大規模差異化點云數據下的聯邦語義分割算法
2024-05-24 01:45:55林佳斌張劍鋒邵東恒郭杰龍楊靜魏憲
計算機應用研究 2024年3期
林佳斌 張劍鋒 邵東恒 郭杰龍 楊靜 魏憲

摘 要:海量點云數據的存儲對自動駕駛實時3D協同感知具有重要意義,然而出于數據安全保密性的要求,部分數據擁有者不愿共享其私人的點云數據,限制了模型訓練準確性的提升。聯邦學習是一種注重數據隱私安全的計算范式,提出了一種基于聯邦學習的方法來解決車輛協同感知場景下的大規模點云語義分割問題。融合具有點間角度信息的位置編碼方式并對鄰近點進行幾何衍射處理以增強模型的特征提取能力,最后根據本地模型的生成質量動態調整全局模型的聚合權重,提高數據局部幾何結構的保持能力。在SemanticKITTI,SemanticPOSS和Toronto3D三個數據集上進行了實驗,結果表明該算法顯著優于單一訓練數據和基于FedAvg的方法,在充分挖掘點云數據價值的同時兼顧各方數據的隱私敏感性。
關鍵詞:聯邦學習;點云語義分割;雙層幾何衍射;動態權重
中圖分類號:TP391.41?? 文獻標志碼:A
文章編號:1001-3695(2024)03-010-0706-07
doi:10.19734/j.issn.1001-3695.2023.07.0320
Federated semantic segmentation algorithm under
large scale differential point cloud data
Lin Jiabin1,2,Zhang Jianfeng2,Shao Dongheng2,Guo Jielong2,Yang Jing3,Wei Xian2
(1.College of Mechanical & Electrical Engineering,Fujian Agriculture & Forestry University,Fuzhou 350100,China;2.Fujian Institute of Research on the Structure of Matter,Chinese Academy of Sciences,Fuzhou 350002,China;3.Longhe Intelligent Equipment Manufacturing Co.,Ltd.,Longyan Fujian 364101,China)
Abstract:The storage of massive point cloud data has great significance to the real-time 3D collaborative perception of autonomous driving.However,due to the requirements of data security and confidentiality,some data owners are unwilling to share their private point cloud data,which limits the improvement of model training accuracy.Federated learning is a computing paradigm that focuses on data privacy and security.This paper proposed a novel approach based on federated learning to address the challenge of large-scale point cloud semantic segmentation in collaborative vehicle perception scenarios.It integrated position encoding with inter-point angle information and geometric diffraction of neighboring points to enhance the feature extraction capability of the model.Finally,it dynamically adjusted the aggregation weights of the global model according to the generation quality of the local model to improve the ability to maintain the local geometric structure of the data.This paper applied the proposed method on three datasets,such as SemanticKITTI,SemanticPOSS and Toronto3D.The results show that the proposed approach significantly outperforms the single training data and the FedAvg-based method,and fully exploits the value of the point cloud data while taking into account the privacy sensitivity of each partys data.
Key words:federated learning;point cloud semantic segmentation;double-layer geometric diffraction;dynamic weighting
0 引言
隨著激光雷達等高精度傳感器的廣泛普及和應用,促使許多對3D數據有著實際需求的領域,如自動駕駛、機器人、虛擬與增強現實等,得到快速發展[1]。與2D圖像不同的是,3D數據可以更好地理解機器周邊環境,更加適用于實際的三維空間場景。點云作為一種常見的三維模型數據,具有非常強的空間表達能力,可以很好地保留原始三維空間的幾何結構,而且能夠很好地刻畫每個類別物體的表面特征以及其他可供深度模型訓練的信息,比如坐標、顏色、反射強度等,因此,它是許多場景理解相關應用的首選表示,但是點云的空間分布不均及數據雜亂無序等特點給點云數據處理和應用帶來了極大的挑戰[2]。當前關于點云感知任務中分割問題的研究往往只專注于在一個完整的集中式數據集上進行模型性能研究,此類方法在真實世界3D應用場景下存在著擴展性差、魯棒性低等問題。
例如,在自動駕駛領域的多個數據持有方中,由于存在部分群體不愿與他人共享其隱私數據,同時受限于單方數據采集的成本和訓練算力要求等問題,形成“數據孤島”,使得數據的潛在價值不能被充分利用。為此,本文將聯邦學習計算范式遷移至此處理該問題,在保證用戶數據隱私的前提下,合法合規地利用私域數據進行訓練。聯邦學習的初衷就是保證“數據不動模型動”,在很大程度上可以促進數據的所有方充分利用分散的數據訓練出令各方都滿意的機器學習模型[3]。由于分散式的用戶數據不能夠充分提取點的特征信息,為進一步優化特征編碼,對輸入點的特征提取采取幾何衍射[4]等處理,并基于每輪學習到的特征質量確定最終模型聚合權重。相較于直接采用聯邦平均算法[5]構建模型,本文方法能更顯著地提升整體性能效果和穩健性。
本文的主要貢獻包括:a)將聯邦學習方法引入到車輛協同感知場景下的大規模點云語義分割任務中,憑借其安全可信的訓練方式,每個數據持有方僅通過私有本地數據生成全局共享知識,從而獲取更好的模型性能;b)針對更小范圍內隨機采樣導致的點信息丟失問題,通過優化相對位置編碼方式,引入雙層幾何衍射[4],將每個采樣中心點的鄰近點作正態分布映射,細化每個鄰域內的特征分布,提升局部特征提取能力;c)對室外真實采樣的點云分割數據集SemanticKITTI[6]、SemanticPOSS[7]和Toronto-3D[8]進行聯邦切片處理,給每個參與方劃分不同場景的數據以實現數據隔離,針對本地數據不平衡帶來的性能下降問題,在經過相應優化方法后準確度得到有效提升。
1 相關工作
1.1 點云分割
點云語義分割是對海量點數據逐點進行語義分類的一種識別任務。相比于傳統方法,深度學習方法能夠更好地處理不規則的3D點云數據,通過端到端的方式訓練直接從原始點云數據中學習特征表示和語義信息,避免了手工設計特征的復雜過程,克服了傳統方法在特征提取和噪聲干擾處理方面的局限性,提高了分割效果并減少了計算時間[9]。現階段基于深度學習的點云分割相關研究大致可以歸納為以下幾種:
a)基于投影的分割方法。例如:Lawin等人[10]使用的多視圖表示辦法,將點云投影到不同的二維平面上,并利用多流的全卷積網絡(FCN)融合不同視角的投影分數來預測每個點的最終語義標簽;Wu等人[11]提出了一種基于SqueezeNet[12]和條件隨機場(CRF)的端到端網絡,將3D點云映射到球面上的二維平面(通常是前視圖),以保留更多的點云細節。但采用投影的方法會受到遮擋物的影響,因此依舊會造成分割精度的下降。
b)基于體素的方法實質上就是將點云結構化為密集網格的過程。Huang等人[13]利用3D卷積進行體素分割,為體素內所有點指定與體素相同的語義標簽。此后,Tchapmi等人[14]創新性地提出了SEGCloud模型,可以實現端到端的細粒度和全局一致性的語義分割。盡管體素化方式可以盡可能地保留點云的域結構,但是不可避免地引入了離散化偽影和信息損失,因此,需要在保留細節和壓縮運算成本之間進行權衡。
c)基于點的網絡模型是較為直接和普遍的方式,可以將點云直接輸入到網絡中進行特征提取。然而由于點云的特性是無序、不規則以及非結構化的,所以直接進行卷積操作是不可取的。早期的開創性工作有PointNet[15],提出使用共享MLP層學習逐點特征,并使用對稱池化函數學習全局特征;為了捕獲來自局部的幾何結構,PointNet++[16]通過分層的方式分組聚合鄰近點的信息,從而學習更精細的局部特征。為了對不同點之間的相互作用進行建模,Zhao等人[17]提出了PointWeb,通過密集構建局部完全相連接的網絡來探索局部區域中所有點對之間的關系,并采取自適應特征調整(AFA)模塊實現信息交換和特征細化。除了PointNet系列,還有一些先進的基于點的網絡模型采用了注意力機制。例如,Chen等人[18]提出了局部空間感知(LSA)層,根據點云的空間布局和局部結構學習空間感知權重。類似于條件隨機場(CRF),Zhao等人[19]提出了基于注意力的分數細化(ASR)模塊,通過結合相鄰點的分數和學習到的注意力權重來改進初始分割結果。
此外,Engelmann等人[20] 也將遞歸神經網絡(RNN)用于捕獲點云的固有上下文特征,提出了一種多尺度塊和網格塊的轉換方法,并通過合并單元(CU)或遞歸合并單元(RCU)逐層獲得輸出級上下文。也有工作試圖探討圖結構下的點云分割模型,如Ma等人[21]提出的即插即用的點全局上下文推理(PointGCR)模塊,使用無向圖表示沿信道維度捕獲全局上下文信息,可以輕松集成到現有的分割網絡中以提高性能。本文采用
一種高效、輕量級的深度網絡RandLA-Net[22,23],作為室外大規模點云分割基準,進一步探索了在聯邦場景下的模型性能,通過多種優化手段提升在差異化數據分布的邊緣客戶端下的系統整體魯棒性。
1.2 聯邦學習
人工智能技術的快速發展依賴于深度學習模型的精心設計,而深度學習的大獲成功又離不開大量可用、易用數據的互連互通,在全球范圍內形成的隱私保護體系大環境下,防范數據泄露和維護數據安全成為了廣泛的共識。無論是跨機構還是跨設備的用戶群體都傾向于打破數據壁壘,通過多方協作完成數據的合法調控,減小隱私風險和額外成本。聯邦學習作為人工智能領域新興的分布式機器學習范式,天然地適用于緩解“數據孤島”和“數據隱私”問題,在數據信息高度敏感的金融、醫療健康和邊緣物聯網等領域都有著廣泛的應用。聯邦學習通常可依照數據樣本和數據特征的重疊程度劃分為橫向聯邦學習、縱向聯邦學習和聯邦遷移學習[24]。從狹義上來闡述聯邦學習:假設進行聯邦訓練后的模型MF的性能為VF,將其與傳統集中式機器學習的模型MS的性能VS進行比較,那么滿足以下條件,即存在一個非負實數δ,使得兩者的性能損失差距為|VS-VF|<δ ,通常情況下的期望是將數據進行表層安全的聯邦訓練后所取得的最終效果近似于將數據集中到一起后訓練的模型性能。
2 聯邦點云語義分割模型
在面對大規模點云數據時,進行精準高效的語義分割是一項極具挑戰性的環境感知任務。RandLA-Net[23]是一種輕量化的語義分割網絡,其整體架構也是采取語義分割網絡中常見的編碼器和解碼器結構,不同于采集少量的室內點云數據(如1 024個點)進行簡單的分類分割任務。本文對輸入高達50K的點云數據進行處理,先逐層下采樣提取,通過四個編碼層將數量壓縮至1/256,每個編碼層將點云數量減少至原始的1/4,同時通過擴充特征維度保留更多的信息;解碼部分選擇高效的最近鄰差值法放大點的尺度,逐層上采樣至原始樣本點數,然后通過跳躍連接將網絡編碼器階段提取到的底層特征與解碼時的高層特征進行融合;最后利用三個全連接層將維度映射到輸出類別數。通過大量的前期調研工作后發現,隨機采樣方法對于大場景下點云分割具備更高的計算效率,相較于最遠點采樣[16],基于生成器的采樣[25]、強化學習下的策略梯度采樣[26]等方法,采樣速度提升百倍且時間復雜度更低,計算資源和內存開銷更小,整體效率更高,更加適用于大場景下的點云分割任務。針對隨機采樣后可能造成點丟失的情況,進一步提出局部特征聚合模塊,通過擴大每個采樣點的感受野,更大范圍地聚攏局部特征。本文提出局部增強的編碼方式并引入雙層幾何衍射模塊,進一步保留了特征細節。
通過聯邦學習進行點云語義分割,如圖1所示,其中LFEA為局部特征增強聚合模塊,DWN為融合模型時第N個本地模型的權值。首先在基準數據上為每個待選擇的客戶端分配一定數量的點云數據(由車載激光雷達等高精度傳感器事先采集而來),每個數據間不存在重疊可共享的部分,且不同端分得的數據在數量上存在顯著差異。采取具有中央服務器的橫向聯邦客戶-服務器架構,中心方負責初始化模型參數并下發給數據持有者,每個本地客戶僅利用自己私人的點云數據(隨機采樣數據)進行訓練,訓練方式等同于常規機器學習模型的訓練流程進行邊緣端的梯度下降,并逐步更新局部模型參數(期間數據僅作用在每個本地端),達到指定局部迭代次數后上傳參數,再由中央服務器采取參數聚合算法融合多個模型,重復聯邦訓練后達到最大迭代次數,獲取最優模型。
2.1 雙層幾何衍射模塊
在局部編碼器進行點云的特征提取關乎最終分割性能的優劣,而局部特征聚合模塊是對點特征提取的關鍵步驟。如圖2所示,主要體現在對輸入點特征不斷進行維度擴充,從而學習到更加豐富的上下文信息。
對于每個輸入采樣點,使用簡單的K近鄰算法找到關聯的鄰居點(設定數量為16),進而對原始采樣點與若干個近鄰點進行相對位置編碼,得到rqi。
其中:函數G(·)由一個共享的MLP和softmax層組成;W為可學習的權重。得到的Sqi可視為選擇重要特征的軟掩模,再與原先的輸出特征f^qi進行加權求和,得到聚合特征輸出。這樣做可以增大每個輸入點的感受野,通過匯聚相鄰點的特征信息更大程度地保留原始輸入點云的局部幾何結構。
2.2 局部和全局優化方法
本文針對經典的聯邦平均算法進行了兩處輕量級的改進。首先重新調整了損失函數,將用于類別不平衡的損失函數FocalLoss(FL)[27],替代傳統聯邦局部監督學習的交叉熵損失。
FL(pt)=-αt(1-pt)γlog(pt)(10)
其中:αt用于調節正負樣本損失之間的比例;pt為預測概率值;γ通過減少易分類權重參數,從而加大對難區分樣本的專注度。由此在進行局部目標優化時能朝著所希望的方向進行,可提升整體聯邦語義分割任務的準確度。
同時,本文對全局聚合函數重新進行設計,采用的優化方法為DW,如式(11)所示。
其中:k為客戶端數量;C為總類別數;pij表示根據每個類別出現頻率所賦予的權重。相當于通過混淆矩陣計算出每個類別的真實數目為TP+FN,總數為TP+FP+TN+FN,分母計算由參與方總數確定的總的模型參數權重。旨在根據既定的權重評價指標進行多個模型的參數融合,在每輪次與中心方通信時能動態地調整每個參與方模型參數所占據的比重,相比于直接根據數量來定義權值大小或者直接平均參數,更能反映出單個參與方每輪學習到的局部模型質量。
3 實驗結果與分析
3.1 實驗配置
本文實驗環境采用的深度學習框架為PyTorch 1.8.1,編程語言為Python,在顯卡型號為NVIDIA GeForce RTX 3090和版本號為11.1的CUDA上開展實驗。進行聯邦學習訓練階段的局部epoch設置為5,全局epoch為20/12;在SemanticKITTI和SemanticPOSS上訓練的batch size設置為6,測試為20;在Toronto-3D上訓練的batch size設置為4,測試時為8。初始學習率為1E-2,采用Adam優化器,每個epoch學習率衰減5%。
3.2 實驗數據集
本次實驗采用SemanticKITTI、SemanticPOSS和Toronto-3D作為室外點云語義分割評估基準數據集。其中:SemanticKITTI是一個通用的具有豐富逐點點云注釋、涵蓋駕駛車輛掃描的大型全視野語義分割戶外場景數據集,數據集由22個序列組成,前11個序列的23 201個點云用于訓練和驗證,其中08序列通常用于由真實標簽生成的對比測試;SemanticPOSS是由北京大學采集的室外大規模稀疏點云實例,包括人和騎手等常規事物,共分為6個LiDAR數據序列,本文使用序列03作為測試,其余的用于聯邦訓練;Toronto-3D是由加拿大多倫多MLS系統獲取的覆蓋了大約1 km由7 830萬個點組成的城市道路語義分割的大規模戶外點云數據集,該數據集采集場景共4個,其中采用L001、L003、L004作為訓練集,L002作為測試集,共擁有8個有效語義標簽類。
對上述三個數據集采取聯邦多場景下的多點實驗數據切分以實現差異化的標簽數量分布。如在Toronto-3D上進行聯邦數據預處理,為保證數據隔離和劃分的有效性,在數量為三個的參與方時由不同采樣場景的訓練集重新分配本地數據空間。
3.3 實驗評估指標
本文實驗采用分割中常見的幾種指標來評估模型性能,包括整體準確率OA和平均交并比mIoU,詳細定義如下:
其中:pij表示每個類別點的真實標簽為i,預測輸出值為j;C表示總的語義類別數。
3.4 實驗結果與分析
為實現公平的實驗對比,所有結果均是在原始點云數據集上評估所得,在進行聯邦訓練后的三個數據集上的實驗可視化結果如圖3~5所示。表1~3分別是不同參與方數量在SemanticKITTI、SemanticPOSS和Toronto3D上的實驗結果。以基于RandLA-Net為backbone進行聯邦基準實驗,在數量CN設置為2和3時分別達到了52.5%和52.3%的mIoU,相較于集中式訓練平均下降了1.3個百分點,但相對于單一數據進行訓練得到42.9%的準確率,性能提升出色。表中FedNRN表示在初始化本地模型中加入雙層局部特征增強聚合模塊后的實驗結果;FedNRNP為融合輕量級的全局和局部優化方法,即采取動態權重聚合和Focal loss為目標函數進行優化。通過FedNRNP將SemanticKITTI的整體分割準確率最高提升了5.6個百分點。在聯邦后的SemanticPOSS數據集上進行實驗,相較于直接采取RandLA-Net進行實驗得到的52.1%和47.0%的語義分割mIoU,優化后的方法FedNRNP實現了57.5%和54.6%的語義分割mIoU,分別提升了5.4%和7.6%。另外,相較于集中式訓練所需要的100個epoch才達到的52.8%的mIoU,在進行聯邦訓練后僅需局部迭代5次,全局迭代20次就能達到52.1%的性能。
在數據分布差異越明顯的聯邦客戶端上,所取得的最終分割結果效果越差。如在SemanticPOSS和Toronto3D三個參與方的基礎上,FedNRNP優化方法相較于FedAvg取得的47.0%和72.4%的結果,最后提高至56.1%和78.9%,本文方法針對具有不平衡的本地數據分布特性下的性能損失更加魯棒,且不同數據集在每個類別的分割交并比均有不同程度的提升。例如在SemanticKITTI上的car、truck、person、trunk、traffic-sign類別,SemanticPOSS上的person,rider,trunk,building,fence類別,Toronto3D上的Road、Rd mrk、Car類別中展現出了同等條件下更有競爭力的分割結果。從圖3中可以看出,直接進行多方聯邦建模的分割結果,FedRN要明顯優于單一數據訓練結果SinSK,且經過優化后的方法FedNRNP取得了最接近真實標簽所預期的分割結果,進一步驗證了優化模型和聚合函數對于捕獲點之間信息的有效性。
本文針對所提出的聯邦共享模型進行了模塊消融實驗,結果如表4所示。FedRN為采取RandLA-Net作為骨干網絡取得的分割結果;PE為增強的位置編碼方式;FGA和BGA分別表示在第一和第二個局部特征聚合模塊后嵌入新穎的幾何衍射處理模塊;DGA為添加的雙層特征增強模塊。實驗結果表明,在融合了PE和DGA方法后的聯邦模型取得了更好的效果,達到了56.6%的mIoU,提升了4.5個百分點。
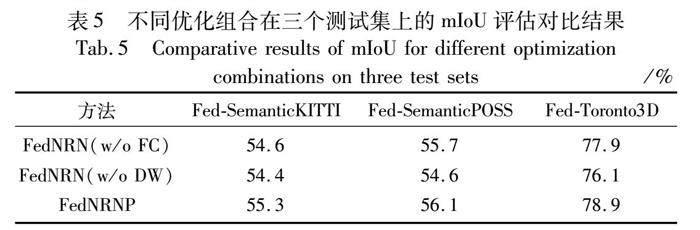
另外,本文還針對提出的全局和局部優化方法進行了消融實驗,結果如表5所示。對于進行聯邦后的三個數據集上訓練得到的模型,在不加入FC(采取FL進行優化)和DW兩種方法得到的mIoU均為最差的效果,經融合后得到的FedNRNP方法在不同用戶數量上提升顯著,均實現了同等條件下的最優,驗證了本文方法在應對大場景下異端用戶差異化數據分布的魯棒性。
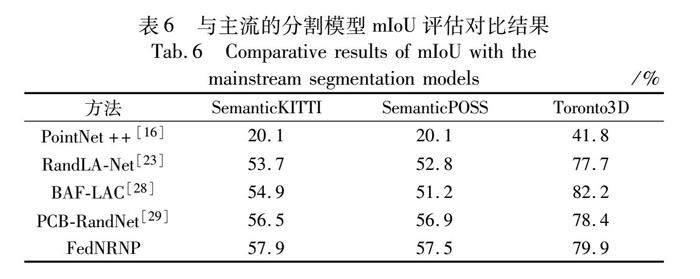
表6將本文方法與主流的大場景點云分割模型進行對比,實驗表明,相較于直接將數據暴露給原始服務器的其余四種方法,本文方法在分割性能和數據隱私上仍能取得較好的平衡。
4 結束語
鑒于現實大規模點云場景下的數據隱私敏感特性,本文設計了基于聯邦學習的點云語義分割算法,通過增強的局部特征聚合模塊提高每個鄰域內的幾何信息捕捉和學習能力,進一步優化損失和全局聚合函數以提升魯棒性。由于點云本身具有很強的稀疏性,在經過聯邦劃分后的數據集無法對多個分散的數據特征進行完整的特征提取,所以進一步優化聯邦模型局部特征編碼提取器,學習到更多細節和更關鍵的點間幾何信息將是未來優化的重點方向之一。
參考文獻:
[1]魏天琪,鄭雄勝.基于深度學習的三維點云分類方法研究[J].計算機應用研究,2022,39(5):1289-1296.(Wei Tianqi,Zheng Xiongsheng.Research of deep learning-based classification methods for 3D point cloud[J].Application Research of Computers,2022,39(5):1289-1296.)
[2]張佳穎,趙曉麗,陳正,等.基于深度學習的點云語義分割綜述[J].激光與光電子學進展,2020,57(4):20-38.(Zhang Jiaying,Zhao Xiaoli,Chen Zheng,et al.Review of point cloud semantic segmentation based on deep learning[J].Laser & Optoelectronics Progress,2020,57(4):20-38.)
[3]周傳鑫,孫奕,汪德剛,等.聯邦學習研究綜述[J].網絡與信息安全學報,2021,7(5):77-92.(Zhou Chuanxin,Sun Yi,Wang Degang,et al.Survey of federated learning research[J].Chinese Journal of Network and Information Security,2021,7(5):77-92.)
[4]Ma Xu,Qin Can,You Haoxuan,et al.Rethinking network design and local geometry in point cloud:a simple residual MLP framework[EB/OL].(2022-11-29)[2023-07-20].https://arxiv.org/pdf/2202.07123.pdf.
[5]McMahan B,Moore E,Ramage D,et al.Communication-efficient learning of deep networks from decentralized data[EB/OL].(2023-01-26).https://arxiv.org/pdf/1602.05629.pdf.
[6]Behley J,Garbade M,Milioto A,et al.SemanticKITTI:a dataset for semantic scene understanding of LiDAR sequences[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:9296-9306.
[7]Pan Yancheng,Gao Biao,Mei Jilin,et al.SemanticPOSS:a point cloud dataset with large quantity of dynamic instances[C]//Proc of IEEE Intelligent Vehicles Symposium.Piscataway,NJ:IEEE Press,2020:687-693.
[8]Tan Weikai,Qin Nannan,Ma Lingfei,et al.Toronto-3D:a large-scale mobile LiDAR dataset for semantic segmentation of urban roadways[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:797-806.
[9]朱威,繩榮金,湯如,等.基于動態圖卷積和空間金字塔池化的點云深度學習網絡[J].計算機科學,2020,47(7):192-198.(Zhu Wei,Sheng Rongjin,Tang Ru,et al.Point cloud deep learning network based on dynamic graph convolution and spatial pyramid pooling[J].Computer Science,2020,47(7):192-198.)
[10]Lawin F J,Danelljan M,Tosteberg P,et al.Deep projective 3D semantic segmentation[C]//Proc of the 17th International Conference on Computer Analysis of Images and Patterns.Cham:Springer,2017:95-107.
[11]Wu Bichen,Wan A,Yue Xiangyu,et al.SqueezeSeg:convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud[C]//Proc of IEEE International Confe-rence on Robotics and Automation.Piscataway,NJ:IEEE Press,2018:1887-1893.
[12]Iandola F N,Han Song,Moskewicz M W,et al.SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and<0.5 MB model size[C]//Proc of the 5th International Conference on Learning Representations.2017.
[13]Huang Jing,You Suya.Point cloud labeling using 3D convolutional neural network[C]//Proc of the 23rd International Conference on Pattern Recognition.Piscataway,NJ:IEEE Press,2016:2670-2675.
[14]Tchapmi L,Choy C,Armeni I,et al.SEGCloud:semantic segmentation of 3D point clouds[C]//Proc of International Conference on 3D Vision.Piscataway,NJ:IEEE Press,2017:537-547.
[15]Qi C R,Su Hao,Mo K, et al.PointNet:deep learning on point sets for 3D classification and segmentation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2017:77-85.
[16]Qi C R,Yi Li,Su Hao,et al.PointNet++:deep hierarchical feature learning on point sets in a metric space[C]//Proc of the 31st International Conference on Neural Information Processing Systems.2017:5105-5114.
[17]Zhao Hengshuang,Jiang Li,Fu C W,et al.PointWeb:enhancing local neighborhood features for point cloud processing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2019:5560-5568.
[18]Chen Linzhuo,Li Xuanyi,Fan Dengping,et al.LSANet:feature lear-ning on point sets by local spatial aware layer[EB/OL].(2019-06-20)[2023-07-20].https://arxiv.org/pdf/1905.05442.pdf.
[19]Zhao Chenxi,Zhou Weihao,Lu Li,et al.Pooling scores of neighboring points for improved 3D point cloud segmentation[C]//Proc of IEEE International Conference on Image Processing.Piscataway,NJ:IEEE Press,2019:1475-1479.
[20]Engelmann F,Kontogianni T,Hermans A,et al.Exploring spatial context for 3D semantic segmentation of point clouds[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:716-724.
[21]Ma Yanni,Guo Yulan,Liu Hao,et al.Global context reasoning for semantic segmentation of 3D point clouds[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2020:2920-2929.
[22]Hu Qingyong,Yang Bo,Xie Linhai,et al.RandLA-Net:efficient semantic segmentation of large-scale point clouds[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2020:11105-11114.
[23]Hu Qingyong,Yang Bo,Xie Linhai,et al.Learning semantic segmentation of large-scale point clouds with random sampling[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2021,44(11):8338-8354.
[24]Yang Aimin,Ma Zezhong,Zhang Chunying,et al.Review on application progress of federated learning model and security hazard protection[J].Digital Communications and Networks,2023,9(1):146-158.
[25]Dovrat O,Lang I,Avidan S.Learning to sample[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2019:2760-2769.
[26]Xu K,Ba J,Kiros R,et al.Show,attend and tell:neural image caption generation with visual attention[C]//Proc of the 32nd International Conference on Machine Learning.[S.l.]:JMLR.org,2015:2048-2057.
[27]Lin T Y,Goyal P,Girshick R,et al.Focal loss for dense object detection[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2020,42(2):318-327.
[28]Shuai Hui,Xu Xiang,Liu Qingshan.Backward attentive fusing network with local aggregation classifier for 3D point cloud semantic segmentation[J].IEEE Trans on Image Processing,2021,30:4973-4984.
[29]Cheng Huixian,Han Xianfeng,Jiang Hang,et al.PCB-RandNet:rethinking random sampling for lidar semantic segmentation in autonomous driving scene[EB/OL].(2022-09-28)[2023-07-20].https://arxiv.org/pdf/2209.13797.pdf.
