基于查詢語義特性的稠密文本檢索模型
2024-06-01 02:51:12趙鐵柱林倫凱楊秋鴻
計算機應用研究 2024年5期
趙鐵柱 林倫凱 楊秋鴻


摘 要:針對現有稠密文本檢索模型(dense passage retrieval,DPR)存在的負采樣效率低、易產生過擬合等問題,提出了一種基于查詢語義特性的稠密文本檢索模型(Q-DPR)。首先,針對模型的負采樣過程,提出了一種基于近鄰查詢的負采樣方法。該方法通過檢索近鄰查詢,快速地構建高質量的負相關樣本,以降低模型的訓練成本。其次,針對模型易產生過擬合的問題,提出了一種基于對比學習的查詢自監督方法。該方法通過建立查詢間的自監督對比損失,緩解模型對訓練標簽的過擬合,從而提升模型的檢索準確性。Q-DPR在面向開放領域問答的大型數據集MSMARCO上表現優異,取得了0.348的平均倒數排名以及0.975的召回率。實驗結果證明,該模型成功地降低了訓練的開銷,同時也提升了檢索的性能。
關鍵詞:查詢;稠密文本檢索;近鄰;對比學習;自監督
中圖分類號:TP391?? 文獻標志碼:A??? 文章編號:1001-3695(2024)05-016-1388-06
doi: 10.19734/j.issn.1001-3695.2023.09.0412
Dense passage retrieval model based on query semantic characteristics
Abstract:Addressing the issues of low negative sampling efficiency and tendency towards overfitting in existing dense passage retrieval (DPR) models, this paper proposed a DPR model based on query semantic characteristics(Q-DPR). Firstly, it introduced a negative sampling method based on neighbor queries for the negative sampling process. This method constructed high-quality negative samples rapidly by retrieving neighboring queries, thereby reducing the training costs. Secondly, to mitigate overfitting, it proposed a query self-supervised method based on contrastive learning. This method alleviated overfitting to training labels by establishing a self-supervised contrastive loss among queries, thereby enhancing retrieval accuracy. Q-DPR performed exceptionally well on the large-scale MSMARCO dataset for open-domain question answering, achieving a mean reciprocal rank of 0.348 and a recall rate of 0.975. Experimental results demonstrate that this model successfully reduces trai-ning overhead while also improving retrieval performance.
Key words:query; dense passage retrieval; neighbor; contrastive learning; self-supervised
0 引言
隨著計算機科學與人工智能的發展,智能問答系統已成為生產和生活中必不可少的工具,巨大應用潛力和極高的商業價值使其在學術界和工業界都備受關注。目前,主流的智能問答系統,例如微軟小冰、百度小度、蘋果Siri等,大多采用基于檢索的開放領域問答[1]。對于用戶提出的問題,系統首先使用文本檢索模型對知識庫中所有候選文本進行檢索,尋找與用戶問題最相關的文本。然后使用機器閱讀理解模型,在文本中抽取出能夠準確回答用戶問題的文本片段[2]。在這個過程中,文本檢索模型扮演著重要角色,若文本檢索模型無法準確檢索到包含問題答案的文本,則無法對用戶問題作出準確的回復。因此,文本檢索在開放領域問答中尤為關鍵,它也成為了限制開放領域問答性能的主要瓶頸[3]。由于檢索過程需要準確且高效地判斷大量文本是否與查詢相關,文本檢索已經成為自然語言處理領域中最具挑戰性的任務之一。
傳統的文本檢索方法,如TF-IDF[4]、BM25[5]等,通常采用基于統計的策略,通過統計查詢以及文本之間的詞頻信息以建立它們之間的關系。盡管這種方法在早期的檢索應用中表現優異,但它并未考慮隱含在詞匯中的語義信息[6],這導致在檢索的過程中,詞匯一致但語義完全不同的兩個文本可能被誤判為高度相關。為了解決這個問題,以BERT(bidirectional encoder representation transformers)[7]為代表的深度學習模型被引入到文本檢索領域。當前,基于深度學習的文本檢索模型主要分為交互檢索模型和稠密檢索模型[8]兩類。交互檢索模型通過對查詢和文本的詞語義表征進行交互,獲取豐富的交互信息以衡量它們的相似度。這種模型在檢索任務中表現出極高的準確性,但高度耦合的語義交互卻嚴重限制了檢索速度。稠密檢索模型則使用稠密向量表示查詢和文本,其在檢索的過程中只需使用簡單的向量計算模型,就能快速預測出它們之間的相關性[9]。這種模型通過舍棄高度耦合的語義交互以提高檢索速度,但同時也導致了檢索準確性下降。為了克服這個難題,許多模型試圖通過提高語義表征的廣度或深度信息以提升檢索的準確性[10]。提升語義表征的廣度,即增加語義表征的數量或維度,這種方法簡單且有效,但檢索的開銷也會隨之增加。因此,許多研究人員開始轉向提升語義表征的深度,即提升模型的語義表征能力,以獲得高質量的語義表征向量,從而提高模型的檢索準確性。
目前,許多研究人員正通過優化模型的負采樣(negative sampling)過程以及對比損失(contrastive losses)的構建方法以增強其語義表征能力。他們致力于讓模型在訓練過程中接觸到可能產生誤判的難以區分的關鍵負相關信息,并建立起有效的對比損失。Karpukhin等人[11]提出的DPR引入了批次內負采樣方法(in-batch negatives),使模型在訓練過程中能夠接觸到同一批次內的更多負相關數據,從而提升模型的檢索性能。然而,其僅在訓練開始前采用BM25進行負采樣,導致模型在訓練的過程中無法接觸到更多有效的負樣本。為了解決這個問題,Xiong等人[12]提出了ANCE,其在訓練過程中不斷使用批次檢查點模型(checkpoint)異步地對數據集進行檢索,以生成靜態難負樣本(static hard negatives),并在新一輪的訓練中使用靜態難負樣本進行模型訓練,使模型在訓練過程中能夠接觸到高質量的負相關數據,從而提高檢索的準確性。然而,其使用批次檢查點模型異步地生成靜態難負樣本,需要消耗大量的計算資源,導致模型的訓練開銷過大。為降低訓練模型的資源開銷,Hofsttter等人[13]從查詢的聚類特征出發,提出了TAS-B,其在訓練前對查詢集合進行一次聚類,并對每個批次的查詢樣本進行聚類內平衡化處理,使模型即使使用小批次進行訓練也能達到較好的效果。然而,該模型使用的無監督聚類過程非常消耗時間,同時,在訓練的過程中將批次內的所有樣本都設置為同一聚類內的樣本會導致模型產生過擬合,從而降低模型的泛化能力。
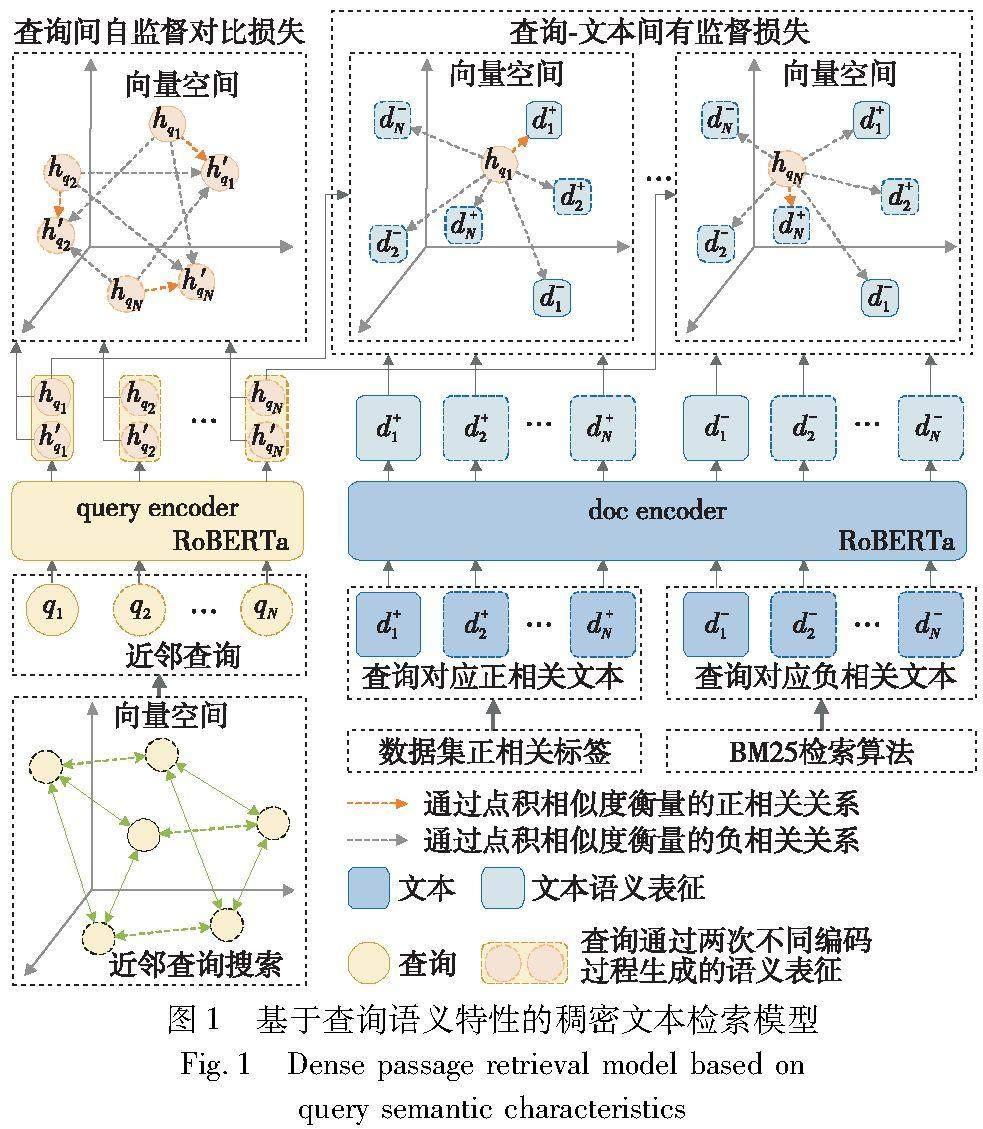
針對上述問題,本文提出了一種基于查詢語義特性的稠密文本檢索模型(Q-DPR),其結構如圖1所示。
模型使用RoBERTa[14]預訓練模型作為編碼器,分別將輸入的查詢和文本編碼為稠密向量,并使用點積計算向量的相似度以衡量它們之間的相關性。同時,模型將查詢、查詢的正相關文本以及BM25檢索的負相關文本作為訓練數據。訓練時,采用了一種基于近鄰查詢的負采樣方法(nearest neighbor query negative,N2Q),該方法在表征空間中選取最近鄰的查詢及其對應的正負文本,在同一批次內采用批次內負采樣策略,構建基于問答樣本的有監督對比損失,以實現高效且高質量的負采樣訓練過程。同時,采用一種基于對比學習的查詢自監督方法(self-supervised learning of query,S2Q),該方法使模型在訓練過程中對查詢進行兩次獨立編碼,將同一查詢的稠密向量作為正相關樣本,不同查詢的則作為負相關樣本,使用自監督方式構建查詢間的對比損失,以減輕模型在訓練過程中可能出現的過擬合問題,提升模型的語義表征能力。
1 相關工作
稠密檢索模型目前在文本檢索領域的研究中占據重要地位。與交互檢索模型不同,稠密檢索模型將查詢語句和文本獨立地編碼為低維的稠密向量。這種方法使模型能夠在進行檢索前預先推斷并儲存潛在文本的語義表征,而在檢索過程中,僅需進行簡單的向量交互,即可快速完成檢索。
雙塔模型(dual-encoder)是稠密檢索模型的典型代表,該模型將查詢和文本獨立編碼為單一的低維稠密向量,然后通過計算向量間的相似度以評估它們之間的關聯性。雙塔模型單一的向量表示以及簡單的相似性計算極大地提升了檢索的速度。然而,這種簡化的檢索方法對模型的語義表征能力要求極高,若表征能力不足,將嚴重影響檢索的準確性。許多研究致力于通過增強語義表征的廣度信息以提高檢索的準確性。
增強語義表征的廣度信息,即增加語義表征的數量或維度。Zhang等人[15]認為查詢與文本之間存在一種單對多的關系,因此,僅使用單一的向量形式對文本進行表示,對于檢索模型來說是有限的。基于這一理念,他們將文本編碼為多個不同語義角度的表征向量,以提高模型的檢索準確性。這種新穎的思路取得了可觀的成果,但使用無監督的方法從不同語義角度對文本進行編碼可能會導致模型產生過擬合,從而退化為雙塔模型。為了提升檢索準確性,語義交互過程被重新引入,并提出了延遲交互 (late interaction)模型。延遲交互模型能夠預先推理并存儲候選文本的細粒度語義向量,然后在檢索過程中再進行查詢和文本之間的細粒度語義交互。DC-BERT[16]使用Transformer模型實現了檢索過程中細粒度的語義交互。Poly-Encoder[17]則使用了全局而非詞標記級別的自注意力特征,并通過注意力機制(attention)實現細粒度的語義交互。這些大規模的交互過程確保了檢索的準確性,但同時也降低了模型的檢索速度,導致模型的推理速度和開銷仍然難以滿足檢索的需求。TK[18]簡化了細粒度語義交互的過程,只使用簡單的神經網絡模型進行交互。而ColBERT[19]則采用了一種簡單的非神經網絡交互步驟構建細粒度的相似性。ColBERT的靈活性更強,實現了TK不支持的端到端檢索,極大地提高了模型的檢索速度。
盡管延遲交互的發展顯著提升了模型的檢索速度,但對存儲大量細粒度語義向量的需求,使其在低成本部署方面存在困難。此外,當系統中存在大量候選文本時,其檢索速度仍未能達到理想的水平。
為了在保持檢索速度的同時提升檢索準確性,眾多科研人員開始研究模型的負采樣策略以及對比損失的構建方法。他們試圖讓模型能夠在訓練過程中接觸到可能產生誤判的難以區分的關鍵負相關信息,以建立有效的對比損失,增強語義表征的深度。Karpukhin等人提出的DPR引入了批次內負采樣操作。對于某一查詢,該方法將同一批次內不同查詢的正相關文本作為該查詢的負相關數據進行對比損失的構建,使模型能夠在同一批次內學習到更多關于查詢的負相關信息。Qu等人[20]提出的RocketQA使用了跨批次負采樣(cross-batch negatives)的方法,以增加訓練過程中負相關樣本的數量,并采用去噪的難負樣本采樣(denoised hard negative sampling)選取更可靠的負樣本,以提升檢索模型的效果。這些模型有效地提升了檢索的準確性,但它們都有一個共同的缺陷,即需要大量的計算機資源進行大批次訓練,使模型在訓練過程中學習到有用的關鍵負相關信息。為了解決這個問題,Xiong等人提出了ANCE,首先讓模型使用BM25檢索結果生成的負樣本進行warmup訓練,然后在訓練過程中不斷使用批次檢查點模型異步地對數據集進行檢索,以生成靜態難負樣本(static hard negatives),并在新一輪的訓練中使用靜態難負樣本進行模型訓練。Zhang等人[21]提出的AR2將交互模型和雙塔模型相結合,雙塔模型作為檢索模型,而交互模型作為重排序模型。檢索模型學習并檢索難負樣本以欺騙重排序模型,而重排序模型通過難負樣本進行學習,并采用知識蒸餾的方法向檢索模型提供軟標簽,形成漸進式的反饋。這些模型有效地提升了關鍵負相關信息的質量,但其不斷對難負樣本索引進行刷新的過程仍然需要較大的開銷。針對這個問題,Hofsttter等人提出了TAS-B,在訓練前對查詢進行一次聚類,并對每個批次的查詢樣本進行聚類內平衡化處理,從而使模型通過小批量訓練就能達到良好的效果。然而,該模型使用的無監督聚類過程非常耗時,同時在訓練過程中將批次內的所有樣本都設置為同一聚類內的樣本,可能會導致模型產生過擬合,從而降低模型的泛化能力。Zhan等人[22]則從理論上研究了不同的抽樣策略,提出了STAR,使用BM25檢索的負樣本進行模型訓練,并引入了隨機采樣的過程增強訓練的穩定性,同時他們提出了ADORE[22]對查詢的語義表征進行微調,該模型提升了檢索的性能,但并沒有考慮到在微調查詢語義表征過程中模型的參數變化可能會使文本的語義表征同時發生變化,導致模型產生過擬合。
當前,稠密文本檢索模型仍面臨諸多問題和挑戰,主要體現在訓練開銷過大及模型易產生過擬合等方面。對此,本文基于查詢的語義特性,提出了一種新的稠密文本檢索模型。
2 基于查詢語義特性的稠密文本檢索模型
在稠密文本檢索任務中,假設存在候選文本集合D={d1,d2,…,d|D|}和待檢索查詢集合Q={q1,q2,…,q|Q|}。對于任意查詢qi∈Q,檢索模型的目標是在候選文本集合D中檢索出與查詢qi相關的文本。為實現這一目標,模型首先需要對所有的文本進行編碼,得到任意文本dj∈D的語義表征E(dj),構成文本語義表征集合E(D)={E(d1),E(d2),…,E(d|D|)}。之后,模型將待檢索的查詢qi進行編碼,得到查詢的語義表征E(qi)。最終,模型通過簡單的向量計算模型預測E(qi)與所有E(dj)∈E(D)的語義表征相關性,以此確定查詢qi和文本dj之間的關聯程度。檢索的準確性對于檢索模型來說極為關鍵,而稠密檢索模型的檢索性能與模型的訓練過程息息相關。在模型的訓練過程中,往往需要使用一些有效的負采樣策略,以獲得模型易產生誤判的關鍵負相關信息,并建立高質量的對比損失以提升模型的檢索準確性。因此,基于查詢語義特性的稠密文本檢索模型在結構上對雙塔模型進行了優化,采用了共享編碼器的方式以降低模型的訓練成本。在訓練方法層面,本文在DPR模型的基礎上,引入了一種基于近鄰查詢的負采樣方法,該方法通過對近鄰查詢進行檢索,快速地構建高質量的負相關樣本,從而提高負采樣過程的效率。此外,本文優化了模型的損失函數,引入了一種基于對比學習的查詢自監督方法。該方法通過自監督的方式構建查詢間的對比損失,有效地減輕了模型的過擬合現象,提升了模型的檢索性能。
2.1 模型結構
如圖1所示,基于查詢語義特性的稠密文本檢索模型采用了雙塔結構,其設計理念與DPR的模型結構相似。然而,區別在于DPR采用兩個獨立的編碼器分別對查詢和文本進行編碼,而本文為了降低模型的訓練成本,選擇使查詢和文本共享一個編碼器。該模型將查詢和文本編碼為單一的語義向量,即
在得到查詢和文本的語義表征之后,需要使用簡單的向量計算模型來獲取它們之間的相關性。本文使用點積相似度函數計算查詢q的語義表征E(q)與文本d的語義表征E(d)之間的相似度。這種語義表征相似度被視為查詢q和文本d之間的相關性得分f(q,d)。以下是計算f(q,d)的具體過程:
f(q,d)=E(q)T·E(d)(3)
2.2 訓練方法
基于查詢語義特性的稠密文本檢索模型的訓練方法基本流程如圖2所示。首先,對于任意查詢qi∈Q,模型將查詢qi、其正相關文本d+i以及BM25檢索出與其呈強負相關的文本d-i作為一個訓練樣本。接下來,采用基于近鄰查詢的負采樣方法實現每一輪訓練的負采樣過程,將負采樣的結果作為訓練數據,采用批次內負采樣策略構建基于問答樣本的有監督對比損失LossN2Q。同時,采用基于對比學習的查詢自監督方法構建查詢間的無監督對比損失LossS2Q,并與LossN2Q進行聯合損失計算,得到Q-DPR訓練損失LossQ-DPR=LossN2Q+LossS2Q。最終,經過多輪訓練,生成一個高效的文本檢索模型。下文將詳細闡述基于近鄰查詢的負采樣及基于對比學習的查詢自監督兩種方法。
2.2.1 基于近鄰查詢的負采樣方法
為了提高稠密檢索模型訓練過程中負采樣的效率并提升負樣本的質量,本文提出了一種基于近鄰查詢的負采樣方法。該方法利用近鄰查詢語義表征向量在表征空間中的特性,即當查詢的語義向量在表征空間中近鄰時,它們對應的正負相關文本的語義向量在表征空間中也會呈現出近鄰的情況。這種特性使查詢及其近鄰查詢的正負相關文本形成了強負相關關系,從而讓模型在訓練過程中能通過檢索近鄰查詢,將查詢與其近鄰查詢的正負相關文本作為負相關數據,以構建高質量的對比損失。由于在訓練集中,查詢的數量及其序列長度都遠小于文本,所以檢索近鄰查詢的開銷要遠小于通過查詢對文本進行檢索的開銷。相比于ANCE等負采樣方法,這種方法極大地提高了負采樣的效率。
假設數據集中存在查詢集合Q={q1,q2,…,q|Q|},基于近鄰查詢的負采樣過程可以描述如下:在每個訓練輪次開始前,首先使用模型對查詢集合Q進行編碼,從
2.2.2 基于對比學習的查詢自監督方法
為了緩解模型在訓練過程中易產生過擬合的問題,本文提出了一種基于對比學習的查詢自監督方法。諸如SimCSE[23]等基于對比學習的自監督方法,在文本相似性匹配任務中得到了廣泛應用。自監督的方式使模型能夠在無標簽的情況下學習到文本間的語義信息,顯著提升模型的語義表征能力。與需要標簽的有監督訓練相比,自監督的方式不再依賴于高質量的標簽,
而是讓模型自主學習語義關系,從而緩解由數據集引發的過擬合問題。雖然這種方法在文本相似性任務中取得了顯著的成效,但在面向問答的文本檢索任務中,這種方法并未展現出其優勢。主要是因為在文本相似性匹配任務中,正相關的文本與文本之間在序列長度、語義表達上沒有明顯差異,而在面向問答的文本檢索任務中,同一個文本可能能夠與多個語義截然不同的查詢相匹配,文本的語義存在多元性,這導致無監督的形式難以使模型學習到復雜的語義信息。然而,在面向問答的文本檢索任務中,查詢往往由序列簡短的關鍵詞匯構成,不存在多元的語義,這符合文本相似性匹配任務中文本的特征。因此,本文在基于問答樣本的有監督訓練方法中引入了基于對比學習的查詢自監督損失,以此來擴大不同查詢的語義向量在表征空間上的距離,緩解了模型在訓練過程中易產生的過擬合問題,使模型學習到高質量的語義表征。
3 實驗及結果分析
3.1 數據集
MSMARCO(Microsoft machine reading comprehension)[24]是一個大規模的開放領域問答數據集,它基于真實數據構建,主要致力于開放領域問答任務,如機器閱讀理解、問題回答和文本排序等。該數據集提供了超過一百萬的開放領域問題和超過八百萬的待檢索文本。在標簽方面,對于每個問題,該數據集都提供了與之相關的一千個文本以及標準答案。MSMARCO的規模和真實性極大地推動了文本檢索模型的發展。
3.2 評估指標
文本檢索模型的性能通過平均倒數排名(mean reciprocal rank,MRR)和召回率進行評估。平均倒數排名首先對每個問題的標準答案在檢索結果中的排位取倒數作為每個問題的檢索準確度,之后,采用對所有問題的檢索準確度取平均的方式以衡量模型的性能。召回率則常用于評估檢索模型檢索正確信息的能力,通常表示為模型檢索出的正確文本在所有正確文本中所占的比例。
假設在待評估的驗證集中存在|Q|個查詢,其集合為Q={q1,q2,…,q|Q|},對于任意查詢qi∈Q,其標準答案為d+i,檢索模型檢索出的與該查詢最為相關的k個文本所構成的集合為Dqi={dqi1,dqi2,…,dqik}。若d+i∈Dqi,將其在Dqi中的下標記為ri,那么MRR和Recall的計算過程可以描述如下:
其中:k作為評估指標的參數,代表檢索模型對排名誤差的容忍度。若k值較大,對檢索模型的要求則相對寬松;反之,若k值較小,則對檢索模型的要求相對嚴格。
3.3 實驗設置
Q-DPR在PyTorch平臺上實現,并使用 NVIDIA 3090進行實驗。表1列出了模型在MSMARCO數據集上使用的最優超參數。在處理原始數據時,將查詢的最大序列長度設定為32,文本的最大序列長度設定為256,如果序列長度超過最大長度,則對序列進行裁剪。在模型訓練階段,將數據集中的BM25檢索結果作為負樣本,并使用MSMARCO數據集中的標準passage訓練數據對模型進行訓練,訓練批次的大小設定為512,訓練的輪次設定為30。在模型評估階段,模型訓練完成后,使用了MSMARCO提供的passage驗證集進行性能評估。在實驗過程中,通過調整學習率、K和L等超參數進行模型訓練,比較模型的MRR和Recall指標以選擇最優的參數組合。需要強調的是,模型性能將受到參數K和L的直接影響。參數K代表在基于近鄰查詢的負采樣方法中檢索近鄰查詢的質心數量。如果參數K設置過大,會降低模型的負采樣效率并使模型在訓練過程中難以收斂;若設置過小,則會降低負采樣的質量。參數L代表在基于近鄰查詢的負采樣方法中同一批次內近鄰查詢的數量。若參數L設置過大,模型會對近鄰查詢產生過擬合;反之,若設置過小,則會導致負采樣的質量降低。本文對超參數K進行了一系列的實驗,實驗的取值為K∈{20×100,21×100,23×100,20×1000,21×1000,23×1000}。同樣地,也對超參數L進行了實驗,實驗的取值為L∈{22,23,…,26}。最終,選取了在MSMARCO數據集表現最優的參數,即K=20×1000,L=22。
3.4 對比實驗
3.4.1 與基線模型對比實驗
表2為基于查詢語義特性的稠密文本檢索模型與其他基線模型在MSMARCO數據集上的性能對比。模型性能的評估采用了兩個指標:k=10的平均倒數排名MRR@10以及k=1000的召回率R@1K。
在僅使用基于近鄰查詢的負采樣方法進行訓練的情況下,Q-DPR在MSMARCO數據集上實現了0.343的平均倒數排名和0.970的召回率。與其他基線模型相比,平均倒數排名有所提升,這驗證了基于近鄰查詢的負采樣方法相較于其他負采樣方法的優越性。通過采用近鄰查詢檢索負相關文本的方式,模型在訓練過程中能接觸到高質量的關鍵負相關信息。這使模型建立了有效的對比損失,從而提高了模型的語義表征能力。然而,與此同時,召回率指標相對于其他基線模型有所下降。這是因為在訓練過程中,考慮到訓練的開銷問題,并未采用刷新查詢負相關文本的操作,這導致模型對近鄰查詢內的樣本產生了過擬合,從而降低了召回率。
在僅采用基于對比學習的查詢自監督方法進行訓練的情況下,Q-DPR在MSMARCO數據集上的性能超過了其他基線模型,實現了0.342的平均倒數排名和0.972的召回率。這種提升得益于查詢自監督學習為模型構建了強大的查詢對比損失,使模型在缺乏查詢間標簽關系的情況下,仍能學習到向量空間下的相互關系,從而達到緩解過擬合的目的。
最終,通過應用基于近鄰查詢的負采樣方法和基于對比學習的查詢自監督方法,Q-DPR在MSMARCO數據集上實現了0.348的平均倒數排名和0.975的召回率。實驗結果表明,該模型的性能優于其他基線模型,證明了采用基于近鄰查詢的負采樣方法來檢索高質量的負相關文本,同時利用基于對比學習的查詢自監督方法來緩解模型的過擬合問題的有效性。
3.4.2 模型訓練開銷對比實驗
表3為基于查詢語義特性的稠密文本檢索模型與一些高性能基線模型在MSMARCO數據集上的訓練成本比較。利用近鄰查詢及其正負相關文本在向量空間上的特性,本模型在訓練過程中僅對查詢進行檢索。由于查詢的檢索開銷遠小于文本的檢索開銷,這種方法確保了檢索過程的高效性。僅需在兩塊GPU上進行36 h的訓練,就可以得到一個高效的稠密文本檢索模型。實驗結果表明,Q-DPR的訓練成本要顯著低于其他基線模型。
3.5 消融實驗
為了驗證Q-DPR模型中各組成部分的有效性,本文在MSMARCO數據集上進行了一系列的消融實驗。實驗的目標是探究基于近鄰查詢的負采樣方法(N2Q)、基于對比學習的查詢自監督方法(S2Q)以及BM25負樣本對模型性能的影響。
表4為Q-DPR的各類變體在MSMARCO數據集上的消融實驗對比。其中,“Rand-Neg”代表采用隨機批次內負采樣策略;“BM25-Neg”代表采用BM25檢索負樣本進行批次內負采樣;“N2Q”代表采用基于近鄰查詢的負采樣方法;“S2Q”代表采用基于對比學習的查詢自監督方法。值得注意的是,無論是否采用BM25檢索負樣本,使用N2Q或S2Q進行訓練的模型在平均倒數排名指標上都有所提升。但是,在采用隨機批次內負采樣的情況下,模型的性能提升并不顯著。這是因為隨機批次內負采樣的隨機性無法確保負樣本的質量,即使采用N2Q或S2Q也無法完全克服這一缺陷。同時,負采樣的隨機性使N2Q的負采樣過程過于依賴聚類,導致模型在召回率指標上有所下降,這與3.4.1節的分析結果相吻合。在采用BM25檢索負樣本進行訓練的情況下,使用N2Q或S2Q均能使模型性能得到普遍提升,這進一步證實了基于近鄰查詢的負采樣方法和基于對比學習的查詢自監督方法的有效性。
3.6 檢索樣例
表5展示了在MSMARCO數據集上,DPR和Q-DPR對兩個不同查詢的檢索結果。對于查詢“What is on the outside of DNA?”,DPR檢索出了錯誤的答案,其僅定位到查詢中的關鍵詞“DNA”,卻未能捕捉到查詢的核心語義“on the outside of DNA”,因此檢索出的結果無法準確地回答問題。相反,Q-DPR檢索出了正確的答案,準確地解答了DNA外側的構成。這歸功于Q-DPR模型強大的語義表征能力,能夠捕捉查詢的關鍵信息。對于查詢“Which Vitamins help heal bruises?”,DPR和Q-DPR都捕捉到了查詢的核心語義,給出了哪些維生素能夠治療瘀傷的答案。然而,DPR的檢索結果更多的是在描述維生素E的作用,而Q-DPR的檢索結果則更為準確,明確地回答了維生素C和維生素K能夠治療瘀傷。這進一步證實了Q-DPR具備更強的檢索準確性。
4 結束語
為了降低稠密文本檢索模型在訓練過程中的負采樣成本,并抑制可能出現的過擬合問題,提出了一種基于查詢語義特性的稠密文本檢索模型。該模型采用了基于近鄰查詢的負采樣方法和基于對比學習的查詢自監督方法。基于近鄰查詢的負采樣方法通過對查詢進行近鄰檢索,有效地提高了模型在訓練過程中負采樣的效率和質量,降低了模型的訓練成本。基于對比學習的查詢自監督方法通過構建查詢間的對比損失,有效地抑制了模型的過擬合問題,使模型能夠學習到高質量的語義表征。實驗結果證明,Q-DPR在訓練成本和檢索性能方面表現優異,
但與交互模型相比,其檢索準確率仍有待提高。未來的研究可以探索如何以低成本的方式利用交互模型進行負采樣,實現從交互模型到稠密文本檢索模型的知識蒸餾,從而進一步提升模型的檢索準確性。這將成為稠密文本檢索模型未來研究的重要方向。
參考文獻:
[1]方明弘,萬里,戴凡杰. 基于雙層記憶網絡的多領域端到端任務型對話系統 [J]. 計算機應用研究,2023,40(10): 2945-2950. (Fang Minghong,Wan Li,Dai Fanjie. Multi-domain end-to-end task-oriented dialogue system based on double-layer memory network [J]. Application Research of Computers,2023,40(10): 2945-2950.)
[2]趙蕓,劉德喜,萬常選,等. 檢索式自動問答研究綜述 [J]. 計算機學報,2021,44(6): 1214-1232. (Zhao Yun,Liu Dexi,Wan Chang-xuan,et al. Retrieval-based automatic question answer:a literature survey [J]. Chinese Journal of Computers,2021,44(6):1214-1232.)
[3]邸劍,劉駿華,曹錦綱. 利用BERT和覆蓋率機制改進的HiNT文本檢索模型 [J/OL]. 智能系統學報. (2023-09-27) [2023-10-22].http://kns.cnki.net/kcms/detail/23.1538.TP.20230926. 1452.002.html. (Di Jian,Liu Junhua,Cao Jingang. An improved hint test retrieval model using BERT and coverage mechanism [J/OL]. CAAI Trans on Intelligent Systems. (2023-09-27) [2023-10-22]. http://kns.cnki.net/kcms/detail/23.1538.TP.20230926.1452.002.html.)
[4]Aizawa A. An information-theoretic perspective of TF-IDF measures [J]. Information Processing & Management,2003,39(1):45-65.
[5]Robertson S,Zaragoza H. The probabilistic relevance framework: BM25 and beyond [J]. Foundations and Trends in Information Retrieval,2009,3(4): 333-389.
[6]韓華珍. 面向智能問答系統的語義匹配技術研究與實現 [D]. 成都: 電子科技大學,2021. (Han Huazhen. Research and implementation of semantic matching technology for intelligent question answering system [D]. Chengdu: University of Electronic Science and Technology of China,2021.)
[7]Devlin J,Chang Mingwei,Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proc of Conference of the North American Chapter of Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2019: 4171-4186.
[8]胡文浩,羅景,涂新輝. 面向稠密檢索的偽相關反饋方法 [J]. 計算機應用,2023,43(4): 1036-1042. (Hu Wenhao,Luo Jing,Tu Xinhui. Pseudo relevance feedback method for dense retrieval [J]. Journal of Computer Applications,2023,43(4): 1036-1042.)
[9]羅雅蘭. 基于BERT上下文感知的多層級信息檢索方法 [D]. 汕頭: 汕頭大學,2021. (Luo Yalan. Contextual awared multi-layer information retrieval method based on BERT [D]. Shantou: Shantou University,2021.)
[10]吳昭. 結合字面匹配與上下文交互的全文檢索研究與實現 [D]. 吉林: 吉林大學,2022. (Wu Zhao. Research and implementation of full-text retrieval combining word matching and context interaction [D]. Jilin: Jilin University,2022.)
[11]Karpukhin V,Ouz B,Min S,et al. Dense passage retrieval for open-domain question answering [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2020: 6769-6781.
[12]Xiong L,Xiong Chenyan,Li Ye,et al. Approximate nearest neighbor negative contrastive learning for dense text retrieval [EB/OL]. (2020-10-20)[2023-10-22].https://doi.org/10.48550/arXiv.2007.00808.
[13]Hofsttter S,Lin S C,Yang J H,et al. Efficiently teaching an effective dense retriever with balanced topic aware sampling [C]// Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press,2021: 113-122.
[14]Liu Yinhan,Ott M,Goyal N,et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26) [2023-10-22]. https://doi. org/10. 48550/arXiv. 1907. 11692.
[15]Zhang Shunyu,Liang Yaobo,Gong Ming,et al. Multi-view document representation learning for open-domain dense retrieval [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: ACL Press,2022: 5990-6000.
[16]Nie Yuyu,Nie Ping,Geng Xiubo,et al. DC-BERT: decoupling question and document for efficient contextual encoding [C]// Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2020:1829-1832.
[17]Humeau S,Shuster K,Lachaux M A,et al. Poly-Encoders:Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring [EB/OL]. (2020-07-25) [2023-10-22]. https://doi.org/10.48550/arXiv.1905.01969.
[18]Hofsttter S,Zlabinger M,Hanbury A. Interpretable & time-budget-constrained contextualization for re-ranking [M].[S.l.]: IOS Press,2020: 513-520.
[19]Khattab O,Zaharia M. ColBERT:efficient and effective passage search via contextualized late interaction over BERT [C]// Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press,2020: 39-48.
[20]Qu Yingqi,Ding Yuchen,Liu Jing,et al. RocketQA: an optimized training approach to dense passage retrieval for open-domain question answering [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: ACL Press,2021: 5835-5847.
[21]Zhang Hang,Gong Yeyun,Shen Yelong,et al. Adversarial retriever-ranker for dense text retrieval [EB/OL]. (2022-10-30) [2023-10-22]. https://doi. org/10. 48550/arXiv. 2110. 03611.
[22]Zhan Jingtao,Mao Jiaxin,Liu Yiqun,et al. Optimizing dense retrieval model training with hard negatives [C]// Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press,2021: 1503-1512.
[23]Gao Tianyu,Yao Xingcheng,Chen Danqi. SimCSE: simple contrastive learning of sentence embeddings [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2021: 6894-6910.
[24]Nguyen T,Rosenberg M,Song Xia,et al. MSMARCO: a human gene-rated machine reading comprehension dataset [EB/OL]. (2016-11-28) [2023-10-22]. https://doi.org/10.48550/arXiv.1611.09268.
[25]Nogueira R,Lin J,Epistemic A I. From doc2query to docTTTTTquery [EB/OL]. (2019-06-05)[2023-10-22].https://www.researchgate.net/publication/360890853_From_doc2query_to_docTTTTTquery.
[26]Mallia A,Khattab O,Suel T,et al. Learning passage impacts for inverted indexes [C]// Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press,2021: 1723-1727.
[27]Lu Shuqi,He Di,Xiong Chenyan,et al. Less is more: pretrain a strong Siamese encoder for dense text retrieval using a weak decoder [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2021: 2780-2791.
[28]Lin S C,Yang J H,Lin J. Distilling dense representations for ranking using tightly-coupled teachers [EB/OL]. (2020-10-22) [2023-10-22]. https://doi. org/10. 48550/arXiv. 2010. 11386.
