基于KNN的電力計量自動化系統異常分析
2024-05-12 11:28:10鐘睿君
電子產品世界 2024年1期
關鍵詞:數據挖掘
鐘睿君

摘要:針對電力計量自動化系統異常分析的問題,提出了一種基于 K 最近鄰(k-nearest neighbor,KNN) 算法的異常檢測方法。通過概述電力計量自動化系統的結構以及常見檢測方法,重點探究 KNN 算法的應 用,驗證了其在電力計量自動化系統中的有效性。實驗結果表明,基于 KNN 算法的異常檢測方法能夠較好 地發現和定位系統的異常情況,為系統運行維護提供了重要支持。
關鍵詞:數據挖掘;電力計量自動化;電力計量;計量自動化
中圖分類號:TP311.13;TM933.4文獻標識碼:A
0 引言
信息時代下,數據的積累和應用已經成為各行 各業不可或缺的一部分 [1]。在電力行業中,電力計 量自動化系統作為電力系統的關鍵組成部分,其產 生的海量數據蘊含著寶貴的信息。然而,要從這些 數據中準確地發現異常情況并非易事。這就需要將 現代數據挖掘技術與電力計量自動化系統相結合, 從而更有效地分析和處理異常情況。
數據挖掘作為一種強大的技術手段,具有從大 量數據中發現隱藏信息和規律的能力。通過運用數 據挖掘技術,可以更加深入地挖掘電力系統運行過 程中所產生的數據,識別出其中的異常模式和規 律。例如,基于數據挖掘的異常檢測算法可以實現 快速發現電力系統中的異常行為,從而提前預警潛 在的問題,保障電力系統的穩定運行 [2-4]。
因此,將數據挖掘技術與電力計量自動化系統 相結合,不僅可以提高發現和處理的異常情況效 率,還可以為電力系統的優化提供新的思路和方 法。本文旨在探討如何利用數據挖掘技術來改進電 力計量自動化系統的異常分析能力,以應對日益復 雜的電力系統運行環境 [5]。
1 計量自動化系統結構及常見檢測方法
1.1 電力計量自動化系統結構
電力計量自動化系統的結構主要包括:傳感器 和儀表,用于實時測量電力參數;通信網絡,通過 有線或無線通信協議將數據傳輸至中央數據管理系 統;數據管理系統,負責數據存儲、實時監測、分 析和報告;計量管理軟件,用于電力計費和結算,并提供用戶友好的界面;報警和異常處理系統,監 測異常情況并發送通知;安全性和權限控制,確保 系統訪問的安全性和合法性;可擴展性和集成性, 允許系統與其他能源管理系統、建筑自動化系統等 集成。整個系統負責全面監測、測量和管理電力使 用情況,以提高能源效率并確保電費計量和結算的 準確性。
1.2 常見的數據異常檢測方法
1.2.1 基于模型的方法
基于模型的數據異常檢測方法是利用已知的數 據模型來識別數據中的異常值,這些模型可以是統 計模型、機器學習模型或其他數學模型。基于模型 的方法試圖捕捉數據中的整體結構和規律,然后使 用這些模型來評估數據點的異常程度。
一種常見的基于模型的方法是使用概率統計 模型,如高斯混合模型(gaussian mixture model, GMM)。在 GMM 中,假設數據由多個高斯分布組 成,其中大多數數據點屬于正常高斯分布,而異常 點則可能來自于異常的高斯分布或者屬于極端值。 通過擬合 GMM,可以計算每個數據點屬于正常高 斯分布的概率,然后根據概率值來判斷數據點是否 異常。
基于模型的方法通常需要一定數量的訓練數據 來建立模型,然后利用這些模型來評估新數據的異 常程度。其優勢在于能夠捕捉數據的復雜結構和模 式,且在處理復雜數據集時表現良好。然而,其缺 點是需要精心選擇和訓練合適的模型,并且可能對 數據的分布和特性有一定的假設要求。
1.2.2 基于近鄰度的方法
基于近鄰度的數據異常檢測方法是利用數據點 之間的相似度或距離來識別異常值。這種方法假設 正常數據點通常會在特征空間中聚集成簇,而異常 點則可能遠離這些簇或者與周圍的數據點相比具有 顯著不同的特征。
基于近鄰度的方法包括 K 最近鄰(k-nearest neighbors,KNN)、 局 部 離 群 因 子(local outlier factor,LOF)、 具 有 噪 聲 的 基 于 密 度 的 聚 類 (density-based spatial clustering of applications with noise,DBSCAN)等。這些方法通過分析數據點周 圍的密度或局部結構來評估數據點的異常程度,從 而有效地識別出異常點。
基于近鄰度的方法的優點:簡單直觀,易于理 解和實現;不需要假設數據的分布或特性,因此對 于不同類型的數據集都能夠適用;能夠靈活地調整 參數以適應不同的異常檢測任務。然而,基于近鄰 度的方法也存在一些限制。例如,對于高維數據或 大規模數據集的計算開銷較大,且對參數的選擇較 為敏感。因此,在應用這些方法時需要謹慎選擇合 適的參數,并根據具體情況進行優化。
1.2.3 基于密度的方法
基于密度的方法是一種常用的數據挖掘技術, 通過分析數據點在特征空間中的分布密度來發現數 據的模式和結構。在電力計量自動化系統中,基于 密度的方法可以應用于異常檢測、數據清洗、模式 識別等多個方面,以提高系統的可靠性和效率。
在異常檢測方面,基于密度的方法可以幫助識 別出數據中的異常點,這些異常點可能代表了系統 中的故障、惡意操作或其他異常情況。通過計算數 據點周圍的密度值,可以確定哪些數據點與周圍的 數據分布不一致,從而視其為異常。這種方法能夠 有效地發現不符合正常數據分布規律的異常情況, 有助于及時發現和處理電力計量系統中的問題。
2 基于KNN算法的計量自動化終端異常 檢測
2.1 異常檢測流程介紹
基于 KNN 算法的計量自動化終端異常檢測流 程涵蓋了多個關鍵步驟,如圖 1 所示。首先,通過 數據收集,獲取包括電流、電壓等參數的時間序列 數據,確保數據集包含正常和異常狀態。其次,對 數據進行異常值和標準化處理,以保證數據的質 量。通過特征選擇,選擇最具代表性的特征用于訓 練和測試 KNN 算法模型。數據集分為訓練集和測 試集,利用有標簽的訓練數據訓練 KNN 算法模型,并通過評估指標驗證模型性能。確定最優的 K 值 以提高模型的泛化能力。將訓練好的 KNN 算法模 型集成到實際系統中,實時監測終端數據,當檢測 到異常時可觸發報警機制。系統需要不斷優化和調 整,根據實際情況和反饋,以確保模型在不同條件 下的準確性和穩定性。
2.2 異常分析
KNN 算法是一種基于實例的學習方法,常用 于分類和回歸問題。其核心思想是基于特征空間 中的數據點之間的距離或相似度,從而判斷一個 新的數據點屬于哪一類別或者對應的數值(圖 1)。 KNN 算法基本步驟如下。
(1)準備好帶有標簽的訓練數據集,其中包括 特征值和相應的類別標簽。
(2)對于一個新的未標記數據點 x,計算該數 據點與訓練數據集中所有數據點的距離或相似度。 常用的距離度量包括歐氏距離 d(x,xi )或其他相 似度度量方法。假設訓練數據集包含 N 個樣本,其 中第 i 個樣本的特征向量表示為 xi 。
(3)選擇與新數據點距離最近的 K 個鄰居。通 常通過計算距離度量來確定最近鄰居。設 D(x) 為新數據點 x 與所有訓練數據點的距離集合,則選 擇 D(x)中距離最小的 K 個樣本。
(4)假設 C(xi )為第 i 個樣本的異常類別(正 常或異常),則新數據點 x 的類別 C(xi )計算公式 如下:
其中,1(·)為指示函數,如果括號內條件成立 則取值為 1,否則為 0。
(5)根據投票決策結果,將新數據點劃分為正 常或異常。對于回歸問題,可以使用 K 個最近鄰居 的異常度量的平均值或加權平均值來估計新數據點 的異常度。
(6)使用評價指標(準確率、召回率、F1 分 數)來評估模型的性能。
3 實驗結果與分析
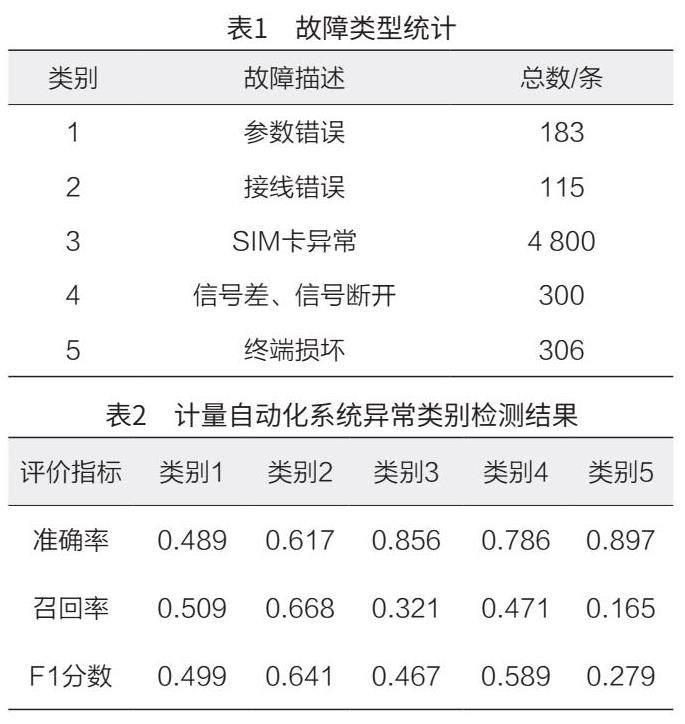
本文選取某地區 2020 年現場運行維護的信息 表作為數據進行分析,其中包含 5 704 條數據,這 些數據中包括終端編號、終端最后在線時間、計量 點最后數據時間和故障類型。故障類型統計如表 1 所示。
利用 KNN 算法計量自動化終端進行異常類型 檢測,利用準確率、召回率和 F1 分數對得到的結 果進行評估。由表 2 可知,類別 3、類別 4 和類 別 5 這 3 種故障能夠被有效識別。類別 1 和類別 2 識別效果較差,證明該算法可能在識別某些特定類 型的故障時存在困難或者漏洞。因此,需要進一步 分析低 F1 分數對應的具體故障類型,并考慮改進 算法或者調整模型參數以提高對這些故障類型的識 別能力。
4 結論
本文深入探討了電力計量自動化系統異常分析 的方法,對電力計量自動化系統的結構和常見檢測 方法進行了概述,重點探究了基于 KNN 算法的異 常檢測方法,并通過實驗驗證其性能。結果表明, 基于 KNN 算法的異常檢測方法在電力計量自動化 系統中表現出良好的效果,能夠有效地發現和定位 系統的異常情況,為系統運行維護提供了重要支 持。未來,將進一步探索 KNN 算法在電力系統異 常分析中的應用,以進一步完善異常檢測機制,保 障電力計量系統的正常運行。
參考文獻
[1] 劉璐,蘇逸塵 . 基于大數據的電力計量裝置故障智能化診 斷分析 [J]. 集成電路應用,2023,40(12):216-217.
[2] 康艷 . 電能計量自動化系統在電能計量裝置異常處理 中的應用 [J]. 光源與照明,2023(3):136-138.
[3] 余健,林炳鋒,趙矚華,等 . 一種基于聚類分析的電 力計量自動化檢定流水線故障診斷方法 [J]. 電子設計 工程,2020,28(8):76-79,84.
[4] 王永才,余永忠,翟鴻榮 . 電力計量自動化海量實 時數據管理平臺的設計與實現 [J]. 企業技術開發, 2013,32(14):117-118.
[5] 李景青 . 電力計量大數據對計量裝置運維的應用 [J]. 技術與市場,2017,24(9):103-104
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
