重載鐵路列車障礙物檢測研究
2024-05-01 14:57:40張東濤
鐵路通信信號工程技術 2024年4期
張東濤
(國能新朔鐵路有限責任公司,呼和浩特 010300)
1 概述
從列車行車方面來看,異物入侵是影響其安全的一項重要因素。鐵路覆蓋區(qū)域跨度大,沿線地形地貌復雜多變,部分線路沒有布置于高架橋上且沒有鐵絲網防護,周圍人員和動物活動頻繁、兩側樹木生長茂盛時均有可能入侵軌行區(qū),總體運營環(huán)境復雜,所以對于軌行區(qū)異物入侵檢測的需求較大。由自然災害引起的泥石流覆蓋軌道等,國內外均有事故發(fā)生。列車一旦在運行中與障礙物發(fā)生碰撞,將會帶來嚴重后果,研究障礙物檢測技術具有重要意義。另外,貨運鐵路通常存在運力緊張、作業(yè)繁忙等問題,加上貨物裝卸、巡檢等作業(yè)人員較多,容易發(fā)生工作人員誤入線路的情況。僅依靠司機瞭望檢測軌行區(qū)障礙物這種傳統(tǒng)方式存在以下缺點:1)在惡劣天氣或光線昏暗時肉眼識別的可靠性低;2)受到生理機能限制,人眼遠距離識別障礙物困難,難以預防或避免事故;3)檢測結果受人員注意力是否集中等主觀因素影響較大;4)人工瞭望的方式不適應全自動軌道交通的發(fā)展要求。通過增加障礙物探測裝置可以有效避免列車與人員之間的碰撞事故,其能夠實時檢測線路上的障礙物,及時向司機發(fā)送警報,以便司機能夠采取制動措施。
當前,關于列車自主障礙物檢測技術的研究較多。有學者以激光雷達作為傳感器,提出考慮激光反射強度的全自動運行列車障礙物檢測方法,實現(xiàn)列車自主障礙物檢測,但由于激光束沿直線傳播,該方法在軌道彎曲區(qū)段應用效果差,導致最遠探測距離只能達到80 ~100 m。張林等以小型障礙物作為目標,提出基于視覺和Faster RCNN(Faster Region Based CNN)網絡的障礙物檢測算法,融合FPN(Feature Pyramid Network)網絡與Faster RCNN 原始網絡,使小型障礙物的位置信息和語義信息融合,提高了對小型障礙物的辨識能力,但是無法避免基于視覺傳感器的算法在雨、雪、霧和隧道等環(huán)境下檢出率低的缺陷。綜上所述,傳感器本身固有的限制導致基于單一傳感器的障礙物檢測方法信息來源單一、檢出率有限。多傳感器融合的檢測方法才能實現(xiàn)多源信息采集,許多學者開始研究基于多傳感器的障礙物檢測方法。趙宇恒分析了鐵路環(huán)境的特點及各傳感器性能,面向振動劇烈、檢測目標信號難以區(qū)分和具有電磁噪聲污染的高動態(tài)鐵路環(huán)境提出毫米波雷達與激光雷達融合檢測的方法,用毫米波雷達檢測目標位置、速度信息,用激光雷達采集軌道限界信息,再進行時間配準和空間配準,以融合檢測目標信息和軌道信息進行障礙物檢測。鞠夕強在機動車的環(huán)境感知中提出基于毫米波雷達與雙目視覺融合的方法,其中,在雷達數(shù)據(jù)處理方面采用基于DBSCAN 算法的自適應聚類算法提高毫米波雷達數(shù)據(jù)聚類效果,在多傳感器融合處理方面,在進行時間配準、空間同步后采用了特征級與決策級結合的方法融合兩種傳感器的數(shù)據(jù),最后經實驗證明該方法的物體識別率優(yōu)于單傳感器檢測,但是由于實驗中使用的毫米波雷達不具備高度信息,視角僅為一個平面,對高處物體的檢測能力弱,如會將高處的高架誤檢為障礙物。孫一珉研究了隧道內微光、封閉環(huán)境的障礙物檢測,提出熱成像儀與光學攝像機融合的方法,用時間戳配準方法和以世界坐標系為過渡坐標系的方式進行兩個傳感器數(shù)據(jù)時間、空間配準,采用基于IHS(Intensity、Hue、Saturation)技術和小波的融合方法,將熱成像圖像中物體溫差特征與光學圖像中物體色彩細節(jié)特征結合起來,提高隧道環(huán)境下對障礙物的辨識能力,但是由于熱成像儀對遠距離目標的成像效果差,所提方法難以滿足對遠距離障礙物檢測的需求。綜上所述,多傳感器融合的方法雖然為障礙物檢測提供了多源的信息,但是不合適的傳感器也會限制整個系統(tǒng)的檢測性能。
本文提出了一種基于激光雷達和視覺融合的障礙物檢測系統(tǒng)(簡稱系統(tǒng)),結合了激光雷達測距、定位精度高且受光照、天氣影響小的優(yōu)勢與高清像機能獲取豐富環(huán)境、顏色信息的優(yōu)勢,實現(xiàn)精準、可靠識別軌行區(qū)障礙物。
2 研究方法
系統(tǒng)具有障礙物檢測功能,利用視覺技術檢測軌行區(qū),輔以激光雷達點云數(shù)據(jù),依托車載探測主機的深度學習算法,實施精準檢測、主動預警,為列車運行提供主動安全保障。
系統(tǒng)結構如圖1 所示,分別在機車兩端車頭安裝激光雷達和高清像機。其中,像機選用長短焦結合的雙目攝像機,內置1 臺遠焦攝像機和1 臺近焦攝像機,能擴大圖像采集范圍,在隧道、高架等照度變化范圍大的環(huán)境中,系統(tǒng)采取激光補光、濾鏡等組合措施,確保采集視頻質量,為障礙物辨識提供高質量基礎數(shù)據(jù)。激光雷達(LiDAR),全稱為激光探測和測距(Light Detection and Ranging),激光發(fā)射器向外發(fā)射激光,激光遇物體后反射,雷達接收器接收反射光線,由反射光線和發(fā)射光線可計算出反射點的相關信息,如距離和高度等。激光雷達采用半固態(tài)激光雷達,由于不具備旋轉組件,能降低設備磨損消耗、降低硬件成本,且在個別光束陣元損壞的前提下,整個雷達仍可持續(xù)工作,提升了可靠性,符合軌道交通長壽命要求。

圖1 系統(tǒng)結構Fig.1 System structure
3 視覺融合方法描述
分別進行基于視覺和激光點云的障礙物檢測,再將檢測結果后融合,如圖2 所示,使兩者互為校驗,從而實現(xiàn)提高檢測結果準確性和可靠性的目的。

圖2 后融合流程Fig.2 Post-fusion flow chart
3.1 基于視覺的障礙物檢測
基于視覺的障礙物檢測流程如圖3 所示。
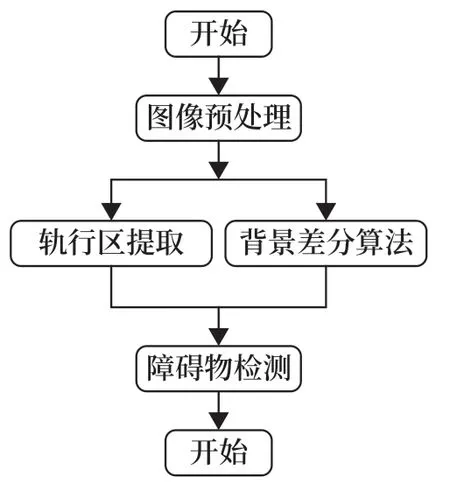
圖3 基于視覺的障礙物檢測流程Fig.3 Vision-based obstacle detection flow chart
步驟如下:
1)圖像預處理,包括提升運算速度的灰度化處理等。圖像由像素點組成,由于每個像素點內均有R、G、B三個顏色分量,每個顏色分量的取值范圍均為[0,255] ,因此每個像素點的顏色變換有1 670萬余種,不便于后續(xù)計算。圖像灰度化處理使圖像像素點中的R、G、B三分量取相等值,則每個像素點的顏色變換只有在[0,255] 范圍內的256 種,大大降低了計算量。本文用彩色圖像中每個像素點R、G、B三分量的平均值作為其灰度值(Grayscale),如公式(1)所示。
2)通過Canny 邊緣檢測算法提取軌道線,結果如圖4 所示。
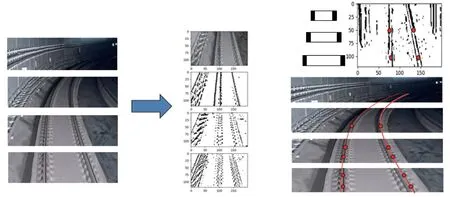
圖4 軌行區(qū)提取Fig.4 Track area extraction
首先,應用高斯濾波去除圖像噪聲,減少噪聲對圖像邊緣的干擾;其次,利用Sobel 算子計算圖像像素梯度,得到圖像中可能存在的邊緣像素點,計算如公式(2)~(4)所示,其中I為圖像像素矩陣,Gx為x方向像素梯度矩陣、Gy為y方向像素梯度矩陣,G與θ分別為梯度的幅度與方向;再次,應用非極大值抑制法去除非邊緣的像素點:遍歷圖像像素點,根據(jù)梯度幅度是否為周圍同梯度方向像素點中的最大值來判斷是否抑制該點,即是否將該點歸零,若該像素點是同梯度方向中的極大值,則保留該點,否則抑制該點;最后,應用雙閾值的方法剔除可能存在的由噪聲產生的邊緣。
3)對圖像進行二值化處理,將所有像素點的值設置為0 或255,此時圖像變?yōu)楹诎讏D像。再通過當前幀與背景幀的差分算法,檢測出障礙物在圖像上的位置。
4)深度學習提取障礙物特征,進一步計算障礙物的大小和距離。
3.2 基于激光點云的障礙物檢測
基于激光點云的障礙物檢測原理如圖5 所示。
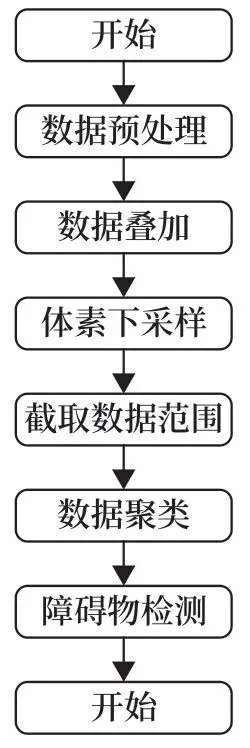
圖5 基于激光點云的障礙物檢測流程Fig.5 Flow chart of obstacle detection based on laser point cloud
步驟如下:
1)對點云數(shù)據(jù)進行預處理:因為在激光雷達采集數(shù)據(jù)的過程中,受到掃描環(huán)境、待測物及雷達自身的影響,點云數(shù)據(jù)中會存在一定噪點,需要進行數(shù)據(jù)清除或平滑等處理,以保證后續(xù)過程的準確性。
2)因為激光雷達采集的點云數(shù)據(jù)比較稀疏,所以疊加當前幀與前3 幀數(shù)據(jù),并對疊加后的數(shù)據(jù)進行體素下采樣,在保持點云形狀特征基本不變、空間結構信息基本保留的情況下,減少點的數(shù)量,降低計算量。體素下采樣原理如圖6 所示,在空間上將采集到的點云數(shù)據(jù)網格化,也稱體素化,得到的小格子稱為體素,對各體素內的點取平均,用平均值來代替體素內原有點即完成體素下采樣過程。體素化時選取的網格大小決定采樣后得到的點云數(shù)據(jù)量,網格越大,則采樣后獲得點云數(shù)據(jù)量越少,計算速度越快,但對原先點云數(shù)據(jù)的還原度越低,因此需合理選擇網格大小。

圖6 體素下采樣原理Fig.6 Schematic diagram of voxel downsampling
3)對采樣后的點云數(shù)據(jù)進行截取,根據(jù)檢測對象不同來決定截取數(shù)據(jù)的范圍:在本文中暫定,檢測列車前方是否有其他列車時,假設h為激光雷達的安裝高度,以激光雷達的安裝位置為坐標原點,截取高度范圍在(-h+0.3 m,-h+5 m)內的點云數(shù)據(jù),以減去高空數(shù)據(jù)和地面數(shù)據(jù)的干擾;檢測軌行區(qū)是否有異物侵限時,同樣以雷達位置作為坐標原點,截取寬度范圍在(-1.5 m,1.5 m)的點云數(shù)據(jù),因為在近距離范圍內軌道彎曲程度不大,因此可近似將軌道視為兩條直線,則軌道限界范圍可視為固定值1.435 m,選擇(-1.5 m,1.5 m)寬度范圍作為固定范圍。
4)通過K-means 算法對截取后的數(shù)據(jù)進行聚類,檢測是否有異物侵限或前方是否有車輛。
3.3 后融合法
采用后融合法處理基于激光點云和基于視覺檢測結果的融合,后融合是指各傳感器根據(jù)各自算法得到結果,再將其融合。由于各傳感器輸出已經為目標輸出,因此,后融合也稱為目標級別融合。其優(yōu)點在于:1)障礙物檢測精度不低于最好的傳感器,并能降低單傳感器的漏檢率或虛警率;2)系統(tǒng)魯棒性強,可容錯單傳感器模塊失效。在本文所提出的系統(tǒng)中,只有基于激光點云和基于視覺的檢測算法均未檢測到前方存在障礙物時才認為前方沒有異物侵限,其余情況均給出告警信息,如表1 所示,其中,0 表示未檢出障礙物,1 表示檢測到障礙物。

表1 檢測結果真值Tab.1 Test result truth value
4 實驗驗證
對系統(tǒng)功能進行驗證實驗:分別以人(170 cm)、行李箱(64 cm×41 cm×26 cm) 和反光三腳架(35 cm×43 cm)作為障礙物模型,分別在列車前方20 m、50 m、100 m、150 m 和200 m 處進行實驗,3種障礙物檢出率均達到100%。結果如表2 所示,該系統(tǒng)能有效、準確地檢測出列車前方障礙物。
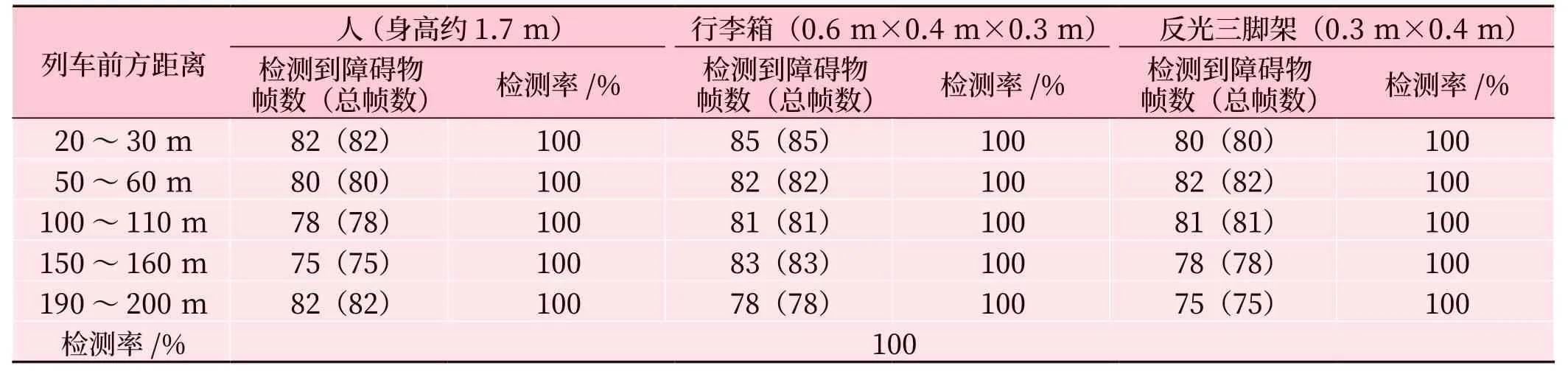
表2 不同障礙物在不同距離下的檢測結果Tab.2 Detection results of different obstacles at different distances
5 實驗數(shù)據(jù)分析
結合表2 的數(shù)據(jù),可以大致獲得以下4 類數(shù)據(jù)關系及結論。
1)障礙物類型與檢測率的關系
對不同類型的障礙物具有很高的識別能力。人、行李箱和反光三腳架在所有距離范圍內都被100%檢測到。
2)距離與檢測率的關系
在較遠的距離上也能保持高檢測率。在20 ~30 m、50 ~60 m、100 ~110 m 和150 ~160 m 的距離范圍內,障礙物的檢測率均為100%。但在190~200 m 的距離范圍內,雖然人被檢測到的幀數(shù)有所下降,但總體檢測率仍然為100%。
3)檢測到的幀數(shù)與總幀數(shù)
無論距離遠近,人、行李箱和反光三腳架在大多數(shù)幀數(shù)中被檢測到,能夠實時、準確地檢測到障礙物。
4)不同障礙物在同一距離內的比較
在20 ~30 m、50 ~60 m、100 ~110 m 和150~160 m 的距離范圍內,人、行李箱和反光三腳架的檢測率均為100%。這說明對于不同類型的障礙物檢測性能是一致的。
在各種距離范圍內都能保持高檢測率,對不同類型的障礙物也有很好的識別能力。尤其在短距離上具有非常高的檢測率,但在較遠的距離上,如190 ~200 m,可能需要進一步提高檢測精度。
6 結束語
本論文提出的雷達和視覺融合技術解決了單一技術的固有問題,為重載列車自主障礙物檢測提供了方法,能替代傳統(tǒng)人工瞭望檢測方式,提高列車主動安全防護能力。由于目前檢測距離受到商用傳感器設備的性能限制,暫時只適用于列車低速運行下且制動距離短的場景。若應用于高速線,仍需要深入研究從而順應全自動軌道交通系統(tǒng)的發(fā)展。
猜你喜歡
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(yè)(2021年19期)2022-01-12 06:16:36
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
無線電工程(2020年11期)2020-10-29 01:25:46
