基于深度學習的電影智能化攝制技術研究
2024-04-12 06:58:22胡堃解沛
現代電影技術 2024年3期
胡 堃 解 沛
1.悉尼大學計算機科學學院,澳大利亞新南威爾士州 2006 2.中國電影科學技術研究所(中央宣傳部電影技術質量檢測所),北京 100086
1 引言
2023 年我國電影總票房為549.15 億元,其中國產電影票房為460.05 億元,占比83.77%[1],觀影人次為12.99 億。隨著科技發展,電影拍攝與制作的工業化水平取得了極大提升,我國也正由電影大國向電影強國邁進。與此同時,深度學習(DL)作為機器學習(ML)的重要分支,近些年在計算機視覺(CV)、自然語言處理(NLP)、數據挖掘(DM)以及多模態內容理解等領域發揮了巨大作用。因部分環節工作的主觀性與藝術性,電影攝制流程對于深度學習的結合與應用仍處于探索階段。本文通過調研國內外現有技術與文章,針對攝制流程中的不同階段,對深度學習技術在電影智能化攝制中的應用進行探討與分析,以期提出電影工業化未來的發展趨勢與方向。
2 深度學習技術與電影攝制流程的結合
電影攝制是一個涉及多個環節的復雜過程,通常根據時間線分為三大階段:前期創意與籌備、中期拍攝以及后期制作。在前期創意階段,首先是劇本創作環節,劇本作者會按照線性結構詳細描繪故事情節、場景布局和對白。劇本完成之后,導演會要求分鏡師根據劇本內容制作分鏡頭腳本,并詳細規劃每一鏡頭的編號、畫面類型、拍攝手法和時長等信息。此外,對于包含計算機圖形學(CG)元素的電影,還需對虛擬場景和角色進行建模和繪制;為了確保拍攝過程的順暢,許多創作者還會對分鏡頭進行虛擬預演(PreViz)。拍攝階段是電影制作中至關重要的一環,旨在捕捉分鏡頭腳本中所需的全部視頻畫面及部分現場聲音素材,主要設備包括攝影機、麥克風和燈光系統等。在拍攝過程中,導演和攝影指導需緊密協作,確保每一鏡頭的構圖與劇本或預演保持一致;燈光系統需提供符合鏡頭氛圍的照明;盡可能多角度拍攝;要隨時注意素材的安全保存與傳輸。此外,隨著虛擬攝制技術的推廣普及,運用動作捕捉和面部捕捉技術也日漸成為常態。后期制作指的是拍攝結束后進行的全部工作,包括素材的剪輯、聲音設計、視覺效果(VFX)制作、色彩校正、混錄以及母版制作等環節。
深度學習技術通過自動整合特征提取和建模過程,推動了多種任務的成功解決。與傳統機器學習相比,深度學習依托于神經網絡(Neural Network)架構,通過增加網絡深度來形成對輸入數據更強大的深層表示能力。目前,常用的深度學習架構主要包括多層感知機(MLP)、卷積神經網絡(CNN)、循環神經網絡(RNN)、圖神經網絡(GNN)[2]以及Transformer網絡[3]等。其中,MLP 是深度神經網絡的基礎算法;CNN 擅長處理視覺和聽覺方面的信息[4];RNN 能夠有效處理和理解文章、視頻或動作序列等連續的信息流;GNN 在動畫仿真包括粒子特效領域、處理基于人體姿態識別[5][6]領域顯示出強大能力;Transformer 網絡具有理解復雜數據結構和模式的強大能力,同時通過引入跨模態注意力(Cross-Attention)機制,催生了如GPT[7]和Stable Diffusion[8]等模型。
基于電影攝制的流程順序,深度學習技術在不同階段均有應用,主要應用場景如圖1所示。
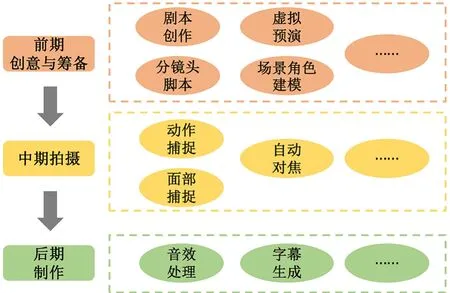
圖1 電影攝制流程
3 深度學習在電影前期創意籌備階段的應用
前期創意與籌備工作是整部電影的基石,既需要足夠獨特的劇本,也需要將創意落地的分鏡頭腳本,部分還需要為電影拍攝準備虛擬預演,此外,含虛擬場景的片段還應當為拍攝時使用的場景與角色進行建模。近年來,基于深度學習實現文本擴充、文生圖以及文生視頻等技術發展迅猛,在電影前期也得到了廣泛應用。
3.1 劇本創作
劇本作為一部電影的基石,其創作顯得尤為重要。隨著數據集與模型的不斷優化,現有技術所生成的劇本內容更加流暢也更符合人類閱讀習慣。常見的劇本生成方式是利用已有文本對神經語言模型進行訓練,輸入簡單的創意內容文本(通常是幾句話),輸出具有情節、人物等內容的長篇幅文本。Dharaniya 等[9]提出一種基于自然語言處理(NLP)的啟發式算法的電影劇本生成模型。通過采集不同電影的文本數據(包括角色、場景和類型等)并進行數據預處理;再使用深度置信網絡(Deep Belief Network, DBN)從代表性批歸一化方法(Representative Batch Normalization, RBN)層中提取深度特征后獲得相關特征;最后,將深度特征賦予基于集成學習的電影腳本生成(Ensemble-based Movie Script Generation,EMCG)系統,其中使用集成學習的腳本生成過程由雙向長短期記憶網絡(LSTM)、GPT-3 和GPT-NeoX模型執行。為了保證劇本內容既有相鄰句子連貫性,又有段落之間的統一,相較于通過大量文本內容進行訓練,Cho 等[10]嘗試從連貫性和內聚性的角度對神經語言模型(NLM)進行升級,提出一種基于神經網絡的跨句語言特征、連貫和銜接的長文本生成方法。作者在該方法中提供了兩種鑒別器(Discriminator),其中連貫鑒別器幫助從宏觀角度上構建段落,銜接鑒別器從微觀上對相鄰的句子進行連接。近年來,隨著對話式人工智能的迅速發展,劇本生成也采用了類似模式,Zhu 等[11]提出一種基于所提供的敘述內容生成電影腳本的方法。該方法主要針對場景生成,通過更新機制跟蹤敘述中提供的內容,每一次新生成的內容均是基于上下文、敘述和反饋之間的多重匹配。此外,他們還構建了一個大規模數據集,用于從電影腳本中生成敘事引導腳本。類似的,Eldhose 等[12]提出一種名為“Alyce Garner Peterson”的人工智能劇本微調模型,該模型能夠根據給定的故事給出劇本內容。
3.2 圖像生成
無論是創作用于拍攝的分鏡頭故事板,還是設計現場或虛擬場景的布景說明,將文字描述轉換成相應的圖像內容都是一個關鍵步驟。對于圖像生成任務,主要的模型包括生成式對抗網絡(GAN)[13][14][15]、擴散模型(Diffusion Model)[16][17]以及變分自編碼器(Variational AutoEncoder, VAE)[18]三類(圖2);每一類模型都可以進行有條件和無條件的圖像生成。其中,有條件生成根據給定的條件或信息生成圖像,而無條件生成則隨機生成符合訓練數據分布的圖像。
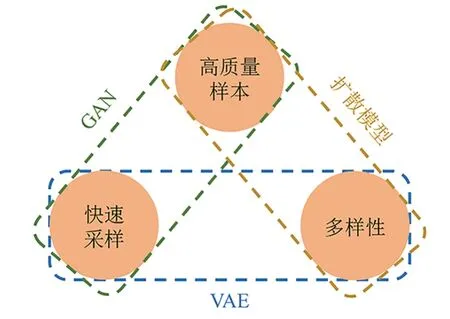
圖2 三類生成模型的特點
特別地,以文本作為條件,微軟和京東共同開發了一種名為對象驅動的注意力生成式對抗網絡(Object-driven Attentive Generative Adversarial Network,Obj-GAN)[19]。它允許以對象為中心的復雜場景的文本生成圖像,并引入了一種基于快速R-CNN 的目標檢測模型,以提供詳細的對象信息來確保生成的對象與文本描述和預設的布局相匹配。作為近年來熱門的深度學習模型,Stable Diffusion 是一個文本生成圖像模型。該模型通過逐步迭代的方式,將原始圖像的潛在表示擴散到高分辨率圖像。
相較于單純的文本到圖像的轉換,基于圖像作為條件的場景也得到了廣泛研究。例如,Zeng 等[20]提出用于從任何精度級別語義實現圖像生成的框架SceneComposer,既實現了基于純文本生成圖像,也可以針對畫布上的涂鴉進行圖像生成。
3.3 虛擬預演
在電影準備階段,為了保證開拍后的每一個鏡頭順利完成拍攝,不僅需要繪制故事板,還需要完成部分鏡頭的虛擬預演(PreViz)。利用深度學習技術完成虛擬預演視頻的生成,通常需要提供每一個分鏡的場景描述,包括但不限于人物、置景、光線以及構圖等內容,利用上述內容,我們期望生成一個合理、能夠符合所提供文本內容的視頻。基于上述需求,Zhang 等[21]提出一個處理復雜文本到動畫的方法。基于現有的劇本創作動畫生成系統,作者構建了一個自然語言處理(NLP)流程。首先將輸入的劇本內容分割成不同的功能塊,然后對描述性的句子進行簡化,最后使用簡化句子生成動畫。作者還提出一組簡化復雜句子的語言轉換規則,以從簡化句子中提取的信息用于生成描述文本的粗略故事板和視頻。通過實驗,68%的參與者認為該系統可以基于劇本生成合理的動畫。虛擬預演除了根據文本生成相關視頻畫面外,通常還需要體現鏡頭、布景、人物位置甚至燈光等內容。針對這類需求,Zhu 等[22]提出MovieFactory,該方法可以根據自然語言所描述的需求生成包含畫面的多模態電影內容。這是第一個完全自動化的電影生成模型,使用簡單的文本輸入創建連貫的電影內容。該方法第一步利用ChatGPT將提供的文本擴展為用于電影生成的詳細順序腳本;第二步通過視覺生成和音頻檢索,在視覺和聽覺上進一步豐富腳本;第三步,采用空間微調彌合預訓練圖像模型和新視頻數據集之間的差異;最后,引入時間學習來捕捉對象運動的特征。此外,在音頻方面,該方法利用檢索模型來選擇和對齊與電影情節和視覺內容相對應的音頻元素。對于聲音效果,作者從原始文本內容或生成的視頻內容中提取特征,并將它們與數據庫中合適的音頻剪輯進行匹配;對于背景音樂,則利用ChatGPT 來總結情節和音調,然后將推薦的音調類別與音樂信息檢索技術相結合來識別合適的音樂曲目。MovieFactory 生成的樣本可在 YouTube 或者bilibili上查閱。
近期,OpenAI 提出其第一個視頻模型Sora[23]。在發布的技術報告中,研究人員表示其與GPT 模型同樣采用Transformer 網絡架構,這種架構可以處理視頻和圖片中時空片段的隱式空間表示。Sora 是一種擴散模型,它從看起來像靜態噪聲的視頻開始生成視頻,通過多個步驟消除噪聲來逐漸還原視頻。除了能夠僅根據文本說明生成視頻,該模型還能通過靜止圖像生成視頻,從而提升準確性和對細節的關注。基于不同的輸入(文本、圖像甚至視頻),Sora可以應用在不同的場景下,它可以將視頻沿時間線向前或向后進行擴展;改變輸入視頻的風格和環境;實現視頻間的拼接與平滑過渡;還可以對現有視頻進行擴展或填充缺失幀。Sora 目前也存在無法精確模擬物理運動以及長視頻邏輯不連貫等問題,但相比于其他視頻生成模型,Sora 已經能夠創造出更符合真實運鏡效果的視頻,也更加契合電影攝制的技術與藝術要求。
3.4 場景建模
在現代電影制作中,除了實地拍攝外,部分鏡頭常采用虛擬攝制技術,包括傳統藍幕/綠幕技術和采用LED 顯示屏的新技術。無論選擇藍幕/綠幕還是LED 顯示屏,構建逼真的虛擬場景都非常關鍵,這不僅包括整體環境的搭建,還涉及場景中的細節,比如紋理和氣候所形成的地質特點。三維掃描實際場景后創建虛擬環境,是一種被廣泛應用的整體環境構建方法。為了解決從實景點云數據輸入到3D 建模場景輸出的問題,Handa 等[24]提供了一個用于生成高質量室內環境3D 場景的框架——SceneNet。他們提出一種分層模型生成器,利用從現有室內場景數據集中學習到的對象關系先驗,通過模擬退火算法(Simulated Annealing, SA)進行求解。掃描后的場景在轉換成虛擬場景時,如需對不同物體進行識別和分割,過去通常需要耗費大量的人工進行識別。對于該問題,Chen 等[25]提出通過點云驅動的深度學習方法,該方法可以檢測并分類點云場景中的建筑元素。在論文中,首先將點云轉換為圖形表示并通過基于邊緣的分類器對來自不同對象的點的邊緣進行識別;之后利用分類器識別到的邊緣進行組件分割并確定建筑組件的類型;最后,將每個檢測到的對象與特征空間中的建筑信息模型(Building Information Modeling, BIM)進行匹配。針對場景中每一個對象的動態紋理生成,Tesfaldet 等[26]提出用于動態紋理合成的基于卷積神經網絡(CNN)的雙流網絡模型。Pajouheshgar 等[27]提出一種可以實時合成任意幀大小和無限長度動態紋理視頻的模型。利用多尺度感知和位置編碼,該模型中局部單元可以進行遠距離建模并獲取全局信息。通過定性和定量實驗表明,與普通的近鄰成分分析(Neighbourhood Components Analysis, NCA)模型相比,該模型在視覺質量和計算表達能力方面有更高的性能。
3.5 角色建模和設計
除了場景建模外,電影拍攝還常常會用到角色建模技術。通過角色建模,既可以實現對真人演員的數字化,也可以構建純虛擬的數字人物。在真人建模的領域,相較于全身的數字化生成,僅針對面部或頭部建模的研究與應用更為研究者所熱衷。在角色建模和設計時,通常需要真實人物數據(一張圖片或一段視頻)來生成數字角色。Nagano 等[28]通過GAN 實現了僅使用一張2D 輸入圖像來驅動動態頭像的構建。該網絡根據生成的口腔內部和眼睛紋理來合成動態頭像動畫,這是第一個能夠從單個圖像生成具有口腔內部動態紋理的技術。Wei 等[29]提出一個利用面部特征制作與真人表情相似動畫的系統,該系統使用消費級別的頭戴式攝像頭(Headset Mounted Camera, HMC)即可實現。該系統需要使用兩套不同的HMC 設備——訓練HMC 和追蹤HMC,訓練HMC 體積較大,配備9 個攝像頭,旨在數據采集和模型構建;追蹤HMC 內置3 個攝像頭,用于精確制作動畫。Galanakis 等[30]通過創建一個巨大的帶有標簽的面部渲染合成數據集并將其用于訓練網絡,使后者能夠準確地建模和概括面部身份、姿勢和外觀。該模型可以準確地提取面部特征,擬合任意姿勢和光照的面部圖像,并用于在可控條件下重新渲染面部。除了角色建模外,如何實現生成角色與虛擬場景的交互也是目前熱門研究內容,對于該問題,Starke 等[31]提出一種神經網絡框架來合成涉及與環境密切交互的動作(坐下、站立、繞行以及開門等)。該系統通過輸入目標位置以及需要實現的動作,計算完成目標動作過程中需要的動作,同時計算過程中需要避開或適應的障礙或家具,最終生成一段動畫序列。
4 深度學習在電影拍攝中的應用
相較于電影制作前期,深度學習在電影拍攝過程中的應用并不普遍。這是因為實際拍攝環節涉及攝影師、燈光師和錄音師等分屬不同工種的眾多專業人員,使基于深度學習的技術解決方案尚未能夠在全環節廣泛實施。目前深度學習技術主要應用于動作與面部捕捉、實時對焦等方面。
4.1 動作捕捉與面部捕捉
在電影拍攝當中,動作捕捉通常用于利用捕捉到的運動數據驅動已建模角色進行同樣的運動。通過結合深度學習技術,可以對已經記錄下的運動數據進行插幀以及修改。此外,目前還有技術可實現對視頻內容中的人物進行動作捕捉,Tung 等[32]提出一種單相機輸入的基于深度學習的運動捕捉模型。該模型不是直接優化網格和骨架參數,而是優化神經網絡權重,在給定單目視頻的情況下預測3D 形狀和骨架配置。該模型使用強監督和自監督相結合的端到端方式進行訓練,其中強監督數據使用合成數據,自監督數據使用骨骼關鍵點、密集3D 網格運動以及人類-背景分割三部分可微分渲染數據。在面部捕捉領域,研究方向更多是對拍攝視頻內容進行識別與捕捉。Laine 等[33]提出一個基于視頻的面部表演捕捉實時深度學習框架,在給定單目視頻的情況下對人臉進行密集的3D 追蹤。為了提升準確性,該框架的面部捕捉流程使用了多視角立體跟蹤方法和藝術家手動修正關鍵區域(例如眼睛和嘴唇)的方式。Wang 等[34]針對面部表情動態捕捉,提出一種基于深度學習的面部特征提取和3D 動畫生成方法,并利用支持向量機(Support Vector Machine, SVM)技術進行特征分類。作者通過C++和OpenGL 對3D 動畫進行渲染模擬。實驗結果表明,該方法的人臉檢測算法在準確率和速度上均具有良好的性能,可以實現視頻圖像中人臉區域的實時檢測。
4.2 對焦的實現
在電影拍攝中,確保焦點的準確性至關重要,而自動對焦技術則能進一步保障拍攝工作的順利進行。目前,大多數技術專注于對已拍攝的視頻或圖像內容進行后期對焦處理。Wang 等[35]研究者提出一種基于圖像的自動對焦新流程,能夠迅速準確地找到焦點,速度比以往對比度增強方法快5~10 倍,通過建立圖像與其焦點位置之間的直接映射來實現快速對焦,并設計了一種焦點控制策略,通過動態調整焦點位置,極大地提高了基于焦點堆棧估計的圖像質量。Zhang 等[36]提出一種電影焦點追蹤方法和系統,能夠在智能手機拍攝的深景深視頻中生成可重調焦的視頻內容,并利用對未來視頻幀的分析,為當前幀提供上下文感知的自動對焦功能。為了生成這種可重新對焦的視頻,研究者們擴展了原本設計用于靜態攝影的先進機器學習方法,提供了新的數據集、更適合電影焦點處理的渲染模型,以及保證時間連貫性的過濾方案。Nazir 等[37]提出一種利用深度神經網絡實現對單張失焦圖像的深度估計,并獲得全焦(All-in-Focus, Aif)圖像。該方法是由一個編碼器和兩個并行解碼器組成的雙頭架構,每個解碼器實現不同的任務,一個輸出深度信息,另一個輸出去模糊圖像。
5 深度學習在電影后期制作中的應用
對于后期制作,深度學習主要應用于音視頻處理與增強等方面。相較于其他兩個階段,深度學習在后期制作中已具備較為成熟的應用場景,也是應用效果較好的一個領域。
5.1 音樂處理和生成
除了拍攝期間錄制的同期聲外,音樂和音效的制作通常都在后期完成。目前,基于深度學習的音樂處理技術發展迅猛,尤其是在利用樂譜進行音樂合成方面已經取得較為成熟的進展。Mao 等[38]開發了一種名為DeepJ 的端到端生成模型,該模型能夠模仿特定作曲家的風格來創作音樂,并能學習不同的音樂風格和音符的高低起伏。通過主觀評價,證明了該模型相比于傳統的長短期記憶網絡(LSTM)方法有明顯改進。Li 等[39]提出一種創新的旋律創作方法,該方法優化了基于單個小節的生成式對抗網絡(GAN)模型,并引入了兩個判別器來構建一個增強型的GAN 模型:一是LSTM 模型,確保樂段之間的連貫性;另一是CNN 模型,增強樂段間的一致性。另一項研究中,Li 等[40]還提出MRBERT 預訓練模型,專注于多任務音樂生成,包括旋律和節奏的學習。該模型經過微調后,能夠在多種音樂生成應用中使用,如網絡音樂作曲家,實現旋律生成、編輯、補全及和弦匹配等功能。Li 等[41]還提出一種使用基于Transformer 網絡的序列到序列模型生成旋律和弦的方法,該模型分為預訓練的編碼器和解碼器。Lu 等[42]則提出一種從文本描述生成樂譜的系統,該系統通過音樂屬性作為中介,將任務分解為從文本到屬性的解析和從屬性到音樂的生成兩個階段,特點是數據高效和能夠精確控制生成結果。Parker 等[43]提出一種基于非自回歸Transformer 的端到端音樂生成模型,該模型可以理解給定音樂并基于輸入音樂生成新的音樂。
5.2 字幕生成
字幕生成通常是后期制作中耗費人工時間最長的幾項工作之一,目前深度學習技術還無法完全代替手動添加字幕,但也有了不錯的方法。Xu 等[44]提出一種深層框架,通過學習多模態注意力長短期記憶(Multimodal Attention Long-Short Term Memory, MA-LSTM)來增強視頻字幕的網絡。MA-LSTM 網絡充分利用多模態流和時間注意力,在句子生成過程中有選擇地關注特定元素。此外,MA-LSTM 中還設計了一種新穎的子和(Child-sum)融合單元,以將不同的編碼模式有效組合到初始解碼狀態。Li 等[45]提出一個分層模塊化網絡,在生成字幕之前在實體、動詞、謂詞和句子4 個粒度上橋接視頻表示和語言語義。每個級別由一個模塊實現,以將相應的語義嵌入到視頻表示中。此外,作者還提出一個基于字幕場景圖的強化學習模塊,以更好地測量句子相似度。實驗結果表明,所提出的方法在三個廣泛使用的基準數據集上的性能優于此前的模型。
6 挑戰與前景
電影攝制是藝術創作與高新技術應用相結合的工作,既有需要大量創意與設計的劇本撰寫、拍攝等工作,也有簡單機械的字幕生成等工作。通過上述回顧我們可以看到,無論是藝術創作還是簡單的重復性工作,都已經開始通過與深度學習技術相結合,進一步提升電影制作效率。未來,應做好以下工作。
(1)提升輸出效率與輸出內容專業性
在電影攝制過程中,Transformer 網絡已然成為構建各種生成模型的首選。基于Transformer 網絡的GPT 和Sora 能夠很好地理解與分析自然語言,在劇本創作、分鏡腳本生成、虛擬預演等工作上具有優秀的表現;基于擴散模型和Transformer 網絡的Stable Diffusion 更擅長于文生圖以及圖生圖等領域;基于Transformer 網絡的SteamGen 等模型在音樂的生成與處理領域具有更多的研究進展。然而,目前各類算法仍然存在輸出效率不高,輸出內容不精細等問題。未來,研究人員可以繼續在Transformer 網絡上進行深入研究,升級或創新生成模型,提高生成效率,進一步提升輸出的音視頻內容精確性與專業性。
(2) 擴充完善電影級訓練數據集
目前基于電影的專用深度學習算法與技術還處于發展階段,這不僅需要硬件的升級與算法的創新,同樣需要基于電影領域專用訓練數據集的幫助。由于深度學習的主要算法是數據驅動,如果用于訓練的數據由于人為選擇標準或標簽而分布不均或不具代表性,則學習后的結果同樣可能存在偏差。未來,研究人員在提出新算法的同時,也應當建立和補充更加豐富多元也更為專業的訓練數據集,同時考慮觀眾偏好以及時代特征,符合相關審查規范,進一步推動深度學習模型在訓練時數據集的專業性與完備性。
(3)研究基于電影攝制全流程的深度學習技術
基于深度學習的電影攝制解決方案仍在持續涌現,然而目前深度學習技術在電影攝制方面的應用仍然處于割裂且分散的狀態,無法實現對電影前后期全流程進行統一而全面的應用。在持續推進各階段不同工作的新技術新應用的同時,還應當全局考慮電影攝制整體流程,嘗試實現基于全流程的深度學習新應用;還可嘗試將不同深度學習網絡模型進行融合與集成,從而使深度學習技術不再單獨完成單一任務,真正實現從劇本創作到成品電影的全流程智能化,進而創造出有價值、有意義的作品與內容。?
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
