的情況效果較差。BM25 算法在TF-IDF 算法上增添了一個常量k,用于限制TF 值的增長極限,使TF 值對打分值的影響存在上限。BM25 考慮到文本長度和平均文本長度對相關(guān)性的影響,加入了超參數(shù)調(diào)節(jié)文本長度因素在打分中所占權(quán)重。
逆文檔頻率如式(2)所示:
其中:N代表語料庫中文本的總數(shù);而N(x)代表語料庫中包含詞x的文本總數(shù)。IDF 值越高,表示該詞語出現(xiàn)的文檔數(shù)越少。
其中:fi為詞qi在文本d中出現(xiàn)的頻率,由于病歷文本長短沒有規(guī)律,故本文采用頻數(shù)代替頻率;qfi為詞qi在語料庫Q中出現(xiàn)的頻數(shù),通常取qfi=1;k1、k2、b都為可調(diào)節(jié)的超參數(shù),通常取k2=0;ld為文本d的長度;lavg為所有文檔的平均長度。詞與文檔相關(guān)性的計算如式(4)所示:
在本實驗中,使用該算法的目的是獲取關(guān)鍵詞與病歷間的關(guān)系,所以只需考慮病歷d中的詞qi在該條病歷d中的打分。故可將公式簡化為:
取最常見的k1=1.2,b=0.75,代入式(5),Score(qi,d)的結(jié)果即為關(guān)鍵詞qi在病歷d中的打分,將該打分作為“病歷-關(guān)鍵詞”邊的權(quán)重加入異構(gòu)圖。
因為病歷都是中醫(yī)臨床診斷中凝練的關(guān)鍵信息,所以本實驗將病歷中分詞得到的所有詞語都視為關(guān)鍵詞作為圖的節(jié)點,不進行篩選。比如“舌質(zhì)/偏/暗青/苔/淡黃/稍/厚”,則會 將“舌質(zhì)”“偏”“暗青”“苔”“淡黃”“稍”“厚”加入圖的節(jié)點,相同詞語不會重復添加。
異構(gòu)圖的方法在面對中醫(yī)電子病歷實體不連續(xù)的特點有著獨特的解決辦法,通常在中醫(yī)中,比如“脈弦”必須視為一個整體,但在普通的分詞方法中,通常會將“脈”與“弦”分離開來,視為兩個詞語。而異構(gòu)圖會對拆開的“脈”“弦”兩個關(guān)鍵詞構(gòu)建邊,關(guān)鍵詞節(jié)點之間使用PMI 法計算“關(guān)鍵詞-關(guān)鍵詞”邊的權(quán)重。該方法考慮到了關(guān)鍵詞之間的全局共現(xiàn)性,即如果“脈”與“弦”總是在一條病歷中同時出現(xiàn),那么它們的邊的值就會很高,特征關(guān)系更加明顯。PMI 算法的使用增強了中醫(yī)電子病歷數(shù)據(jù)結(jié)構(gòu)特征表達,成功改善了由其數(shù)據(jù)特點引發(fā)的數(shù)據(jù)難以利用的困境。
PMI 法公式如下:
其中:p(word1word2)是兩個詞語同時出現(xiàn)在一句話的概率,本文將其視為兩個詞語同時出現(xiàn)在一個病歷中的概率;p(word1)是詞語在語料庫中出現(xiàn)的概率(出現(xiàn)次數(shù)/文檔總詞數(shù))。PMI 越大,兩個詞之間的聯(lián)系越緊密,一般取0 為閾值:當PMI>0,可以認為兩個詞語是相關(guān)的;當PMI=0,兩個詞語是獨立的;當PMI<0,兩個詞語不相關(guān),互斥。取PMI>0 的兩個詞語建立邊,邊的權(quán)重為PMI 的值。
如圖2 所示,異構(gòu)圖的邊由通過BM25 算法獲得的“關(guān)鍵詞-病歷”邊和用PMI 算法篩選得到的“關(guān)鍵詞-關(guān)鍵詞”邊組成,由于是無向圖,故將異構(gòu)圖轉(zhuǎn)換為稀疏軸對稱矩陣保存。
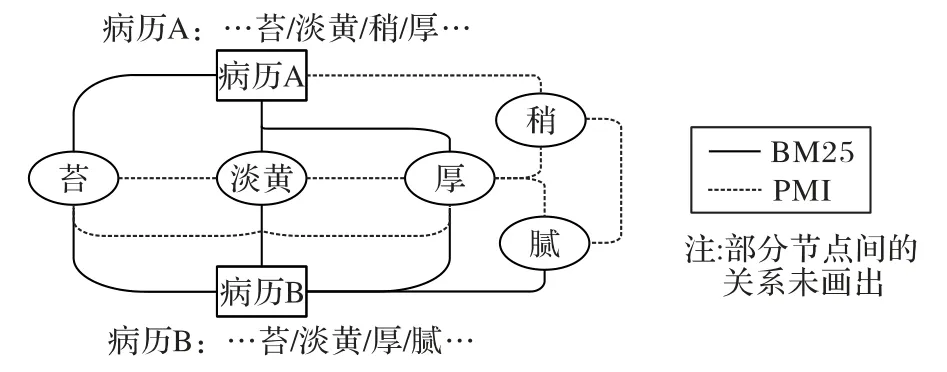
圖2 中醫(yī)電子病歷異構(gòu)圖示例Fig.2 Heterogeneous graph example of TCM electronic medical records
2.3 TCM-GCN
TCM-GCN 的LERT 層由微調(diào)好的LERT 預訓練模型構(gòu)成,如圖3 所示,將預處理后的數(shù)據(jù)集輸入,通過Token Embedding 層獲取每一條病歷緯度為C的特征向量[CLS],數(shù)據(jù)初始節(jié)點特征矩陣為單位矩陣其中n(doc) 為病歷數(shù),n(word)為全部病歷中的關(guān)鍵詞數(shù),將[CLS]與X融合得到XL以供GCN 層使用。
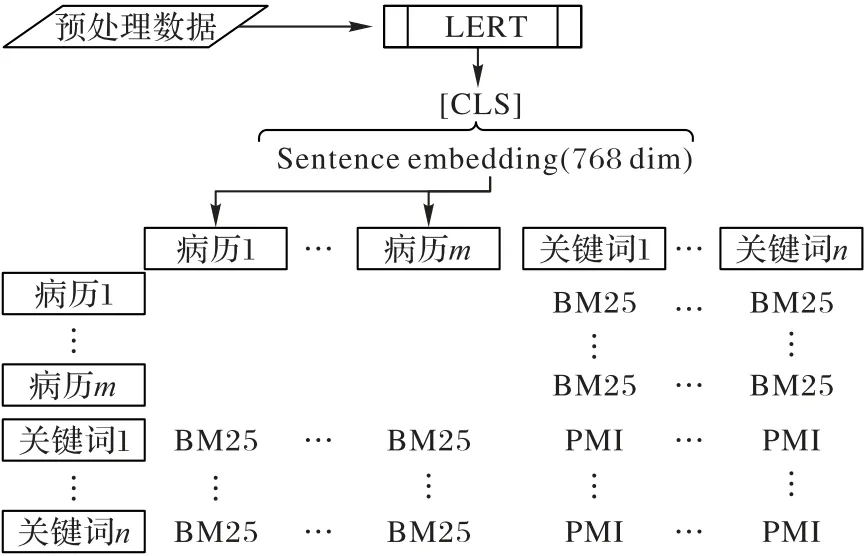
圖3 LERT句嵌入傳遞到異構(gòu)圖Fig.3 LERT sentence embedding transferring to heterogeneous graph
LERT 的輸出矩陣通過Softmax 層得到LERT 層的輸出ZLERT:
GCN 層中,設(shè)定中醫(yī)電子病歷的病歷圖G={V,E},V是節(jié)點,E是邊。LERT 傳遞過來的特征矩陣XL的緯度為N×C,N為病歷節(jié)點與關(guān)鍵詞節(jié)點總數(shù),C為LERT 中[CLS]的緯度,一般為768,節(jié)點間的特征關(guān)系用一個N×N的鄰接矩陣A存儲,在圖G上使用卷積操作的公式為:
為了緩解網(wǎng)絡(luò)非常深時可能導致的梯度爆炸和消失問題,采用Wu 等[17]的renormalization trick 方法,該方法對鄰接矩陣A進行歸一化操作(式(11)),將特征值的絕對值范圍縮小,約束網(wǎng)絡(luò)參數(shù),避免梯度爆炸。
本文的下游任務屬于節(jié)點分類的一種,GCN 的輸出結(jié)果需要使用Softmax 層以完成節(jié)點分類任務,且TCM-GCN 只有1 層隱藏層,由此可得模型中GCN 部分的傳播公式為:
其中:W(0)∈RC×H是輸入層到隱藏層的權(quán)重矩陣,C為LERT傳遞的特征緯度,H為隱藏層特征數(shù)。W(1)∈RH×L是隱藏層到輸出層的權(quán)重矩陣,L為數(shù)據(jù)標簽數(shù)。
最終分類結(jié)果為LERT 與GCN 的聯(lián)合預測:
其中:λ為模型GCN 部分在聯(lián)合預測中所占的權(quán)重,Z為最終輸出分類矩陣。
3 實驗與結(jié)果分析
3.1 數(shù)據(jù)集預處理與評價指標
本文實驗使用江西中醫(yī)藥大學-岐黃國醫(yī)書院脫敏后的中醫(yī)電子病歷數(shù)據(jù)作為原始實驗數(shù)據(jù)集,該數(shù)據(jù)集包含了2014—2021 年江西中醫(yī)藥大學岐黃國醫(yī)書院中醫(yī)接診患者病歷信息。
提取中醫(yī)電子病歷信息中每一條病歷的性別、望診、舌診、脈診、查體、主訴,中醫(yī)診斷信息,出于對數(shù)據(jù)有效性與樣本容量考慮,篩選提取后的病歷信息,去除中醫(yī)臨床診斷階段較重要的主訴信息缺失的病歷。
對性別、望診、脈診、舌診、查體、主訴、癥候信息去標點符號、去缺失值和分詞處理。本文使用哈爾濱工業(yè)大學研發(fā)的LTP(Language Technology Platform)[18]作為分詞工具,并為LTP 詞庫添加中醫(yī)語料,提高對中醫(yī)術(shù)語的識別率與分詞準確率。
以表1 中“舌診:舌質(zhì)偏暗青,苔淡黃稍厚”為例,預處理后的結(jié)果為“舌質(zhì)/偏/暗青/苔/淡黃/稍/厚”。

表1 中醫(yī)電子病歷示例Tab.1 Example of TCM electronic medical records
對數(shù)據(jù)集數(shù)據(jù)預處理篩選過后最終得到5 500 條病歷,其中包含感冒、失眠、濕疹、痹癥、哮喘、便秘、頭痛、痤瘡、月經(jīng)不調(diào)、鼻鼽和虛勞11 種疾病,每種疾病有500 條病歷。隨機打亂后按照8∶1∶1 的比例分為訓練集、驗證集、測試集,最終獲得4 400 條訓練集數(shù)據(jù),550 條驗證集數(shù)據(jù),550 條測試集數(shù)據(jù)用于實驗。
3.2 評價指標
數(shù)據(jù)經(jīng)過隨機打亂后,實驗為樣本不平衡的多分類實驗,故采取加權(quán)平均(weight-averaging)后的精確率P(Precision)、召回率R(Recall)、F1 作為評價指標,n為標簽種類的數(shù)目。表2 為混淆矩陣,其中TP、TN、FP、FN將用于評價指標的計算。

表2 混淆矩陣Tab.2 Confusion matrix
準確率、召回率、單標簽的F1 值公式如下:
數(shù)據(jù)加權(quán)平均F1 值WF1為:
為了更直觀地體現(xiàn)模型效果,展示模型在不同閾值時的性能,加入了受試者工作特征(Receiver Operating Characteristic,ROC)曲線與曲線下面積(Area Under Curve,AUC),AUC 值越大,準確率越高。ROC 曲線是二分類模型經(jīng)典的評價指標,多分類中可以通過one-rest 方法計算真陽率(True Positive Rate,TPR)與假陽率(False Positive Rate,F(xiàn)PR),本文使用加權(quán)平均后的TPR 與FPR 作為ROC 曲線的坐標。
TPR 等于召回率(式(14)),F(xiàn)PR 計算公式為:
為了標準化各模型分類效果,本實驗采用數(shù)據(jù)加權(quán)后的精確率、召回率、F1、AUC 與ROC 曲線作為指標衡量模型的性能。
3.3 參數(shù)設(shè)置
LERT 的Fine-tune 與TCM-GCN 訓練時超參數(shù)設(shè)置如表3所示。
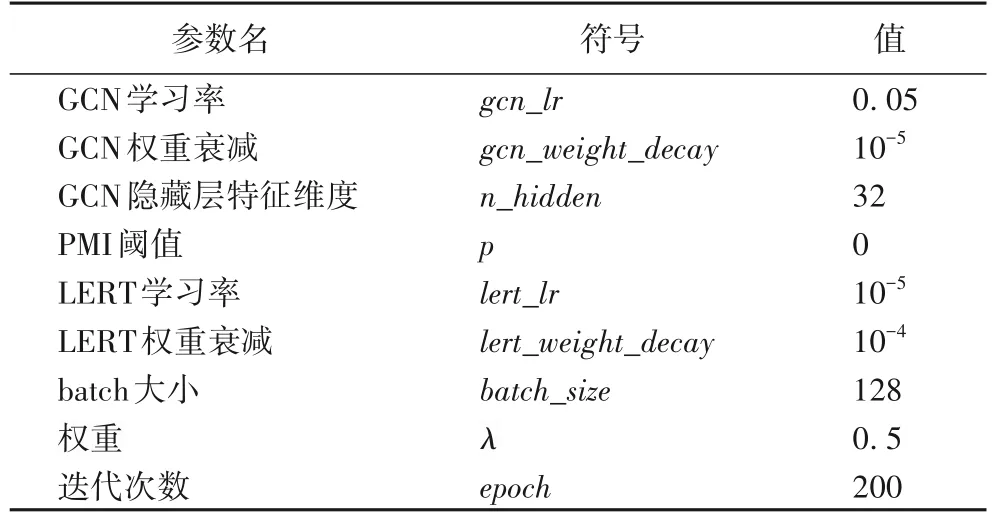
表3 超參數(shù)設(shè)置Tab.3 Super parameter setting
LERT 預訓練模型選擇適合中文文本分類的Chinese-LERT-base 版本,訓練優(yōu)化器選擇自適應矩估計(Adaptive moment estimation,Adam),學習率衰減選用余弦退火(Cosine Annealing)[19]算法,通過余弦函數(shù)降低學習率,可以防止訓練時梯度下降算法可能陷入局部最小值的問題,此時可以通過余弦函數(shù)周期性的特點改變學習率,“跳出”局部最小值的困境。
3.4 對比實驗
為了驗證TCM-GCN 的有效性,將TCM-GCN 與LSTM[20]、Text-GCN[13]、LERT[8]、Text-CNN[10]、Text-RNN[21]、FastText[22]在預處理后的岐黃中醫(yī)數(shù)據(jù)集上進行對比,不同模型實驗中所用訓練集、驗證集與測試集均相同。
TCM-GCN 與其他經(jīng)典文本分類模型的對比結(jié)果如表4所示,最優(yōu)結(jié)果加粗表示,TCM-GCN 的加權(quán)平均準確率為78.46%,加權(quán)平均召回率為78.18%,加權(quán)平均F1 為78.07%,均優(yōu)于其他6 種基線模型,與次優(yōu)的LERT 相比,TCM-GCN 加權(quán)平均后的準確率、召回率、F1 值分別提升了2.24%、2.38%、2.32%。證明了在異構(gòu)圖中,將病歷和關(guān)鍵詞一同作為節(jié)點,并通過連接“病歷-關(guān)鍵詞”和“關(guān)鍵詞-關(guān)鍵詞”的邊來構(gòu)建圖結(jié)構(gòu)的構(gòu)圖方式發(fā)揮重要作用。這種構(gòu)圖方式解決了傳統(tǒng)分詞方法造成的研究難題,即使分詞將中醫(yī)術(shù)語錯誤拆分,也可以通過異構(gòu)圖成功地抽取到病歷中該術(shù)語信息,并且針對電子病歷數(shù)據(jù)長文本且語義不可分割的特點,異構(gòu)圖中采用LERT 轉(zhuǎn)化的句向量作為節(jié)點的特征向量的語義信息傳遞方式,成功使異構(gòu)圖同時保存病歷語義信息與結(jié)構(gòu)信息,提高了模型分類性能。
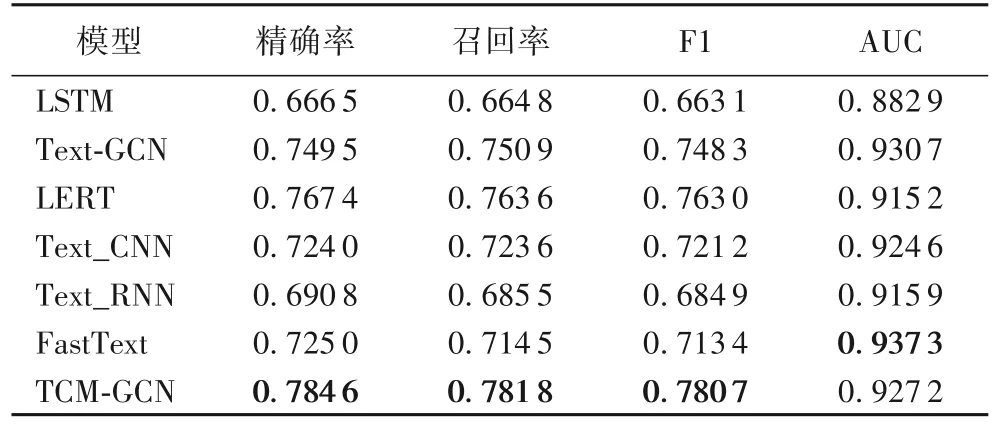
表4 不同模型的結(jié)果對比Tab.4 Result comparison of different models
ROC 曲線如圖4 所示,在較為靠近起點的區(qū)域TCM-GCN一直領(lǐng)先于其他模型,但是在后半部分被FastText、TextGCN等模型超過。雖然TCM-GCN 的ROC 曲線不是一直領(lǐng)先,但是可以看出,它的曲線是靠近左上角,這也說明了最佳臨界點領(lǐng)先其他模型,靈敏度和特異度之和最大。TCM-GCN 的AUC 為0.927 2,略低于TextGCN 的0.930 7 與FastText 模型的0.937 3。由圖4 可知,是因為后半段曲線走勢偏低。考慮到TCM-GCN 為醫(yī)生輔助診斷的實際應用,在ROC 曲線前半段的優(yōu)勢即在假陽性率低的情況下真陽率最高,仍然表明TCM-GCN 在實際應用中優(yōu)于其他模型。
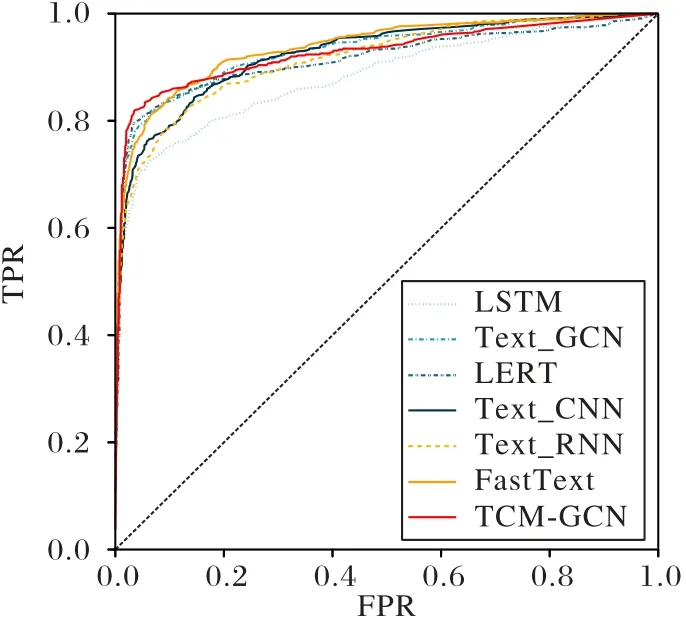
圖4 不同模型的ROC曲線Fig.4 ROC curves of different models
綜上所述,通過對比實驗分析,說明了本文算法的有效性,有效緩解了中醫(yī)電子病歷數(shù)據(jù)難以利用的問題。
3.5 消融實驗
為了進一步體現(xiàn)TCM-GCN 算法與LERT-BW25-PMI 聯(lián)合構(gòu)圖方法的有效性,設(shè)計5 個分組進行消融實驗。實驗1去除掉BM25 算法計算關(guān)鍵詞與病歷的相關(guān)性的部分,替換為簡單的one-hot 方法構(gòu)圖,若病歷包含該關(guān)鍵詞,該“病歷-關(guān)鍵詞”邊的值就為1;實驗2 刪除了PMI 方法構(gòu)造的“關(guān)鍵詞-關(guān)鍵詞”邊;實驗3 則刪除LERT 將embedding 后的句向量回傳給異構(gòu)圖的步驟;實驗4 為對照實驗,將BM25 算法置換為TF-IDF 算法進行實驗,驗證BM25 算法在中醫(yī)電子病歷數(shù)據(jù)集的優(yōu)勢;實驗5 為TCM-GCN 原模型。全部實驗組除了上述提及的操作外,其他模型參數(shù)與訓練過程均未作變動,消融實驗結(jié)果如表5 所示。
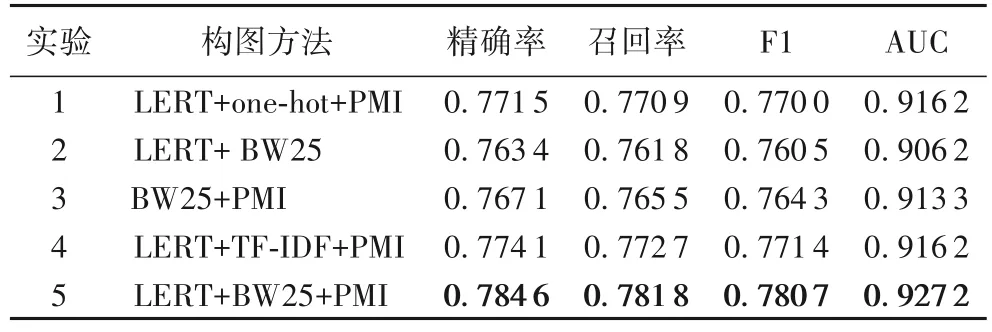
表5 消融實驗結(jié)果Tab.5 Results of ablation experiments
表5 的消融實驗結(jié)果顯示,TCM-GCN 使用的LERT+BW25+PMI 構(gòu)圖方法在加權(quán)平均后的Precision、Recall、F1、AUC 值中均取得了最高值,并且圖5 中ROC 曲線領(lǐng)先其余構(gòu)圖方法,證明了該構(gòu)圖方法的合理性與有效性。根據(jù)實驗組1、2、3、5 的結(jié)果對比分析可以得出LERT、BM25、PMI 的構(gòu)圖方法均對模型性能產(chǎn)生積極影響,刪除任意方法后模型的各評價指標均下降,分別證實了LERT 傳遞病歷句向量、BM25評估關(guān)鍵詞在病歷中的重要程度、PMI 評價詞之間的共現(xiàn)性3 種方法的有效性。第4 組將BW25 置換為TF-IDF 后的實驗中,3 個評價指標也均低于TCM-GCN 原模型,證明異構(gòu)圖構(gòu)圖過程中BW25 算法在通過評估關(guān)鍵詞在病歷中的重要程度方面上的表現(xiàn)優(yōu)于TF-IDF,即頻數(shù)與文本長度是中醫(yī)電子病歷提取特征方法的重要參數(shù)。
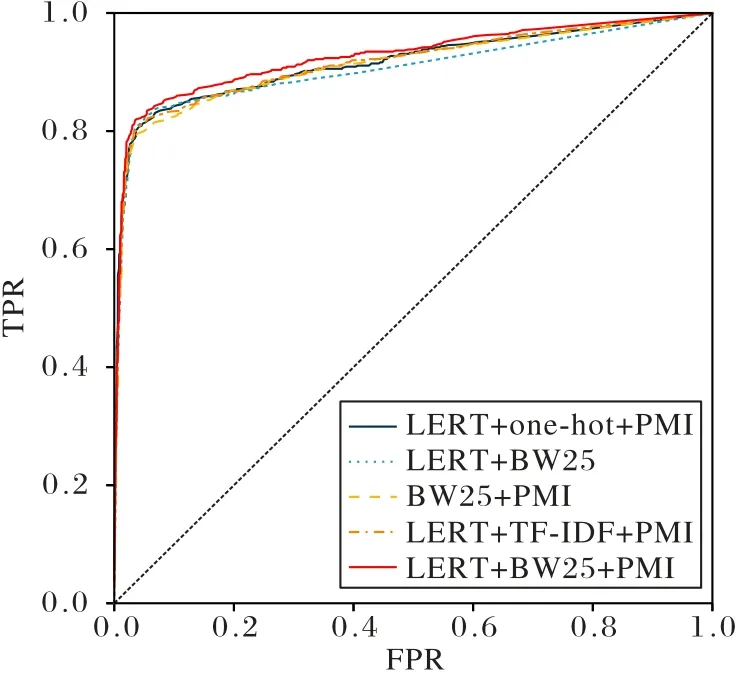
圖5 消融實驗中不同模型的ROC曲線Fig.5 ROC curves of different models in ablation experiments
3.6 實驗總結(jié)
實驗結(jié)果總結(jié)如下:
1)LERT 通過病歷embedding 得到的768 維的句向量融合到圖節(jié)點讓圖的特征更加豐富,該句向量隨訓練步數(shù)進行更新的方式也加強了模型的泛化能力。
2)異構(gòu)圖構(gòu)圖過程中,BM25 算法中對于頻數(shù)的控制與引入文本長度作為相關(guān)性的影響因素,比TF-IDF 更適合中醫(yī)電子病歷數(shù)據(jù)。PMI 對于詞共現(xiàn)的計算,適配中醫(yī)電子數(shù)據(jù)前后文關(guān)聯(lián)性較強的數(shù)據(jù)特征,并且能夠彌補分詞識別切分中醫(yī)術(shù)語準確率較低所帶來的不良影響。
3)LERT-BW25-PMI 所構(gòu)成的文本異構(gòu)圖中節(jié)點-邊-節(jié)點的特征傳遞方式有效表達了中醫(yī)電子病歷復雜多樣的結(jié)構(gòu)關(guān)系,解決了中醫(yī)電子病歷結(jié)構(gòu)復雜多樣等數(shù)據(jù)特點所導致的難以利用問題。
4 結(jié)語
本文提出了一種基于異構(gòu)圖表示的中醫(yī)電子病歷分類模型,利用LERT-BW25-PMI 構(gòu)建的異構(gòu)圖與LERT 和GCN聯(lián)合預測的方法改善了中醫(yī)電子病歷因為其前后文關(guān)聯(lián)性強、語義不可分割、實體不連續(xù)等特點致使數(shù)據(jù)難以利用的問題。在中醫(yī)電子病歷數(shù)據(jù)集上的對比實驗與消融實驗結(jié)果驗證了TCM-GCN 在中醫(yī)電子病歷文本分類任務上的有效性。在未來工作中,對中醫(yī)電子病歷的研究方向?qū)亩嗉膊》诸愔羞M行,挖掘復合疾病患者的中醫(yī)電子病歷數(shù)據(jù)中潛在的關(guān)系,進而更好地應用到輔助中醫(yī)診斷的工作上。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
