基于OpenCL 的駕駛監(jiān)控系統(tǒng)自調(diào)優(yōu)化研究
2024-04-20 17:09:58劉創(chuàng)李智
電子制作 2024年7期
劉創(chuàng),李智
(四川大學(xué) 電子信息學(xué)院,四川成都,610000)
0 引言
人工智能在視頻圖像領(lǐng)域已經(jīng)從理論研究進(jìn)入了工業(yè)和生活,例如自動(dòng)駕駛、智能視頻監(jiān)控分析等。這項(xiàng)技術(shù)的實(shí)現(xiàn)與應(yīng)用就是讓計(jì)算機(jī)系統(tǒng)能快速地讀取大量的視頻圖像信息,并及時(shí)做出一系列判斷和反饋。因此,如何在有限的時(shí)間內(nèi)分析處理大批量圖像數(shù)據(jù)是實(shí)際產(chǎn)業(yè)應(yīng)用系統(tǒng)設(shè)計(jì)中的難點(diǎn)。為了滿足駕駛員監(jiān)控系統(tǒng)(DMS)的應(yīng)用需求,各類計(jì)算機(jī)視覺(jué)算法及框架層出不窮,各種異構(gòu)計(jì)算架構(gòu)及高性能計(jì)算平臺(tái)百花齊放。與此同時(shí),面對(duì)特定場(chǎng)景需求的復(fù)雜性,學(xué)術(shù)界和產(chǎn)業(yè)界陸續(xù)展開(kāi)了關(guān)于如何將算法模型輕松高效部署在特定計(jì)算平臺(tái)的研究與應(yīng)用工作[1-4]。
OpenCL 是專門(mén)為異構(gòu)計(jì)算制定的標(biāo)準(zhǔn),它可以協(xié)調(diào)具有不同架構(gòu)的處理器同時(shí)進(jìn)行工作,這就解決了傳統(tǒng)的同構(gòu)架構(gòu)下資源利用率低、處理速率慢的問(wèn)題。同時(shí),OpenCL可以充分發(fā)揮不同架構(gòu)處理器的性能,比如將C 與GPU 和FPGA 強(qiáng)大的并行處理能力相結(jié)合,可以完成高性能和低功耗的產(chǎn)品設(shè)計(jì)以及物聯(lián)網(wǎng)應(yīng)用等[5]。
以駕駛員監(jiān)控系統(tǒng)應(yīng)用為項(xiàng)目背景,針對(duì)深度學(xué)習(xí)模型計(jì)算量大,視頻圖像識(shí)別實(shí)時(shí)性要求高,應(yīng)用場(chǎng)景設(shè)備資源受限等問(wèn)題,利用 OpenCL 在基于 CPU+GPU 的異構(gòu)計(jì)算平臺(tái)上研究實(shí)現(xiàn) YOLOv3 算法的并行化,并且結(jié)合最新自動(dòng)化的端到端的深度學(xué)習(xí)優(yōu)化編譯器 TVM 解決算法的多平臺(tái)移植和部署問(wèn)題[6-7]。
1 背景與相關(guān)研究
1.1 車載監(jiān)控系統(tǒng)
駕駛員監(jiān)控系統(tǒng),縮寫(xiě)DMS,主要是實(shí)現(xiàn)對(duì)駕駛員的身份識(shí)別、駕駛員疲勞駕駛以及危險(xiǎn)行為的檢測(cè)功能[8]。在現(xiàn)階段開(kāi)始量產(chǎn)的L2-L3 級(jí)自動(dòng)駕駛中,其實(shí)都只有在特定條件下才可以實(shí)行,很多實(shí)際情況需要駕駛員能及時(shí)接管車輛進(jìn)行處置。因此,在駕駛員過(guò)于信任自動(dòng)駕駛而放棄或減弱對(duì)駕駛過(guò)程的掌控時(shí)可能會(huì)導(dǎo)致某些事故的發(fā)生,而DMS 的引入可以有效減輕這一問(wèn)題的出現(xiàn)。因此,近年來(lái)各國(guó)的政策法規(guī)等多方面開(kāi)始推進(jìn)DMS 的上車:歐盟和中國(guó)均出臺(tái)法律法規(guī)。國(guó)內(nèi)已率先對(duì)“兩客一危”等商用車車型安裝DMS 系統(tǒng)作出強(qiáng)制要求,乘用車搭載要求也在推進(jìn)制定中。而歐盟則將DMS 納入EuroNCAP 五星安全評(píng)級(jí)的關(guān)鍵要素,而且是必要條件。幾乎是從2020 年開(kāi)始,DMS系統(tǒng)的裝車率快速提升,行業(yè)進(jìn)入發(fā)展快車道。
DMS 的核心功能主要是疲勞監(jiān)測(cè)、分心監(jiān)測(cè)、危險(xiǎn)行為監(jiān)測(cè)。早期的DMS 方案主要通過(guò)非生物特征的技術(shù)來(lái)實(shí)現(xiàn),比如通過(guò)方向盤(pán)及轉(zhuǎn)向傳感器,監(jiān)測(cè)任何不穩(wěn)定的方向盤(pán)運(yùn)動(dòng)、車道偏離或無(wú)故改變速度等。但由于系統(tǒng)復(fù)雜,非直觀感知,整體的搭載率一直很低。現(xiàn)階段的DMS 則大多是基于攝像頭的面部識(shí)別和眼球跟蹤技術(shù),通過(guò)紅外光等采集駕駛員面部信息再經(jīng)過(guò)算法分析出人員當(dāng)下的身體狀態(tài),在檢測(cè)到駕駛員處于不安全狀態(tài)時(shí),再通過(guò)閃爍紅光或是方向盤(pán)震動(dòng)等方案對(duì)駕駛者進(jìn)行提醒。整個(gè)系統(tǒng)的硬件部分是由攝像頭+集成座艙車機(jī)/域控制器解決方案組成;軟件部分則主要涉及視覺(jué)加速算法。
1.2 異構(gòu)編程模型設(shè)計(jì)
OpenCL 在高性能計(jì)算領(lǐng)域具有許多優(yōu)勢(shì),而最重要的優(yōu)勢(shì)之一就是可移植性,允許使用多種加速器,包括多核CPU,GPU,DSP,F(xiàn)PGA 和專用硬件[9]。OpenCL 由三個(gè)模塊構(gòu)成:實(shí)現(xiàn)執(zhí)行在OpenCL 設(shè)備上的內(nèi)核程序的編程語(yǔ)言,定義和控制平臺(tái)的應(yīng)用編程接口和運(yùn)行時(shí)系統(tǒng)。OpenCL 支持任務(wù)與數(shù)據(jù)兩種并行化計(jì)算模式,很大程度上增強(qiáng)了GPU 的計(jì)算性能,其整體核心架構(gòu)包括:平臺(tái)模型,執(zhí)行模型,存儲(chǔ)模型,編程模型四種模型。基于OpenCL的異構(gòu)編程模型設(shè)計(jì)如圖1 所示。
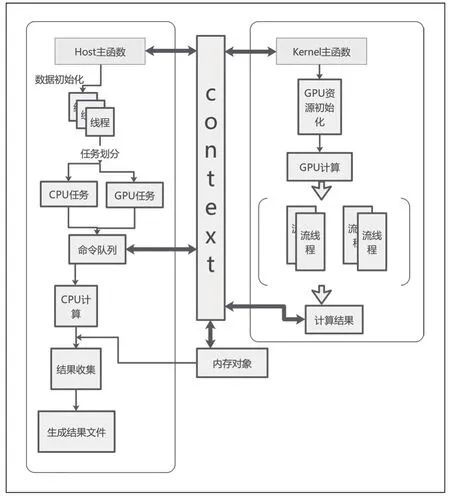
圖1 基于OpenCL 的異構(gòu)編程模型設(shè)計(jì)
在CPU+GPU 異構(gòu)硬件平臺(tái)上,通過(guò)OpenCL API 調(diào)用查詢平臺(tái)和設(shè)備屬性,選擇合適的平臺(tái)和設(shè)備進(jìn)行初始化。主機(jī)端創(chuàng)建上下文、命令隊(duì)列,分配內(nèi)存,并在主機(jī)與設(shè)備之間進(jìn)行數(shù)據(jù)傳輸和計(jì)算。異構(gòu)平臺(tái)上,主機(jī)封裝設(shè)備內(nèi)存為內(nèi)存對(duì)象以實(shí)現(xiàn)數(shù)據(jù)管理,通過(guò)命令隊(duì)列向設(shè)備發(fā)送命令,使用上下文與設(shè)備進(jìn)行信息交互。設(shè)備端實(shí)現(xiàn)并行算法核函數(shù),創(chuàng)建程序?qū)ο髨?zhí)行內(nèi)核,最后將設(shè)備執(zhí)行的數(shù)據(jù)結(jié)果映射到主機(jī)內(nèi)存,以生成最終的結(jié)果文件。
基于CPU+GPU 異構(gòu)架構(gòu),將計(jì)算任務(wù)劃分為塊。CPU 負(fù)責(zé)任務(wù)調(diào)配、復(fù)雜邏輯處理和事務(wù)管理,GPU 處理簡(jiǎn)單邏輯、計(jì)算密集、大規(guī)模并行的任務(wù)。通過(guò)并發(fā)執(zhí)行映射到CPU+GPU 多個(gè)計(jì)算單元的子任務(wù),進(jìn)一步細(xì)粒度劃分模塊以提高CPU 和GPU 的協(xié)同計(jì)算效率。
1.3 TVM 深度學(xué)習(xí)自動(dòng)化端到端優(yōu)化編譯器
TVM 是一種編譯器,支持計(jì)算圖級(jí)和運(yùn)算符級(jí)優(yōu)化,能將深度學(xué)習(xí)任務(wù)映射到各種硬件原語(yǔ),實(shí)現(xiàn)性能在不同硬件設(shè)備上的可移植性。通過(guò)機(jī)器學(xué)習(xí)方法解決高級(jí)算子融合和內(nèi)存延遲等優(yōu)化問(wèn)題,并提出了基于成本建模的高效搜索方法,自動(dòng)優(yōu)化生成滿足底層硬件特性的程序。
TVM 系統(tǒng)框架與執(zhí)行流程如下:導(dǎo)入現(xiàn)有框架中的網(wǎng)絡(luò)模型,轉(zhuǎn)換為計(jì)算圖,利用高級(jí)數(shù)據(jù)流對(duì)計(jì)算圖進(jìn)行優(yōu)化。運(yùn)算符級(jí)優(yōu)化生成高效可執(zhí)行代碼,其中運(yùn)算符的定義簡(jiǎn)化為使用張量描述語(yǔ)言宏觀指定。TVM 結(jié)合用戶設(shè)定的硬件目標(biāo)將運(yùn)算符映射到可能的代碼優(yōu)化集合,通過(guò)基于機(jī)器學(xué)習(xí)的成本模型在優(yōu)化空間中搜索運(yùn)算符的優(yōu)化。最終,系統(tǒng)將訓(xùn)練得到的優(yōu)化代碼整合為可部署的編譯運(yùn)行時(shí)模塊,包括優(yōu)化處理的計(jì)算圖、映射及搜索生成的運(yùn)算符庫(kù)和目標(biāo)設(shè)備的運(yùn)行參數(shù)。
2 實(shí)現(xiàn)與優(yōu)化
2.1 性能模型的設(shè)計(jì)與實(shí)現(xiàn)
設(shè)計(jì)一種基于GPU 架構(gòu)的自調(diào)優(yōu)性能模型[10~11]。參數(shù)化影響GPU 程序性能的因素并確定取值范圍,構(gòu)建參數(shù)集合空間。通過(guò)在GPU 平臺(tái)上配置所有可能的參數(shù)并測(cè)量實(shí)際的kernel 執(zhí)行時(shí)間,從測(cè)試結(jié)果中選取最小值,對(duì)應(yīng)于最優(yōu)配置。首先,向Host 端主機(jī)內(nèi)存輸入并初始化數(shù)據(jù)。利用搜索空間優(yōu)化算法選擇一組最優(yōu)參數(shù)配置。然后,將輸入數(shù)據(jù)和kernel 函數(shù)的參數(shù)配置傳輸?shù)紻evice 端顯存內(nèi),初始化設(shè)備平臺(tái),并在GPU 上執(zhí)行kernel 函數(shù)進(jìn)行自調(diào)優(yōu)。最后,將最優(yōu)配置和實(shí)際執(zhí)行時(shí)間返回到Host 端并輸出結(jié)果。
基于GPU 架構(gòu)的OpenCL 性能模型實(shí)現(xiàn)如圖2 所示,分為兩方面:一是從并行粒度出發(fā),包括設(shè)置OpenCL 核函數(shù)中work-group 大小和每個(gè)線程處理任務(wù)量,workgroup 的維度根據(jù)具體應(yīng)用確定。二是布爾型變量,評(píng)估GPU 平臺(tái)的優(yōu)化方法,如局部?jī)?nèi)存使用、循環(huán)展開(kāi)、避免bank conflict 等,以確定這些優(yōu)化方法對(duì)特定算法應(yīng)用的有效性。
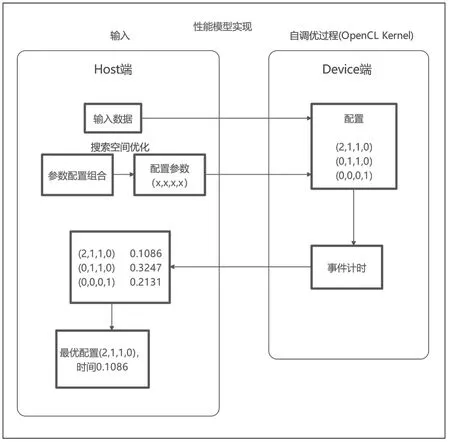
圖2 基于 GPU 架構(gòu)的自調(diào)優(yōu)性能模型實(shí)現(xiàn)
步驟1:讀取輸入數(shù)據(jù),對(duì)平臺(tái)配置參數(shù)化;
步驟2:將輸入數(shù)據(jù)從host 內(nèi)存拷貝到device 的全局內(nèi)存中;
步驟3:通過(guò)搜索空間優(yōu)化算法選取參數(shù)配置,所選取的參數(shù)配置用來(lái)初始化OpenCL 核函數(shù);
步驟4:在device 端執(zhí)行kernel 函數(shù),得出測(cè)試時(shí)間并將結(jié)果返回host 中;
步驟5:重復(fù)步驟3、4,直至遍歷完全部的搜索空間;
步驟6:對(duì)所有測(cè)試時(shí)間進(jìn)行排序,即可得出最小時(shí)間與最優(yōu)配置。
2.2 YOLOv3 算法在異構(gòu)計(jì)算的實(shí)現(xiàn)
在上文模型搭建完成的基礎(chǔ)上,設(shè)計(jì)實(shí)現(xiàn)基于 OpenCL的 YOLOv3 視頻圖像識(shí)別算法的并行加速[12~13],根據(jù)用 C語(yǔ)言和 CUDA 編寫(xiě)的開(kāi)源神經(jīng)網(wǎng)絡(luò)框架 DarkNet 項(xiàng)目,然后結(jié)合視頻圖像識(shí)別任務(wù)需求、硬件平臺(tái)特征和 OpenCL編程模型,利用OpenCL 的可移植性,在異構(gòu)系統(tǒng)上實(shí)現(xiàn)基于OpenCL 的YOLOv3 卷積神經(jīng)網(wǎng)絡(luò)算法模型。
使用并行編程模型OpenCL 設(shè)計(jì)規(guī)范實(shí)現(xiàn)算法,主機(jī)應(yīng)完成OpenCL 平臺(tái)設(shè)備選擇,內(nèi)存聲明,建立上下文并創(chuàng)建命令執(zhí)行隊(duì)列等工作,為設(shè)備創(chuàng)建緩沖內(nèi)存及內(nèi)存對(duì)象,將數(shù)據(jù)從主機(jī)端緩存區(qū)發(fā)送到目標(biāo)設(shè)備的緩存區(qū)。設(shè)備端應(yīng)編寫(xiě)算法中需要并行化設(shè)計(jì)的內(nèi)核代碼,然后創(chuàng)建對(duì)應(yīng)的程序?qū)ο蟛⒃谠O(shè)備上執(zhí)行內(nèi)核,在主機(jī)代碼中,需要使用clSetKernelArg()設(shè)置內(nèi)核參數(shù),然后調(diào)用clEnqueueNDRangeKernel()劃分安排NDRange 工作項(xiàng)和工作組的大小,調(diào)用OpenCL 內(nèi)核函數(shù)啟動(dòng)內(nèi)核。內(nèi)核運(yùn)行后得到的結(jié)果數(shù)據(jù)仍然存儲(chǔ)在設(shè)備內(nèi)存空間,主機(jī)需要將數(shù)據(jù)映射主機(jī)內(nèi)存空間中,最后在設(shè)備任務(wù)執(zhí)行完成后,由主機(jī)清理工作期間創(chuàng)建的內(nèi)存緩沖區(qū)并關(guān)閉OpenCL 對(duì)象等。主機(jī)函數(shù)設(shè)計(jì)流程圖如圖3 所示。
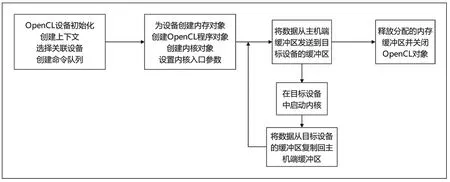
圖3 主機(jī)函數(shù)設(shè)計(jì)流程圖
本文基于clBLAS 庫(kù)(OpenCLBLAS,基于OpenCL 內(nèi)核的基礎(chǔ)線性代數(shù)操作數(shù)值庫(kù)),采用im2col 法將整個(gè)卷積過(guò)程轉(zhuǎn)換為GEMM(通用矩陣乘法)過(guò)程實(shí)現(xiàn)卷積層內(nèi)核函數(shù)。采用NDRange模式實(shí)現(xiàn)數(shù)據(jù)并行,利用系統(tǒng)的多級(jí)存儲(chǔ)結(jié)構(gòu)和程序執(zhí)行的局部性來(lái)充分加速運(yùn)算。
傳統(tǒng)卷積計(jì)算的復(fù)雜度很高,需要7 層循環(huán)遍歷圖像batch 數(shù)、batch 大小、圖像通道、圖像尺寸、卷積尺寸。采用矩陣乘法的方式將卷積計(jì)算轉(zhuǎn)化,將圖像通道和卷積核按矩陣拼接,減少循環(huán)層數(shù)。通過(guò)OpenCL 執(zhí)行模型中的單指令多線程(SIMT)特性,利用多個(gè)工作項(xiàng)同時(shí)計(jì)算,實(shí)現(xiàn)并行加速。
在二維卷積運(yùn)算中,每個(gè)輸出點(diǎn)的計(jì)算是獨(dú)立且不依賴的,因此,通過(guò)將OpenCL 工作項(xiàng)一對(duì)一映射到輸出點(diǎn),可以輕松實(shí)現(xiàn)多輸出點(diǎn)的并行計(jì)算。在卷積神經(jīng)網(wǎng)絡(luò)中,卷積層、批量歸一化和激活函數(shù)層通常形成一個(gè)固定的結(jié)構(gòu)。為了進(jìn)一步優(yōu)化數(shù)據(jù)流,采用算子融合,將固定結(jié)構(gòu)的計(jì)算集中處理,減少數(shù)據(jù)移動(dòng)和內(nèi)核啟動(dòng)關(guān)閉帶來(lái)的額外性能開(kāi)銷。下面為卷積計(jì)算convolutional_kernels_cl.cpp 函數(shù)設(shè)計(jì):

2.3 基于TVM 的加速優(yōu)化設(shè)計(jì)實(shí)現(xiàn)
為了描述算法模型中計(jì)算操作指定的張量輸出大小以及每個(gè)元素的計(jì)算表達(dá)式,TVM 采用一種張量描述語(yǔ)言來(lái)描述張量在索引空間中的每個(gè)操作,張量描述語(yǔ)言不僅支持常見(jiàn)的數(shù)學(xué)運(yùn)算表示,而且實(shí)現(xiàn)了常見(jiàn)的深度學(xué)習(xí)運(yùn)算符的表示。借用Halide 將計(jì)算算法和調(diào)度邏輯進(jìn)行抽象并分離的思想優(yōu)化神經(jīng)網(wǎng)絡(luò)算子,然后采用一些搜索算法來(lái)找到較優(yōu)的調(diào)度方案,從而自動(dòng)生成最終的執(zhí)行代碼。其中Halide 是C++實(shí)現(xiàn)的圖像處理領(lǐng)域的領(lǐng)域?qū)S谜Z(yǔ)言(DomainSpecifiedLanguage,DSL)。它的特點(diǎn)是實(shí)現(xiàn)了圖像算法的運(yùn)算(包含函數(shù)及表達(dá)式),這些運(yùn)算在計(jì)算硬件單元上以函數(shù)為單位進(jìn)行可分離性的調(diào)度。
2.3.1 TVM 運(yùn)行環(huán)境搭建
在異構(gòu)平臺(tái)上構(gòu)建TVM 運(yùn)行環(huán)境,運(yùn)行系統(tǒng)為Windows10 x64,由于TVM 需要將張量表達(dá)式映射到特定的低級(jí)代碼以便部署在異構(gòu)平臺(tái)上,因此需要采用低級(jí)編譯器中間表示(IR),準(zhǔn)備visualstudio2017,CMake。由于TVM 在CPU 平臺(tái)的編譯會(huì)依賴LLVM,下載LLVM source code 和Clang source code 并使用CMake 編譯,再添加到系統(tǒng)路徑下配置系統(tǒng)環(huán)境變量,配置CUDA 及OpenCL。
接下來(lái)安裝TVM,從GitHub 上下載整個(gè)安裝包,修改tvm 源碼下面的CMakeLists.txt,把USE_LLVM、USE_OPENCL、USE_CUDA 等設(shè)置修改為ON。使用CMake 編譯生成tvm.sln,打開(kāi)tvm.sln,確認(rèn)編譯的平臺(tái)和版本release x64,編譯成功后,獲取Windows 動(dòng)態(tài)庫(kù)libtvm.dll,libtvm_topi.dll, 進(jìn) 入tvm/python,tvm/topi/python,運(yùn)行pythonsetup.pyinstall,安裝成功便可以導(dǎo)入tvm 包文件。
2.3.2 YOLOv3 模型優(yōu)化部署
使用TVM 進(jìn)行模型部署的完整流程:
(1)導(dǎo)入DarkNet 深度學(xué)習(xí)框架的YOLOv3 模型,以實(shí)現(xiàn)計(jì)算圖 iR(中間表示)的轉(zhuǎn)換。
(2)對(duì)原始計(jì)算圖中間表示(IR)進(jìn)行計(jì)算圖優(yōu)化,得到優(yōu)化的計(jì)算圖。
(3)對(duì)計(jì)算圖中的每個(gè)計(jì)算操作用張量表示描述語(yǔ)言描述的張量計(jì)算表達(dá)式,并針對(duì)異構(gòu)硬件平臺(tái),選擇最小計(jì)算原語(yǔ)生成具體的調(diào)度。
(4)使用基于成本模型的機(jī)器學(xué)習(xí)自動(dòng)優(yōu)化器生成經(jīng)過(guò)優(yōu)化的特定的低級(jí)代碼。
(5)生成特定于硬件設(shè)備的二進(jìn)制程序。
(6)構(gòu)建異構(gòu)平臺(tái)可部署的模型。
訓(xùn)練好的模型編譯為T(mén)VM 模型,TVM 模型由deploy.dll、deploy.json、deploy.params 三個(gè)文件組成。將生成的TVM 部署庫(kù)文件deploy.dll 添加到動(dòng)態(tài)鏈接庫(kù),deploy.json、deploy.params 作為資源文件加入工程項(xiàng)目中。部分核心代碼代碼如下:

3 實(shí)驗(yàn)結(jié)果與分析
本文分為三組實(shí)驗(yàn)組進(jìn)行對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)組一從MagicData 發(fā)布的開(kāi)源DMS 駕駛員行為數(shù)據(jù)集中隨機(jī)抽5000 張圖,劃分為5 個(gè)圖片集,將準(zhǔn)備好的每組測(cè)試集圖片的路徑全部存放在一個(gè)txt 文件里建立測(cè)試文件,修改detector.c 文件,在異構(gòu)平臺(tái)上用GPU+CUDA cuDNN 庫(kù)執(zhí)行批量測(cè)試,重新make Darknet 框架,進(jìn)行五次重復(fù)測(cè)試,并記錄圖片識(shí)別推理時(shí)間,得到原模型在 GPU 并行運(yùn)行的性能數(shù)據(jù),該實(shí)驗(yàn)為基準(zhǔn)實(shí)驗(yàn)組。
實(shí)驗(yàn)組二將YOLOv3 算法移植到基于 OpenCL 的異構(gòu)平臺(tái)上實(shí)現(xiàn)優(yōu)化卷積計(jì)算過(guò)程,融合卷積層+批量歸一化+激活函數(shù)層固定的組成結(jié)構(gòu),在主機(jī)函數(shù)和內(nèi)核函數(shù)設(shè)計(jì)實(shí)現(xiàn)過(guò)程中運(yùn)用循環(huán)展開(kāi)、向量化、數(shù)據(jù)重排、多線程并行和內(nèi)存訪問(wèn)優(yōu)化等運(yùn)算并行化策略,同時(shí)將計(jì)算負(fù)載合理分配給 CPU 和 GPU,通過(guò) OpenCL 實(shí)現(xiàn)異構(gòu)并行計(jì)算并解決移植性問(wèn)題。基于 OpenCL 的異構(gòu)并行編程模型,在CPU+GPU 異構(gòu)計(jì)算平臺(tái)上運(yùn)行 YOLOv3 算法模型,得到手動(dòng)優(yōu)化算法模型運(yùn)行性能數(shù)據(jù)。
手動(dòng)憑借經(jīng)驗(yàn)在異構(gòu)平臺(tái)對(duì)算法模型優(yōu)化設(shè)計(jì),存在局限性,無(wú)法實(shí)現(xiàn)全局最優(yōu)以及負(fù)載均衡,對(duì)于算法的優(yōu)化,涉及高性能張量分解,數(shù)據(jù)布局,低開(kāi)銷負(fù)載平衡調(diào)度,內(nèi)存分配、通信、同步等多重優(yōu)化方案。引入TVM 自動(dòng)優(yōu)化算法模型,并面向目標(biāo)平臺(tái)編譯生成部署代碼。以實(shí)驗(yàn)組一和實(shí)驗(yàn)組二為參考,在實(shí)驗(yàn)組二算法實(shí)現(xiàn)的基礎(chǔ)上植入TVM 的 CPU/GPU 自動(dòng)編譯優(yōu)化部署運(yùn)行測(cè)試,得到測(cè)試結(jié)果。對(duì)比結(jié)果如表1,圖4 所示。
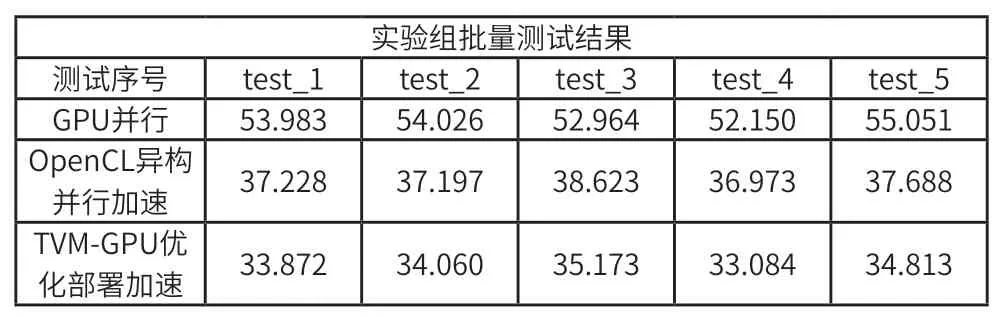
表1 優(yōu)化對(duì)比實(shí)驗(yàn)

圖4 優(yōu)化對(duì)比實(shí)驗(yàn)結(jié)果
通過(guò)實(shí)驗(yàn)數(shù)據(jù)結(jié)果,計(jì)算三個(gè)實(shí)驗(yàn)組的平均時(shí)間分別53.635(ms)、37.542(ms)、34.200(ms),實(shí)驗(yàn)表明 YOLOv3 算法在基于OpenCL 的 CPU+GPU 異構(gòu)計(jì)算平臺(tái)上相對(duì)于GPU 加速比達(dá)到 1.42。TVM 優(yōu)化部署在GPU加速比達(dá)到 1.56,并且相對(duì)于手動(dòng)優(yōu)化也能達(dá)到1.10 的加速比。結(jié)果表明,本文提出的基于OpenCL 異構(gòu)平臺(tái)的視頻監(jiān)控圖像處理加速方案和自調(diào)優(yōu)化編譯方法具有可行性和有效性,突破了原算法的應(yīng)用平臺(tái)局限性,有利于與其他設(shè)備擴(kuò)展結(jié)合及移植且自動(dòng)編譯優(yōu)化方案可快速部署在各種設(shè)備端。

4 結(jié)束語(yǔ)
本文主要從汽車智能化的駕駛員監(jiān)控系統(tǒng)實(shí)際應(yīng)用出發(fā),構(gòu)建了OpenCL 框架下的自調(diào)編程模型和TVM 優(yōu)化編譯器以及算法研究,利用 OpenCL 在基于GPU 的異構(gòu)計(jì)算平臺(tái)上實(shí)現(xiàn)視頻圖像識(shí)別 YOLO 算法的并行化加速,并進(jìn)一步結(jié)合TVM 進(jìn)行自動(dòng)編譯優(yōu)化部署,完成了三個(gè)對(duì)照組實(shí)驗(yàn),結(jié)果表明相較于基準(zhǔn)對(duì)照實(shí)驗(yàn),植入YOLOv3 算法的OpenCL 異構(gòu)并行編程模型的加速比能達(dá)到1.42,基于TVM 優(yōu)化部署后加速比能達(dá)到1.56。表明本文提出的基于異構(gòu)平臺(tái)的圖像識(shí)別加速方案和基于 TVM 的端到端自動(dòng)優(yōu)化編譯方法具有可行性和有效性,且OpenCL 框架突破了原始基于 CUDA 的應(yīng)用平臺(tái)局限性,利于與其他設(shè)備擴(kuò)展結(jié)合及移植且自動(dòng)編譯優(yōu)化方案可快速部署在各種設(shè)備端。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國(guó)特種設(shè)備安全(2022年6期)2022-09-20 02:52:28
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:26:08
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
