注意力機制量化剪枝優化方法
2024-04-08 11:38:38何源宏姜晶菲許金偉
國防科技大學學報 2024年1期
何源宏,姜晶菲*,許金偉
(1. 國防科技大學 計算機學院, 湖南 長沙 410073; 2. 國防科技大學 并行與分布計算全國重點實驗室, 湖南 長沙 410073)
近年來,基于Transformer的模型(如BERT[1]、GPT-2[2])在機器翻譯、句子分類、問題回答等自然語言處理(natural language processing, NLP)任務中實現了最先進的(state-of-the-art, SOTA)成果。在一些具有挑戰性的任務上,典型的BERT模型處理效果甚至超過人類[3]。相比傳統的循環神經網絡[4](recurrent neural network, RNN)模型和長短期記憶[5](long short-term memory, LSTM)模型,基于Transformer的模型采用注意力機制[6],能更有效地捕獲輸入序列中的上下文信息,使得模型精度顯著提高。
在注意力機制的原始計算流程中,注意力機制的輸入由查詢(Q)、鍵(K)和值(V)三個激活值矩陣組成。注意力機制首先通過Q和K的相乘計算得到分數矩陣(S),然后采用歸一化指數函數(softmax)對分數矩陣進行逐行操作得出概率矩陣(P)。最后將P與V相乘得到輸出。相較于RNN和LSTM模型只計算了輸入的局部信息,注意力機制計算了每一對查詢向量和鍵向量的注意力結果,從而實現了對全局關系的提取。但由于注意力機制的計算開銷和輸入序列的長度的平方成正比,全局信息提取帶來模型精度提升的同時也使得計算復雜度大幅增加。例如,對于涉及圖像或長文本的任務,輸入的序列長度可能高達16×103,而對于具有16×103個Token的單個輸入序列,BERT-Base中一個自注意力模塊的浮點運算次數[7]高達861.9×109。基于注意力機制模型的計算復雜性給實時響應系統和移動設備上的開發部署帶來了巨大挑戰,模型的輕量化方法是解決計算難題的關鍵手段。
現有的大部分工作[7-19]著重于對基于注意力機制模型的權重進行量化和剪枝,取得了較好的效果。但是在計算復雜度較高的注意力機制中,大多數模型仍采用單精度浮點表示的稠密激活值矩陣進行運算,激活值不屬于權重量化剪枝的范疇,因此計算開銷依然很高。本文對基于注意力機制模型的優化訓練方法展開研究,通過有效的量化和剪枝方法對激活值矩陣進行量化和剪枝,從而達到大幅降低基于注意力機制模型的計算量和訪存量的目的,使得模型推理更適應輕量化智能應用的需求。
1 相關工作
深度神經網絡往往被認為是過度參數化的,目前學術界提出了許多方法去除冗余的參數來實現存儲或者計算的優化。使用的方法包括量化、剪枝、知識蒸餾、參數共享、專用的FPGA和ASIC加速器等[20-23]。
1.1 深度神經網絡的量化方法
量化指用低精度數(如定點8位)表示高精度數(如浮點32位)。除了可以減少神經網絡模型占用的空間大小,量化還能在支持低精度運算的硬件中提升模型運算速度。文獻[8]利用量化感知訓練(quantization-aware training, QAT)和對稱線性量化將BERT量化到8位定點整數,同時在下游任務中幾乎沒有精度損失,從而節省75%的存儲空間占用。文獻[9]利用權重矩陣的二階海森信息對BERT進行混合精度和分組量化。文獻[10]利用聚類的思想將BERT中99.9%的權重量化到3 bit,剩余權重按照原樣存儲,但是需要在專用硬件上實現推理過程。為了得到更高的模型壓縮比,文獻[11]使用三值化的權重分割來獲得二值化的權重,文獻[12]通過引入二值注意力機制和知識蒸餾[24]得到二值化的權重,雖然二值化后的模型理論上相較于原始模型可以獲得32倍的壓縮比,但是上述兩種方法均會導致模型精度相對于原始模型精度有顯著的下降,難以在實際應用中起到較好的效果。
1.2 深度神經網絡的剪枝方法
剪枝分為結構化剪枝和非結構化剪枝。非結構化剪枝去除不重要的神經元,可以顯著減少模型的參數量和理論計算量,但通用平臺擅長的規則計算難以利用其稀疏性,需要專用的硬件或者計算庫來支持稀疏矩陣運算。magnitude剪枝[13-15]是應用最廣泛也是效果較好的非結構化剪枝方法之一,該方法認為如果一個權重或激活值的絕對值越小,那么對后續結果的影響也越小,則可以將其置為0。文獻[14]發現在BERT的預訓練過程中,對權重使用magnitude剪枝在低稀疏度(0.3~0.4)情況下不會影響模型在下游任務中的精度,而在高稀疏度(高于0.7)情況下模型難以在下游任務中取得較好的效果。文獻[16-17]提出了一種基于訓練中權重移動方向的剪枝方法,該方法認為在訓練過程中,權重的更新如果越靠近0,則表明該權重越不重要;權重的更新如果越遠離0,則表明該權重越重要。
結構化剪枝通常以神經網絡中的一個注意力頭[18-19]或整層[18]為剪枝的基本單位。結構化剪枝的相關工作輸出的模型在計算模式上更匹配CPU、GPU規則計算構架,因此仍然可以通過CPU和GPU完成推理加速,但是存在稀疏度遠低于非結構化剪枝的稀疏度等劣勢。本文面向實時響應系統和低算力移動設備的計算優化需求,主要研究非結構化剪枝及量化在基于注意力機制模型上的計算優化技術,能夠在較好平衡任務準確率的條件下達到良好的計算壓縮效果。這種量化剪枝技術能輸出更為精簡、采用低位寬數據表示的稀疏化模型。面向該類模型,很多工作研究了低位寬智能加速器,通過專用結構高效處理低位寬數據,為低位寬計算和非結構化稀疏計算定制更適合的運算結構,如4位定點運算器、專用稀疏格式的數據運算通路等。相較于CPU、GPU等面向規則計算的體系結構,這些結構能進一步獲得大幅能效提升,更加適用于面向實時響應系統和低算力移動設備應用的需求。
2 量化剪枝優化方法
注意力機制的原始計算流程和優化后的計算流程如圖1所示,在本文提出的注意力機制模型量化剪枝優化總體流程中,輸入激活值矩陣Q、K、V是輸入信息在不同空間的表達,在BERT模型中具有相同的維度:①對于給定的輸入激活值矩陣Q、K、V,首先量化Q和K到4位或8位定點整數,計算分數矩陣的結果;②將分數矩陣進行反量化并送入softmax得到P;③將P中絕對值低于閾值的數剪枝為0;④將稀疏的P量化到4位或者8位定點整數并將其與量化后的V相乘,得到注意力機制的輸出結果。第②步和第③步進行反量化和量化操作的原因是直接將線性量化的數據送入softmax,這一類非線性運算會顯著影響模型在數據集上的精度[25],同時為了后續量化計算,需要將剪枝后的結果進行量化。考慮到對計算過程進行簡化,該方法根據是否為同一矩陣乘的輸入采取了分組量化,即Q和K為一組,P和V一組。同一組的兩個矩陣量化到相同的比特數,而不同組之間可以量化到不同比特數。

2.1 激活值矩陣的對稱線性量化方法
對稱線性量化、非對稱線性量化、非線性量化、K-means量化等是典型的模型量化方法[21]。對稱線性量化相較于其他方法所需的硬件計算更加簡單,更易于高效的專用加速器實現。本文采取的激活值矩陣的kbit對稱線性量化公式定義如下:
(1)
其中:Q是量化函數;r是輸入的原始數據;S是量化縮放因子;α是量化到kbit時的最大值,例如,當量化到4位時,α=7。由于注意力機制的輸入是動態變化的,故使用指數滑動平均(exponential moving average, EMA)來收集其信息,并在訓練的過程中確定S。clip是截斷函數,確保量化后的值不超出kbit所能表示的范圍。round函數起到四舍五入的作用。對稱線性量化本質上是將輸入r映射到對稱區間[-α,α]之中。對于反量化公式定義如下:
DQ(S,q)=S×q
(2)
式中,DQ是反量化函數,q表示輸入的量化值。量化過程和反量化過程均采用相同的S。訓練過程中為了傳遞量化誤差,本文采用量化感知訓練實現偽量化;同時考慮到round函數的不可導性,采用直通估計器(straight-through estimator, STE)進行梯度反向傳播。
2.2 漸進剪枝訓練
漸進剪枝策略[26]能有效避免剪枝帶來的模型精度顯著下降,參考其原理,本文采用magnitude剪枝方法實現,在每次剪枝迭代時,將待剪枝的激活值矩陣中絕對值低于預設閾值的數剪枝為0。訓練過程采用三段式漸進剪枝方法,在總迭代次數為T的訓練過程中,前ti次迭代只進行模型的微調;在ti到tf次迭代的過程中稀疏度s從0提升到預設的目標稀疏度st,在這期間s以三次函數的趨勢呈先快后慢的非線性增長;最后維持目標稀疏度st進行微調實現精度的回調。其中稀疏度s表示一個矩陣中數值為0的權重所占的比值,具體取值如分段函數(3)所示:
(3)

3 實驗分析
3.1 實驗設置
本文在BERT-Base[1]模型上針對通用語言理解評估[27](general language understanding evaluation, GLUE)基準進行了一系列的實驗分析。GLUE包含了9個數據集來對自然語言模型進行訓練、評估和分析,分別為CoLA、RTE、MRPC、STS-B、SST-2、QNLI、QQP、MNLI、WNLI,但是本文沒有在WNLI數據集上進行評估,因為它通常被認為存在一定的問題[1]。此外,本文也在問答任務SQuAD v1.1[28]上進行了評估。對于MRPC、QQP、SQuAD v1.1數據集采用F1值評估;對于STS-B數據集用皮爾遜相關系數評估;對于CoLA數據集用馬修斯相關系數評估;對于GLUE中剩余的數據集均采用準確率評估。所有數據集的評估指標都與模型的精度成正相關。
實驗中BERT實現代碼是基于HuggingFace 的Transformer庫[29],并在PyTorch深度學習框架完成了量化剪枝實驗和模型精度的評估。所有的實驗均運行在單GPU(NVIDIA Tesla V100 PCIe 32 GB)上。因為本文提出的方法不涉及預訓練,故直接將預訓練好的BERT-Base模型在數據集上進行量化剪枝訓練。CoLA、RTE、MRPC、STS-B數據集訓練時的批大小為8,學習率為2×10-5;SST-2、QNLI、QQP、MNLI、SQuAD v1.1數據集訓練時的批大小為32,學習率為3×10-5。每次訓練為10個epoch:①前3個epoch對應漸進稀疏的第一階段,模型的稀疏度為0;②接下來4個epoch對應漸進剪枝的第二個階段,此時稀疏度s隨時間從0增長到目標稀疏度st;③最后3個epoch對應漸進剪枝的第三個階段,此時維持目標稀疏度st對模型進行微調完成最后的訓練,該階段可以在一定程度上緩解剪枝帶來的模型精度損失。在整個訓練過程中,都實施本文提出的對稱線性量化流程。
3.2 實驗結果
圖2表明了各數據集在不同的目標稀疏度st(大于0.9)下對Q、K、V、P單獨剪枝的結果,基線表示沒有進行剪枝和量化的結果, 0.95*基線表示基線的95%的精度。首先,結果顯示Q和K在剪枝效果上具有一致性:即Q和K的結果曲線具有相似的變化趨勢。而P和V也有類似的性質。這表明同一個矩陣乘的兩個輸入具有相似的剪枝效果。其次,隨著稀疏度的提升,除CoLA數據集外,P和V的剪枝效果逐漸優于Q和K。本文認為這是因為P之前的softmax運算隱式的將重要的信息進行了提取,并賦予其較大的值,這也表明P更適合進行剪枝。最后,在較高的稀疏度(大于0.95)下,所有矩陣剪枝后的模型精度均出現了明顯的下降,尤其是Q和K。

(b) RTE數據集(b) RTE dataset

(c) MRPC數據集(c) MRPC dataset

(d) STS-B數據集(d) STS-B dataset
在單獨剪枝的基礎上,本文還比較了Q、K、V分別和P進行聯合剪枝后模型精度的差異,如圖3所示。從圖2和圖3的對比可以看出,在大多數情況下,Q、K、V在單獨剪枝中具有最好效果的那一個矩陣,在和P進行聯合剪枝時也會具有最好的效果。但是Q、K、V分別和P的聯合剪枝比單獨剪枝時的精度下降得更快。同時考慮到P的大小與輸入序列長度的大小的二次方成正比,故本文在接下來的量化實驗中只針對P進行剪枝。

(a) CoLA數據集(a) CoLA dataset

(b) RTE數據集(b) RTE dataset

(c) MRPC數據集(c) MRPC dataset

(d) STS-B數據集(d) STS-B dataset
實驗結合了量化和剪枝來探究量化帶來的影響。實驗設置了兩種量化位寬,分別是4位和8位。結合兩種量化位寬的設定和分組量化,圖4展示了四種量化方案和剪枝共同優化的結果。圖例中的8+4表明對于Q和K量化到8位,P和V量化到4位。從圖4中可以清楚地看到,在大多數情況下,量化對P的剪枝效果的影響較小。在STS-B數據集中,即使量化比特方案為4+4,在相同稀疏度水平下,量化剪枝比非量化剪枝還能獲得更好的結果,這表明量化和剪枝在實際的應用中具有正交性,同時量化能提升模型的魯棒性。
在STS-B和CoLA數據集中,不同量化比特方案產生的模型精度差異較小。但是在RTE和MRPC數據集中,不同的量化比特設定帶來了明顯的精度差異,表明不同的數據集對于量化的敏感程度不一樣。同時較低的量化比特設定并不意味著較低的模型精度。例如,4+4的量化方案在CoLA、MRPC、STS-B數據集中并不是精度最低的,甚至在STS-B數據集中,4+4的量化方案能獲得最好的整體效果,而8+8的量化方案在整體效果表現上最差。

(a) CoLA數據集(a) CoLA dataset

(b) RTE數據集(b) RTE dataset

(c) MRPC數據集(c) MRPC dataset

(d) STS-B數據集(d) STS-B dataset
在圖2到圖4的三組實驗中,RTE數據集均為結果波動較大的數據集之一,本文認為是RTE數據集對于量化和剪枝較敏感,特別是在量化和剪枝協同優化時,波動更為明顯。總體來說,即使在較高的稀疏度下,本文的量化方案也不會使模型的精度產生顯著的下降。
3.3 和Sanger的比較

一些相關研究表明[8-10],針對深度神經網絡一定程度的壓縮(量化、剪枝、知識蒸餾等)能夠提升模型的魯棒性,因此使得壓縮后模型的精度略微超過基線模型,而當壓縮率繼續提升時模型的精度可能會逐漸下降。但目前尚無相關研究能夠定量說明什么程度的壓縮能起到泛化的作用。從定性的角度,本文分析深度學習模型一般具有較大的信息冗余和噪聲,一定的壓縮使得這些冗余噪聲被更高比例去除,因此使得模型精度得以保持甚至略有上升。
3.4 計算輕量化分析
模型稀疏量化可以從計算次數和數據表示兩方面降低模型推理的計算量,提升計算速度。以BERT模型的一個自注意力頭模塊為例,推理任務的絕大多數計算是Q、K、P、V涉及的矩陣運算,對于兩個n階方陣的矩陣乘法,其他配套操作(包括量化、反量化、softmax、剪枝)的計算量約為其1/n,當n較大時,這部分運算量可忽略。模型計算復雜度一般由矩陣乘加量代表。當把模型稀疏度提升至x%時,稀疏模型計算復雜性約可降為原模型稠密矩陣計算的1-x%。稀疏矩陣一般以CSR稀疏格式存儲,大小約為稠密矩陣的2(1-x%)。同時,當模型將原有數據位寬W量化為W/y時,壓縮后數據的存儲量將降低為原來的1/y。
根據上述分析以及表1所獲得的BERT模型稀疏量化結果,在P×V計算稀疏度為95%、所有矩陣4+4量化協同優化下,得到式(4):
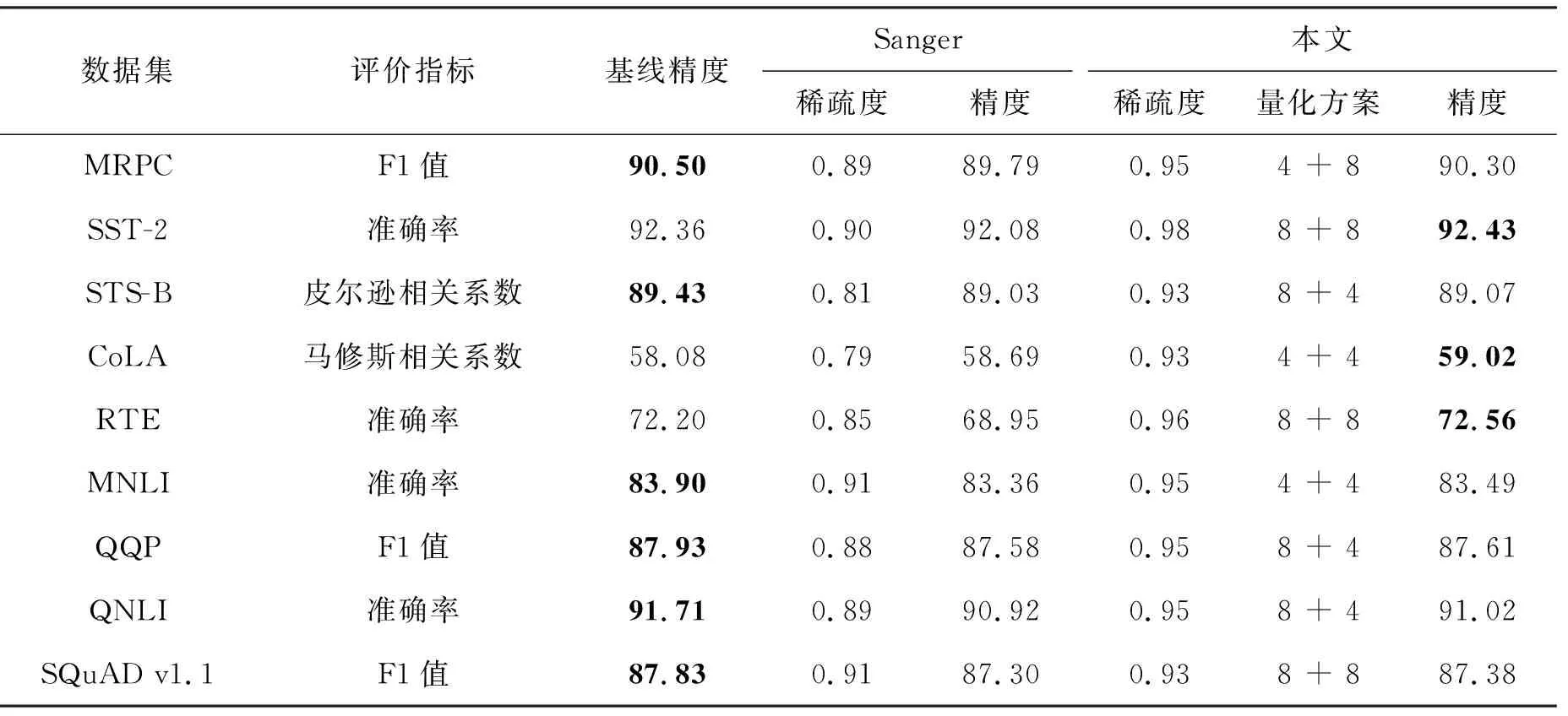
表1 不同數據集上的量化剪枝結果

(4)
整個模塊的理論推理速度可提升約16倍。其中:a為P×V計算量占比,(1-a)為Q×K計算量占比,在該模塊中a約為50%;sP為P的稀疏度;NPV和NQK分別為P、V和Q、K量化到N比特后N位定點運算相較于32位浮點運算的加速比,根據硬件運算單元速度的一般結論,4位定點乘加單元的運算速度為32位浮點乘加單元運算速度的8倍以上。就存儲量而言,4+4量化后Q、K、V占用存儲空間的大小可降為原始的1/8,同時在95%稀疏度下P的大小約為原始的1/80。
上述分析面向可有效處理稀疏運算和低位寬量化運算的定制加速器,有較多前沿相關工作[3,7]基于此思路開展,相較于通用平臺,加速器不僅能高效處理上述運算,還可消除CPU、GPU等由于指令和調度執行帶來的額外控制開銷,大幅提升最終性能。
4 結論
針對基于注意力機制模型計算復雜度和訪存開銷過高等問題,本文提出了一種量化剪枝協同優化方法,該方法通過采用對稱線性量化和漸進剪枝來降低注意力機制的計算復雜量。本文提出的方法在較低或者沒有精度損失的情況下,在BERT模型上有著較好的實驗效果,對于GLUE基準和SQuAD v1.1數據集,該方法將注意力機制運算涉及的Q、K、V、P采用分組量化,其中Q和K為一組,V和P為一組,分別量化到4位或者8位,并且剪枝P,最終可以得到0.93~0.98的稀疏度,大幅度降低模型計算量。在SST-2、CoLA、RTE數據集上,該優化方法得到的模型在精度上甚至超過了基線。
本文提出的方法在各方面也優于Sanger稀疏模式,包括稀疏度和最終的模型精度。但本文所提出優化方法是非結構化稀疏模式,該稀疏模式具有稀疏度高和難以在通用平臺加速等特點,故下一步的工作展望為在專用的硬件平臺上充分利用其量化和稀疏特性,將量化剪枝的理論計算性能提升轉換為實際推理能耗和延遲的降低。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年9期)2015-11-10 03:11:12
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年3期)2014-11-12 13:18:12
