
Apache Flink流式計算模型在數據處理中的應用與性能優化研究
2024-05-19 14:36:42徐海霞
電腦知識與技術 2024年7期
徐海霞

摘要:文章旨在研究Apache Flink流式計算模型在數據處理中的應用與性能優化。先從可擴展性、容錯性和數據并行處理能力三個方面對Apache Flink流式計算框架技術特點進行論述,再對Apache Flink流式計算框架核心思想與工作流程進行研究,并提出一套執行數據處理任務的Java源碼,再從并行計算、數據存儲和傳輸、算法參數、系統配置、資源管理與調度、檢查點和容錯機制、編碼和序列化等方面就如何進行Apache Flink性能優化進行分析,最后通過實驗手段就優化性能進行分析。實驗結果表明,優化后的平均響應時間顯著減少,吞吐量相應增加,調整并行度和內存分配等參數可顯著提升系統性能,但還需要考慮任務調度和資源分配等方面的綜合因素,因此,Apache Flink流式計算框架調優策略具有一定的應用價值。
關鍵詞:流式計算;Apache Flink;大規模數據處理;性能優化;并行計算
中圖分類號:TP311? ? ? 文獻標識碼:A
文章編號:1009-3044(2024)07-0071-03
開放科學(資源服務)標識碼(OSID)
隨著互聯網、物聯網、社交媒體等信息源的不斷增加,組織和分析海量數據已經變得日益復雜,大規模數據處理已經為信息領域帶來新的挑戰。大數據涵蓋了各種類型,包括結構化數據(如數據庫中的表格數據)、半結構化數據(如XML、JSON格式的文檔)以及非結構化數據(如文本、圖像和視頻),處理這些數據需要高效的算法和系統來提取有價值的信息和支持決策,傳統的單機處理和集中式計算模型已經顯得力不從心,數據量的急劇增加導致了存儲、計算和通信等方面存在瓶頸,數據處理時間大幅度延長,因此,尋找更加高效、可擴展的數據處理方法成為當務之急。Apache Flink作為流式計算框架,適用于大規模數據的處理和分析,在實時處理、高吞吐量、容錯性、靈活的窗口操作以及豐富的API支持等方面具有眾多優勢,使得Flink成為處理復雜數據的理想選擇。
1 Apache Flink流式計算框架技術特點
1.1 可擴展性
Apache Flink采用基于流的計算模型,具備出色的可擴展性,允許用戶在處理無邊界數據流時輕松地擴展計算能力。Flink可以通過簡單地增加計算節點的數量來水平擴展,每個節點都可以獨立地處理數據流,而無需對整個系統進行大規模改動,動態的資源管理機制,可以根據工作負載的變化自動調整計算資源的分配,確保系統在不同規模的數據處理任務中都能高效運行。
1.2 容錯性
容錯性是大規模數據處理框架中不可或缺的技術特點,尤其是在長時間運行的流處理任務中。Flink通過定期生成任務的檢查點(checkpoint) 來記錄任務的狀態,在發生故障時系統可以使用最近的檢查點來恢復任務的狀態,從而避免數據丟失和任務重新計算。提供Exactly-Once語義,確保每個事件都被處理一次且僅一次,即使在發生故障時,系統也能夠保持數據處理的準確性和一致性。
1.3 數據并行處理能力
用戶可以根據實際需求配置Flink的容錯性級別,平衡容錯開銷和系統性能。Flink通過數據并行處理的方式實現高效的大規模數據處理,將流處理任務劃分為多個子任務,每個子任務在一個獨立的并行線程上執行,這種任務并行度的設計允許系統在多個計算節點上同時處理數據,提高整體計算能力。支持事件時間處理,允許在有序和無序事件流中處理數據,有助于保持數據處理的準確性,并支持窗口操作,例如時間窗口和會話窗口。采用流水線執行模型,使數據在各個算子之間流動,減少了數據在節點之間的傳輸和復制開銷,提高了數據處理的效率[1]。
通過這些技術特點,Apache Flink在大規模數據處理場景中表現出色,為用戶提供了高效、可擴展且容錯性強的流式計算解決方案。
2 Apache Flink流式計算框架核心思想與工作流程
Apache Flink流式計算框架作為新型分布算法,將大規模數據處理任務劃分為一系列小的、連續的數據流操作,每個操作形成一個計算階段,可以在集群的不同節點上并行執行。數據以流的形式在不同計算階段之間傳遞,避免了顯式的數據共享和同步,提高了整個系統的效率,同時,Flink使用異步、非阻塞的消息傳遞模型,通過輕量級的異步通信實現節點之間的協調。數據以流的形式加載并實時地從各種數據源獲取,預處理包括數據清洗、轉換等操作,可以更好地確保數據質量和格式的一致性,任務調度器根據數據流圖和集群狀態動態地調度任務,并通過任務管理器將任務分配給空閑的計算節點以實現負載均衡,在每個計算節點上,Flink并行執行不同的數據流操作,充分利用集群的計算資源,實現高效的大規模數據處理,計算完成后,Flink通過流式的方式將結果輸出,支持多種輸出目標,例如文件、數據庫或其他流處理應用[2]。
3 DataStream API執行數據處理任務
Apache Flink作為一個分布式流處理框架,在Flink中定義的計算邏輯通常采用高級API,如DataStream API或Table API,采用Java執行數據處理任務源碼為:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkExample {
public static void main(String[] args) throws Exception {
// 創建流處理環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 從數據源讀取數據流
DataStream
// 轉換和處理數據
DataStream
.map(new Tokenizer())
.keyBy(0)? // 按第一個元素(用戶ID) 分組
.sum(1);? ?// 計算第二個元素(數據值)的總和
// 輸出結果
sumStream.print();
// 執行任務
env.execute("Flink Example");
}
// 定義一個簡單的MapFunction用于數據轉換
public static final class Tokenizer implements MapFunction
@Override
public Tuple2
// 假設數據格式為 "UserID,Value"
String[] tokens = value.split(",");
return new Tuple2<>(tokens[0], Integer.parseInt(tokens[1]));
}
}
}
Flink流處理任務定義了一個MapFunction來解析和轉換輸入數據。在實際應用中,任務的復雜性和算法的具體形式將取決于需要解決的問題,而Flink提供了豐富的操作符和API,可以有效應對各種復雜的分布式數據處理算法[3]。
4 Apache Flink性能優化
4.1 并行計算優化
Apache Flink的流處理模型允許用戶在運行時動態調整任務的并行度,通過合理調整并行度充分利用集群資源,提高任務的處理速度。將多個操作符組成操作鏈,減少數據在不同算子之間的序列化和反序列化開銷,提高計算效率。對于涉及外部存儲或服務的異步IO操作,可以采用異步的方式進行避免計算節點的等待時間,提高并行計算效率。
4.2 數據存儲和傳輸優化
使用本地存儲減少數據在節點之間的傳輸開銷,特別是窄依賴的操作,在同一節點上執行,減少網絡通信。使用高效的數據壓縮算法,減小數據在網絡傳輸和存儲過程中的體積,降低傳輸開銷。選擇Flink默認支持的Kryo以減小數據序列化和反序列化的開銷,調整網絡緩沖區大小,使其適應集群規模和網絡延遲,以提高數據傳輸效率。
4.3 算法參數調優
窗口操作合理選擇窗口大小和滑動間隔參數,平衡數據處理的準確性和性能,迭代算法優化迭代次數、收斂條件等參數,以加速算法的收斂過程。調整任務管理器和任務執行器的內存分配,確保系統在大規模數據處理任務中充分利用資源。
4.4 系統配置調優
采用動態的檢查點觸發機制,根據系統負載和任務性質動態調整檢查點的生成頻率,高負載時可以降低觸發頻率,降低性能開銷,而低負載時可以增加觸發頻率,提高系統容錯性,對不同的任務設置不同的檢查點觸發策略,確保不同任務的容錯機制更加靈活。
4.5 資源管理與調度
Flink支持動態資源分配,可以根據任務的實時需求調整計算資源的分配情況,避免資源浪費,確保任務在不同計算節點上的負載均衡,避免出現某些節點過載而其他節點閑置的情況。
4.6 檢查點和容錯機制優化
調整檢查點的觸發頻率,確保在保證數據一致性的前提下,不會過于頻繁地生成檢查點,以減小性能開銷,采用高效的存儲系統來保存檢查點,以提高檢查點的存取速度。對檢查點進行壓縮和歸檔,減小存儲空間占用,提高數據的讀寫效率,使用壓縮算法和有效的存儲結構,以降低整體系統負擔[4]。
4.7 編碼和序列化優化
采用性能較好的序列化框架,如Avro、Protocol Buffers等,以減小數據序列化和反序列化的開銷,盡可能采用自定義的數據結構,以減小數據在內存中的存儲和傳輸開銷。采用自定義的數據結構,避免使用過于復雜的數據類型,精簡的數據結構能夠減小數據在內存中的存儲開銷,提高序列化和反序列化的效率。使用緊湊的數據表示形式,如使用整數代替字符串標識符,以降低數據傳輸時的帶寬占用[5]。
5 實驗效果分析
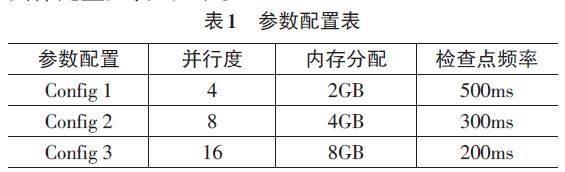
為深入了解Apache Flink在不同參數配置下的性能表現,采用平均響應時間(Response Time) 和吞吐量(Throughput) 來評估系統的實時性和處理能力,選擇了三種不同的參數配置,分別代表不同的調優策略。具體配置如表1如示。
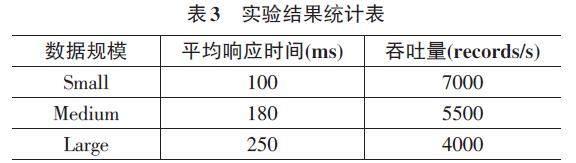
為了評估系統在處理不同規模數據集時的性能,使用不同大小的數據集進行測試。保持相同的性能指標,即平均響應時間和吞吐量,以確保實驗結果的可比性,選擇三個不同規模的數據集,分別是小規模(Small) 、中規模(Medium) 、大規模(Large) ,執行每個數據集規模下的實驗,使用相同的參數配置,監測系統的性能表現,并記錄實驗結果如表3所示。
6 實驗效果評價
通過比較Config 1和Config 2的實驗結果,在Config 2中平均響應時間顯著減少,吞吐量相應增加,表明增加并行度和調整內存分配等參數可以顯著提升系統性能。比較Config 2和Config 3可以發現,雖然在Config 3中增加了并行度,但注意到平均響應時間卻有所增加,在某些情況下增加并行度并不總是線性地提高性能,還需要考慮任務調度和資源分配等方面的綜合因素。從不同規模數據集的實驗結果來看,隨著數據規模的增加,平均響應時間呈上升趨勢而吞吐量逐漸下降。表明系統在處理大規模數據時可能會面臨一些性能瓶頸,需要更多的優化策略來應對。
7 結束語
綜上所述,通過深入剖析Apache Flink流式計算框架在大規模數據處理中的性能與優化,可以發現調整任務的并行度和選擇合適的窗口大小、滑動間隔等參數,直接關系到系統的實時性和吞吐量, Config 2的優異表現提示了適度的并行度和內存分配的重要性。此外,不同規模數據集下的實驗表明系統在面對大規模數據時的挑戰時,采用動態調整策略可為系統提供更靈活的應對手段,但性能波動的原因仍需進一步研究,總體而言,Apache Flink流式計算框架可提供更深層次的性能分析和更智能的調優策略。
參考文獻:
[1] 王肇康.分布式圖處理若干算法與統一圖處理編程框架研究[D].南京:南京大學,2021.
[2] 朱光輝.分布式與自動化大數據智能分析算法與編程計算平臺[D].南京:南京大學,2020.
[3] 母亞雙.分布式決策樹算法在分類問題中的研究與實現[D].大連:大連理工大學,2018.
[4] 司魯.數據規約中分布式實例選取關鍵技術研究[D].長沙:國防科學技術大學,2017.
[5] 劉健.Hadoop平臺下的分布式聚類算法研究與實現[D].沈陽:東北大學,2013.
【通聯編輯:張薇】
