一種基于MobileFaceNet 的人臉識別方法
2024-05-02 15:48:18陸正球
電腦知識與技術 2024年5期
陸正球
摘要:隨著深度學習技術的發展,人臉識別成為身份識別最常用的生物特征識別技術。針對移動終端計算資源不足的實際情況和特點,該文在MobileNet模型的基礎上,構建基于MobileFaceNet的人臉檢測和識別模型。首先,使用MTCNN模型對傳入的人臉進行檢測,然后采用MobileFaceNet模型進行人臉特征提取,最后通過構建本地人臉庫,完成對人臉圖像識別。實驗結果表明,該方法在常見的人臉數據庫中具有較好的識別準確率。
關鍵詞:人臉識別;MobileFaceNet;人臉檢測;MTCNN
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)05-0012-03
0 引言
人臉識別是計算機視覺領域的關鍵技術,在電子金融、視頻監控、智慧安防、個人生活等方面有著廣闊的應用前景。人臉識別技術作為一種常見的生物識別技術,常用來根據人的臉部特征信息進行身份識別[1]。通過將提取的人臉特征與人臉數據庫中已有的特征進行匹配,再結合設定的閾值就可以根據相似度來判斷人臉信息[2]。具有直接、方便、易被使用者接受的特點,極大地解決了傳統信息安全識別等問題。
當前,在非受控環境下制約人臉識別性能和效果的最主要因素是人臉檢測和人臉特征學習。人臉檢測是指檢測出人臉圖像中人臉的具體位置,是人臉識別不可或缺的重要環節,目前使用最多的是深度級聯的多任務框架MTCNN[3],它具有速度快且在CPU環境下也能進行單臉實時檢測的能力。在人臉特征學習方面,2012年,Krizhevsky[4]首次將深度卷積神經網絡成功應用于解決計算機視覺領域的關鍵問題。Sun等人[5]提出首先將多個深度卷積神經網絡提取的特征拼接并使用PCA降維得到更有效的特征。之后,VGG?Net[6]、GoogLeNet[7]以及ResNet[8]這三類網絡相繼被提出并成功被應用于物體識別和人臉識別。隨后,針對移動端計算資源不足的特點[1],Google在2017年設計了一個專為移動端和嵌入式設備做深度學習計算的輕量級網絡MobileNetV1,該網絡提出了一種新的卷積方式深度可分離卷積[9]。同年9月,曠視科技通過使用Group Convolution 和Channel Shuffle改進ResNet 的殘差模塊[10],提出了一個復雜度更低、精度更高的輕量級網絡ShuffleNet V1。而MobileNet V2 和Shuf?fleNet V2等輕量級網絡的提出為人臉識別任務部署在移動端提供了更便利的條件[11-12]。
1 相關算法應用
1.1 人臉檢測模塊
傳統的人臉檢測方法需要人工提取圖像特征,而基于深度學習的檢測方法通過搭建卷積神經網絡自動提取特征,減少了人為因素的干擾,識別準確度上更高[13]。
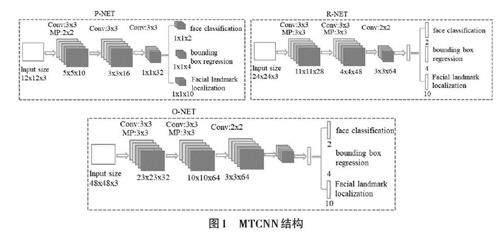
MTCNN 是一個深度級聯的多任務框架,可以同時完成人臉檢測和人臉對齊的功能,具有網絡結構簡單、識別速度快的優點。它由三個子網絡組成,分別是候選網絡(P-Net) 、提純網絡(R-Net) 和輸出網絡(ONet),可同時檢測人臉及定位人臉關鍵點[13]。但是,由于原始的人臉圖片存在尺度不一的情況,對于比較小的人臉,需要放大后再進行檢測;對于比較大的人臉,需要縮小后再圖檢測。在MTCNN中首先要進行將人臉原始圖片縮放到不同尺度,形成一個“圖像金字塔”[14],然后對每個尺度的圖片通過神經網絡計算一遍,這樣可以在統一的尺度下檢測人臉。
1.1.1 P-Net
P-Net是一個全卷積神經網絡,輸入的是一個寬和高都是12像素、3通道的RGB圖像。輸出有三部分:輸入的12×12×3的圖像中是否有人臉,人臉框的位置和5個關鍵點的位置,5個關鍵點是指:左眼、右眼、鼻子、左嘴角、右嘴角。
P-Net采用較低的精度最大程度上保證將所有的人臉都檢測到,在實際計算中,會將輸入的圖像進行多尺度金字塔處理,也就是通過輸入層的移動,對原始圖像中每一個12×12的區域都進行一次人臉檢測。同時,對于重疊的候選框,采用非極大值抑制(NMS) 篩選,最后送入 P-Net 網絡參與訓練。
1.1.2 R-Net
R-Net的結構跟P-Net非常類似,R-Net的輸入是24×24×3的圖像,表示像素值大小是24×24的3通道圖像。R-Net是判斷24×24×3的圖像中是否含有人臉以及預測關鍵點位置。在實際應用中,對每個P-Net 輸出可能為人臉的區域都放大到24×24的大小,再輸入到R-Net中,進行進一步判斷,這樣消除了P-Net中很多誤判的情況,提高人臉檢測的精度。 R-Net網絡結構如下。
1.1.3 O-Net
在R-Net的基礎上,把得到的區域放大至48×48 的大小,作為 O-Net網絡的輸入,其他結構跟P-Net類似,不同點在于O-Net的網絡通道數和層數增多了。
1.2 人臉識別模塊
為了減少移動終端設備的模型計算量與參數量,本文在MobileNet V1[15]網絡模型的基礎上設計了Mo?bileFaceNet模型,它使用深度可分離卷積代替傳統的平均池化操作。該模型同時采用PReLU作為激活函數,在網絡開始階段使用快速下采樣策略,在后面幾層卷積層采用早期降維策略,在最后的線性全局深度卷積層后加入一個1×1 的線性卷積層作為特征輸出[16]。通過這些改進,模型可以獲得更高的準確率及更快的速度。
1.2.1 深度可分離卷
深度可分離卷積則將這個過程分為兩個部分,首先進行深度卷積操作,由于深度卷積在每個通道都與一個卷積核進行卷積操作,因此輸出特征圖與輸入特征圖具有相同的通道數。假如當輸入特征圖為10×10×3,經過3×3×1×3的深度卷積核后會得到一個8×8×3的輸出特征圖,由于維度不變會導致能提取到的特征非常有限[17]。然后,使用逐點卷積操作,解決深度卷積存在的維度不變的問題。當對上面深度卷積輸出的8×8×3的特征圖使用1×1×3的卷積核進行卷積操作后,同樣會得到8×8×1的輸出特征圖。
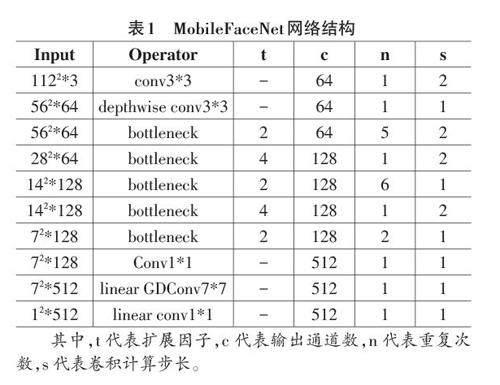
1.2.2 網絡結構
MobileFaceNet 的網絡結構如表1 所示,它采用MobileNet 中的bottle?necks 作為構建網絡的主要模塊,而且Mobile?FaceNet 中的 bottlenecks 的擴展因子更小一點。
2 基于MobileFaceNet的人臉識別設計
整個人臉識別包括人臉數據采集、人臉檢測、人臉特征提取、人臉比對四個階段。
2.1 人臉數據采集
本文主要采用目前公認的人臉數據庫進行模型訓練和測試。CASIA-WebFace是一款免費開源的用于人臉識別的數據集,數據集包含了10 575個人的494 414張圖像,它的優勢在于具有非常多的人臉特征,并且數據集里不會有重復特征。由于lfw數據集在非受限情況下的人臉識別效果檢測效果比較好,是目前人臉識別的常用測試集。該數據集包含5749人,共有13233張人臉圖片,因此本文使用lfw數據集作為模型的測試數據集。此外,在進行人臉識別時,構建一個本地人臉庫,該數據庫中存放需要日常檢測的人臉,每個人一張人臉。
2.2 人臉檢測
本文中采用MTCNN算法進行人臉檢測。首先加載MTCNN模型和人臉數據庫,然后讀取需要檢測的人臉圖片,并對圖片進行預處理。接下來通過MTCNN三個模型調用后獲取人臉特征關鍵點和候選框,本文使用貪婪策略選擇人臉框,設置非極大值0.5作為判定是否保留該人臉圖片的依據,最后使用仿射變化將MTCNN推理得到的人臉關鍵點中雙眼的坐標校正為水平狀態,然后旋轉角度和旋轉中心點,再將MTCNN 推理的人臉框對應旋轉,從而得到校正后的人臉。
2.3 人臉特征提取
本文使用MobileFaceNet作為人臉識別特征提取的基礎網絡,網絡結構如圖4所示。該模型體積較小,準確率很高,非常適用于移動設備。同時,為了使訓練的模型更加有效,本文采用ArcFace作為損失函數。
2.4 人臉比對識別
人臉比對是最后一個階段,將上一步模型提取到的人臉與自己建的本地人臉庫中的已有人臉進行比對,就能獲取與該人臉相似的每個人臉的概率及其對應的姓名,程序會對得到的人臉比對結果進行排序,最后選取排序后概率值最高的那張人臉圖片并表示該人臉圖片對應的姓名,這里設置最小閾值為0.6。
3 實驗
本文所有方法都是在pytorch框架下通過python 語言實現的,訓練和測試步驟在NVIDIA GeForceGTX 1060 GPU上運行。
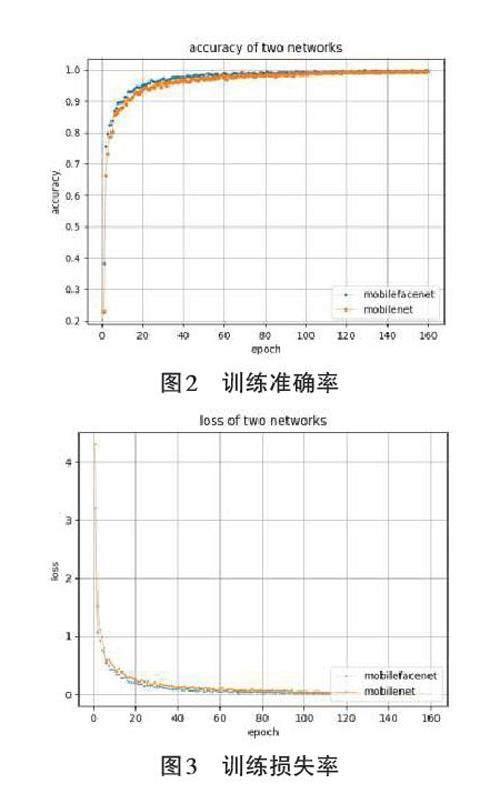
首先,實驗選擇CASIA-WebFace 人臉數據庫進行訓練,由于該數據庫數量比較大,鑒于硬件條件限制,因此選取了其中100人共7 157張人臉,其中90% 數據用于訓練,10%的數據用于測試。訓練總輪數epoch設置為160,訓練初始學習率設置為0.001,訓練中的bitch-size設置為12。使用隨機梯度下降策略優化模型,動量參數設置為 0.9。模型在訓練集上的準確率和誤差loss曲線如圖2和圖3所示。
其次,模型參數量表示網絡模型中包含的參數個數,主要影響模型計算所需要的內存,模型計算量主要衡量模型的復雜度。結果如表2所示,改進的Mo?bileFaceNet的參數量和計算量都有一定程度的降低。
最后,依次傳入兩張人臉圖片分別進行檢測,其中左邊人臉圖片信息已經存儲在本地人臉庫中,右邊人臉圖片信息沒有存儲在本地人臉庫中,測試結果如圖4,可以發現左邊的人臉能夠被檢測并顯示該人臉信息,而右邊則顯示“unknow”。
4 結論
通過對人臉檢測和人臉識別問題的研究,本文提出了一種基于MobileFaceNet的人臉識別方法。首先,使用opencv 進行人臉采集,然后使用級聯網絡MTCNN進行人臉檢測和處理,并使用MobileFaceNet 進行人臉特征提取和人臉比對,最后通過常見人臉數據庫和本地數據庫可知該方法具有較好的人臉識別效果和網絡性能。
參考文獻:
[1] 龔銳.基于深度學習的輕量級和多姿態人臉識別方法[D].武漢:武漢科技大學,2020.
[2] 馬懷清.人臉識別技術在城市軌道交通售檢票系統的應用研究[J].世界軌道交通, 2017(9):54-57.
[3] ZHANG K P,ZHANG Z P,LI Z F,et al.Joint face detection andalignment using multitask cascaded convolutional networks[J].IEEE Signal Processing Letters,2016,23(10):1499-1503.
[4] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C].26th Annual Conference on Neural Information Processing Systems,Lake Tahoe, 2012:1106-1114.
[5] SUN Y,WANG X G,TANG X O.Deeply learned face representa?tions are sparse, selective, and robust[C]//2015 IEEE Confer?ence on Computer Vision and Pattern Recognition (CVPR).Bos?ton,MA,USA.IEEE,2015:2892-2900.
[6] SIMONYAN K,ZISSERMAN A.Very deep convolutional net?works for large-scale image recognition[EB/OL]. [2022-10-20].2014:arXiv:1409.1556.http://arxiv.org/abs/1409.1556.pdf.
[7] SZEGEDY C,LIU W,JIA Y Q,et al.Going deeper with convolu?tions[C]//2015 IEEE Conference on Computer Vision and Pat?tern Recognition (CVPR).Boston,MA,USA.IEEE,2015:1-9.
[8] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vi?sion and Pattern Recognition (CVPR). Las Vegas, NV, USA.IEEE,2016:770-778.
[9] HOWARD A G,ZHU M L,CHEN B,et al.MobileNets:efficient convolutional neural networks for mobile vision applications[EB/OL].[2022-10-20].2017:arXiv:1704.04861.http://arxiv.org/abs/1704.04861.pdf.
[10] ZHANG X Y,ZHOU X Y,LIN M X,et al.ShuffleNet:an ex?tremely efficient convolutional neural network for mobile de?vices[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:6848-6856.
[11] SANDLER M,HOWARD A,ZHU M L,et al.MobileNetV2:in?verted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:4510-4520.
[12] MA N N,ZHANG X Y,ZHENG H T,et al.ShuffleNet V2:practi?cal guidelines for efficient CNN architecture design[C]//Com?puter Vision-ECCV 2018:15th European Conference,Munich,Germany,September 8-14,2018,Proceedings,Part XIV.ACM,2018:122-138.
[13] 尚曉銳.基于深度神經網絡的人臉識別校園門禁系統設計與實現[D].重慶:重慶理工大學,2020.
[14] 高峰.基于人臉特征分析的哨兵疲勞警示系統的設計與實現[D].長沙:湖南師范大學,2019.
[15] HOWARD A G,ZHU M L,CHEN B,et al.MobileNets:efficient convolutional neural networks for mobile vision applications[EB/OL].[2022-10-20].2017:arXiv:1704.04861.http://arxiv.org/abs/1704.04861.pdf.
[16] 李航.基于MobileFaceNet的輕量化人臉識別系統的設計與實現[D].重慶:西南大學,2020.
[17] 瞿照.移動端人臉識別系統活體檢測實現技術[D].武漢:華中科技大學,2021.
【通聯編輯:代影】
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
學生天地(2020年31期)2020-06-01 02:32:06
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
