基于注意力機制語譜圖特征提取的語音識別
2024-05-15 19:23:13姜囡龐永恒高爽
吉林大學學報(理學版) 2024年2期
姜囡 龐永恒 高爽

摘要: 針對連接時序分類模型需具有輸出獨立性的假設, 對語言模型的依賴性強且訓練周期長的問題, 提出一種基于連接時序分類模型的語音識別方法. 首先, 基于傳統聲學模型的框架, 利用先驗知識訓練基于注意力機制的語譜圖特征提取網絡, 有效提高了語音特征的區分性和魯棒性; 其次, 將語譜圖特征提取網絡拼接在連接時序分類模型的前端, 并減少模型中循環神經網絡層數進行重新訓練. 測試分析結果表明, 該改進模型縮短了訓練時間, 有效提升了語音識別準確率.
關鍵詞: 語音識別; CTC模型; 循環神經網絡; 注意力機制
中圖分類號: TP391文獻標志碼: A文章編號: 1671-5489(2024)02-0320-11
Speech Recognition Based on Attention Mechanism and Spectrogram Feature Extraction
JIANG Nan1, PANG Yongheng1, GAO Shuang2
(1. School of Public Security Information Technology and Intelligence,Criminal Investigation Police University of China, Shenyang 110854, China;2. College of Information Science and Engineering, Northeastern University, Shenyang 110819, China)
Abstract: Aiming at the problem that the connected temporal classification model needed to have output independence assumption, and there was strong dependence on language model and long training period, we proposed? a speech recognition method based on connected temporal classification model. Firstly, based on the framework of traditional acoustic model, spectrogram feature extraction network based on attention mechanism was trained by using prior knowledge, which effectively improved the discrimination and robustness of speech features. Secondly, the spectrogram feature extraction network was spliced in the front of the connected temporal? classification model, and the number of layers of the recurrent neural network in the model was reduced for retraining. The test analysis results show that the improved model shortens the training time, and effectively improves the? accuracy of speech recognition.
Keywords: speech recognition; CTC model; recurrent neural network; attention mechanism
近年來, 在信息處理、 通信與電子系統、 自動控制等領域相繼出現了不同用途的語音識別系統, 低信噪比下語音識別已顯露強大的技術優勢和生命力, 但仍面臨諸多問題需要完善. 環境噪音和雜音對語音識別的效果影響不容忽視; 在多語言混合、 無限詞匯識別和自適應方面需要進一步改進, 以達到不受口音、 方言和特定人影響的要求[1-3].
傳統基于GMM-HMM(Gaussian mixture model-hidden Markov model)的語音識別框架得到廣泛使用和研究[4-5], 提出了語音識別聲學模型的區分性訓練準則, 有效提升了語音識別的準確率和識別速率. 基于聲學模型的區分性訓練(discriminative training, DT)準則和最大似然估計訓練GMM-HMM, 根據區分性準則對模型參數進行更新, 可以顯著提升模型的性能[6-8]. 文獻[9-10]將深層神經網絡用于語音的聲學建模, 在音素識別TIMIT(聲學-音素連續語音語料庫, The DARPA TIMIT acoustic-phonetic continuous speech corpus)任務上獲得成功, 但由于TIMIT是一個小詞匯量的數據庫, 連續語音識別任務更關注的是詞組和句子的正確率, 識別效果并不理想. 文獻[11]提出了在CD-DNN-HMM框架下利用混合帶寬訓練數據, 提高寬帶語音識別精度的策略, DNN(deep neural network)提供了使用任意特性的靈活性.
隨著基于GMM-HMM的語音識別框架被打破, 文獻[12]考慮卷積提供了一種改進的混響建模能力, 將CNN(convolutional neural network)與全連接的DNN相結合, 可以在參數小于DNN的特征向量中建立短時間相關性模型, 從而更好地泛化未發現的測試環境. 文獻[13]提出一種具有規則化自適應性的基于長短時記憶(long and short term memory, LSTM)循環神經網絡的聲學模型. 在混合模型中, DNN/CNN/RNN(recurrent neural network)與隱Markov模型(HMM)是分開優化的, 又由于語音識別中存在序列識別問題, 因此聯合優化模型中的所有組件會有效提升識別率, 因而端到端的處理方式被引入到語音識別系統中. 文獻[13]提出了一種基于Gammatone頻率倒譜系數(GFCC)的特征提取方法, 彌補了Mel頻率倒譜系數(MFCC)特征的局限性. 文獻[14-18]提出了混合式CTC(connected temporal classification)/注意端到端的語音識別技術, 這是一種用于語音識別、 文本識別等任務的深度學習模型, 它可以直接從時序數據中學習并預測出整段序列的標簽. CTC模型的基本架構是一個由多個循環神經網絡(RNN)單元組成的雙向網絡, 該網絡在輸入時序數據后, 可以輸出整段序列的標簽概率分布, 通過反向傳播算法進行訓練, 最終得到的模型可以對新的未知序列進行標簽預測, 有效利用了訓練和譯碼的優點, 采用多任務學習框架提高魯棒性, 可以實現快速收斂.
本文提出一種基于連接時序分類模型的語音識別方法. 充分利用先驗知識, 基于注意力機制訓練語譜圖特征提取網絡, 有效提升提取特征的區分性和魯棒性. 最終保證模型訓練時間有效降低, 提升語音識別準確率.
1 端到端模型的語音識別框架
1.1 語音識別系統流程
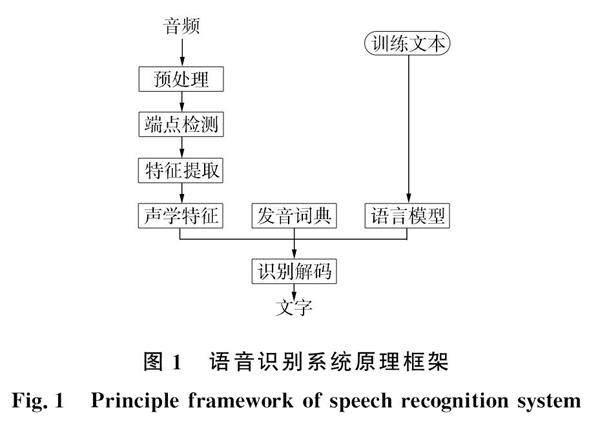
語音識別系統包括聲學特征提取、 語言和聲學模型、 發音詞典和解碼器5個模塊, 如圖1所示.
從語音信號中提取到的聲學特征經過統計訓練到聲學模型, 把該聲學模型作為識別單元的模板, 結合發音詞典和語言模型, 經過解碼器處理得到識別結果.
1.2 基于CTC的端到端語音識別框架
CTC的連續語音識別系統主要包括循環神經網絡和CTC函數計算層, 其中循環神經網絡包含4層LSTM單元, 如圖2所示, 其作用主要是提取輸入特征中的有效時序信息, 提升特征的區分性能和表達能力. CTC函數計算層則可以直接計算輸出序列后驗概率.
LSTM模型是RNN的一種變形. RNN存在梯度消失的問題, 即后面時間節點對前面時間節點的感知力下降, 網絡深度過大無法訓練. 圖3為循環神經網絡模型的結構. 由圖3可見, Xt是網絡在t時刻的輸入, 經過網絡結構處理得到ht, 它可以進行輸出, 也可以傳遞給下一時刻. yt+1為t+1時刻網絡得到的輸出結果, 包含了當前時刻和所有歷史時刻共同作用的結果, 以此可以對時間序列建模. 其中隱含層狀態計算公式為ht=f(Whxxt+Whhht-1);(1)輸出和隱含層狀態的關系為yt=g(Whyht),(2)其中f(·)是隱含層激活函數, g(·)是輸出層激活函數, Whx,Why和Whh是權重矩陣.
LSTM在RNN的基礎上, 增加了一個存儲單元、 一個輸入門、 一個輸出門和一個遺忘門, 如圖4所示.
在CTC算法中, 同一個實際音素序列可由基于幀的音素序列轉換, 多個基于幀的音素序列的后驗概率相加可得到實際音素序列的后驗概率. 通常CTC算法在進行計算前, 都要在識別音素集合中加入空白符“—”和序列映射函數Γ, 其中空白符不但代表連續語音中的靜音區間, 也可作為兩個音素之間的分隔符. 加入空白符后新的音素集合A={c1,c2,…,cm,—}元素數量為m+1, 因此需要把模型中Softmax層單元數調整至m+1. 序列映射函數Γ定義為: AT→A≤T, 即把基于幀的音素序列映射成長度較短的實際音素序列.
基于CTC和文本對齊的音頻示例如圖5所示. 由圖5可見, 分幀式方法需要做每個音素的標記, 而CTC只是預測一系列的峰值和緊接著一些可能的空白符用于區分字母, 分幀式的方法可能出現對齊錯誤, 因為相鄰兩幀的標簽概率分布圖太接近, 如在dh,ax有明顯的重疊, 而CTC卻沒有出現這種情況.
雖然基于CTC的端到端語音識別模型摒棄了傳統HMM框架, 輸出可以達到音素甚至更小的狀態, 但其仍存在一些不足:
1) CTC損失函數訓練時間較長, 優化空間相對復雜, 損失函數的數值敏感較易出現波動, 越接近優化目標, 優化空間變得越小, 易導致反優化;
2) 有輸出獨立性的假設, 對于語言模型的依賴性較強;
3) 循環神經網絡在時域上呈遞歸結構, 不能同時處理多幀數據.
2 基于注意力機制語譜圖特征提取模型
針對CTC的端到端語音識別模型的局限性, 研究者已提出在端到端模型的前端增加一個基于注意力機制的語譜圖特征提取模型. 基于語譜圖提取聲學特征相當于對原始語音非線性特征進行壓縮變換, 相比常規MFCC等特征維度更低, 同時對背景噪聲、 信道和說話人的魯棒性和區分度也更強. 利用端到端可以實現直接建模, 將特征提取模型拼接到識別模型的前端, 對融合后的識別模型進行聯合訓練, 并微調參數, 可有效提升識別準確率.
2.1 利用語譜圖提取發音特征
語音幀長通常是20~50 ms, 為準確獲取說話人音質、 音色的信息, 選擇單個完整音節作為語譜圖的最小單位, 時間為50~200 ms. 考慮通常自然發音的頻率范圍在100~3 000 Hz, 設置縱坐標的頻率標尺范圍. 下面用一段語音的語譜圖進行分析.
圖6為一個灰度窄帶語譜圖, 灰度值深淺漸變的像素值可精確反映不同時間點頻率分布的動態變化. 語音信號在低頻處分布較多, 高頻處分布較少, 且含有許多不同的花紋, 如橫杠、 豎直條和亂紋等, 其中橫杠與時間軸平行, 表示共振峰, 深色條紋呈周期性均勻分布, 從它對應的縱軸頻率和寬度可確定相應的共振峰頻率和帶寬. 共振峰的個數、 走向以及帶寬都是重要的特征參數. 為更清晰直觀地說明語譜圖特征參數的優越性. 將語音信號的各特征參數進行對比, 結果列于表1.
現在大多數語音識別系統都采用MFCC參數, 但它的抗噪性和穩定性較差, 因此本文采用在語譜圖上提取特征, 具有較強的穩定性和魯棒性, 能進一步提升語音識別的準確率.
2.2 注意力機制模型
注意力機制模擬人類視覺機制忽略無關特征, 將注意力分配在特征序列的部分相關區域, 從特征序列中提取有效特征. 在序列到序列模型中, 將特征序列(h1,h2,…,hT)映射成一個目標向量cto, 計算輸出序列的元素yo. 為便于后端模式分類,? 將序列中壓縮后的重要信息變換為固定長度向量, 再將cto作為注意力子網絡后的解碼網絡輸入, 依次計算出循環神經網絡隱含層狀態序列(s1,s2,…,sO)和輸出序列(y1,y2,…,yO). 注意力模型結構如圖7所示.
輸出序列位置o∈{1,2,…,O}所對應的目標向量為cto, 根據注意力機制其計算過程如下. 輸出序列位置o-1的隱含層狀態為so-1, 首先計算其與t時刻的特征關聯度:eo,t=a(so-1,ht),(3)其中a(·)為只含一個隱含層的多層感知機. 注意力子網絡表示為eo,t=ωTtanh(W[so-1,ht]+b),(4)其中W為輸入層到隱含層的權重矩陣, b為偏置向量, ω為隱含層到輸出層的權重矩陣.
將對所有時刻特征的關聯度進行指數歸一化后的數值作為注意力系數:αo,t=exp{eo,t}/∑T/t=1exp{eo,t},(5)其中αo,t為權重, 針對全部時刻的特征加權求和, 利用注意力機制, 得到輸出序列位置o對應的目標向量cto為cto=∑T/t=1αo,tht.(6)采用注意力機制計算目標向量的過程可記為cto=attention((h1,h2,…,hT),so-1).(7)
2.3 基于語譜圖特征提取模型的訓練
3 基于語譜圖特征提取模型的語音識別
3.1 匹配相似度定義
引入更靈活的方式比較兩個序列之間的相似度: 最長公共子串(longest common substring, LCS)和編輯距離匹配法(edit distance matching).
3.2 注意力機制端到端語音識別設計
在語譜圖利用注意力模型提取高維特征, 在基于CTC的端到端模型上進行語音識別. 步驟如下:
1) 樣本輸入. 基于自適應門限的分形維數算法對音頻進行語音端點檢測, 然后轉化成灰度語譜圖Xi(i=1,2,…,n), 作為系統的輸入.
2) 訓練基于注意力的模型. 首先引入不同的函數和計算機制, 根據輸入序列X和目標序列P, 計算兩者的相似性或者相關性, 點積為Similarity(X,P)=X·P,(10)余弦相似性為Similarity(X,P)=X·P/‖X‖·‖P‖,(11)MLP網絡為MLP(X,P).(12)引入Softmax的計算方式對第一步的得分進行值轉換, 采用如下公式計算:ai=Softmax(Simi)=eSimi/∑Lx/j=1eSimj.(13)計算特征Valuei對應的權重系數, 然后加權求和即可得到Attention數值:Attention(X,P)=∑LX/i=1ai·Valuei.(14)
3.3 注意力模型提取語譜圖特征
由于注意力輸出序列未知, 同時考慮注意力模型中解碼網絡位置輸出對計算結果的影響, 基于帶序列終止符的BeamSearch算法在注意力模型解碼網絡的輸出中, 將負概率最低的序列作為輸出. 按照序列的長度逐步枚舉解碼結果, 并將其存儲在一個容量為beam_size 序列集合中. 根據集合中元素, 在進行每次搜索時序列輸入和解碼網絡將序列長度拓展1位, 能同時得到多個候選結果和對應的得分. 從中可篩選出最好的beam_ size個序列保留在集合中, 根據此流程循環運行.
3.4 基于CTC端到端模型的訓練和識別
在注意力模型中從語譜圖上得到高維特征, 輸入到LSTM神經網絡, 繼續經過一層全連接神經網絡, 將最后一個維度映射作為所有可能的類標. 同時數據會進入 CTC模塊和計算損失函數, 經反向傳播神經網絡, 預測輸入數據所對應的序列.
綜上, 基于注意力機制的端到端語音識別算法的系統框圖如圖8所示.
4 實驗分析
4.1 實驗配置
在PyCharm軟件TensorFlow框架下進行語音識別實驗. 使用的語料庫是thchs-30語音庫, 該數據庫設計的目的是作為863數據庫的補充, 盡可能提高中文發音的涵蓋率.
thchs-30語音庫是使用單個碳粒麥克風在安靜的辦公室環境下錄制的, 總時長約30 h, 參與錄音的人員為會說流利普通話的大學生, 設置采樣頻率為16 kHz, 其文本選取自大容量的新聞和文章, 全部為女聲. 表2列出了該數據集包含的全部內容. 其中開發集的作用是調整參數、 選擇特征, 與訓練集進行交叉驗證. 訓練和測試的目標數據可分為詞和音素兩類. 表3列出了訓練thchs語料庫的一些基本信息.
在語音識別中, 常用的評價指標除有識別的準確率, 還有詞錯誤率(word error rate, WER).為保持識別的詞序列和目標序列的一致性, 需要進行替換、 刪除或插入等操作, 錯誤率用WER表示, 其計算公式為WER=S+D+I/N×100%,(15)其中S表示替換, D表示刪除, I表示插入, N為單詞數目.
語音識別結構如圖9所示, 分別提取MFCC特征, 用CNN和Attention在語譜圖上提取特征, 再分別輸入到HMM,RNN和LSTM+CTC模型中進行語音識別, 對比分析, 以驗證改進算法的有效性.
4.2 基于MFCC特征的語音識別模型分析
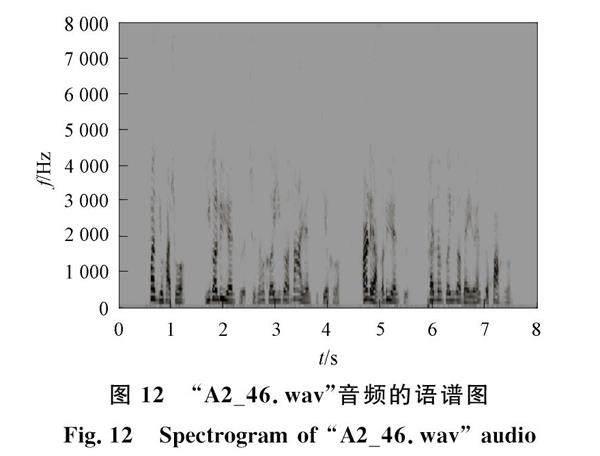
選取thchs語料庫中一段名為“A2_46.wav”的音頻文件, 該音頻內容為“換句話說, 一個氯原子只能和一個鈉原子結合, 而兩個氯原子才能和一個鎂原子化合.” 音頻時長為8 s, 提取的時域波形如圖10所示.
對音頻進行端點檢測, 由于音頻中含有多段短語音段, 用紅色豎線標記過于雜亂. 因此對檢測出的短語音段, 用紅色覆蓋, 靜音部分用灰色標記, 得到的語音波形如圖11所示.
提取特征維度為12維的語音MFCC特征, 并對其逐幀提取. 各語音的長度不同, 所得特征矩陣的大小也不同, 例如當一段語音的幀數為n, 則對應提取的特征是一個n×12的特征矩陣, 因此無法統一模型輸入的尺度. 因此, 計算全部幀的MFCC向量均值, 并將其作為整段語音的MFCC特征, 按列求取特征矩陣的平均值, 歸一化后可得到1×12的MFCC特征向量. 將MFCC特征分別輸入到DNN-HMM,RNN和LSTM+CTC三個模型中, 對比平均迭代周期和識別錯誤率, 以證明LSTM+CTC模型的優越性.
采用三音素的狀態作為DNN網絡的標簽信息. 整個網絡包括1個輸入層、 6個隱含層和1個輸出層. Tanh 函數作為隱含層的激活函數, 輸出層分類用Softmax函數, 以最小化交叉熵為目標函數, 權重學習率為0.001. 整個RNN網絡包括1層輸入層, 輸入層的節點數為300; 3個隱含層每層有2 048個節點; 一個輸出層, 對應36 016個節點. Sigmoid函數作為隱含層的激活函數, 輸出層分類用Softmax函數. 采用最小化交叉熵作為目標函數, 學習率初始值為0.001.
針對LSTM單元訓練神經網絡的隱含層, 設置狀態維度為300, LSTM堆疊的層數為4, 隱藏節點為40個, 1個全連接層. CTC為目標損失函數, 學習率為0.001.
表4列出了基于MFCC特征的語音識別模型對比結果. 由表4可見, LSTM+CTC語音識別模型在訓練時間和識別性能上都優于其他模型, 平均迭代周期降低到37 min, 識別的錯誤率僅為7.5%.
4.3 基于語譜圖特征的語音識別模型分析
繼續采用“A2_46.wav”音頻, 轉化成語譜圖如圖12所示. 圖12為灰度窄帶語譜圖, 通過灰度值漸變的像素值可精確反應不同時間點頻率分布的動態變化情況. 圖13為灰度統計直方圖的實例及原圖. 由圖13可得到各種像素所占的比例, 同時可對應語譜圖中的頻率信息. 因為語音信號頻率本身具有高頻部分不明顯、 低頻處明顯的特征, 并且圖中顯示低頻部分顏色較深, 且顏色的覆蓋率也相對較大, 這與人類的發音特點一致.
將語譜圖分別輸入到CNN網絡和注意力模型中, 再拼接在LSTM+CTC模型中, 對比并證明注意力機制的優越性. 針對CNN網絡中的每個卷積層, 采用3×3的小卷積核, 并在多個卷積層后加上池化層, 增強了CNN的表達能力. 但它與注意力網絡相比, 不能很好地表達語音的長時相關性, 魯棒性也較差. 圖14為兩種網絡模型識別錯誤率的對比. 由圖14可見, 用CNN在語譜圖上提取特征得到識別錯誤率平均約為4.9%, 而基于注意力模型得到的識別錯誤率約維持在4.0%, 識別效果得到了有效提升.
4.4 實驗結果對比分析
針對下面選取的9段中文音頻文件分別進行識別分析驗證. 進行端點檢測后, 基于注意力機制的語音識別模型的識別結果列于表5. 由表5可見, 只有第4段和第7段語音識別結果出現明顯的局部錯誤. 基于注意力機制的端到端的語音識別模型識別的錯誤率可降低到約5%. 表6統計了不同特征在不同模型下語音識別的詞錯誤率.
由表6可見: 從特征的角度, 用注意力機制提取語譜圖得到的錯誤率要低于MFCC特征和利用CNN提取語譜圖特征的錯誤率; 從模型的角度, LSTM+CTC語音識別模型明顯要優于DNN-HMM和RNN模型. 因此, 基于注意力機制的LSTM+CTC模型能有效降低識別錯誤率, 縮短了訓練時間.
綜上所述, 本文以thchs語料庫為樣本集, 提取了MFCC特征, 用CNN和Attention在語譜圖上提取特征, 通過輸入到HMM,RNN和LSTM+CTC模型的識別分析對比, 基于注意力機制的LSTM+CTC模型能同時彌補其他兩種模型的缺陷, 縮短了訓練周期, 并有效提高了語音識別的準確率.
參考文獻
[1]王建榮, 張句, 路文煥. 機器人自身噪聲環境下的自動語音識別 [J]. 清華大學學報(自然科學版), 2017, 57(2): 153-157. (WANG J R, ZHANG J, LU W H. Automatic Speech Recognition with Robot Noise [J]. Journal of Tsinghua University (Science and Technology), 2017, 57(2): 153-157.)
[2]姚慶安, 張鑫, 劉力鳴, 等. 融合注意力機制和多尺度特征的圖像語義分割 [J]. 吉林大學學報(理學版), 2022, 60(6): 1383-1390. (YAO Q A, ZHANG X, LIU L M, et al. Image Semantic Segmentation Based on Fusing Attention Mechanism and Multi-scale Features [J]. Journal of Jilin University (Science Edition), 2022, 60(6): 1383-1390.)
[3]茍鵬程, 宗群. 車載語音識別及控制系統的設計與實現 [J]. 計算機應用與軟件, 2017, 34(5): 129-134. (GOU P C, ZONG Q. Design and Realization of Vehicle Speech Recognition and Control System [J]. Computer Applications and Software, 2017, 34(5): 129-134.)
[4]HAN L H, WANG B, DUAN S F. Development of Voice Activity Detection Technology [J]. Application Research of Computers, 2010, 27(4): 1220-1226.
[5]金超, 龔鋮, 李輝. 語音識別中神經網絡聲學模型的說話人自適應研究 [J]. 計算機應用與軟件, 2018, 35(2): 200-205. (JIN C, GONG C, LI H. Speaker Adaptation Research of Neural Network a Coustic Model in Speech Recognition [J]. Computer Applications and Software, 2018, 35(2): 200-205.)
[6]陶勇, 朱媛. 基于深度神經網絡聲學模型及其改進的語音識別研究 [J]. 吉林大學學報(理學版), 2021, 59(4): 539-546. (TAO Y, ZHU Y. Research on Speech Recognition Based on Deep Neural Network Acoustic Model and Its Improvement [J]. Journal of Jilin University (Science Edition), 2021, 59(4): 539-546.)
[7]CAO D Y, GAO X, GAO L. An Improved Endpoint Detection Algorithm Based on MFCC Cosine Value [J]. Wireless Personal Communications, 2017, 95(3): 2073-2090.
[8]KHELIFA O M, ELHADJ Y M, YAHYA M. Constructing Accurate and Robust HMM/GMM Models for an Arabic Speech Recognition System [J]. International Journal of Speech Technology, 2017, 20: 937-949.
[9]陳愛月, 徐波, 申子健. 基于高斯混合模型及TIMIT語音庫的說話人身份識別 [J]. 信息通信, 2017, 7: 51-52.(CHEN A Y, XU B, SHEN Z J. Speaker Recognition Based on Gaussian Mixture Model and TIMIT Speech Database [J]. Information and Communication, 2017, 7: 51-52.)
[10]LANJEWAR R B, MATHURKAR S, PATEL N. Implementation and Comparison of Speech Emotion Recognition System Using Gaussian Mixture Model (GMM) and K-Nearest Neighbor (KNN) Techniques [J]. Procedia Computer Science, 2015, 49(1): 50-57.
[11]CUI X D, JING H, CHIEN J T. Multi-view and Multi-objective Semi-supervised Learning for HMM-Based Automatic Speech Recognition [J]. IEEE Transactions on Audio Speech & Language Processing, 2012, 20(7): 1923-1935.
[12]MAAS A L, QI P, XIE Z, et al. Building DNN Acoustic Models for Large Vocabulary Speech Recognition [J]. Computer Speech & Language, 2017, 41(7): 195-213.
[13]邵玉斌, 陳亮, 龍華, 等. 基于改進GFCC特征參數的廣播音頻語種識別 [J]. 吉林大學學報(理學版), 2022, 60(2): 417-424. (SHAO Y B, CHEN L, LONG H, et al. Broadcast Audio Language Identification Based on Improved GFCC Feature Parameters [J]. Journal of Jilin University (Science Edition), 2022, 60(2): 417-424.)
[14]HINTON G, DENG L, DONG Y, et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups [J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[15]YI J Y, WEN Z Q, TAO J H, et al. CTC Regularized Model Adaptation for Improving LSTM RNN Based Multi-accent Mandarin Speech Recognition [J]. Journal of Signal Processing Systems, 2017, 90(2): 1-13.
[16]WATANABE S, HORI T, KIM S, et al. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition [J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1240-1253.
[17]張宇, 張鵬遠, 顏永紅. 基于注意力LSTM和多任務學習的遠場語音識別 [J]. 清華大學學報(自然科學版), 2018, 58(3): 249-253. (ZHANG Y, ZHANG P Y, YAN Y H. Long Short-Term Memory with Attention and Multitask Learning for Distant Speech Recognition [J]. Journal of Tsinghua University (Science and Technology), 2018, 58(3): 249-253.)
[18]龍星延, 屈丹, 張文林. 結合瓶頸特征的注意力聲學模型 [J]. 計算機科學, 2019, 46(1): 260-264. (LONG X Y, QU D, ZHANG W L. Attention-Based Acoustic Model with Bottleneck Features [J]. Journal of Computer Science, 2019, 46(1): 260-264.)
(責任編輯: 韓 嘯)
收稿日期: 2023-03-08.
第一作者簡介: 姜 囡(1979—), 女, 漢族, 博士, 教授, 從事智能識別的研究, E-mail: zgxj_jiangnan@126.com.
基金項目: 教育部重點研究項目(批準號: E-AQGABQ20202710)、 遼寧省自然科學基金(批準號: 2019-ZD-0168)、 遼寧省科技廳聯合開放基金機器人學國家重點實驗室開放基金(批準號: 2020-KF-12-11)、 中國刑事警察學院重大計劃培育項目(批準號: 3242019010)、 公安學科基礎理論研究創新計劃項目(批準號: 2022XKGJ0110)和證據科學教育部重點實驗室(中國政法大學)開放基金(批準號: 2021KFKT09).
