解糾纏鄰域信息聚合的知識圖譜補全方法
2024-05-24 04:45:35馬浩凱祁云嵩吳宇斌
計算機應用研究 2024年3期
馬浩凱 祁云嵩 吳宇斌
摘 要:針對現有基于圖神經網絡的知識補全模型在處理知識圖譜異構性上的不足,及大部分模型采用單一靜態實體表示方式導致的模型表達能力受限問題,提出一種基于圖注意力網絡的解糾纏鄰域信息聚合模型。首先,該模型通過學習每個實體的解糾纏表示,對實體的潛在影響因子進行多組件表示。其次,利用注意力機制,為兩個相連的實體選擇最具影響力的潛在影響因子作為連接要素。接著,通過關系感知注意力機制自適應地聚合實體因子級的鄰域消息,有效地減少了在信息聚合過程中不相關信息的相互干擾,進而顯著增強了模型的語義表達能力。此外,為了使模型在評分過程中關注與給定關系最相關的實體組件,進一步引入了一個自適應評分系數,使模型能夠自適應地感知給定的關系與實體不同組件的關聯度。實驗結果顯示,提出的模型在WN18RR和FB15K-237數據集的知識圖譜補全任務上相較其他先進基線模型表現更優,并顯著地增強了模型的表達能力。
關鍵詞:知識圖譜補全; 圖神經網絡; 解糾纏鄰域信息; 注意力機制
中圖分類號:TP391?? 文獻標志碼:A
文章編號:1001-3695(2024)03-018-0772-07
doi:10.19734/j.issn.1001-3695.2023.07.0294
Knowledge graph completion method for disentangledneighborhood information aggregation
Ma Haokai, Qi Yunsong, Wu Yubin
(School of Computer, Jiangsu University of Science & Technology, Zhenjiang Jiangsu 212000, China)
Abstract:Addressing the shortcomings of existing knowledge completion models based on graph neural networks in handling the heterogeneity of knowledge graphs and the limitations posed by most models adoption of a single static entity representation, this paper introduced a model based on the graph attention mechanism for disentangled neighborhood information aggregation. Initially, this paper learnt the disentangled representation of each entity, providing a multi-component representation for the latent influential factors of entities. Using the attention mechanism, the model selected the most influential latent factors as connection elements for two connected entities. Subsequently, by leveraging a relation-aware attention mechanism, the model adaptively aggregated neighborhood messages at the entity factor level, effectively reducing interference from irrelevant information during aggregation and significantly enhancing the models semantic representation capability. Moreover, to focus on the most relevant entity component in the scoring process with a given relation, this paper introduced an adaptive scoring coefficient, enabling the model to perceive the relevance between the given relationship and various entity components adaptively. Experimental results on the WN18RR and FB15K-237 datasets indicate that the proposed model outperforms other advanced baseline models in knowledge graph completion tasks, substantially enhancing the models expressive power.
Key words:knowledge graph completion; graph neural network; disentangled neighborhood information; attention mechanism
0 引言
知識圖譜(KG)是真實世界信息的結構化映射,用于描述實體或概念間的關聯。KG的應用遍及多個領域,如問答系統[1]、信息檢索[2]和基于內容的推薦系統[3]等。隨著技術的發展,知識圖譜越來越普及,當前流行的大型KG有WikiData[4]、Google KG[5]等,然而即使是這些擁有上百萬個實體和數十億個事實的大型知識圖譜也不可避免地存在知識不完整性問題。因此,知識圖譜補全(knowledge graph completion,KGC)技術被提出,用來解決KG中知識不完整性問題。目前,知識圖譜嵌入技術(knowledge graph embedding,KGE)已經成為知識圖譜補全任務的主流方法。知識圖譜嵌入模型主要有平移距離模型[6~10]、雙線性模型[11~14]和神經網絡模型[15~30]三類。平移距離模型以TransE[6]為代表,它以轉換關系將頭實體映射到尾實體,但對復雜關系和多語義問題處理能力有限,因此出現了TransG [7]、TransH[8]、TransR[9]、TransD[10]等改進模型。雙線性模型,如DistMult[11],以二維矩陣形式表示關系嵌入,但其不能對非對稱關系建模,后期研究者提出ComplEx[12]、Ana-logy[13]、SimplE[14]等模型以增強對非對稱關系建模的能力。
平移距離模型[6~10]和雙線性模型[11~14]主要挖掘實體間的線性關系,對知識圖譜中的潛在信息挖掘能力不足。傳統的神經網絡模型[15,16,26]因能有效挖掘KG中的潛在信息,逐漸成為研究焦點,例如ConKB[15]、ConvE[16]等模型。其中ConvE[16]模型將頭實體和關系拼接重塑為二維矩陣,然后使用卷積濾波器對重塑的二維矩陣進行卷積操作,提取實體與關系交互的特征信息,并將特征信息傳遞到密集層,最后將輸出與尾實體的嵌入進行點積,從而得到事實三元組的得分。然而,傳統的神經網絡模型不能有效挖掘KG中的實體鄰域信息,而圖神經網絡(graph neural network,GNN)[17~25,27~30]已經被證明能夠有效挖掘實體的鄰域信息,因此,越來越多基于圖神經網絡的知識圖譜嵌入模型被提出,最早的圖神經網絡模型之一是圖卷積網絡(graph convolutional network,GCN)[17],它通過利用鄰域實體的信息來更新每個實體的表示。GCN考慮了實體與其一階鄰域實體之間的關系,取得了優異的性能。隨后,提出了GraphSAGE[18],通過采樣鄰居節點的方式,使得模型在大規模圖上更具可擴展性。然而在圖卷積網絡模型中,分配給中心實體的所有鄰域實體的權值都是相等的,這顯然不利于捕獲節點之間的復雜關系。因此,研究人員將注意力機制與GCN[17]相結合,提出了圖注意力網絡(graph attention network,GAT)[19],GAT利用注意力機制為每個鄰居分配不同的權重,能夠更好地捕獲節點之間的復雜關系。在GAT的基礎上,KBGAT[20]將關系納入嵌入過程,能夠更好地捕捉實體和關系之間的復雜依賴關系。為了適應知識圖譜具有異構性的特點,RGHAT[21] 、MRGAT[22]和HRAN[23]模型開始關注關系對知識圖譜異構性的影響。其中:RGHAT將實體的局部鄰域視為一個層次結構,使用注意力機制分層捕獲鄰域實體與關系的依賴程度,使實體聚合更加細粒度化,同時提高了模型的可解釋性;MRGAT設計了一種能夠適應異構多關系連接的不同情況的多關系圖注意網絡,使模型能夠捕獲實體在不同關系下的語義信息;HRAN在不同關系路徑下通過關系特征計算該關系路徑的重要性,并利用關系路徑的重要性聚合實體特征,使模型能夠捕獲各種類型的語義信息。這些模型大多采用編碼器-解碼器框架,在編碼階段運用各種圖聚合機制傳播包含相鄰實體與關系的嵌入信息,在解碼階段對三元組打分。
盡管基于編碼器-解碼器框架的GNN模型在知識圖譜補全領域取得了重大進展,但是,現有的GNN模型在編碼階段通常將具有不同影響因子的實體和關系嵌入到一個低維向量中,這會導致不同影響因子相互干擾,從而影響模型的語義表達能力。例如在圖1中,實體“Steve Jobs”的局部鄰域實體包含了不同的“主題”,如“family”“career”和“birth information”等,本文將這些“主題”視作實體“Steve Jobs”的潛在影響因子。在圖2中實體“Steve Jobs”和“Kobe Bryant”擁有相同的國籍,一般的GNN模型通常會使“Steve Jobs”與“Kobe Bryant”的嵌入表示更接近這種身份,然而在“career”方面,這兩個人卻表現出很大的差異。顯然,這種將具有不同影響因子的實體作為一個整體并利用向量相似性表達語義信息的靜態嵌入方法,會明顯影響知識補全的性能。
因此,需要一種方法能夠分別考慮并表示這些不同的影響因子,從而提高模型的表達能力。通過研究發現,解糾纏表示學習是解決上述問題的一種有效方法,它旨在將高維、復雜的數據表示分解為一系列獨立或弱相關的因子,使這些因子之間的數據互不干擾。解糾纏圖卷積網絡(disen-tangled graph convolutional networks,DisenGCN)[24] 即是基于這一思想提出的。DisenGCN通過鄰域路由機制調整每個鄰居的權重來捕捉不同的因子通道的特定信息,從而實現實體的解糾纏表示,極大地提高了模型的性能,證明了利用解糾纏學習提高模型的表達能力是可行的。然而,DisenGCN模型的鄰域路由機制更注重將鄰域實體識別到不同影響因子的表示空間中,在相同的影響因子下,鄰域實體的貢獻度僅由鄰域實體與中心實體在該因子中的相似度決定,忽略了與該因子中其他鄰域實體比較的過程。因此,本文希望設計出一種模型,在相同因子中能夠將不同鄰域實體與中心實體的相似度進行對比,從而確定在該因子下鄰域實體對中心實體的貢獻度。這一過程與傳統的基于GAT的模型相似,不同的是本文采用因子級對比來確定鄰域實體信息在信息聚合過程中的權值,這種做法能夠有效減少不相關鄰域信息產生的干擾。例如,將圖2中實體“Steve Jobs”和“Kobe Bryant”的職業信息與國籍信息聚合到各自對應影響因子的表示空間下,即影響因子對應的表示組件下,由于國籍信息與職業信息存在于不同的表示空間中,能夠有效避免兩者的國籍信息對職業信息造成的干擾。然而,在實現因子級鄰域信息聚合之前,面臨的一個關鍵挑戰是如何確定不同影響因子中具有哪些鄰域實體。本文觀察到,在知識圖譜中,中心實體與鄰域實體產生連接的原因是它們擁有相同潛在影響因子,所以兩個相連的實體在導致它們相連的潛在影響因子的表示空間中,要比在其他影響因子下更加相似,并且這種相似度差別越大越好。例如在圖1中,鄰域實體“Apple”與中心實體“Steve Jobs”在潛在影響因子“career”中要比在“family”中更相似。基于這一觀察,本文利用中心實體與鄰域實體在不同潛在影響因子的表示空間中的相似度不同,選擇最大相似度的潛在影響因子作為中心實體與鄰域實體的連接因子,形成新的知識圖譜連接子圖,從而確定不同影響因子中有哪些與中心實體相連的鄰域實體。
綜合上述過程,本文結合注意力機制提出了一種新的基于圖注意力網絡的解糾纏鄰域信息聚合模型(disentangled neighborhood information aggregation with graph attention network,DNIAGAT)來解決傳統知識圖譜補全模型表達能力不足的問題。DNIAGAT模型能夠根據知識圖譜中實體的性質來學習其解糾纏表示,將實體的潛在影響因子分為多個組件表示,并在兩個相連的實體中選擇最重要的影響因子作為連接因子,確保每個組件相互獨立。在所選的連接因子中,運用關系感知注意力機制自適應聚合目標實體在該組件(連接因子)下對應一階鄰域實體的嵌入信息。這種方法可以有效增強模型的表達能力,避免實體中不同的潛在影響因子相互干擾。此外,為了使模型在解碼的過程中能夠適用給定的關系,本文引入了一個關系感知注意力自適應評分系數,控制評分函數對于給定關系相近的分量表示給予更高的評價,提高模型的準確率。
1 相關技術
1.1 解糾纏表示學習
解糾纏表示學習(disentangled representation learning)旨在將高維、復雜的數據表示分解為一系列獨立或弱相關的因子。通過這種方式,模型能夠更好地捕獲潛在的數據結構,從而提高模型的語義表達能力和可解釋性。其核心思想是找到一種有效的方法將輸入數據的不同屬性或因子分離開來。解糾纏學習的目標是通過編碼器將輸入數據映射到潛在表示空間,在此空間中,數據的每個維度代表一個獨立的因子,這意味著改變一個因子不會影響其他因子的表示。在圖1中,實體“Steve Jobs”的鄰居包含了不同的“主題”,如“family”“career”和“education”等。本文將每個主題視為實體的一個影響因子,實體的每一個組件對應實體在該影響因子下的嵌入表示。在預測三元組時,需要關注一個與任務更相關的影響因子。假設在(Steve Jobs,work of,?)的預測任務中,所設計的模型應該更多地關注“career”組件中的內容,如“Apple”,而不是“family”組件中的內容。
1.2 圖注意力網絡
圖注意力網絡(GAT)是圖神經網絡的一個重要分支,它將注意力機制與圖卷積網絡(GCN)相結合,利用注意力機制為其鄰域實體分配不同的權重,根據不同的權重聚合鄰域實體的嵌入信息,從而生成實體新的嵌入表示。與傳統的圖卷積網絡相比,GAT的優勢在于它可以為每對相鄰節點分配不同的權重,從而實現對鄰域信息的自適應聚合。這使得模型可以在節點間的交互中為每個鄰居分配不同的重要性。研究表明,該方法可以有效挖掘實體鄰域潛在的隱藏信息,提高模型的表達能力。
本文結合解糾纏表示學習的方法,在相同的潛在影響因子中引入GAT技術,將不同鄰域實體與中心實體的相似度對比,確定在該因子下鄰域實體對中心實體的貢獻度,使得中心實體能夠自適應地聚合在該因子下的鄰域實體信息,從而實現因子級鄰域信息的聚合。
2 準備工作
本文用G=(E,R,T)表示知識圖譜,其中E和R分別表示實體集和關系集,包含知識圖譜中所有關系,T表示三元組集合,(h,r,t)∈T表示一個三元組,其中h,t∈E,r∈R,每個三元組表示實體h與實體t關系間存在關系r。知識圖補全的任務包括在知識圖G中推斷缺失的邊,即預測一個給定的頭部實體和關系查詢的目標實體(h,r,?)。具體來說,該任務通常被定義為一個排名問題,目的是學習一個分數函數η(h,r,t),為有效的三元組分配比無效三元組更高的分數。這種通過已知三元組來預測未知三元組的任務也被稱為鏈接預測任務,是知識圖譜補全任務中的一個子任務。
3 本文方法
3.1 模型框架
基于圖注意力網絡的解糾纏鄰域信息聚合模型(DNIAGAT)遵循編碼器-解碼器框架。為解決傳統GAT模型在嵌入過程中將實體與關系信息描述為一個整體,從而導致模型語義表達能力不足的缺陷,DNIAGAT編碼器利用解糾纏表示學習的方法將每個實體表示分為K個不同的組件,每個組件負責實體在一個潛在影響因子下的鄰域實體信息聚合。DNIAGAT模型在編碼階段基于圖注意力網絡的思想,使用注意力機制聚合實體在不同組件(影響因子)下的相關鄰域實體信息。與DisenGCN模型相比,在聚合過程中,DNIAGAT模型利用注意力機制能夠自適應地感知不同組件(影響因素)下鄰域實體的重要程度,這對提高模型的表達能力是非常重要的。在解碼階段,DNINAGAT模型選擇ConvE作為實體各個組件之間的評分函數。此外,在聚合各個組件評分的過程中,DNINAGAT模型還引入了一個關系感知自適應評分系數來控制評分系統,更加關注與給定關系相關的組件分量信息。圖3為實體e0局部鄰域信息在模型框架中的計算過程,編碼器部分包括解糾纏表示、鄰域信息聚合等模塊,解碼器包括評分函數、自適應評分系數等模塊。圖中:(a)為e0與鄰域實體原始連接示意圖;(b)為e0在編碼器中聚合不同因子下鄰域實體組件信息的過程;(c)為e0與鄰域實體經過解糾纏以及確立連接因子操作后,在不同因子下的實體連接示意圖;(d)為編碼器輸出實體新的解糾纏表示作為解碼器的輸入并計算e0所在三元組最終評分的過程。
3.2 編碼器
3.2.1 實體解糾纏表示
在KG中,實體常常與多種語義相關。例如在圖1中,實體“Steve Jobs”與鄰域實體在家庭、職業等多個方面相關聯。本文DNIAGAT模型的主要目標是學習實體的解糾纏表示,通過解糾纏讓實體的各種語義特征從一個復雜的特征向量中分解出來。將特征向量投影到不同的潛在空間中,使每個組件可以從初始實體節點特征中提取不同的語義。具體來說,對于每個實體e,本文希望它的嵌入由K個獨立的組件表示,即e=[e1,e2,…,ek],其中ek∈Euclid ExtraaBpd/k描述了實體e的第k個潛在影響因子對應的語義特征。設計這種策略是基于一個觀察:每個潛在影響因子都與實體的一個特定語義屬性相對應,采用不同的投影矩陣W={W1,W2,…,Wk}來捕獲這些特定的語義屬性。具體過程為
4 實驗及結果分析
4.1 實現細節
本文在NVIDIA RTX 4090上使用PyTorch框架實現DNIAGAT模型。采用編碼器-解碼器架構,具體模塊包括數據預處理、實體解糾纏表示、連接因子選擇、鄰域組件信息聚合、自適應評分系數和預測層。所有參數通過Xavier初始化,確保了早期的穩定訓練。使用Adam優化器,并采取學習率衰減策略,初始學習率為0.001,每10個epoch減少10%。本文選取交叉熵作為損失函數,并引入了0.5的dropout和0.000 1權重的L2正則化防止過擬合。模型訓練了300個epoch,每10個epoch基于驗證集效果進行了模型保存。將所得到的實驗結果與其他較為先進的基線模型作對比,來驗證本文模型的先進性。通過消融實驗,驗證解糾纏表示以及因子級圖注意力機制聚合鄰域信息的有效性。
4.2 數據集
本文實驗采用的數據集為WN18RR、FB15K-237,這兩個數據集是知識圖譜補全任務常用的數據集。WN18RR是從WordNet抽取的子集,包含了40 943個實體和11種關系。由于FB15K中包含大量的逆關系,這會影響關系學習的精度,所以本文采用的是FB15K的子集FB15K-237。FB15K-237從FB15K中抽取,并且只保留每對互逆關系中的一個關系,它包含了14 541個實體,237種關系。兩種數據集具體統計情況如表1所示。
4.3 基線模型以及參數設置
為了驗證DNIAGAT模型的先進性,將該模型與現有較為先進的基線模型進行了對比實驗。基線模型包括傳統的知識圖譜嵌入模型、神經網絡模型。其中傳統的知識圖譜嵌入模型包括TransE[6]、DistMult[11],神經網絡模型包括ConvE[16]、KBGAT[20]、R-GCN[25]、CompGCN[27]、InteractE[26]、TRAR[28]、LTE-GCE[29]、MVCL[30]。
本文使用PyTorch實現了該模型,在模型中每個組件的嵌入維度為200,批處理大小batchsize設為{128,256,512,1024}。潛在影響因子K分別設為{2,4,6,8,10},參數γ值分別設置為{0.4,0.5,0.6,0.7,0.8},訓練迭代輪數epoch設置為300。數據集FB15K-237、WN18RR的學習率分別設置為0.000 5、0.000 1。
4.4 評估指標
本文選用MR(mean rank)、MRR(mean reciprocal rank)、hits@N作為模型的評估指標。MR是正確實體或關系的平均排名,MRR是正確實體或關系倒敘的排名。hits@N是一種計算正確實體或關系前N名的評估方法,例如N為3時,表示正確實體或關系排在前3名的比例,本文采用hits@1、hits@3、hits@10三種方法,計算前1、3、10名正確實體和關系的比例。在上述的三個指標中,MR越低、MRR或者hits@N越高,表明模型的實驗結果越好,進而說明模型的性能更優越。
4.5 實驗結果分析
4.5.1 實驗結果與基線模型對比分析
本文在不同的模型上對數據集WN18RR、FB15K-237進行了實驗,并將本文設計的DNIAGAT模型與其他基線模型的評估結果進行了對比分析,具體的實驗結果如表2所示。由表2可知,本文DNIAGAT模型的結果為所有設置參數中表現最好的結果。在表2中,粗體表示最優的性能,帶下畫線的數據表示次優的性能。可以發現,在FB15K-237數據集上,DNIAGAT模型在MR、MRR、hits@1、hits@3、hits@10指標中獲得了最好的性能,與其他最好的基線模型相比,在MRR、hits@1、hits@3、hits@10上性能分別提升了1.2%、1.1%、3.3%、1.7%。在WN18RR數據集上,DNIAGAT模型在MRR、hits@1、hits@3、hits@10上表現最佳,與最好的基線模型相比,分別提升了0.6%、1.4%、0.2%、1%。從表2可以發現,DNIAGAT模型在多個評估指標上都優于最先進的基線模型,這表明DNIAGAT模型具備有效性和先進性。具體來說,DNIAGAT模型利用解糾纏表示學習,將實體分為K個獨立組件表示,增強了模型的語義表達能力。在聚合鄰域信息時,每個組件通過關系注意力機制自適應地聚合與該組件對應影響因子相關的鄰域信息,這使得實體在聚合鄰域信息時能夠有效避免不相關鄰域信息的干擾,從而提升模型的性能。
4.5.2 實驗結果具體實例分析
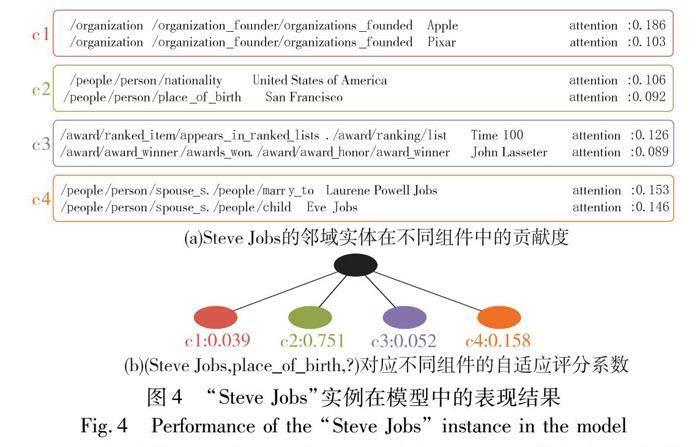
本節結合FB15K-237數據集中實體在模型中解糾纏表示的具體實例,來研究解糾纏表示學習如何促進實體的嵌入,從而提高知識圖譜補全任務的準確性。詳細的觀察結果如圖4所示。
在鄰域信息聚合過程中,首先確定了中心實體與鄰域實體之間的連接因子,即在k因子中與中心實體相連的鄰域實體,每一個因子k表示實體的一個潛在影響因素,因此,因子k中的鄰域實體應該與一個“主題”相關聯。然后,利用圖注意力機制自適應聚合相同因子中與中心實體相連的鄰域實體信息。因此,在相同因子中,不同鄰域實體對應的組件信息的貢獻度是不同的。在對預測三元組評分時,通過自適應評分系數使模型在評分過程中能夠更加關注與給定關系最相關的實體組件。
圖4(a)中給出了實體“Steve Jobs”在不同因子k中,貢獻度排名前2的鄰域實體。從圖4(a)中可以發現,組件C1、C2、C3、C4中的實體集信息屬于同一個“主題”,例如在組件C1中,“Apple” 和“Pixar”實體都是“Steve Jobs”創辦的,它們都反映了“Steve Jobs”在“career”方面的信息,并且“Apple”比“Pixar”的貢獻度大得多,這說明利用圖注意力機制能夠捕獲到相同因子中不同實體組件信息的貢獻度。而在組件C2中,包含了實體“United States of America”和“San Francisco”,兩者都與“birth information”這一主題相關聯。因此,根據圖4(a)可以推測出組件C1、C2、C3、C4為“Steve Jobs”分別在“career”“birth information”“achievement”“family”四個不同“主題”中的解糾纏表示。圖4(b)給出了預測三元組(Steve Jobs,place_of_birth,?)在解碼器中不同因子k對應組件的自適應評分系數,可以發現組件C2的自適應評分系數值遠遠高于其他組件,這是因為“place_of_birth”與組件C2反映的主題更相關,同時這一現象也充分驗證了本文對C2組件對應“birth information”這一主題的推測。圖4(b)的結果證實了自適應評分系數能夠使模型在評分過程中更加關注與給定關系最相關的實體組件。
4.6 消融實驗
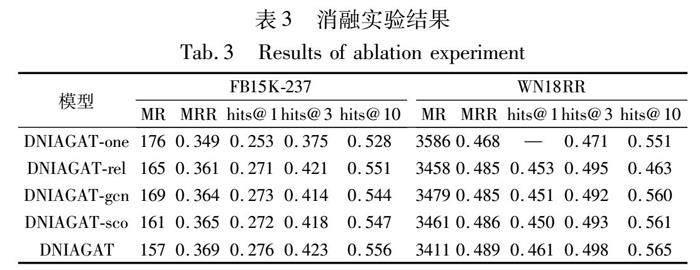
為了進一步驗證實體解糾纏表示、關系信息、因子級圖注意力機制、自適應評分系數對模型預測效果的影響。建立DNIAGAT的變體模型DNIAGAT-one、DNIAGAT-rel、DNIAGAT-gcn、DNIAGAT-sco。在DNIAGAT-one模型中設置因子數K值為1,使實體所有的信息都通過一個特征向量表示,從而使模型失去解糾纏表示的能力,其他部分與DNIAGAT模型一致。DNIAGAT-rel消去了關系投影矩陣、實體對應的線性投影矩陣,實體對應的組件信息不再投影到相應的關系子空間中。其他部分與DNIAGAT模型一樣。DNIAGAT-gcn在聚合因子k中鄰域實體的組件信息時,不再采用圖注意力機制,而是采用圖卷積操作,即對因子中鄰域實體組件集合求和除平均值。其他步驟與DNIAGAT一樣。DNIAGAT-sco不再使用自適應評分系數,直接使用ConvE[16]作為解碼器生成三元組最終評分。將DNIAGAT模型與它的四個變體模型在數據集FB15K-237、WN18RR上分別進行了鏈接預測任務實驗,消融實驗結果如表3所示。
從消融實驗的結果可以發現,具備解糾纏表示學習能力的模型在兩個數據集上表現更好,并且改善較為明顯,這說明對實體進行解糾纏表示能夠提升知識圖譜補全任務的性能;利用特異性投影矩陣將實體的組件信息投影到對應的關系子空間中,從而使模型融入關系信息,在不同數據集上各個評估指標值都有所提升,說明融入關系信息對模型有促進作用。利用圖注意力機制的方法聚合因子中鄰域組件信息對比利用圖卷積操作的方法,在FB15K-237和WN18RR上的MRR、hits@3、hits@10指標分別提升了0.5%、0.9%、1.2%、0.4%、0.6、0.5%。這說明利用圖注意力機制聚合因子中的鄰域組件信息是有效的;使用自適應評分系數的模型比不使用自適應評分系數的模型在兩個數據集上各項指標更優異,顯然,自適應評分系數可以促進模型的性能。
4.7 超參數分析
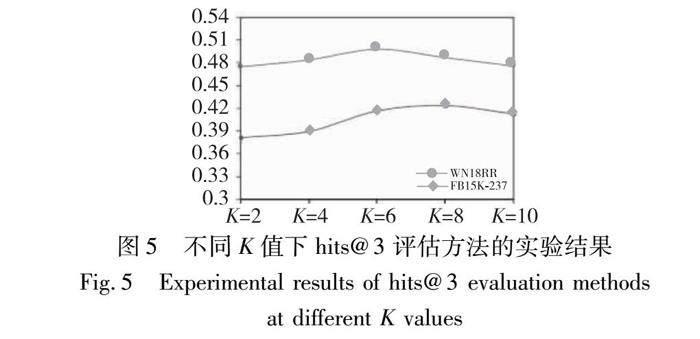
為了驗證因子數量對模型性能的影響,在其他參數相同的情況下,設置不同的K值{2,4,6,8,10},分別在數據集WN18RR[22]與FB15K-237[23]上采用hits@3評估方法進行實驗,不同K值的表現如圖5所示。
圖5 不同K值下hits@3評估方法的實驗結果
Fig.5 Experimental results of hits@3 evaluation methodsat different K values
從圖5中可以發現:在數據集WN18RR上,K=6時,模型的性能表現最優;在數據集FB15K-237上,K=8時,模型的表現最優。這表明隨著K值的增大,模型在知識補全任務上的表現會更優,將實體分為不同組件進行解糾纏表示的方法可以有效促進知識圖譜補全任務的質量。然而,并不是K值越大越好,當K值增大到一定區間時,模型的表現會呈現下降趨勢。從實驗結果可以發現,K的值對模型性能的影響是巨大的。因此,設置合適的K值是本文模型的重點。
5 結束語
本文提出了一種新的基于圖注意力網絡的解糾纏鄰域信息聚合模型(DNIAGAT)來完成知識圖譜補全任務。該模型將實體嵌入分為K個組件表示,每個組件對應一個實體的影響因子,選擇最重要的影響因子作為兩個實體的連接因子,使用注意力機制聚合實體在不同組件(影響因子)下的相關鄰域實體信息,并且在解碼過程中引入一個關系感知系數來控制評分系統,使其更加關注與給定關系相關的組件分量信息,進一步分離了組件間的干擾信息。通過與基線模型對比的實驗,證明了DNIAGAT模型的先進性。未來將關注少關系知識圖譜的聚合方法,將其融合到DNIAGAT模型中,并改進DNIAGAT模型的算法,減少模型的計算量。
參考文獻:
[1]Huang Xiao, Zhang Jingyuan, Li Dingcheng, et al. Knowledge graph embedding based question answering[C]//Proc of the 12th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2019: 105-113.
[2]Li Fangyi, Li Ying, Shang Changjing, et al. Fuzzy knowledge-based prediction through weighted rule interpolation[J]. IEEE Trans on Cybernetics, 2019,50(10): 4508-4517.
[3]Wang Hongwei, Zhang Fuzheng, Wang Jialin, et al. Exploring high-order user preference on the knowledge graph for recommender systems[J]. ACM Trans on Information Systems, 2019,37(3): 1-26.
[4]Vrandecˇic' D, Krtzsch M. WikiData: a free collaborative knowledgebase[J]. Communications of the ACM, 2014,57(10): 78-85.
[5]Singhal A. Introducing the knowledge graph: things, not strings[EB/OL]. (2012)[2022-10-30]. https://blog.google/products/search/introducing-knowledge-graph-things-not/.
[6]Antoine B, Nicolas U, Alberto G D, et al. Translating embeddings for modeling multi-relational data[C]//Proc of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013:2787-2795.
[7]Xiao Han, Huang Minlie, Zhu Xiaoyan. TransG: a generative model for knowledge graph embedding[C]//Proc of the 54th Annual Mee-ting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computer Linguistics, 2016: 2316-2325.
[8]Wang Zhen, Zhang Jianwen, Feng Jianlin, et al. Knowledge graph embedding by translating on hyperplanes[C]//Proc of the 28th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2014:1112-1119.
[9]Lin Yankai, Liu Zhiyuan, Sun Maosong, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Proc of the 29th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2015: 2181-2187.
[10]Ji Guoliang, He Shizhu, Xu Liheng, et al. Knowledge graph embedding via dynamic mapping matrix[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 687-696.
[11]Yang Bishan, Yih S, He Xiaodong, et al. Embedding entities and relations for learning and inference in knowledge bases[C]//Proc of International Conference on Learning Representations. 2015.
[12]Trouillon T, Welbl J, Riedel S, et al. Complex embeddings for simple link prediction[C]//Proc of the 33rd International Conference on International Conference on Machine Learning.[S.l.]: JMLR. org, 2016: 2071-2080.
[13]Liu Hanxiao, Wu Yuexin, Yang Yiming. Analogical inference for multi-relational embeddings[C]//Proc of the 34th International Conference on Machine Learning.[S.l.]: JMLR. org, 2017: 2168-2178.
[14]Kazemi S M, Poole D. Simple embedding for link prediction in knowledge graphs[J]. Advances in Neural Information Proces-sing Systems, 2018,31: 4289-4300.
[15]Nguyen D Q, Nguyen D Q, Nguyen T D, et al. A convolutional neural network-based model for knowledge base completion and its application to search personalization[J]. Semantic Web, 2019,10(5): 947-960.
[16]Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2D know-ledge graph embeddings[C]//Proc of the 32nd AAAI Conference on Artificial Intelligence and the 30th Innovative Applications of Artificial Intelligence Conference and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto,CA: AAAI Press, 2018: 1811-1818.
[17]Zhang Si, Tong Hanghang, Xu Jiejun, et al. Graph convolutional networks: a comprehensive review[J]. Computational Social Networks, 2019,6(1): 1-23.
[18]Hamilton W L, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:1025-1035.
[19]Velickovic P, Cucurull G, Casanova A, et al. Graph attention networks[EB/OL]. (2017-10-30). https://arxiv.org/abs/1710.10903.
[20]Nathani D, Chauhan J, Sharma C, et al. Learning attention-based embeddings for relation prediction in knowledge graphs[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4710-4723.
[21]Zhang Zhao, Zhuang Fuzhen, Zhu Hengshu, et al. Relational graph neural network with hierarchical attention for knowledge graph completion[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2020: 9612-9619.
[22]Dai Guoquan, Wang Xizhao, Zou Xiaoying, et al. Multi-relational graph attention network for knowledge graph completion[J]. Neural Networks, 2022,154: 234-245.
[23]Li Zhifei, Liu Hai, Zhang Zhaoli, et al. Learning knowledge graph embedding with heterogeneous relation attention networks[J]. IEEE Trans on Neural Networks and Learning Systems, 2022,33(8): 3961-3973.
[24]Ma Jianxin, Cui Peng, Kuang Kun, et al. Disentangled graph convolutional networks[C]//Proc of the 36th International Conference on Machine Learning.[S. l. ] : PMLR, 2019: 4212-4221.
[25]Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling relational data with graph convolutional networks[C]//Proc of the 15th International Conference on Semantic Web. Berlin : Springer-Verlag, 2018: 593-607.
[26]Vashishth S, Sanyal S, Nitin V, et al. InteractE: improving convolution based knowledge graph embeddings by increasing feature interactions[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2020: 3009-3016.
[27]Vashishth S, Sanyal S, Nitin V, et al. Composition-based multi-relational graph convolutional networks[EB/OL]. (2019-11-08). https://arxiv.org/pdf/1911.03082.pdf.
[28]Zhao Xiaojuan, Jia Yan, Li Aiping, et al. Target relational attention-oriented knowledge graph reasoning[J]. Neurocomputing, 2021, 461: 577-586.
[29]Zhang Zhanqiu, Wang Jie, Ye Jieping, et al. Rethinking graph con-volutional networks in knowledge graph completion[C]//Proc of ACM Web Conference. New York: ACM Press, 2022: 798-807.
[30]喬梓峰, 秦宏超, 胡晶晶,等. 融合多視圖對比學習的知識圖譜補全算法[J/OL]. 計算機科學與探索.[2023-08-06]. http://kns.cnki.net/kcms/detail/11.5602.TP.20230329.1546.002.html. (Qiao Zifeng, Qin Hongchao, Hu Jingjing, et al. Knowledge graph completion algorithm fused with multi-view contrastive learning[J/OL]. Computer Science and Exploration.[2023-08-06]. http://kns.cnki.net/kcms/detail/11.5602.TP.20230329.)
