存儲體編譯和布局協同的片上緩存設計方法
2024-04-08 11:39:12劉必慰宋雨露
國防科技大學學報 2024年1期
劉必慰,熊 琪,楊 茗,宋雨露
(1. 國防科技大學 計算機學院, 湖南 長沙 410073; 2. 國防科技大學 理學院, 湖南 長沙 410073; 3. 國防科技大學 軍政基礎教育學院, 湖南 長沙 410073)
現代微處理器和各種系統級芯片(system on chip,SoC)中都具有大容量片上緩存[1-2],它們一般由存儲體編譯器生成的靜態隨機存取存儲器(static random-access memory, SRAM)存儲體構成。這些單個存儲體容量一般在1 Kbit~1 Mbit。多個這樣的存儲體,經過粘合邏輯合并和選擇來形成各種大容量的Cache、Scratch Pad Memory、共享緩沖池等片上緩存結構。片上緩存的容量不斷增大,其面積可達到全芯片面積的30%~45%或更高,功耗占比也隨之提高,同時片上緩存往往也處于關鍵時序路徑,決定了全芯片頻率。因此進一步提高片上緩存的性能,并降低其功耗是提高芯片性能的關鍵。
現有的片上緩存的設計可劃分為三個獨立的階段:①存儲體編譯與生成方面,有學者研究了SRAM存儲體本身的定制優化設計[3-4],有的學者提出了高性能低功耗存儲編譯技術[5-6],也有學者在存儲體集成上開展研究——Gupta等提出使用異構的存儲體來優化片上存儲子系統的總體面積[7],閆戰磊等提出了超大容量存儲體的定制優化技術[8];②在存儲體布局方面,主要依賴于設計者人工進行,Cadence公司的mix placer工具[9]實現了自動存儲體布局的功能,相比人工布局在性能和功耗上均有改進;③存儲體相關粘合邏輯優化,通過現有的綜合和布局布線工具實現。
然而,現有的設計流程中這三個階段是相互割裂的。存儲體編譯時僅考慮存儲體的功能,存儲體布局時僅考慮存儲體的幾何尺寸,優化粘合邏輯時才考慮存儲體的時序。這使得在存儲體編譯時不得不預留較大的時序余量,從而造成不必要的面積和功耗開銷。
為了實現高性能、低功耗的片上緩存,本文提出了一種存儲體編譯和布局協同的設計方法,在存儲體編譯的同時就考慮該存儲體的位置信息,從而準確地制定存儲體編譯的時序要求,編譯出速度符合要求、功耗最優化的SRAM存儲體。
1 片上緩存構成與存儲體編譯空間
片上緩存的一般結構如圖1所示,主體是SRAM存儲體組成的存儲陣列;存儲陣列外是粘合邏輯——包括一系列的合并、選擇、寄存操作,或者總線協議轉換邏輯;最后輸出到外部單元或總線上。
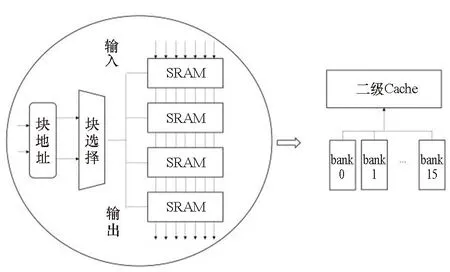
(a) 邏輯結構(a) Logical structure
(b) 物理結構(b) Physical structure
由于存儲體具有較大的尺寸,不同位置的存儲體與粘合邏輯的距離各不相同。例如圖1中角部的存儲體與粘合邏輯的距離較遠,需要預留較大的時序余量,并采用速度快的存儲體。然而中心區域的存儲體與粘合邏輯的距離很近,如果和角部的存儲體采用相同的編譯配置則會導致功耗和面積的浪費。因此,對不同位置的存儲體采用不同的編譯配置能夠減小面積、功耗并同時提升速度。一般來說存儲體的編譯配置包括閾值替換、尺寸調整、長寬比變形、拆分/合并四種,如圖2所示。
(a) 基本配置(a) Basic configuration
(b) 改變列多選(b) Change the MUX
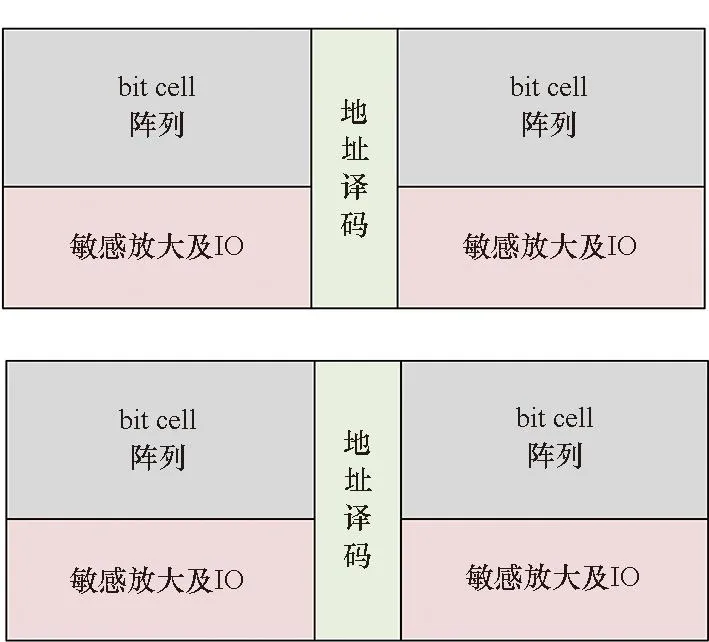
(c) 拆分(c) Splitting
1.1 閾值替換
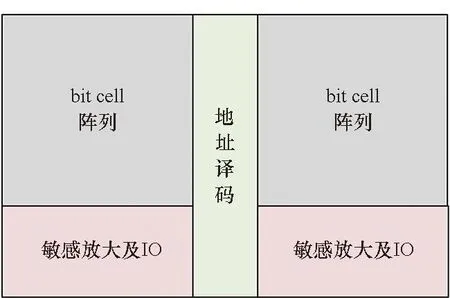
集成電路中經常采用閾值替換的方式在速度和功耗之間權衡。低閾值的晶體管速度快但功耗高;高閾值的晶體管速度慢但功耗低,在標準單元里較為常見。閾值替換的優點是,其占用的面積相同,不需要調整芯片的布局規劃,可以在物理設計的任意階段替換插入。
存儲體編譯的基本配置如圖2(a)所示,SRAM主要包含bit cell陣列、敏感放大及輸入/輸出(input/output, IO)、地址譯碼三個部分。閾值替換一般僅對地址譯碼以及IO等外圍電路進行閾值替換。bit cell的閾值替換會影響其噪聲容限等特性,因此一般不進行閾值替換。
1.2 尺寸調整
尺寸調整也是速度和功耗之間權衡的一種常見方式。一般來說增大尺寸可以提高速度,但同時也會帶來面積和功耗的增加。尺寸調整以bit cell為核心進行,根據性能要求增大bit cell的尺寸,然后根據bit cell的尺寸,調整設計譯碼器、IO、列多選器(multiplexer, MUX)等外圍電路的尺寸。這一方法將會顯著改變存儲體面積,從而導致預布局規劃(floorplan)的改變。
1.3 長寬比變形
存儲體可以保持容量不變,但使長寬比發生改變。方法之一是改變存儲體內的列多選,例如使得bit cell陣列的行數減半但列數加倍,再增加一個列多選來選擇輸出數據,如圖2(b)所示。另一種保持容量不變的方法是改變存儲體的深度與寬度,例如深度減半而寬度加倍或反過來。也有以上兩種方法的組合。
總的來說,這些方法能保持存儲體的容量不變、總面積基本不變,但會明顯改變字線和位線的長度,使得速度和功耗都有所變化。
1.4 拆分/合并
拆分有兩種方式:一種是保持深度不變、拆分位寬,這種情況下,拆分后的小存儲體可以保持和原大存儲體的譯碼電路相同,僅僅將bit cell陣列寬度縮減一半;另一種是保持位寬不變、拆分深度,如圖2(c)所示,這種情況下,bit cell陣列高度將縮減一半,地址縮減1位,譯碼電路隨之縮減。拆分后的兩個小存儲體都保持原有數據位寬,使得數據線增加一倍,在外部需要加多選器在多個小存儲體之間選擇數據,這將對邏輯設計、布線都有影響。這兩種方法都會縮短字線或位線,從而提高速度。但是拆分后,各個體都需要譯碼電路等外圍電路,且需要增加存儲體間的間距,因此面積和功耗會變大。反之可以將2個(或多個)存儲體合并為1個,從而減小面積和功耗,但會導致性能降低。
2 協同編譯方法
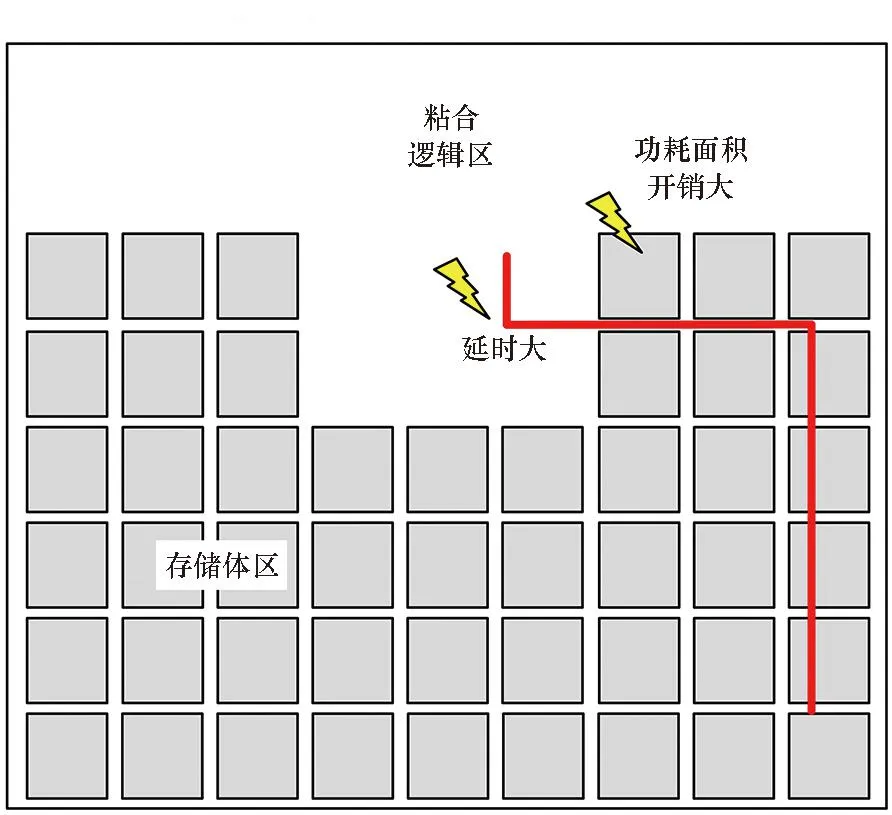
本文打破原有位置無關的同構SRAM存儲體編譯方法,提出了一種存儲體位置驅動的存儲體協同編譯的流程。對遠離粘合邏輯的存儲體通過拆分、低閾值替換、增大尺寸等方式來加快速度;對于靠近粘合邏輯的存儲體通過合并、高閾值替換、減小尺寸等方式來減小面積和功耗,達到時序、功耗和面積的均衡。其具體過程如圖3所示。
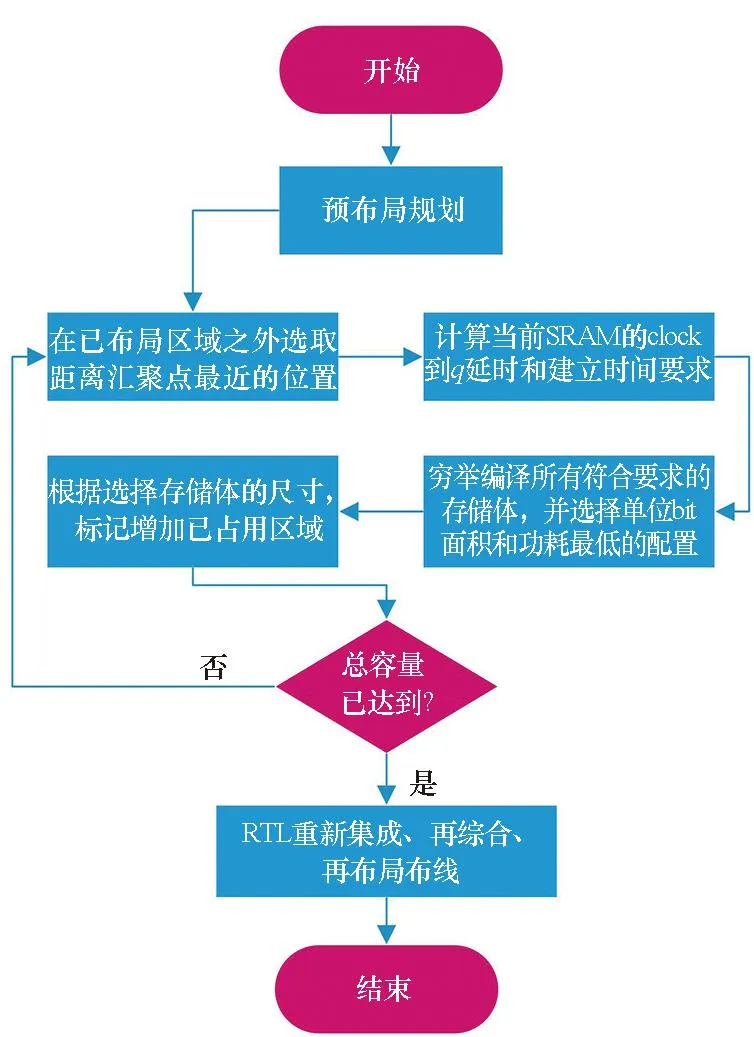
圖3 協同編譯流程Fig.3 Cooperative compilation flow
設計包含粘合邏輯和存儲體兩部分。首先基于對粘合邏輯進行floorplan,得到粘合邏輯的布局區域,在其中選取存儲體的匯聚點,作為存儲體距離計算的基準點——匯聚點一般為粘合邏輯區域的中心,或中心靠近端口的位置,同時在floorplan中將粘合邏輯區域設為已布局區域。
其次,在預布局規劃中選擇離匯聚點最近的未布局區域的位置作為第一個存儲體布局位置。根據它相對于匯聚點的距離計算出對于布局在該位置存儲體的時序要求。
然后,窮舉編譯可能的存儲體,在包括深度、位寬、閾值、尺寸、長寬比等幾個維度上窮舉編譯,在其中選擇時序滿足要求且單bit面積和單bit功耗最小的一個。
最后,根據選出的存儲體的尺寸,在floorplan中標記該區域為已布局區域,并記錄已布局的總容量。繼續選擇下一個最近位置進行存儲體編譯,直到已布局存儲體總容量達到預期。這樣就得到了所有存儲體的配置和布局位置。
經過以上流程,存儲體可能有拆分和合并,原有的粘合邏輯可能需要微調。重新進行寄存器傳輸級(register transfer level,RTL)集成、綜合,并對前序步驟生成的存儲體位置進行布局布線,最終完成整個設計。
下面對位置相關的存儲時序計算和窮舉編譯的過程再進一步詳細說明。
2.1 位置相關時序約束確定
存儲體協同編譯過程如圖4所示,如果已完成存儲體1和存儲體2的編譯與布局,可以在未布局區域找到存儲體3的布局位置,那么它的時序要求可分為兩項:①粘合邏輯到存儲體3的建立時間要求;②存儲體3到粘合邏輯的建立時間要求。可表示為以下兩個不等式:
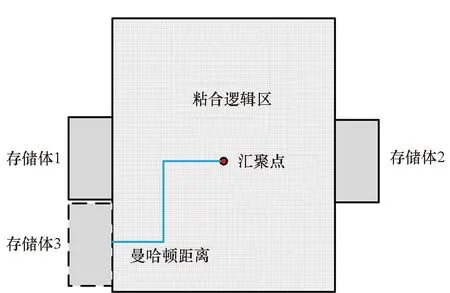
圖4 存儲體協同編譯過程Fig.4 Cooperative memory compilation process
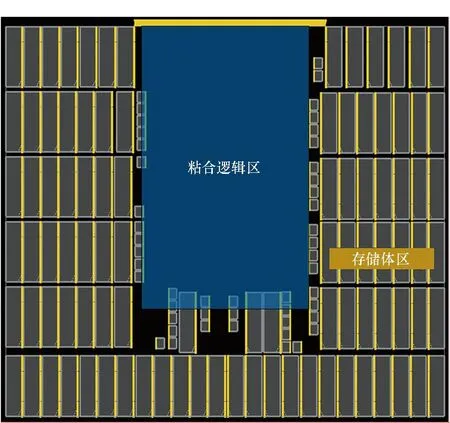
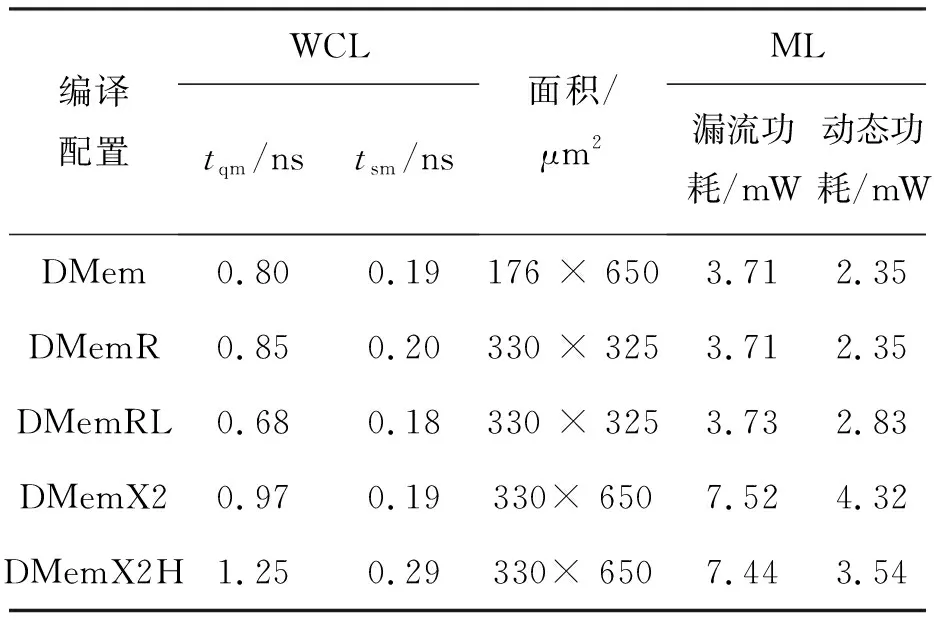
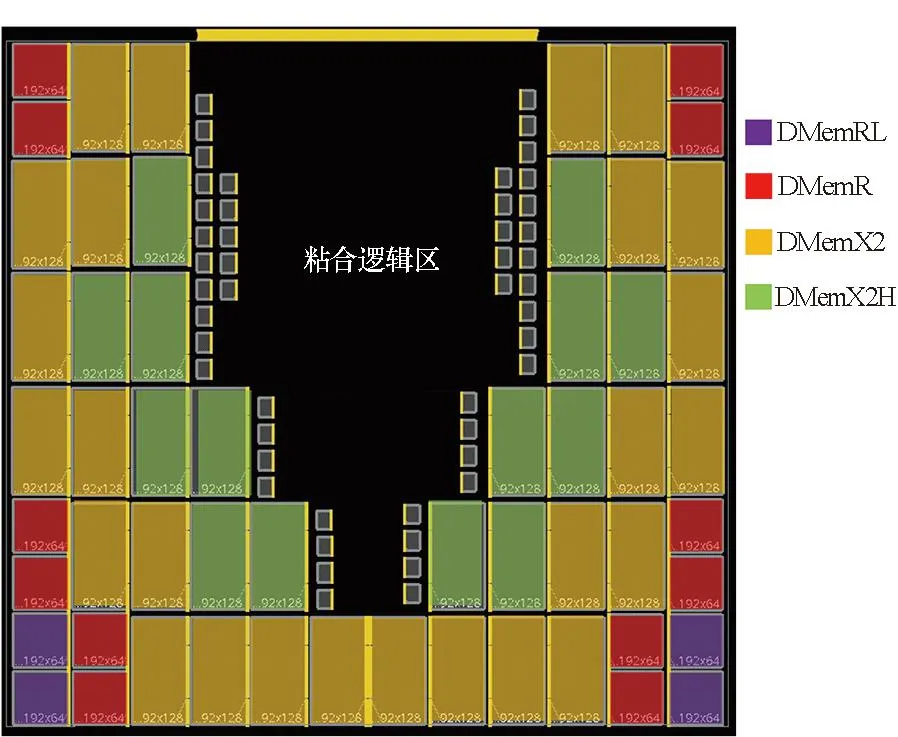
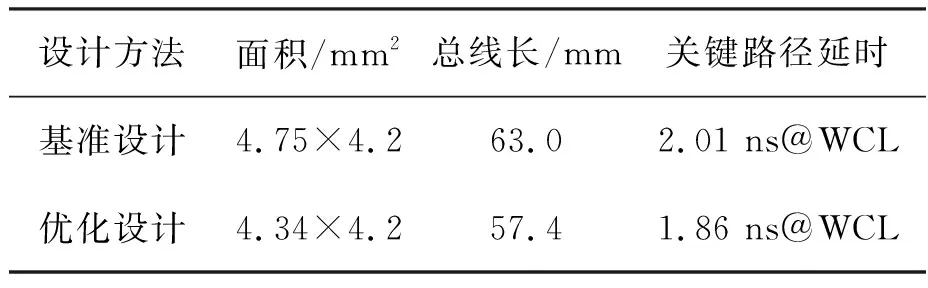
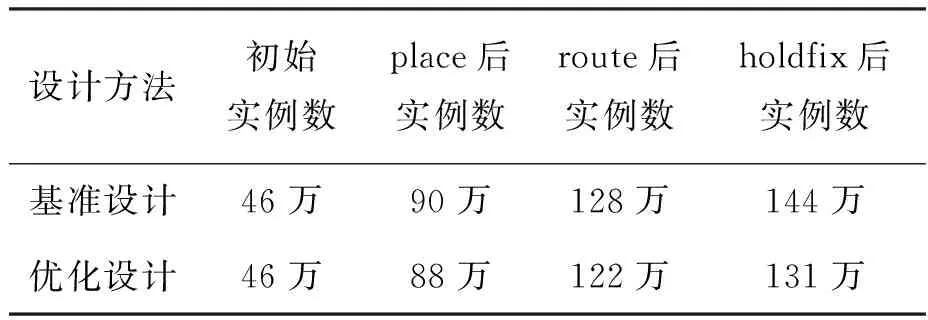
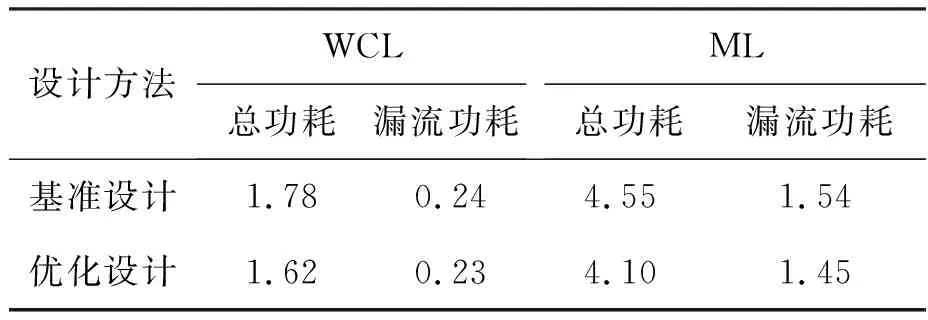
tqm+tgt+td+tsr+tmg (1) tqr+tgf+td+tsm+tmg (2) 其中:tqm和tsm分別是存儲體clock到q的延時和存儲體的建立時間,二者是需要求解的目標;tgt和tgf分別是粘合邏輯上組合邏輯的延時;tqr和tsr分別是粘合邏輯上寄存器clock到q的延時和建立時間,它們可以從時序庫中查表得到;tmg是預留的一定余量,以抵消實際布線時少量的繞線和串擾的影響;td是匯聚點到存儲體距離造成的延時,可以采用與曼哈頓距離相關的延時模型進行計算[10];tp是電路工作的時鐘周期。以上兩個不等式變形即可得到存儲體的時序要求: tqm (3) tsm (4) 還可以考慮使用有效時鐘偏斜的設計簡化約束,那樣時鐘樹構建將更加復雜,但不影響本方法實現,因此不再做進一步的討論。 存儲體窮舉編譯同時考慮深度、位寬、閾值、尺寸、長寬比等幾個維度上可能的存儲體實例生成,這是一個很大的搜索空間,為了在有限時間內完成搜索,需要對這些維度作出一些限制。 在寬度和深度方面,要求它們都必須是2的冪次,且總容量不超過1 Mbit,這樣便于RTL代碼編寫和物理實現,也不會跳過那些明顯優化的配置;在閾值方面,考慮高閾值、普通閾值、低閾值三種選項;在尺寸方面,一般選擇較小和較大的兩種bit cell尺寸,更精細的尺寸選項在實際工程中也不會帶來更多優化;在多選器方面,一般也為2的冪次,且最大不超過16,因為超過16時存儲器的速度會有較大程度降低。 在以上約束下,存儲器的編譯配置一般能縮減在30~120種之間,從而窮舉編譯能夠在3~4個小時內完成。 針對第2節的方法,可以用一個實例來具體說明其過程并展示其效果。這是一個共有48 Mbit存儲容量的片上共享緩沖池,深度為24 576,寬度為256,具有AXI總線協議接口與片上其他部件互聯。 圖5是采用文獻[5,8]中的傳統方法進行的SRAM布局。該共享緩沖內部通過96個同構的數據存儲體(data memory,DMem)。表1為不同編譯配置下存儲體的指標,分別在最差低溫(worst case low temperature,WCL)和最大漏流(max leakage,ML)兩個端角下進行了分析。為了實現500 MHz的頻率選擇如表1中第一行的存儲體配置方式,其容量為4 096×128 bit,列多選為4。其面積為4.75×4.2 μm2=19.95 μm2,關鍵路徑延時為2.01 ns。 圖5 傳統方法的SRAM布局Fig.5 The SRAM layout in traditional methodology 表1 不同編譯配置下存儲體的指標 采用協同編譯優化的方法得到如圖6所示的存儲體的配置和布局,選取的匯聚點是粘合邏輯中間靠上的區域。其中包含四種不同存儲體來實現這一片上緩存,每種存儲體的具體參數如表1所示。DMemX2H是深度相比DMem增大2倍且進行了高閾值電壓(high voltage threshold,HVT)單元替換的存儲體,它布局在最靠近中心標準單元的區域,在ML端角下該存儲體的單位動態功耗相比原存儲體有24.7%的減少,單位漏流功耗與基準設計基本相當。DMemX2是深度相比DMem增大2倍的存儲體,它布局在DMemX2H的外圍,它的單位動態功耗相比原DMem也有8.1%的降低。DMemR容量與DMem相同,只是深度增加了一倍、寬度降低了一半,可以減少存儲體端口的布線擁塞,同時其功耗也有所降低,DMemR放置在DMemX2的更外圍,用于跨越更遠的距離。DMemRL是在DMemR的基礎上進一步做了低閾值電壓(low voltage threshold,LVT)單元替換,僅用在左下和右下兩個角上,用于提高這兩個關鍵位置的速度。 圖6 協同設計的SRAM布局Fig.6 The SRAM layout in co-operative methodology 在嘗試了增大尺寸的配置后發現這種配置單位功耗過大,所以在所有位置都沒有選用。 基準設計和優化設計的一些關鍵指標的對比如表2和表3所示。在面積方面優化設計減小了8.6%,原因是采用了很多DmemX2容量的存儲體,消除了存儲體之間的縫隙,從而使全芯片寬度有所縮減。在關鍵路徑延時上優化設計縮短了7.5%,這是因為在角部采用了LVT的存儲體。在實例數方面,在設計的各個階段優化設計都要明顯少于基準設計,這是因為采用了DMemX2以及DMemR存儲體使得多選單元都在存儲體內部,減少了外部所需要的多選單元及布線,因此單元數減少了9.0%。類似的原因,布線線長也減少了8.9%。 表2 設計指標對比 表3 設計實例數對比 最后,對比基準設計和優化設計的功耗情況。功耗分析都按500 MHz的頻率進行,數據路徑設定為0.2的翻轉率,時鐘路徑設定為2的翻轉率,時鐘門控系數為0.6。分別在WCL和ML兩個端角下進行了分析,具體結果如表4所示。優化設計WCL下總功耗降低了9.0%,漏流功耗與基準設計基本相當。優化設計ML下總功耗降低了9.9%,漏流功耗降低了5.8%。 表4 功耗對比 本文的方法已應用于一款SoC芯片片上共享緩存的物理設計。SoC芯片如圖7所示,其中,片上共享緩存實測達到了預期的頻率,全芯片功耗符合預期。 圖7 集成了優化片上緩存的SoC芯片Fig.7 SoC chip integrated optimized on-chip cache 本文提出了一種存儲體編譯和布局協同的片上緩存設計方法。該方法基于存儲體在芯片上的不同位置,分別采用拆分/合并、尺寸調整、閾值替換和長寬比變形等多種方法優選SRAM存儲體編譯實例,從而同時帶來性能的提升、功耗和面積的減小。實驗結果表明,該方法相比傳統的設計方法能夠降低約9.9%的功耗,同時縮短7.5%的關鍵路徑延時。2.2 存儲體窮舉編譯
3 實驗與結果

4 結論
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14建材發展導向(2021年12期)2021-07-22 08:06:48建材發展導向(2021年7期)2021-07-16 07:07:52中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48藝術啟蒙(2018年7期)2018-08-23 09:14:18海峽姐妹(2017年7期)2017-07-31 19:08:17Coco薇(2017年5期)2017-06-05 08:53:16Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56
