基于PPYOLOE的師生互助訓(xùn)練半監(jiān)督目標(biāo)檢測(cè)網(wǎng)絡(luò)
2024-03-29 02:27:00張國(guó)山魏金滿(mǎn)
張國(guó)山,魏金滿(mǎn)
基于PPYOLOE的師生互助訓(xùn)練半監(jiān)督目標(biāo)檢測(cè)網(wǎng)絡(luò)
張國(guó)山,魏金滿(mǎn)
(天津大學(xué)電氣自動(dòng)化與信息工程學(xué)院,天津 300072)
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,基于卷積神經(jīng)網(wǎng)絡(luò)的目標(biāo)檢測(cè)技術(shù)成為當(dāng)前計(jì)算機(jī)視覺(jué)領(lǐng)域的研究熱點(diǎn)之一.目前主流的目標(biāo)檢測(cè)算法依賴(lài)于監(jiān)督學(xué)習(xí)方式,需要在大量有標(biāo)注圖像數(shù)據(jù)上訓(xùn)練網(wǎng)絡(luò),然而,無(wú)標(biāo)簽的數(shù)據(jù)易于獲取,而有標(biāo)簽的數(shù)據(jù)收集起來(lái)通常很困難,標(biāo)注也耗時(shí)和耗力.為了解決數(shù)據(jù)標(biāo)注難以獲取的問(wèn)題,提出了教師學(xué)生互助訓(xùn)練的半監(jiān)督目標(biāo)檢測(cè)(PPYOLOE-SSOD)算法.首先,同時(shí)訓(xùn)練一個(gè)學(xué)生模型和逐漸改進(jìn)的教師模型,使用教師模型篩選高質(zhì)量偽標(biāo)簽,將偽標(biāo)簽作為未標(biāo)注圖像的回歸目標(biāo),指導(dǎo)學(xué)生模型訓(xùn)練,挖掘未標(biāo)注圖像的知識(shí)信息,為了減小參數(shù)傳遞的不穩(wěn)定性,每次迭代學(xué)生模型使用指數(shù)移動(dòng)平均方法更新教師模型參數(shù);此外,引入不同種類(lèi)的半監(jiān)督數(shù)據(jù)增強(qiáng)方法來(lái)增強(qiáng)網(wǎng)絡(luò)的抗干擾能力;最后,針對(duì)無(wú)標(biāo)注數(shù)據(jù)的學(xué)習(xí),新增無(wú)監(jiān)督學(xué)習(xí)分支,使用密集學(xué)習(xí)方式對(duì)模型預(yù)測(cè)得到的特征進(jìn)行處理,通過(guò)對(duì)教師模型預(yù)測(cè)的分類(lèi)特征排序,自動(dòng)選擇高質(zhì)量特征作為教師模型生成的偽標(biāo)簽,從而避免了繁瑣的偽標(biāo)簽后處理,提升網(wǎng)絡(luò)的精度和訓(xùn)練速度.在MS COCO 數(shù)據(jù)集上,通過(guò)使用半監(jiān)督學(xué)習(xí)方法,PPYOLOE 在1%、5%、10%的標(biāo)注數(shù)據(jù)集上分別得到了1.4%、1.6%、2.1%的精度提升.與其他半監(jiān)督目標(biāo)檢測(cè)算法比較,PPYOLOE-SSOD算法的精度達(dá)到最優(yōu).代碼已開(kāi)源在https://github.com/wjm202/ PPYYOLOE-SSOD.
半監(jiān)督學(xué)習(xí);目標(biāo)檢測(cè);PPYOLOE;師生互助訓(xùn)練
目前使用全監(jiān)督學(xué)習(xí)方法的目標(biāo)檢測(cè)[1-3]技術(shù)已經(jīng)發(fā)展到瓶頸,僅使用有標(biāo)注數(shù)據(jù)集難以使檢測(cè)模型性能得到進(jìn)一步提升,同時(shí)在部分下游任務(wù)的訓(xùn)練中,存在實(shí)例級(jí)數(shù)據(jù)標(biāo)注難以獲取的問(wèn)題,因此使用有標(biāo)注數(shù)據(jù)和無(wú)標(biāo)注數(shù)據(jù)相結(jié)合的半監(jiān)督學(xué)習(xí)方法[4-6]得到了廣泛關(guān)注.當(dāng)前的半監(jiān)督學(xué)習(xí)方法主要分為以下3步:①使用有標(biāo)注數(shù)據(jù)訓(xùn)練一個(gè)基線(xiàn)教師模型;②使用基線(xiàn)教師模型對(duì)無(wú)標(biāo)注數(shù)據(jù)進(jìn)行預(yù)測(cè);③將無(wú)標(biāo)注數(shù)據(jù)預(yù)測(cè)后的結(jié)果送入學(xué)生模型進(jìn)行訓(xùn)練.
與知識(shí)蒸餾[7]不同,半監(jiān)督學(xué)習(xí)的教師學(xué)生模型均采用相同的模型結(jié)構(gòu).半監(jiān)督學(xué)習(xí)常用的訓(xùn)練方法大致可以分為兩類(lèi):一類(lèi)是一致性正則化,該方法通過(guò)對(duì)未標(biāo)記的圖像施加不同的擾動(dòng)來(lái)構(gòu)建正則化損失,鼓勵(lì)對(duì)同一圖像的不同擾動(dòng)來(lái)產(chǎn)生類(lèi)似的預(yù)測(cè),其中擾動(dòng)包括模型級(jí)擾動(dòng)[8]、圖像增強(qiáng)[9-12]和對(duì)抗性訓(xùn)練[13];另一類(lèi)是自我訓(xùn)練,又名偽標(biāo)記方法,教師模型使用弱圖像增強(qiáng)數(shù)據(jù)為預(yù)測(cè)結(jié)果打上偽標(biāo)簽,而利用強(qiáng)圖像增強(qiáng)的數(shù)據(jù)送給學(xué)生模型訓(xùn)練,然后與已標(biāo)記的數(shù)據(jù)聯(lián)合訓(xùn)練模型.在偽標(biāo)記方法中,偽標(biāo)簽通常使用基于置信度的閾值過(guò)濾處理,教師模型只能保留具有高置信度的圖像作為偽標(biāo)簽.
近年來(lái)應(yīng)用有標(biāo)數(shù)據(jù)和無(wú)標(biāo)數(shù)據(jù)訓(xùn)練網(wǎng)絡(luò)的半監(jiān)督學(xué)習(xí)取得了重要進(jìn)展,但是大部分研究都聚焦于圖像分類(lèi)任務(wù),對(duì)于需要大量注釋的目標(biāo)檢測(cè)任務(wù)少有涉及.文獻(xiàn)[14]作為半監(jiān)督目標(biāo)檢測(cè)的最先一批的算法,它首先通過(guò)預(yù)先訓(xùn)練好的模型生成偽標(biāo)簽,然后將它們反饋給網(wǎng)絡(luò),并通過(guò)調(diào)整損失函數(shù)比重進(jìn)行模型微調(diào).文獻(xiàn)[15]為未標(biāo)記的數(shù)據(jù)引入了更復(fù)雜的增強(qiáng)功能,包括Mix-up和Mosiac.目前的這些半監(jiān)督目標(biāo)檢測(cè)方法,均是在Faster-RCNN[16]進(jìn)行的實(shí)驗(yàn),目前尚無(wú)在YOLO[17]系列的目標(biāo)檢測(cè)模型上相關(guān)的半監(jiān)督目標(biāo)檢測(cè)工作.相比Faster-RCNN,YOLO系列模型兼具速度快和精度高的優(yōu)點(diǎn),最新推出的YOLO系列模型PPYOLOE,在MS COCO[18]數(shù)據(jù)集中已經(jīng)接近目前基于CNN[19]的目標(biāo)檢測(cè)算法的最高精度,因此將半監(jiān)督學(xué)習(xí)應(yīng)用到Y(jié)OLO系列模型中,將可能突破模型精度提升的瓶頸,考慮到Y(jié)OLO模型的復(fù)雜結(jié)構(gòu),將半監(jiān)督學(xué)習(xí)方法應(yīng)用到Y(jié)OLO系列不是一件簡(jiǎn)單的工作.
本文采用師生互助訓(xùn)練方式,設(shè)計(jì)了在線(xiàn)偽標(biāo)簽更新的半監(jiān)督學(xué)習(xí)框架PPYOLOE-SSOD,在該框架中教師能夠?qū)崟r(shí)向?qū)W生模型傳遞偽標(biāo)簽,并進(jìn)行教師模型參數(shù)的實(shí)時(shí)更新,提高了模型的訓(xùn)練速度和精度;此外,本文改進(jìn)了無(wú)監(jiān)督分支的偽標(biāo)簽策略,在分類(lèi)分支引入質(zhì)量焦點(diǎn)損失(quality focal loss)[20],并在回歸分支引入分布焦點(diǎn)損失(distribution focal loss)[21],使用更適合于YOLO系列無(wú)錨框密集檢測(cè)器的密集偽標(biāo)簽方案,避免了冗余的后處理,使訓(xùn)練速度和精度得到提升;之后,本文為半監(jiān)督目標(biāo)檢測(cè)框架設(shè)計(jì)了多種強(qiáng)數(shù)據(jù)增強(qiáng)和弱數(shù)據(jù)增強(qiáng),通過(guò)對(duì)輸入圖像施加不同程度的擾動(dòng),降低網(wǎng)絡(luò)過(guò)擬合到少量標(biāo)注數(shù)據(jù)的風(fēng)險(xiǎn).在MS COCO數(shù)據(jù)集上的實(shí)驗(yàn)表明,在1%、5%、10%的標(biāo)注數(shù)據(jù)上精度分別能夠提升1.4%、1.6%、2.1%,充分證明了本文方法的有效性.
1?相關(guān)工作
1.1?YOLO系列目標(biāo)檢測(cè)
單級(jí)目標(biāo)探測(cè)器由于其優(yōu)異的速度和精度的權(quán)衡而在實(shí)時(shí)應(yīng)用中非常流行.在單級(jí)探測(cè)器中,最突出的體系結(jié)構(gòu)是YOLO系列[22-24].YOLO目標(biāo)檢測(cè)算法的核心在于模型的體積小,計(jì)算速度快.它可以通過(guò)神經(jīng)網(wǎng)絡(luò)直接輸出邊界框的位置和類(lèi)別.自YOLO模型提出以來(lái),YOLO系列標(biāo)檢測(cè)器在網(wǎng)絡(luò)結(jié)構(gòu)、標(biāo)簽分配等方面都發(fā)生了巨大的變化.YOLO系列檢測(cè)器通常由兩部分組成:一個(gè)是提取特征的主干網(wǎng)絡(luò),即基礎(chǔ)網(wǎng)絡(luò),一般在ImageNet數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練;另一個(gè)是預(yù)測(cè)對(duì)象類(lèi)別和邊界框的頭部.近幾年,頸部被構(gòu)建在主干與頭部之間,用于匯集不同的特征圖.以往的YOLO模型以基于錨定的方式分配地面真值框(GTbox).然而,錨框機(jī)制引入了許多超參數(shù),并依賴(lài)于手工設(shè)計(jì),基于上述原因,PP-YOLOv2[25]中引入了無(wú)錨框方法.此外為了得到全局最優(yōu)的分配策略,YOLOX[26]引入了先進(jìn)的動(dòng)態(tài)標(biāo)簽分配方法SIMOTA,以提高標(biāo)簽匹配的準(zhǔn)確度,在精度方面顯著優(yōu)于YOLOv5[27].
1.2?半監(jiān)督目標(biāo)檢測(cè)
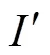
2?本文算法
圖1展示了本文的半監(jiān)督算法結(jié)構(gòu),本文使用的半監(jiān)督算法框架總共包含兩個(gè)PPYOLOE模型,分別被稱(chēng)作學(xué)生模型和教師模型.在訓(xùn)練過(guò)程中有標(biāo)注圖像和經(jīng)過(guò)強(qiáng)圖像增強(qiáng)的未標(biāo)注圖像被送入學(xué)生模型中,經(jīng)過(guò)弱圖像增強(qiáng)的未標(biāo)注圖像被送入教師模型中,將教師模型的預(yù)測(cè)結(jié)果作為偽標(biāo)簽來(lái)指導(dǎo)學(xué)生模型訓(xùn)練.學(xué)生模型通過(guò)標(biāo)記圖像和未標(biāo)記圖像的檢測(cè)損失來(lái)學(xué)習(xí).學(xué)生模型參數(shù)通過(guò)指數(shù)移動(dòng)平均方法(EMA)[32]對(duì)教師模型的參數(shù)進(jìn)行更新.損失函數(shù)的計(jì)算為
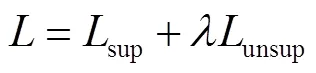



圖1? PPYOLOE-SSOD半監(jiān)督檢測(cè)算法流程
教師模型在訓(xùn)練過(guò)程中只進(jìn)行偽標(biāo)簽推理,不進(jìn)行梯度反向傳播,EMA參數(shù)更新為
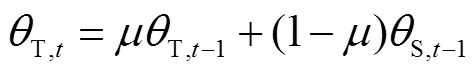
2.1?PPYOLOE介紹
本文的半監(jiān)督目標(biāo)檢測(cè)算法所選用的基準(zhǔn)模型是PPYOLOE的s版本,其網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示. PPYOLOE在速度和準(zhǔn)確性權(quán)衡方面優(yōu)于YOLOv5和YOLOX.在640×640的分辨率下,PPYOLOE-s的mAP=43.7,F(xiàn)PS=208.3.在特征提取網(wǎng)絡(luò)部分其保持著優(yōu)越的泛化能力和訓(xùn)練速度,設(shè)計(jì)了CSPRepResNet作為主干網(wǎng)絡(luò),頸部網(wǎng)絡(luò)也采用了新設(shè)計(jì)的CSPPAN,通過(guò)神經(jīng)網(wǎng)絡(luò)寬度乘法和深度乘法靈活地配置模型的大小.PPYOLOE的頭部網(wǎng)絡(luò)可以認(rèn)為是任務(wù)相關(guān)的自回歸模塊,由于分類(lèi)和回歸需要關(guān)注的高層語(yǔ)義特征不同,PPOYOLOE將輸入的特征解碼成回歸任務(wù)和分類(lèi)任務(wù)相關(guān)的特征,使用ESE模塊替換TOOD[33]中的層注意力模塊,將分類(lèi)分支的對(duì)齊簡(jiǎn)化,將回歸分支的損失函數(shù)替換為分布焦點(diǎn)損失,以TOOD中的頭部網(wǎng)絡(luò)為基礎(chǔ)去掉冗余的卷積,引入解耦特征結(jié)構(gòu)和通道層的自注意力機(jī)制,來(lái)提取更加細(xì)致的特征.

圖2?PPYOLOE算法結(jié)構(gòu)
2.2?無(wú)監(jiān)督標(biāo)簽匹配策略:密集偽標(biāo)簽
以往的目標(biāo)檢測(cè)算法選擇教師模型預(yù)測(cè)的分類(lèi)分?jǐn)?shù)大于指定分類(lèi)分?jǐn)?shù)閾值的預(yù)測(cè)框作為偽標(biāo)簽,并經(jīng)過(guò)非極大值抑制處理(NMS)后送入學(xué)生模型進(jìn)行損失計(jì)算,然而這種方法不僅對(duì)模型的非極大值抑制參數(shù)的選擇有苛刻的要求,還會(huì)造成一定的監(jiān)督信息損失.如圖3所示,本文對(duì)訓(xùn)練集上的圖像進(jìn)行了偽標(biāo)簽的可視化,通過(guò)修改密集偽標(biāo)簽的學(xué)習(xí)區(qū)域,可以通過(guò)選擇額外的樣本來(lái)很容易地實(shí)現(xiàn)硬負(fù)挖掘,綠色點(diǎn)表示地面真值框的特征點(diǎn)分布,紅色點(diǎn)和藍(lán)色點(diǎn)分別表示采用NMS 和密集偽標(biāo)簽的方式特征點(diǎn)分布.經(jīng)過(guò)NMS后大部分特征點(diǎn)被過(guò)濾掉,造成了一定量的監(jiān)督信息損失,而密集偽標(biāo)簽很好地保留了物體的關(guān)鍵信息.
與經(jīng)過(guò)NMS選取的硬標(biāo)簽不同,密集偽標(biāo)簽的分類(lèi)分?jǐn)?shù)表示連續(xù)值(值在0~1之間),由于PPYOLOE所使用的分類(lèi)損失函數(shù)變焦點(diǎn)損失(varifocal loss)只能處理離散的二進(jìn)制值(0或1),本文改進(jìn)了質(zhì)量焦點(diǎn)損失作為無(wú)監(jiān)督部分的分類(lèi)損失函數(shù),其計(jì)算式為

圖3 使用NMS閾值過(guò)濾的偽標(biāo)簽選擇策略與密集偽標(biāo)簽選擇策略對(duì)比
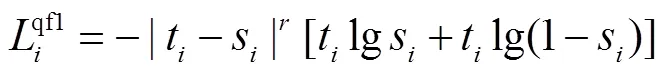
步驟1 統(tǒng)計(jì)最后一層特征層的特征點(diǎn)數(shù),=××(和表示特征層的長(zhǎng)和寬,表示訓(xùn)練批次).
步驟2 選取前×作為保留的特征點(diǎn)數(shù)量.
步驟3 根據(jù)個(gè)特征點(diǎn)所預(yù)測(cè)的訓(xùn)練集類(lèi)別中的最大值進(jìn)行排序,選擇分類(lèi)分?jǐn)?shù)最大的前×個(gè)特征點(diǎn)作為計(jì)算無(wú)監(jiān)督損失值的特征點(diǎn).
步驟4 根據(jù)前×個(gè)特征點(diǎn)的索引值選擇對(duì)應(yīng)的方框和分類(lèi)分?jǐn)?shù).
步驟5 計(jì)算無(wú)監(jiān)督部分的分類(lèi)損失和回歸損失,分類(lèi)損失函數(shù)和回歸損失函數(shù)以及額外的分布焦點(diǎn)損失函數(shù)的表示分別為



2.3?圖像增強(qiáng)策略
在引入未標(biāo)注數(shù)據(jù)學(xué)習(xí)時(shí),由于缺乏監(jiān)督信息,這些未標(biāo)注數(shù)據(jù)很容易關(guān)注模型的訓(xùn)練偏離的有效目標(biāo),由于模型的學(xué)習(xí)能力本身較強(qiáng),從而導(dǎo)致模型在半監(jiān)督學(xué)習(xí)中過(guò)擬合大量的未標(biāo)注數(shù)據(jù),并且由于YOLO系列模型缺乏二級(jí)檢測(cè)器對(duì)預(yù)測(cè)框的二次處理,本文重新設(shè)計(jì)了PPYOLOE的圖像增強(qiáng)策略.
本文對(duì)教師模型和學(xué)生模型分別使用不同強(qiáng)度的圖像增強(qiáng),具體地,對(duì)教師模型的輸入采用弱圖像增強(qiáng)(圖像旋轉(zhuǎn)、圖像縮放等),保證偽標(biāo)簽的質(zhì)量;而對(duì)學(xué)生的輸入,采用強(qiáng)圖像增強(qiáng)(高斯噪聲、顏色抖動(dòng)、隨機(jī)擦除和灰度變換等),增加學(xué)生模型的訓(xùn)練難度,防止過(guò)擬合.在訓(xùn)練過(guò)程中所使用的圖像增強(qiáng)效果如圖4所示,圖4(a)表示沒(méi)經(jīng)過(guò)圖像增強(qiáng)的圖像(原圖),圖4(b)、(c)、(d)、(e)分別表示經(jīng)過(guò)高斯噪聲、顏色抖動(dòng)、隨機(jī)擦除和灰度變換后的圖像.
(a)原圖 (b)高斯噪聲 (c)顏色抖動(dòng) (d)隨機(jī)擦除 (e)灰度變換
圖4?教師模型所使用的強(qiáng)數(shù)據(jù)增強(qiáng)
Fig. 4?Strong data augmentations used in the teacher model
2.4?實(shí)時(shí)更新偽標(biāo)簽和模型參數(shù)的方法
如圖5(a)所示,在以往的半監(jiān)督圖像分類(lèi)方法中通常用有標(biāo)注數(shù)據(jù)訓(xùn)練一個(gè)教師模型;生成偽標(biāo)簽,將無(wú)標(biāo)注數(shù)據(jù)輸入進(jìn)教師網(wǎng)絡(luò)中,得到的目標(biāo)框預(yù)測(cè)結(jié)果,將這些目標(biāo)框預(yù)測(cè)結(jié)果作為偽標(biāo)簽存儲(chǔ)在偽標(biāo)簽庫(kù)中,待所有的未標(biāo)記圖像均被打上偽標(biāo)簽后使用這些偽標(biāo)簽重新載入到數(shù)據(jù)加載器中進(jìn)行模型的無(wú)監(jiān)督訓(xùn)練.然而這種方法無(wú)法做到隨著訓(xùn)練進(jìn)程實(shí)時(shí)更新偽標(biāo)簽,導(dǎo)致在模型的性能有所提高時(shí),下一個(gè)迭代的偽標(biāo)簽的質(zhì)量沒(méi)能做到及時(shí)更新,因此本文重新設(shè)計(jì)半監(jiān)督算法的偽標(biāo)簽標(biāo)注流程,如圖5(b)所示,本文新建立了用于半監(jiān)督兩種數(shù)據(jù)加載器,一種是用于傳遞監(jiān)督數(shù)據(jù)的加載器,另一種是無(wú)監(jiān)督數(shù)據(jù)加載器.無(wú)監(jiān)督數(shù)據(jù)加載器在每個(gè)迭代分別向教師模型和學(xué)生模型送入同一未標(biāo)記圖像,并在該迭代直接對(duì)教師的偽標(biāo)記計(jì)算損失值,更新學(xué)生參數(shù),之后教師模型的參數(shù)會(huì)通過(guò)EMA方式同步得到更新,使教師模型下一迭代得到的偽標(biāo)簽有更高的質(zhì)量.

(a)離線(xiàn)更新偽標(biāo)簽和模型參數(shù)方法

(b)實(shí)時(shí)更新偽標(biāo)簽和模型參數(shù)方法
圖5?偽標(biāo)簽更新方法比較
Fig.5?Comparison of pseudo label update methods
3?實(shí)驗(yàn)結(jié)果與分析
3.1?實(shí)驗(yàn)數(shù)據(jù)集
本文在目標(biāo)檢測(cè)公開(kāi)數(shù)據(jù)集MS COCO和PASCAL VOC數(shù)據(jù)集上驗(yàn)證所提方法的有效性,MS COCO數(shù)據(jù)集包含 80個(gè)目標(biāo)類(lèi)別,它包含約115000 張訓(xùn)練圖像、5000張驗(yàn)證圖像本文使用訓(xùn)練集(train2017)訓(xùn)練,使用驗(yàn)證集(val2017)進(jìn)行評(píng)估.PASCAL VOC數(shù)據(jù)集則使用VOC07 test數(shù)據(jù)集評(píng)估.在目標(biāo)檢測(cè)中,因?yàn)橛形矬w定位框,圖像分類(lèi)中的精度并不適用,本文使用均值平均精度(mean of average precision,mAP)作為評(píng)價(jià)指標(biāo),均值平均精度表示所有類(lèi)別的平均精度求和除以所有類(lèi)別.
3.2?實(shí)施細(xì)節(jié)
本文代碼使用PPYOLOE在obj365數(shù)據(jù)集上的預(yù)訓(xùn)練,用8張23G P40顯卡訓(xùn)練模型在前80批次進(jìn)行全監(jiān)督訓(xùn)練,在這個(gè)訓(xùn)練過(guò)程中,不使用無(wú)標(biāo)注數(shù)據(jù),學(xué)習(xí)策略使用動(dòng)量=0.9和權(quán)重衰減系數(shù)=0.0005的隨機(jī)梯度下降(SGD),基礎(chǔ)學(xué)習(xí)率為0.01,使用余弦學(xué)習(xí)速率調(diào)度,總時(shí)間段為80批次,預(yù)熱階段為3批次,在預(yù)熱階段使用ATSSAssigner靜態(tài)匹配策略,在預(yù)熱階段后,使用TaskAlignedAssigner動(dòng)態(tài)策略,總批次為64.在經(jīng)過(guò)80批次的全監(jiān)督訓(xùn)練后,開(kāi)啟半監(jiān)督訓(xùn)練,對(duì)學(xué)生模型和教師模型分別載入全監(jiān)督階段訓(xùn)練好的權(quán)重參數(shù),在此過(guò)程中向?qū)W生模型送入有標(biāo)注數(shù)據(jù)以及經(jīng)過(guò)強(qiáng)圖像增強(qiáng)的未標(biāo)注數(shù)據(jù),向教師模型送入經(jīng)過(guò)弱圖像增強(qiáng)的未標(biāo)注數(shù)據(jù),在半監(jiān)督訓(xùn)練過(guò)程持續(xù)80批次,使用TaskAlignedAssigner動(dòng)態(tài)策略基本學(xué)習(xí)率為0.01,無(wú)監(jiān)督部分的總批次為128,有監(jiān)督部分的總批次同樣為128.無(wú)監(jiān)督部分和有監(jiān)督部分權(quán)重為1∶1,無(wú)監(jiān)督部分的分類(lèi)損失、回歸損失和DFL損失比為1.0∶2.5∶0.5.
3.3?方法有效性驗(yàn)證
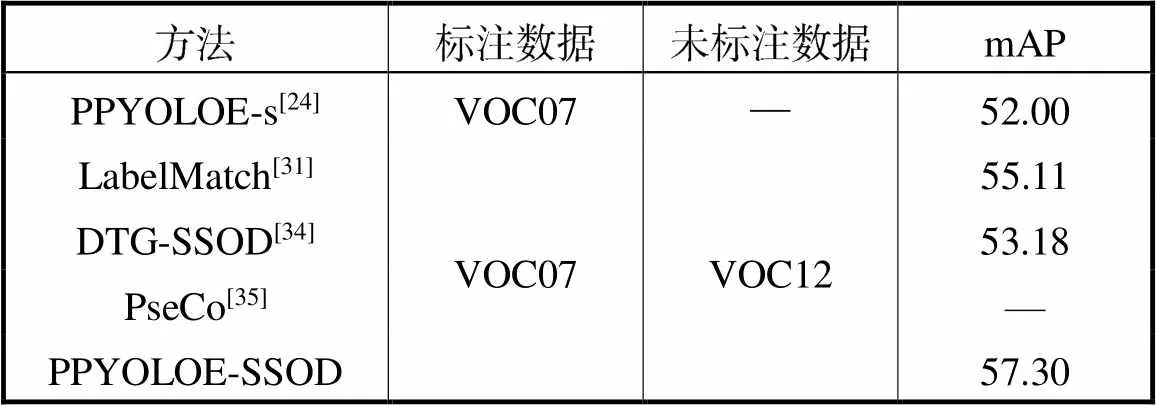
本文方法和PPYOLOE-s的全監(jiān)督訓(xùn)練結(jié)果以及其他半監(jiān)督目標(biāo)檢測(cè)算法在MS COCO數(shù)據(jù)集和PASCAL VOC數(shù)據(jù)集上進(jìn)行了比較.遵循STAC的有效性驗(yàn)證方式,使用MS COCO數(shù)據(jù)集的訓(xùn)練集train2017中的1%、5%和10%的圖像采樣作為標(biāo)記的訓(xùn)練數(shù)據(jù),以train2017剩余的未采樣圖像作為未標(biāo)記訓(xùn)練數(shù)據(jù).對(duì)于所有比例的標(biāo)注數(shù)據(jù)集,STAC隨機(jī)抽取5個(gè)不同的數(shù)據(jù)組,得到的最終的性能指標(biāo)是這5個(gè)數(shù)據(jù)組上的平均值.實(shí)驗(yàn)結(jié)果如表1所示,在使用1%、5%和10%的訓(xùn)練集數(shù)據(jù)作為有標(biāo)記數(shù)據(jù)集進(jìn)行半監(jiān)督訓(xùn)練,PPYOLOE模型精度mAP分別提升了1.4%、1.6%、2.1%.使用PASCAL VOC數(shù)據(jù)集的VOC07數(shù)據(jù)集作為有標(biāo)注數(shù)據(jù),VOC12作為無(wú)標(biāo)注數(shù)據(jù),實(shí)驗(yàn)結(jié)果如表2所示.在半監(jiān)督訓(xùn)練中,PPYOLOE模型精度mAP提升了5.3%.
3.4?消融實(shí)驗(yàn)
所有消融實(shí)驗(yàn)均是在訓(xùn)練集的10%作為有標(biāo)注數(shù)據(jù)其余作為無(wú)標(biāo)注數(shù)據(jù)的設(shè)置下進(jìn)行的,本文對(duì)所使用的無(wú)監(jiān)督學(xué)習(xí)密集偽偽標(biāo)簽選擇策略與其他半監(jiān)督目標(biāo)檢測(cè)算法中的硬標(biāo)簽選擇策略非極大值抑制進(jìn)行了比較,使用密集偽標(biāo)簽選擇策略相比于硬標(biāo)簽選擇策略,mAP提升了0.4%,訓(xùn)練速度由平均訓(xùn)練2.4張/s,提升至平均訓(xùn)練3.1張/s.
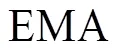
表1 PPYOLOE-SSOD在MS COCO數(shù)據(jù)集半監(jiān)督訓(xùn)練精度提升效果

Tab.1 PPYOLOE-SSOD accuracy improvement effect in MS COCO
表2 PPYOLOE-SSOD在PASCAL VOC數(shù)據(jù)集的半監(jiān)督訓(xùn)練精度
Tab.2 Semi-supervised training accuracies of PPYOLOE-SSOD in the PASCAL VOC dataset
表3?特征點(diǎn)選擇區(qū)域?qū)Ρ葘?shí)驗(yàn)

Tab.3 Comparison experiment of feature point selection area
表4?半監(jiān)督訓(xùn)練中使用的強(qiáng)圖像增強(qiáng)

Tab.4 Strong image enhancement used in semi-supervised training
表5?EMA權(quán)重更新參數(shù)對(duì)比實(shí)驗(yàn)

Tab.5 Comparison experiment of EMA weighting pa-rameter update
3.5?實(shí)驗(yàn)結(jié)果可視化
為了充分驗(yàn)證密集偽標(biāo)簽策略的有效性,本文對(duì)PPYOLOE-SSOD模型的頭部分類(lèi)分?jǐn)?shù)預(yù)測(cè)結(jié)果進(jìn)行了可視化,如圖6所示,分類(lèi)得分高的區(qū)域均準(zhǔn)確地對(duì)應(yīng)在了需要檢測(cè)的物體目標(biāo)上.

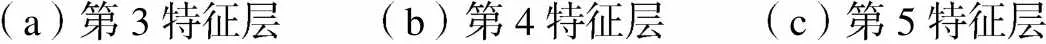
(a)第3特征層(b)第4特征層(c)第5特征層
與監(jiān)督基線(xiàn)相比,本文方法的可視化檢測(cè)結(jié)果如圖7所示,圖7(a)、(b)分別表示使用半監(jiān)督方法前后的檢測(cè)效果,可以觀察到使用本文提出的半監(jiān)督方法后,模型能夠檢測(cè)出大部分漏檢物體,檢測(cè)精度提高.訓(xùn)練過(guò)程的損失曲線(xiàn)如圖8所示.在訓(xùn)練的早期階段,網(wǎng)絡(luò)的精度不足,難以獲得高質(zhì)量的偽標(biāo)簽.半監(jiān)督模型的損失大部分由有標(biāo)注數(shù)據(jù)獲得,隨著模型精度的提升,有監(jiān)督部分損失逐漸減小,更多高質(zhì)量的偽標(biāo)簽參與訓(xùn)練,導(dǎo)致模型的損失上升,隨著半監(jiān)督訓(xùn)練趨于飽和,模型總體的損失曲線(xiàn)下降,并趨于平穩(wěn).

(a)PPYOLOE-s預(yù)測(cè)結(jié)果 (b)PPYOLOE-SSOD預(yù)測(cè)結(jié)果
圖7?模型預(yù)測(cè)結(jié)果可視化展示
Fig.7?Visual display of model prediction results
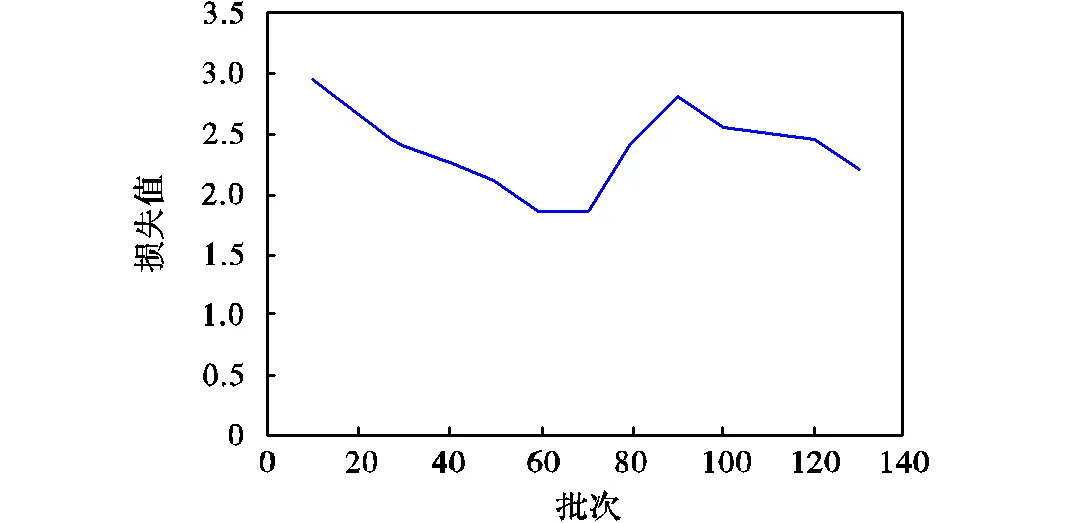
圖8?損失變化曲線(xiàn)
4?結(jié)?語(yǔ)
本文針對(duì)全監(jiān)督學(xué)習(xí)的模型精度難以提升以及數(shù)據(jù)集注釋難以獲取的問(wèn)題,提出了一種新型的基于YOLO系列的半監(jiān)督目標(biāo)檢測(cè)方法(PPYOLOE-SSOD).該方法利用教師學(xué)生互助訓(xùn)練方式挖掘未標(biāo)注數(shù)據(jù)的知識(shí)信息,并通過(guò)密集學(xué)習(xí)的偽標(biāo)簽選擇策略,使模型避免了硬標(biāo)簽依賴(lài)于非極大值抑制等冗余后處理的困擾,并改進(jìn)了模型的圖像增強(qiáng)方法和訓(xùn)練流程,使模型的訓(xùn)練速度和最終精度得到了進(jìn)一步提升,本文在MS COCO公開(kāi)數(shù)據(jù)集上比對(duì)了本文算法與監(jiān)督基線(xiàn)算法和其他半監(jiān)督檢測(cè)算法的檢測(cè)性能,并通過(guò)對(duì)比實(shí)驗(yàn)驗(yàn)證了本文算法的有效性,明顯優(yōu)于其他半監(jiān)督目標(biāo)檢測(cè)算法.
[1] Deng J,Xuan X J,Wang W F,et al. A review of re-search on object detection based on deep learning [C]//Journal of Physics Conference Series. Kunming,China,2020:12028-12067.
[2] Park H J,Kang J W,Kim B G. SSFPN:Scale se-quence(S2)feature-based feature pyramid network for object detection[J]. Sensors,2023,23(9):4432-4440.
[3] Carion N,Massa F,Synnaeve G,et al. End-to-end object detection with transformers[C]//Computer Vision-ECCV 2020:16th European Conference. Glasgow,UK,2020:213-229.
[4] Sohn K,Berthelot D,Carlini N,et al. Fixmatch:Simplifying semi-supervised learning with consistency and confidence[C]//Advances in Neural Information Processing Systems. Beijing,China,2020:596-608.
[5] Zhou H Y,Ge Z,Liu S T,et al. Dense teacher:Dense pseudo-labels for semi-supervised object detec-tion[C]//Computer Vision-ECCV 2022:17th European Conference. Tel Aviv,Israel,2022:35-50.
[6] Zang Y H,Zhou K Y,Huang C,et al. Semi-supervised and long-tailed object detection with CascadeMatch[J]. International Journal of Computer Vision,2023,131(3):1-15.
[7] Chen G B,Choi W G,Yu X,et al. Learning efficient object detection models with knowledge distilla-tion[C]//Advances in Neural Information Processing Systems. Long Beach,USA,2017:1010-1022.
[8] Berthelot D,Carlini N,Goodfellow I,et al. Mixmatch:A holistic approach to semi-supervised learning[C]//Advances in Neural Information Processing Systems. Vancouver,Canada,2019:980-994.
[9] Zhang X F,Dai L W. Image enhancement based on rough set and fractional order differentiator[J]. Fractal and Fractional,2022,6(4):214-215.
[10] Yan H,Zhang J X,Zhang X F. Injected infrared and visible image fusion via L1decomposition model and guided filtering[J]. IEEE Transactions on Computational Imaging,2022,8(3):162-173.
[11] Zhang X F,Liu R,Ren J X,et al. Adaptive fractional image enhancement algorithm based on rough set and particle swarm optimization[J]. Fractal and Fractional,2022,6(2):100-101.
[12] Shorten C,Khoshgoftaar T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data,2019,6(1):1-48.
[13] Din N U,Javed K,Bae S,et al. A novel GAN-based network for unmasking of masked face[J]. IEEE Access,2020,8:44276-44287.
[14] Sohn K,Zhang Z,Li C L,et al. A simple semi-supervised learning framework for object detection [EB/OL]. https://arxiv.org/abs/2005.04757,2020-05-10.
[15] Zhou Q,Yu C H,Wang Z B,et al. Instant-teaching:An end-to-end semi-supervised object detection frame-work[C]//2021 IEEE/CVF Conference on Computer Vi-sion and Pattern Recognition. Kuala Lumpur,Malaysia,2021:4081-4090.
[16] Ren S Q,He K M,Girshick R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems. Montreal,Canada,2015:28-36.
[17] Redmon J,Divvala S,Girshick R,et al. You only look once:Unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Rec-ognition. Las Vegas,USA,2016:779-788.
[18] Lin T Y,Maire M,Belongie S,et al. Microsoft coco:Common objects in context[C]//Computer Vi-sion-ECCV 2014:13th European Conference. Zurich,Switzerland,2014:740-755.
[19] Neelapu R,Devi G L,Rao K S. Deep learning based conventional neural network architecture for medical im-age classification[J]. Traitement Du Signal,2018,35(2):169.
[20] Li X,Wang W H,Wu L J,et al. Generalized focal loss:Learning qualified and distributed bounding boxes for dense object detection[C]//Advances in Neural In-formation Processing Systems. Beijing,China,2020:21002-21012.
[21] Li X,Wang W H,Hu X L,et al. Generalized focal loss v2:Learning reliable localization quality estimation for dense object detection[C]//2021 IEEE/CVF Confer-ence on Computer Vision and Pattern Recognition. Kuala Lumpur,Malaysia,2021:11632-11641.
[22] Li C Y,Li L L,Jiang H L,et al. YOLOv6:A single-stage object detection framework for industrial applica-tions[EB/OL]. https://arxiv.org/abs/2209.02976,2022-09-07.
[23] Wang C Y,Bochkovskiy A,Liao H Y M. YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. https://arxiv.org/abs/ 2209.02976,2022-07-06.
[24] Xu S L,Wang X X,Lü W Y,et al. PP-YOLOE:An evolved version of YOLO[EB/OL]. https://arxiv.org/abs/ 2203.16250,2022-03-30.
[25] Huang X,Wang X X,Lü W Y,et al. PP-YOLOv2:A practical object detector[EB/OL]. https://arxiv.org/abs/ 2104.10419,2021-04-21.
[26] Ge Z,Liu S T,Wang F,et al. Yolox:Exceeding yolo series in 2021[EB/OL]. https://arxiv.org/abs/2107. 08430,2021-07-18.
[27] Wu T H,Wang T W,Liu Y Q. Real-time vehicle and distance detection based on improved YOLOv5 net-work[C]//2021 3rd World Symposium on Artificial Intel-ligence. Guangzhou,China,2021:24-28.
[28] Liu Y C,Ma C Y,He Z,et al. Unbiased teacher for semi-supervised object detection[EB/OL]. https://arxiv. org/abs/2102.09480,2021-02-18.
[29] Xu M D,Zhang Z,Hu H,et al. End-to-end semi-supervised object detection with soft teacher[C]//2021 IEEE/CVF International Conference on Computer Vision. Kuala Lumpur,Malaysia,2021:3060-3069.
[30] Zhang F Y,Pan T X,Wang B. Semi-supervised object detection with adaptive class-rebalancing self-training [C]//2022 AAAI Conference on Artificial Intelligence. Vancouver,Canada,2022:3252-3261.
[31] Chen B B,Chen W J,Yang S C,et al. Label matching semi-supervised object detection[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans,USA,2022:14381-14390.
[32] Tarvainen A,Valpola H. Mean teachers are better role models:Weight-averaged consistency targets improve semi-supervised deep learning results[C]//Advances in Neural Information Processing Systems. Long Beach,USA,2017:30-40.
[33] Feng C J,Zhong Y J,Gao Y,et al. TOOD:Task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision. Kuala Lumpur,Malaysia,2021:3490-3499.
[34] Li G,Li X,Wang Y J,et al. DTG-SSOD:Dense teacher guidance for semi-supervised object detection[EB/OL]. https://arxiv.org/abs/2209.02976,2022-07-06.
[35] Li G,Li X,Wang Y J,et al. Pseco:Pseudo labeling and consistency training for semi-supervised object de-tection[EB/OL]. http://arxiv.org/abs/2203.16317v1,2022-07-22.
Teacher-Student Mutual Training for Semi-Supervised Object DetectionBased on PPYOLOE
Zhang Guoshan,Wei Jinman
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
With the continuous advancements in deep learning,object-detection technology based on convolutional neural network has become a research hotspot in the field of computer vision. Currently,mainstream object-detection algorithms rely on supervised learning and training models on extensive labeled data. However,unlabeled data are easy to obtain,while labeled data are usually challenging,time-consuming,and labor-intensive to collect. This study proposed a semi-supervised object-detection(PPYOLOE-SSOD)algorithmbased on teacher-student mutual training to easily obtain data annotations. First,the student and gradually improved teacher models were trained simultaneously. The teacher model was then used to filter high-quality pseudo labels,which guided students during model training and extracted information from unlabeled images. Further,the exponential average method was used in each iteration to update the teacher model parameters to reduce the instability of parameter transfer. In addition,different data-augmentation methods were introduced to enhance the anti-interference ability of the network. Finally,the unsupervised learning branch was added for the learning of unlabeled data,and the features predicted by the model were processed using an intensive learning method. By sorting the classification features predicted by the teacher model,high-quality features were automatically selected as the pseudo labels generated by the teacher model,thus avoiding the tedious post-processing of pseudo labels and improving the accuracy and training speed of the network. On the MS COCO dataset,the accuracy of the PPYOLOE is improved by 1.4%,1.6%,and 2.1% on 1%,5%,and 10% labeled datasets,respectively,using the semi-supervised learning method. Compared with other SSOD algorithms,PPYOLOE-SSOD achieves the highest accuracy. The source code is at https://github.com/ wjm202/PPYYOLOE-SSOD.
semi-supervised learning;object detection;PPYOLOE;teacher-student mutual training
TP391.4
A
0493-2137(2024)04-0415-09
10.11784/tdxbz202302035
2023-02-22;
2023-06-23.
張國(guó)山(1961—??),男,博士,教授.
張國(guó)山,zhanggs@tju.edu.cn.
國(guó)家自然科學(xué)基金資助項(xiàng)目(62073237).
the National Natural Science Foundation of China(No.62073237).
(責(zé)任編輯:孫立華)
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
人大建設(shè)(2020年4期)2020-09-21 03:39:12
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
