基于特征調節器和雙路徑引導的RGB-D室內語義分割
2024-06-01 08:37:35張帥雷景生靳伍銀俞云祥楊勝英
計算機應用研究 2024年5期
張帥 雷景生 靳伍銀 俞云祥 楊勝英

摘 要:針對室內場景圖像語義分割結果不精確、顯著圖粗糙的問題,提出一種基于多模態特征優化提取和雙路徑引導解碼的網絡架構(feature regulator and dual-path guidance,FG-Net)。具體來說,設計的特征調節器對每個階段的多模態特征依次進行噪聲過濾、重加權表示、差異性互補和交互融合,通過強化RGB和深度特征聚合,優化特征提取過程中的多模態特征表示。然后,在解碼階段引入特征交互融合后豐富的跨模態線索,進一步發揮多模態特征的優勢。結合雙路徑協同引導結構,在解碼階段融合多尺度、多層次的特征信息,從而輸出更細致的顯著圖。實驗在公開數據集NYUD-v2和SUN RGB-D上進行,在主要評價指標mIoU上達到48.5 %,優于其他先進算法。結果表明,該算法實現了更精細的室內場景圖像語義分割,表現出了較好的泛化性和魯棒性。
關鍵詞:室內語義分割;特征調節器;雙路徑協同引導;RGB-D特征
中圖分類號:TP391.41?? 文獻標志碼:A??? 文章編號:1001-3695(2024)05-044-1594-07
doi: 10.19734/j.issn.1001-3695.2023.07.0355
RGB-D indoor semantic segmentation based on feature regulator and dual-path guidance
Abstract:Aiming at the problems of inaccurate semantic segmentation results and rough saliency maps of indoor scene images, this paper proposed a network architecture (feature regulator and dual-path guidance, FG-Net) based on multi-modal feature optimization extraction and dual-path guided decoding. Specifically, the feature regulator sequentially performed noise filtering, re-weighted representation, differential complementation and interactive fusion on the multi-modal features at each stage, and optimized multi-modal feature representation in the feature extraction process by strengthening RGB and depth feature aggregation. Then, the dual-path guidance component introduced rich cross-modal cues after feature interactive fusion in the decoding stage to further take advantage of multi-modal features. The dual-path cooperative guidance structure outputted a more detailed saliency map by integrating multi-scale and multi-level feature information in the decoding stage. This paper conducted experiments on the public datasets NYUD-v2 and SUN RGB-D, and achieved 48.5% in the main evaluation metric mIoU, which is better than other state-of-the-art algorithms. The results show that the algorithm achieves more refined semantic segmentation of indoor scene images, and has good generalization and robustness.? Key words:indoor semantic segmentation; feature regulator; dual-path cooperative guidance; RGB-D features
0 引言
近年來,語義分割作為一種有效的室內場景分析和處理的技術手段,被廣泛應用于移動機器人、監控和智能家居等領域,為這些應用提供了有用的語義信息。然而,室內場景存在光線環境暗淡、物品雜亂等現象,這些因素影響了基于RGB圖像進行室內場景語義分割的準確性,導致語義分割結果不理想。深度攝像機的使用提供了獲取深度信息作為互補幾何線索的條件,深度信息能夠有效補充RGB圖像的信息,提高模型對場景的理解和分析能力。然而,如何增強兩種不同模態的特征表示,并有效利用互補信息實現跨模態信息融合是具有挑戰性的任務。因此,許多學者致力于研究有效的策略來應對這些挑戰,以釋放多模態信息的全部潛力。在解決多模態信息差異性問題的過程中,學者進行了多種嘗試。一些學者為RGB-D 數據設計了特定的體系結構,在多模態信息交互時,通過制定不同的策略融合兩種數據,以獲得更有效的跨模態線索。還有一些學者利用數據增強的方式,在特征提取階段設計了專門的卷積層來增強RGB和深度信息。例如,Chen 等人[1]設計了一種門融合方法,在雙流特征融合時通過多模態特征的重要性獲得特征權值,利用特征權值對特征進行篩選和增強。Fernando等人[2]通過多任務聯合優化引導語義分割,并提出了隨機多目標梯度校正方法來增強多目標學習過程。Sun 等人[3]提出了一種有效的多任務剪枝和稀疏性訓練方案,通過對多個任務進行重要性度量來實現一致決策。Popovic'等人[4]在處理多模態特征時,通過選擇空間條件解決了空間多條件標簽的異質性和稀疏性問題。Wu 等人[5]設計了一個深度適應偏移模塊,利用深度線索指導 RGB 圖像上的特征提取,并將深度信息進一步整合到RGB卷積神經網絡中。Dong 等人[6]提出了一種輕量級的帶有點監督的邊界細化模塊,以提高現有分割模型生成的顯著圖的邊界質量,并實現更好的邊界特征提取。Cao 等人[7]引入了形狀感知卷積層處理深度特征,通過對深度特征分解和重加權組合增強特征表示。在以往基于RGB-D信息的室內場景語義分割研究中,由于深度圖像采集設備自身的缺陷,生成的圖像在物體邊界含有大量的噪聲,成像物體的顯著性也會隨著距離的變遠迅速降低。針對這個問題,Wu 等人[8]嘗試僅獲取少量的高顯著深度線索,將深度信息作為輔助手段融入到RGB信息中。Seichter 等人[9]直接在編碼器階段將深度信息加到RGB信息中,將模型重心轉移到解碼器階段。Li 等人[10]通過小容量適配器將多任務與網絡對齊,從而將多任務網絡的知識提取到單一網絡。文獻[9,11,12]中,研究人員制定深度信息和RGB信息融合的策略時,往往只是將兩種信息進行相加或相乘合并,亦或只在解碼階段將模型注意力傾向于跨模態信息,直接輸出顯著圖結果。上述算法在物體布局規整和空間結構簡單的場景下具有非常不錯的表現,但在室內場景物體體型小、互相遮擋,以及空間布局復雜時,語義分割算法精度會變低,顯著圖粗糙。簡單的整合多模態特征的互補性不能進一步提高室內語義分割的準確性。深入挖掘和利用深度線索,將兩種不同的統計數據整合到模型架構中,成為提高算法性能的關鍵。基于以上問題,本文提出的FG-Net采用了兩個獨立的ResNet50[13]骨干網絡分支分別進行深度特征和RGB特征提取,并在編碼器階段設計了一個特征調節器來優化特征提取過程,同時對多模態信息進行特征增強。該部件具有特征強化聚合、特征差異性互補和特征交互融合三個功能,能夠充分挖掘多模態線索并將它們緊密結合在一起,使得模型可以更加全面地學習多模態信息,提高對場景的語義分割能力。同時,本文設計了一個雙路徑協同引導結構,通過融合不同層次、不同尺度的特征強化解碼過程,并利用不同階段特征的特性進行雙向引導,進一步細化顯著圖結果。實驗數據表明,使用特征調節器和雙路徑引導結構可以顯著增強模型的魯棒性,尤其是在處理室內復雜場景時,模型的細節分割能力和語義識別能力較目前算法有顯著提高。
1 本文模型與方法
1.1 模型架構
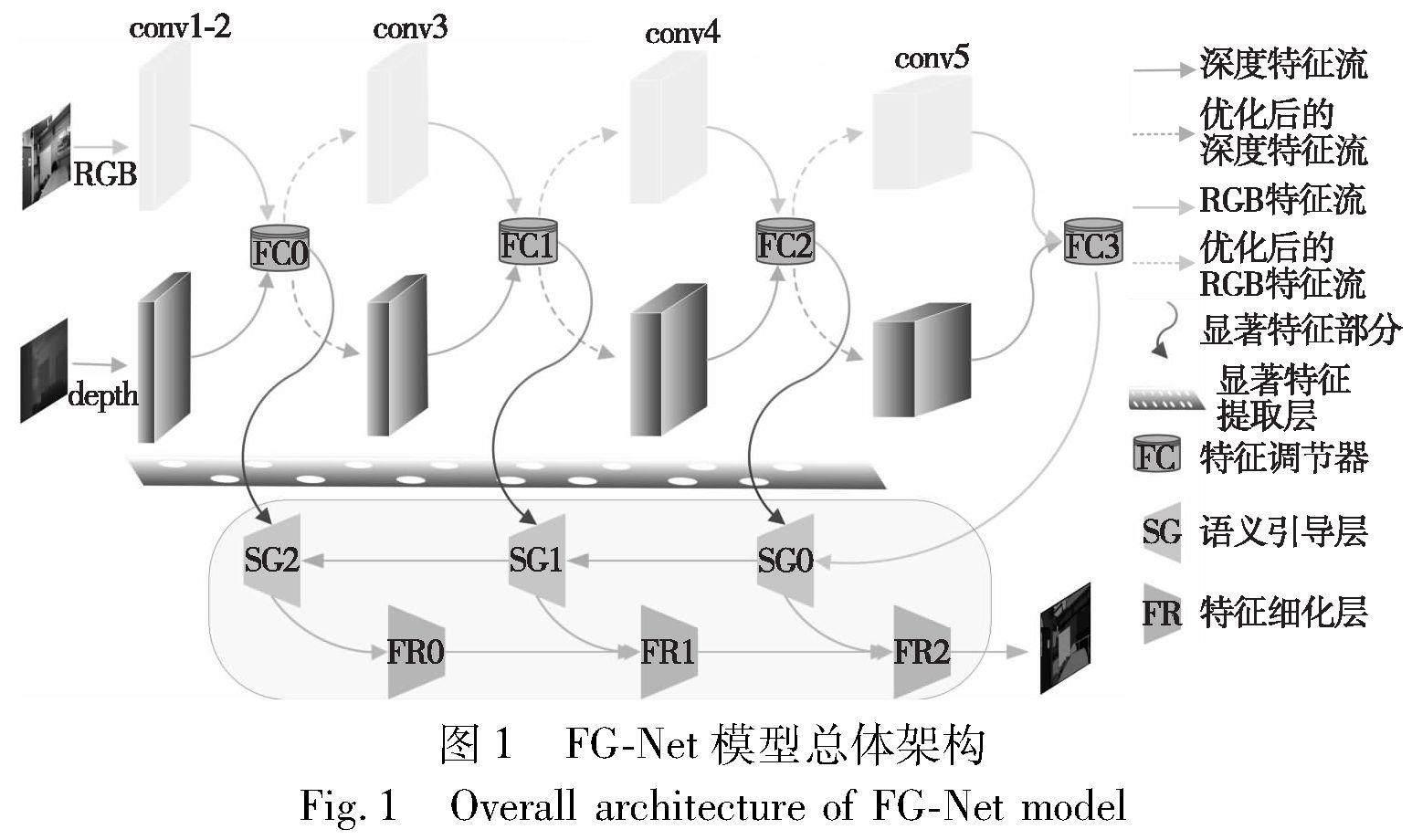
首先介紹了FG-Net的網絡框架,然后描述了本文設計的特征調節器各個組件,以及雙路徑引導結構創新角度和解決的問題。最后,闡述了各個模塊的工作流程和具體內容。如圖1所示,本文采用編碼器-解碼器結構,使用兩個獨立的分支從RGB圖像和深度圖像中提取特征。這種設計既便于在特征提取階段根據不同的模態特性設計針對性的特征處理方式,也可以使得每個模態的編碼器專注于各自特征的提取。由于RGB圖像與深度圖像的特征存在顯著差異,為了充分發揮多模態特征的特性,本文設計了特征調節器優化特征提取過程。首先,考慮到深度相機成像時在物體邊界附近區域以及遠距離物體的表面區域會出現很多噪聲,特征強化聚合模塊通過全局平均池化和卷積操作獲得跨模態信息的全局表達和權重表示,并依據其中顯著部分信息對噪聲進行過濾,將過濾后的特征映射與交叉信息進行信道相乘,實現多模態特征的重加權表示,從而降低噪聲干擾,增強特征表達。之后,為了充分發揮RGB特征和深度特征各自的優勢,特征差異性互補模塊利用池化和卷積操作對多模態信息進行特征質量評估,并選取顯著部分補充到特征融合階段,通過特征重建增強多模態特征優勢。最后,不同于以往直接將兩種模態信息相加或相乘的融合方法,特征交互融合模塊從通道角度對兩種模態特征進行切割、重組和交互。通過混合和連接兩種類型的特征,并用歸一化的卷積層、ReLU函數優化特征,以及調整通道數量,得到緊密聚合的特征表示,從而更深層次地結合多模態信息,并在特征傳遞時突出有用的線索。此外,考慮到編碼時各個階段的融合特征具有不同的層次體現,雙路徑協同引導結構通過跳躍連接的方式以及上采樣和卷積操作,結合不同層次、不同尺度的融合特征引導解碼過程,進一步細化語義分割顯著圖的輸出。
RGB特征和深度特征經過特征調節器處理后,得到優化后不同尺度的融合特征FC0、FC1、FC2和FC3,這些融合特征依次傳遞到下一階段的分支進行特征提取。在這個過程中,RGB-D特征經過特征強化聚合模塊不斷優化,而后通過互補和不斷重組的方式,突出其包含的有效線索。隨后,將每次的融合結果傳遞到解碼階段,結合本文提出的雙路徑協同引導結構,獲得語義引導層的輸出SG0、SG1和SG2。接著,將語義引導層的輸出傳遞到特征細化層,得到細化的輸出FR0、FR1和FR2,并最終輸出顯著圖。
1.2 特征調節模塊基于RGB-D跨模態信息的場景語義分割,主要的挑戰在于如何充分發揮多模態特征的優勢,尤其是在物體之間存在大量遮擋的室內環境中。這要求算法既要進一步獲取有效的線索,又要高效利用獲取的多模態信息。本文設計的特征調節器通過對多模態特征進行過濾、強化、重建增強和交互融合,可以獲得更豐富和有效的多模態信息。特征調節模塊由特征強化聚合、特征差異性互補和特征交互融合三個部分組成。
1.2.1 特征強化聚合
RGB數據和深度數據的特征存在顯著差異,如何有效處理兩種特征是首先要考慮的問題。此外,雖然深度圖像包含大量幾何線索,但由于深度傳感器的物理特性,深度相機在采集物體信息時,性能會隨著距離的擴大迅速地降低,導致物體邊界附近區域以及遠距離物體的表面區域會出現很多噪聲。這些噪聲會干擾特征提取過程,降低語義分割的精度。針對這個問題,在本文中,特征提取網絡先通過特征強化聚合進行局部區域的噪聲信號過濾和重加權強化表示,這樣可以有效減少特征傳播過程中誤導性信息的出現,降低噪聲的干擾。而且,通過強化特征進一步挖掘可利用線索,可以在特征融合時提供更多的對齊基準,進而提高語義分割的準確性。
模塊設計原理如圖2所示。本文利用RGB模態中的高自信激活部分輔助優化深度特征的提取,過濾掉低級別的異常深度激活信號。具體來說,首先從通道角度對兩種特征進行全局平均池化,獲取兩種模態的全局空間信息,并通過這些信息獲得跨模態優化的注意力向量:
φ=GAP(RGBin‖Depthin)(1)
其中:‖ 表示兩種模態信息的特征映射的連接;GAP表示全局平均池化;φ 描述了跨模態信息全局的表達,用于展示整個輸入的表達性統計信息。之后,將兩種模態的特征映射輸入到MLP操作中,通過將權重值變換為(0,1)的sigmoid函數對整個輸入的信息進行表達性統計:
Wdepth=δ(FMLP(φ))(2)
其中:FMLP(φ) 表示MLP網絡;δ 是輸入信息經sigmiod函數將權重值轉換為(0,1)值。這樣,神經網絡在學習過程中就可以通過光感特征和幾何特征中最具有表達性和顯著性的部分對深度流中異常的噪聲信息進行過濾。然后,通過將過濾后的深度特征映射與輸入到MLP中的交叉信息進行信道相乘,獲得過濾后的深度表示,即過濾后的深度信息為
這樣,就可以獲得高質量的深度特征,這些更精確的深度特征在特征融合時會成為更精準的對齊基準,從而增強對RGB特征的響應。同樣地,利用過濾后的深度信息中的高自信激活部分,對RGB圖像中的異常噪聲進行抑制。在實踐中,本文采用這種對稱和雙向的方式重新校準不同模態信息,進而實現特征的強化聚合。
1.2.2 特征差異性互補
不同模態的特征具有不同的特性,例如RGB圖像具有豐富的紋理、色彩等信息,深度圖像則包含大量的幾何線索。雙流網絡在特征提取時關注的注意力方向會因模態特性不同而不一致,而兩者又具有強相關性。為了充分發揮多模態信息的優勢,利用彼此的相關性,本文先對存在差異性的兩種特征按通道分組,利用卷積操作進行權重分級,求得特征顯著性,從而實現特征質量評估。然后,選取顯著部分(經過概率轉變后,大于0.5顯著因子)補充到特征融合階段,與融合后的交互信息實現特征重建增強。這種增強方式針對的是不同模態中最顯著的部分,既可以進一步發揮各自的優勢,還能夠進一步豐富跨模態線索,從而輸出更加細化的顯著圖。消融實驗的結果和對比實驗中模型可視化圖部分驗證了這種互補方法的有效性。具體的關于差異性信息互補性的衡量則是通過下文中特征質量評估方法IDM實現的。
特征差異性互補模塊如圖3所示。首先將兩個編碼器輸出的RGB特征和深度特征輸入到IDM模塊進行特征質量評估。然后,對單模態特征的貢獻基于評估的結果進行重加權表示,以促使神經網絡在特征提取過程中將注意力偏向于特征圖顯著且具有各自代表性的區域。
然后,求得I(i) 的平均值β 作為F(i) 的顯著因子,通過softmax函數歸一化顯著因子B=(β1,…,βk)T,就可以得到給定特征的質量評估結果。下一步,選取特征最顯著部分(大于0.5顯著因子)進行特征增強得到 Fb,并通過卷積操作得到顯著特征的特定表示 Fp。
至此,可以獲得兩種模態信息中最顯著的部分,同時,也是最具有代表性和差異性的部分。進一步地,將獲取的顯著信息補充到特征交互融合階段,進行重建增強,以實現對多模態特征的充分探索和利用。
1.2.3 特征交互融合在特征融合階段,將兩種模態信息統一為一種高效的表示形式是非常有挑戰性的任務。不同于以往直接將兩種模態信息相加或相乘的融合方法,考慮到室內環境的復雜性,需要進一步突出多模態線索,以輸出更細致的顯著圖。本文設計了一種特征重組-交互的方式,在多模態特征傳遞時,通過交叉組合,將不同模態的特征緊密結合在一起來突出有效線索。這種交互融合的方式從更深層次結合多模態特征,可以獲得更豐富、更準確的校準信息,使得模型能夠更加全面地學習多模態信息,從而提高其對場景語義分割的準確度。
本文方法從通道角度對兩種模態特征進行切割、重組和交互,更深層次地結合深度特征和RGB特征,不僅強調了不同模態中的一致重要信息,還充分探索了不同層次之間的跨模態有效線索。多模態特征交互融合模塊如圖4所示。首先將兩種模態特征fri 和ftj 按信道方向平均分成兩部分,得到fij,在形式上為
fri,tj=Cat(fri,ftj)? i=1,2; j=1,2
fri,rj=Cat(fri,ftj)? i=1; j=2
fti,tj=Cat(fri,ftj)? i=1; j=2(11)
其中:Chunk是沿通道軸分裂的操作;Cat是沿通道軸連接的操作。之后,將四個特征按信道方向成對拼接,得到多方位特征。同時,通過計算不同模態中每一對特征的乘積,強調了一致的重要信息,具體的過程是:
然后,為了進一步探索跨模態線索,混合這兩種類型的特征,將它們連接起來,用歸一化(BN)的卷積層和ReLU函數來優化特征 Frti 并調整通道數量。這樣,就可以得到緊密聚合的特征 Fi 。
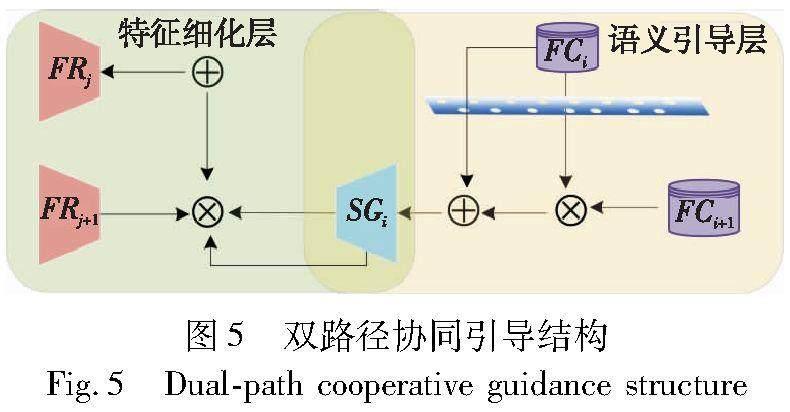
1.3 雙路徑協同引導結構基于文獻[14],不同階段的特征是整個對象不同層次的體現。高層特征具有豐富的綜合性和邊緣性的語義信息,底層特征受限于感受野的因素,具有豐富的局部性細節信息。為了追求更豐富的跨模態線索,本文設計了一種多階段多尺度相互引導融合的機制,充分利用不同階段的語義信息特點,優化多層次多模態特征聚合的結果。具體實現的過程是將交互融合后的特征提供給雙向引導組件。雙向引導組件致力于發揮不同階段、不同尺度特征的特點,利用高層具有的豐富的語義信息,先自頂向下引導和底層特征的融合,之后,利用融合后的具有豐富細節信息的底層特征細化高層特征輸出。通過兩個路徑聚合多尺度多層次特征,輸出精確的語義分割結果,實驗結果證明了這種解碼機制更適合本文設計的框架結構。
雙路徑協同引導結構的工作流程如圖5所示。
在解碼階段,首先獲取融合特征的顯著部分,方法與特征差異性互補模塊中的方法一致,通過上采樣,將特征調節器的輸出與前一層獲取顯著特征相融合,由此獲得融合后的特征SGi (i=0,1,2)。然后,通過下采樣,將引導后的底層特征FRj (j=0,1,2)與下一階段的高層特征SGj+1相融合,輸出最終的語義分割顯著圖。
整個相互引導機制可以分為語義引導層(SG)和特征細化層(FR)兩個部分。在語義引導層,先提取融合特征 FCi 的顯著部分,并通過一個3×3卷積運算對該部分進行優化,得到輸出 FCni。之后,經過特征調節器輸出的高層特征 FCi+1 通過1×1卷積和平均池化操作后與前者進行元素點乘,接著,FCi+1 在經過上采樣和3×3卷積運算后與點乘結果累加,輸出引導后的特征 SGi,該步驟依次迭代至語義引導層結束。在特征細化層,底層特征 FRj-1 先經過3×3卷積操作后與 SGi 進行元素點乘,之后,點乘結果與 SGi 累加并通過1×1卷積輸出細化后的特征 FRj。其中,所有的卷積操作都是在ReLU激活下進行的,整個流程可以描述為
2 實驗針對基于RGB-D信息進行室內語義分割容易出現顯著圖粗糙、語義分割結果精度低的問題,本文提出了一個基于RGB-D信息的室內場景語義分割模型,其在光照條件惡劣、空間結構復雜以及物體堆疊等室內場景下可以獲得更好的分割結果。本文在公開的室內場景數據集NYUD-v2[15]上進行了大量的對比和消融實驗,NYUD-v2數據集包含了各種室內環境,可以驗證算法的性能。此外,為了驗證算法的魯棒性,本文在SUN RGB-D[16]數據集上進行了對比實驗,作為算法性能檢驗的補充。SUN RGB-D數據集包含了NYUD-v2數據集的所有圖片,還額外具有8 886張室內場景圖像,通過在此數據集上進行對比實驗,驗證了本文算法不僅在一個特定的數據集上表現良好,而且在不同數據集的場景下仍能保持較高的準確性,這種一致的表現可以被認為是算法魯棒性的一個指標。通過與最近發表的最先進算法進行比較,本文算法在NYUD-v2和SUN RGB-D數據集上都取得了最佳結果,證明了算法的先進性和模型的魯棒性。此外,本文還進行了嚴謹細致的消融實驗,驗證了每個方法和模塊的可行性。
2.1 實驗細節
本文實驗平臺使用 PyTorch,所有實驗在一臺內存為24 GB的 GeForce RTX 3090 上運行。在參數設置方面,本文對設計的模型進行了300個epoch的學習,batch size為6,使用 SGD 作為優化器,在模型訓練的300個 epoch 中,設置動量參數為0.9,初始學習率為 5E-3,并隨著訓練輪數增加遞減學習率,利用當前訓練輪數與總訓練輪數的比例控制學習率遞減速度,并以0.9的指數進一步調整學習率的遞減速度。為了防止過擬合,設置權重衰減為0.000 5。在數據預處理方面,本文采用了類似于文獻[8,9,17~19]的數據增強方法,包括隨機水平翻轉、隨機縮放和隨機裁剪等技術。在每一輪的訓練中,將數據集的輸入設定為480×640的分辨率,RGB特征和深度特征先經過特征強化聚合模塊實現噪聲過濾和特征的重加權表示。之后,特征差異性互補模塊利用特征質量評估,選取具有代表性的差異性信息補充到不同模態,并將重建的特征采取重組交互的方式進行特征融合。此外,獲取融合后特征的顯著部分信息補充到雙向引導組件,以進一步發揮多模態特征的優勢。在解碼階段,通過雙重引導解碼的方式融合不同層次、不同尺度的特征,輸出更細致的語義分割圖。
2.2 數據集和評估指標實驗細節本文在具有說服力和挑戰性的NYUD-v2數據集上對本文方法進行評估和對比,并在SUN RBG-D數據集上進一步驗證了本文方法的泛化性和魯棒性。NYUD-v2數據集由各種室內場景的視頻序列組成,總共包括1 449張室內空間RGB-D圖像,在數據集制作時,本文選擇其中 795 張圖像作為訓練集,另外 654 張圖像作為測試集,采用通用的標簽設置,所有的標簽都映射到40個類。SUN RGB-D數據集包含了NYUD-v2數據集的所有圖片,具有10 335張室內場景RGB-D圖像,本文采用包含5 285張圖片的官方訓練集進行訓練,以及包含5 050張圖片的官方測試集對模型進行評估。在評價指標方面,本文采用了近期研究[9,11,17,18,20,21]中廣泛使用的三個指標,即類別平均精度 (mAcc)、平均交并比 (mIoU) 和像素準確率 (pixel Acc.)。
2.3 對比實驗本節評估了本文模型在 NYUD-v2 數據集上的性能,并通過可視化部分場景的語義分割結果,與目前先進的算法進行比較。表1 顯示了使用 ResNet-50 作為骨干與最先進模型在 NYUD-v2 數據集上的性能比較,圖6分別展示了RGB、depth和GT圖像,以及RGB單模態、FuseNet、ACNet、ESANet、RedNet和本文模型的可視化結果。
圖6中的場景包括燈光昏暗的臥室、空間狹小的浴室、物體體型較小的廚房、擺放雜亂的玩具房、長焦鏡頭拍攝的書桌、廣角鏡頭拍攝的餐廳,以及包含動態人物的場景。這些場景覆蓋了曝光、物體遮擋、物體重疊、燈光昏暗、物體細小和布局緊密等復雜環境。本文模型在這些不同場景的室內環境下都能夠產生更精細和準確的分割結果。從以上展示的可視化結果可以直觀地看到,本文算法在細節分割方面優于其他方法。在沒有深度信息的情況下,RGB單模態分割結果的性能較差,特別是對物體邊緣的分割效果很差,很難準確識別物體語義。這是因為在沒有深度信息的情況下,很難從RGB圖像中提取出空間深度信息,因此很難進行精確的物體分割。FuseNet通過結合深度信息,提升了物體邊緣的分割效果,但是由于其使用反卷積操作,導致生成的圖像會產生棋盤效應和顆粒感,從而影響分割結果的精度和細節表現。ACNet和RedNet通過上采樣等措施緩解了這種效應,但從用戶的角度來看,仍然會產生較為模糊不清的分割圖像。與之相比,ESANet的模型采用了中間融合策略和跳躍連接等方式,可以更好地提取RGB和深度特征,并進一步利用跨模態線索來優化分割結果的幾何層面。然而,ESANet在準確分割和噪聲去除方面仍有待進一步優化。本文模型能夠更加準確地分割出堆疊的物體、識別在強曝光場景下的物體,并且在分割不同距離物體時表現更佳。特別是在物體邊緣處理方面,本文模型的細化分割效果也是最好的。這得益于對多模態特征的優化提取和深層次整合,從而獲取了更多有效的跨模態線索,進一步增強了幾何層面的語義分割結果。這種方法在環境復雜、光照條件惡劣的室內場景中能夠實現更好的場景語義分割。在NYUD-v2數據集上進行的對比和消融實驗都證明了本文模型具有良好的魯棒性和先進性。本文模型與目前最先進的語義分割方法在 NYUD-v2 數據集上,基于 mAcc、mIoU 和 pixel Acc. 三個主要評價指標進行了語義分割性能比較。如表1 所示(本文使用官方的開放源代碼復現了部分模型,所有的實驗設置都與本文模型參數一樣),本文提出的特征調節器和雙路徑協同雙向引導解碼方式的訓練結果能夠媲美目前先進的算法,在 ResNet-50 的 backbone 上,mIoU結果可以達到 48.5% 。其中,本文模型比目前先進的語義分割算法 REDNet[18] 在主要指標 mIoU 上提高了 4.5%,比 ACNet[17] 提高了 4.7%,比 ESANet[1]提高了 1.2%。這些算法有的專注于多模態特征融合策略,有的專注于特征提取過程,各自研究的方法都達到了很好的效果,但在場景語義分割的結果上還有所欠缺。本文的研究同時考慮了這兩個過程,在多模態特征融合過程中采用中期融合的策略優化特征提取,將高質量的多模態線索傳遞到神經網絡深層,同時連接到解碼過程,再通過不同階段特征雙向引導的方式完成了更精準的室內場景分析。本文還與一些其他 backbone 的模型進行比較,在分割性能方面依舊優于基于 Transformer 的 AdaPoinTr 的 44.1%精準度,對比多任務學習模型 TLAM 的結果提高了 10.2%。其中,FuseNet、ACNet、REDNet 和 ESANet 模型的分割結果是在與本文模型相同的環境配置下進行的模型復現,這種比較方式更有說服力。
此外,如表2所示,本文算法還與更深層次的算法網絡進行了比較,即使使用更少的神經網絡層數,依舊能夠提高場景解析的性能,在主要指標mIoU上高于使用ResNet152結構的 RDFNet和CFNet的47.7%,相較于RefineNet提高了2.6%。這表現出本文模型在網絡設計和參數設置方面的優越性,使其能夠更加有效地利用特征信息,在減少網絡計算和存儲成本的同時,實現更準確的語義分割結果。
為了進一步驗證本文算法的泛化性和魯棒性,在更大的數據集SUN RGB-D上與目前先進的語義分割算法進行了比較,實驗結果如表3所示。由于數據集龐大,本文在實驗參數設置時只進行了200個epoch的訓練,其他參數設置與NYUD-v2數據集實驗一致。本文算法在該數據集上,即使面對更惡劣的光照條件和更復雜的室內環境,主要指標mIoU依舊達到了最高的47.6%,相較于RefineNet提高了1.9%,比SGNet提高了0.5%。其證明了在不同類型的對象下,本文提出的特征調節器可以充分發揮多模態特征各自的優勢,并通過雙路徑引導結構,充分利用各個層次模態的特點,在不同數據集上能夠實現更高的語義分割精度,輸出更細致的室內語義分割顯著圖。
2.4 消融實驗為了驗證提出的特征調節器和雙路徑協同引導結構的效果,本文基于NYUD-v2 數據集,在相同的環境配置和超參數下進行了消融實驗。在消融實驗中,采用了mAcc、mIoU 和 Pixel Acc. 這三個評價指標,對比了特征調節器、雙路徑協同引導結構以及兩者結合的模型,并且針對不同的特征融合策略進行了比較。
本文設計的特征調節器主要由三個部分組成,分別是能夠過濾噪聲的特征強化聚合模塊、能夠提取顯著區域信息的特征差異性互補模塊,以及可以緊密結合多模態信息的特征交互融合模塊。為了驗證特征調節器的性能,分別對三個模塊進行了消融實驗,結果如表4所示,以主要評價指標 mIoU 為評價標準,其可視化結果如圖7所示。
從表4中可以看出,初始模型的語義分割結果為45.5%。在多模態特征未經過特征強化聚合模塊進行特征篩選和強化的情況下,將多模態特征重組交互后模型的性能提高了0.7%。即使目前網絡中存在異常噪聲,特征重組仍舊能緊密結合兩種模態信息,提高模型的魯棒性。第5行的結果是加入特征強化聚合模塊后的模型輸出結果,性能提高了0.9%。這說明在排除異常噪聲后,神經網絡對室內場景學習和分析的能力得到了大幅提高。這一點還可以體現在第6行與第8行結果的對比上,因為更多有效幾何信息的加入,模型語義分割的能力在特征經過噪聲過濾和強化聚合后得到了顯著的提升。為了更好地探索和利用多模態信息的優勢,本文將兩種單模態各自具有特性的部分延展到特征融合的階段,通過傳播多模態特征的差異性到網絡中,實現跨模態傳播共享特征和特定特征,以彌補缺少的特定信息并增強共享特征。通過特征重建增強,模型語義分割準確率提高了1.4%。該方法不需要對樣本相似性進行建模,也無須接收鄰近模態信息,從而大大減少了計算量和參數。第3行與第6行的對比結果驗證了本文策略的正確性。
本文針對 ResNet50架構設計了雙路徑協同引導結構,通過聚合不同尺度的多模態特征和融合不同時期不同層次的特征表現,在挖掘和利用跨模態線索方面取得了非常好的效果。同時,考慮到初始數據對深度學習過程的指導作用非常重要,特別是隨著深度網絡的加深,這一作用愈加重要。因此,本文使用了類似于跳躍連接的方式對特征數據進行跨結構傳輸。不同的是,本文算法不直接傳輸數據,而是先對多模態特征融合結果進行顯著信息提取,然后將提取的顯著信息與解碼過程中的特征信息進行多步驟的乘法和加法處理,從而取得了最好的實驗結果48.5%。表4中第7行和第8行的結果表明,對融合特征進行顯著性提取,確實可以進一步提高語義分割效果。
基于特征融合是多模態信息的重要環節,本文設計的多模態特征交互融合方法與目前比較流行和公認的特征融合方法結果進行了對比。表5的實驗結果表明,本文算法在通道方面的獨特設計,使其比基于RGB-D對應元素總和(即基線)、卷積注意力(CBAM)和SE注意力機制的特征融合方法性能表現更好。這驗證了通過特征重組交互的方式,可以有效地緊密結合多模態特征。本文還展示了這幾種不同特征融合方式的語義分割圖,如圖8所示。通過獲取更豐富的跨模態線索,本文模型語義分割的結果在物體邊緣分割和重疊物體區分等精細分割部分有更好的表現。
3 結束語
本文從多模態特征在神經網絡中的提取和傳遞過程出發,針對現有語義分割算法難以妥善處理多模態數據、無法高效融合多模態特征的問題,提出了一個特征調節器,用于優化特征提取和傳遞過程。該組件在編碼器階段通過對雙流特征進行篩選實現噪聲去除,并通過特征差異性互補的方式實現共享特征和特定特征在神經網絡中的傳輸,同時結合交互融合的方式進一步獲取跨模態信息。在解碼階段,本文設計了雙路徑協同引導結構,用于融合多尺度、多層次的特征信息,并通過傳遞融合特征的顯著部分到解碼階段,進一步提高了語義分割的準確率。相對于以往方法,本文方法在公開數據集NYUD-v2上的性能取得了更好的結果。
參考文獻:
[1]Chen Xiaokang,Lin K Y,Wang Jingbo,et al. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation [C]//Proc of European Conference on Computer Vision. Cham: Springer International Publishing,2020: 561-577.
[2]Fernando H,Shen Han,Liu Miao,et al. Mitigating gradient bias in multi-objective learning: a provably convergent approach [C]// Proc of the 11th International Conference on Learning Representations. 2022.
[3]Sun Xinglong,Hassani A,Wang Zhangyang,et al. DiSparse: disentangled sparsification for multitask model compression [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 12372-12382.
[4]Popovic' N,Chakraborty R,Paudel D P,et al.Spatially multi-conditional image generation [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE Press,2023: 734-743.
[5]Wu Zongwei,Allibert G,Stolz C,et al.Depth-adapted CNNs for RGB-D semantic segmentation [EB/OL]. (2022-06-08) [2023-07-29]. https://doi. org/10. 48550/arXiv. 2206. 03939.
[6]Dong Zihao,Li Jinping,Fang Tiyu,et al. Lightweight boundary refinement module based on point supervision for semantic segmentation [J]. Image and Vision Computing,2021,110: 104169.
[7]Cao Jinming,Leng Hanchao,Lischinski D,et al. ShapeConv: shape-aware convolutional layer for indoor RGB-D semantic segmentation [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2021: 7088-7097.
[8]Wu Zongwei,Gobichettipalayam S,Tamadazte B,et al.Robust RGB-D fusion for saliency detection [C]// Proc of International Conference on 3D Vision. Piscataway,NJ: IEEE Press,2022: 403-413.
[9]Seichter D,Khler M,Lewandowski B,et al. Efficient RGB-D semantic segmentation for indoor scene analysis [C]// Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ: IEEE Press,2021: 13525-13531.
[10]Li Weihong,Liu Xialei,Bilen H. Universal representations: a unified look at multiple task and domain learning [J/OL]. International Journal of Computer Vision. (2023-11-24). https://doi.org/10.1007/s11263-023-01931-6.
[11]Hazirbas C,Ma Lingni,Domokos C,et al. FuseNet: incorporating depth into semantic segmentation via fusion-based CNN architecture [C]// Proc of the 13th Asian Conference on Computer Vision. Berlin: Springer International Publishing,2017: 213-228.
[12]Chen Linzhuo,Lin Zheng,Wang Ziqin,et al. Spatial information guided convolution for real-time RGBD semantic segmentation [J]. IEEE Trans on Image Processing,2021,30: 2313-2324.
[13]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 770-778.
[14]Zeiler M D,Fergus R. Visualizing and understanding convolutional networks [C]// Proc of the 13th European Conference on Computer Vision. Cham: Springer,2014: 818-833.
[15]Silberman N,Hoiem D,Kohli P,et al. Indoor segmentation and support inference from RGB-D images [C]// Proc of the 12th European Conference on Computer Vision. Berlin: Springer,2012: 746-760.
[16]Song Shuran,Lichtenberg S P,Xiao Jianxiong.Sun RGB-D:a RGB-D scene understanding benchmark suite [C]// Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 567-576.
[17]Hu Xinxin,Yang Kailun,Fei Lei,et al. ACNet: attention based network to exploit complementary features for RGB-D semantic segmentation [C]// Proc of IEEE International Conference on Image Proces-sing. Piscataway,NJ: IEEE Press,2019: 1440-1444.
[18]Jiang Jindong,Zheng Lunan,Luo Fuo,et al. REDNet: residual encoder-decoder network for indoor RGB-D semantic segmentation [EB/OL]. (2018-06-04) [2023-07-29]. https://doi. org/10. 48550/arXiv. 1806. 01054.
[19]Park S J,Hong K S,Lee S. RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 4980-4989.
[20]Abbasi K,Razzaghi P. Incorporating part-whole hierarchies into fully convolutional network for scene parsing [J]. Expert Systems with Applications,2020,160: 113662.
[21]Lin Guosheng,Milan A,Shen Chunhua,et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 1925-1934.
[22]Groenendijk R,Dorst L,Gevers T. MorphPool: efficient non-linear pooling & unpooling in CNNs [EB/OL]. (2022-11-25) [2023-7-29]. https://doi. org/10. 48550/arXiv. 2211. 14037.
[23]Yu Xumin,Rao Yongming,Wang Ziyi,et al. AdaPoinTr: diverse point cloud completion with adaptive geometry-aware transformers [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45(12): 1414-14130.
[24]Lin Di,Chen Guangyong,Cohen-Or D,et al. Cascaded feature network for semantic segmentation of RGB-D images [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 1311-1319.
