基于遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的情緒分析算法在自然語(yǔ)言處理中的研究
2024-04-23 06:15:30張世宏賴(lài)德剛黃婷婷
中國(guó)信息化 2024年3期
張世宏 賴(lài)德剛 黃婷婷
一、引言
自然語(yǔ)言處理(NLP)的核心目標(biāo)是使計(jì)算機(jī)能夠理解和處理人類(lèi)語(yǔ)言,其中情感分析是NLP領(lǐng)域的重要分支,其主要用于解讀和理解文本中的情感趨勢(shì),以實(shí)現(xiàn)對(duì)文本的情感分類(lèi)或預(yù)測(cè)。早期采用簡(jiǎn)單RNN結(jié)構(gòu)的情感分析算法在處理長(zhǎng)期依賴(lài)關(guān)系上常面臨梯度消失或梯度爆炸等問(wèn)題,因此在處理復(fù)雜任務(wù)時(shí)其性能受到了限制。現(xiàn)在,長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)在情感分析中展現(xiàn)出了強(qiáng)大的性能,提高了情感分析任務(wù)的準(zhǔn)確率。雙向循環(huán)神經(jīng)網(wǎng)絡(luò)和注意力機(jī)制也獲得了成功應(yīng)用。在實(shí)際的情感分析應(yīng)用中,社交媒體分析、電影評(píng)論分析和產(chǎn)品評(píng)論分析等方面都具有許多研究?jī)r(jià)值。本文通過(guò)數(shù)據(jù)預(yù)處理技術(shù),將原始文本轉(zhuǎn)換為RNN模型可接受的形式,使用訓(xùn)練數(shù)據(jù)進(jìn)行RNN模型的訓(xùn)練和參數(shù)優(yōu)化,并通過(guò)測(cè)試數(shù)據(jù)對(duì)訓(xùn)練好的模型進(jìn)行評(píng)估,計(jì)算F1分?jǐn)?shù)、準(zhǔn)確率等性能指標(biāo)。本研究的目標(biāo)是探索基于RNN的情感分析算法在電影評(píng)論中的應(yīng)用,利用RNN模型來(lái)分析文本情感,為相關(guān)領(lǐng)域的應(yīng)用和研究提供有價(jià)值的參考資料。
二、算法設(shè)計(jì)
本文算法設(shè)計(jì)思路源于我們處理時(shí)間序列數(shù)據(jù)的方式,可以有效地掌握在序列數(shù)據(jù)中出現(xiàn)的時(shí)間序列信息和上下文關(guān)聯(lián)性。采用遞歸神經(jīng)網(wǎng)絡(luò)(RNN)實(shí)現(xiàn),其實(shí)現(xiàn)過(guò)程中需要為訓(xùn)練準(zhǔn)備好輸入數(shù)據(jù)和相應(yīng)的標(biāo)簽,并選用合適的循環(huán)單元類(lèi)型,如基礎(chǔ)循環(huán)單元、長(zhǎng)短期記憶單元或門(mén)控循環(huán)單元。在編譯模型之前,需要設(shè)定損失函數(shù)、優(yōu)化器和評(píng)價(jià)指標(biāo),常用的損失函數(shù)是交叉熵?fù)p失函數(shù),優(yōu)化器可以選擇Adam或SGD,評(píng)價(jià)指標(biāo)可以選擇準(zhǔn)確率。在訓(xùn)練階段,通過(guò)反向傳播算法更新模型參數(shù),讓模型逐漸學(xué)習(xí)并掌握輸入序列的模式和規(guī)律,還可以使用驗(yàn)證集來(lái)評(píng)估模型和預(yù)防過(guò)擬合。模型訓(xùn)練完成后,可以用測(cè)試集對(duì)模型進(jìn)行最后的評(píng)估,根據(jù)任務(wù)需求,預(yù)測(cè)結(jié)果可以進(jìn)行后續(xù)的分析和應(yīng)用。在實(shí)際操作中,還可以根據(jù)任務(wù)特性和需求進(jìn)行適當(dāng)?shù)恼{(diào)整和優(yōu)化,如添加正則化處理、使用dropout等技術(shù)來(lái)提升模型的泛化能力和預(yù)防過(guò)擬合。此外,還可以結(jié)合其他的技術(shù)和模型進(jìn)行優(yōu)化,如注意力機(jī)制、雙向RNN等。RNN的核心概念包括前向傳播公式、輸出公式和隱藏狀態(tài)傳遞公式,其中隱藏狀態(tài)可以看作是模型對(duì)過(guò)去輸入序列的記憶或表示。通過(guò)隱藏狀態(tài)的傳遞或更新,RNN可以在時(shí)間序列上循環(huán)傳遞,同時(shí)還可以結(jié)合反向傳播算法,計(jì)算損失函數(shù)對(duì)各個(gè)參數(shù)的梯度,從而進(jìn)行參數(shù)更新和模型優(yōu)化。在具體實(shí)現(xiàn)中,還需要選擇和配置具體的激活函數(shù)、損失函數(shù)等。RNN實(shí)現(xiàn)過(guò)程如圖1所示。

三、情感分析算法實(shí)現(xiàn)
情感分析算法的設(shè)計(jì)是本文的核心內(nèi)容之一,本研究采用基于遞歸神經(jīng)網(wǎng)絡(luò)的方法來(lái)實(shí)現(xiàn)情感分析,算法設(shè)計(jì)主要包括以下步驟:
數(shù)據(jù)準(zhǔn)備:研究主要集中在IMDB的電影評(píng)論數(shù)據(jù)集上。數(shù)據(jù)集中的文本數(shù)據(jù)已經(jīng)經(jīng)過(guò)標(biāo)記,標(biāo)記對(duì)應(yīng)不同的情感類(lèi)別,例如正面、負(fù)面、中立等。通過(guò)這些數(shù)據(jù)準(zhǔn)備,可以為情感分析算法提供準(zhǔn)備好的數(shù)據(jù)集,方便后續(xù)的模型訓(xùn)練和評(píng)估。
特征提取:主要是將電影評(píng)論的文本數(shù)據(jù)轉(zhuǎn)換為適用于RNN處理的特征表示。它包括五個(gè)主要部分:讀取測(cè)試數(shù)據(jù),創(chuàng)建和適配分詞器,將文本數(shù)據(jù)轉(zhuǎn)換為序列,序列填充以及標(biāo)簽獨(dú)熱編碼和數(shù)據(jù)劃分。通過(guò)讀取名為電影評(píng)論Test.txt的文件獲取測(cè)試數(shù)據(jù)。使用分詞器Tokenizer將文本轉(zhuǎn)換成數(shù)值型數(shù)據(jù),并構(gòu)建詞匯表。使用適配過(guò)的分詞器將訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)的文本轉(zhuǎn)換為數(shù)值序列,序列長(zhǎng)度被填充到100,以便RNN處理。標(biāo)簽也被轉(zhuǎn)換成獨(dú)熱編碼形式。隨機(jī)劃分訓(xùn)練數(shù)據(jù)成訓(xùn)練集和驗(yàn)證集,確保模型泛化性能。整個(gè)程序綜合了分詞、填充、編碼和劃分等技術(shù),為情感分析任務(wù)提供了良好的數(shù)據(jù)基礎(chǔ)。
構(gòu)建RNN模型:本文在設(shè)計(jì)上采用了循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)中的長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM),總共實(shí)現(xiàn)分三步完成。第一步,通過(guò)Keras的Sequential()方法創(chuàng)建一個(gè)空的序貫?zāi)P停缓筇砑右粚覧mbedding層作為詞嵌入層,將詞的整數(shù)表示轉(zhuǎn)換為密集向量。Embedding層的參數(shù)確定了輸入數(shù)據(jù)的最大詞匯量、詞嵌入的維度和輸入序列的長(zhǎng)度。第二步,添加兩個(gè)LSTM層,每個(gè)LSTM層都有32個(gè)隱藏單元,并通過(guò)dropout參數(shù)設(shè)置隨機(jī)失活的概率。第一個(gè)LSTM層設(shè)置return_sequences=True,以便將每個(gè)時(shí)間步的隱藏狀態(tài)傳遞給下一個(gè)LSTM層。緊接著,添加一個(gè)全連接層(Dense層),它有64個(gè)神經(jīng)元,并使用ReLU激活函數(shù)。然后添加一個(gè)Dropout層,以防止過(guò)擬合。第三步,添加輸出層,它是一個(gè)全連接層,有2個(gè)神經(jīng)元對(duì)應(yīng)兩種情感類(lèi)別,并使用softmax激活函數(shù)輸出預(yù)測(cè)概率。這個(gè)RNN模型結(jié)合了LSTM和dropout等技術(shù),能夠在處理文本情感分析任務(wù)時(shí)更好地解決梯度消失和爆炸問(wèn)題,提高模型的準(zhǔn)確性和泛化性能。
模型訓(xùn)練:使用標(biāo)記的訓(xùn)練數(shù)據(jù)對(duì)RNN模型進(jìn)行訓(xùn)練。在訓(xùn)練過(guò)程中,將文本序列輸入RNN模型,通過(guò)優(yōu)化算法(如隨機(jī)梯度下降)調(diào)整模型參數(shù),提高對(duì)情感類(lèi)別的預(yù)測(cè)能力。使用model.compile()函數(shù)配置模型的訓(xùn)練過(guò)程,選擇分類(lèi)交叉熵作為損失函數(shù),優(yōu)化器選擇Adam,并將準(zhǔn)確率作為評(píng)估指標(biāo)。通過(guò)model.fit()函數(shù)進(jìn)行模型訓(xùn)練,使用訓(xùn)練數(shù)據(jù)的特征和標(biāo)簽進(jìn)行訓(xùn)練,并提供驗(yàn)證數(shù)據(jù)來(lái)評(píng)估模型性能。進(jìn)行20輪訓(xùn)練,每輪使用64個(gè)樣本進(jìn)行訓(xùn)練。model.fit()函數(shù)返回一個(gè)History對(duì)象,其中包含每個(gè)epoch的訓(xùn)練損失、驗(yàn)證損失、訓(xùn)練準(zhǔn)確率和驗(yàn)證準(zhǔn)確率等信息。這樣的訓(xùn)練過(guò)程能夠使模型逐漸優(yōu)化參數(shù),提高對(duì)情感類(lèi)別的預(yù)測(cè)準(zhǔn)確性。
模型評(píng)估:使用預(yù)留的測(cè)試數(shù)據(jù)集對(duì)訓(xùn)練好的RNN模型進(jìn)行評(píng)估。常用的評(píng)估指標(biāo)包括準(zhǔn)確率、精確率、召回率和F1分?jǐn)?shù)等,用于衡量模型在情感分析任務(wù)上的性能。設(shè)計(jì)了model.evaluate()函數(shù)用于評(píng)估模型的性能,該函數(shù)將模型對(duì)測(cè)試數(shù)據(jù)進(jìn)行預(yù)測(cè),并將預(yù)測(cè)結(jié)果與真實(shí)的標(biāo)簽進(jìn)行比較,計(jì)算出損失值和指定的評(píng)估指標(biāo)。這個(gè)過(guò)程不會(huì)改變模型的參數(shù),只是用于衡量模型的性能。model.evaluate()函數(shù)返回的是一個(gè)包含損失值和所有評(píng)估指標(biāo)值的列表。有兩個(gè)返回值:test_loss和test_ accuracy,分別代表在測(cè)試集上的損失值和準(zhǔn)確率。最后,將這兩個(gè)值輸出,以便查看模型在測(cè)試集上的表現(xiàn)。這兩個(gè)指標(biāo)反映了模型在未見(jiàn)過(guò)的數(shù)據(jù)上的預(yù)測(cè)能力,可以幫助我們判斷模型的泛化能力。
四、算法結(jié)果分析
(一)初始方案

隨機(jī)選擇10個(gè)樣本,輸入初始化RNN模型進(jìn)行訓(xùn)練,得到在訓(xùn)練過(guò)程中準(zhǔn)確率和損失值。從圖2、圖3可見(jiàn)測(cè)試集上的損失值為0.6893,準(zhǔn)確率為0.5122,以上數(shù)據(jù)可以看出損失值較高且準(zhǔn)確率較低。模型的損失值較高表示模型對(duì)于某些樣本的預(yù)測(cè)存在較大的誤差,準(zhǔn)確率較低表示模型在預(yù)測(cè)時(shí)存在一定程度的誤分類(lèi)。效果并不理想,需要對(duì)模型進(jìn)行進(jìn)一步優(yōu)化。
(二)優(yōu)化方案
本文提出了一種優(yōu)化方案,該方案采用本文情感分析算法,在模型的最后添加了一個(gè)具有64個(gè)神經(jīng)元的全連接層,并使用ReLU激活函數(shù)。全連接層可以進(jìn)一步提取抽象的特征表示,并增加模型的非線(xiàn)性能力。更多的神經(jīng)元可以提供更豐富的特征表達(dá)能力,有助于提高模型的性能。


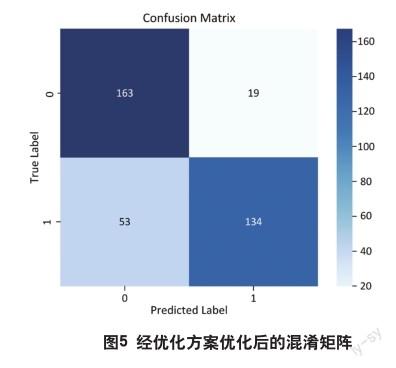
從圖4可以看出,輸入與初始方案相同的樣本,優(yōu)化后模型的測(cè)試損失為0.4652,表示模型在測(cè)試集上的平均損失較低。較低的損失值意味著模型能夠更準(zhǔn)確地預(yù)測(cè)樣本的標(biāo)簽。模型的測(cè)試準(zhǔn)確率為80.49%,表示在測(cè)試集上能夠正確預(yù)測(cè)80.49%的樣本標(biāo)簽。結(jié)果表明,經(jīng)過(guò)優(yōu)化的模型在測(cè)試集上取得了較好的性能。然而,準(zhǔn)確率和損失值并不能完全描述模型的性能,因此還需要綜合考慮其他指標(biāo)和評(píng)估方法,如精確率、召回率、F1值等,以全面評(píng)估模型的性能和可靠性。從圖5可以看出,混淆矩陣的每個(gè)方塊提供了關(guān)于模型預(yù)測(cè)結(jié)果的信息,從而可以計(jì)算出多個(gè)評(píng)估指標(biāo)。本模型精確率為89.56%,表示有約89.56%是真正的正類(lèi)樣本。模型召回率為75.47%,意味著模型能夠正確地識(shí)別出約75.47%的正類(lèi)樣本。模型F1值為81.98%,F(xiàn)1值越高,說(shuō)明模型在預(yù)測(cè)和識(shí)別上的綜合表現(xiàn)越好。經(jīng)過(guò)優(yōu)化后的結(jié)果要遠(yuǎn)高于初始模型。
五、結(jié)論
本研究基于遞歸神經(jīng)網(wǎng)絡(luò)(RNN)實(shí)現(xiàn)了情感分析算法,并在IMDB電影評(píng)論數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)和優(yōu)化。經(jīng)過(guò)多次迭代和參數(shù)調(diào)整,得到了優(yōu)化后的RNN模型,并通過(guò)評(píng)估指標(biāo)對(duì)其性能進(jìn)行了評(píng)估。本文在初始模型的基礎(chǔ)上增加了一個(gè)具有64個(gè)神經(jīng)元的全連接層,并使用了ReLU激活函數(shù)。經(jīng)過(guò)優(yōu)化后,模型的測(cè)試準(zhǔn)確率提高到80.49%,損失值下降到0.4652。通過(guò)混淆矩陣的分析,發(fā)現(xiàn)模型對(duì)于負(fù)面評(píng)論的預(yù)測(cè)準(zhǔn)確性較低。總之,通過(guò)持續(xù)改進(jìn)算法和模型,我們可以更好地理解和分析人類(lèi)的情感傾向,為社會(huì)輿情分析、市場(chǎng)調(diào)研、用戶(hù)反饋分析等領(lǐng)域提供有價(jià)值的信息和洞察。
作者單位:張世宏、賴(lài)德剛 中國(guó)電子科技集團(tuán)公司第三十研究所
黃婷婷 成都工百利自動(dòng)化設(shè)備有限公司
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽(yáng)畫(huà)報(bào)(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
