改進YOLOv5的小目標多類別農田害蟲檢測算法研究
2024-06-17 11:21:43周康喬劉向陽鄭特駒
中國農機化學報 2024年6期
周康喬 劉向陽 鄭特駒

摘要:針對農田害蟲圖像中感興趣目標特征不明顯、小目標居多導致的目標檢測精度較低的問題,提出一種基于YOLOv5改進的小目標多類別農田害蟲目標檢測算法。首先,在主干網絡最后兩個C3卷積塊特征融合部分引入Swin Transformer窗口注意力網絡結構,增強小目標的語義信息和全局感知能力;其次,在頸部網絡的C3卷積塊后添加通道注意力機制和空間注意力機制的可學習自適應權重,使網絡能夠關注到圖像中關于小目標的特征信息;最后,由于YOLOv5自身的交并比函數存在收斂速度較慢且精確率較低的問題,引入SIOU函數作為新的邊界框回歸損失函數,提高檢測的收斂速度和精確度。將所提出的算法在包含28類農田害蟲公開數據集上進行試驗,結果表明,改進后的算法在農田害蟲圖像數據集上的準確率、召回率和平均準確率分別達到85.9%、76.4%、79.4%,相比于YOLOv5分別提升2.5%、11.3%、4.7%。
關鍵詞:農田害蟲檢測;小目標;YOLOv5;注意力機制;損失函數
中圖分類號:S763.3; TP391
文獻標識碼:A
文章編號:2095-5553 (2024) 06-0235-07
收稿日期:2022年12月10日
修回日期:2023年1月13日
*基金項目:云南省重大科技專項計劃項目資助(202002AE090010)
第一作者:周康喬,男,1998年生,江蘇徐州人,碩士研究生;研究方向為深度學習與目標檢測。E-mail: 1207581563@qq.com
通訊作者:劉向陽,男,1976年生,山東青島人,副教授,碩導;研究方向為智能計算、機器學習。E-mail: liuxy@hhu.edu.cn
Research on improved YOLOv5 small target multi-class farmland pest detection algorithm
Zhou Kangqiao, Liu Xiangyang, Zheng Teju
(College of Science, Hohai University, Nanjing, 211100, China)
Abstract: Aiming at the problem of low target detection accuracy caused by the lack of obvious features of the interested target and the majority of small targets in the farmland pest images, a small target multi-category farmland pest target detection algorithm based on YOLOv5 was proposed. Firstly, the Swin Transformer window attention network structure was introduced into the feature fusion part of the last two C3 convolution blocks of the trunk network to enhance the semantic information and global awareness of small targets. Secondly, the learnable adaptive weights of the channel attention mechanism and the spatial attention mechanism were added to the C3 convolution block of the neck network, so that the network could pay attention to the feature information of small targets in the image. Finally, since the intersection ratio function of YOLOv5 itself had the problem of slow convergence speed and low accuracy rate, SIOU function was introduced as a new boundary box regression loss function to improve the convergence speed and accuracy of detection. The proposed algorithm was tested on the open data set of 28 farmland pests. The results showed s that the accuracy rate, recall rate and average accuracy of the improved algorithm in the farmland pest image data set reached 85.9%、 76.4% and 79.4%, respectively, which were 2.5%、 11.3% and 4.7% higher than that of YOLOv5.
Keywords: farmland pest detection; small goal; YOLOv5; attention mechanism; loss function
0 引言
中國是世界上最大的農業生產國之一,也是農業有害生物問題的高發區。農業害蟲每年都會對農作物造成很大的危害[1]。如果沒有專業知識,人們很難識別害蟲,而錯誤地使用農藥往往會對受蟲害影響的地區造成二次損害[2]。近年來,計算機技術發展迅速,農業害蟲識別作為研究的熱點,其中包括一些基于計算機視覺的方法。Larios等[3]開發了一種采用級聯特征直方圖方法對石蠅幼蟲進行分類的系統。Zhu等[4]通過分析翅膀圖像的顏色直方圖和灰度共生矩陣,提出一種昆蟲分類方法。在100種鱗翅目昆蟲數據庫中對該方法進行測試,識別率高達71.1%。Wang等[5]設計了昆蟲自動識別系統。使用人工神經網絡和支持向量機作為模式識別方法對昆蟲進行分類。利用人工神經網絡對具有不同特征的八階和九階昆蟲圖像進行測試,系統穩定性良好,準確率為93%。Faithpraise等[6]提出了一種基于k-means聚類和對應濾波器相結合的害蟲檢測系統。Xia等[7]使用分水嶺算法將害蟲圖像從背景中分離出來,然后通過馬氏距離提取害蟲的顏色特征,對移動和嵌入式設備捕獲的害蟲圖像進行分類。以常見溫室害蟲粉虱、蚜蟲和薊馬為對象,在低分辨率圖像下,粉虱、薊馬、蚜蟲與人工鑒定的相關性較高,分別為0.934、0.925和0.945。Wang等[8]提出一個局部Chan-Vese模型來完成圖像分割任務。Xie等[9]開發了具有先進多任務稀疏表示和多核學習的昆蟲識別系統。對24種常見作物害蟲的試驗結果表明,該方法在昆蟲種類分類方面表現良好。
然而,上述害蟲識別方法在很大程度上依賴于人工選擇的害蟲特征,這些特征對模型性能有很大影響。深度學習技術在圖像識別工作中已經取得了良好的效果,利用深度卷積神經網絡可以自動學習不同害蟲的特征,不需要人工選擇的害蟲特征。目前計算機視覺方面的目標檢測算法可以分為2類:一類是一階段檢測算法(one-stage),直接在一個階段里完成尋找目標出現的位置和目標類別的預測;另一類是二階段檢測算法(two-stage)[10, 11],二階段算法通常在第一階段專注于感興趣區域的生成,得到建議框,然后在第二階段專注于對建議框進行類別的分類與位置的回歸,尋找檢測目標更確切的位置。二階段檢測以Girshick等[12]提出的R-CNN為代表,包括Fast R-CNN[13]、Faster R-CNN[14]、MASK R-CNN[15]和R-FCN[16]。一階段檢測以Redmon等[17]提出的YOLO為代表,除此之后還有Swin Transformer[18]和SSD[19]。一階段與二階段的主要不同之處在于沒有候選框生成階段。
由于農田害蟲圖像中害蟲尺寸通常較小,攜帶的信息量較少,且圖像背影信息較為復雜,一般的深度學習目標檢測算法直接應用于農田害蟲圖像會出現目標檢測精度較低的問題。針對上述出現的問題,本文提出一種基于注意力機制和新的邊界框損失函數的YOLOv5的農田害蟲目標檢測算法。首先,本文為了避免主干網絡中隨著網絡結構的加深,小目標的語義信息在深層特征圖中丟失問題,在主干網絡的C3卷積塊引入Swin Transformer網絡結構;其次,為了提高Neck網絡對目標的特征提取能力,在頸部的C3卷積塊后引入CBAM[20]模板;最后,引入SIOU函數作為新的邊界框回歸損失函數,提高模型的收斂速度和精確率。
1 材料與方法
1.1 材料
本文采用2022年中國高校大數據教育創新聯盟和泰迪杯數據挖掘委員會提供的公開數據集作為試驗的檢測基準。該數據集中圖像尺寸較大,數據集包含對農作物生長有危害的28種農田害蟲目標,害蟲的尺寸較小且分布不均衡,某些類別害蟲目標數量少且分辨率較為模糊,不易檢測,如圖1所示。對數據集進行數據清洗和增強[21, 22]操作后獲得2 200張標注準確的圖像,可以用于研究。其中最多的156類(八點灰燈蛾)共有288次標記,占總標記的24.26%;而最少的430類(豆野螟)和673類(干紋冬夜蛾)均小于10次標記;各類害蟲標記數量并不平衡,且每張圖片的類別數不相同,此時模型對于數目少的類別的學習效果有可能不如數目多的類別的學習效果。因此人工劃分訓練集和驗證集,以確保驗證集中每種害蟲的圖片至少存在一張,進一步驗證算法對每一類別害蟲的預測精度。具體劃分方法:若包含某種害蟲的圖片少于或等于10張,則隨機選擇1張圖片劃分入驗證集,其余圖片劃分入訓練集[23];若包含某種害蟲的圖片多于10張,則以1∶9的比例劃分入驗證集和訓練集。
按照上述方法對2 200張圖片進行劃分,最后訓練集中包含1 760張圖片,測試集中包含440張圖片。
1.2 試驗環境及參數設置
本試驗使用的操作系統為Ubuntu 18.04 LTS,GPU為2塊NVIDI A10 24G,CUDA版本為11.6,深度學習框架為pytorch1.10。預訓練權重采用Yolov5s.pt,輸入圖片大小為640像素×640像素,batch-size為16。采用隨機梯度下降算法訓練300epoch[24]。其中初始學習率為0.01;采用余弦退火衰減策略調整學習率,余弦函數動態降低學習率為0.1;權重衰減度為0.937;預熱訓練時輪數的學習率為0.000 5;預熱訓練時的梯度動量為3;預熱訓練時偏置b的學習率為0.8。Loss函數的定位框損失函數的增益比為3;分類損失的增益比為0.5;正樣本的權重為1;目標距離的權重為1;負樣本的權重為1。
1.3 YOLOv5原理
YOLOv5[25]網絡模型主要分為如下4個模塊:輸入端、主干網絡(backone)、頸部網絡(neck)和預測端(prediction)。其中YOLOv5在輸入端使用了Mosaic方法,隨機將訓練集中的任意4張圖像拼接在一起生成一張新的圖像,增強圖像的輸入,同時在輸入端自適應計算錨框的尺寸,自適應縮放圖像縮的尺寸。在主干網絡中引入一種新的SPPF結構對處理后的特征圖在通道方向進行拼接,同時引入一種新的C3網絡結構,有效減少了信息丟失。在Neck部分使用FPN+PAN結構,首先FPN通過將上采樣后的特征圖和backbone中的低層特征圖進行concat,增強網絡學習圖像特征的能力。然后PAN對FPN獲得的圖像通過自下向上傳遞強的定位信息,同時使用兩者達到互補效果,增強模型的特征提取能力。
YOLOv5網絡進行通用目標檢測時,雖然其精度較好,但是在小目標農田害蟲檢測中仍存在不理想的地方:一是由于主干網絡對于小目標的特征提取能力較弱;二是由于Neck網絡在連續多次采樣過程中會出現目標信息丟失嚴重的情況,特別是在融合不同層級特征時,淺層特征會受到深層特征的干擾,而淺層特征通常包含小目標豐富的位置信息,這樣會造成定位失準。對此,本文提出了更適用于小目標農田害蟲檢測的改進YOLOv5網絡結構。
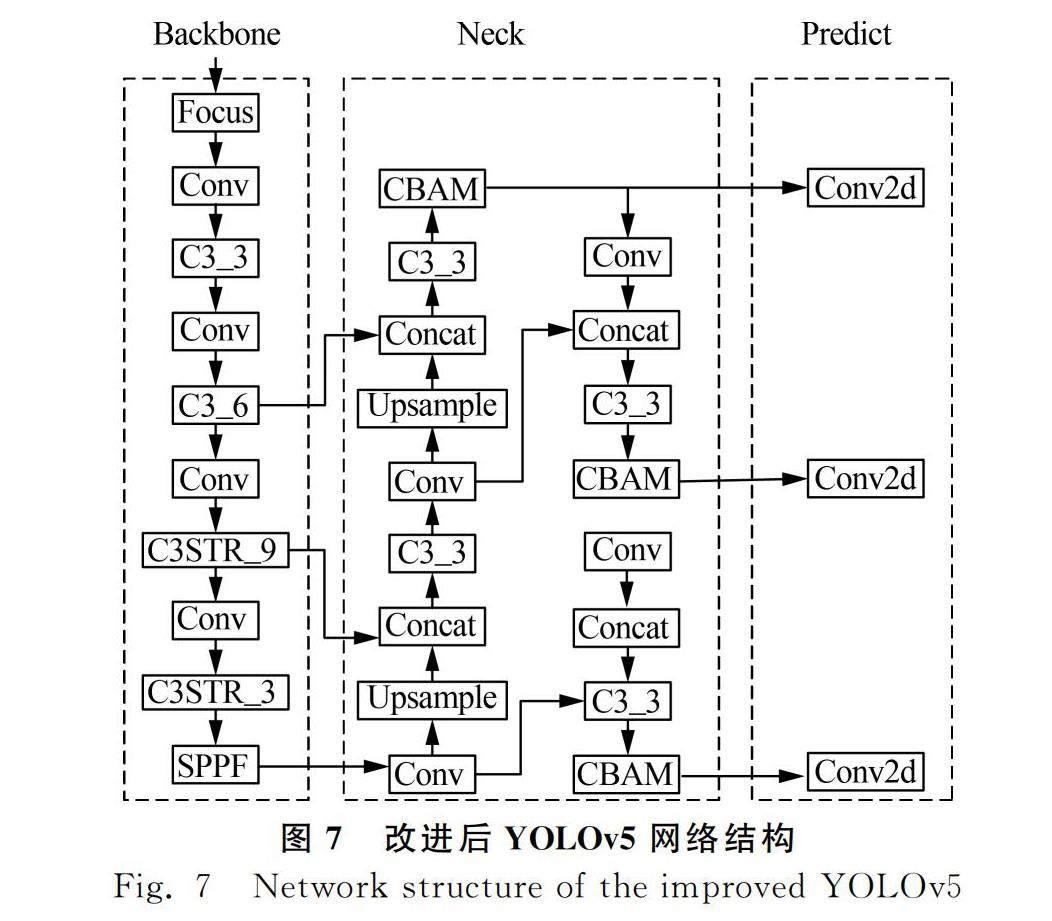
1.4 主干網絡的改進
在主干網絡中隨著網絡結構的加深,經過多次卷積操作,農田害蟲圖像中小目標應該具有的大部分目標特征信息在深層特征圖中可能會丟失。所以,在主干網絡最后兩個C3卷積塊特征融合部分借鑒Swin Transformer的思想,將其替換掉原有的BottleNeck模塊。替換后的C3STR結構作為一個輔助模塊,借助窗口自注意力模塊增強小目標的語義信息和特征表示,改進后的卷積結構圖2所示。
Swin Transformer Block將Transformer Block中多頭自注意力模塊(MSA)改進成窗口多頭自注意力模塊(W-MSA)和滑動窗口多頭自注意力模塊(SW-MSA),兩個模塊成對出現,再經過多層感知機MLP,其中每個模塊內部均采用殘差連接。具體結構如圖3所示。
其中局部窗口大小為7,多層感知機隱藏層的嵌入維度為4。多頭自注意力機制[26]的計算過程引入相對位置編碼,具體公式如式(1)所示。
Attention(Q,K,V)=softmax(QKT/d+B)V(1)
式中:Q、K、V——對應Query、Key和Value矩陣;
d——輸入特征圖的channels;
B——相對位置偏差,由網絡學習得到。
與傳統的Transformer[27]中的多頭自注意力模塊相比,W-MSA和SW-MSA模塊和通過劃分局部窗口控制每一個窗口中計算區域的方法降低計算復雜度和網絡計算量,同時利用Shifted Windows實現跨窗口的信息交互。
1.5 Neck網絡的改進
為提高Neck網絡對目標的特征提取能力,更好地抑制連續多次采樣過程中出現的目標信息丟失嚴重的情況,得到具有方向感知和位置感知信息的特征圖,對融合后的特征圖進行更新,在Neck的C3卷積塊后引入卷積注意力機制模板(CBAM),CBMA模塊通過卷積核池化操作計算出特征圖在空間維度和通道維度的不同權重,使網絡能夠更加關注到圖像中關于檢測目標的特征信息,如圖4所示。假設特征圖有C個通道,通道注意力機制對特征圖進行全局最大池化和全局平均池化兩種池化操作,分別得到C個1×1大小的特征圖,再將得到的兩個特征圖分別進行MLP操作后加在一起,最后經過Sigmoid函數獲得特征圖在每一個通道的權重。通道注意力具體如式(2)所示。
Mc(F)=σ(W1(W0(Fcavg))+W1(W0(Fcmax)))(2)
式中:σ——使用Sigmoid函數近激活;
Fcmax——對特征圖進行全局最大池化;
Fcavg——對特征圖進行全局平均池化;
W0、W1——對應第1個和第2個全連接層的權重,為了降低計算參數,通道注意力模塊在MLP的第一個全連接層中采用了一個降維系數r;
Mc(F)——通道注意力得到每一個通道權重。
如圖5和式(3)所示,假設特征圖在每個通道上的尺寸為H×W,空間注意力機制模塊對學習到的特征圖在通道方向上進行平均和最大池化操作,分別得到1個H×W大小的特征圖,再將兩個特征圖在通道方向上進行拼接,得到一個2×H×W大特征圖,最后經過卷積核為7×7的卷積操作和Sigmoid激活函數獲得學習到的特征圖在每一空間位置上的權重。
Ms(F)=σ(f7×7([Fsavg;Fsmax]))(3)
式中:f7×7——空間注意力模塊的MLP操作采用的是7×7卷積操作。
1.6 損失函數的改進
YOLOv5自身的交并比函數為CIoU[28]邊界框回歸損失函數,只考慮到IoU loss、中心點損失和長寬比例損失,沒有考慮到真實框與預測框之間的方向,導致收斂速度較慢,對此本文考慮到期望的真實框和預測框之間的向量夾角,引入SIoU函數重新定義相關損失函數,SIoU[29]函數具體包含四個部分。
角度損失(Angle cost),定義如式(4)和圖6所示。
Λ=1-2×sin2arcsinckξ-π4(4)
式中:ck——真實框和預測框中心點的高度差;
ξ——真實框和預測中心點的距離。
距離損失(Distance cost),定義如式(5)所示。其中ρx=bgtcx-bcxcw2,ρy=bgtcy-bcych2,γ=2-Λ,(bgtcx,bgtcy)和(bcx,bcy)分別表示真實框和預測框中心點坐標,(cw,ch)為真實框和預測框最小外接矩形的寬和高。
Δ=∑t=x,y(1-e-rρt)=2-e-rρx-e-rpy(5)
形狀損失(Shape cost),定義如式(6)所示。其中Ww=|w-wgt|max(w,wgt),Wh=|h-hgt|max(h,hgt),(w,h)和(wgt,hgt)分別為預測框和真實框的寬和高,θ控制對形狀損失的關注程度,一般取4。
Ω=∑t=w,h(1-e-wt)θ=(1-e-ww)θ+(1-e-wh)θ(6)
IoU損失(IoU cost),定義如式(7)所示。
IoU=交集A并集B(7)
最終SIoU損失函數定義如式(8)所示。改進后的YOLOv5網絡結構如圖7所示。
LossSIoU=1-IoU+Δ+Ω2(8)
1.7 評價指標
本文對算法的性能評估,以準確率(Precision,P)、召回率(Recall,R)和平均準確率(mAP)為主要評價指標。當真實框與預測框的IoU值大于0.5時即認為檢測正確。評價指標計算公式如式(9)~式(11)所示。
P=TPTP+FP(9)
R=TPTP+FN(10)
mAP=∫10P(R)dR(11)
其中,正確預測框TP表示真實框與預測框正確匹配,兩者間的IoU大于0.5;誤檢框FP表示將背景預測為目標;漏檢框FN表示本應被模型檢測出的目標被預測為背景。
2 結果與分析
2.1 不同檢測試驗結果及分析
為了驗證本文提出的改進YOLOv5算法模型的性能,在公開數據集上將其與其他主流目標檢測算法進行了試驗對比,試驗結果如表1所示。
由表1可知,本文改進的算法模型YOLOv5+C3STR+CBMA+SIOU相比于其他主流目標檢測算法,準確率、召回率和平均準確率均有所提升。與SSD、YOLOv3相比,mAP值分別提升16.7%、9.4%。
TPH-YOLOv5是基于Transformer改進的YOLOv5模型,在YOLOv5的基礎上又添加了一個用來檢測小目標的預測頭,為其設置初始錨框,并同時對YOLOv5的head部分進行改進,將Transformer Prediction Heads集成到YOLOv5中,代替原來的prediction heads,能有效提高小目標的平均檢測精確度。本文模型與TPH-YOLOv5相比,準確率提升了2.8%,召回率提升了9.1%,平均準確率mAP提升了2.1%。
由表1可知,本文算法相比于原始的YOLOv5模型,改進后的YOLOv5算法模型對農田害蟲檢測的準確率、召回率、平均正確率的指標參數都有所提升。將改進前后的模型在數據集上的準確率、召回率、mAP等參數變化進行了可視化展示。一般來說,準確率和召回率為負的相關的互斥關系,但文本改進后的算法在數據集上準確率相較于原始值提升了2.5%,召回率提升了近11.3%,平均準確率mAP提升了4.7%,在準確率和召回率中達到了最優的平衡狀態,因此本文提出的YOLOv5改進模型是適合用于小目標農田害蟲的檢測實際應用中,如圖8和圖9所示。
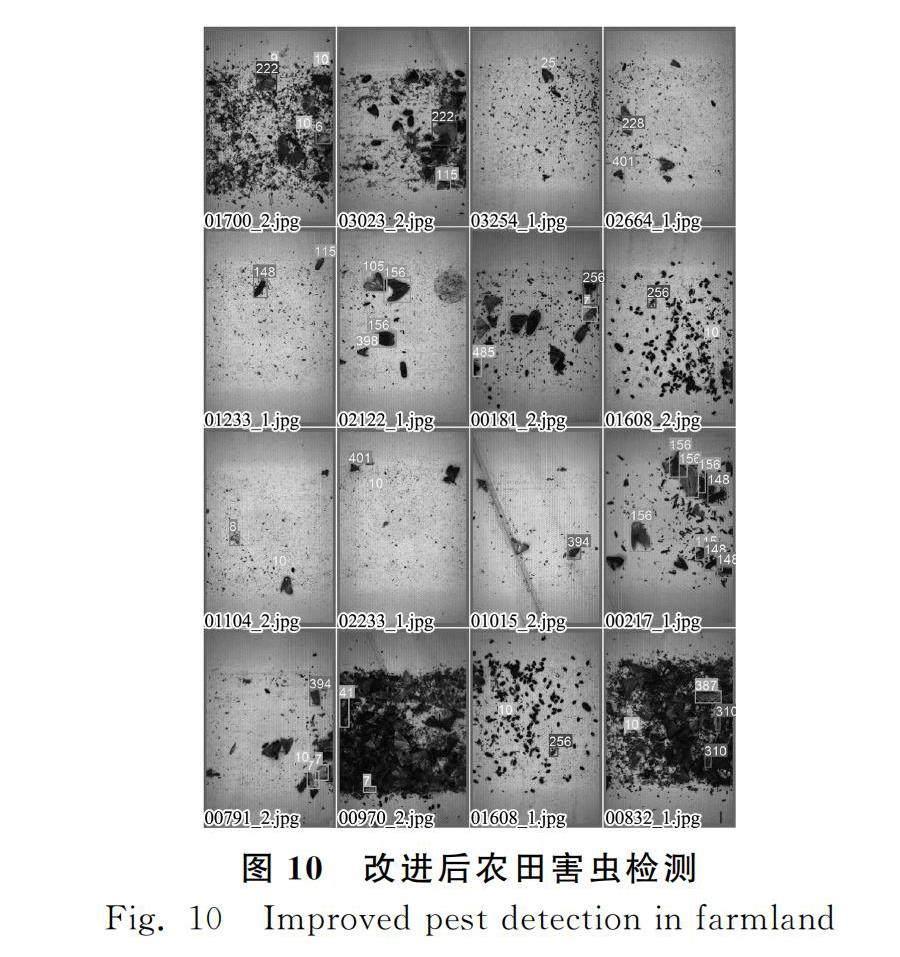
對數據集進行訓練得到的結果,如圖10所示。
從圖10可以得知,改進后的算法對農田害蟲的檢測結果精度更高,檢測結果更全面;同時改進后的算法對小目標檢測具有良好的識別性,比原始算法具有更高的置信度。對于訓練樣本中某些標記次數較多的害蟲類別,如148類(黃足獵蝽)、156類(八點灰燈蛾)和256類(蟋蟀)等,不存在誤檢和漏檢情況。但由于訓練樣本中有些類別害蟲標記次數過少,如430類(豆野螟)和673類(干紋冬夜蛾)等,網絡對于這些類別學習能力不足,仍然會出現部分害蟲誤檢和漏檢情況。
2.2 消融試驗結果及分析
通過本文對原始YOLOv5s模型的三個改進,在公開數據集上進行了消融試驗,證明所提出的改進模型的有效性,試驗結果如表2所示。
其中,C3STR是指在主干網絡的C3卷積塊特征融合部分引入Swin Transformer模塊;CBAM是指在Neck的C3卷積塊后引入卷積注意力機制模板CBAM;SIOU是指在YOLOv5中引入SIOU邊界框回歸損失函數。
由表2可知,本文所提出改進方法中,在YOLOv5s主干網絡中加入C3STR,mAP可以提升1.6%;加入C3STR并進入SIOU損失函數,mAP可以提升2.6%;加入C3STR并在Neck中加入CBAM,mAP可以提升3.5%;當所有改進方法同時加入原始YOLOv5s模型后,模型整體的mAP可以提升4.7%,達到79.4%。
3 討論
本文針對小目標多類別農田害蟲圖像識別問題提出的改進后的YOLOv5模型,對圖像數據集進行預處理并進行數據增強處理,克服部分類別的訓練樣本數據量不足的問題。模型能夠較好地識別定位出小目標和大目標的害蟲圖像,檢測效率高。模型中采用自適應錨框,能夠根據圖像數據選擇合適的錨框并進行檢測,很好地解決農業害蟲圖像多尺度檢測的問題,模型適應性強,對害蟲圖像數據的魯棒性較好。模型的模塊化和可遷移性較好,下一批害蟲圖像數據可以添加進入模型的訓練中,不需要重新訓練全部數據,在之前訓練權重基礎上進行訓練。在處理更大的數據量,模型的遷移性好。
本文是針對農業病蟲害圖像的識別,模型可以推廣到其他的包含小目標檢測的問題。模型可以進一步考慮剔除一些不是病蟲的昆蟲,減小其噪聲的干擾。
4 結論
針對農田害蟲圖像中目標檢測存在的問題,本文提出了改進后的YOLOv5算法。
1) 首先,主干網絡中隨著網絡結構的加深,經過多次卷積操作,小目標應該具有的大部分目標特征信息可能會丟失。故在主干網絡最后兩個C3卷積塊引入Swin Transformer網絡結構,借助窗口自注意力模塊增強小目標的語義信息和特征表示。
2) 其次,在頸部的C3卷積塊后引入CBAM模板,CBMA模塊通過卷積核池化操作計算出特征圖在空間維度和通道維度的不同權重,使網絡能夠更加關注到圖像中關于檢測目標的特征信息。
3) 最后,由于YOLOv5自身的交并比函數為CIOU邊界框回歸損失函數,沒有考慮到真實框與預測框之間的方向,導致收斂速度較慢,且對小目標的檢測精度不準確。對此本文考慮到期望的真實框和預測框之間的向量夾角,引入SIOU函數重新定義相關損失函數。
4) 經過試驗對比,本文算法相比于原始的YOLOv5s,平均檢測準確率在公開數據集上提升4.7%,可以表明本文算法在農田害蟲圖像目標檢測領域的有效性。
本文算法也存在一定的局限性:改進后的模型會使得網絡結構變復雜,使得網絡的訓練時間增加,檢測速度下降,實時性變差。未來的研究方向是采用網絡剪枝、權重量化等手段使模型更加輕量化,繼續優化硬件資源占用,提高檢測速度,實現農田害蟲的實時監測在工業中的實際應用。
參 考 文 獻
[1]肖忠毅. 農業生產數字化轉型的實踐機制研究[D]. 無錫: 江南大學, 2022.
Xiao Zhongyi. Practical mechanism of digital transformation of agricultural production [D]. Wuxi: Jiangnan University, 2022.
[2]牛霆葳. 基于機器視覺的農田害蟲自動識別方法研究[D]. 天津: 天津科技大學, 2015.
Niu Tingwei. Study on automatic identification method of agricultural pests based on machine vision [D]. Tianjin: Tianjin University of Science and Technology, 2015.
[3]Larios N, Deng H, Zhang W, et al. Automated insect identification through concatenated histograms of local appearance features: feature vector generation and region detection for deformable objects [J]. Machine Vision and Applications, 2008, 19(2): 105-123.
[4]Zhu L Q, Zhang Z. Auto-classification of insect images based on color histogram and GLCM [C]. 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery. IEEE, 2010, 6: 2589-2593.
[5]Wang J, Lin C, Ji L, et al. A new automatic identification system of insect images at the order level [J]. Knowledge-Based Systems, 2012, 33: 102-110.
[6]Faithpraise F, Birch P, Young R, et al. Automatic plant pest detection and recognition using k-means clustering algorithm and correspondence filters [J]. Int. J. Adv. Biotechnol. Res, 2013, 4(2): 189-199.
[7]Xia C, Chon T S, Ren Z, et al. Automatic identification and counting of small size pests in greenhouse conditions with low computational cost [J]. Ecological Informatics, 2015, 29: 139-146.
[8]Wang X F, Huang D S, Xu H.An efficient local Chan-Vese model for image segmentation [J]. Pattern Recognition, 2010, 43(3): 603-618.
[9]Xie C, Zhang J, Li R, et al. Automatic classification for field crop insects via multiple-task sparse representation and multiple-kernel learning [J]. Computers and Electronics in Agriculture, 2015, 119: 123-132.
[10]文斌, 曹仁軒, 楊啟良, 等. 改進YOLOv3算法檢測三七葉片病害[J]. 農業工程學報, 2022, 38(3): 164-172.
Wen Bin, Cao Renxuan, Yang Qiliang, et al. Detecting leaf disease for Panax notoginseng using an improved YOLOv3 algorithm [J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(3): 164-172.
[11]周逸博, 馬毓濤, 趙艷茹. 基于YOLOv5s和Android的蘋果樹皮病害識別系統設計[J]. 廣東農業科學, 2022, 49(10): 155-163.
Zhou Yibo, Ma Yutao, Zhao Yanru. Design of mobile app recognition system for apple bark disease based on YOLOv5s and Android [J]. Guangdong Agricultural Sciences, 2022, 49(10): 155-163.
[12]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, 1: 580-587.
[13]Girshick R. Fast R-CNN [C]. Proceedings of the IEEE International Conference on Computer Vision, 2015, 1: 1440-1448.
[14]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. Advances in Neural Information Processing Systems, 2015, 28.
[15]He K, Gkioxari G, Dollár P, et al. Mask R-CNN [C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
[16]Dai J, Li Y, He K, et al. R-FCN: Object detection via region-based fully convolutional networks [J]. Advances in Neural Information Processing Systems, 2016, 29.
[17]Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[18]Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows [C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 10012-10022.
[19]Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector [C]. European Conference on Computer Vision, 2016: 21-37.
[20]Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module [C]. Proceedings of the European Conference on Computer Vision (ECCV), 2018, 1: 3-19.
[21]趙文博, 周德強, 鄧干然, 等. 基于改進YOLOv5的甘蔗莖節識別方法[J]. 華中農業大學學報, 2023, 42(1): 268-276.
Zhao Wenbo, Zhou Deqiang, Deng Ganran, et al. Sugarcane stem node recognition method based on improved YOLOv5 [J]. Journal of Huazhong Agricultural University, 2023, 42(1): 268-276.
[22]Wan J, Chen B, Yu Y. Polyp detection from colorectum images by using attentive YOLOv5 [J]. Diagnostics, 2021, 11(12): 2264.
[23]汪斌斌, 楊貴軍, 楊浩, 等. 基于YOLO_X和遷移學習的無人機影像玉米雄穗檢測[J]. 農業工程學報, 2022, 38(15): 53-62.
Wang Binbin, Yang Guijun, Yang Hao, et al. UAV images for detecting maize tassel based on YOLO_X and transfer learning [J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(15): 53-62.
[24]Xue Z, Lin H, Wang F. A small target forest fire detection model based on YOLOv5 improvement [J]. Forests, 2022, 13(8): 1332.
[25]Redmon J, Farhadi A. Yolov3: An incremental improvement [J]. arXiv Preprint arXiv: 1804.02767, 2018.
[26]Parmar N, Vaswani A, Uszkoreit J, et al. Image transformer [C]. International Conference on Machine Learning, 2018: 4055-4064.
[27]Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection [J]. arXiv Preprint arXiv: 2004.10934, 2020.
[28]Yan B, Fan P, Lei X, et al. A real-time apple targets detection method for picking robot based on improved YOLOv5 [J]. Remote Sensing, 2021, 13(9): 1619.
[29]Gevorgyan Z. SIoU Loss: More powerful learning for bounding box regression [J]. arXiv Preprint arXiv:2205.12740, 2022.
