面向深度學(xué)習(xí)應(yīng)用的組件式開發(fā)框架的設(shè)計實現(xiàn)
2024-03-21 02:25:00魏宏原
計算機應(yīng)用 2024年2期
劉 祥,華 蓓,林 飛,魏宏原
(中國科學(xué)技術(shù)大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,合肥 230027)
0 引言
近年來,深度學(xué)習(xí)算法在圖像識別[1]、目標(biāo)檢測[2]、目標(biāo)追蹤[3]等領(lǐng)域正逐漸取代傳統(tǒng)算法[4]。隨著深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)模型和通用數(shù)據(jù)處理過程的日趨多樣化,以及各種加速硬件的不斷涌現(xiàn),深度學(xué)習(xí)應(yīng)用的軟件開發(fā)難度在不斷增大。一個深度學(xué)習(xí)應(yīng)用的開發(fā)通常需要整合來自多個開源項目的代碼,并針對底層硬件平臺進行運行效率優(yōu)化,開發(fā)工作量大、周期長,而且圖形處理器(Graphics Processing Unit,GPU)資源利用率通常不高。GPU是深度學(xué)習(xí)的主要算力來源,但目前GPU 運行模型推理任務(wù)的資源利用率很低。例如,實時車牌識別應(yīng)用中分別將YOLO(You Only Look Once)用于車輛檢測、RetinaNet 用于車牌檢測、LPRNet 用于車牌識別這3 個神經(jīng)網(wǎng)絡(luò)模型,在3 840×2 160 分辨率、30 FPS(Frames Per Second)幀率的視頻流輸入下,使用單塊NVIDIA RTX2080Ti 依次推理模型時,GPU 的平均利用率僅為30.7%。
為了讓開發(fā)者從繁重的代碼開發(fā)、移植和調(diào)優(yōu)中解脫出來,近些年出現(xiàn)了一些針對特定平臺的組件式深度學(xué)習(xí)應(yīng)用開發(fā)框架,如MediaPipe[5]、OpenVINO[6]等。MediaPipe 是Google 面向感知應(yīng)用開發(fā)的流水線構(gòu)建套件,允許用戶通過網(wǎng)頁前端或配置文件組合組件庫的算子,構(gòu)造輸入和輸出管道快速設(shè)計應(yīng)用原型。用戶可以自定義算子加入MediaPipe庫,在移動端或桌面端部署應(yīng)用。OpenVINO 是Intel 開發(fā)的一款面向計算機視覺應(yīng)用的開發(fā)和部署工具,除支持深度學(xué)習(xí)模型部署外,還包含圖片處理工具包OpenCV 和視頻處理工具包Media,用于圖像和視頻解碼和推理前后的處理等,在Intel x86 中央處理器(Central Processing Unit,CPU)上的推理速度達到了行業(yè)領(lǐng)先。然而,MediaPipe 在設(shè)計之初主要面向移動端,僅提供有限數(shù)量的TensorFlow 或TensorFlow Lite類的模型,無法為PyTorch 模型和桌面端GPU 提供支持。OpenVino 面向的異構(gòu)加速設(shè)備主要是Intel 的核心顯卡或集成顯卡,并不支持目前服務(wù)器節(jié)點中廣泛使用的NVIDIA GPU。
針對現(xiàn)有深度學(xué)習(xí)應(yīng)用開發(fā)框架存在的問題,本文設(shè)計和實現(xiàn)了一個針對通用GPU 服務(wù)器,兼具靈活性、易用性和高效率的組件式深度學(xué)習(xí)應(yīng)用開發(fā)框架。一方面,對深度學(xué)習(xí)應(yīng)用中常見的通用處理過程提取和管理,降低開發(fā)者的查找和移植成本,提高代碼的可復(fù)用性;另一方面,將神經(jīng)網(wǎng)絡(luò)的推理過程融入組件式開發(fā)方案,允許用戶指定吞吐量和延遲的平衡策略,保證應(yīng)用運行的高效性。本文使用真實交通視頻進行的車牌檢測識別實驗結(jié)果表明,單塊GPU 卡(NVIDIA RTX 2080Ti)在吞吐優(yōu)先的場景下最多可以支持7路視頻輸入,GPU 利用率(執(zhí)行YOLO、RetinaNet 和LPRNet 推理任務(wù))達到82%;在延遲優(yōu)先的場景下平均單幀端到端延遲0.73 s,延遲標(biāo)準差0.57 s,可以滿足實時處理的要求。本文使用框架重新開發(fā)了MediaPipe 上的典型應(yīng)用(單人姿態(tài)估計和多人姿態(tài)估計)并進行實驗對比。在擁有2 個CPU(40個CPU 核)以及4 個GPU(NVIDIA RTX 2080Ti)的服務(wù)器上,單人姿態(tài)估計在延遲優(yōu)先模式下處理幀率提高了0.64 倍,吞吐優(yōu)先模式下處理幀率提高了12.11 倍;多人姿態(tài)估計應(yīng)用處理幀率分別提高了31.61倍和107.70倍。
1 框架的設(shè)計準則及主要設(shè)計問題
1.1 框架的設(shè)計目標(biāo)
框架的設(shè)計目標(biāo)如下。
1)易用性:組件豐富,且便于擴展組件庫和移植新組件,保證應(yīng)用程序編程接口(Application Programming Interface,API)的簡潔。
2)高效性:利用框架開發(fā)的深度學(xué)習(xí)應(yīng)用資源利用高效,并能根據(jù)平臺資源作橫向擴展。
3)靈活性:包括應(yīng)用開發(fā)的靈活性(可通過改變組件或組件參數(shù)實現(xiàn)新的應(yīng)用),以及應(yīng)用部署的靈活性(可提供不同場景的部署方案,并根據(jù)應(yīng)用偏好平衡吞吐量和延遲)。
1.2 框架的設(shè)計準則
框架的設(shè)計準則如下:
1)應(yīng)用是由若干組件通過輸入和輸出相連構(gòu)成的有向無環(huán)圖(Directed Acyclic Graph,DAG),一個組件可以有0個、1 個或多個輸入,也可以有0 個、1 個或多個輸出。
2)有清晰的組件管理規(guī)范,以及完整的組件開發(fā)和移植規(guī)范。
3)面向開發(fā)者提供開發(fā)過程中需要用到的調(diào)試工具、運行日志、校驗工具以及可視化工具。
4)提供C++編程API,以及可選的配置文件開發(fā)方式。
5)支持Python 類型的組件,支持高效的C++數(shù)據(jù)類型和Python 數(shù)據(jù)類型之間的轉(zhuǎn)換,以保證Python 類深度學(xué)習(xí)項目的移植性。
6)使用C++作為主要開發(fā)語言,減少對第三方庫的依賴,保證框架的低開銷。
7)針對模型數(shù)多于GPU 卡的情況[7],保證單個GPU 上能高效運行多個深度學(xué)習(xí)模型。
8)保證應(yīng)用設(shè)計邏輯和框架解耦,應(yīng)用執(zhí)行的高效性由框架保證,框架中的繁瑣算法以及高性能保證的實現(xiàn)對開發(fā)者透明;
9)保證在大多數(shù)高負載情況下對CPU 邏輯核和GPU 的高利用率。
其中:準則1)為基本的組件式設(shè)計原則,準則2)~5)等細分小點旨在減輕用戶開發(fā)過程中的心智負擔(dān),準則6)~9)旨在保證開發(fā)的應(yīng)用能高效利用平臺資源,實現(xiàn)高吞吐或低延遲。
1.3 主要技術(shù)問題及解決方案
在滿足設(shè)計原則的基礎(chǔ)上,在框架設(shè)計實現(xiàn)中需要重點解決以下問題。
1.3.1 組件的劃分問題
基于組件庫構(gòu)建軟件的最大特點之一是層次化程度高。層次化建模的基礎(chǔ)是系統(tǒng)的可分解性,即系統(tǒng)可分解為若干相互作用的子系統(tǒng),子系統(tǒng)本身又可以進一步分解。對每個子系統(tǒng)建立模型,就形成了層次化、模塊化的系統(tǒng)模型[8]。
劃分組件的目的是想通過以下3 點提高應(yīng)用開發(fā)效率:1)增加組件的可重用性,繼承以往項目中的開發(fā)成果;2)降低組件之間的耦合程度,每個組件后期可以單獨修改和調(diào)試;
3)增強功能的內(nèi)聚性和軟件的可配置性和可移植性,使組件具有靈活的結(jié)構(gòu)和清晰的接口。
組件庫的開發(fā)在Linux 下GUN C 語言編譯器(GNU C Compiler,GCC)環(huán)境完成,按照功能分類分級構(gòu)造組件庫的軟件層次體系。如圖1 所示,將組件庫劃分為功能層和實現(xiàn)層兩個層次,其中功能層又按照其包含關(guān)系進行二級分類。
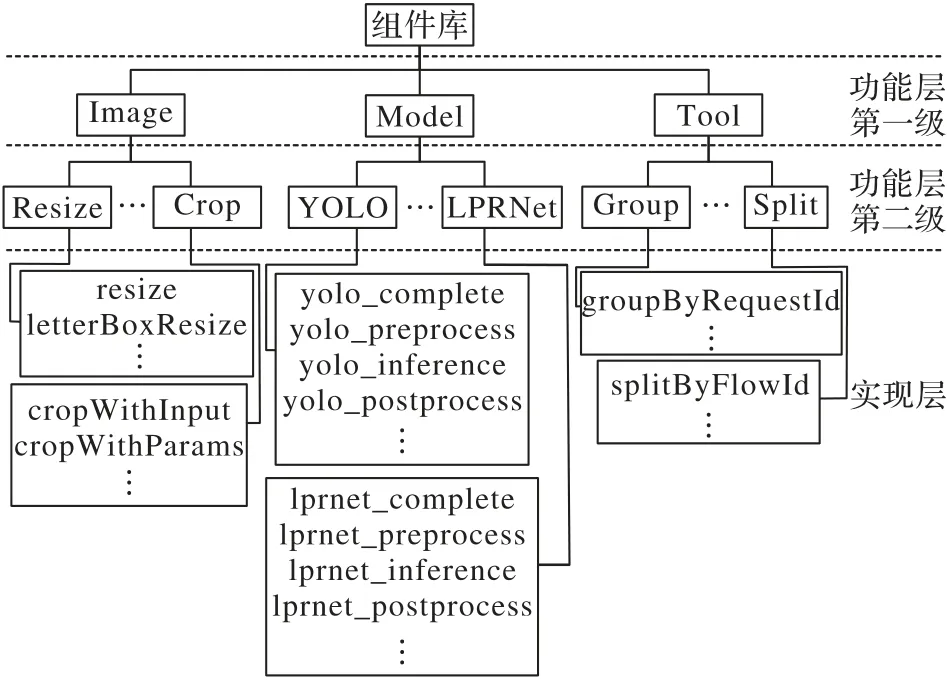
圖1 組件庫的分層組織Fig.1 Hierarchical organization of component library
模型推理是深度學(xué)習(xí)應(yīng)用的最重要組成部分,通常按執(zhí)行流程分為前處理、推理和后處理三個過程。模型推理是一個相對復(fù)雜的任務(wù),包含CPU 處理過程(消耗CPU 資源)、GPU 處理過程(消耗GPU 資源)以及主存和顯存之間的數(shù)據(jù)傳輸過程(消耗外圍組件快速互聯(lián)(Peripheral Component Interconnect express,PCIe)帶寬)。GPU 作為一種批量計算設(shè)備還會涉及任務(wù)組批和分批處理,因此在對模型推理過程進行拆分時,采用更細粒度的拆分方案:不僅將前處理、后處理、分批和組批功能放置到組件庫中,還抽象出了兩個傳輸組 件(簡 稱 trans 組 件):transferToDeviceMemory 和transferToHostMemory,可以在主存和顯存之間傳遞張量(Tensor)或者批量張量(Batch_Tensor)。
如圖2 所示,一個YOLO 模型的推理過程被拆分為包含CPU 處理任務(wù)、GPU 處理任務(wù)和數(shù)據(jù)傳輸任務(wù)的7 個階段。這種拆分方式便于將推理任務(wù)的瓶頸轉(zhuǎn)移到GPU 上,從而實現(xiàn)較高的GPU 利用率。
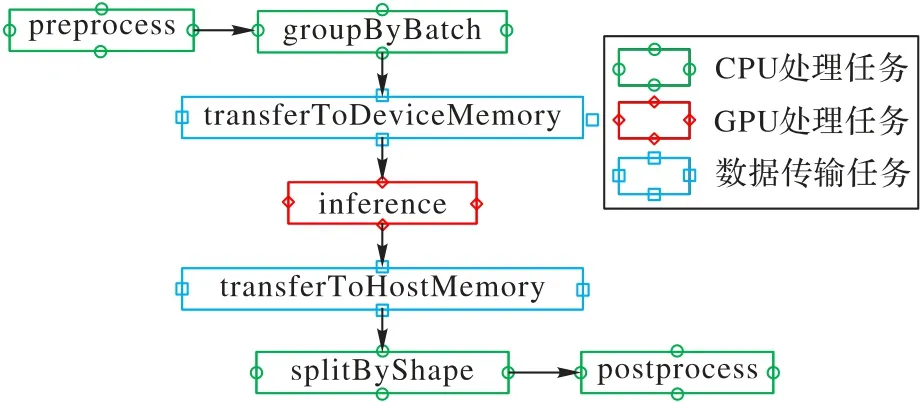
圖2 YOLO模型推理過程的組件拆分Fig.2 Component splitting of YOLO model inference process
較細粒度的組件拆分會增加任務(wù)間通信次數(shù),需要高效設(shè)計底層數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)通信方式。在進行數(shù)據(jù)結(jié)構(gòu)設(shè)計時需要考慮以下幾點因素:
1)良好的數(shù)據(jù)結(jié)構(gòu)可操縱性,以便節(jié)省操作數(shù)據(jù)時的時間復(fù)雜度;
2)較少的存儲空間占用,盡量減少冗余的存儲開銷;
3)統(tǒng)一的管理方案,方便擴展新的數(shù)據(jù)類型;
4)安全性,在意外情況發(fā)生時能根據(jù)持久化的信息進行重建。
框架在存儲高效性方面借助C++的預(yù)編譯指令(pack)和共用聯(lián)合體(union),數(shù)據(jù)結(jié)構(gòu)的元信息控制在20 個字節(jié)以內(nèi):若數(shù)據(jù)本身較小,例如矩形(Rect)數(shù)據(jù)和字符串(String)數(shù)據(jù),數(shù)據(jù)體直接相連描述數(shù)據(jù)基本信息的元數(shù)據(jù);若數(shù)據(jù)本身較大,例如矩形(Mat)數(shù)據(jù)和張量(Tensor)數(shù)據(jù),則將真實的數(shù)據(jù)體單獨存放,元數(shù)據(jù)只存儲一些基本信息和真實數(shù)據(jù)體的指針,方便數(shù)據(jù)的統(tǒng)一管理和擴展。
元數(shù)據(jù)和數(shù)據(jù)體的分離也可以帶來某些細分操作的高效性,例如某些方法可能只需要訪問元數(shù)據(jù),而另一些方法可能只需要拷貝數(shù)據(jù)體。在安全性方面,本框架開放了保存日志的選項,如果開啟數(shù)據(jù)日志,則會以文件形式記錄數(shù)據(jù)流。用戶借助Google 的Tracing 組件能對數(shù)據(jù)的處理時間線做可視化展示,方便進行意外中斷分析以及應(yīng)用快照重建。
組件間通信時僅傳遞數(shù)據(jù)的首地址(在64 位系統(tǒng)中占用8 個字節(jié))。實際測量表明,兩個組件之間的數(shù)據(jù)通信時間(從發(fā)出數(shù)據(jù)到接收到數(shù)據(jù))可以控制在20 μs 以內(nèi)。
1.3.2 GPU共享問題
模型推理主要在GPU 上執(zhí)行,由于通用服務(wù)器中GPU數(shù)一般遠小于模型數(shù),多個模型推理任務(wù)需共用1 個GPU。NVIDIA 從Kepler 架構(gòu)開始提供Hyper-Q[9]硬件特性,結(jié)合多進程服務(wù)(Multi-Process Service,MPS)可允許多個進程同時加載任務(wù)到一個GPU 上,并共享同一個統(tǒng)一的計算設(shè)備架構(gòu)上下文(Compute Unified Device Architecture Context,CUDA Context)。然而文獻[10-14]研究發(fā)現(xiàn),在GPU 上同時執(zhí)行多個任務(wù)會在任務(wù)間產(chǎn)生干擾,導(dǎo)致任務(wù)計算速度減慢,大多數(shù)情況下甚至比串行執(zhí)行還慢。在數(shù)據(jù)中心聯(lián)合調(diào)度訓(xùn)練任務(wù)和推理任務(wù)的PipeSwitch[15]采用在GPU 上一次執(zhí)行一個任務(wù)的方式保證計算速度,同時通過有效的顯存管理、提前綁定計算邏輯、主備worker、模型分塊以及邊加載模型邊計算等方法減少從訓(xùn)練任務(wù)切換到推理任務(wù)的時間。但PipeSwitch 的任務(wù)切換方式存在以下不足:
1)邊加載模型邊計算的方式不能完全隱藏模型載入時間,且模型分塊策略僅針對卷積神經(jīng)網(wǎng)絡(luò)設(shè)計,不能用于Transformer 模型[16];
2)經(jīng)過組批后模型的輸入數(shù)據(jù)往往很大,例如YOLO 模型的單次輸入可達100 MB 以上,但PipeSwitch 并未試圖隱藏數(shù)據(jù)傳入傳出GPU 的時間;
3)主備worker 方式可重疊舊任務(wù)的結(jié)束處理和新任務(wù)的初始化過程,對于模型訓(xùn)練任務(wù)效果很好,但對于模型推理任務(wù)過于笨重。
總之,目前尚缺少一個通用、簡潔、高效的多模型推理任務(wù)共享GPU 的方案。本文框架主要從應(yīng)用層面解決GPU 共享問題,提高GPU 利用率,主要通過以下兩個策略實現(xiàn):
1)增加數(shù)據(jù)批量,在吞吐量要求較高的場景下,輸入較大的批量進行推理;
2)任務(wù)打包,將多個模型推理任務(wù)打包到一個GPU 上,在滿足數(shù)據(jù)依賴和資源依賴的情況下串行執(zhí)行。
其中,策略1)要提高單模型推理時的GPU 利用率,策略2)要使GPU 的空閑時間盡可能短,從而使GPU 利用率長時間保持在較高水平。以上策略在應(yīng)用時會帶來一些問題:
1)批量處理會帶來較高的數(shù)據(jù)輸入、輸出時間;
2)對于實時應(yīng)用而言,串行執(zhí)行模型推理的切換時間不可忽略,包括模型換入/換出時間、模型啟動/結(jié)束時間、計算緩存的換入/換出時間等。
本文框架通過兩個trans 組件分離數(shù)據(jù)傳輸任務(wù)和推理任務(wù),并在功能放置階段將它們分開放置,實現(xiàn)GPU 計算和數(shù)據(jù)傳輸?shù)闹丿B,從而隱藏數(shù)據(jù)傳輸時間;進一步地,將預(yù)先加載模型權(quán)重文件、提前綁定模型計算邏輯、統(tǒng)一管理顯存等策略集成到框架實現(xiàn)和組件開發(fā)規(guī)范中,以減少任務(wù)切換開銷。
1.3.3 流水線部署問題
在采用流水線部署的應(yīng)用中,輸入數(shù)據(jù)以一定的速率進入流水線,理想情形是每個階段的處理速度一致,且剛好最大限度利用了系統(tǒng)資源;然而真實情形通常如圖3 所示,流水線各階段的處理速度并不一致,有些階段的處理速度甚至低于數(shù)據(jù)到達速率,成為系統(tǒng)瓶頸。一旦形成瓶頸,處理負載就會堆積,導(dǎo)致端到端延遲不斷增大。
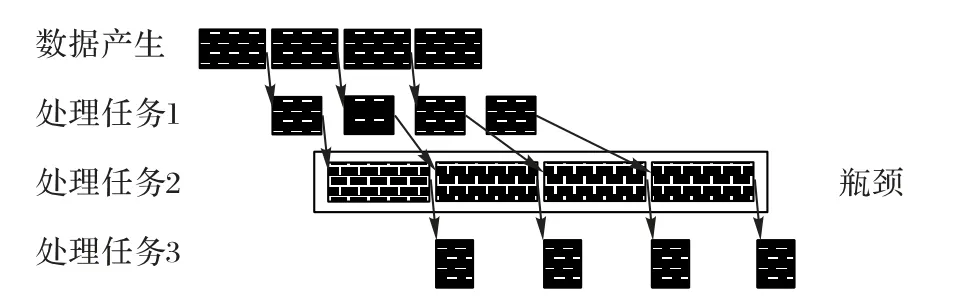
圖3 流水線瓶頸示意圖Fig.3 Schematic diagram of pipeline bottleneck
消除流水線瓶頸的方法是給瓶頸階段分配更多的資源。但流水線各階段的處理速度與各自階段的任務(wù)類型、平臺資源、輸入數(shù)據(jù)量等都有關(guān)系,難以精確刻畫。幸運的是,大多數(shù)深度學(xué)習(xí)應(yīng)用的輸入數(shù)據(jù)來自通信頻率固定的傳感器,它的數(shù)據(jù)速率相對固定,例如智慧交通、智慧校園等場景下的應(yīng)用[17-18]通常以固定幀率的視頻作為輸入數(shù)據(jù)。為此,框架對應(yīng)用進行一段時間的評測,根據(jù)評測結(jié)果指導(dǎo)流水線分配各階段資源,具體分為任務(wù)評測和以任務(wù)實例為單位的資源分配兩個步驟。
任務(wù)評測包括測量任務(wù)對單項數(shù)據(jù)的平均處理時間Ti,以及在不同批量(batch_size)下相對于batch_size=1 時的加速比(僅針對GPU 上的任務(wù))。圖4 為根據(jù)評測結(jié)果繪制的YOLO(yolo_v5m)、RetinaNet 和LPRNet 這3 個模型在不同的batch_size下,推理一張圖片的平均時間相對于batch_size=1時圖片推理時間的加速比。
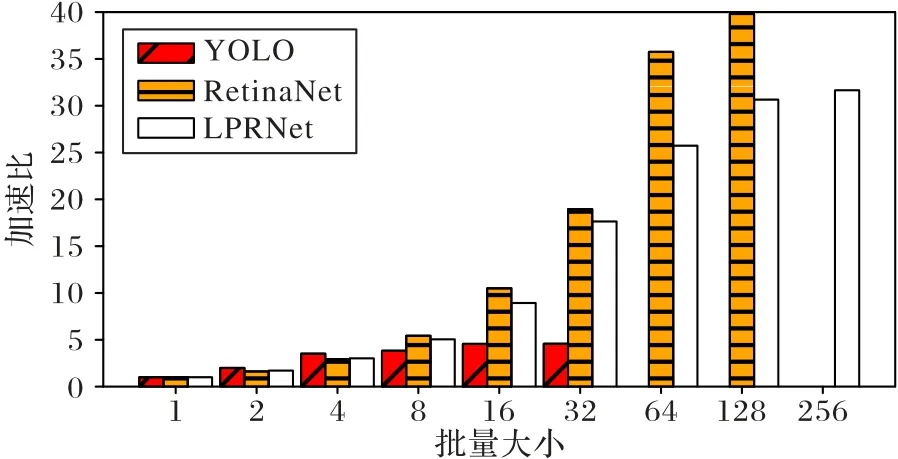
圖4 不同批量大小推理加速比對比Fig.4 Comparison of inference speedup ratios under different batch_sizes
本文框架采用以任務(wù)實例為單位的資源分配方法。當(dāng)一個處理過程不能在時間T內(nèi)完成對數(shù)據(jù)項的處理時,增加該處理過程的運行實例數(shù),通過任務(wù)并行提高該階段的處理能力。具體地,對于CPU 消耗型任務(wù)fi,若評測時得到它的單項數(shù)據(jù)處理時間為Ti,則為它分配的實例數(shù)由式(1)計算:
GPU 消耗型任務(wù)需要先確定批量大小,批量大小的選擇本質(zhì)上是在GPU 吞吐量和應(yīng)用延遲之間進行權(quán)衡。框架將選擇權(quán)交給用戶,引入?yún)?shù)scale?[0,1]表示用戶對吞吐量或延遲的偏好。對于GPU 消耗型任務(wù)fi,其batch_size由式(2)計算:
當(dāng)scale取0 時,batch_size為1,對應(yīng)延遲優(yōu)先的情況;當(dāng)scale取1 時,batch_size最大,對應(yīng)吞吐優(yōu)先的情況;當(dāng)scale取其他值時,表示對吞吐量和延遲的綜合考慮。在評測階段提前測量推理過程fi在某個batch_size下的用時Ti,根據(jù)式(3)確定分配的實例數(shù)量:
由于PCIe 傳輸過程和GPU 推理過程關(guān)聯(lián),因此為PCIe傳輸任務(wù)分配的實例數(shù)與為對應(yīng)的GPU 推理任務(wù)分配的實例數(shù)相等。
1.3.4 CPU利用率問題
以實例為單位的資源分配只考慮到消除流水線瓶頸,帶來的問題是CPU 核使用數(shù)較多,CPU 利用率很低。本文框架通過對任務(wù)實例進行組合放置解決CPU 利用率過低的問題。在對任務(wù)實例進行組合放置時,需要遵循以下3 條原則。首先,由于放入同一組合的任務(wù)實例將被串行執(zhí)行,因此需要并行執(zhí)行的任務(wù)實例必須放入不同的組合中(互斥原則),為此以下兩類任務(wù)實例必須放入不同的組合:①同一任務(wù)的不同實例;②模型推理任務(wù)及其對應(yīng)的數(shù)據(jù)傳輸任務(wù)。其次,為使得CUDA Context 占用最少的顯存,GPU 上的進程數(shù)應(yīng)盡可能少,為此放置在同一個GPU 上的推理任務(wù)所關(guān)聯(lián)的PCIe 任務(wù)應(yīng)放入同一個組合中。最后,在滿足互斥原則的基礎(chǔ)上,最終得到的組合數(shù)越少越好(最小化原則)。
盡管本文將處理功能劃分成3 種資源類型,事實上所有功能都需要消耗CPU 時間,因為PCIe 傳輸和GPU 上的操作都需要CPU 調(diào)度控制。特別是,GPU 任務(wù)會占用與GPU 時間等長的CPU 時間,因此,需按照以下順序進行組合放置:①由于GPU 資源是瓶頸,應(yīng)優(yōu)先放置GPU 任務(wù);②按照互斥原則放置與GPU 任務(wù)綁定的PCIe 任務(wù);③按照互斥原則和最小化原則放置剩余的CPU 任務(wù)。
以上問題可以規(guī)約為一個分步裝箱問題。共有GPU 和CPU 兩種箱子,每個GPU 箱子代表一個GPU,每個CPU 箱子代表一個CPU 核。每個GPU 箱子必須唯一綁定一個CPU 箱子。GPU 箱子中只能放入GPU 任務(wù),CPU 箱子按照可以放入的任務(wù)類型又分為CG、CT 和CC 三種箱子。CG 箱子允許放入GPU 任務(wù)和CPU 任務(wù),CT 箱子允許放入PCIe 任務(wù)和CPU任務(wù),CC 箱子只能放入CPU 任務(wù),CG 和CT 箱子數(shù)相同。箱子的容量是數(shù)據(jù)流中數(shù)據(jù)項到達的時間間隔T,物品是任務(wù)實例f,物品的體積是任務(wù)實例的單項數(shù)據(jù)處理時間。
裝箱問題是組合優(yōu)化問題中常見的NP Hard 問題,框架采用First Fit 貪心算法進行近似求解,即按照順序每次選擇剩余容量最大的箱子進行放置。
2 框架的設(shè)計與實現(xiàn)
如圖5 所示,框架設(shè)置了3 個層次:核心層、組件層和應(yīng)用層。
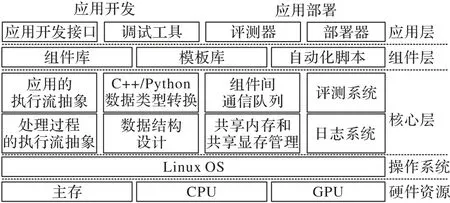
圖5 本文框架的三層架構(gòu)Fig.5 Three-layer architecture of proposed framework
核心層提供應(yīng)用和處理過程的執(zhí)行流抽象、高效的底層數(shù)據(jù)結(jié)構(gòu)和C++/Python 數(shù)據(jù)類型轉(zhuǎn)換、共享內(nèi)存和共享顯存管理、低開銷的組件間通信、評測系統(tǒng)和日志系統(tǒng);組件層提供豐富的組件庫、模板庫以及用于構(gòu)建組件的自動化腳本;應(yīng)用層提供應(yīng)用開發(fā)接口和調(diào)試工具用于應(yīng)用開發(fā)、評測器和部署器用于應(yīng)用部署。
2.1 核心層的設(shè)計實現(xiàn)
核心層由Function、Executor、App、Data、Queue、Memory和Profile 這7 個模塊組成。其中:Function 類提供處理過程對應(yīng)代碼體的靜態(tài)抽象,它的子類PythonFunction 類提供C++/Python 數(shù)據(jù)類型轉(zhuǎn)換;Executor 類提供處理過程的執(zhí)行流抽象,同時負責(zé)管理運行時日志;App 類提供應(yīng)用的執(zhí)行流抽象;Data 類提供高效的底層數(shù)據(jù)結(jié)構(gòu);Queue 類提供低開銷的組件間通信;Memory 模塊提供共享內(nèi)存和共享顯存管理;Profile 類提供應(yīng)用和處理過程的評測。7 個模塊相互協(xié)作,為組件層和應(yīng)用層提供高效服務(wù)。
2.1.1 Function類
Function 類對應(yīng)組件或任務(wù)體。Function 是所有組件的基類,向下派生出PythonFunction 和GpuFucntion 兩個類。PythonFunction 類中提供convertToPython 和convertToCpp 方法,提供常用C++和Python 類型的高效轉(zhuǎn)換。
Function 類是所有執(zhí)行任務(wù)的代碼對應(yīng)的靜態(tài)結(jié)構(gòu)。一個執(zhí)行過程開發(fā)為Function(組件)需要實現(xiàn)以下5 個函數(shù)。
1)void star(t):任務(wù)的初始化函數(shù),在Function 初始化時被調(diào)用一次。
2)bool waitForResource():等待資源函數(shù),在任務(wù)的process 方法被調(diào)用前執(zhí)行,采用非阻塞式結(jié)構(gòu),不滿足依賴時返回false。
3)void process(&data_inputs,&data_outputs):處理函數(shù),輸入?yún)?shù)為輸入數(shù)據(jù)集合和輸出數(shù)據(jù)集合的引用。
4)bool releaseResource():釋放資源函數(shù),在process 方法執(zhí)行后調(diào)用,釋放資源。
5)void finish():結(jié)束函數(shù),在Function 完全執(zhí)行完后調(diào)用。
Function 采用數(shù)據(jù)驅(qū)動的方式執(zhí)行,當(dāng)被當(dāng)前Executor(CPU 核)調(diào)度時,僅當(dāng)輸入數(shù)據(jù)依賴被滿足(指定batch_size的數(shù)據(jù)全部到達)時,它的process 函數(shù)才會被調(diào)用執(zhí)行。
2.1.2 Executor類
Executor 類對應(yīng)執(zhí)行器,所有的應(yīng)用邏輯、任務(wù)實例都要借助Executor 來執(zhí)行。一個Executor 向上承載每個任務(wù)的執(zhí)行邏輯,向下綁定平臺的硬件資源。每個Executor 類對應(yīng)一個任務(wù)實例集合,同時綁定一個CPU 邏輯核,是連接硬件邏輯和軟件邏輯的核心中介。
Executor 類的主要功能如下:
1)管理任務(wù)實例的執(zhí)行,提供非阻塞式、非搶占式的輪詢?nèi)蝿?wù)調(diào)度方案;
2)提供共享內(nèi)存和共享顯存的操作接口,供組件層調(diào)用;
3)管理任務(wù)邏輯在執(zhí)行器的額外工作,包括環(huán)境初始化,向共享內(nèi)存管理器和共享顯存管理器下發(fā)命令,以及在運行期間采集信息和記錄日志等。
Executor 根據(jù)它綁定的任務(wù)實例集合,在初始化階段決定是否需要進行Python 環(huán)境或GPU 運行環(huán)境的初始化。在GPU 運行環(huán)境初始化階段會進行Torch 的初始化,并根據(jù)App 提供的信息引導(dǎo)顯存空間的申請,以及控制顯存空間句柄的發(fā)送和接收。
2.1.3 App類
App 類對應(yīng)應(yīng)用,所有應(yīng)用都需要借助App 執(zhí)行。一個App 向上承載指定的應(yīng)用邏輯和部署邏輯,向下管理若干個Executor,是從應(yīng)用邏輯到硬件執(zhí)行邏輯所要經(jīng)歷的第一關(guān)。
App 類的主要功能如下:
1)在App 運行前檢查上下游組件的輸出輸入數(shù)據(jù)類型是否匹配;
2)管理Executor 的生命周期,在應(yīng)用開始執(zhí)行時統(tǒng)籌所有Executor 的初始化,并啟動所有Executor 執(zhí)行;
3)為Executor 提供一些全局信息,例如哪些Executor 被綁定到同一個GPU 上,或者該Executor 在某個GPU 上的序號。
App 通常在主進程中建立,與每個Executor(對應(yīng)子進程)都有兩個傳遞命令的管道(分別用于接收命令和發(fā)送命令),并負責(zé)管理Executor 的生命周期。
2.1.4 Data類
Data 類對應(yīng)不同任務(wù)間傳輸?shù)臄?shù)據(jù),所有任務(wù)的輸入輸出都以Data 類的對象作為媒介。Data 下維護9 個子類型,分別為存儲圖片的Mat、存儲字符串的String、存儲矩形坐標(biāo)的Rect、存儲網(wǎng)格信息的Mesh、在主存中存儲單個張量的Tensor 和存儲多個張量的Batch_Tensor、在顯存中存儲單個張量的Gpu_Tensor、存儲多個張量的Batch_Gpu_Tensor 以及僅用于數(shù)據(jù)初始化的Unknown 類型。
Data 數(shù)據(jù)類型還包含3 個id,分別為用于標(biāo)識應(yīng)用的app_id、標(biāo)識流的flow_id 和標(biāo)識請求的request_id。一些Data類型中只包含數(shù)據(jù)的元信息(String、Rect、Gpu_Tensor 和Batch_Gpu_Tensor),另有一些Data 類型(Mat、Mesh、Tensor 和Batch_Tensor)會額外申請數(shù)據(jù)體空間,用于存放相對較大的連續(xù)數(shù)據(jù),元信息中附加存放數(shù)據(jù)體首地址。Data 類提供面向指定內(nèi)存地址的構(gòu)造方案,方便開發(fā)者在共享內(nèi)存中創(chuàng)建Data 類型。事實上,由于不同Executor 執(zhí)行流在不同的子進程中,所有的Data 類型都是在共享內(nèi)存中被創(chuàng)建和使用。
Data 類可以擴展子類型,擴展時需要指定新的type 標(biāo)識和3 個id 屬性,其余部分的存儲結(jié)構(gòu)可以按照1.3.1 節(jié)的原則自行設(shè)計。
2.1.5 Queue類
Queue 使用C++泛型實現(xiàn)多生產(chǎn)者多消費者隊列,提供阻塞和非阻塞發(fā)送和接收API。底層基于共享內(nèi)存的環(huán)形隊列實現(xiàn),通過atomic 庫模擬自旋鎖的方式實現(xiàn)進程間互斥。框架使用Queue 傳遞Data 類型的指針,實現(xiàn)組件之間的消息傳遞。
2.1.6 Memory模塊
Memory 模塊首先封裝了一個基本的共享內(nèi)存池類SharedMemoryPool,該類可以提供共享內(nèi)存中相同大小數(shù)據(jù)單元的連續(xù)存儲。在共享內(nèi)存池類的基礎(chǔ)上,Memory 模塊構(gòu)造了共享內(nèi)存管理器smm,smm 包含了9 個固定的共享內(nèi)存池(維持基本的框架功能)和1 個用于自定義的共享內(nèi)存池容器。9 個固定內(nèi)存池為Data、Mat4K、Mat1080P、Mat720P、Mat540P、Tensor10M、Tensor1M、Tensor100K 和Tensor10K 內(nèi)存池,分別用于存儲不同類型或不同大小的數(shù)據(jù),內(nèi)存池的容量大小可以根據(jù)配置文件自行指定。一個自定義的共享內(nèi)存池容器可以根據(jù)需求使用smm 自行創(chuàng)建和刪除共享內(nèi)存池。
Memory 模塊還包含一個共享顯存管理器類gpu_smm,gpu_smm 接管整個GPU 顯存,將整個顯存劃分為數(shù)據(jù)存儲區(qū)、模型區(qū)和計算區(qū)。數(shù)據(jù)存儲區(qū)用于緩存輸入輸出數(shù)據(jù),模型區(qū)用于存儲模型權(quán)重,計算區(qū)用于模型推理時存儲中間數(shù)據(jù)。數(shù)據(jù)存儲區(qū)劃分成多個數(shù)據(jù)存儲單元(block),每次數(shù)據(jù)傳輸時申請一個block,傳輸完后釋放。框架會在PyTorch 插件(針對PyTorch 的Cache 層編寫的插件,提供申請/釋放顯存空間、申請/釋放顯存塊等API)的基礎(chǔ)上提供操縱顯存的C++API,供App 類和Executor 類在操作顯存中使用。相關(guān)的Python API 跟隨PyTorch 插件編譯至PyTorch 庫,供深度學(xué)習(xí)推理組件和trans 組件調(diào)用。
2.1.7 Profile類
Profile 類主要評測應(yīng)用和處理過程,匯總和處理每個Executor 運行過程產(chǎn)生的時間戳信息,產(chǎn)生應(yīng)用運行日志并統(tǒng)計應(yīng)用運行時的資源消耗,為應(yīng)用層部署器的決策提供底層信息參考。
2.2 組件層的設(shè)計實現(xiàn)
組件庫目前共實現(xiàn)了Image、Model、Tool 這3 類共36 個基礎(chǔ)組件,涵蓋實時視頻流的推拉,圖像的變形、裁剪、仿射變換和標(biāo)記,5 個常用深度學(xué)習(xí)模型的前處理、后處理和推理過程,2 個主存和顯存之間傳輸?shù)膖rans 過程,與批處理相關(guān)的組批、分批過程,與流控相關(guān)的多流聚合和多流分離過程,為開發(fā)新組件也提供了豐富的模板和范例。
框架提供groupByRequestId 和SplitByFlowId 兩個與流控相關(guān)的組件,用于多流應(yīng)用中面向相同類型數(shù)據(jù)的多流聚合和其后的多流分離,在聚合和分離的過程中主要使用了Data中攜帶的flow_id 信息。由于多流應(yīng)用中多數(shù)處理過程與流無關(guān),即對于處理任務(wù),只是增加了輸入數(shù)據(jù)流的密度,因此可以在單流輸入數(shù)據(jù)負載較小時,通過擴展應(yīng)用服務(wù)范圍對輸入數(shù)據(jù)源進行橫向擴展,實現(xiàn)對批量計算硬件的充分利用。
2.3 應(yīng)用層的設(shè)計實現(xiàn)
應(yīng)用層提供豐富的組件、簡潔的應(yīng)用開發(fā)和部署API,以及相關(guān)開發(fā)、調(diào)試和部署工具。API 主要分為以下幾類:①構(gòu)建應(yīng)用DAG 的連接類API(connect、connectOneByOne、connectOneToMany、connectManyToOne、connectOneFanMany、connectManyCollectOne);②擴展多實例的expand;③用于打印App 信息的help。
圖6 中,f 表示處理過程(function),q 表示隊列(queue)。圖6 列舉了6 種不同連接關(guān)系的API,在滿足多樣化開發(fā)需求的基礎(chǔ)上,力求簡潔規(guī)范易用,減少開發(fā)者的心智負擔(dān)。在框架的examples 文件夾下實現(xiàn)了6 個經(jīng)典應(yīng)用,涵蓋了所有API 的使用,為開發(fā)者開發(fā)應(yīng)用提供范例和參考。
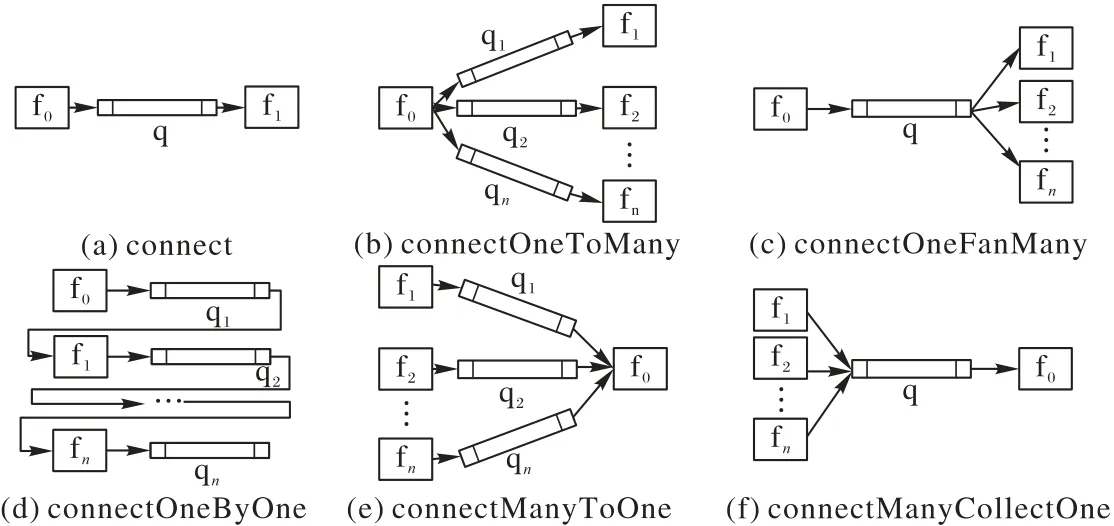
圖6 應(yīng)用開發(fā)API示意圖Fig.6 Schematic diagram of application development API
3 應(yīng)用實例
本章通過一個車牌號識別應(yīng)用的開發(fā)和部署實例說明框架在應(yīng)用開發(fā)和部署過程中的簡潔性、易用性和靈活性表現(xiàn)。
3.1 應(yīng)用描述
車牌檢測識別應(yīng)用以交通路口的高清攝像頭視頻流作為輸入數(shù)據(jù),提取進入檢測區(qū)域的所有車輛的車牌號,繪制在圖片的右上角。圖7 為該應(yīng)用的一個效果,可用于車輛追蹤和車流密度檢測等。

圖7 車牌號識別應(yīng)用效果Fig.7 Rendering of license plate number recognition
3.2 應(yīng)用開發(fā)
實現(xiàn)3.1 節(jié)應(yīng)用需要車輛檢測、車牌位置檢測、車牌號識別等功能。經(jīng)過調(diào)研,最終用YOLO(yolo_v5m)模型作車輛檢測、RetinaNet模型作車牌位置檢測和端到端的LPRNet模型作車牌圖片到車牌號碼字符的轉(zhuǎn)換。在以上3 個模型的基礎(chǔ)上,再結(jié)合一些常規(guī)的圖片處理過程,就能夠構(gòu)造出一個實時車牌號檢測應(yīng)用。圖8為該應(yīng)用構(gòu)建的處理任務(wù)DAG。
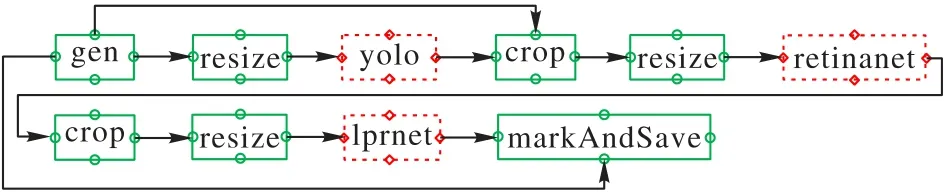
圖8 構(gòu)成車牌號檢測應(yīng)用的DAGFig.8 DAG of license plate number recognition application
根據(jù)處理流程的DAG 及性能要求在組件庫中選取組件。在實際開發(fā)時,可以根據(jù)組件的輸入?yún)?shù)作檢測效果和檢測速度的權(quán)衡。圖9 為使用CPU 進行推理的低速版本,圖10 為在GPU 上進行批量推理的高速版本,批量推理時的批處理大小可以通過參數(shù)指定。

圖9 CPU推理版本的關(guān)鍵代碼Fig.9 Key code for inference version on CPU

圖10 GPU推理版本的關(guān)鍵代碼Fig.10 Key code for inference version on GPU
框架還提供了使用MarkDown 文檔構(gòu)建應(yīng)用的方式。圖11 展示了CPU 推理版本的MarkDown 文檔輸入。
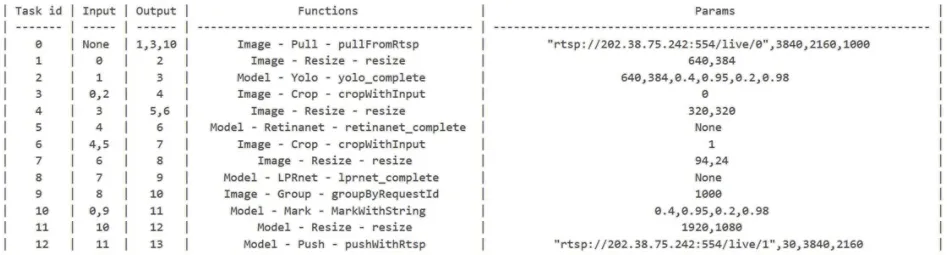
圖11 使用MarkDown方式開發(fā)應(yīng)用Fig.11 Application development using MarkDown
得益于豐富的層次化組件設(shè)計和多種構(gòu)造函數(shù)重載,通過調(diào)整各處理過程的輸入?yún)?shù)可進行例如檢測范圍的改變、標(biāo)識位置和顏色的更新、輸出視頻流的分辨率大小調(diào)整等。如圖12 所示,改變一些組件和參數(shù),就能得到一個車輛統(tǒng)計應(yīng)用。
框架提供標(biāo)準化的流程和豐富的模板范例用于新組件的開發(fā)和移植。例如,移植一個YOLO 模型至組件庫遵循以下流程:
1)下載ultralytics/yolov5 項目至本地,并下載模型權(quán)重文件(本例使用yolo_v5m.pt)至本地文件夾;
2)在根目錄文件夾中新建yolo.py 文件,提取preprocess和postprocess 過程接口,封裝于yolo 類;
3)運行框架提供的create_Python_GPU_Function.py 文件,在命令行參數(shù)中指定yolo 項目的根目錄、yolo.py 文件路徑和yolo_v5m.pt 權(quán)重文件路徑;
4)框架根據(jù)模板生成yolo_preprocess.h/.cpp、yolo_inference.h/.cpp、yolo_postprocess.h/.cpp 和新的yolo.py文件,并編譯入基礎(chǔ)組件庫。
3.3 應(yīng)用部署
在定義了應(yīng)用的處理邏輯后,需要進行應(yīng)用的部署。本框架提供3 種部署方案:純手動部署、半自動部署和全自動部署。不同部署方案適用的場景不同,對應(yīng)著對開發(fā)者不同的開放自由度。
3.3.1 純手動部署
框架提供expand API 用于擴展某個階段或多個連續(xù)階段的實例數(shù),提供cpus_map 和gpus_map 兩個參數(shù)指示任務(wù)實例所放置的CPU 核或GPU。使用此種方式部署車牌識別應(yīng)用的關(guān)鍵代碼如圖13 所示。

圖13 純手動部署關(guān)鍵代碼Fig.13 Key code for pure manual deployment application
純手動部署方案提供了直接面向硬件進行資源分配和功能放置的底層接口,是半自動部署和全自動部署方案的基礎(chǔ),給部署人員提供了最高的自由度。
3.3.2 半自動部署
半自動部署是指部署人員可以結(jié)合框架提供的工具進行自動化的評測,評測器根據(jù)平臺硬件環(huán)境和運行環(huán)境給出流水線各階段的實例分配數(shù)及功能放置方案,部署人員可以直接使用此方案或在此方案的基礎(chǔ)上進行調(diào)整。圖14 為評測器統(tǒng)計的各階段消耗的CPU 時間。
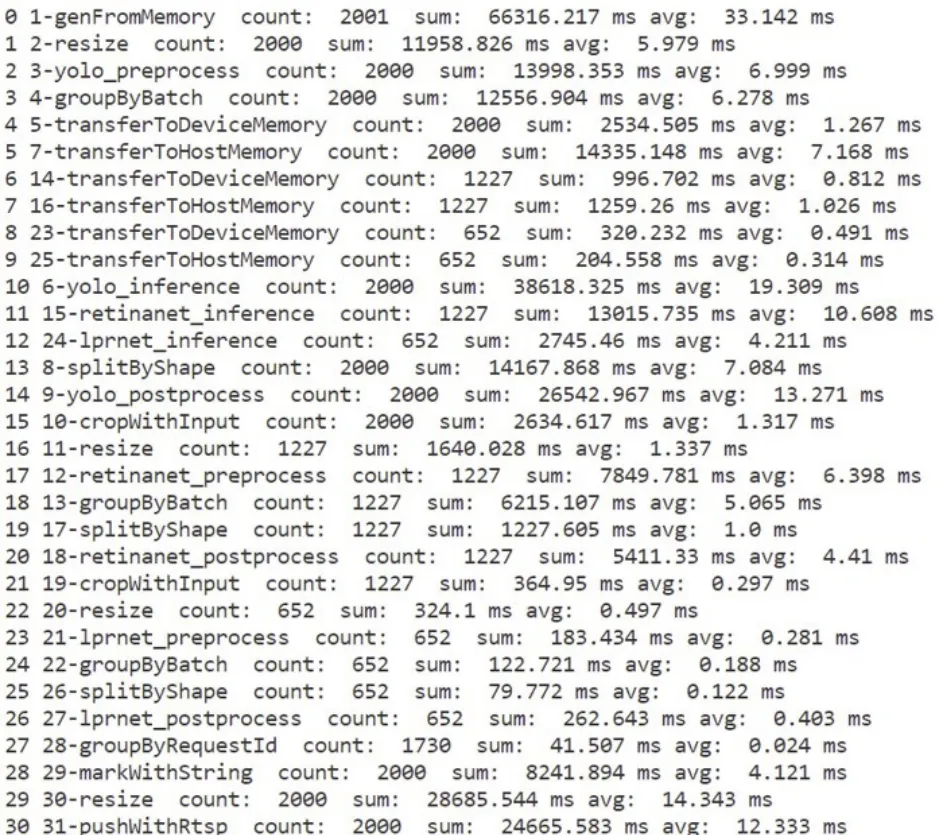
圖14 各階段耗時統(tǒng)計Fig.14 Time consumption statistics of each stage
半自動化部署要求部署人員對軟件執(zhí)行情況和服務(wù)器硬件資源有基本認知和了解,可用于專業(yè)人員的定制化部署。
3.3.3 全自動部署
全自動部署直接調(diào)用部署器的deploy 函數(shù),部署器調(diào)用評測器,根據(jù)評測結(jié)果和自動化算法進行資源分配和實例放置,其函數(shù)原型為:
void deployer::deploy(float scale);
此種部署方式借助1.3.3 節(jié)和1.3.4 節(jié)中提及的資源分配和實例放置方式,只需指定scale值就能將部署方案編譯進應(yīng)用的可執(zhí)行文件中,不需要部署人員額外干預(yù),是應(yīng)用開發(fā)者的一鍵式部署方案。
3.4 擴展到多路輸入(多流)
上述應(yīng)用可以通過使用 groupByRequestId 和splitByFlowId 組件改變應(yīng)用的DAG 邏輯,將應(yīng)用擴展到多路輸入。圖15 展示了一個四路視頻輸入的實時車牌號檢測應(yīng)用的處理流程DAG。
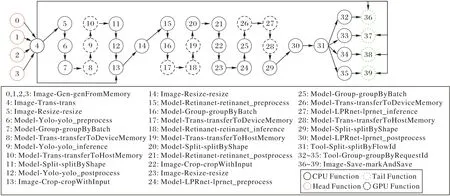
圖15 四路視頻輸入的車牌號檢測應(yīng)用DAGFig.15 DAG of license plate number recognition application with four-way video input
4 實驗驗證
4.1 實驗環(huán)境
實驗在一臺AMAX Super Server X11DPG-QT 上運行,包括2 片Intel Xeon Gold6230 CPU(每個CPU 包含20 個邏 輯核)、4 塊NVIDIA GeForce RTX 2080Ti GPU、376 GB 內(nèi)存和PCI-E 3.0 X16。操作系統(tǒng)為Ubuntu16.04,編程語言為gcc-6.5.0,Python3.8.0,采用深度學(xué)習(xí)框架PyTorch1.7.0,軟件庫OpenCV4.5.4。
4.2 吞吐量和延遲
4.2.1 實驗?zāi)康?/p>
實驗旨在驗證框架在深度學(xué)習(xí)應(yīng)用開發(fā)時的有效性。首先,通過一段時間的運行,驗證應(yīng)用運行時的穩(wěn)定性(不會產(chǎn)生數(shù)據(jù)項堆積);其次,通過對CPU 利用率和GPU 利用率等指標(biāo)的測量驗證框架對平臺資源的利用效果。最后,通過觀察scale值對資源利用率以及應(yīng)用延遲的影響,驗證scale值對應(yīng)用吞吐/硬件延遲偏好的調(diào)節(jié)效果。
4.2.2 應(yīng)用描述
本實驗選用3.1 節(jié)中的車牌識別應(yīng)用進行框架開發(fā)有效性的驗證。車牌號識別應(yīng)用使用支持多流的GPU 推理版本,采用全自動部署方式,scale值設(shè)置為0、0.5 和1。應(yīng)用的輸入為四路分辨率為4K(3 840×2 160)、幀率為30 fps 的視頻流,采用實時流傳輸協(xié)議(Real Time Streaming Protocol,RTSP)格式從流服務(wù)器拉取;輸出為四路1080P(1 920×1 080)、幀率為30 fps 的視頻流,實時推流到流媒體服務(wù)器。數(shù)據(jù)源來自手機拍攝的交通路口視頻(https://gitee.com/blazarx/ traffic_video_dataset)。
4.2.3 實驗結(jié)果
在應(yīng)用運行過程中統(tǒng)計所支持的最大路數(shù)、資源使用量、資源利用率、平均單幀延遲和延遲標(biāo)準差,實驗結(jié)果如表1 所示。
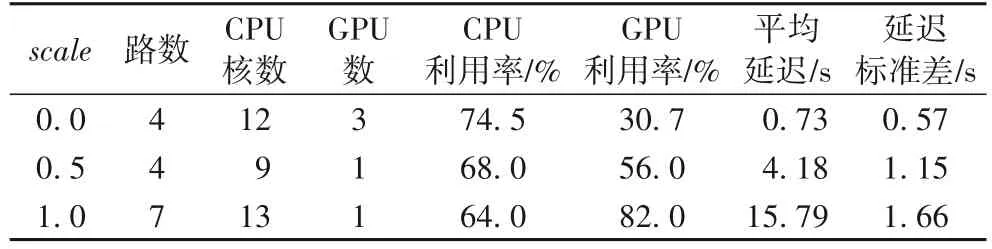
表1 不同scale下的吞吐量和延遲Tab.1 Throughput and latency under different scale
在吞吐優(yōu)先模式(scale=1)下,單塊GPU 卡最多可支持七路視頻;在延遲優(yōu)先模式(scale=0)下,可得到0.73 s 的應(yīng)用延遲,能夠滿足此應(yīng)用的實時性要求;在吞吐和延遲的均衡模式(scale=0.5)下,單塊GPU 卡最多支持四路視頻,得到1.15 s 的應(yīng)用延遲,是吞吐量和延遲綜合考慮的結(jié)果。CPU單核利用率在三種模式下平均為68.8%,GPU 利用率在吞吐優(yōu)先模式下可達到82%。
實驗結(jié)果表明,車牌識別應(yīng)用能在快捷開發(fā)和全自動部署模式下正確平穩(wěn)運行,能根據(jù)用戶意愿在不增加開發(fā)負擔(dān)的前提下,對硬件的使用作橫向擴展(CPU 核和GPU),在吞吐優(yōu)先模式下能獲得較高的GPU 利用率,在延遲優(yōu)先模式下能獲得較低的應(yīng)用延遲,并且在三種模式下都能得到較高的CPU 利用率。
4.3 與MediaPipe的開發(fā)和性能對比測試
4.3.1 實驗?zāi)康?/p>
本實驗旨在通過與MediaPipe(針對移動端需求設(shè)計且被廣泛使用的深度學(xué)習(xí)應(yīng)用構(gòu)建框架)在開發(fā)成本和運行效率上的對比,驗證框架針對CPU-GPU 異構(gòu)服務(wù)器進行深度學(xué)習(xí)應(yīng)用開發(fā)時的獨特優(yōu)勢。其中,開發(fā)成本可用代碼行數(shù)來衡量,實時視頻流應(yīng)用的運行效率使用運行時能夠達到的最大幀率衡量。
4.3.2 框架和應(yīng)用描述
本文選用MediaPipe 支持的經(jīng)典應(yīng)用,基于BlazePose[19]的單人姿態(tài)估計以及與YOLO(yolo_v5m)相結(jié)合的多人姿態(tài)估計。應(yīng)用在Python 環(huán)境下采用MediaPipe 提供的Python API 開發(fā),其中,mediapipe.solutions.pose.Pose 函數(shù)參數(shù)MODEL_COMPLEXITY=1(中等復(fù)雜度模型)。作為對比方案,選取 BlazePose 的 PyTorch 版(https://github.com/WangChyanhassth-2say/BlazePose_torch)的開源項目作為原項目,進行組件開發(fā)和移植,其余組件選用組件庫中已有方案,選用最細粒度的組件劃分方式。
人體姿態(tài)估計應(yīng)用將每幀視頻中人體和手部共33 個關(guān)鍵點標(biāo)識出來并連成骨架,可用于人員數(shù)量統(tǒng)計、人體動作捕捉、手勢識別等諸多應(yīng)用。圖16 是多人姿態(tài)估計應(yīng)用的其中一個輸出幀。

圖16 多人姿態(tài)估計應(yīng)用效果Fig.16 Effect of multi-person pose estimation
應(yīng)用的輸入和輸出為分辨率為720P(1 280×720)、幀率為23 fps 的視頻流。數(shù)據(jù)源來自網(wǎng)絡(luò)上真實舞蹈大賽視頻(https://www.youtube.com/watch?v=pObHe2A8ID4&ab_channel=TranslationSIT)。
4.3.3 實驗結(jié)果
實驗比較應(yīng)用的開發(fā)成本(代碼行數(shù))和執(zhí)行效率(最高支持的處理幀率),實驗結(jié)果如表2 所示。

表2 與MediaPipe的開發(fā)成本和運行效率比較Tab.2 Comparison with MediaPipe on development cost and operating efficiency
在開發(fā)成本方面,使用本框架開發(fā)的應(yīng)用代碼行數(shù)(C++API)與使用MediaPipe 開發(fā)的應(yīng)用代碼行數(shù)(Python API)相近。在運行效率方面,單人姿態(tài)估計應(yīng)用在延遲優(yōu)先模式下,相較于MediaPipe 獲得0.64 倍的幀率提升,吞吐優(yōu)先模式下獲得12.11 倍的幀率提升;多人姿態(tài)估計應(yīng)用中分別獲得31.61 倍和107.70 倍的幀率提升。
4.4 實驗總結(jié)
在4.2 節(jié)中,通過對車牌號檢測應(yīng)用在不同scale值下的應(yīng)用延遲、CPU-GPU 資源占用量及資源利用率等指標(biāo)的評測,驗證了框架開發(fā)深度學(xué)習(xí)應(yīng)用的有效性,展示了框架在各個關(guān)鍵問題,如流水線部署問題、GPU 共享問題和資源利用率問題上的解決表現(xiàn)。4.3 節(jié)將框架和MediaPipe 在開發(fā)成本和運行性能進行對比,說明了框架在CPU-GPU 異構(gòu)的服務(wù)器平臺下應(yīng)用運行性能優(yōu)勢。綜合兩個實驗結(jié)果可得,該框架能夠作為CPU-GPU 異構(gòu)服務(wù)器上面向深度學(xué)習(xí)應(yīng)用開發(fā)部署的有效解決方案。
5 結(jié)語
本文針對深度學(xué)習(xí)應(yīng)用缺少開發(fā)與部署工具的問題,提出一個組件式的深度學(xué)習(xí)應(yīng)用開發(fā)框架。就框架設(shè)計過程中的組件劃分問題、GPU 共享問題、流水線部署問題以及由此帶來的CPU 利用低效的問題做了詳細的考量,并給出了解決方案。在考慮深度學(xué)習(xí)應(yīng)用的特點、組件間的通信開銷、應(yīng)用的資源利用方式和應(yīng)用的部署方式之后,設(shè)計并實現(xiàn)了應(yīng)用開發(fā)和部署一體化的三層軟件框架。
通過應(yīng)用開發(fā)和部署實例以及性能對比實驗表明,本工作基本上實現(xiàn)了框架初始設(shè)計時提出的易用性、高效性、靈活性等目標(biāo),說明了框架在實際的應(yīng)用開發(fā)和部署場景下的實用性和有效性。框架能根據(jù)吞吐和時延偏好作出對硬件方面的自適應(yīng)擴展,為面向流式數(shù)據(jù)的深度學(xué)習(xí)應(yīng)用提供了有效的開發(fā)部署方案。
本文框架尚存在許多不足,還有很多進一步的工作可以完成,現(xiàn)結(jié)合需求以及技術(shù)的發(fā)展趨勢,總結(jié)3 點如下:
1)框架目前僅對視頻流應(yīng)用提供支持,無法完成其他模態(tài)的應(yīng)用開發(fā)。應(yīng)用開發(fā)和框架完善是一個互相迭代的過程。在之后的工作中,可以對更多類型的應(yīng)用進行考量,進一步增加框架組件庫的豐富度。
2)當(dāng)前深度學(xué)習(xí)領(lǐng)域前端框架和后端平臺類型十分豐富。本文框架目前只對PyTorch 類型的前端框架和CPU、GPU 等部署后端提供支持。后續(xù)可以面向更多硬件的存儲特點及編程范式進行分析、考量和設(shè)計,對更多種類的硬件平臺提供支持。
3)當(dāng)前面向特定硬件的深度學(xué)習(xí)部署加速工具在不斷發(fā)展進程之中。為了得到在相應(yīng)硬件上更高的模型推理效率,框架需要面向主流推理引擎做兼容性設(shè)計。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年6期)2019-01-08 02:43:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
