
基于無服務器邊緣計算下的服務負載調度算法
2024-05-24 04:37:59高明陳國揚
計算機應用研究 2024年3期
高明 陳國揚


摘 要:隨著邊緣計算的不斷發展,其在資源管理配置方面逐漸出現相關問題,無服務器計算作為一種新的方式可以有效解決邊緣計算的相關問題。然而,無服務器計算不具備在分布式邊緣場景中高效處理請求所需服務負載調度的能力,針對這一問題,提出了一種基于無服務器邊緣計算的服務負載調度算法(service load scheduling algorithm,SLSA)。SLSA的核心是通過隱式建模充分考慮了動態變化的節點狀態、負載調度器放置等影響因素來優化整體時延,然后通過改進的平滑加權輪詢調度(smooth weighted round robin,SWRR)算法進行服務調度。經仿真實驗分析,SLSA在資源消耗上有著明顯下降,同時在單城市場景與多城市場景下均有良好的性能表現,其中在單城市場景中相對于集中式輪詢調度(round robin centralized,RRC)算法提升了43.01%,在多城市場景中提升了53.81%。實驗結果表明,SLSA可以有效降低資源消耗率并提升性能。
關鍵詞:邊緣計算; 無服務器計算; 負載調度; 性能對比
中圖分類號:TP393?? 文獻標志碼:A
文章編號:1001-3695(2024)03-024-0811-07
doi:10.19734/j.issn.1001-3695.2023.07.0295
Service load scheduling algorithm based on serverless edge computing
Gao Ming, Chen Guoyang
(School of Information & Electronic Engineering, Zhejiang Gongshang University, Hangzhou 310018, China)
Abstract:With the continuous development of edge computing, there are gradually related problems in resource management and configuration. As a new way, serverless computing can effectively solve the related problems of edge computing. However, serverless computing does not have the ability to efficiently process requests in distributed edge scenarios. To solve this problem, this paper proposed a service load scheduling algorithm(SLSA) based on serverless edge computing. The core of SLSA was to fully consider the dynamic changes of node status, load scheduler placement and other influencing factors through implicit modeling to optimize the overall delay, and then used the improved smooth weighted round robin(SWRR) scheduling algorithm for service scheduling. The simulation results show that SLSA has a significant reduction in resource consumption, and has good performance in both single-city scenarios and multi-city scenarios. In the single-city scenario, SLSA is 43.01% higher than the RRC algorithm. It improves 53.81% in multi-city scenarios. Experimental results show that SLSA can effectively reduce the resource consumption rate and improve the performance.
Key words:edge computing; serverless computing; load scheduling; performance comparison
0 引言
隨著大量互聯網應用(如虛擬現實、人工智能等)的不斷發展,數據量日益增長,由于網絡遠距離傳輸的不確定性,云計算這種集中處理模式對于那些實時性和可靠性要求比較高的應用場景非常不適用[1]。邊緣計算在此背景下應運而生,它在靠近用戶側的網絡邊緣部署云計算環境,就近處理數據和計算任務,可以有效處理大量任務需求,相比于傳統的云計算更高效、更安全[2]。但也正是由于邊緣計算靠近數據源頭,其工作環境更為復雜,存在大量的分布式異構設備和資源,這為管理和維護這些設備以確保它們的正常運行和安全性帶來了極大的困難。此時,無服務計算(serverless computing)[3]進入業界視線當中。無服務計算是指在構建和應用程序時不需要管理服務器的一種計算范式,它描述了細粒度部署模型,由一個或多個函數組成的應用可上傳到平臺,并執行、擴縮容和基于實際運行時的資源消耗及進行計費[4]。無服務器計算并不是沒有服務器,Serverless架構的背后依然是虛擬機和容器,只不過服務器部署、runtime安裝、編譯等工作,都由Serverless平臺負責完成,對開發人員來說,只需維護源代碼和Serverless執行環境的相關配置即可。同時,相比于基礎設施即服務(infrastructure as a service,IaaS)、平臺即服務(platform as a service,PaaS)等計算架構,Serverless計算架構能提供更細粒度的資源管理和部署模型,通過計算資源的按需分配,實現計算資源的動態調整和高效利用[5]。
基于該思路,業界逐漸意識到邊緣計算和無服務器計算融合的價值和必要性[6]。邊緣設備上的計算和存儲資源是相對有限的,且在傳統的邊緣計算框架下,用戶仍然承擔著繁重的資源配置和管理負擔,因此迫切需要一種方法來有效利用邊緣資源。無服務器計算提供了一種新的方式,基于輕量級抽象(含容器、Unikernel等),Serverless 會滿足較小的占用空間,細粒度自動擴縮容,因此創建/終止副本的開銷相對是非常小的[7]。同時,將無服務器計算集成到邊緣計算場景中,可以讓應用在使用邊緣計算資源時不考慮運行環境、負載均衡和可擴展性,從而有效提高邊緣資源的利用率,為用戶提供更靈活的服務。
隨著兩者進一步的融合,無服務器邊緣計算的概念也隨之提出[6]。但是,無服務器計算設計的初衷是為云計算服務的,將其應用在邊緣計算場景中仍存在挑戰。邊緣計算的基礎設施資源是受限且異構的,每個邊緣計算節點會對所部署的服務類型具有限制,無服務器計算不具備在分布式邊緣場景中高效處理請求所需服務負載調度的能力[1]。因此,在無服務器邊緣計算中,如何在分布式的網絡環境中實現高效的服務調度成為了亟待解決的問題,為此,本文提出了一種基于無服務器邊緣計算環境的服務負載調度算法。首先把工作過程中的服務負載調度響應時間看成黑盒,然后基于負載調度器來觀察節點對應的平均歷史響應時間,推導出其對應動態變化的節點權重,通過動態權重來進一步改進平滑加權輪詢調度算法,同時判斷放置負載調度器的有效性,最后進行優化調度來實現高效服務調度。
1 相關工作
隨著無服務邊緣計算的不斷發展,業界對如何提升其性能展開了研究工作。在服務負載調度方面,Rausch等人[8]利用 Serverless 架構的優勢將AI應用推向邊緣,并通過對調度決策采用更細粒度的控制和約束以保障在資源受限的邊緣計算中獲得更優的性能表現。進一步地,面對邊緣架構的異構性,以及計算和存儲基礎設施的地理分布,他們在文獻[8]中使用啟發式的方法,提出一種容器調度策略以優化在 Serverless 邊緣計算中部署數據密集型應用的開銷,通過自動微調調度約束權重以最小化任務執行時間以及上行鏈路使用成本,但是他們并不認為系統的負載平衡組件可以獨立于其他功能進行擴展和調度。Cicconetti等人[9]提出了在無服務器系統中匹配客戶端和功能副本的不同方法,他們評估了不同的分配策略,通過模擬顯示,在靜態全局匹配、周期性全局匹配和客戶端到副本的動態分散匹配之間,分散版本表現最佳。然而,在他們的研究中,客戶機通過一個集中的編排組件被分配給調度程序,這在大量數據來臨時可能會造成資源浪費,因此在論文中改進成客戶機連接到發送請求時距離最近的負載平衡器。
除了無服務器計算和邊緣計算之間的融合,Zhao等人[10]提出了啟發式算法,有效地將服務放置在移動邊緣計算環境中。他們的目標是通過優化邊緣計算系統中給定數量的副本的放置決策,最大限度地減少系統內的總體數據流量。他們首先制定了優化問題,其目標是在可用節點中放置k個服務副本,以便由客戶機請求生成的網絡內的總體流量最小。他們提出了一種啟發式算法,對于給定的k個副本的目標部署,將所有可能節點的集合劃分為k個集群。在每個集群中,一個副本被放置在集群中可用的最佳節點上。雖然不一定是最優的,但劃分為多個集群大大降低了計算復雜性,同時執行的性能幾乎與最佳放置的全空間搜索相同。但是,他們的方法沒有考慮節點之間的任務劃分,這會導致一定資源的浪費。
基于上述工作,本文作出了進一步改進,通過考慮邊緣計算中不同的網絡條件、動態變化的節點狀態等因素,同時綜合考慮服務負載調度器的擴展和調度來實現高效服務負載調度的目標。
2 無服務器邊緣計算系統建模與問題描述
2.1 整體模型
如圖1所示,一種典型的基于無服務器邊緣計算系統的場景[11]設置在智慧城市中,系統由若干個Serverless邊緣計算集群、服務調度器、云計算中心和用戶設備組成,并通過圖1中的鏈路進行連接。
由圖1可知,用戶設備指需要調用計算服務的終端設備,用戶設備向Serverless 邊緣計算集群提交服務請求,根據服務請求,將會分配對應的Serverless函數,這些函數根據服務放置策略將會在相應節點中實例化,然后由服務調度器將服務請求調度至相應的節點。當某種服務的請求量出現突發增長時,Serverless計算集群將會對函數實例進行擴容,即在其他節點增加函數的副本數來滿足計算需求。基于該框架,開發人員只需關心服務所對應函數的功能實現,即“無服務”。云計算中心為客戶端提供了無限的計算能力,云計算中心通常離客戶端較遠,將導致較高的傳輸成本和服務執行時延,因此云計算中心更適合執行延遲非敏感型應用。此外,當函數不適合在邊緣執行時,云計算中心還可以進一步提供計算服務。
在了解上述場景的具體流程后,在實際場景中能夠發現當前的Serverless計算架構不具備在邊緣場景中高效處理請求所需的服務負載調度機制。現有的Serverless平臺通常建立在容器編排平臺Kubernetes之上來實現計算資源的池化和納管,并基于Kubernetes平臺實現Serverless服務管理平臺[12]。這些Serverless服務管理平臺依賴于Kubernetes底層原有的服務負載調度策略,而這些服務負載調度策略是基于云計算中計算能力和網絡結構相對同質的前提實現的。因此,將在2.2節中定義一個問題描述來進一步了解問題所在。
2.2 問題描述
如圖2所示,以最受歡迎的開源Serverless框架OpenFaaS為例[13],其使用API Gateway組件作為請求的入口,該組件接收客戶端的請求,再將請求轉發至相應的函數。
在OpenFaaS中,API Gateway收到請求后依賴Kubernetes平臺進行路由,Kube-Proxy作為Kubernetes中負責處理網絡路由和容器實例負載均衡的組件,默認采用的是輪詢的策略進行負載調度。也就是說,函數f1對應的請求將在已實例化的node1和node2中輪詢執行。對于計算資源和網絡都比較統一的云計算來說,采用輪詢的調度策略從長期來看是公平的,而對于異構的邊緣計算網絡來說,簡單的輪詢策略無論從短期還是長期來說都是不公平的。如圖2所示,上一輪請求中,函數f1在node1中被執行,而在本輪請求中,函數f1被調度至node2執行,node1與node2之間存在著50 ms的網絡延遲,在節點性能相同的情況下,本輪請求繼續在node1中執行會比在node2中執行具有更低的響應時延,但由于負載調度策略未考慮到異構性,從而造成了更長的客戶端等待時間。此外,從圖2可以發現,API gateway作為唯一請求的入口,部署于node1中,當另一個客戶端在node2附近提交計算任務,那么請求需要借助Kubernetes底層網絡轉發至node1中的API gateway,采用集中式的服務負載入口會導致更長的客戶端等待時間。這些問題都是采用云計算中的Serverless服務負載調度策略導致的。
對以上問題進行分析,主要是現有的服務負載調度策略沒有考慮到邊緣結構中不同節點性能會實時變化,除此之外,現有策略的集中式調度會導致更長的等待時間。所以,為了在邊緣計算環境下更好地應用Serverless架構,對于服務負載調度策略,需要滿足以下兩點:
a)自適應負載調度:服務負載調度器在調度計算任務時應盡量選擇網絡距離較近的實例化節點,并且綜合考慮動態變化的邊緣節點、客戶端網絡位置對函數執行時間的影響。
b)有效放置:服務負載調度器應放置在離客戶端和實例化節點網絡距離較近的節點,并且考慮位置對性能的影響,來解決由于負載調度器放置問題引起的調度時延放大問題。
考慮到負載調度的各種潛在復雜因素,本文決定給負載調度方法采用一種相對簡單的方法。服務負載調度決策完全基于負載調度器觀察到的總響應時間,這意味著其不區分不同網絡部分產生的時間,因此,本文將總響應時間視為整個系統的黑盒來進行度量。除此之外,加權輪循調度是實現負載均衡的重要策略之一,在實驗了其他解決方案,并根據無服務器邊緣計算環境帶來的獨特挑戰分析了它們的性能概況和特征后,本文選擇了Nginx[14]中的平滑加權輪詢調度算法(smooth weighted round robin,SWRR),相比于經典的加權輪詢調度在某些特殊的權重下會生成不均勻的實例序列,SWRR算法克服了這一問題,避免了實例負載突然加重的可能。但是,SWRR無法動態感知系統集群中實例的性能變化[15],會導致系統穩定性的惡化。因此,針對SWRR無法動態感知性能變化這一缺點,同時針對服務調度器的有效放置問題,在第3章中設計了一種基于無服務器邊緣計算下的服務負載調度算法(service load scheduling algorithm,SLSA),以高效地尋找響應時間最優解。
3 無服務器邊緣計算下的服務負載調度算法
SLSA的核心思想主要是把整個工作過程中的服務負載調度響應時間看成黑盒,基于負載調度器來觀察每個節點對應的平均歷史響應時間,接著推導出對應動態變化的節點性能權重,基于上面得到的動態權重進行加權輪詢調度,同時考慮在節點處放置負載調度器對響應時間的影響來判斷是否放置該調度器,最后得到一個最優化調度。
在上述步驟中,推導出了動態變化的節點權重這一概念,這個概念是對比于SWRR調度算法的一個優化,來改進SWRR無法動態感知系統集群中實例的性能變化這一缺點。在Serverless邊緣計算中,邊緣節點、客戶端網絡位置是動態變化的,節點中部署的函數也會隨時進行縮放。因此在SLSA中引入了動態節點權重,其好處是所有因素都將被包含在內,當某節點由于多函數共享計算資源出現性能降級時,負載調度器所觀察到的該節點服務響應時間也將出現相應增加。SLSA雖然沒有對這些因素進行顯式建模,但這些因素會不斷地通過服務響應時間的變化,隱式地通過動態變化的節點權重體現出來,同時負載調度器放置也是影響調度性能的重要因素。故本算法的關鍵在于確定對應動態變化的節點權重的映射方法,以及確定負載調度器放置的有效性。
算法 SLSA
輸入:可用節點集合n;請求負載ω;負載調度器lc。
輸出:節點動態權重;響應時間。
Function SLSA:
1 n←[] //初始化節點集合
2 for n∈N do //遍歷所有節點
3?? avg_resp_time←calculate_ema(time,window_size)
4?? weight←range_weight_mapping(avg_resp_time)
5?? n←n.append(n,weight)
6?? for n in lc do //在節點運行調度器
7??? if effect(n,f)>0 //判斷性能影響因子
8???? lc.add(n) //保留調度器
9??? else effect(n,f)<0
10??? lc.remove(n)
11?? end for
12? end for
13 return smooth_weight(n,ω)←response_time //返回響應時間
3.1 計算動態權重
算法首先輸入了可用節點集合n,請求負載ω,負載調度器lc這三個指標。SLSA的第1行對輸入的節點集合n進行初始化,第2~5行遍歷所有對應的Serverless函數節點來計算節點的動態權重,并把節點動態權重放入初始節點集合n中。第3行計算了節點的平均歷史響應時間,考慮到節點的性能會隨時間變化,而作為性能指標,變化之后的值更為重要。為了解決這一問題,在第3行中采用了固定窗口大小的指數移動平均值(exponential moving average,EMA)這一指標。EMA在計算服務響應平均值時使用了固定窗口大小并且使用了指數衰減因子,它只需要記錄上次更新的時間和當前的值,使其能確保最小的內存消耗,同時易于理解和實現,與簡單的移動平均值相比,它能更快地反映響應時間的變化。給定某邊緣節點先前服務響應時間平均值、最近的響應時間t、上次請求以來經過的時間Δt和窗口大小w,則更新之后的服務響應平均值′,即算法第3行的EMA具體實現可以表示為
′=e-Δtw×+(1-e-Δtw)×t(1)
根據式(1)得到平均歷史響應時間。但是,單純得到服務平均響應時間還不夠,使用基于黑盒的響應時間觀測方法也存在一定缺點,因為節點性能會受到潛在因素影響而顯著變化。假設一個邊緣服務節點n1在t1時刻由于網絡原因導致在該時刻性能變差,服務響應時間比較長,但該節點n1在大部分時刻,性能都表現很好。此時,由于服務調度器總是基于平均歷史響應時間決策,那將不會有任務被調度在節點n1上。這時,就出現了由于節點性能在提升后沒有被及時記錄而導致次優調度現象。基于此,本文在第3行得到平均歷史響應時間之后,在第4行附加了邊緣節點權重的動態分配策略配合動態加權輪詢調度算法,使每個節點都能分配到固定的流量,讓每個節點能夠分配到一個權重初始值,從而對節點的性能變化及時采樣,以避免次優調度問題的出現。算法第4行使用了固定范圍的權重,確保每個節點都分配到初始值,每個節點的權重由最新的服務響應平均時間所決定。下面假設′∈R表示節點服務響應平均值的集合,Wmax表示最大權重,Wmin表示最小權重,則每個節點響應時間平均值的權重W(′)定義為
W(′)=maxWmin,Wmax(′min{′,′∈R})s(2)
其中:s>0是選定的比例因子,比例因子決定了服務平均響應時間和邊緣節點權重之間的映射關系,當s=1時,表示服務平均響應時間和節點權重間存在線性關系。基于網格搜索實驗,選擇了Wmin=10,Wmax=30,以及s=2.0,具體網格搜索實驗的選擇過程將在4.2節中詳細解釋。
在得到上述動態變化的權重值后,可以對SWRR算法進行一個改進。SWRR算法的步驟分為兩步:所有節點都有一個初始值,用它們的初始值加上設定的權重值得到當前節點集;在當前節點集中選擇當前值最大的節點為命中節點,并把它的當前值減去所有節點的權重總和作為其新權重值,其他節點保持不變。因為其設定的權重值是不變的,所以在若干個周期之后,當前節點值會重新變為初始值,即一個周期,后面就會按照這個周期進行循環。通過式(2)得到的動態變化的節點權重W(′),替代了SWRR中設定的權重值,使其不再一直按照周期進行變化,可以使集群中動態變化的服務器在負載分布時更加均勻。最后,算法第5行把節點信息和對應動態權重加入到了初始創建的集合當中。
3.2 負載調度器放置
上一節描述了計算動態權重的過程,而在實際過程中,負載調度器的有效放置是影響服務響應時間的一大重要因素[16],因此本文在算法6~11行加入了對服務調度器位置判斷的一個過程,來決定調度器適合放在哪些對應節點。為了針對性地進行判斷,本節提出一個問題:“在該節點運行服務調度器會對調度性能產生什么影響?”。而為了解決上述問題,提出了影響因子effect(n,f)這一概念進行判斷。
當影響因子effect(n0,f)>0時,代表預測性能比當前性能要好,調度器的放置提升了服務調度性能,則對應算法第7、8行所示,保留對應節點上的負載調度器,并把這一信息加入到集合當中;當影響因子effect(n0,f)<0時,則正好相反,降低了性能,此時對應算法第9、10行,刪除對應節點的負載調度器,并把該信息加入集合當中。最后,算法通過式(1)~(11)得到的信息,在算法第13行返回優化后的動態權重和響應時間。
4 算法仿真和分析
為了驗證第3章中提出的算法,本文要對其進行全面的評估。考慮到使用小規模的邊緣計算集群部署Serverless平臺無法模擬邊緣計算節點地理部分的特征,實驗說服力不夠強;另一方面,搭建實際的Serverless邊緣計算網絡以及大規模部署集群極其復雜且成本高。因此,本章使用仿真平臺來模擬大規模的Serverless邊緣計算環境。實驗選取了維也納工業大學分布式系統研究組開發的FaaS-Sim平臺[17]來進行仿真,框架如圖3所示。FaaS-Sim基于SimPy離散事件仿真框架,使用Ether作為網絡仿真層,并創建集群配置和網絡拓撲。
相對于其他仿真平臺,FaaS-Sim能夠模擬類似Serverless框架OpenFaaS提供的功能[18],其包含容器、容器鏡像、資源需求、縮放和調度的概念。FaaS-Sim還支持模擬大量不同類型的邊緣計算設備和通過Ether更靈活地創建不同的邊緣網絡拓撲。默認情況下,FaaS-Sim通過Skippy調度器進行資源調度,用戶可通過自定義方式替換負載調度和容器縮放策略來驗證本文方案。
4.1 實驗環境
在采用FaaS-Sim平臺之后,使用該平臺模擬了四種不同類型的邊緣計算設備:
a)單片機節點:包含一些基于ARM架構的低功耗邊緣接入點,如Raspberry Pi等,這些設備在IoT場景中充當邊緣網關。
b)小型計算節點:包含了較低功耗的小型計算機,如Intel平臺的下一代計算單元(next unit of computing,NUC)等。
c)嵌入式AI節點:包含一些具有嵌入式GPU的小型設備,如NVIDIA的Jetson系列設備。
d)邊緣數據中心:包含一些通用的VM設備,可以理解為邊緣網絡的數據中心,稱為Cloudlet。
本文所用的模擬設備的詳細描述如表1所示。
4.2 網格搜索實驗
在開始算法對比前,本文要對3.1節中計算的動態權重給定其中的縮放因子和權重范圍的參數,因為這些參數會影響平均響應時間與調度權重之間的映射關系,最后又反作用于平均響應時間。下面通過網格搜索實驗,嘗試大量排列組合方法來確定其行為模式。在本次網格搜索實驗中,使用Mobilenet-Inference函數作為請求的服務,針對縮放因子s和權重范圍進行網格搜索。在參數設定上,本文把縮放因子s設置為[0.1,10],權重設置為[1,100],對于權重范圍,設置最小權重為1,最大權重在[2,100]變化以全面分析權重的影響。
本次分別進行了三組網格實驗,請求負載依次設置為:50 rps、250 rps、500 rps。對于每組實驗,都按照不同的縮放因子與權重范圍組合進行200次實驗,每次實驗持續600 s以收集盡可能多的服務響應時間樣本。最終,通過統計服務平均響應時間(ART)作為結果來評估縮放因子和權重范圍對服務響應時間性能的影響。最終結果如圖4所示,從整體上看,隨著請求負載的變大,圖中深色區域占比不斷增大,也就是說,整體服務平均響應時間隨著請求負載的變大而逐漸變大。在縮放因子與權重范圍過大或過小時,服務平均響應時間明顯增大。而當縮放因子f在[1.0,4.0]內,權重在[10,30]內時,服務平均響應時間相對較小。在不同請求負載下,服務平均響應時間雖然存在較大差異,但在權重范圍為 20 左右,縮放因子s在[1.0,3.0]內時,整體平均響應時間均達到了較優值。這表明在此范圍內,服務平均響應時間能夠合理地映射成相應的動態權重,從而使得調度器能夠作出更準確的調度行為。
綜合實驗結果,本文選擇Wmin=10,Wmax=30,以及縮放因子s=2.0作為最終的實驗參數設置,這些參數能夠使得在不同請求負載下的服務平均響應時間盡可能小。并且,這些結論在實際無服務器邊緣計算應用中優化縮放因子和權重范圍,從而對于提高服務性能提供了重要的參考。
4.3 算法對比測試
4.3.1 仿真場景和函數設定
為了更全面地對算法進行評估,本次實驗考慮了兩種地理分布范圍不同的智慧城市場景,每個場景具體設定如下所示。
a)單個城市場景。邊緣計算集群由3個邊緣計算中心和9個共享鏈路帶寬的分布式計算單元組成,總計150個邊緣計算節點,假設所有節點位于城市A中,這意味著網絡鏈路間延遲較小,平均延遲為5 ms。
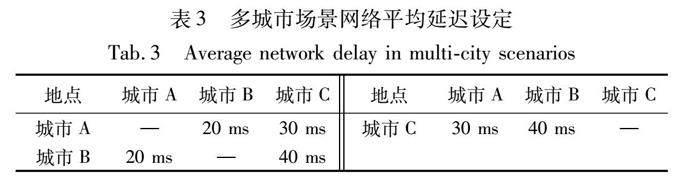
b)多個城市場景。邊緣計算集群跨越了三個城市A、B、C。每個城市之間的節點數量各不相同,計算能力有著差異。計算集群位于同一城市間的節點網絡延遲較低,但跨城節點之間的網絡延遲較高。客戶端提交的數據會讓本地節點優先處理,當本地節點性能不足或網絡阻塞時,向其他城市節點提交請求任務,不同城市的具體設定如表2和3所示。
接下來是對本次實驗部署的四種不同函數進行說明,在仿真集群中部署了四種函數:Resnet50-Inference[18]、Mobilenet-Inference[18]、Speech-Inference[18]、FFmpeg-Convert[19]。前三種函數函數對應典型的邊緣AI推理服務,是實現邊緣智能的基石,FFmpeg-Convert是實現音視頻數據處理的前提,在邊緣視覺中較常見,各個函數具體描述如表4所示。
4.3.2 對比算法和對比指標選擇
本節對SLSA的性能進行了對比實驗,用響應時間和資源消耗來進行表示,一共對比了五種調度算法,分別設置在不同的請求負載情況下進行實驗。實驗把請求負載設置為20 rps,30 rps,40 rps,50 rps,60 rps,并選擇三種時間對比指標來進行分析。同時,實驗測量了不同的負載調度策略在系統中運行時其產生的資源使用情況,來對比不同算法的資源消耗。由于實驗在模擬功能時會具有隨機采樣特征,本文對比實驗運行10次,取其平均值得出相對穩定的結果。
在調度算法的選擇上,本文為了探究不同復雜度的負載平衡和負載調度器放置是否會帶來總體性能的提高,選用了開源無服務器框架OpenFaas中采用的集中式輪詢調度算法(round robin centralized,RRC)和較常見的集中式最小響應時間調度算法(least response time centralized,LRTC),以及對應的分布式輪詢調度算法(round robin on all nodes,RRA)和分布式最小響應時間調度算法(least response time on all nodes,LRTA)。RRC和LRTC算法把所有客戶端請求設置在單個集中式負載均衡器實例中,對性能要求比較高,區別是前者以循環的方式依次將請求調度不同的服務器,而后者是優先把任務調度給平均響應時間最短的服務器。RRA和LRTA算法則是相對應的分布式算法,在分布式場景中每個節點都托管了一個負載均衡器,對性能要求更低,區別是前者以循環的方式依次將節點上的任務調度給其對應的服務器,后者優先執行平均響應時間最短節點的負載均衡器。為了進一步驗證SLSA的有效性,實驗還需要和最新的調度算法進行性能對比。本文選擇了雙層動態規劃(DLDP)算法[20]進行對比, DLDP算法采用多階段漸進優化的方法,解決了考慮依賴包的函數卸載問題,且通過分階段優化的方法將緩存策略嵌入到調度算法中,實現聯合優化。
在結果對比指標上,實驗選取了資源消耗(resource consumption,RC)指標對算法資源使用情況進行驗證,選取了平均響應時間(average response time,ART)、平均調度時間(average scheduling time,AST)、平均函數執行時間(average function time,AFT)三個指標來對算法性能進行驗證。RC是調度策略在系統運行時產生的內存消耗情況,用來反映整體的資源消耗情況。ART是服務負載請求的整體平均響應時間,其包含了網絡開銷、調度開銷和節點函數執行時間。AST是請求調度花費的時間,其包含了請求從客戶端到負載調度器以及負載調度器將請求調度至節點所花費的網絡時間和調度決策時間。AFT是函數在節點上執行花費的平均時間,反映函數執行所產生的性能影響。
實驗首先測試了不同算法的資源消耗情況,RC指標通過Telemd[21]進行測量。由于負載調度器是容器化的,所以Telemd依賴于Kubernetes提供的指標來測量資源消耗, Telemd每隔一段時間報告文件提供的內存消耗[21]。實驗把請求速率設置為250 rps,測試時間設置為0~250 ms,把負載調度器定位在一個模擬的邊緣應用程序上,客戶端發送一張圖像對其進行分類,有效負載是一個文件大小為250 KB的壓縮圖像,響應是一個大小可以忽略不計的簡單JSON,通過讀取Telemd返回指標,得到圖5所示的五種調度算法的RC指標對比。從圖5中可以明顯看出,隨著時間的推移,RRC、 RRA和LRTC算法對資源消耗的程度較高,LRTA、DLDP和SLSA算法相對較低。在對比算法中,SLSA調度算法對資源的使用情況最低,相比于其他調度算法,其在資源消耗上有著明顯改善,特別是對于RRC和RRA,SLSA的資源消耗降低程度超過了15%。由此可以看出,SLSA相比于其他算法的資源消耗情況是有所改善的。
不同服務負載調度實驗性能測試的結果如圖6、7所示,分別展示了在兩個不同場景下不同調度算法的性能對比。
根據圖6(a)~(c)中不同指標的對比,可以得出以下結論。從ART和AFT指標來看,對圖6(a)(c)進行分析,在單城市場景下,除了RRA調度算法相比于RRC算法的ART指標性能有所下降,其余調度算法均比RRC算法性能有所提升,在提升范圍里,SLSA對ART和AFT兩個指標的整體性能提升水平是最高的。此外,在請求負載為20 rps的情況下,LRTA調度算法的ART和AFT指標相較于SLSA性能更高,但差異并不明顯;在請求負載為30 rps以及更高情況下,SLSA的ART和AFT指標性能更高,且隨著請求負載的加大,性能提升更多。由此可以發現,在請求負載較低時,LRTA采用的分布式最小響應時間策略取得的性能指標會更高,但是隨著請求負載的增大,因為其采用貪心的思想容易導致羊群效應,把大量的請求調度到同一個節點執行,使函數執行時間更長。所以,總體來說,SLSA在ART和AFT指標上具有更好的性能表現。
從AST指標來看,對圖6(b)進行分析,在單個城市場景下, SLSA相比于RRC和RRA的AST指標性能具有明顯提升。在低負載請求速率20 rps情況下,SLSA性能不如LRTC和LRTA性能;在負載請求速率30 rps及以上情況,SLSA性能超過LRTA,但是不如LRTC的性能。
對單城市場景做完分析后,實驗還對多城市場景下的不同算法進行了對比,以驗證SLSA在更大地理范圍的環境下還存在其性能優勢。圖7(a)~(c)對比了在多城市場景下不同調度算法的性能對比。
如圖7所示,多城市場景下,三個指標的變化規律和單城市場景類似。從ART和AFT指標來看,SLSA相比于其他算法的性能提升率比單城市場景下更大。從AST指標來看,當負載請求速率為20 rps,SLSA的性能不如LRTA和LRTC算法,但是差距很小;在負載請求速率為30 rps及以上時,SLSA在AST指標性能上優于LRTA和LRTC算法。通過以上分析,對于三種指標性能,隨著地理分布和負載請求速率的增大,SLSA對比于其他算法的優勢會更明顯。
在比較完不同復雜度的負載平衡策略之后,本文對SLSA和最新的調度算法DLDP進行比較。SLSA和DLDP都適用于分布范圍更大的場景,而AST的指標比較小,不足以體現兩者算法的區別,因此本文在多城市場景下對兩個算法的ART和AFT指標進行了對比,如圖8所示。從ART和AFT指標來看,在20 rps和30 rps的情況下,SLSA性能不如DLDP算法,但隨著請求速率的提升,SLSA的性能逐漸超過DLDP算法。由此可以發現,在低請求速率情況下,DLDP算法的性能相對更高,而隨著請求速率的增大,SLSA的優勢逐漸得到體現。從總體來看,SLSA的性能超過DLDP算法。
為了更直觀地體現SLSA對比于其他算法的優勢,表5和6對實驗中得到的性能指標取平均值,把RRC算法作為基準,用百分比來表示其余算法相比于RRC算法在ART、AST、AFT三個指標性能上的提升情況。
從表5和6中可以得到,對于不同場景的ART指標,SLSA對比RRC算法提升的性能是最高的,在單個城市場景中相對于RRC算法提升了43.01%,在多城市場景中提升了53.81%。對于AST指標,在單個城市場景中,SLSA提升率為42.07%,性能提升率不如LRTA的45.78%,但隨著地理分布范圍的增大,可以發現SLSA性能提升率變為59.75%,超過了LRTA。從AFT指標來看,調度策略性能提升類似于ART指標,無論在單個城市場景還是多城市場景,SLSA性能提升百分比都是最大的。在單個城市場景中,SLSA性能提升率為43.25%,而在多城市場景中提升到了53.82%,SLSA性能對比其他算法有著明顯提升。
綜上所述,SLSA在ART和AFT指標性能的提升上均優于其他調度算法,在AST指標上,雖然在單個城市場景中不如LRTA和DLDP算法,但差異并不大,且隨著地理范圍的增加,AST指標性能提升也實現了反超,隨著地理分布范圍的增加,SLSA性能提升的優勢會更加明顯。
5 結束語
本文針對當前無服務器計算架構不具備在邊緣場景中高效處理請求所需服務負載調度機制的問題,提出了SLSA來解決直接采用云計算中輪詢調度策略而引起的函數執行時延放大問題,SLSA首先把工作過程中的服務負載調度響應時間看成黑盒,然后基于負載調度器來觀察每個節點對應的平均歷史響應時間,接著推導出對應動態變化的節點權重,基于得到的動態節點權重對SWRR調度算法進行改進,同時判斷在節點處放置負載調度器的有效性,最后進行一個最優化調度。經仿真實驗分析,在資源消耗方面,提出的SLSA相比于其他算法在資源消耗上有著明顯降低;在性能對比方面,SLSA在兩個不同場景下都有良好的性能表現,且隨著地理位置分布和負載調度速率的增大,SLSA對比于其他調度算法的優勢更明顯。在后續的研究中,將會對本文算法作進一步優化,針對不同請求可能具有不同的服務質量(QoS)級別,來優化不同QoS級別的請求響應時間。
參考文獻:
[1]Al-Doghman F, Moustafa N, Khalil I, et al. AI-enabled secure microservices in edge computing: opportunities and challenges[J]. IEEE Trans on Services Computing, 2022,16(2):1485-1504.
[2]Tang Qinqin, Xie Renchao, Yu F R,et al. Decentralized computation offloading in IoT fog computing system with energy harvesting: a Dec-POMDP approach[J]. IEEE Internet of Things Journal, 2020,7(6): 4898-4911.
[3]Jonas E, Schleier-Smith J, Sreekanti V, et al. Cloud programming simplified: a Berkeley view on Serverless computing[EB/OL]. (2019). https://arxiv.org/abs/1902. 03383.
[4]Li Yongkang, Lin Yanying, Wang Yang, et al. Serverless computing: state-of-the-art, challenges and opportunities[J]. IEEE Trans on Services Computing, 2022,16(2): 1522-1539.
[5]馬澤華, 劉波, 林偉偉, 等. 無服務器平臺資源調度綜述[J]. 計算機科學, 2021,48(4): 261-267. (Ma Zehua, Liu Bo, Lin Weiwei, et al. Survey of resource scheduling for Serverless platforms[J]. Computer Science, 2021,48(4): 261-267.)
[6]Xie Renchao, Tang Qinqin, Qiao Shi, et al. When serverless computing meets edge computing: architecture, challenges, and open issues[J]. IEEE Wireless Communications, 2021,28(5): 126-133.
[7]Cassel G A S, Rodrigues V F, Da Rosa Righi R, et al. Serverless computing for Internet of Things: a systematic literature review[J]. Future Generation Computer Systems, 2022,128: 299-316.
[8]Rausch T, Rashed A, Dustdar S. Optimized container scheduling for data-intensive Serverless edge computing[J]. Future Generation Computer Systems, 2021,114: 259-271.
[9]Cicconetti C, Conti M, Passarella A, et al. Toward distributed computing environments with Serverless solutions in edge systems[J]. IEEE Communications Magazine, 2020,58(3): 40-46.
[10]Zhao Zichao, Zhao Rui, Xia Junjuan, et al. A novel framework of three-hierarchical offloading optimization for MEC in industrial IoT networks[J]. IEEE Trans on Industrial Informatics, 2019,16(8): 5424-5434.
[11]Xie Renchao, Gu Dier, Tang Qinqin, et al. Workflow scheduling in Serverless edge computing for the industrial Internet of Things: a learning approach[J]. IEEE Trans on Industrial Informatics, 2023,19(7):8242-8252.
[12]Suresh A, Somashekar G, Varadarajan A, et al. Ensure: efficient scheduling and autonomous resource management in Serverless environments[C]//Proc of IEEE International Conference on Autonomic Computing and Self-Organizing Systems. Piscataway,NJ:IEEE Press, 2020: 1-10.
[13]Ellis A. OpenFaaS-serverless functions made simple[EB/OL]. (2021)[2023-06-10]. https://docs.openfaas.com/.
[14]Dounin M. Nginx[EB/OL]. (2023)[2023-08-07]. https://github.com/nginx/nginx.
[15]Gao Chenhao, Wu Hengyang. An improved dynamic smooth weighted round-robin load-balancing algorithm[J]. Journal of Physics: Conference Series, 2022,2404(1): 012047.
[16]Aumala G, Boza E, Ortiz-Avilés L, et al. Beyond load balancing: package-aware scheduling for Serverless platforms[C]//Proc of the 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. Piscataway,NJ:IEEE Press, 2019: 282-291.
[17]Rausch T, Lachner C, Frangoudis P A, et al. Synthesizing plausible infrastructure configurations for evaluating edge computing systems[C]//Proc of the 3rd USENIX Workshop on Hot Topics in Edge Computing. 2020.
[18]Hannun A, Case C, Casper J, et al. Deep speech: scaling up end-to-end speech recognition[EB/OL]. (2014).https://arxiv.org/abs/1412.5567.
[19]Ellison R. Go-Ffmpeg[EB/OL]. (2021)[2023-06-10]. https://github. com/rodellison/go-ffmpeg.
[20]Zheng Senjiong, Liu Bo, Lin Weiwei, et al. A package-aware sche-duling strategy for edge Serverless functions based on multi-stage optimization[J]. Future Generation Computer Systems, 2023,144: 105-116.
[21]Raith P. Telemd[EB/OL]. (2022)[2023-06-10]. https://github. com/edgerun/telemd.
