一種基于梯度的多智能體元深度強化學習算法
2024-06-01 01:53:41趙春宇賴俊陳希亮張人文
計算機應用研究 2024年5期
趙春宇 賴俊 陳希亮 張人文
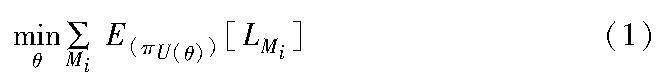


摘 要:多智能體系統在自動駕駛、智能物流、醫療協同等多個領域中廣泛應用,然而由于技術進步和系統需求的增加,這些系統面臨著規模龐大、復雜度高等挑戰,常出現訓練效率低和適應能力差等問題。為了解決這些問題,將基于梯度的元學習方法擴展到多智能體深度強化學習中,提出一種名為多智能體一階元近端策略優化(MAMPPO)方法,用于學習多智能體系統的初始模型參數,從而為提高多智能體深度強化學習的性能提供新的視角。該方法充分利用多智能體強化學習過程中的經驗數據,通過反復適應,找到在梯度下降方向上最敏感的參數并學習初始參數,使模型訓練從最佳起點開始,有效提高了聯合策略的決策效率,顯著加快了策略變化的速度,面對新情況的適應速度顯著加快。在星際爭霸Ⅱ上的實驗結果表明,MAMPPO方法顯著提高了訓練速度和適應能力,為后續提高多智能強化學習的訓練效率和適應能力提供了一種新的解決方法。
關鍵詞:元學習;深度強化學習;梯度下降;多智能體深度強化學習
中圖分類號:TP181?? 文獻標志碼:A??? 文章編號:1001-3695(2024)05-011-1356-06
doi: 10.19734/j.issn.1001-3695.2023.09.0411
Gradient-based multi-agent meta deep reinforcement learning algorithm
Abstract:Multi-agent systems have a wide range of applications in many fields, such as autonomous driving, intelligent logistics, and medical collaboration, etc. However, due to technological advances and increased system requirements, these systems face challenges such as large scale and high complexity, and often suffer from inefficient training and poor adaptability. To address these problems, this paper proposed a multi-agent first-order meta proximal policy optimization (MAMPPO) method by extending gradient-based meta-learning to multi-agent deep reinforcement learning. The method learned the initial model parameters in the multi-agent system to provide a new perspective for improving the performance of multi-agent deep reinforcement learning. It made full use of the previous experience in the process of multi-agent reinforcement learning to find the most sensitive parameters in the direction of gradient descent through repeated adaptation, and learned the initial parameters so that the model training starts from the optimal starting point. This method effectively improved the decision-making efficiency of the joint policy, and led to a significant increase in the speed of its policy change, which significantly accelerated the speed of adaptation in the face of a new situation. Experimental results on StarCraft Ⅱ show that the MAMPPO method can significantly improve the training speed and adaptability, which provides a new solution for the subsequent improvement of the training efficiency and adaptability of multi-agent reinforcement learning.
Key words:meta learning; deep reinforcement learning; gradient descent; multi-agent deep reinforcement learning
0 引言
在單智能體強化學習(single-agent deep reinforcement learning,SARL)中,智能體與環境相互作用并作出有效決策以最大化累積收益。隨著計算能力和存儲容量的顯著提高,任務的規模和復雜程度也進一步提高。為了有效解決一系列復雜問題,深度學習(deep learning, DL)和強化學習(reinforcement learning,RL) 成功結合產生了深度強化學習(deep reinforcement learning,DRL)。并展現了廣泛的應用前景,如掌握圍棋[1]、平流層氣球導航[2]、大規模戰略博弈[3]、機器人在挑戰性地形中的移動[4]、3D打印[5]等。例如,Open AI Five在Dota 2 中首次擊敗人類冠軍隊伍[6],并在模擬的捉迷藏物理環境中成功訓練出一個可以像人類一樣使用工具的智能體[7]。
為了解決多智能體系統(multi-agent system,MAS)下的復雜決策問題,在MAS中引入了DRL的思想和算法,提高多智能體深度強化學習(multi-agent deep reinforcement learning,MADRL)的性能和效率,MADRL具有較強的決策和協調能力,是解決大規模復雜任務的重要方法。
元學習通過積累先前經驗來快速適應新的任務,憑借“學習如何學習”的特性,在單智能體強化學習(SADRL)中得到了廣泛應用,有效避免了巨大數據量和高復雜度的樣本數據出現。基于梯度的元強化學習在學習過程中學習模型初始參數,使模型在每次學習任務時可以從一個最佳的起點開始,而不是像強化學習一樣從零出發,有效提高了訓練效率;因其初始參數是在訓練任務上反復適應經多次梯度下降所得,該參數在梯度方向上與目標參數接近,所以訓練好的模型在適應過程中僅需幾步梯度下降步驟就可以達到目標參數,縮短了大量的適應時間。然而與SADRL相比,MADRL具有更多的智能體,更高的網絡結構復雜性,并且在聯合狀態-行動空間中呈指數增長,這大大增加了探索的難度,致使其每次訓練都要處理巨大的計算量和高復雜度的樣本數據,延長了訓練和適應速度[8]。
為了提高訓練效率和適應能力,受單智能體元強化學習的啟發,將基于梯度的元學習方法擴展到MAS,提出了一種名為多智能體一階元近端策略優化(multi-agent first-order meta proximal policy optimization PPO, MAMPPO)的方法,旨在從有限的經驗中不斷學習和適應,該方法通過收集每個智能體與環境交互產生的經驗數據,并將其劃分為不同的任務數據塊,通過任務數據塊進行反復自適應和更新,充分利用先前經驗,學習最接近目標模型的起始參數作為模型的初始化參數。這使得模型在新情況下只需幾步的梯度下降就能達到目標,有效提高了MADRL的策略更新效率,面對新形勢的適應速度顯著加快。通過本文的研究和實驗證明了MAMPPO方法在提高MADRL的速度泛化方面的有效性和效果,為改善多智能體系統中的決策問題提供了一種新的方法,并為進一步應用MADRL技術提供了有益的啟示和指導。
1 相關工作
本文主要探討了一種將MADRL與元學習相結合的方法,涉及到元深度強化學習、MADRL的相關研究工作以及多種成功的組合成果,本章對元強化學習和MADRL的相關工作進行介紹,討論了各自領域中的重要研究成果和方法,并指出了它們在實踐中的優點和局限性。
元學習因其“學習如何學習”的特性而被廣泛應用于強化學習,通過利用先前任務中學到的經驗和知識,智能體能夠更快地適應新任務、更高效地利用數據、更準確地選擇參數更新方向,并更好地平衡探索與利用。元強化學習旨在通過學習適應性算法或策略,使智能體能夠從先前的經驗中快速適應新任務。與傳統的強化學習不同,元強化學習是一種學習輸出策略的強化學習算法,通過數據驅動的方式來開發學習所需的訓練環境和參數。
元強化學習假設存在相關任務的分布p(T),這對應于馬爾可夫決策過程(MDP)M={Mi}Ni=1的分布,其中可以參數化MDP的動態或獎勵。M由元組〈S,A,p,R,γ,ρ0,H〉定義,其中S為狀態空間,A為行動空間,p為轉移概率密度,R為獎勵函數,H為事件的時間范圍。元學習的目標是找到一組合適的參數集θ和配對更新方法U,使策略π在保持累積獎勵最大的情況下解決新情況。設L(Mi)為Mi的損失函數,則元學習的目標可以表示為
本文的工作主要涉及基于梯度的元強化學習方法,該方法學習初始化模型參數使之在新任務上僅需微調,從而使訓練好的模型能夠適應新任務。Finn等人[9]提出了一種名為無模型元學習(model-agnostic meta-learning,MAML)方法,通過在梯度下降過程中尋找對更新方向敏感的模型參數,從而學習到適當的初始模型參數,實現了深度網絡在快速適應任務上的能力增強;然而MAML方法在實際應用中仍面臨一些挑戰,如對任務表示的依賴性和計算復雜度有所增加。在MAML的基礎上,Xu等人[10]提出了一種名為無模型元學習的元權重學習方法,在訓練過程中對權重進行適應性更新,從而增強了神經網絡的性能和泛化能力;然而該方法仍然面臨一些挑戰,如合理選擇元學習率、網絡結構的適應性以及計算復雜度的增加等。類似于MAML,Nichol等人[11]提出了一種稱為一階元學習(Reptile)的方法,通過在每個任務的訓練后利用參數差異進行參數更新,從而實現了原始模型的快速適應,該方法在元學習的過程中避免了二階導數的計算;然而仍面臨一些挑戰,如如何選擇合適的學習率和對參數更新的限制等問題。Song等人[12]提出了一種名為ES-MAML的簡單、不使用Hessian矩陣的元學習方法,該方法通過應用進化策略(ES)[13]來解決MAML中估計二階導數的問題,在元學習過程中通過在目標函數中添加額外的探索項增加了探索的機會,以提供最大量的有用信息。為了選擇合適的探索策略并平衡探索與利用之間的關系,Stadie等人[14]在元強化學習中考慮了學習探索策略,通過將額外的探索項添加到目標函數中,提出了一種名為學習探索的元強化學習方法,旨在增加探索的機會,以提供更多有用信息的數據量。Xu等人[15]提出了一種名為元策略梯度學習探索的方法,通過使用元策略梯度優化探索策略,使智能體能夠學會探索未知環境,該方法旨在通過元學習的方式,提高智能體的探索能力。
在MAS中,Sunehag等人[16]提出了值分解網絡(value decomposition networks,VDN)多智能體強化學習算法,將全局Q值分解為局部Q值的加權和,并在聯合動作Q值中考慮各個智能體的行為特征,提高了多智能體系統的學習效果,但需要進一步平衡個體智能體的貢獻和團隊合作關系,以及如何處理高維狀態空間等問題。Rashid等人[17]提出了QMIX算法,通過將值函數分解為單調函數和非單調函數的組合,以提高多智能體系統的學習效果,解決了值函數的高方差和不穩定性;然而該方法仍面臨一些問題,如如何選擇合適的值函數分解形式和如何處理大規模多智能體系統的挑戰等。Foerster等人[18]提出反事實基線的多智能體策略梯度方法(counterfactual multi-agent policy gradients,COMA),通過引入對抗性訓練和對抗性評估來進行策略優化,使用反事實基線對不同主體的貢獻進行信用分配,從而提高多智能體系統的學習性能,解決了非平穩環境和非合作行為等問題,但在訓練的穩定性和計算復雜度等方面有所欠缺。Lowe等人[19]提出MADDPG(multi-agent deep deterministic policy gradient)算法,使用集中式訓練和去中心化執行機制,基于DDPG的每個智能體的全局Q值來更新本地策略,智能體能夠在協作和競爭之間進行平衡以達到更好的性能,但在如何處理大規模多智能體系統和如何處理合作與競爭之間的平衡等方面存在不足。MAPPO(multi-agent PPO)[20]采用基于近端策略優化(proximal policy optimization,PPO)[21]的集中函數來考慮全局信息,智能體之間通過全局值函數實現相互協作,在處理合作多智能體環境時表現出良好的性能和魯棒性,為解決合作問題提供了一種有效的方法。
元學習應用于MADRL中,從不同的角度解決了許多問題,如學習與誰溝通[22]、學習特定于智能體的獎勵函數以實現機制設計的自動化[23],但是目前的研究仍然較少。Charakorn等人[24]提出了一種通過元強化學習與未知智能體合作的方法,該方法使智能體能夠快速適應與未知智能體的合作任務,并取得良好的性能,但需要解決如何處理未知智能體的行為和如何在實際環境中應用該方法等問題。Feng等人[25]引入了神經自動課程(neural auto-curriculum,NAC),通過自適應調整游戲難度和規則,智能體能夠通過自我學習來改進策略和適應對手,該方法在零和博弈中取得了良好的效果,但仍面臨一些問題,即如何處理復雜博弈和如何擴展到更大規模的對抗環境等。為了解決多智能體環境下的非平穩問題,Foerster等人[26]提出了一種對手感知的學習方法(learning with opponent-lear-ning awareness,LOLA),通過考慮對手的策略和行為來指導智能體的學習過程,該方法能使智能體更好地適應對手的變化和策略調整,從而提高了在對抗環境中的學習性能。Kim等人[27]提出了一種多智能體強化學習中的元策略梯度算法,通過優化策略梯度來實現智能體的元學習,使得智能體能夠通過學習適應性策略來快速適應多智能體環境,并取得更好的性能。Al-Shedivat等人[28]基于單智能體MAML設計了一種基于梯度的多智能體元學習方法,用于自適應動態變化和對抗場景,有效提高了多智能體強化學習的訓練效率和適應速度。多智能體MAML在MAML算法架構中設計多智能體強化學習,且僅用兩個智能體之間的交互過程。與多智能體MAML算法不同,MAMPPO方法是在不改變多智能體強化學習架構的前提下引入元學習;與多智能體MAML算法類似,MAMPPO將基于梯度的一階元Reptile的思想用于多智能體環境中,以達到通過元學習提高多智能體強化學習算法性能的目的。
2 MAMPPO方法
本文提出的方法以MAPPO算法為基礎,引入基于梯度的一階元學習Reptile的思想,在學習過程中整合以往經驗所需的元知識,并將其保存為模型參數初始化的規則,實現使用有限經驗的持續學習和快速適應。
2.1 MAPPO算法
PPO是一種非常流行的RL算法,在各種單智能體任務場景中都有非常出色的表現。MAPPO是在MARL中應用的PPO的一種變體,采用集中訓練分散執行框架(centealized training and decentralized execution, CTDE)。MAPPO框架如圖1所示。
MAPPO算法的網絡由AC網絡支持,參數化的策略和值函數由兩套獨立的網絡進行計算,不同智能體各自擁有一套策略網絡并共享網絡參數。中心控制器由一套值函數網絡構成,全局值函數作為中心控制器,智能體將在全局狀態s下將局部觀察信息oi=O(s;i)傳遞給中心控制器,中心控制器根據全局狀態信息進行訓練,得到策略πθ,各智能體執行聯合動作分布A=(a1,a2,…,an)。待訓練完成后,智能體可以獨立于中心控制器,僅根據自己的局部觀察信息進行決策并執行最優動作。
為了使單智能體PPO算法適應多智能體的設置,局部觀察信息設定為學習策略πθ和基于全局狀態S的集中值函數V(s),并使用PopArt對V(s)進行歸一化處理,策略函數πθ和價值函數V(s)分別由行動者網絡(actor)和評論家網絡(critic)產生。具體來說,critic網絡將所有全局信息和一些特定于智能體的特征作為critic網絡的輸入,實現了從狀態S到獎勵R的映射;actor網絡將智能體的觀察信息映射到離散動作空間中的動作分布或者連續動作空間中的多元高斯分布的均值和標準差向量。另外在訓練過程中,將無法執行的動作概率設為零,使用帶有智能體特定標識的向量區分訓練過程中死亡的智能體,并將其作為critic網絡的輸入。actor網絡的訓練目標是使損失函數L(θ)最大化,critic網絡的訓練目標則是使損失函數L()最小化。假設有n個智能體,B為小批處理數
2.2 MAMPPO方法設計
MAMPPO將基于一階梯度的元學習思想應用到MARL設置中,提高MARL的泛化能力和訓練速度,實現從有限經驗中不斷學習和適應的能力。其關鍵在于學習過程中整合以往經驗所需的元知識,并將其保存為模型的初始參數,以實現有限經驗的持續學習和快速適應。圖2顯示了MAMPPO框架。
MAMPPO首先按照MAPPO訓練流程進行訓練,存儲交互過程中產生的數據元組并計算對應折扣累積獎勵和獎勵函數,將過程中產生的數據劃分為不同的任務數據塊(task data chunks)用于元更新。在元更新階段,通過在任務數據塊上反復采樣進行元學習,經過一定次數的梯度下降進行參數軟更新,完成對模型初始化參數的學習,實現在新任務上的快速微調。
最后更新后的網絡模型參數滿足梯度下降方向最敏感的要求,使模型在處理新任務時從最佳起點開始,有效提高了聯合策略的決策效率。
算法1 MAMPPO方法
3 實驗和結果討論
在SMAC實驗平臺上進行實驗,SMAC是研究CTDE算法的主流基準,具有連續的觀察空間和離散的動作空間,有各種各樣的地圖,具有很高的學習復雜性。每個智能體都是獨立的,組成一個小組與內置腳本AI競爭,適合在各種協作的多智能體情況下測試本文方法。在每場戰斗中,每個智能體都需要給對方造成最大化傷害,并將自身承受的傷害最小化。
本文選擇在一個簡單地圖(3 m)、兩個困難地圖(3s_vs_5z, 3s5z)和一個超難地圖(corridor)上評估了本文方法。表1介紹了地圖的特點,比較的方法有MAPPO、QMIX和VDN。其中,VDN算法將全局值函數分解為每個智能體的局部值函數的加權和,全局值函數考慮智能體個體行為的特性,使得該值函數更易于學習,能夠解決多智能體系統中的合作與競爭問題,并且可在一定程度上緩解多智能體系統中環境不穩定的問題。QMIX采用混合網絡模塊將各智能體的局部值函數組合為全局值函數,通過對全局值函數進行因子分解,將智能體的局部值函數與一個可學習的混合函數相結合,使得每個智能體可以獨立地選擇行動,且同時考慮其他智能體的行動和全局信息,從而提高了整體協作效果。下面分別對MAMPPO的訓練速度和適應性進行了評價。
在訓練實驗中對模型進行多步訓練,測量訓練速度。除地圖訓練2M時間步外,其余地圖訓練5M時間步。在元學習過程中,適應的數量被設置為15,元更新中的步長設置為0.05。首先對訓練過程中的勝率曲線圖進行分析。
a)在簡單地圖3m中的勝率曲線對比如圖4所示。可以看出,MAMPPO和MAPPO的勝率曲線遠高于QMIX和VDN算法,雖然MAMPPO和MAPPO在1M時間步之后的曲線大體一致,但MAMPPO訓練前期的勝率曲線斜率大于MAPPO且比其更早收斂,說明MAMPPO的訓練效率有所提升。
b)在困難地圖(3s_vs_5z和3s5z)中的勝率曲線對比如圖5所示。可以看出,MAMPPO訓練前期的勝率曲線增長速率和訓練結束所得的勝率明顯高于其他三種算法,并且能夠更快地收斂。在3s_vs_5z地圖中,作戰智能體為同構類型,共享一套網絡參數,MAMPPO的勝率在1M時間步后率先大于0,說明由MAMPPO訓練的我方作戰智能體比其他算法訓練的作戰智能體出現獲勝的場次更早。在3s5z地圖中,作戰智能體為異構類型,分別處理各自的網絡參數,在整個訓練過程中,MAMPPO的勝率曲線均高于其他三條曲線,說明經MAMPPO訓練的作戰智能體擁有更強的作戰能力。
c)在超難地圖corridor中的勝率曲線對比如圖6所示。可以看出,MAMPPO的勝率曲線整體高于QMIX和VDN對應勝率,且略高于MAPPO的勝率曲線,因為超難地圖中的敵方作戰智能體較多,需要處理的數據也對應增加,增加了元更新階段中反復適應的計算難度,訓練過程中會出現計算量代償的問題。
計算訓練步最后10次的平均勝率,結果如表2所示。從表中可以看出,MAMPPO方法在簡單地圖3m中的平均勝率高于QMIX和VDN算法,并且與MAPPO算法的對應勝率持平。在困難地圖(3s_vs_5z和3s5z)和超難地圖corridor中的平均勝率均高于參與比較的三種算法,具體勝率提升百分比為:MAMPPO方法在3m、3s_vs_5z、3s5z、corridor地圖中的勝率比MAPPO算法分別提高了0%、4.12%、16.93%、2.62%,比QMIX算法分別提高了28.55%、87.80%、39.58%、19.04%,比VDN算法分別提高了23.51%、514.66%、241.47%、342.48%。
因此在訓練階段,MAMPPO所學策略的改進速度明顯加快,訓練速度明顯提高,訓練所得的勝率高于其他方法,經過元學習訓練的作戰智能體的作戰能力高于其他多智能體算法訓練所得。
為了評估MAMPPO的適應能力,通過計算每次訓練迭代32場后測試的勝率來測試MAPPO和MAMPPO訓練的作戰智能體的作戰能力,并將最后10次測試所得勝率的中位數作為評估勝率,四種地圖的評估勝率如表3所示。由表可得,除了在簡單地圖中的勝率恒為100%之外,經過MAMPPO訓練的作戰智能體在其他三個地圖中取得的勝率均高于MAPPO訓練所得,具體勝率提升百分比為:MAMPPO方法在3s_vs_5z、3s5z、corridor地圖中的勝率比MAPPO算法在其上的勝率分別提高了37.02%、18.18%、11.73%。
因MAMPPO方法相較于MAPPO算法在困難地圖(3s_vs_5z和3s5z)中的性能表現提升明顯,在測試階段選擇這兩個地圖的測試勝率曲線對比如圖7所示。
MAMPPO方法在困難地圖(3s_vs_5z和3s5z)和超難地圖corridor的評估勝率均高于MAPPO算法,表現出色。另外,雖然在簡單地圖3m中的評估勝率均為100%,但是MAMPPO方法在6K步時獲得的作戰智能體勝率便可以達到100%,MAPPO算法則需要在1M步時獲得的作戰智能體勝率達到100%。由困難地圖(3s_vs_5z和3s5z)的評估勝率曲線可得,MAMPPO方法的勝率開始變化,時間步長早于MAPPO算法,說明MAMPPO方法訓練所得作戰智能體的適應能力強于MAPPO算法,更快地開始適應新的情況。相比于MAPPO算法,在相同時間步長的情況下,MAMPPO方法所得勝率高于MAPPO算法,說明模型適應性提升顯著,作戰智能體對訓練場新情況的處理能力明顯提升。MAMPPO方法在新任務情況下的評估勝率高于MAPPO算法,且適應速度顯著提高,表明MAMPPO方法的自適應能力在引入元學習后有所提高。
實驗結果表明,用MAMPPO方法訓練得到的作戰智能體在總體上取得了更優的性能,在訓練場中能夠更早更高效地探索出獲勝策略,在相同訓練時間步長情況下的訓練速度明顯提升,其訓練所得的適應性明顯增強,能夠處理在訓練場中出現的情況,表現了出良好的訓練效率和適應能力。
4 結束語
本文將元學習引入到MADRL中,提出了一種MAMPPO方法,從元學習的角度提升多智能體算法性能,為解決多智能體泛化能力問題提供了一個新的視角。將基于梯度的元強化學習擴展到多智能體強化學習,在智能體完成交互后構建任務數據塊,在模型參數更新階段定義元梯度,并執行多次梯度下降來學習網絡模型的初始參數。在SMAC環境下的實驗結果表明,該方法在各種場景下的性能都優于基線方法,有效地提高了多智能體系統的強化學習性能,縮短了訓練時間,進一步證實了將元學習引入多智能體強化學習的可行性。
然而在訓練多個智能體的過程中,每個智能體的感知轉移概率分布和獎勵函數都會發生變化。從每個智能體的角度來看,環境具有非平穩性。如何從每個智能體的角度使用元學習,同時考慮自身的學習過程和環境中其他智能體的學習,是未來需要解決的問題。
參考文獻:
[1]Silver D,Huang A,Maddison C J,et al. Mastering the game of Go with deep neural networks and tree search [J]. Nature,2016,529(7587): 484-489.
[2]Bellemare M G,Candido S,Castro P S,et al. Autonomous navigation of stratospheric balloons using reinforcement learning [J]. Nature,2020,588(7836): 77-82.
[3]Henderson P,Islam R,Bachman P,et al. Deep reinforcement learning that matters [C]// Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 3207-3214.
[4]Miki T,Lee J,Hwangbo J,et al. Learning robust perceptive locomotion for quadrupedal robots in the wild [J/OL]. Science Robotics,2022,7(62). https://arxiv.org/abs/2201.08117.
[5]Yang Jiongzhi,Harish S,Li C,et al. Deep reinforcement learning for multi-phase microstructure design [J]. Computers,Materials & Continua,2021,68(1): 1285-1302.
[6]Berner C,Brockman G,Chan B,et al. Dota 2 with large scale deep reinforcement learning [EB/OL]. (2019-12-13). https://arxiv.org/pdf/1912.06680.pdf.
[7]Baker B,Kanitscheider I,Markov T,et al. Emergent tool use from multi-agent autocurricula [EB/OL]. (2020-02-11). https://arxiv.org/pdf/1909.07528.pdf.
[8]Nguyen T T,Nguyen N D,Nahavandi S. Deep reinforcement learning for multiagent systems: a review of challenges,solutions,and applications [J]. IEEE Trans on Cybernetics,2020,50(9): 3826-3839.
[9]Finn C,Abbeel P,Levine S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proc of the 34th International Conference on Machine Learning. [S.l.]: PMLR,2017: 1126-1135.
[10]Xu Zhixiong,Chen Xiliang,Tang Wei,et al. Meta weight learning via model-agnostic meta-learning [J]. Neurocomputing,2021,432(4): 124-132.
[11]Nichol A,Achiam J,Schulman J. On first-order meta-learning algorithms [EB/OL]. (2018-10-22) [2023-09-19]. https://arxiv.org/pdf/1803.02999.pdf.
[12]Song Xingyou,Gao Wenbo,Yang Yuxiang,et al. ES-MAML: simple Hessian-free meta learning [EB/OL]. (2020-07-07)[2023-09-19]. https://arxiv.org/pdf/1910.01215.pdf.
[13]Wierstra D,Schaul T,Glasmachers T,et al. Natural evolution strategies [J]. Journal of Machine Learning Research,2014,15(1): 949-980.
[14]Stadie B C,Yang Ge,Houthooft R,et al. Some considerations on learning to explore via meta-reinforcement learning [EB/OL]. (2019-01-11)[2023-09-19].https://arxiv.org/pdf/1803.01118.pdf.
[15]Xu Tianbing,Liu Qiang,Zhao Liang,et al. Learning to explore with meta-policy gradient [C]// Proc of the 35th International Conference on Machine Learning. [S.l.]: PMLR,2018: 5463-5472.
[16]Sunehag P,Lever G,Gruslys A,et al. Value-decomposition networks for cooperative multiagent learning based on team reward [C]// Proc of the 17th International Conference on Autonomous Agents and Multi Agent Systems. 2018: 2085-2087.
[17]Rashid T,Samvelyan M,De Witt C S,et al. Monotonic value function factorisation for deep multi-agent reinforcement learning [J]. Journal of Machine Learning Research,2020,21(1): 7234-7284.
[18]Foerster J N,Farquhar G,Afouras T,et al. Counterfactual multi-agent policy gradients [C]// Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 2974-2982.
[19]Lowe R,Wu Yi,Tamar A,et al. Multi-agent actor-critic for mixed cooperative-competitive environments [C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2017: 6379-6393.
[20]Yu Chao,Velu A,Vinitsky E,et al. The surprising effectiveness of PPO in cooperative multi-agent games [C]// Proc of the 35th Neural Information Processing Systems. Cambridge,MA: MIT Press,2022: 24611-24624.
[21]Schulman J,Wolski F,Dhariwal P,et al. Proximal policy optimization algorithms [EB/OL]. (2017-08-28)[2023-09-19]. https://arxiv.org/pdf/1707.06347.pdf.
[22]Zhang Qi,Chen Dingyang. A meta-gradient approach to learning cooperative multi-agent communication topology [C]// Proc of the 5th Workshop on Meta-Learning at NeurIPS. [S.l.]: Artificial Intelligence Institute,2021.
[23]Yang Jiachen,Ethan W,Trivedi R,et al. Adaptive incentive design with multi-agent meta-gradient reinforcement learning [C]// Proc of the 21st International Conference on Autonomous Agents and Multiagent Systems. 2022: 1436-1445.
[24]Charakorn R,Manoonpong P,Dilokthanakul N. Learning to cooperate with unseen agents through meta-reinforcement learning [C]// Proc of the 20th International Conference on Autonomous Agents and Multi Agent Systems. Richland,SC: IFAAMAS,2021: 1478-1479.
[25]Feng Xidong,Slumbers O,Wan Ziyu,et al. Neural auto-curricula in two-player zero-sum games [J]. Neural Information Processing Systems,2021,34(1): 3504-3517.
[26]Foerster J,Chen R Y,Al-Shedivat M,et al. Learning with opponent-learning awarenesss [C]// Proc of the 17th International Conference on Autonomous Agents and Multi Agent Systems. 2018: 122-130.
[27]Kim D K,Liu Miao,Riemer M D,et al. A policy gradient algorithm for learning to learn in multiagent reinforcement learning [C]// Proc of the 38th International Conference on Machine Learning. [S.l.]: PMLR,2021: 5541-5550.
[28]Al-Shedivat M,Bansal T,Burda Y,et al. Continuous adaptation via meta-learning in nonstationary and competitive environments [EB/OL]. (2018-02-23)[2023-09-20]. https://arxiv.org/pdf/1710.03641.pdf.
