基于深度學(xué)習(xí)的有錨框行人檢測(cè)方法綜述
2024-03-28 07:10:50章博聞
傳感器世界 2024年1期
章博聞
重慶交通大學(xué) 機(jī)電與車輛工程學(xué)院,重慶 400074
0 引言
行人檢測(cè)(Pedestrian Detection)是指利用計(jì)算機(jī)視覺(jué)技術(shù)判斷圖像或者視頻序列中是否存在行人并給予精確定位,被廣泛應(yīng)用于智能駕駛、智慧交通、智能機(jī)器人等領(lǐng)域。基于錨框的目標(biāo)檢測(cè)算法有著檢測(cè)精度高、提取特征能力強(qiáng)等特點(diǎn),因此一直是目標(biāo)檢測(cè)領(lǐng)域的研究熱點(diǎn)。有錨框的行人檢測(cè)算法按照是否需要生成區(qū)域候選框可以分為兩階段(two-stage)和單階段(one-stage)。本文介紹了傳統(tǒng)的行人檢測(cè)方法,重點(diǎn)闡述了基于有錨框的行人檢測(cè)算法在面對(duì)小尺度行人和遮擋行人等檢測(cè)問(wèn)題上的研究進(jìn)展。
1 傳統(tǒng)的行人檢測(cè)算法
傳統(tǒng)的行人檢測(cè)算法主要是依靠人工設(shè)計(jì)的特征算子來(lái)提取特征,再將提取后的特征傳入分類器,得到最終的檢測(cè)結(jié)果,即特征提取+分類器模式。VIOLA P 和JONES M[1]提出了Viola-Jones 檢測(cè)器用于人臉檢測(cè),Viola-Jones 檢測(cè)器主要由Haar-like 特征、Adaboost 分類器和Cascade 級(jí)聯(lián)分類器組成。DALAL N 等人[2]提出方向梯度直方圖(Histogram of Oriented Gradients,HOG),HOG 算法主要利用光強(qiáng)梯度或邊緣方向的分布能夠?qū)D片中物體外形進(jìn)行描述的原理,但是難以應(yīng)對(duì)有遮擋或者人體姿態(tài)變化較大的情況。FELZENSZWALB P F 等人[3]在HOG 的基礎(chǔ)上,采用多組件的策略,提出可變形的組件模組(Deformable Part Model,DPM),DPM 對(duì)目標(biāo)的形變具有很強(qiáng)的魯棒性。由于傳統(tǒng)的行人檢測(cè)算法大多是采用滑動(dòng)窗口來(lái)一一篩選,所以效率低下,同時(shí),人工設(shè)置的特征提取算子會(huì)使準(zhǔn)確性和魯棒性都得不到保證,在復(fù)雜場(chǎng)景下,準(zhǔn)確率會(huì)大大降低。深度學(xué)習(xí)的迅猛發(fā)展為目標(biāo)檢測(cè)帶來(lái)了轉(zhuǎn)機(jī),與傳統(tǒng)檢測(cè)方法相比,通過(guò)讓網(wǎng)絡(luò)自己學(xué)會(huì)如何提取特征,取代人工設(shè)置的特征提取器,充分學(xué)習(xí)圖片中的特征,使網(wǎng)絡(luò)檢測(cè)目標(biāo)的性能大幅度提高。
2 兩階段行人檢測(cè)方法
兩階段的目標(biāo)檢測(cè)算法主要分為兩步,即先從原始圖片或者特征圖產(chǎn)生可能包含物體的候選框,再對(duì)候選框中的特征進(jìn)行分類回歸。基于錨框的兩階段目標(biāo)檢測(cè)算法有Faster R-CNN[4]、Cascade R-CNN[5]等。
2.1 R-CNN
GIRSHICK R[6]提出R-CNN 目標(biāo)檢測(cè)算法。首先輸入原始圖像,通過(guò)選擇搜索(selective search)網(wǎng)絡(luò),獲得約2 000 個(gè)尺寸不一致的候選區(qū)域;再將這些區(qū)域縮放到同一尺寸(227×227)后,利用卷積神經(jīng)網(wǎng)絡(luò)對(duì)候選區(qū)域提取特征;最后使用分類器對(duì)得到的特征向量進(jìn)行分類,以及使用回歸器對(duì)候選框的位置進(jìn)行修正。
DONG P 等人[7]提出了一種基于ACF(Aggregated Channel Feature)模型的候選區(qū)域獲取算法,用于替換R-CNN 中的選擇搜索網(wǎng)絡(luò),算法流程如圖1 所示。該候選區(qū)域獲取算法只在可能包含行人的區(qū)域生成區(qū)域候選框,將R-CNN 通用目標(biāo)檢測(cè)器變?yōu)橹会槍?duì)行人進(jìn)行檢測(cè),在提升檢測(cè)精度的同時(shí),減少了大量無(wú)用的候選框,檢測(cè)速度有所提升。

2.2 Faster R-CNN
由于在一張圖像內(nèi)的候選框之間存在著大量重疊的區(qū)域,提取圖像特征時(shí)操作冗余。為了解決上述問(wèn)題,GIRSHICK R[8]提出了Fast R-CNN。Fast R-CNN 是將整張圖像進(jìn)行卷積得到特征圖,再把生成的候選框投影到特征圖上,與R-CNN 算法中對(duì)約2 000 個(gè)候選框進(jìn)行卷積操作相比,減少了大量冗余計(jì)算。同時(shí),F(xiàn)ast R-CNN將分類與邊界框回歸任務(wù)融合在一個(gè)網(wǎng)絡(luò),不再單獨(dú)訓(xùn)練分類器和邊界框回歸器。但Fast R-CNN依然采用了選擇搜索算法來(lái)生成區(qū)域候選框,該過(guò)程十分耗時(shí)。因此,GIRSHICK R 又提出了Faster R-CNN,使用區(qū)域建議網(wǎng)絡(luò)(RPN)生成區(qū)域候選框,同時(shí)提出了錨框(Anchor)這一重要概念。Anchor 是指在圖像上預(yù)先設(shè)置好尺寸和比例不同的參照框,盡可能地包含物體出現(xiàn)的位置。Faster R-CNN 設(shè)置了3 組高寬比(0.5,1,2)以及每種高寬比又分為3 組尺度(8,16,32)的Anchor,共組成了9 種形狀大小不一的邊框。
ZHANG H 等人[9]提出了一種基于Faster R-CNN的行人檢測(cè)算法,如圖2 所示。該算法通過(guò)ZFnet[10]提取圖片特征,將K-means 聚類算法與RPN 相結(jié)合,生成可能包含行人的候選區(qū)域,最后檢測(cè)網(wǎng)絡(luò)對(duì)候選區(qū)域中的行人進(jìn)行檢測(cè)與定位。但是,這種方法在面對(duì)圖像中小尺度行人時(shí)檢測(cè)效果較差。
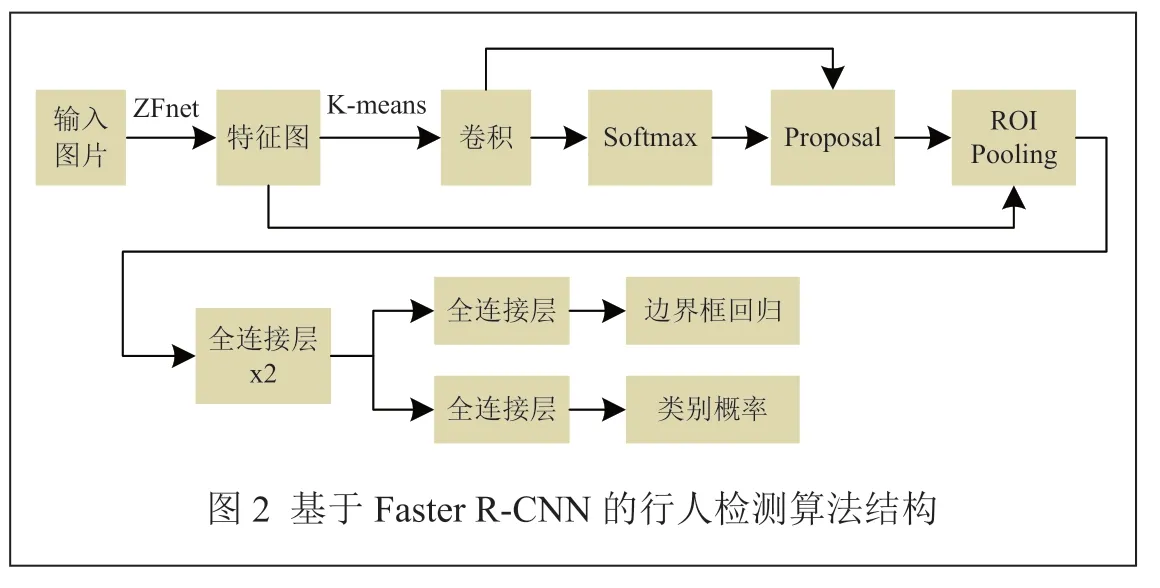
SHAO X 等人[11]提出了一種改進(jìn)的基于Faster R-CNN 的行人檢測(cè)算法。在前者的基礎(chǔ)上,提出了一種基于級(jí)聯(lián)的多層特征融合策略,通過(guò)高層次特征與低層次特征相結(jié)合來(lái)增強(qiáng)網(wǎng)絡(luò)的語(yǔ)義信息。同時(shí),采用OHEM(Online Hard Example Mining,在線困難樣本挖掘)方法對(duì)高損失樣本進(jìn)行訓(xùn)練,處理正負(fù)樣本的不平衡。實(shí)驗(yàn)結(jié)果表明,該方法提高了小尺度行人檢測(cè)的精度。但是,由于這些方法都是對(duì)行人的整體特征進(jìn)行計(jì)算,在有部分身體被遮擋的情況下,其檢測(cè)效果明顯降低。
為了解決對(duì)遮擋行人檢測(cè)的問(wèn)題,許多研究者發(fā)現(xiàn),可以采用基于人體部位的行人檢測(cè)方法來(lái)解決。XU M 等人[12]提出了一種基于人體關(guān)鍵節(jié)點(diǎn)的行人檢測(cè)算法,該算法通過(guò)關(guān)鍵點(diǎn)檢測(cè)器來(lái)獲取行人的6 個(gè)關(guān)鍵節(jié)點(diǎn)(頭部、上身、左右手臂和腿)的語(yǔ)義信息,將這些語(yǔ)義信息與原圖信息相融合,從而使最終的檢測(cè)器對(duì)遮擋和變形具有魯棒性。
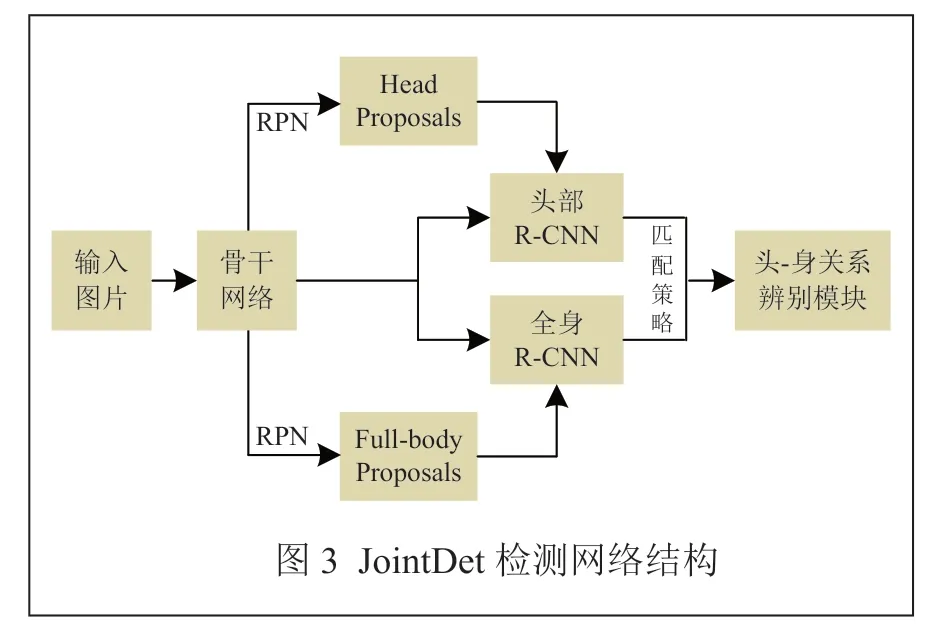
基于人體關(guān)鍵部位的行人檢測(cè)網(wǎng)絡(luò)傾向于關(guān)注行人的部位信息,忽略了行人整體的信息,容易對(duì)形似人體部位的物體產(chǎn)生誤判。因此,研究者提出了基于行人整體與部位加權(quán)的檢測(cè)方法[13]。CHI C 等人[14]提出了一種頭部和人體聯(lián)合檢測(cè)網(wǎng)JointDet,如圖3 所示。使用RPN 生成頭部候選框,頭部和全身的候選框分別經(jīng)過(guò)頭部R-CNN 和全身R-CNN 提取特征;將提取的特征進(jìn)行匹配后,使用RDM 判別是否屬于同一個(gè)人。
2.3 Cascade R-CNN
在行人檢測(cè)中,使用IOU 閾值來(lái)定義正負(fù)樣本。如果IOU 閾值越小,那么就會(huì)學(xué)習(xí)越多的背景框。但是隨著IOU 閾值的增加,正樣本的數(shù)量會(huì)大量減少,容易發(fā)生過(guò)擬合。同時(shí),訓(xùn)練優(yōu)化感知器過(guò)程中的最優(yōu)IOU 與輸入proposal 的IOU 會(huì)出現(xiàn)誤匹配,從而降低檢測(cè)精度。CAI Z 等人[5]提出了Cascade R-CNN,該算法采用級(jí)聯(lián)式的結(jié)構(gòu),由多個(gè)感知器組成,這些感知器通過(guò)遞增的IOU 閾值進(jìn)行訓(xùn)練,從而解決了高IOU 下容易發(fā)生過(guò)擬合的情況。
BRAZIL G 等人[15]在Cascade R-CNN 的基礎(chǔ)上提出了AR-Ped 框架,該框架由自回歸RPN(AR-RPN)和R-CNN 檢測(cè)器兩個(gè)部分構(gòu)成,其中,AR-RPN 由多個(gè)階段以及encoder-decoder 模塊組成,每個(gè)階段預(yù)測(cè)分類分?jǐn)?shù),并通過(guò)encoder-decoder 模塊將上一階段的特征傳遞到下一階段,從而增強(qiáng)候選框中的語(yǔ)義信息。
3 單階段行人檢測(cè)方法
單階段目標(biāo)檢測(cè)算法不需要生成區(qū)域候選框,而是直接對(duì)圖片提取特征后進(jìn)行分類回歸。其檢測(cè)速度與兩階段的目標(biāo)檢測(cè)算法相比更快,但是精度會(huì)有所降低。基于錨框的單階段目標(biāo)檢測(cè)算法有SSD[16]、YOLOv3[17]、YOLOv4[18]、YOLOv5 等。
3.1 基于SSD 的行人檢測(cè)算法
LIU W 等人[16]提出了SSD 算法,圖片通過(guò) VGG-16[19]網(wǎng)絡(luò)提取特征,再經(jīng)過(guò)多次下采樣獲得6 個(gè)不同尺度的特征圖,每個(gè)特征圖都會(huì)預(yù)測(cè)多個(gè)bounding box,最后對(duì)這些不同尺度的特征進(jìn)行檢測(cè)以及非極大值抑制。
為了提升SSD 對(duì)行人檢測(cè)的準(zhǔn)確率,LI X 等人[20]提出了一種基于改進(jìn)SSD 稀疏連接的多尺度融合行人檢測(cè)方法,采用inception[21]網(wǎng)絡(luò)代替SSD 中的 VGG-16 進(jìn)行特征提取,利用FPN[22](特征金字塔網(wǎng)絡(luò))將不同層次的特征圖像進(jìn)行合并,并將合并后的特征圖像進(jìn)行分類和回歸。與SSD 原算法相比,改進(jìn)后的方法在面對(duì)一般行人檢測(cè)時(shí),其精度和速度上都有明顯提高,但是文章指出,該算法對(duì)擁擠人群中有遮擋行人的檢測(cè)效果沒(méi)有明顯提高。
為了解決遮擋行人檢測(cè)準(zhǔn)確度不高的問(wèn)題,袁姮等人[23]提出一種基于改進(jìn)SSD 的行人檢測(cè)算法,使用BN 層(Batch Normalization)[24]來(lái)增加VGG 網(wǎng)絡(luò)分支結(jié)構(gòu),充分利用淺層網(wǎng)絡(luò)的語(yǔ)義信息,提升小尺度行人的檢測(cè)精度,引入融合SE(Squeeze-Excitation)注意力機(jī)制的GhostModule 模型[25],通過(guò)SE 注意力機(jī)制提升遮擋行人的檢測(cè)精度。
3.2 YOLO 系列行人檢測(cè)算法
REDMON J 等人[26]提出了YOLOv1,在保證較高的檢測(cè)精度下,以其簡(jiǎn)潔的網(wǎng)絡(luò)結(jié)構(gòu)和高效的計(jì)算速度給目標(biāo)檢測(cè)領(lǐng)域帶來(lái)了巨大的沖擊,其結(jié)構(gòu)如圖4 所示。但是,由于YOLOv1 的每個(gè)網(wǎng)格只含有兩個(gè)邊界框,且每個(gè)網(wǎng)格只能預(yù)測(cè)一個(gè)目標(biāo),導(dǎo)致其定位誤差高以及小目標(biāo)的檢測(cè)效果差。所以REDMON J 等人[27]又提出了YOLOv2,該算法借鑒了Faster R-CNN的思想,使用Anchor 來(lái)預(yù)測(cè)邊界框,同時(shí)使用BN 層來(lái)防止過(guò)擬合。

3.2.1 YOLOv3
YOLOv3 算法采用DarkNet53 作為骨干網(wǎng)絡(luò)間特征提取,得到3 個(gè)不同尺度的特征圖,通過(guò)K-means算法在每個(gè)特征圖上預(yù)設(shè)3 個(gè)不同尺寸的邊界框,最后分別對(duì)這3 個(gè)特征圖進(jìn)行預(yù)測(cè)輸出。
GONG X 等人[28]提出了一種基于YOLOv3 的行人檢測(cè)算法,引入CSPNet[29],將梯度變化全局整合到特征圖中,提高了推理的速度和準(zhǔn)確性,加入ECA(Efficient Channel Attention)注意力機(jī)制[30],增強(qiáng)網(wǎng)絡(luò)提取重要特征的能力,在保持性能穩(wěn)定的同時(shí),顯著降低了模型的復(fù)雜度。
YU Y 等人[31]為解決行人檢測(cè)中多尺度目標(biāo)、遮擋等問(wèn)題,增加CBAM(Convolutional Block Attention Module)注意力機(jī)制[32],使網(wǎng)絡(luò)更加關(guān)注行人相關(guān)特征,提高檢測(cè)速度和精度,以及引入SPP 模塊,實(shí)現(xiàn)局部特征與全局特征的融合,提高面對(duì)遮擋行人時(shí)的檢測(cè)準(zhǔn)確率。
李翔等人[33]提出了一種面向遮擋行人檢測(cè)的改進(jìn)YOLOv3 算法,通過(guò)提高每層金字塔特征的分辨率,使重疊度高的目標(biāo)框中心點(diǎn)盡量落在不同的區(qū)域,同時(shí),為了使相鄰區(qū)域的特征區(qū)別更明顯,將淺層和深層的語(yǔ)義信息進(jìn)行融合,增加高重疊區(qū)域的特征差異,從而盡可能區(qū)分重疊行人的特征。
3.2.2 YOLOv4
BOCHKOVSKIY A 等人[18]提出了YOLOv4,使用CSPDarkNet53 作為主干網(wǎng)絡(luò),利用SPP 和PANNet來(lái)增大感受野以及提取更豐富的圖像特征。
原始的YOLOv4 模型在面對(duì)小尺度行人時(shí)容易出現(xiàn)漏檢和誤檢的情況。為了解決這個(gè)問(wèn)題,王程等人[34]提出了一種小目標(biāo)行人檢測(cè)算法 YOLOv4-DBF。在骨干網(wǎng)絡(luò)中融入SCSE 注意力機(jī)制[35](Concurrent Spatial and Channel Squeeze &Excitation),從空間維度和通道維度兩個(gè)方面進(jìn)行特征提取融合,提高了小目標(biāo)行人的檢測(cè)精度,并采用可分離卷積提升檢測(cè)速度。
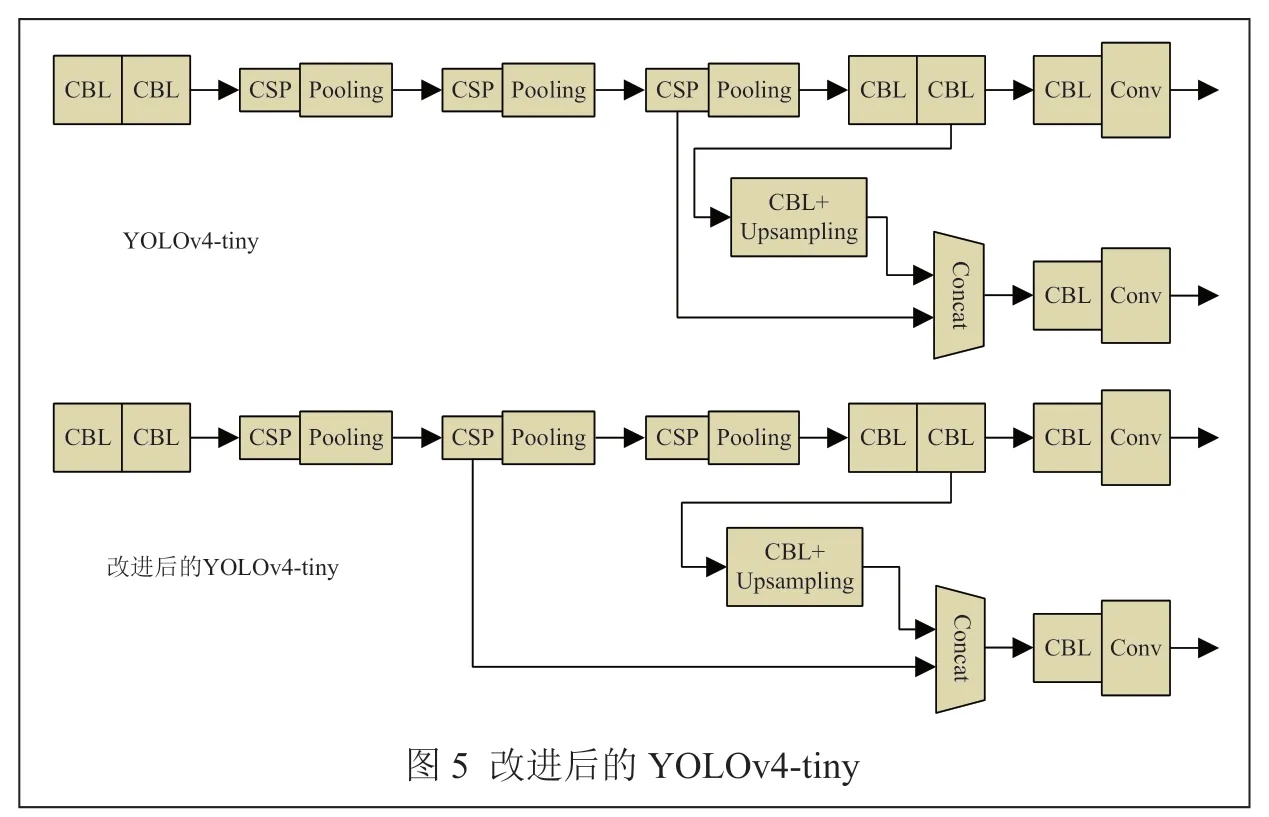
FAN P 等人[36]提出一種基于YOLOv4-tiny 的行人檢測(cè)方法,使用K-means 重新生成更符合行人尺寸的錨框,替換原本的錨框尺寸。同時(shí),為了提取更多淺層語(yǔ)義信息和小尺度信息,將拼接層從第24 層移動(dòng)到第17 層,將第34 層的上采樣倍數(shù)從2 改為4,從而提升遮擋行人以及小尺度行人的檢測(cè)精度。改進(jìn)后的結(jié)構(gòu)與YOLOv4-tiny 對(duì)比如圖5 所示。
3.2.3 YOLOv5
YOLOv5 采用CSP-Darknet53 作為主干網(wǎng)絡(luò)對(duì)圖片進(jìn)行特征提取,通過(guò)頸部網(wǎng)絡(luò)將淺層特征融入特征圖中,最后在預(yù)測(cè)端對(duì)特征圖進(jìn)行預(yù)測(cè)。
由于YOLOv5 算法結(jié)構(gòu)較為復(fù)雜,為了滿足行人檢測(cè)實(shí)時(shí)性的要求,王亮等人[37]提出了一種改進(jìn)的YOLOv5 行人檢測(cè)算法。該算法引入輕量級(jí)卷積模塊Ghost 卷積以及輕量注意力機(jī)制ECA,同時(shí)使用加權(quán)雙向金字塔結(jié)構(gòu)BiFPN 替換PAN+FPN 結(jié)構(gòu)。結(jié)果表明,改進(jìn)后的模型大小約為YOLOv5 模型的1/2,檢測(cè)速度(FPS)提高了約1.67 倍。
針對(duì)現(xiàn)有行人檢測(cè)模型在密集場(chǎng)所行人檢測(cè)中存在漏檢和誤檢的現(xiàn)象,王宏等人[38]在YOLOv5 的主干網(wǎng)絡(luò)中加入了一種坐標(biāo)注意力機(jī)制,其目的是為了使網(wǎng)絡(luò)能更精確地對(duì)目標(biāo)行人進(jìn)行識(shí)別定位,同時(shí),增加了一層尺度為160×160 的檢測(cè)層用來(lái)檢測(cè)小尺度行人。ZHANG R 等人[39]使用BoT3 模塊代替YOLOv5骨干網(wǎng)絡(luò)中的csp2_1 模塊,增強(qiáng)網(wǎng)絡(luò)的全局特征提取能力,在骨干網(wǎng)絡(luò)的輸出端添加HAM(hybridatattention Module)[40],該注意力機(jī)制模塊結(jié)構(gòu)簡(jiǎn)單且兼顧了通道和空間兩個(gè)維度,使網(wǎng)絡(luò)提取行人相關(guān)特征能力得到增強(qiáng),提高了在面對(duì)擁擠人群時(shí)的檢測(cè)精度與速度。
4 結(jié)束語(yǔ)
本文介紹了傳統(tǒng)的行人檢測(cè)算法以及基于錨框兩階段和單階段的行人檢測(cè)算法的發(fā)展現(xiàn)狀,重點(diǎn)闡述基于錨框的行人檢測(cè)算法在面對(duì)遮擋行人和小尺度行人檢測(cè)任務(wù)上的優(yōu)化方法。隨著Faster R-CNN、YOLO 系列等通用目標(biāo)檢測(cè)算法的快速發(fā)展,在一般行人的檢測(cè)任務(wù)上,無(wú)論是精度還是速度都已經(jīng)取得了優(yōu)秀的成績(jī)。但是在面臨擁擠人群或者小尺度行人時(shí),通用目標(biāo)檢測(cè)算法容易發(fā)生誤檢和漏檢,因此,許多研究者都嘗試在此基礎(chǔ)上進(jìn)行改進(jìn),例如通過(guò)添加注意力機(jī)制、增加不同尺度的檢測(cè)層,以及將不同層的語(yǔ)言信息進(jìn)行融合等方式,增強(qiáng)網(wǎng)絡(luò)對(duì)行人特征的提取能力。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
