基于隱式反饋和加權用戶偏好的推薦算法
2024-03-25 02:11:08陸勁宇
計算機技術與發展 2024年3期
夏 翔,劉 姜,倪 楓,陸勁宇
(上海理工大學 管理學院,上海 200093)
0 引 言
隨著互聯網技術和短視頻平臺的飛速發展,用戶獲取信息的能力不斷增強,方式不斷增多,各類信息的種類和數量也急劇增加。在海量信息資源條件下,用戶由于其認知能力和特點的限制,很難在有限的時間內選擇到符合需求的信息,這就呈現出“信息過載”和“信息缺失”的矛盾[1]。與以往搜索引擎需要用戶輸入關鍵字才能從數據庫中檢索所需內容不同,推薦系統根據每個客戶的用戶資料自動生成推薦列表,從而顯示出更大的便利性[2]。
推薦算法是推薦系統的核心,主要分為3類:(1)基于內容的推薦[3-4];(2)協同過濾推薦[5];(3)混合推薦[6]。其中協同過濾(CF)算法廣泛應用于推薦領域,通常依賴于用戶的歷史評分或行為(如購買或觀看、收聽等)。核心思想是具有相同或相似的價值觀、思想觀、知識水平和興趣偏好的用戶,其對信息的需求也是相似的[7]。
用戶行為數據通常在項目推薦中起著至關重要的作用,基本分為兩類:顯式反饋[8]和隱式反饋[9]。顯式反饋是指用戶主動或者在一定的提示和指引下,根據自身偏好對某個推薦對象或者某種服務的主觀使用或者體驗感受進行打分、評級或是進行語言評價等行為,以此來很明顯地表達用戶體驗感受和偏好程度[10]。現實生活中,顯式反饋的數據收集依賴于用戶的主動配合,數據十分稀疏。而隱式反饋是在用戶并不知情的情況下,系統記錄的用戶在系統中的所有操作行為數據[11],數據量大,數據更稠密、更穩定,通常可以真實反映用戶態度,具有很好的應用價值。然而,隱式反饋推薦也存在一些常見的問題,例如缺少正負反饋維度的區分、用戶偏好程度不明確、隱式反饋數據樣本利用度低等。
根據上述隱式反饋推薦存在的問題,現有的隱式反饋推薦算法主要分為3類:面向單類協同過濾的推薦、引入輔助信息的推薦以及基于排序的推薦。
(1)單類協同過濾推薦。Pan等[12]于2008年提出了單類協同過濾問題(One-Class Collaborative Filtering,OCCF),主要是指用戶所產生的隱式反饋行為僅能反映用戶對當前項目進行過一定的操作,但未被用戶進行操作過的項目,不能直接反映用戶對其沒有偏好,也有可能是用戶沒有接觸到該項目。不少學者從權重、置信度加權及矩陣分解等角度對OCCF問題進行研究。Pan等人[13]提出利用wALS算法(weighted Alternating Least Squares)和權重來緩解負樣本問題,其基本思想是:將所有的缺失數據作為負樣本,對所有樣本進行加權。用戶對項目的操作行為代表了用戶偏好,具有較高的可行度,將其權重設置為1。相反若用戶對其沒有操作,即將其相關權重設置為0或1。Hu等人[14]提出了改進的Implicit ALS算法,考慮了用戶偏好和置信度之間的聯系,將是否有過用戶操作行為的項目進行二進制量化,并給數據集中的正負樣本分別分配一個變化的信任權值,在經典的矩陣分解模型基礎上進行優化。但都僅根據用戶是否有過操作對樣本進行正負劃分,而忽略用戶操作頻次帶來的影響,且將缺失數據作為負反饋的推薦算法復雜度高,數據集較大。
(2)引入輔助信息的推薦。在單類協同過濾方法的基礎上引入輔助信息,便可以挖掘用戶潛在興趣偏好,進而提高推薦效果,引入的輔助信息包含用戶或項目內容、時間或位置的上下文信息、用戶的信任網絡或社交關系等。Chen等人[15]引入項目信息,提出一種基于項目的相似性的模型(HCoM)來處理用戶購買行為等隱式反饋數據的稀疏問題,在提高OCCF的準確性的基礎上還緩解了數據稀疏問題,但引入項目信息的算法針對的特征需求不同,需要根據用戶偏好合理選取,所以缺乏一定的通用性。俞東進等人[16]基于玩家操作次數和操作時常等隱式反饋數據及其時效性,提出了一種基于隱式反饋數據的網吧游戲推薦方法(DIIF-SVD++),克服了用戶偏好不完整性問題,實現了游戲的實時個性化推薦。陳婷等人[17]通過計算用戶間的相似度和信任度構建用戶之間的偏好關系,提出了一種基于信任的社交推薦算法(Trust-PMF),但對于隱式反饋推薦中負樣本的缺失問題依然沒有解決。
(3)基于排序的隱式反饋推薦。Rendle等人[18]于2009年圍繞隱式反饋提出了貝葉斯個性化排序(BPR),其關鍵思想是實現最大后驗概率估計規則,以確保觀察項目的排名應高于未知項目。Guo等人[19]利用項目內容信息和隱式反饋進行建模,提出一種自適應個性化排序方法(CA-BPR),加快了個性化排序的成對學習,提高了個性化排序的準確性。申艷梅等人[20]針對BPR未能充分利用用戶行為信息導致數據稀疏的問題,提出了均值貝葉斯個性化排序算法(MBPR),并通過引入遺忘函數,根據用戶評分信息對項目進行了正負反饋劃分,進一步挖掘了用戶對未知項目的偏好,實驗結果表明該算法的推薦性能及魯棒性均有顯著提高。
綜上所述,現有的單類協同過濾以及引入輔助信息推薦方法中存在正負樣本劃分不合理、忽略用戶操作頻次、無法準確建模用戶偏好等問題。針對這些問題,該文引入輔助信息并提出了一種基于隱式反饋和加權用戶偏好的推薦算法(IFW-LFM)。該算法首先對wALS算法進行改進,考慮用戶操作頻次與正負樣本劃分間的關系,從缺失的數據集中劃分正負樣本,并不再需要人為引入負樣本;其次考慮了用戶操作頻次對用戶偏好程度的影響,定義了置信度這一概念,明確了用戶偏好程度,并將其應用在隱因子模型的框架中;對于隱式反饋數據利用度低的問題,通過動態考慮時間問題,將用戶收聽歌曲起止時間、收聽時長等隱式反饋樣本利用進來,提高了隱式反饋數據利用價值;最后,在兩組真實數據集上對算法進行了測試,從兩個不同的數據集得出結論,比一個數據集更為嚴格可信。
1 基于隱式反饋和加權用戶偏好的推薦算法
為了便于形式化描述,符號定義見表1。

表1 符號定義
1.1 隱式反饋中正負反饋維度區分
針對隱式反饋數據缺少正負反饋維度的區分問題,即隱式反饋一般只有正反饋而缺失負樣本的問題,常見的思路是人為引入負樣本或者將所有的缺失值均作為負樣本來使用,這兩種解決策略都與實際數據有較大偏差。Pan等人[13]提出利用wALS算法(weighted Alternating Least Squares)和權重來緩解負樣本問題,僅僅只考慮了用戶是否進行過操作,但將所有缺失數據都當成負反饋其實是不合理的,忽略了用戶頻次對正負反饋劃分的影響。因此,該文學習wALS算法的思想從缺失值中劃分潛在的正負樣本。首先,定義用戶u和項目i,設置Aui>1,這與wALS中將Aui=0設為正樣本不同,原因在于表示用戶u對項目i進行了不止一次的操作,說明用戶對該項目有一定的偏好,且這種推斷具有較強的可信度,即設置該項目的偏好值pui=1。對于缺失值來說Aui=0,表示用戶u對項目i沒有進行過操作,但只能推斷這些項目可能并不一定為負樣本,因此設置其偏好pui=δ∈[0,1]。對于臨界值Aui=1,即用戶對推薦項目i只進行過一次操作,該文也將其偏好設定為與Aui=0時取值一致,這是因為一次點擊并不能推斷用戶偏好,可能為正樣本,也可能為負樣本,如公式1所示:

(1)
其中,當δ=0時,說明所有缺失值都無法劃分正負樣本,即將所有樣本都作為正樣本,當δ=1時,即將所有缺失值都當做負反饋樣本。
1.2 引入偏好程度
單純將用戶有無隱式行為作為區分用戶偏好與否的標準,這樣簡單的判斷是有問題的。比如當用戶點擊某一首歌曲時,用戶可能對這首歌曲沒有偏好,可能只是分享給朋友收聽,也可能用戶不知道該首歌曲的存在。而當用戶某種隱式行為的操作頻次增加時,用戶對該項目的喜好程度隨之增加。因此,結合音樂收聽背景,文中模型引入一個新的概念偏好程度Eui,它表示用戶u在某一操作頻次下對該項目i具有偏好的置信度,如公式2所示:
Eui=1+βAui
(2)
其中,Aui為用戶收聽歌曲操作頻次;β為偏好程度的計算系數,通過控制其大小可以為每一個用戶-項目對提供最小置信度。由式2可以看出,當用戶隱式反饋中收聽歌曲的頻次數值越大,其偏好程度Eui越大。
1.3 提高隱式反饋樣本利用度
如上所述,通過劃分正負反饋以及引入用戶偏好程度只能解決隱式反饋數據中的前兩個問題,并沒有解決傳統隱式反饋推薦算法樣本利用度低的問題。例如,音樂推薦背景中的用戶收聽歌曲的起止時間、收聽時長等數據在傳統的LFM模型中并沒有加以利用,因而不能充分發揮隱式反饋推薦作用。時間敏感性對于隱式反饋推薦系統同樣至關重要。對此,Li等人[21]提出用戶偏好呈指數衰減,這一觀點與艾賓浩斯遺忘曲線相吻合,即人們忘記事情的速度先快后慢。申艷梅[20]也將遺忘函數加入到了MBPR算法中,考慮了用戶興趣隨時間變化的特征。但統一的遺忘函數并未實現用戶遺忘規律的個性化,對用戶收聽時長數據也沒有加以利用。因此,該文結合音樂推薦背景,用戶收聽歌曲起止時間,對歌曲收聽時長等數據,利用經典的矩陣分解方法,提出了如下優化目標函數:
(3)
1.4 用戶興趣預測和推薦算法
在實際應用中,較多顯式反饋中的推薦算法并不能直接應用于隱式反饋推薦中。該文選取LFM方法實現用戶對某首歌曲的興趣預測,通過將用戶和項目都投射至隱因子空間得到隱式特征,分別計算用戶以及項目每一個隱因子類別之間的關系,如式4所示:
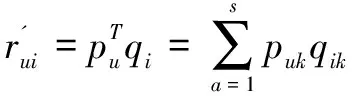
(4)
綜上,需要對優化的如下損失函數找到合適的參數puk,qik:

(5)
其中,正則化參數λ‖pu‖2+λ‖qi‖2是為了避免模型過度擬合,即利用隨機梯度下降法求解puk和qik。主要步驟如下:
(1)通過反復實驗設定合適的學習率Learning rate和正則化參數λ。
(2)計算puk和qik的偏導數,找到最速下降方向:
(6)
(7)
(3)根據最速下降方向,不斷更新puk和qik,反復迭代優化參數:
(8)
(9)
具體算法描述如下:
算法:基于隱式反饋和加權用戶偏好的推薦算法(IFW-LFM)
輸入:用戶-項目操作矩陣A,偏好程度計算系數β,偏好值δ∈[0,1]
輸出:用戶-項目預測偏好程度矩陣R'
Step 1:讀取數據集,初始化用戶-項目操作矩陣A;
Step 2:根據式1計算用戶偏好pui,根據偏好程度計算系數β計算式2用戶偏好程度;
Step 3:根據用戶收聽歌曲起止時間,對歌曲收聽時長等信息,得到式3的優化函數;
Step 4:根據式6~9反復迭代更新計算puk,qik,使得式5的損失函數最小;
Step 6:設定Top-N推薦中N的數值,根據步驟5中得到的R',選取前N個產生推薦列表。
2 實驗評估
2.1 實驗數據集
實驗利用了兩組國外大型音樂數據集,以便更好地呈現出算法的性能。數據集1為last.fm-1k,包含兩個表,其中用戶歷史交互記錄表記錄了從2005年7月到2009年5月992個用戶的全部收聽歷史記錄(約2 000萬條),包括userID,event timestamp, artistID,artist_name,songID,song_name等信息,用戶特征表包含性別、年齡、國家、注冊時間等。另一組數據是來自數據集last.fm-360k,包含六個表,記錄了1 892個用戶的全部收聽歷史記錄,last.fm 360k數據的格式與1k數據大致相同,增加了user對artist收聽次數的記錄。
2.2 評價指標
在一般的推薦算法指標評價中,評分預測通常使用平均絕對誤差和均方根誤差來度量,但在隱式反饋中不存在用戶“實際”評分,因此,上述兩個由用戶實際評分與預測評分之間的誤差來評估推薦性能的指標不適合計算。該文的目的是對用戶進行個性化的音樂推薦,注重的是最終的推薦效果,而不是預測評分與實際評分間的誤差。因此,選取準確率、召回率和NDCG作為實驗的評估標準。準確率為相關的推薦物品數占推薦物品總數的比率,召回率為相關的推薦數占實際相關物品總數的比率,NDCG表示歸一化折損累計概率,與DCG相比,可以更準確地評估排序性能。其計算方法如式10~12所示:
(10)
(11)
(12)
其中,N為推薦列表中的項目數量,reli表示推薦列表中第i個位置的項目的相關分數。實驗中,如果結果為正,則reli=1,否則,reli=0。IDCG(理想折損累計增益)表示可得到的DCG的最大值。
2.3 參數影響分析
在文中算法中,4個重要參數分別為隱性特征個數F,負樣本比例ratio,正則化參數λ,以及學習速率Learning rate,實驗研究了這4個參數對推薦結果的影響。
由圖1可以看出,隨著隱性特征數目的增多,算法的Precision、Recall和NDCG值均成下降趨勢。這是由于在音樂推薦背景中,隱性特征個數相對來說比較單一,用戶的興趣偏好主要受幾個關鍵的隱性特征影響,并不是隱性特征越多越好。
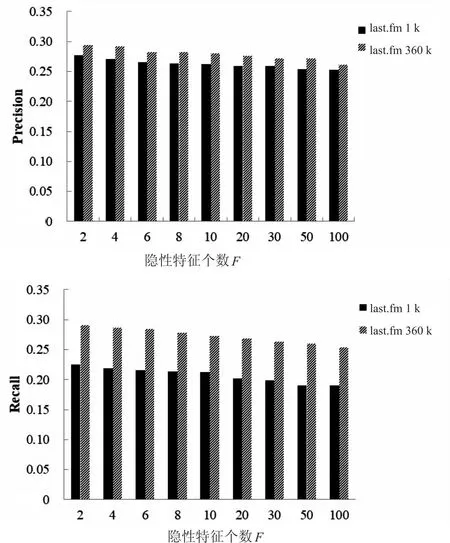
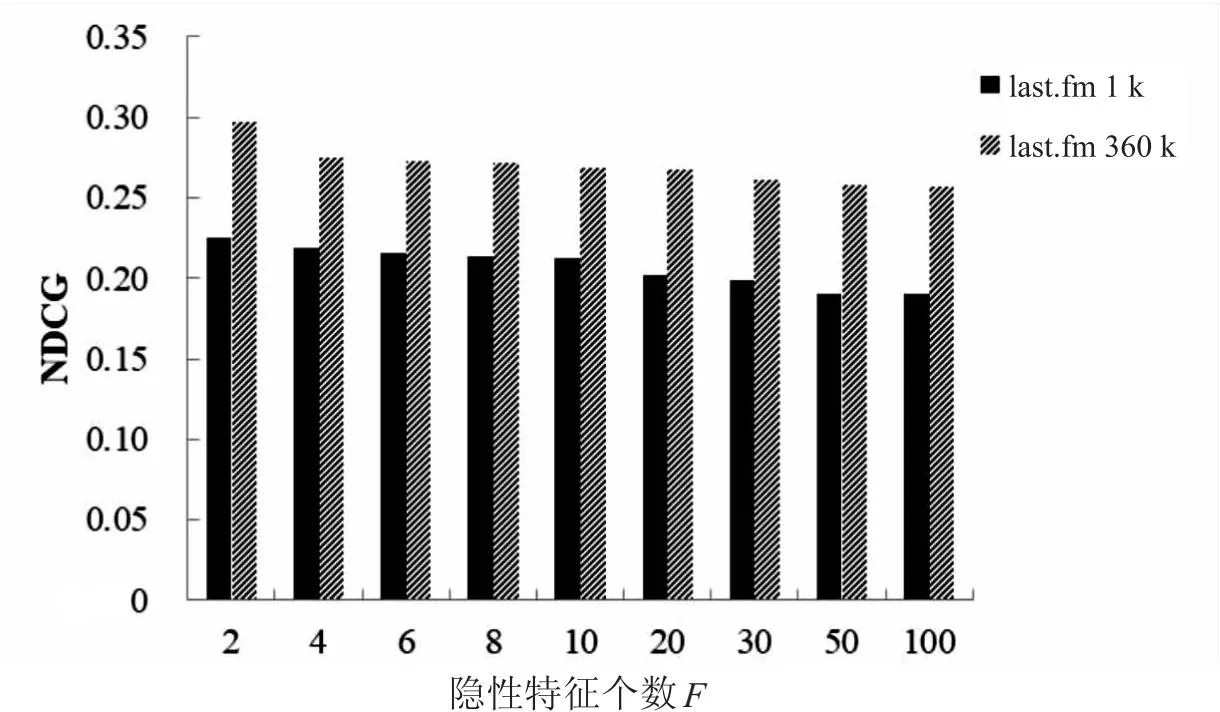
圖1 隱性特征個數對性能的影響
如圖2所示,負樣本比例ratio對算法的性能也有一定影響。實驗發現,當ratio小于等于5時,準確率、召回率和NDCG值均隨ratio的增加而提高,當ratio大于5后,圖像趨于平緩,三類評價指標基本保持穩定。
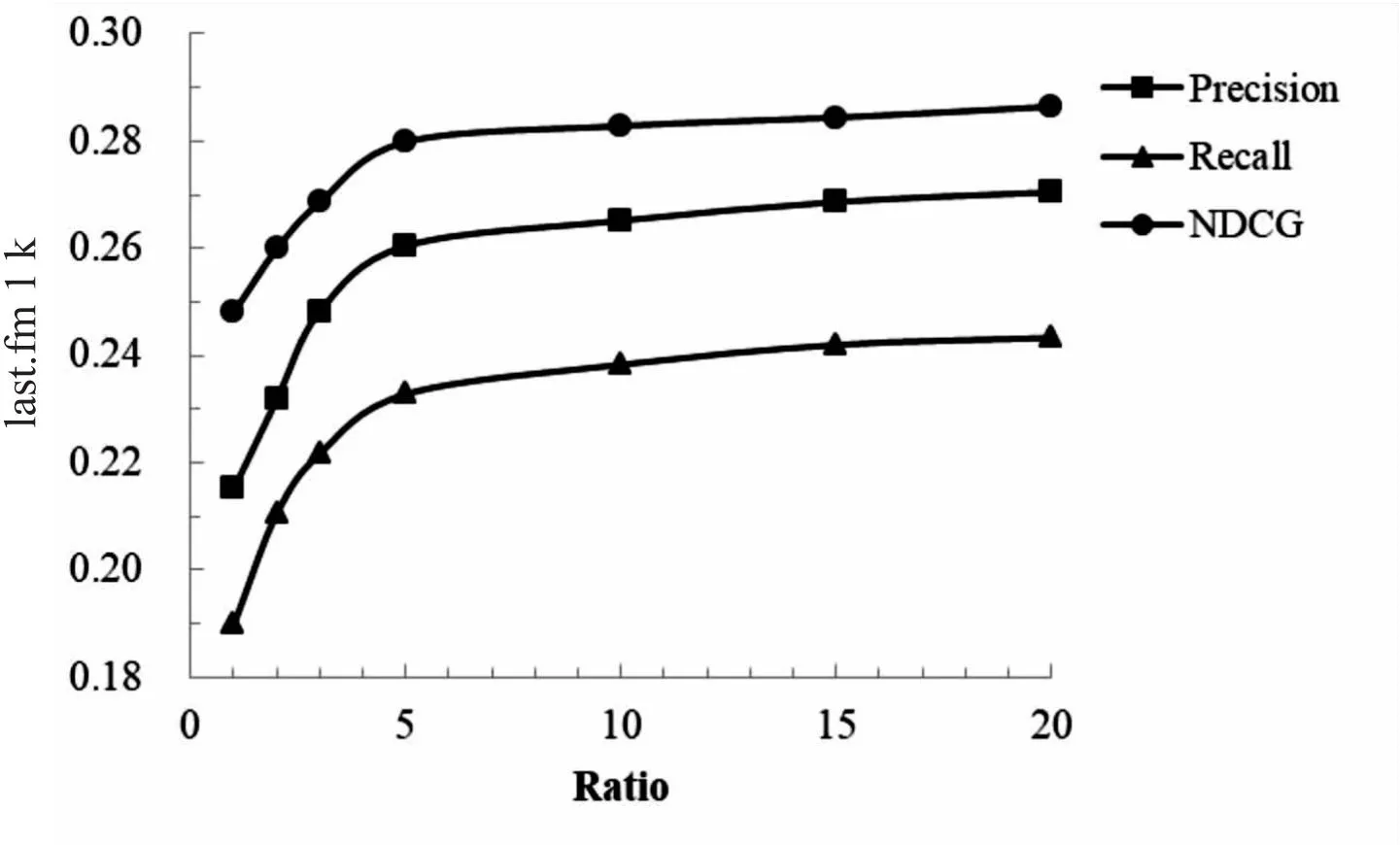
圖2 負樣本比例對性能的影響
圖3展示了數據集1中準確率等指標在不同正則化參數λ值下的變化。當λ在0.07至0.4之間時推薦效果最好,當λ<0.07時,推薦效果隨λ值的增大而提升,當λ>0.4時,模型不能很好擬合,經過實驗可以選取合適的λ值,使得算法的推薦效果更好。
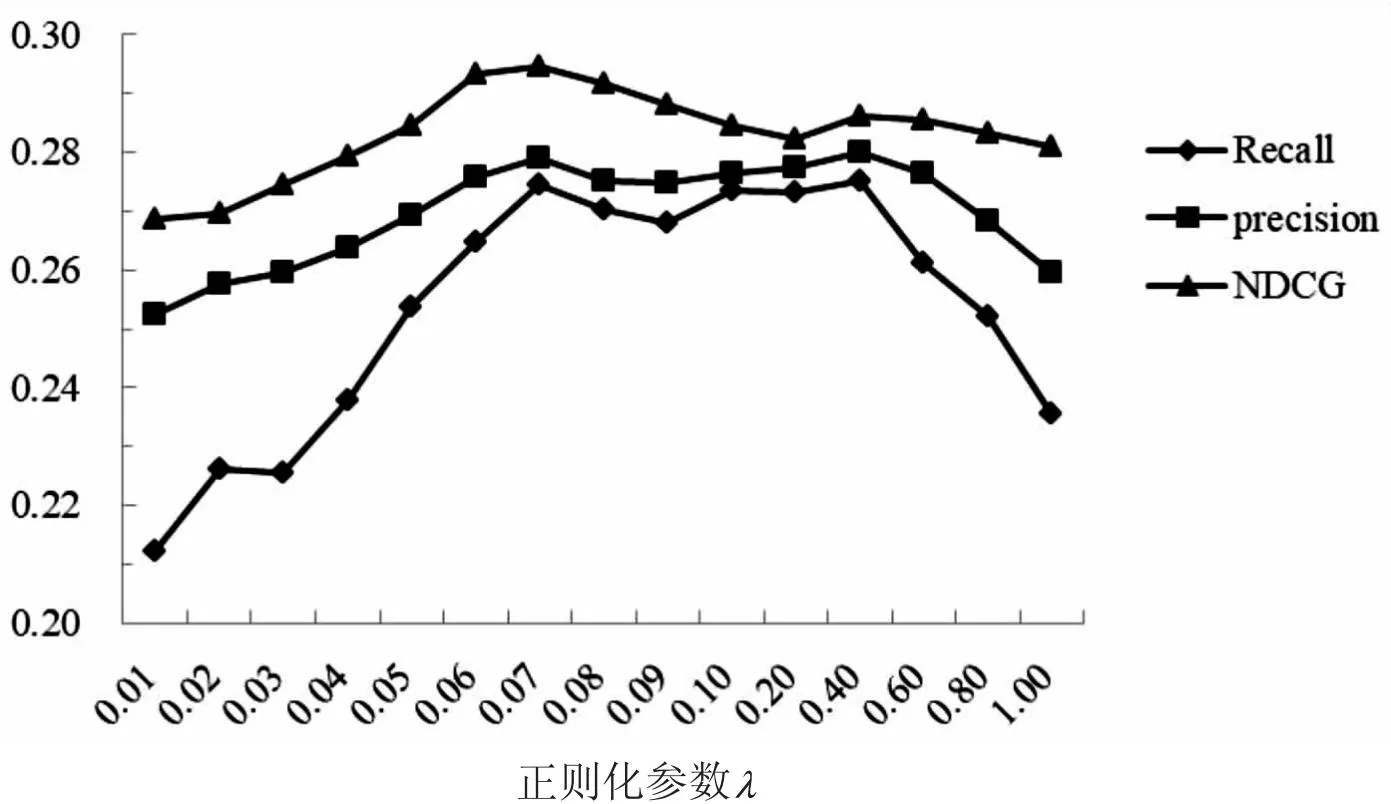
圖3 正則化參數對性能的影響
在梯度下降法中,學習率Learning rate會直接影響算法的收斂速度和最終優化效果。由圖4可知,推薦效果隨迭代次數的增加會先有一個增強趨勢至峰值,而后逐漸下降。在數據集1中,當初始學習率為0.002時,推薦效果最為理想,但需要30次左右的迭代才能達到,當學習率為0.001時,推薦效果反而下降,這說明當學習率過小時,收斂速度變慢,推薦效果也隨之下降,這需要進一步地動態調整學習率,使得迭代次數也調整為合適的值。
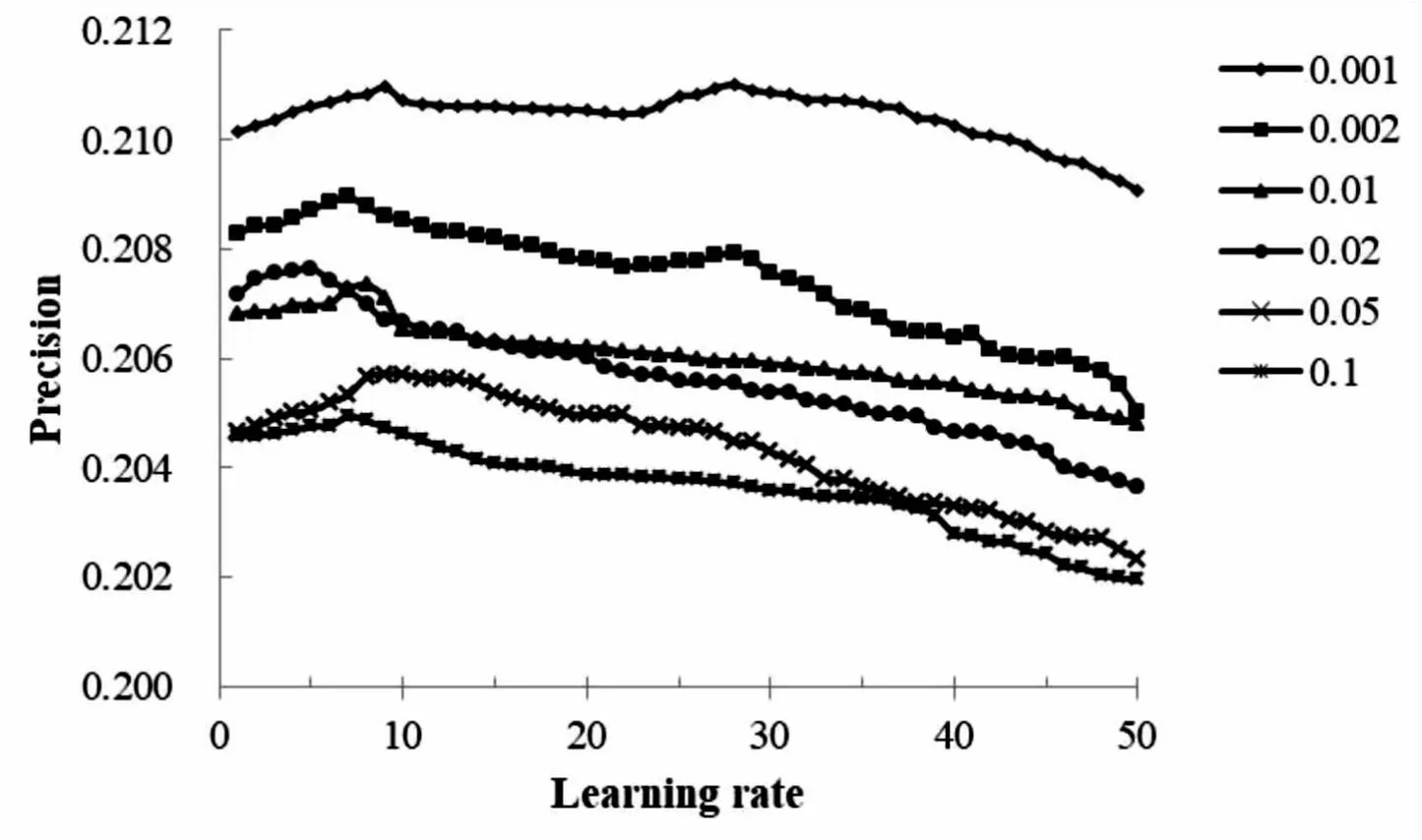
圖4 學習率對性能的影響
2.4 實驗結果與分析
基于隱式反饋的音樂推薦算法較少,同時考慮到隱式反饋應用到音樂推薦場景本身的特點,一些已有的隱式反饋推薦算法不適用于音樂推薦場景。該文選擇以下5種算法作為對比算法。
(1)UserCF:基于用戶的協同過濾推薦算法。
(2)ItemCF:基于項目的協同過濾推薦算法。
(3)BPR[18]:將推薦問題轉化為成對排序問題,將用戶參與項與未參與項分別作為正負反饋,構造矩陣參數,從而對每名用戶產生推薦列表。
(4)SVD[21]:采用隨機梯度下降法優化用戶及物品特征矩陣,使其接近原始的評分矩陣,常應用于隱式反饋推薦中。
(5)LFM[22]:通過隱含特征聯系用戶興趣和物品,是經典的隱式反饋推薦方法之一。
為達到理想的推薦效果,實驗選取了80%的數據作為訓練集,20%作為測試集,隱性特征個數F=10,負樣本比例Ratio=5,正則化參數λ=0.07,學習率Learning rate=0.002,模型迭代次數為30,實驗結果如表2和表3所示。
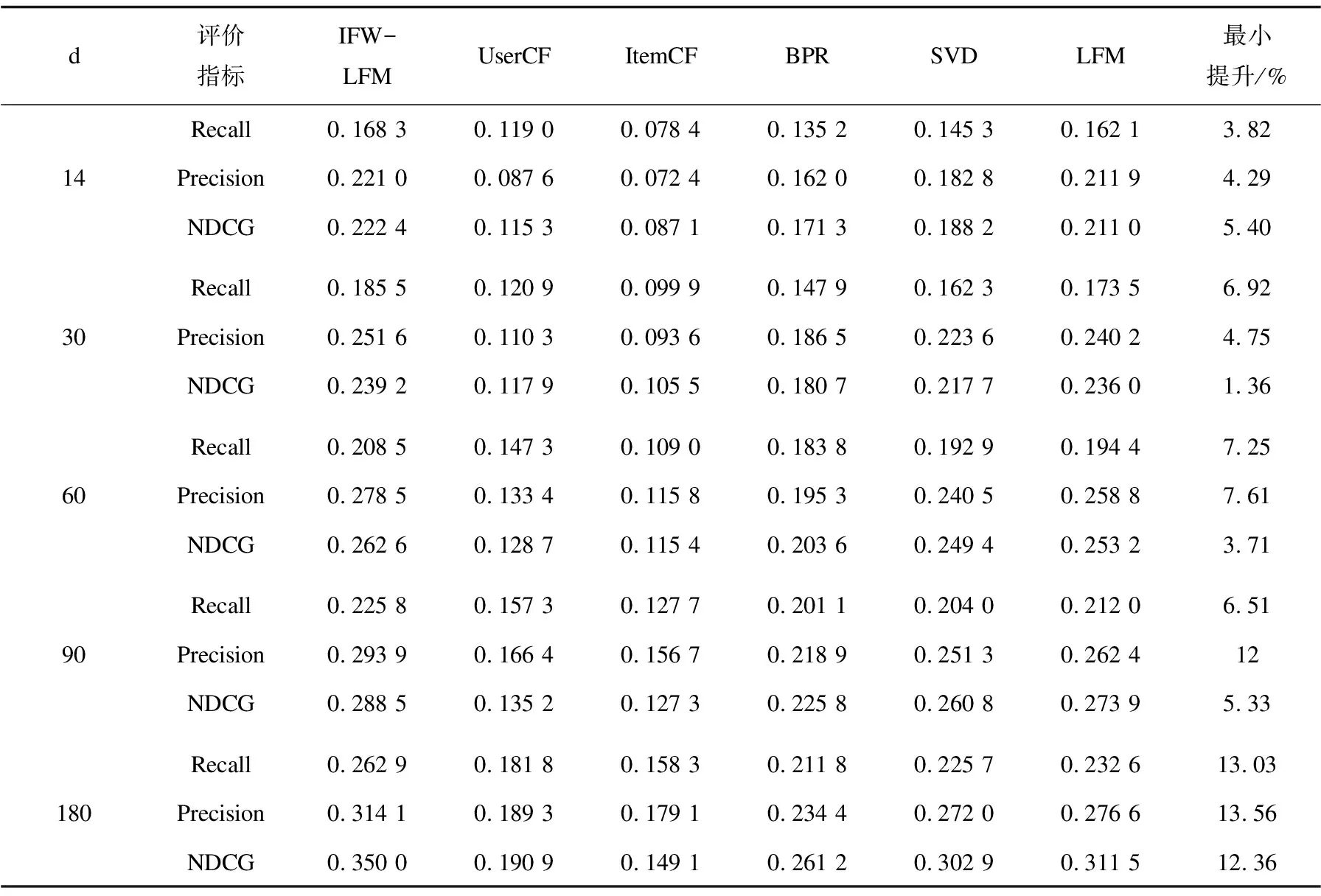
表2 last.fm 1k數據集實驗結果
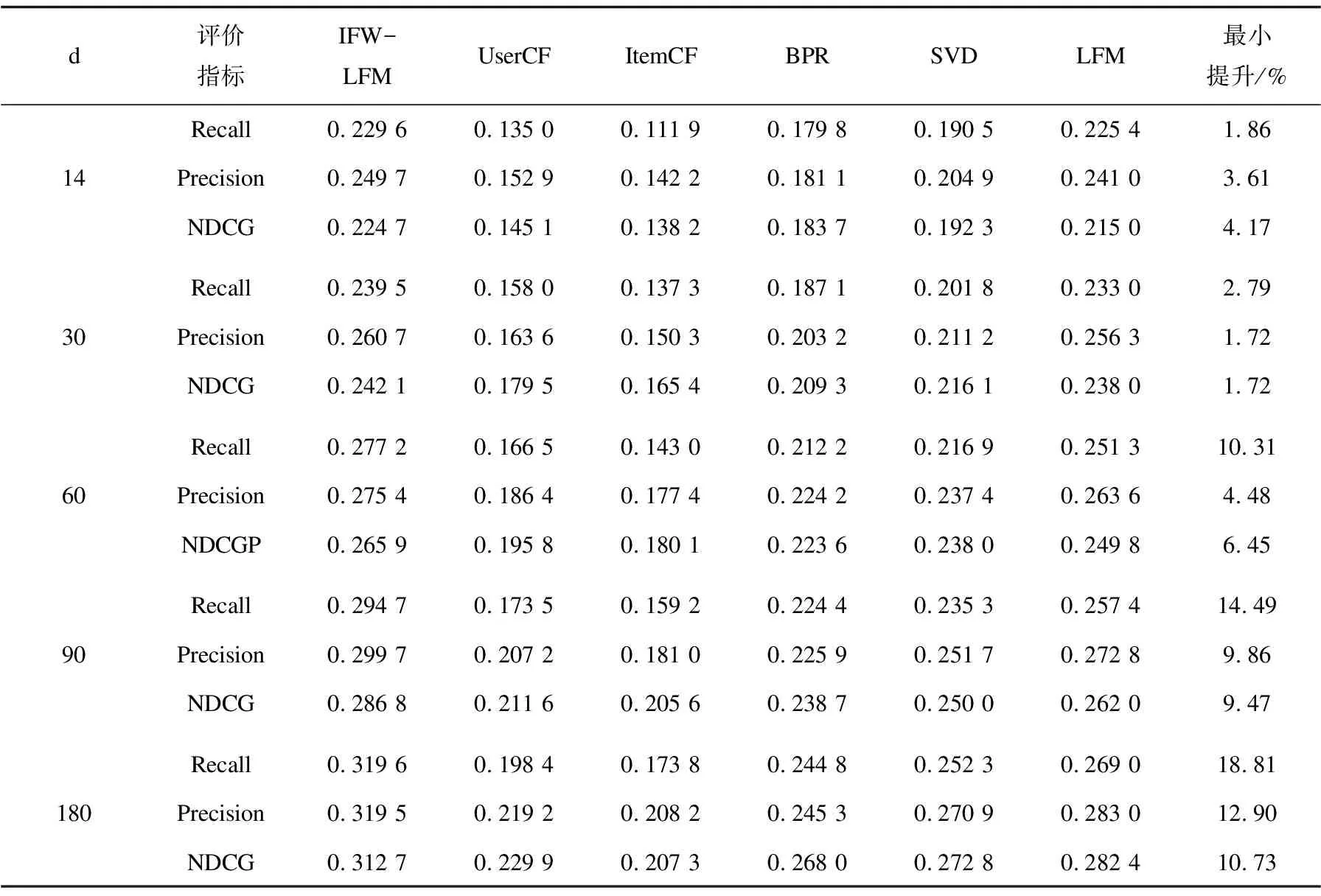
表3 last.fm 360k數據集實驗結果
由表2和表3可以觀察到,文中算法在兩個數據集下明顯優于5種對比算法,其中Item CF算法的召回率、準確率和NDCG值最低,比UserCF的值都要低,這說明基于項目的協同過濾算法沒有利用用戶行為數據,其推薦效果最差。而相較于SVD僅考慮了隱式特征,并未涉及隱式正負反饋樣本的劃分,BPR算法將所有缺失值都當做負樣本,LFM缺乏時間敏感性的問題,文中提出的基于隱式反饋和加權用戶偏好的推薦算法對隱式反饋正負樣本進行了合理的劃分,同時考慮了收聽時長等時效性隱式反饋數據,推薦性能均有顯著提升。數據集2中,IFW-LFM算法在時間跨度為180天時,其召回率、準確率和NDCG值較UserCF、ItemCF、LFM、BPR、SVD分別最大平均提升了45.81%,83.83%和60.33%,這說明考慮用戶操作頻次從缺失值中劃分正負樣本與考慮其和用戶偏好間的關系并引入時間輔助信息的思路是行之有效的。
3 結束語
針對現有隱式反饋中存正負樣本劃分不合理、忽略用戶操作頻次、無法準確建模用戶偏好的問題,提出了基于隱式反饋和加權用戶偏好的推薦算法(IFW-LFM)。該算法借助wALS思想,考慮用戶操作頻次與正負樣本劃分間的關系,并對臨界值的用戶偏好進行了討論;接著考慮了用戶收聽歌曲頻次對用戶偏好程度的影響,根據用戶操作頻次定義了置信度,明確了用戶偏好程度這一重要信息;最后提高了隱式反饋樣本中關于時效性信息的利用,根據用戶收聽歌曲起止時間與收聽時長等樣本數據,構建了隱式反饋推薦模型,并利用LFM算法預測用戶興趣,提高了推薦性能。然而,在考慮樣本利用率低的問題時,僅加入了時效性信息而未考慮其他輔助信息,未來將在此模型的基礎上考慮加入更多的輔助信息,以進一步提高樣本利用率。此外,該文是基于純粹隱式反饋數據上的推薦,對顯式反饋數據沒有加以利用,下一步也可以考慮這兩種反饋數據如何進行有效的結合以提高推薦性能。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
