基于代碼注釋調優的智能合約自動生成方法
2024-06-01 10:24:02陳勇胡德鋒徐超陳楠楠
計算機應用研究 2024年5期
陳勇 胡德鋒 徐超 陳楠楠


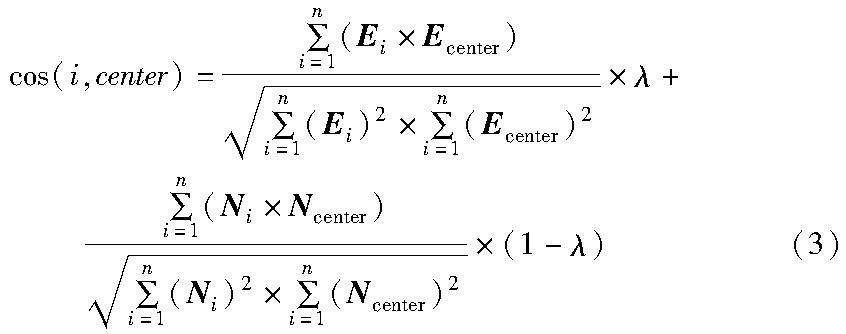
摘 要:針對智能合約開發效率不高、安全漏洞頻發等問題,提出了一種基于代碼注釋調優的智能合約自動生成方法。首先結合智能合約代碼關聯注釋的語義信息,構建智能合約聚類分析模型,實現功能類似智能合約的快速精準聚類;接著劃分注釋關聯的合約層、函數層、接口層等不同層次智能合約知識庫,以聚類后的代碼及注釋信息為基礎,構造多樣化Prompt特征提示語句數據集;最后,以大語言模型ChatGLM2-6B為基礎,借助P-Tuning v2微調技術,實現特定需求智能合約的自動生成。為檢測該方法的有效性,借助雙語互譯質量評估輔助工具BLEU和代碼安全檢測工具Mythril與VaaS,同現有方法進行了對比。實驗結果表明,該方法生成的代碼BLEU平均值提升了13%左右,代碼安全性提高6%左右。此方法將代碼注釋信息融入智能合約的自動生成,有效提升了智能合約的質量,為高效開發安全可靠的智能合約提供了一種新的方法。
關鍵詞:智能合約;注釋;大語言模型;微調;自動生成
中圖分類號:TP183?? 文獻標志碼:A??? 文章編號:1001-3695(2024)05-031-1502-06
doi: 10.19734/j.issn.1001-3695.2023.09.0401
Research of smart contract automatic generation method based on code annotation optimization
Abstract:To address the issues of low efficiency and frequent security vulnerabilities in smart contract development, this paper proposed a smart contract auto-generation method based on code comment optimization. Firstly, it constructed a smart contract clustering analysis model based on the semantic information of smart contract code associated annotations to achieve fast and accurate clustering of functions similar to smart contracts. Then,it divided the smart contract knowledge base into different levels such as the contract layer, function layer, and interface layer associated with the annotation. And based on the clustered code and annotation information, it constructed a diversified Prompt feature prompt statement dataset. Finally, it achieved automatic generation of smart contracts with specific needs based on the large language model ChatGLM2-6B and with the help of P-Tuning v2 fine-tuning technology. In order to test the effectiveness of this method, this paper conducted comparative experiments with existing methods using the bilingual translation quality assessment assistant tool BLEU and the code security detection tools Mythril and VaaS. Experimental results show that the average BLEU of the code generated by this method is increased by about 13%, and the code security is improved by about 6%. This method integrates code annotation information into the automatic generation of smart contracts, effectively improves the quality of smart contracts, and provides a new method for the efficient development of safe and reliable smart contracts.
Key words:smart contract; annotation; big language model; fine-tuning; automatically generate
0 引言
隨著智能合約的快速發展,其應用領域越來越廣泛,智能合約的設計除了保證其本身的安全性之外,還需要了解相關應用領域的知識和技能。因此,在智能合約領域經常出現合約開發者與合約設計者的分離:合約開發人員在掌握智能合約編程語言的同時卻缺乏對合約邏輯的認識,設計人員在熟悉業務規則的同時卻缺乏對智能合約的理解。這無形中降低了智能合約開發效率,影響智能合約發展的步伐。其次,據文獻[1]調查統計,截至2022年10月,以太坊中部署發布的智能合約數量已經高達5 100萬,其市場規模將以每年32%的增長率增加,涉及的金額已經超過億級。龐大的市場規模導致對智能合約的開發效率以及安全性要求更加嚴格,因此,如何快速開發出準確安全的智能合約成為該領域發展亟待解決的關鍵問題。
然而,目前智能合約的研究主要集中在合約的安全性,對智能合約的開發效率關注較少。一些研究[2,3]開始嘗試利用RNN等神經網絡實現智能合約的自動生成,但該類研究在代碼語義理解層面仍然存在不足,使得生成的合約存在安全性和正確性不高、人機交互效率低等問題,難以滿足快速發展的智能合約應用場景。近年來,隨著注意力機制[4]的快速發展,以Chat-GPT[5]為代表的各種大語言模型廣泛應用于各類通用場景,在代碼生成領域也表現卓越。微軟的Copilot融合了GPT的強大能力,能夠根據使用者輸入的信息從而生成相應的通用類代碼;MetaAI發布的Code LLaMA Python可以生成各種高效的Python代碼。因此,大語言模型對于提升代碼生成的質量和效率具有極大的促進作用。然而,大語言模型的構建離不開高質量基礎數據的支撐,對于各類常規代碼的生成,大語言模型可以通過對大量成熟代碼的學習獲得出色的表現,但對于智能合約這類新型軟件,直接應用已有的大語言模型難免出現生成代碼不準確、安全性不高等問題,有必要進行針對性的訓練和調優。
程序語義信息的提取是代碼自動生成的關鍵,代碼注釋[6]作為源代碼的輔助信息,標注了代碼實現的目的和基本思路,對于提升代碼語義信息提取的準確率具有極大的幫助,已經被開發者所廣泛使用以提升開發效率[7]。為此,本文從大語言模型出發,借助于智能合約的代碼注釋,提出了一種基于注釋調優的智能合約自動生成方法,將代碼注釋提供的額外語義信息輔助大語言模型的調優,以提高模型學習過程中對于代碼語義的理解,從而更快速準確地生成滿足不同需求的智能合約代碼,提高智能合約相關應用的開發效率。本文的主要貢獻如下:
a)設計了基于注釋輔助聚類分析的智能合約相似性評估。對爬蟲程序獲取的智能合約進行預處理和劃分代碼層次,從注釋信息和代碼兩個維度出發,分別給予不同的權重并對各層次的智能合約源代碼進行聚類分析,從而獲取到具有相似特征的層次化智能合約源代碼文檔和注釋,保證智能合約生成模型的準確性,同時提高代碼的復用性。
b)構建了代碼注釋組成的Prompt指令數據集。設計了多個Prompt模版,與注釋信息組成數據集的輸入部分,同時將智能合約代碼劃分為函數層、合約層、庫合約層以及接口層四個層次,并以此作為數據集的輸出部分。
c)訓練了注釋輔助調優的智能合約自動生成大模型。采用P-Tuning v2微調方法,在ChatGLM2-6B大模型的基礎上利用智能合約數據集進行高效的微調和訓練,并選取調優后的最佳模型,實現注釋信息輔助的智能合約代碼自適應匹配。
1 相關研究
目前,大語言模型[8]在醫療、金融以及教育等領域都得到了廣泛的應用,各大公司都發布了相應的大語言模型,例如OpenAI的Chat-GPT、清華大學發布的ChatGLM-6B[9]大模型、Meta的LLaMA[10]以及百川等模型,大模型雖然具有強大的學習能力,但其參數量巨大、硬件要求高等特點成為了眾多學者考慮的問題。另一方面,針對特定領域的問題,其處理能力仍然有待提高,因此研究者們提出了大模型在垂直領域進行下游任務的進一步微調的方法。微軟公司提出了一種基于低階自適應的大語言模型微調方法(LoRA)[11],該方法通過修改模型結構實現高效微調。斯坦福大學提出的基于提示詞前綴優化的方法(Prefix Tuning)[12]在近幾年里也得到了不斷的優化和改進,例如Prompt Tuning、P-Tuning[13]、P-Tuning v2[14]等。微調使得大語言模型的發展更為廣泛,北京大學提出了開源的法律大語言模型(ChatLaw)[15],該模型是以LLaMA模型為基礎并采用LoRA方法針對法律領域知識進行精準微調而來。Wang等人[16]以LLaMA-7B為基準模型,融入了大量的結構化和非結構化醫學領域的知識進行微調,提出了在醫療領域表現更佳的HuaTuo大語言模型。
針對智能合約領域的研究,目前主要以智能合約代碼漏洞檢測為主。文獻[17~19]從區塊鏈結構中Solidity代碼層、EVM執行層、區塊鏈系統層三個角度分析智能合約漏洞,其中Solidity代碼層包含重入漏洞(The Dao攻擊)、整數溢出漏洞等十幾個漏洞,EVM執行層涉及短地址漏洞、以太丟失漏洞等四個漏洞,區塊鏈系統層主要包括時間戳依賴漏洞等三個漏洞。針對智能合約漏洞的檢測方法[17]主要分為形式化驗證法、符號執行法、模糊檢測法、中間表示法以及深度學習的方法,因此VaaS、Oyente[17]、SmartCheck[19]等工具廣泛應用于智能合約漏洞的檢測,智能合約的安全性問題得到了有效的改善。此外,在智能合約與開發人員友好性交互方面,文獻[18,20]提出了一種對于特定領域智能合約自動生成的方法,借助于深度學習中長短期記憶遞歸神經網絡(LSTM)構建智能合約自動生成模型,采用SmartCheck檢測生成代碼并得到了較好的實驗結果,最后通過設計良好的交互界面提高了編程的友好性和高效性。
代碼注釋作為理解代碼的重要手段,不少研究者[21,22]對其使用方式、質量評估和改進等方面進行了研究。王潮等人[23]總結了代碼注釋質量評估相關的研究成果,從代碼注釋的一致性、重要性等角度指出代碼注釋對于程序語義的理解有著至關重要的作用。代碼注釋的一致性能夠充分體現出注釋內容和對應代碼真實運行邏輯是否一致。高質量代碼注釋有效減少了大模型理解代碼的代價,尤其是在面臨著較大的代碼數據量的情況下,合理的代碼注釋從很大程度上緩解了該問題。
在利用深度學習進行代碼自動生成的研究中,Iqbal等人[2]指出遞歸神經網絡(RNN)、卷積神經網絡(CNN)以及生成的對抗網絡(GAN)是主要研究方向,其思想是利用各種神經網絡結構搭建代碼自動生成模型,并通過大量數據訓練模型生成相應的代碼。另一方面,ChatGLM2-6B 是由清華大學開源的開源中英雙語對話模型,Zheng等人[24]在此基礎上,經過了600B代碼數據預訓練,提出了CodeGeeX2的多語言代碼生成模型以及LLaMA在多語言代碼微調后的代碼生成模型Code LLaMA[25]。此外,BigCoder也發布了編程助手StarCode[26],具有代碼生成、補齊以及解釋等多種功能。
綜上所述,大模型在智能合約代碼生成領域已經展現出良好的趨勢,但如何增強大模型對代碼的語義理解能力仍然是研究者們需要進一步探索的內容,而注釋內容能夠提供較強的語義信息,對于增強大模型的語義分析能力具有積極意義。基于此,本文提出了基于代碼注釋和大語言模型微調技術相結合的智能合約自動生成方法,以充分利用注釋的語義信息增強大模型的語義分析能力,提高其生成的智能合約代碼的正確性。
2 注釋信息輔助調優的智能合約自動生成與匹配方法
2.1 總體框架
以上述研究工作作為基礎,本文提出了基于注釋信息輔助的智能合約自動生成與匹配方法。首先,本文將從智能合約的注釋信息和代碼體兩個角度出發,采用聚類技術針對智能合約各類層次的代碼進行分析。然后,通過劃分聚類后的代碼層次并將注釋與之關聯,構建智能合約代碼生成的指令數據集,同時利用注釋信息輔助和安全檢測工具分別增強和保證其代碼的易理解性和可靠性。最后,以ChatGLM2-6B為基座模型,采用P-Tuning v2方法結合構建的特定數據集對基座模型進行高效微調,開發人員利用界面輸入自己的功能需求從而匹配目標代碼設計智能合約代碼,提高開發的高效性和準確性。
本節將介紹整個研究過程的總體框架,具體如圖1所示。
由框架圖可知,本文研究思路主要分為三部分。首先利用爬蟲程序從以太坊上爬取智能合約源代碼文檔,將代碼和對應注釋文檔劃分層次并通過文件序號建立對應的映射關系。在注釋輔助智能合約源代碼聚類階段,本文對聚類的代碼和注釋文檔分別進行預處理后作為輸入,從注釋和代碼兩個維度出發,采用K-means算法生成各層次代碼簇,從而提取出具有高相似性的層次化代碼和注釋信息作為代碼生成的數據集。其次,在大模型微調數據集構造部分,為確保篩選出對應注釋內容較多的代碼體,本文將聚類后的層次化代碼進行二次預處理,并將代碼體對應的注釋與Prompt模版構成指令數據集的輸入部分,輸出部分為相應的層次化智能合約代碼。最后,采用ChatGLM2-6B模型作為基礎模型,結合構建的數據集進行P-Tuning v2方式微調,選取訓練后智能合約代碼生成效果最優的大模型,同時本文設計了便捷的人機交互界面,用戶在交互界面輸入需求信息,從而實現注釋輔助智能合約自適應匹配。
2.2 注釋指導的智能合約聚類
就代碼分析而言,大多數研究僅局限于代碼內容本身,往往忽略了注釋為對應代碼體所帶來的信息。因此除了代碼體本身這一基礎維度之外,注釋是本次研究的另一個重點。本文結合注釋信息文本和代碼文本兩個維度進行聚類,從而提取相似的各層次智能合約代碼。聚類具體操作步驟如下:
注釋中含有較多的源代碼描述信息,能夠幫助開發者快速理解和閱讀智能合約源代碼。為提高研究的準確性,本文對于獲取的智能合約源代碼文檔,應盡量保證聚類實驗前的智能合約文檔具有較多的注釋內容。本文通過統計智能合約源代碼中注釋的行數,從中篩選出注釋行數在300以上的智能合約代碼,同時文本量較大的智能合約文件含有豐富的注釋信息和代碼,故保留文件大小在50 KB~80 KB的智能合約文檔作為聚類的數據集。其次智能合約源程序文檔中含有眾多的JSON格式文本、二進制代碼文本以及不含注釋的智能合約文本,這些源代碼對于實驗沒有參考意義,因此在聚類實驗前要進行預處理,刪除此類智能合約源代碼文檔。
智能合約源代碼大體上由“function”“contract”“interface”和“library”四個層次代碼組成,對于聚類的數據集本文進行了上述層次劃分。劃分過程中,鑒于源代碼結構復雜,根據代碼的特殊形式獲取代碼和對應的注釋內容,例如“library”層代碼以“library Math {”和單行“}”結尾,注釋內容則一般處于代碼開頭部分上一行并以“/**”開頭和“*/”結尾,故首先采用正則化表達式提取出注釋內容,當檢測到下述的代碼時,首先提取出四個層次對應的代碼存儲在相應的文件中,層次化的代碼可以幫助開發者快速生成和管理目標代碼。其次,注釋作為代碼的信息描述,將含注釋的源代碼中的注釋與源代碼分別進行了不同文件的存儲,有效地避免了聚類過程中這兩類樣本的相互干擾。然后通過文檔序號建立代碼體文檔和對應注釋文檔的聯系,例如在提取過程中,提取出一個“interface”層代碼中一個接口代碼則為interface1文件,相應的注釋文檔即對應為interface1_note文件,建立序號映射關系的智能合約代碼體樣本和注釋信息樣本即為本次研究實驗數據集。
K-means是一種基于距離劃分的聚類算法,其認為兩個目標的距離越近,相似度越大,故選取該算法為聚類算法。本文所處理的代碼和注釋都為字符和符號組成的文本,且隨著文本長度增加,數據向量化的維度也會增大,余弦距離在高維空間中只受其向量夾角影響,而不受文本長度的影響,從而能更好地捕捉數據之間的相似性。其次余弦距離的計算相對簡單,這使得它在大規模數據集上的計算效率較高,故選取該算法為聚類算法。本文采用余弦距離(cosine distance)作為計算依據,并分別計算智能合約各層次代碼內容的余弦距離值以及對應注釋內容的余弦距離值,最后給予兩個余弦值一定的權重后相加即為樣本最終的判斷距離,通過衡量各樣本之間該距離從而實現聚類。
為提高聚類的準確性,智能合約數據集在聚類前應進行預處理。首先,智能合約代碼中有些詞出現了很多次但不能體現出在代碼中的重要性,比如“public”“return”“internal”等詞并不能作為特征項,因此本文設置了“public”該類詞作為停用詞。同理,注釋一般則是以“//”“/**/”等形式存在,所以這些詞也不能作為特征項,注釋文檔聚類中應設置“//”等停用詞。其次,鑒于Solidity語言特性,許多標識符是含有大小寫的,例如“Contract”、變量名等,因此這里將大小寫視為一致。
在聚類過程中,需將每個文檔向量化,計算其余弦距離。本文采用空間向量模型(VSM),將代碼和注釋文檔看作由多組不同的特征項與對應權重組成的向量,公式如下:
Di=Di(t1,w1;t2,w2;…;tn,wn)(1)
Gi=Gi(t1,w1;t2,w2;…;tn,wn)(2)
其中:Di和Gi分別表示第i個代碼和注釋文檔;tn為其中每個標識符或關鍵字;wn為對應的詞頻。每個代碼文檔中詞頻構成代碼文檔向量化表示Ei=[w1;w2;…;wn],注釋文檔向量化表示為Ni=[w1;w2;…;wn],計算每個文檔與中心點的向量內積和。實驗中選取多個聚類中心,依次計算各層次智能合約代碼Ei與中心文檔Ecenter的余弦距離值,同時計算該文檔對應的注釋文檔Ni與中心文檔Ncenter的余弦距離,分別給予權重且比例為λ∶(1-λ),加權計算后進行相加,公式為
聚類過程如算法1所示,具體如下:
a)對智能合約數據集進行無效文檔去除,避免非合約結構代碼對聚類的干擾,同時分別對代碼和注釋文檔進行停用詞處理。
b)通過空間向量模型將各文檔向量化,隨機選取K個中心文檔作為聚類中心,循環開始標志flag為true,當滿足所有文檔都聚類至最近的聚類中心時,循環標志為false,即結束聚類。采用式(3)依次計算每段代碼及其注釋文檔與各中心點的距離,并將其分配給距離最近的中心文檔(第5~13行)。
c)在上一步完成后,重新計算K個簇中各文檔的平均距離并更新聚類中心(第15~17行)。
d)計算新、舊聚類中心的余弦距離,若中心點沒有發生變化,則結束本次聚類,否則返回算法1中第5行重復上述步驟直至聚類中心不再變化,結束標志為flag=false(第18~23行)。
經過聚類處理后,每個層次的代碼分為多個簇,一個簇中的代碼為相似的智能合約代碼,例如具有相似功能描述的“function”層次代碼則為一個簇。
算法1 基于注釋指導的智能合約K-means聚類算法
2.3 基于注釋輔助微調的多層次智能合約自動生成方法
大模型是指深度學習中具有數以億計參數的巨大神經網絡模型,這些模型在過去的幾年中得到了廣泛關注和發展,主要是由于它們在各種任務上取得了令人矚目的性能提升。本文以ChatGLM2-6B 大模型為基座模型,設計了15個模仿使用者提問方式的Prompt同注釋構成指令數據集的輸入,注釋信息對應的層次化代碼為輸出部分,通過基座模型對微調指令數據集的二次訓練生成新的智能合約生成模型,實現智能合約的自動化生成。在上述基礎上,本文采用了目前比較主流的P-Tuning v2微調方法訓練模型,對生成的模型進行評估并選取效果最優的模型作為智能合約生成的大語言模型。
2.3.1 指令數據集預處理
聚類后的數據以代碼簇的形式輸出,每個代碼簇中含有較多高相似功能的智能合約代碼,因此需要對該數據進行二次預處理。首先刪除智能合約注釋中的無關內容,由于在聚類過程中進行了停用詞處理,并沒有進行相關代碼和注釋內容的修改,注釋中仍存在著“/**”“@dev”“@notice”等無意義內容,在這里將這些字符替換為空字符,并將注釋內容重新寫入從而保證內容的連貫性。其次,每個代碼簇中存在高相似度的智能合約代碼,為保證指令數據集的質量,對每個簇中數據進行相似度計算,對于相同的代碼則提取其中一個參與指令數據集的構建。鑒于對智能合約代碼數據集劃分了層次,因此與之相對應的單個注釋匹配字符量比較小,可以認為是短文本類型,這恰恰符合Jaccard的計算特性。另一方面,Jaccard是一種常用的相似度計算方法,相比于其他算法,計算量以及效率更為良好,在智能合約自適應匹配過程中,較好地降低了開發時間并且對于開發環境的要求更加友好。
故本文采用Jaccard[27]作為度量標準,計算簇中代碼的相似度。對于每個簇中代碼,分別計算注釋和代碼的相似度,當其中任意一者相似度高于0.9,則認為這兩段代碼功能重復。 本文給定兩個集合,如式(4)所示,ui為代碼簇,表示簇中第i個代碼,ci為注釋文本簇,表示簇中對應的第i個注釋,N為集合數量,相似度值為簇中代碼之間Jaccard度量值以及對應注釋內容Jaccard度量值最大值,當最大值>0.9,則認為是功能相同的代碼。
2.3.2 指令數據集構建
在上述預處理后,如圖2所示,本文中指令數據集為JSON格式的數據,數據模式如下:{“instruction”:“value1”,“input”:“value2”,“output”:“value3”},每條數據為包含instruction、input以及output三個鍵值對形式的JSON數據,其中instruction為Prompt模版,該部分設計了15個模仿使用者提問的方式,例如“請幫我生成{input}的相關代碼內容”“你現在是一個語言模型,幫我生成相關的智能合約代碼,注釋如下:input”等,盡量最大范圍達到使用者在獲取智能合約代碼的各種提問方式,從而提升大模型的輸出的準確性。
注釋是代碼的相關信息描述,對于代碼的易理解性發揮著至關重要的作用,研究者們往往忽略了這兩者的關聯性。由于大語言模型在自然處理領域引起了廣泛關注,如何更有效地提升Prompt指令質量也成為了研究熱點之一,智能合約代碼附有的注釋信息能夠為其帶來更加準確的描述。因此在提示指令工程中,本文加入了注釋信息同時隨機抽取一個模版構建微調數據集的指令,這也是本文研究的要點。眾所周知,目前大多數研究者在提問方式中通過GPT生成、人工構造等方式盡可能最大化涉及使用者可能會提問的各類問句,由于智能合約涉及金融、醫療等多個領域,其代碼和注釋信息中內容具有很強的現實含義,例如“token”代表貨幣,“address”代表使用者地址。結合這一內容,本文在智能合約指令的數據集的input部分加入了注釋信息來幫助大模型更好地學習智能合約領域的知識,如圖2所示,本文設計了多個提問模版,隨機與注釋信息搭配構成大模型學習的輸入內容,output部分為輸出信息,即大模型在接收使用者的需求信息后所回應的內容,在這里將注釋對應的層次化代碼作為數據集的輸出部分。
2.3.3 模型微調
自然語言處理目前存在一個重要范式,即一般領域的大規模預訓練對特定任務領域的適應。但隨著規模的變大,當進行特定任務適應時,由于訓練成本太高,無法重新訓練所有模型參數,所以研究者提出在原有模型基礎上進行一些垂直領域的微調,從而達到更優的效果。ChatGLM2-6B是由清華大學團隊發布的第二代大模型,具有高性能、強大的推理能力等特點。本文以該模型作為微調的基礎模型,同時采用了目前比較熱門的P-Tuning v2方法。
P-Tuning v2是P-Tuning的優化,利用多層提示(即深度提示優化),在每一層都加入了Prompts tokens作為輸入,而不是僅僅加在輸入層,因此具有更多可學習的參數以及對模型的預測更直接的影響。在本實驗中,學習率為1E-4 ,每訓練1 000步保存一次模型,梯度累積次數和GPU設備上批次大小都為1,詞表大小為1 560,設定模型接收的最大輸入長度為1 024,采用單卡進行訓練。
在微調訓練后,本文將訓練后的模型保存至相應文件夾中,ChatGLM2-6B官方源碼中提供了模型測試的可視化界面。因此本文將代碼中模型路徑更改為訓練后的模型,在測試界面對微調訓練的智能合約生成大模型進行測試。使用者在界面中輸入自己的需求信息,大模型根據接收內容返回相應的智能合約代碼內容。
3 實驗與結果分析
3.1 實驗環境及數據集
本文實驗是在算力服務器上完成的,顯卡為單卡A100,程序編寫和運行環境為Python 3.10、PyTorch 2.0以及CUDA 11.6。本文采用的數據集由自編爬蟲程序獲取,選取以太坊平臺(Ethereum)并爬取10 437個智能合約源程序,智能合約文檔的大小在1 KB~211 KB。本文將數據集進行初步的預處理,去除一些JSON、ABI等格式的智能合約,保留大小集中在50 KB~80 KB的1 737個智能合約文檔作為本文實驗的數據集。最后對數據集中智能合約源代碼進行“function”“contract”“interface”和“library”層次劃分以及注釋和對應代碼體劃分,并定義了聚類分析中所需要的停用詞文檔,同時設計了15個提示指令的模板。
本文首要步驟是獲取聚類的智能合約數據集,以太坊是目前應用最廣泛的區塊鏈交互平臺,其平臺公布了眾多獲得開源許可的智能合約源代碼,本文通過編寫智能合約源代碼爬蟲程序獲取該平臺最近一年的智能合約作為實驗數據集。具體操作流程如下:從以太坊平臺下載智能合約地址文件,借助自動化程序打開以太坊瀏覽器,讀取文件中地址構建智能合約源代碼頁面,從第一頁開始,循環更新內容,按照上述方法依次獲取每頁智能合約源代碼存儲至本地文件中,直至智能合約地址文件讀取完畢。
3.2 結果及分析
在完成聚類實驗后,本文獲取了618個智能合約代碼簇,每一個代碼簇包含較多相似的智能合約代碼,因此本文對簇中數據進行上述的相似度計算,選取一個代碼以及對應的注釋內容和指令模板隨機構成一條數據,數據量為782條。
為確保生成代碼的有效性,在微調后的大模型中,通過指令生成50條各層次智能合約代碼,本文采用BLEU指標對其進行評估。BLEU指標[28]是一種廣泛應用于機器翻譯任務的評測機制,在這里通過生成代碼文本和參考文本之間共同出現n元詞的次數(n-gram)衡量生成代碼的質量。n元詞中n取值為1~4,BLEU分數取值為0~1,如果兩個句子完美匹配,那么BLEU為1.0,反之,如果兩個句子完全不匹配, 那么BLEU為0.0。其中,BLEU機制評分如式(5)所示。
對于生成的代碼文本,為避免符號對評測分數的影響,本文將“+”“-”等非詞語統一替換為空格,同時根據Solidity語言特性將代碼文本通過空格進行分詞并得到BLEU分數。式(6)為提高率計算公式,P(x,y)為x相對于y的提高率。
本文針對各層次中生成的代碼分別采用BLEU機制測評,實驗后BLEU得分如表1所示,同時與文獻[14]進行了對比,采用式(6)計算提高率,x為本文實驗中合約層(contract)對應BLEU1~4得分,y為文獻[14]中BLEU1~4得分。從實驗結果可以看出,本文方法生成的代碼評分更高,本實驗得分相對于文獻[14],BLEU1~4得分分別提高了6%、3%、9%、7%。
另外,為驗證生成的智能合約的安全性和正確性,本文分別使用VaaS和Mythril安全檢測工具,對生成的智能合約的正確率進行檢測。在本實驗中,將代碼不完整、代碼編譯錯誤以及檢測不合格統一視為不正確的智能合約,實驗結果如表2所示。其中,第一列表示檢測的自動生成代碼類型,該實驗主要對比了六種類型:本文方法自動生成的函數層(function)代碼、合約層(contract)代碼、接口層(interface)代碼以及庫層(library)代碼、無注釋微調模型生成的合約層代碼、文獻[14]生成的合約層代碼;第二、三列分別表示VaaS和Mythril這兩類智能合約安全檢測工具測得的正確率。
由該實驗結果可以看出,在正確率上,合約層因為功能最全,涉及的元素最多,所以其正確率相對較低,但也達到了72%左右。而無注釋微調的模型,其生成合約代碼的平均正確率僅為65.3%。由于文獻[14]僅利用Vaas檢測了其生成代碼的安全性,所以本文僅比較了Vaas工具的檢測結果。根據結果可以看出,文獻[14]生成的智能合約的正確率為68.27%,根據式(6)計算可得,本文方法相對于文獻[14],正確率提升了(72.3%-68.27%)/68.27%=6%。
此外,本文模型同目前比較主流的代碼生成模型進行了對比實驗。本文選取ChatGPT 3.5、Code LLaMA以及ChatGLM2-6B作為評測衡量的模型,通過同樣的口令在各個模型中生成ERC20智能合約代碼,如表3所示,并將生成代碼分別與源代碼進行BLEU評分計算和對比。
從表3得分來看,各類大模型的低分說明在智能合約生成方面能力很差,無法生成復雜化的代碼。本文相比其他模型具有明顯的提升,評分貼近ChatGPT,生成代碼與源代碼接近度更高,效果更好。其次,本文生成的代碼提供了相關的接口代碼、庫合約代碼。整體來看,大多數通用類模型目前僅局限于單個合約代碼,結構較為簡單,不能滿足當前智能合約領域的多元化。另一方面,本文所生成代碼提供了眾多的注釋信息,這也是本文重點之一,注釋信息能夠幫助開發者快速高效地理解代碼,提高開發效率。
4 結束語
本文提出一種基于代碼注釋調優的智能合約自動生成方法,該方法通過爬取以太坊上智能合約源代碼作為數據集并進行層次化劃分和代碼注釋劃分。在聚類分析中,從注釋和代碼體兩個角度出發,有效地提取出各層次代碼中高相似度的代碼。同時,采用ChatGLM2-6B為基座模型,利用聚類后智能合約源代碼和注釋構建提示指令數據集,采用P-Tuning v2方式訓練智能合約自動生成模型,生成各類應用場景下的智能合約代碼。在智能合約的安全方面,本文采用BLEU評分機制和智能合約檢測工具檢測生成代碼的質量和安全問題,最后設計了便捷快速的可視化界面供開發者使用。實驗結果表明,本文方法生成的智能合約代碼質量和安全指標較好,相比于已有方法具有明顯的提高。
本文方法可有效應用于智能合約的自動生成,對于智能合約開發的效率性、安全性問題具有一定的研究意義,但也存在一定的不足。首先本文沒有針對特定領域智能合約開展研究,目前僅局限于各領域中常用的合約代碼,缺少對各個特定領域代碼的研究。其次,本文所采用的ChatGLM2-6B模型雖有明顯的提高,但后續可以考慮使用更多的大模型作為基座模型開展研究。最后,在數據方面,后續可以加大數據量規模以及考慮其他微調方法,并結合如何構建更高效的指令數據開展工作。
參考文獻:
[1]Tolmach P,Li Yi,Lin Shangwei,et al. A survey of smart contract formal specification and verification [J]. ACM Computing Surveys (CSUR),2021,54(7): 1-38.
[2]Iqbal T,Qureshi S. The survey: text generation models in deep lear-ning [J]. Journal of King Saud University-Computer and Information Sciences,2022,34(6): 2515-2528.
[3]Bas A,Topal M O,Duman C,et al. A brief history of deep learning based text generation [C]// Proc of International Conference on Computer and Applications. Piscataway,NJ:IEEE Press,2022: 1-4.
[4]Ma Tian,Wang Wanwan,Chen Yu. Attention is all you need: an interpretable transformer-based asset allocation approach [J]. International Review of Financial Analysis,2023,90: 102876.
[5]Sallam M. ChatGPT utility in healthcare education,research,and practice: systematic review on the promising perspectives and valid concerns [J]. Healthcare,2023,11(21):2819.
[6]潘興祿,劉陳曉,王敏,等. 基于概念傳播的軟件項目代碼注釋生成方法 [J]. 軟件學報,2023,34(9): 4114-4131. (Pan Xinglu,Liu Chenxiao,Wang Min,et al. Code comment generation based on concept propagation for software projects [J]. Journal of Software,2023,34(9): 4114-4131.)
[7]Geng Mingyang,Wang Shangwen,Dong Dezun,et al. Fine-grained code-comment semantic interaction analysis [C]// Proc of the 30th International Conference on Program Comprehension. Piscataway,NJ:IEEE Press,2022: 585-596.
[8]Xin W,Zhou Kun,Li Junyi,et al. A survey of large language models [EB/OL]. (2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2303.18223.
[9]Zeng Aohan,Wang Zihan,Du Zhengxiao,et al. GLM-130B: an open bilingual pre-trained model [EB/OL]. (2022)[2023-11-04]. https://doi.org/10.48550/arXiv.2210.02414.
[10]Touvron H,Lavril T,Izacard G,et al. LLaMA: open and efficient foundation language models [EB/OL]. (2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2302.13971.
[11]Hu E J,Shen Yelong,Wallis P,et al. LoRA: low-rank adaptation of large language models [EB/OL]. (2021) [2023-11-04]. https://doi.org/10.48550/arXiv.2106.09685.
[12]Li X L,Liang P. Prefix-tuning: optimizing continuous prompts for generation [EB/OL]. (2021) [2023-11-04]. https://doi.org/10.48550/arXiv.2101.00190.
[13]Liu Xiao,Ji Kaixuan,Fu Yicheng,et al. P-Tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks [EB/OL]. (2022)[2023-11-04]. https://aclanthology.org/2022.acl-short.8.
[14]Liu Xiao,Ji Kaixuan,Fu Yicheng,et al. P-Tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks [EB/OL]. (2021)[2023-11-04]. https://doi.org/10.48550/arXiv.2110.07602.
[15]Cui Jiaxi,Li Zongjian,Yan Yang,et al. ChatLaw: open-source legal large language model with integrated external knowledge bases [EB/OL]. (2023)[2023-11-04]. https://doi.org/10.48550/arXiv.2306.16092.
[16]Wang Haochun,Liu Chi,Xi Nuwa,et al. HuaTuo: tuning LLaMA model with Chinese medical knowledge [EB/OL]. (2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2304.06975.
[17]錢鵬,劉振廣,何欽銘,等. 智能合約安全漏洞檢測技術研究綜述[J]. 軟件學報,2022,33(8): 3059-3085. (Qian Peng,Liu Zhenguang,He Qinming,et al. Smart contract vulnerability detection technique: a survey [J]. Journal of Software,2022,33(8): 3059-3085.)
[18]高一琛,趙斌,張召. 面向以太坊的智能合約自動生成方法研究與實現 [J]. 華東師范大學學報: 自然科學版,2020,2020(5): 21-32. (Gao Yichen,Zhao Bin,Zhang Zhao. Research and implementation of a smart automatic contract generation method for Ethe-reum [J]. Journal of East China Normal University: Natural Sciences,2020,2020(5): 21-32.)
[19]Rani P,Birrer M,Panichella S,et al. What do developers discuss about code comments? [C]// Proc of the 21st IEEE International Working Conference on Source Code Analysis and Manipulation. Piscataway,NJ:IEEE Press,2021: 153-164.
[20]Mao Dianhui,Wang Fang,Wang Yalei,et al. Visual and user-defined smart contract designing system based on automatic coding [J]. IEEE Access,2019,7: 73131-73143.
[21]Xing Hu,Xin Xia,Lo D,et al. Practitionersexpectations on automated code comment generation [C]// Proc of the 44th International Conference on Software Engineering. Piscataway,NJ:IEEE Press,2022: 1693-1705.
[22]Rani P,Panichella S,Leuenberger M,et al. What do class comments tell us?An investigation of comment evolution and practices in Pharo [J]. Empirical Software Engineering,2021,26(6): 112.
[23]王潮,徐衛偉,周明輝. 軟件中代碼注釋質量問題研究綜述 [J]. 軟件學報. 2023,35(2): 513-531. (Wang Chao,Xu Weiwei,Zhou Minghui. Survey on quality of software code comments [J]. Journal of Software,2023,35(2): 513-531.)
[24]Zheng Qinkai,Xia Xiao,Zou Xu,et al. CodeGeeX: a pre-trained model for code generation with multilingual evaluations on Human-Eval-X [EB/OL].(2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2303.17568
[25]Roziere B,Gehring J,Gloeckle F,et al. Code LLaMA: open foundation models for code [EB/OL]. (2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2308.12950.
[26]Li R,Allal L B,Zi Yangtian,et al. StarCoder: may the source be with you! [EB/OL]. (2023) [2023-11-04]. https://doi.org/10.48550/arXiv.2305.06161.
[27]郭宏,伊亞聰,閆獻國,等. 基于Jaccard 的協同過濾刀具推薦算法 [J]. 太原科技大學學報,2023,44(5): 464-468,475. (Guo Hong,Yi Yacong,Yan Xianguo,et al. Collaborative filter tool recommendation algorithm based on Jaccard [J]. Journal of Taiyuan Uni-versity of Science and Technology,2023,44(5): 464-468,475.)
[28]Xia Min,Shao Haidong,Ma Xiandong,et al. A stacked GRU-RNN-based approach for predicting renewable energy and electricity load for smart grid operation [J]. IEEE Trans on Industrial Informatics,2021,17(10): 7050-7059.
