面向小型邊緣計算的深度可分離神經網絡模型與硬件加速器設計
2024-05-24 13:18:39孟群康李強趙峰莊莉王秋琳陳鍇羅軍常勝
計算機應用研究 2024年3期
孟群康 李強 趙峰 莊莉 王秋琳 陳鍇 羅軍 常勝


摘 要:
神經網絡參數量和運算量的擴大,使得在資源有限的硬件平臺上流水線部署神經網絡變得更加困難。基于此,提出了一種解決深度學習模型在小型邊緣計算平臺上部署困難的方法。該方法基于應用于自定義數據集的深度可分離網絡模型,在軟件端使用遷移學習、敏感度分析和剪枝量化的步驟進行模型壓縮,在硬件端分析并設計了適用于有限資源FPGA的流水線硬件加速器。實驗結果表明,經過軟件端的網絡壓縮優化,這種量化部署模型具有94.60%的高準確率,16.64 M的較低的單次推理定點數運算量和0.079 M的參數量。此外,經過硬件資源優化后,在國產FPGA開發板上進行流水線部署,推理幀率達到了366 FPS,計算能效為8.57 GOPS/W。這一研究提供了一種在小型邊緣計算平臺上高性能部署深度學習模型的解決方案。
關鍵詞:邊緣計算;深度可分離卷積;流水線部署;硬件加速器;FPGA
中圖分類號:TP391.7?? 文獻標志碼:A??? 文章編號:1001-3695(2024)03-032-0861-05doi: 10.19734/j.issn.1001-3695.2023.07.0335
Design of depthwise separable neural network models and
hardware accelerator for small-scale edge computing
Meng Qunkang1, Li Qiang2, Zhao Feng2, Zhuang Li3, Wang Qiulin3, Chen Kai3, Luo Jun4, Chang Sheng1
(1.School of Physics and Technology, Wuhan University, Wuhan 430072, China; 2.State Grid Information & Telecommunication Co., Ltd., Beijing 102211, China; 3.Fujian Yirong Information Technology Co., Ltd., Fuzhou 350003, China; 4.Institute of Electronic Fifth Research Dept., Ministry of Industry and Information Technology, Guangzhou 510507, China)
Abstract:
The parameter and computational requirements of neural networks have increased, making it increasingly difficult to deploy neural networks on hardware platforms with limited resources. This paper proposed a method to address the challenge of deploying deep learning models on small edge computing platforms. The method utilized a depthwise separable network model applied to a custom dataset. This method carried out model compression on the software end by employing steps as transfer learning, sensitivity analysis, and pruning quantization. On the hardware end, it analyzed and designed a pipeline hardware accelerator suitable for FPGA with limited resources. Experimental results demonstrate that after software-based network compression optimization, this quantized deployment model achieves a high accuracy rate of 94.60%, with a lower single-inference fixed-point operation count of 16.64 M and a parameter count of 0.079 M. Furthermore, after hardware resource optimization, the pipeline deployment on a domestic FPGA development board achieved an inference frame rate of 366 FPS and a computational efficiency of 8.57 GOPS/W. This research provides a solution for high-performance deployment of deep learning models on small-scale edge computing platforms. Key words:edge computing; depthwise separable convolution; pipelined deployment; hardware accelerator; FPGA
0 引言
隨著人工智能技術的發展,深度學習算法在圖像識別[1]、目標檢測[2]、自然語言處理[3]等領域取得了巨大的進展,但這種進展需要龐大、功耗高、性能高的計算機硬件支持[4],即使是可重構的FPGA,也日益難以支持規模逐漸變大的神經網絡參數量和計算量[5,6],這也限制了模型實際應用的落地,例如Anastasios等人[7]分析了邊緣IoT(Internet of Things,物聯網)設備部署神經網絡在內存和算力方面的困難。目前關于神經網絡的邊緣部署的研究,主要分為圖形處理器(graphics processing unit,GPU)、中央處理器(central processing unit,CPU)/微控制單元(microcontroller unit,MCU)和現場可編程邏輯門陣列(field programmable gate array,FPGA)等方向[8]。其中,GPU具有最強的運算能力,但由于其高功耗的特點,在許多功耗敏感領域的使用受到限制[9]。CPU/MCU雖然具有較高的邏輯處理能力,但其在神經網絡的應用中效率較低。相比之下,FPGA具有可重構的特點[10],設計較為靈活,越來越受邊緣計算應用需求的青睞,例如Ferdian等人[11]的研究列舉了大量FPGA應用于邊緣IoT設備的實例。但是基于FPGA平臺設計的高并行度流水線AI加速器,通常需要消耗大量的資源且功耗較高[12],超出大多數小型FPGA平臺的承受能力。例如,Xiao等人[13]為了將MobileNet-V1的每一層均部署在FPGA上且達到55.6的識別幀率,采用了數字信號處理器(digital signal processor,DSP)數量大于600的FPGA開發板,且最終功耗超過8 W;Xie等人[14]為了使用較低資源的FPGA運行MobileNet-v2網絡,計算單元較少,僅達到16推理幀率的情況下功率為2.74 W,運算能效不高。目標檢測任務方面,文獻[15]在較高資源的ZU3EG的FPGA開發板上僅能全流水部署較小的YOLOv3-Tiny網絡,也充分說明了邊緣設備應用先進深度學習算法的困難。
為了緩解上述困難,本文完成的主要工作是應用遷移學習、敏感度分析、剪枝量化和特征圖尺寸壓縮等方法,設計一套在自定義數據集上效果良好的輕量級深度可分離神經網絡,并且在此基礎上,設計出基于國產小資源FPGA的流水線網絡加速模塊,最后配合不同的輸入輸出模塊完成了推理結果疊加圖片的顯示功能。
為了克服神經網絡的流水線展開消耗的FPGA資源過高的困難,本文的主要貢獻有:
a)提出了一種基于自定義數據集的,應用遷移學習、敏感度分析、剪枝量化和特征圖尺寸壓縮等模型優化算法的、面向有限資源FPGA的深度可分離網絡模型。
b)進行了深度可分離卷積(depthwise separable convolution,DSC)硬件加速器中所消耗的緩存資源的設計空間探索,在硬件平臺的算力和資源方面取得平衡。
c)在國產小資源FPGA開發板上對自定義DSC加速模塊進行運行測試,在達到366 FPS的推理運行速度的性能下,功率僅為0.71 W,達到8.57 GOPS/W的高能效比。
1 深度可分離網絡設計優化與硬件加速器設計
1.1 硬件友好的深度可分離卷積
深度可分離卷積的思路最早由Google團隊的Howard等人[16]提出。其思想是將標準卷積操作分為深度卷積和逐點卷積。具體來說,深度可分離卷積使得每個輸入通道先單獨卷積,然后再在輸出通道之間使用1×1逐點卷積,實現通道信息的融合,如圖1所示。深度可分離卷積的優勢主要體現在不顯著降低分類精度的同時顯著降低參數量和運算量,減小模型規模,減輕過擬合風險。相比于在云端運行的計算密集型網絡,深度可分離卷積非常適合邊緣側硬件平臺部署,目前被廣泛應用于卷積神經網絡中,例如MobileNet、Xception等模型,并取得了良好的效果。本文主要應用深度可分離網絡的思想設計和優化網絡結構,在保證精確度的情況下提高硬件適配度和性能。
1.2 DSC硬件加速器緩存資源設計空間探索
與在資源和內存豐富的云端和邊端部署神經網絡不同,在面向小型邊緣計算平臺的時候,運算資源和功耗成為了更加重要的考慮因素。DSC硬件加速器緩存資源設計空間探索的目的就是在有限資源的FPGA平臺上實現算力、資源和存儲的平衡,以達到最佳的性能和效率。
通過對FPGA硬件資源的分析和對深度可分離卷積模塊的參數建模,可以得出硬件對于不同通道數/層數網絡的支持能力。與一般的卷積神經網絡對于并行度的支持相對自由不同,深度可分離卷積網絡由于其交替進行深度可分離卷積DW(depthwise convolution)和點卷積PW(pointwise convolution)的特點,硬件如果無法對PW的全部卷積核作全并行處理的話,就需要數據等待,利用流水線寄存器進行數據重排,才能保證下一卷積層相同位置的數據及時計算完畢。
1.2.1 數據重排的硬件端實現
由于深度可分離卷積神經網絡的深度可分離卷積層各層時間數據相互獨立,在計算上一層的點卷積的時不必等待其他通道的完成即可把數據送出給到深度分離卷積,所以可以在硬件流水線中按照“點卷積-深度分離卷積“的結構構建層流水,能夠節約一半的層間緩存寄存器。圖中給出一般的情況,即通道并行沒有完全充滿的情況下,深度分離卷積到點卷積的計算需要數據重排器對數據重新組合。數據重排器可以理解為層間寄存器。其具體功能如圖2所示。
1.3.4 特征圖尺寸壓縮的軟硬件綜合評估
針對自定義數據集,較大的特征圖尺寸通常提供了過多的信息,而神經網絡推理只需要其中關鍵的部分。因此,對特征圖尺寸進行合理的壓縮,并不會明顯降低識別準確度,或者在接受一定準確度下降的情況下,能夠節省硬件資源。通常情況下,卷積運算是計算密集型的網絡層,因此特征圖尺寸對卷積神經網絡的計算資源使用并沒有太大影響。然而,由于卷積神經網絡在處理圖像序列輸入時需要進行緩存,特征圖尺寸主要會影響作為寄存器的查找表(LUT)和觸發器(FF)。而對于全連接層而言,特征圖尺寸的大小將極大地影響計算資源和存儲資源的利用情況。因此,通過壓縮特征圖尺寸,可以減輕全連接層的負擔,并減少整個圖像識別過程的端到端延遲。
在本文中,由于需要綜合考慮網絡的精度和資源消耗,可以通過軟件評估壓縮后的特征圖尺寸對網絡精度的影響,并使用EDA軟件評估壓縮后特征圖對全連接層資源的消耗情況。這樣可以在保證精度的同時,有效地利用計算和存儲資源。特征圖尺寸壓縮后的精度、延時和全連接層所消耗的硬件資源的情況在2.3節中示出。
1.4 DSC卷積加速器與流水線設計
一般流水線的計算設計按照“卷積-層寄存”的方式堆疊,但是深度可分離卷積的深度分離層各層之間數據沒有聯系,使得這種卷積計算可以減少一半的層緩存,具體設計如圖6所示。
2 實驗平臺部署與結果
2.1 初始模型的選取與遷移學習精度
本實驗的代碼環境為PyTorch 1.13,所采用的數據集分為預訓練階段的完整的、包含120萬張訓練集圖片和5萬張驗證集圖片的1 000分類ImageNet-ILSVRC2012數據集,和模型壓縮部署階段自定義的包含一共13 393張來自互聯網公開野生動物圖片的10分類數據集,該數據集的基本情況如圖7所示。
由于動物種類數量較多,所以本文主要關注圖7中標注的9類動物,其他野生動物和沒有任何野生動物出現的環境背景將同作為背景一類進行分類。較好的監督學習模型需要更大量的標注數據,如果直接使用學習能力很強的CNN在該小規模數據集上進行訓練,很容易就會陷入過擬合狀態,因此引入大數據集預訓練的思路。預訓練階段選取了采用深度可分離卷積的經典網絡MobileNet V1作為原始網絡,在ImageNet-ILSVRC2012數據集上訓練作為初始的卷積分類權重,如圖8所示。經過60個epochs的完整訓練之后,最終的ImageNet最佳測試集準確度為67.18%。自定義數據集上的遷移學習過程如圖4(b)所示,保留整個卷積部分的結構和參數不變,僅改變全連接層的輸出維度,再次做60個epochs的完整訓練之后,將整個網絡所有參數全部設置為可訓練,然后再降低學習率再次做20個epochs,最終在自定義10分類數據集上的精度為97.05%,這個精度也作為后期網絡結構調整的基準線。
2.2 敏感度分析與層剪枝精度
對于上述的網絡進行剪枝,然后再在整個數據集上微調訓練,得到的每一卷積層的敏感度,如圖9所示。
可以發現,對于淺層卷積神經網絡而言,大量的剪枝都不會造成分類精度明顯下降,而最初層卷積神經網絡也能承受較大的剪枝率。因此可以把最淺層的神經網絡層conv13和conv14層完全丟棄。接下來分別采用部分數據集微調訓練,減少微調訓練數據和使用非代表性樣本來進行微調,裁剪最不敏感網絡層以進一步減小模型的大小,適應不同場景的需求,分別得到圖9(b)~(e)的剪枝結果。最終采用的模型剪枝率和模型推理精度、卷積網絡層數、浮點運算量FLOPS、參數量和模型所占空間的大小如表2所示。
2.3 特征圖尺寸壓縮的軟硬件綜合評估結果
采用軟硬件對特征圖尺寸壓縮之后的網絡精度和全連接層所消耗的硬件資源的情況如圖10所示。由于采用不同的并行度所需要的全連接層數據產出和接收速度不同,LUT消耗量與并行度μ也有緊密聯系,所以在圖中畫出不同并行度μ下的資源消耗曲線。橫坐標的特征圖壓縮率越高,表明輸入特征圖的尺寸越小,優勢是能節約大量的全連接層運算和存儲資源(主要以LUT計),而劣勢是壓縮損失信息導致的精度下降越發明顯,因此需要在兩者之間取得平衡。本文的做法是根據能承受的最大全連接層資源量,選擇最高的精度和壓縮率,根據延遲速度的要求來選擇并行度μ。
2.4 量化訓練結果
采用靜態量化位INT8位寬整型數的策略,可以達到92.79%的精度,相較于浮點模型下降了2.58%,采用量化訓練策略得到的量化后的精度可以恢復到94.60%,相比于浮點模型僅下降了0.77%,如圖11所示。由于INT8量化所帶來的存儲器位寬消耗僅為float型浮點數的四分之一,所以在模型結構不變的情況下,模型參數量縮小為原先的25%,在剪枝量化后僅有83 KB的定點數參數量;配合軟硬件協同評估的特征圖尺寸壓縮,模型計算量縮小為16.64 MOPS。
2.5 FPGA部署資源消耗和運行結果
本文選用的開發板是國產Gowin GW2A FPGA,LUT邏輯資源為20 k,BRAM共828 KB,用作乘法器的DSP共48個。本文在邏輯和計算資源均受限的情況下,設計硬件結構能夠運行上述軟硬件綜合優化后的壓縮模型。
系統的整體結構如圖12所示,設計的DSC流水線模塊需要和其他外設控制模塊配合使用,其中MCU軟核主要作用是控制輸出參數。
整體上板運行結果如圖13所示,分別是系統整體結構圖、在USB串口輸出的檢測結果、通過HDMI顯示器和LCD屏幕顯示的輸出結果。
最終設計的整體性能情況與其他硬件加速器工作性能對比如表3所示,其中資源和功耗情況為EDA軟件Gowin FPGA Designer編譯得到,FPS數據為仿真和實際上板運行得到,算力和能耗比數據從上述已有的數據中推算出。
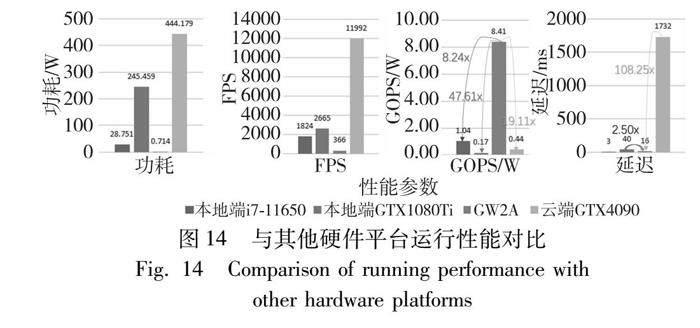
本文模型與其他硬件平臺的性能參數對比如圖14所示。將相同的神經網絡分別部署在本地的Intel的i7-1165的CPU平臺和NVIDIA的GTX1080Ti平臺上,以及云端GTX4090服務器上,可以實測得到其功耗和FPS速度等性能參數。經過對比可以發現,本文設計的硬件加速器在GOPS/W的能效上有明顯的優勢,相比于本地CPU和本地GPU平臺分別有8.24倍和47.61倍的提升,相比于云端GTX4090服務器有19.11倍的提升,充分發揮了邊緣計算平臺低功耗的優勢。另外,本研究在邊緣小型計算平臺上的延遲優勢相比云端計算平臺也很明顯,經過和云端測定的實際延遲進行對比發現,本地計算延遲不到云端計算延遲的1%,甚至低于高功耗高FPS的GPU平臺,充分發揮了邊緣計算的低延遲低功耗優勢。另外,邊緣小面積FPGA平臺相比于云端和邊端計算的巨大優勢,是一旦部署完成之后,無須上位機電腦和操作系統的支持,就可以完全獨立運行。
本文的硬件設計部分充分發揮了國產有限資源FPGA中的LUT和DSP,以及存儲所用的BRAM資源,系統總時鐘約束為54 Hz。而由于邊緣側FPGA整體芯片較小,因此總功耗僅0.71 W。與其他文獻對比,滿負載運行時,計算能效比較高,達8.57 GOPS/W、推理速度能夠達到較快的366 FPS。
3 結束語
本文的研究應用遷移學習、敏感度分析和剪枝量化方法等模型壓縮算法,設計出了一個在自定義數據集上表現優秀的輕量級深度可分離神經網絡,并將其設計為適用于資源有限的邊緣FPGA的流水線網絡加速模塊。本文的貢獻主要是提出了面向小型邊緣計算的輕量級深度可分離網絡模型,該模型在自定義數據集上表現良好;進行了DSC硬件加速器緩存空間設計空間探索,實現了算力和資源的平衡;最終該可部署模型在自定義數據集上準確率達到了94.60%,深度可分離卷積層降低到7層,單次推理定點數運算量僅為16.64 M,參數量僅為0.079 M。該網絡經過硬件資源優化后實現了在20 k LUT邏輯資源的國產FPGA開發板上的流水線部署,在54 MHz的時鐘約束下,推理幀率達到366 FPS,計算能效達到8.57 GOPS/W。這對于提高推理運行速度、降低功耗以及實現高能效比具有重要意義。此研究結果在邊緣計算以及較低資源FPGA領域具有實際應用價值和推廣潛力。
致謝 本文的神經網絡優化得到武漢大學超算中心的支持!
參考文獻:
[1]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 770-778.
[2]Wu Dong,Liao Manwen,Zhang Weitian,et al. YOLOP: you only look once for panoptic driving perception [J]. Machine Intelligence Research,2022,19(6): 550-562.
[3]Sangmin P,Sungho P,Harim J,et al. Scenario-mining for level 4 automated vehicle safety assessment from real accident situations in urban areas using a natural language process[J].Sensors,2021,21(20):6929.
[4]安勝彪,郭昱岐,白宇,等. 小樣本圖像分類研究綜述 [J]. 計算機科學與探索,2023,17(3): 511-532. (An Shengbiao,Guo Yuqi,Bai Yu,et al. Survey of few-shot image classification research [J]. Journal of Frontiers of Computer Science and Technology,2023,17(3): 511-532.)
[5]Kim J. Advanced AI hardware designs based on FPGAs [J]. Electronics,2021,10(20):2551.
[6]陳瑤,王永強,王遠飛,等. 降低實現神經網絡的FPGA硬件資源消耗的方法研究 [J]. 科學技術創新,2023 (13): 78-82. (Chen Yao,Wang Yongqiang,Wang Yuanfei,et al. Research on reduce FPGA for implementing neural networks [J]. Innovation Science and Technology,2023 (13): 78-82.)
[7]Anastasios F,Theofanis O,Konstantinos K,et al. Power efficient machine learning models deployment on edge IoT devices [J]. Sensors,2023,23(3):1595.
[8]Chang Liang,Li Chenglong,Zhang Zhaomin,et al. Energy-efficient computing-in-memory architecture for AI processor: device,circuit,architecture perspective [J]. Science China:Information Sciences,2021,64(6): 45-59.
[9]Ahuja P S,Czarnecki E,Willison S. Multi-factor performance compa-rison of Amazon Web services elastic compute cluster and Google Cloud platform compute engine [J]. International Journal of Cloud Applications and Computing,2020,10(3):1-16.
[10]Dong Yong,Hu Wei,Wang Yonghao,et al. Optimizing accelerator on FPGA for deep convolutional neural networks [C]// Proc of the 20th International Conference on Algorithms and Architectures for Parallel Processing. Berlin: Springer,2020: 97-110.
[11]Ferdian R,Aisuwarya R,Erlina T. Edge computing for Internet of Things based on FPGA [C]// Proc of International Conference on Information Technology Systems and Innovation. Piscataway,NJ: IEEE Press,2020: 20-23.
[12]Bai Lin,Zhao Yiming,Huang Xinming. A CNN accelerator on FPGA using depthwise separable convolution [J]. IEEE Trans on Circuits and Systems II: Express Briefs,2018,65(10):1415-1419.
[13]Xiao Chunhua,Xu Dandan,Qiu Shi,et al. FGPA: fine-grained pipelined acceleration for depthwise separable CNN in resource constraint scenarios [C]// Proc of the 19th IEEE International Symposium on Parallel and Distributed Processing with Applications. Piscataway,NJ: IEEE Press,2021: 246-254.
[14]Xie Xiaofei,Zhao Guodong,Wei Wei,et al. MobileNetV2 accelerator for power and speed balanced embedded applications [C]// Proc of the 2nd International Conference on Data Science and Computer Application. Piscataway,NJ: IEEE Press,2022: 134-139.
[15]江瑜,朱鐵柱,蔣青松,等. 基于FPGA的卷積神經網絡硬件加速器設計 [J]. 電子器件,2023,46(4): 973-977. (Jiang Yu,Zhu Tiezhu,Jiang Qingsong,et al. Design of a convolutional neural network hardware accelerator based on FPGA [J]. Chinese Journal of Electron Devices,2023,46(4): 973-977.)
[16]Howard A G,Zhu Menglong,Chen Bo,et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017-04-17) [2023-07-26]. https://doi. org/10. 48550/arXiv. 1704. 04861.
[17]Butt U,Ullah H,Letchmunan S,et al. Leveraging transfer learning for spatio-temporal human activity recognition from video sequences [J]. Computers,Materials & Continua,2022,74(3):5017-5033.
[18]Deepak G,Kilho L,Seong-heum K. Loss-aware automatic selection of structured pruning criteria for deep neural network acceleration [J]. Image and Vision Computing,2023,136: 104745.
