
基于改進的YOLOv5模型和射線法的車輛違停檢測
2024-06-20 11:05:52莊建軍徐子恒張若愚
南京信息工程大學學報 2024年3期
莊建軍 徐子恒 張若愚

摘要:車輛違法停車將會降低道路通行效率,引發交通擁堵和交通事故.傳統的車輛違停檢測方法參數量大且準確度低.為此,本文提出了一種使用改進的YOLOv5模型和射線法的車輛違停檢測方法.首先設計了輕量化的特征提取模塊,減少模型參數量;其次在模型中加入注意力機制,從通道維度和空間維度增強模型的特征提取能力,保證模型精度;接著使用混合數據增強豐富數據集樣本,提升復雜背景下的檢測效果;然后選用EIoU作為損失函數提高模型定位能力.實驗結果表明,改進后的模型均值平均精度達到91.35%,比原始YOLOv5s提升1.01個百分點,并且參數量減少35.79%.最后將改進后模型與射線法結合,在JetsonXavierNX嵌入式平臺的檢測速度可以達到約28幀/s,能夠實現實時檢測.
關鍵詞車輛違停檢測;YOLOv5s算法;Ghost卷積;注意力機制;射線法
中圖分類號TP391.41
文獻標志碼A
0引言
隨著經濟的快速發展,我國汽車產銷量也在不斷增加.根據公安部2022年12月的統計數據,全國機動車保有量達4.15億輛,其中汽車保有量為3.18億輛,汽車已成為人們主要的交通出行方式之一.在汽車數量高速增長的同時,城市停車難和交通擁堵問題日趨嚴重,違章占道停車現象屢見不鮮.違章停車不僅會擾亂道路秩序、降低通行效率,還會帶來交通安全隱患.
傳統的違章停車檢測主要采用地磁技術[1],通過車輛上的金屬進行識別,這種方法簡單穩定,但是傳感器的檢測范圍很小,只適用于單個停車位,不滿足道路、停車場等大范圍檢測需求.因此,基于視頻流的違停檢測開始慢慢普及.早期基于視頻流的檢測方法主要利用傳統圖形處理技術.例如:王殿海等[2]利用混合高斯模型獲取背景與運動目標以在場景相對復雜的城市主干道上檢測車輛違停;Ye等[3]采用自適應閾值和二值化消除背景干擾,再采用形態學提取車輛目標;楊祖莨等[4]通過混合高斯模型提取出運動目標,利用Meanshift算法跟蹤目標,最后使用卷積神經網絡判斷靜止目標是否為車輛,該方法與傳統方法相比,準確率提升了63%;唐潔[5]對設定的禁停區域進行灰度直方圖計算,當灰度發生變化且趨于穩定時,用SSD算法檢測物體是否為車輛,實現指定區域內的違停檢測.
近年來,基于深度學習的目標檢測算法不斷涌現,其中具有代表性的R-CNN[6]、YOLO[7]系列算法更是被廣泛應用,越來越多的研究者開始使用目標檢測方法識別車輛,來解決傳統方法識別速度慢、易受環境干擾等問題.例如:劉寒迪等[8]使用對小目標檢測效果好的SSD[9]網絡檢測施工車輛,采用MobileNet作為主干網絡,在檢測速度和精度上都有提高;Tang等[10]在SSD網絡中引入空間注意力模塊,提升了模型的檢測精度,并通過前后幀間預測框的交并比實現車輛目標跟蹤,判斷車輛是否停車;丁冰等[11]采用基于卷積神經網絡的YOLOv3模型作為車輛檢測網絡,極大地提高了車輛檢測的精度,并利用Deepsort跟蹤算法作為停車檢測,實現了高速公路隧道中的停車檢測任務;許璧麒等[12]將通道空間注意力模塊引入YOLOv5網絡中,提升小目標檢測精度,并通過Deepsort實現車輛的逆行檢測.上述方法普遍存在參數量大、實時性差的問題,在實際應用中不適合在性能受限的嵌入式設備上運行.因此,本文提出一種使用改進YOLOv5和射線法的車輛違停檢測方法,能夠在保證模型精確度的同時減少算法復雜度和參數量.主要工作如下:
1)利用通道混洗和通道復用卷積重構YOLOv5s的特征提取模塊,減少模型的參數量;在模型中引入改進后的注意力機制,增強模型特征提取能力;優化損失函數提高模型回歸精度,加速模型收斂.
2)對UA-DETRAC數據集進行混合數據增強,提升樣本的復雜度;使用k-means聚類算法在數據集上獲取更適合的初始錨框.
3)通過消融實驗、不同模型對比實驗,驗證模型改進的有效性;將改進后的模型與射線法結合,部署在JetsonXavierNX平臺.
1理論基礎
1.1YOLOv5算法原理
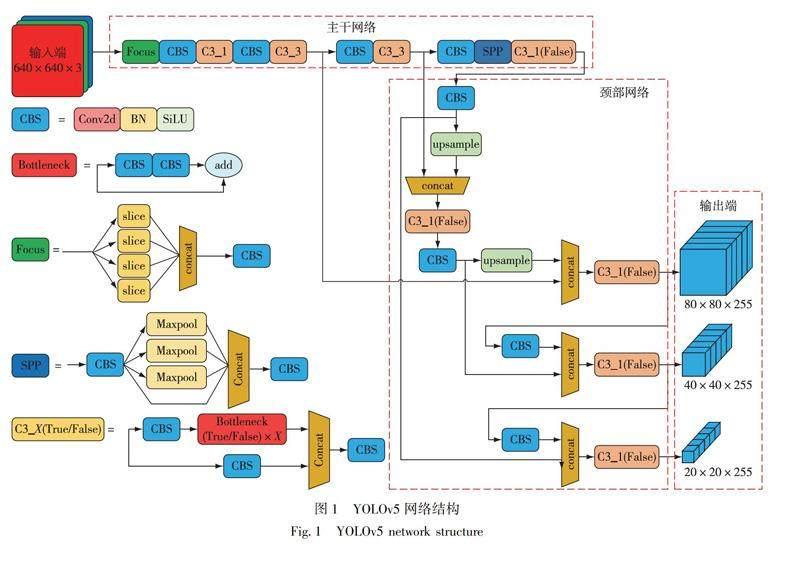
YOLO系列是典型的一階段目標檢測網絡,其中YOLOv3、YOLOv4、YOLOv5[13]、YOLOX和YOLOv7應用較為廣泛.考慮到網絡需要在嵌入式設備下運行,體積超過50MB的YOLOv3、YOLOv4和YOLOv7并不適合本文的實驗環境.YOLOv5和YOLOX則根據模型深度和寬度的不同分為s、m、l、x4個版本,其中s版本的模型體積最小,推理速度最快.YOLOv5s在COCO數據集上的精度比YOLOXs稍低但不超過1%,模型體積卻小了20%,檢測速度也更快,因此本文選擇YOLOv5s作為基礎網絡.YOLOv5可分為輸入端(input)、主干網絡(backbone)、頸部網絡(neck)和輸出端(head)4個部分,模型網絡結構如圖1所示.
YOLOv5的輸入端先對輸入圖像進行預處理,然后采用Mosaic數據增強[14]、自適應錨框計算、自適應圖像縮放.主干網絡的作用是特征提取,首先使用Focus結構對進入主干網絡前的圖片進行切片,將輸入圖片的長寬縮減一半,通道則擴充成4倍.C3模塊為跨階段局部融合網絡,能夠有效獲取特征圖特征.SPP是空間金字塔池化,能將任意大小的特征圖轉變成固定大小的特征向量.Neck采用FPN[15]和PAN[16]融合的結構,FPN自頂向下傳遞高層語義特征,PAN自底向上傳遞定位特征,將語義特征和定位特征混合,可以進一步提升對密集目標的檢測效果.YOLOv5的輸出包括80×80、40×40、20×203個尺度的特征圖,用于檢測不同大小的目標.采用CIOU損失函數來評價預測框和真實框之間的距離,解決了模型訓練過程中預測框和真實框不重合時造成的收斂速度慢的問題.使用非極大值抑制(NMS)保留效果最好的預測框并去除冗余的預測框,增強模型對有遮擋目標的識別能力,從而完成目標檢測過程.
1.2基于射線法的區域入侵
考慮到在不同的地點禁停區域擁有不同的形狀,以及不同距離產生的透視形變,攝像頭圖像中的區域通常由多邊形構成,因此無法像矩形框通過幾何運算快速獲得交并比(IOU)一樣,以此判斷車輛是否在禁停區域內.本文以車輛外接矩形的中心點作為車輛的位置,根據中心點是否在多邊形內判斷車輛是否違停.此方法從車輛質心處向任意方向發射一條射線,根據射線穿過多邊形邊界的次數判斷車輛質心是否在多邊形內.射線法效果如圖2所示,當射線穿過邊界次數為奇數時說明質心在多邊形內部,反之在多邊形外部.
2算法的改進
2.1YOLOv5改進
2.1.1輕量化特征提取模塊
C3是YOLOv5中的特征提取模塊,在網絡中多次使用,但是在關鍵特征提取過程中容易產生很多冗余特征,使得網絡模型整體參數多、計算量大.為了降低模型的計算復雜度、提升實時性,本文引入Ghost卷積模塊[17],其結構如圖3所示.Ghost卷積模塊的輸出分為兩個部分,第一部分由輸入特征圖通過普通卷積生成,第二部分則是對第一部分的輸出使用線性計算得出.將兩部分在通道維度疊加組成整個模塊的輸出,通過線性計算生成特征圖,避免重復特征被再次送入網絡中進行卷積計算,減少了模型的計算量.
利用Ghost卷積模塊代替Bottleneck中的普通卷積,搭建Ghostunit模塊,其結構如圖4所示,降低了模型的參數量和計算量.與原始網絡中Bottleneck不同的是,第一次Ghost卷積模塊不再減少輸入的通道數,而是將通道數提升一倍,第二個Ghost卷積模塊再將通道數恢復到輸入數量,這是因為模塊中使用了深度可分離卷積,在參數下降的同時提取的特征也會減少,因此采用先升維再降維的方式增強特征提取能力.
以C3結構為基礎,設計了SG-CSP(ShuffleGhost-CrossStagePartial)輕量化特征提取模塊,結構如圖5所示,使用Ghostunit替代Bottleneck,并用ChannelSplit和concat操作代替一維卷積實現通道的增減.ChannelSplit是將特征圖從通道維度一分為二,concat是將兩個分支的特征圖在通道維度合并.由于輸出是兩個部分疊加而成,因此在concat后加入ChannelShuffle,該模塊將特征圖的通道維度拆成二維,執行矩陣轉置后再合并為一維,能夠均勻打亂兩個分支的輸出,保證通道間的信息交流.
2.1.2融合注意力機制
注意力機制是人們在機器學習模型中嵌入的一種特殊結構,用來學習和計算輸入數據對輸出數據的貢獻大小.與人眼獲取圖像信息的方式類似,注意力機制通過對不同部分的特征圖賦予權重,使網絡更容易關注圖像中重要信息并抑制無用信息,以選擇出圖片中對目標檢測更有利的特征.
CBAM(ConvolutionalBlockAttentionModule)注意力機制[18]是一種結合通道和空間的注意力模塊,包含兩個子模塊:通道注意力模塊(ChannelAttentionModule)和空間注意力模塊(SpatialAttentionModule),分別進行通道和空間上的注意力操作,這使得CBAM能夠作為即插即用的模塊快速集成到現有的網絡架構中.CBAM模塊的結構如圖6所示.
通道注意力模塊的結構如圖7所示.首先分別經過基于特征圖長寬的全局最大池化(GlobalMaxPooling)和全局平均池化(GlobalAveragePooling),得到兩個1×1×C的特征圖.接著將它們送入兩層的全連接網絡中,第一層網絡的神經元個數為C/r(r為減少率),可以減少模塊計算量,第二層網絡的神經元個數為C,兩層之間使用ReLU激活函數激活.最后將全連接層輸出的兩個特征的對應元素加和,再經過sigmoid激活函數生成通道注意力權重.將權重和輸入特征圖對應元素相乘得到通道注意力特征圖并作為空間注意力模塊的輸入.
空間注意力模塊的結構如圖8所示.首先做基于特征圖通道的全局最大池化和全局平均池化,得到兩個H×W×1的特征圖.將兩個特征圖進行通道緯度的疊加操作形成H×W×2的特征圖,經過一個7×7的卷積降維成H×W×1.最后經過sigmoid生成空間注意力權重,將權重和輸入特征圖相乘,得到最終的特征圖.
CBAM模塊采用先通道后空間的形式,相比只采用通道注意力的SE更能夠幫助網絡獲取有利的特征.但是模塊采用了串行結構,使得通道信息和空間信息起到的作用相同,而事實上,網絡中不同層的特征圖對通道和空間信息有不同的關注度.因此,本文改進了CBAM模塊并將其命名為P-CBAM(Parallel-ConvolutionalBlockAttentionModule),模塊結構如圖9所示.
特征圖輸入模塊后分別送入3個分支,前2個分支分別送入通道注意力模塊和空間注意力模塊,以獲得通道特征圖和空間特征圖,最后一個分支保持不變.3個輸出各自乘上一個歸一化后的可訓練權重系數后按照對應元素相加得到輸出.
2.1.3損失函數優化
YOLOv5的損失函數包含回歸損失、分類損失和置信度損失,其中IOU損失用于衡量真實框和預測框之間的距離,是回歸損失中的重要部分.YOLOv5采用的CIOU損失函數考慮了邊界框回歸的重疊面積、中心點距離和寬高比.CIOU損失函數的公式如下:
其中:v用來衡量預測框和真實框寬高之間比例的一致性;w和h分別表示預測框的寬和高;wgt和hgt分別表示真實框的寬和高;α是用于平衡比例的參數;b和bgt分別表示預測框和真實框的中心點坐標;ρ(·)為計算歐式距離;c表示預測框和真實框最小外接矩形的對角線距離.從CIOU的損失函數公式可以看出,它包含了預測框和真實框重疊區域面積的IOU損失、兩框中心點之間的距離損失和兩框的寬高比損失.CIOU損失函數通過迭代可以將預測框不斷向真實框移動,還可以保證預測框和真實框的寬高比更為接近.
盡管CIOU克服了IOU的缺點,但是在寬高比的描述上,CIOU使用的是相對值,難以反映兩框之間的真實差異,有時候會阻礙模型的有效優化.因此,本文將YOLOv5的損失函數更新為EIOU.EIOU在CIOU懲罰項的基礎上將寬高比的影響因子拆開,利用預測框和目標框的長和寬分別計算損失,明確地衡量了重疊區域、中心點距離和邊長這3個幾何因素的差異.EIOU損失的公式如下:
其中:Cw和Ch分別是預測框和目標框最小外接矩形的寬和高.將寬高比的損失項拆分成寬和高進行獨立計算,能夠提高模型回歸精度.
2.2射線法優化
射線法是根據射線穿過多邊形邊界的次數來判段質心與多邊形的相對位置的,而頂點本身就處于多條邊上,當質心是多邊形的某個頂點時,頂點本身所處邊的數量將算作射線穿過邊界的次數從而影響結果,如圖10a所示.因此,在使用射線法前應判斷質心是否在頂點上,若符合則可以說明車輛已經進入禁停區域.同理,質心在多邊形的邊上也會影響結果,如圖10b所示,提前判斷點在邊上也可說明車輛已經進入禁停區域.
當質心不在多邊形的頂點和邊上時,才會使用射線法進行判別,而此時又有兩種奇異情況需要考慮.第一種是射線與多邊形的某一條邊重疊,如圖11a所示,射線經過重疊邊時會額外增加一次邊界穿越次數,這影響了最終結果,因此在使用射線法時,應當忽略多邊形中與射線平行的邊.第二種是射線會經過多邊形的頂點,如圖11b所示.因此,根據邊的折疊方式采取了兩種處理方式,當頂點所在的邊位于射線兩側,則增加一次邊界穿越次數,若位于射線同側,則不增加穿越次數.
改進后的射線法能夠適用于凸多邊形、凹多邊形、不規則多邊形等各類形狀,滿足車輛違停判斷的需求.
3實驗與分析
3.1數據集的制作和前處理
本文實驗的數據集是UA-DETRAC車輛數據集,該數據集包含24個不同地點,超過14萬幀畫面,8250個手動標注的車輛,總共121萬目標對象外框,滿足車輛檢測的要求,因此選取其中9600張樣本進行實驗.數據集中部分樣本如圖12所示.
數據集制作好后,將對其使用Mosaic加Mixup的混合數據增強.Mosaic數據增強是把4張圖片通過隨機縮放、剪裁、排布、色域變化等方式進行拼接,并按照4個方向進行圖片和框的組合,數據增強效果如圖13a所示.Mixup數據增強則將隨機的2張樣本按比例混合,同時樣本的標簽也按比例混合,效果如圖13b所示,通過2個隨機數據進行正負樣本融合成新的樣本,能夠使數據集數量翻倍,并且生成的樣本中含有更多的目標物.通過混合數據增強使圖像遠遠脫離自然圖片的真實分布,能夠提升模型在多目標和復雜背景下的檢測效果.
3.2錨框值設置
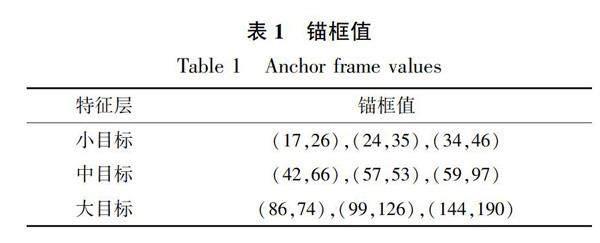
在目標檢測任務中,會提前生成一些先驗信息來約束預測框的范圍大小,通過這些先驗框信息大致確定預測框的范圍.本文的數據集目標尺寸偏小,不適合原始網絡在COCO數據集上形成的錨框,因此使用k-means聚類的方式在數據集上重獲錨框值,錨框數據如表1所示.
3.3實驗平臺和評價指標
為了對比YOLOv5s在改進前后的性能差異,需要在硬件平臺上訓練和驗證,此過程會產生巨大的計算量,對硬件的性能需求非常高,因此本文使用帶有NVIDIA高性能顯卡的主機作為模型訓練和測試的平臺,并選擇JetsonXavierNX作為模型部署的嵌入式平臺,主機端和嵌入式端的配置參數如表2所示.
在搭建好網絡模型后,需要將不同的網絡模型在數據集上進行訓練.為了保證所有網絡模型訓練結果的公平性,將統一設置所有模型的超參數,具體設置如表3所示.
為了定量評價實驗結果,本文使用精確度(Precision,P)、召回率(Recall,R)和均值平均精度(mAP,meanAveragePrecision)來作為模型準確性能的評價指標.精確度是指分類器判定目標為正樣本并且判斷正確的部分占所有分類器判定為正樣本的比例;召回率是指模型預測為正樣本并判斷正確的部分占所有正樣本的比例;平均精度指的是以召回率為橫軸,精確度為縱軸組成的曲線,而曲線所圍成的面積就是平均精度;均值平均精度是數據集中所有類別的平均精度的均值,在本文實驗中采用的mAP指標是指PASVALVOC數據集中所使用的mAP0.5,即IOU閾值設定為0.5時所有類別AP的平均值.上述評價指標計算公式如下:
模型在輕量化方面,使用參數量和權重大小作為模型大小的評價指標,使用每秒可處理的圖片數量(FPS)作為模型檢測速度的評價指標.
3.4實驗結果分析
在驗證改進后的完整模型之前,可以通過消融實驗逐步探究所提改進方法對原始模型的影響.消融實驗將SG-CSP模塊、P-CBAM模塊、Mixup增強和EIOU損失函數逐步加入到YOLOv5s模型中,結果如表4所示.由表4可知,SG-CSP模塊替換C3模塊后,由于參數量的減少,不利于模型在復雜環境下提取車輛特征,模型的mAP值下降了2.03個百分點.為了保持模型的特征提取能力,在模型的backbone和neck之間加P-CBAM注意力模塊,使得模型能夠自主選擇空間信息和通道信息,與使用SG-CSP的模型相比mAP提升了2.06個百分點,也稍高于基準模型.訓練階段,在Mosaic數據增強基礎上額外使用Mixup增強,并用EIOU代替CIOU計算交并比損失,與基準模型相比mAP分別提升0.57和1.01個百分點.最終模型的mAP值對比基準網絡都有更好的表現,并且參數量減少35.78%,模型大小下降36.16%.
根據消融實驗結果不難發現,使用注意力機制有效地彌補了輕量化帶來的負面影響.為了驗證P-CBAM注意力模塊相較于其他注意力模塊有更好的表現,以輕量化后的YOLOv5s模型作為基準網絡,同樣在backbone和neck之間的位置引入不同的注意力模塊,使用mAP、模型體積、參數量作為評價指標,對比結果如表5所示.由表5可知:使用SE(Squeeze-and-Excitation)模塊對比基準模型mAP值幾乎沒有變化,模型大小和參數卻上升最多;使用ECA(EfficientChannelAttention)后模型mAP值提升了1.12個百分點,對模型大小和參數量影響最小;CBAM和P-CBAM都采用空間注意力模塊和通道注意力模塊,性能提升效果明顯.由于P-CBAM增加了自適應權重使模型能夠在通道特征和空間特征之間做選擇,mAP值對比使用CBAM提升了0.35個百分點,模型大小和參數量對比基準模型有些許增加,但是mAP值提升了2.06個百分點,對比使用為了進一步驗證改進后的目標檢測網絡在車輛檢測方面有更好的優勢,將改進后的網絡模型與多個現階段常用的YOLO系列目標檢測網絡進行對比,實驗結果如表6所示.其中:Ghost-v5s和Mobile-v5s是在YOLOv5s的基礎上,分別將主干網絡替換為GhostNet和MobileNetV3網絡;YOLOv5s、YOLOXs和YOLOv7為非輕量化模型;Ghost-v5s、Mobile-v5s和YOLOv4-tiny為輕量化模型.
首先在模型輕量化方面,本文采用的算法以YOLOv5網絡模型為基礎,融合通道分割和輕量化卷積,有效地減少了模型體積和參數量,由表6可以看出,本文算法的參數量和模型體積不僅小于非輕量化模型,還小于YOLOv4-tiny之類的輕量化模型.
其次在性能指標方面,本文算法在P-CBAM注意力機制、Mixup數據增強和EIOU損失的加持下,mAP值僅低于YOLOv7,但模型大小只有YOLOv7的12%,參數量只有YOLOv7的16%.在召回率方面,本文算法弱于YOLOXs和YOLOv7,但在精確度方面,本文算法優于所有對比算法.
最后在處理速度方面,YOLOv4-tiny以142幀/s的處理速度遠超其他網絡模型,但是召回率太低,導致mAP值明顯低于其他模型.本文算法達到了66幀/s,比原版YOLOv5s的處理速度稍快,但本文算法在其他方面對比YOLOv5s表現均更好.
為了驗證本文算法在實際情況下檢測速度,選擇有遮擋、光線差和模糊的圖像,同時對YOLOv5s和本文算法進行測試.置信度均設置為0.5,非極大值抑制的IOU閾值設置為0.3.圖14a、b分別為YOLOv5s和本文算法的檢測結果,可知本文算法的檢測結果均正確,對于YOLOv5s漏檢或錯檢的目標,本文算法依然可以正確檢測.
3.5違停檢測算法部署與應用
基于實際應用性能考慮,本文選用的硬件平臺為JetsonXavierNX(以下簡稱為NX).NX是NVIDIA發布的一款用于AI智能計算的高性能終端,它包含非常豐富的硬件資源,適合目標檢測模型的部署.本文采用640×640大小的圖片作為輸入,在NX上的檢測速度可以達到約28幀/s,能夠滿足實時檢測的需求.將車輛檢測算法和射線法結合,對比人為設定好的禁停區域,能夠快速并準確地進行違停檢測,多個應用場景的效果展示如圖15所示.
4結論
為了解決車輛違停檢測算法復雜、模型大的問題,基于YOLOv5s網絡提出一種輕量化的車輛違停檢測方法.通過構建SG-CSP模塊減少模型的參數;引入P-CBAM注意力機制,增強主干網絡的特征提取能力;訓練階段運用混合數據增強并使用EIOU損失代替CIOU損失,提升模型精度.實驗結果表明,改進后的YOLOv5s在參數量減少35.78%的同時精確度提升1.01個百分點.將本文提出的輕量化模型與射線法結合并部署在嵌入式平臺JetsonXavierNX上,可以實現約28幀/s的檢測速度,達到實時性的需求.
未來的研究中,將著力解決數據集樣本不平衡時,因樣本數量較少導致某一類別召回率偏低的問題,如在損失函數中使用權值均衡等方法進一步優化模型,提升模型精度.
參考文獻
References
[1]
張增超,李強,孫紅雨,等.基于地磁傳感器和UWB技術的停車位車輛檢測方法與實現[J].傳感技術學報,2019,32(12):1917-1922
ZHANGZengchao,LIQiang,SUNHongyu,etal.ParkingvehicledetectionmethodandimplementationbasedongeomagneticsensorandUWBtechnology[J].ChineseJournalofSensorsandActuators,2019,32(12):1917-1922
[2]王殿海,胡宏宇,李志慧,等.違章停車檢測與識別算法[J].吉林大學學報(工學版),2010,40(1):42-46
WANGDianhai,HUHongyu,LIZhihui,etal.Detectionandrecognitionalgorithmofillegalparking[J].JournalofJilinUniversity(EngineeringandTechnologyEdition),2010,40(1):42-46
[3]YeQ,ZhangYM,MaL.Video-baseddetectionmethodofillegalparkingvehicles[J].EnergyProcedia,2011,11:4949-4957
[4]楊祖莨,丁潔,劉晉峰.一種新的結合卷積神經網絡的隧道內停車檢測方法[J].重慶大學學報,2021,44(6):49-59
YANGZuliang,DINGJie,LIUJinfeng.Anewtunnelvehiclestoppingdetectionmethodologycombinedwithconvolutionalneuralnetwork[J].JournalofChongqingUniversity(NaturalScienceEdition),2021,44(6):49-59
[5]唐潔.基于改進的卷積神經網絡的違章停車檢測[D].合肥:安徽大學,2019
TANGJie.Illegalparkingdetectionbasedonimprovedconvolutionneuralnetwork[D].Hefei:AnhuiUniversity,2019
[6]梅舒歡,閔巍慶,劉林虎,等.基于FasterR-CNN的食品圖像檢索和分類[J].南京信息工程大學學報(自然科學版),2017,9(6):635-641
MEIShuhuan,MINWeiqing,LIULinhu,etal.FasterR-CNNbasedfoodimageretrievalandclassification[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2017,9(6):635-641
[7]溫秀蘭,焦良葆,李子康,等.復雜環境下小尺度煙火目標檢測研究[J].南京信息工程大學學報(自然科學版),2023,15(6):676-683
WENXiulan,JIAOLiangbao,LIZikang,etal.Smallscalesmoke&firetargetdetectionincomplexenvironment[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2023,15(6):676-683
[8]劉寒迪,趙德群,陳星輝,等.基于改進SSD的航拍施工車輛檢測識別系統設計[J].國外電子測量技術,2020,39(7):127-132
LIUHandi,ZHAODequn,CHENXinghui,etal.DesignofdetectionandrecognitionsystemofaerialphotographyconstructionvehiclebasedonimprovedSSD[J].ForeignElectronicMeasurementTechnology,2020,39(7):127-132
[9]LiuW,AnguelovD,ErhanD,etal.SSD:singleshotmultiboxdetector[C]//EuropeanConferenceonComputerVision.Cham:Springer,2016:21-37
[10]TangHR,PengAM,ZhangDM,etal.SSDreal-timeillegalparkingdetectionbasedoncontextualinformationtransmission[J].Computers,Materials&Continua,2020,62(1):293-307
[11]丁冰,楊祖莨,丁潔,等.基于改進YOLOv3的高速公路隧道內停車檢測方法[J].計算機工程與應用,2021,57(23):234-239
DINGBing,YANGZuliang,DINGJie,etal.DetectionmethodofhighwaytunnelvehiclestoppingbasedonimprovedYOLOv3[J].ComputerEngineeringandApplications,2021,57(23):234-239
[12]許璧麒,馬志強,寶財吉拉呼,等.基于YOLOv5的高速公路小目標車輛逆行檢測模型[J].國外電子測量技術,2022,41(11):146-153
XUBiqi,MAZhiqiang,BAOCaijilahu,etal.SmalltargetvehicleinhighwayretrogradedetectionmodelbasedonYOLOv5[J].ForeignElectronicMeasurementTechnology,2022,41(11):146-153
[13]莊建軍,葉振興.基于改進YOLOv5m的電動車騎行者頭盔與車牌檢測方法[J].南京信息工程大學學報,2024,16(1):1-10
ZHUANGJianjun,YEZhenxing.HelmetandlicenseplatedetectionforelectricbikeriderbasedonimprovedYOLOv5m[J].JournalofNanjingUniversityofInformationScience&Technology,2024,16(1):1-10
[14]韓澤山,楊紅柳,趙建光,等.基于改進YOLOv5s的口罩佩戴檢測算法研究[J].信息技術與信息化,2023(2):22-25
HANZeshan,YANGHongliu,ZHAOJianguang,etal.ResearchonmaskwearingdetectionalgorithmbasedonimprovedYOLOv5s[J].InformationTechnologyandInformatization,2023(2):22-25
[15]LinTY,DollárP,GirshickR,etal.Featurepyramidnetworksforobjectdetection[C]//2017IEEEConferenceonComputerVisionandPatternRecognition(CVPR).July21-26,2017,Honolulu,HI,USA.IEEE,2017:936-944
[16]LiuS,QiL,QinHF,etal.Pathaggregationnetworkforinstancesegmentation[C]//2018IEEE/CVFConferenceonComputerVisionandPatternRecognition.June18-23,2018,SaltLakeCity,UT,USA.IEEE,2018:8759-8768
[17]HanK,WangYH,TianQ,etal.GhostNet:morefeaturesfromcheapoperations[C]//2020IEEE/CVFConferenceonComputerVisionandPatternRecognition(CVPR).June13-19,2020,Seattle,WA,USA.IEEE,2020:1577-1586
[18]WooS,ParkJ,LeeJY,etal.CBAM:convolutionalblockattentionmodule[C]//EuropeanConferenceonComputerVision.Cham:Springer,2018:3-19
Illegalparkingdetectionbasedonimproved
YOLOv5modelandraymethod
ZHUANGJianjun1XUZiheng1ZHANGRuoyu1
1SchoolofElectronics&InformationEngineering,NanjingUniversityofInformationScience&Technology,Nanjing210044,China
AbstractIllegallyparkedvehiclesreduceroadtrafficefficiency,andcausetrafficcongestioneventrafficaccidents.Traditionalvehicledetectionmethodsareperplexedbyalargenumberofparametersandlowaccuracy.Here,weproposeamethodusingtheimprovedYOLOv5modelandraymethodtodetectillegallyparkedvehicles.First,alightweightfeatureextractionmoduleisdesignedtoreducetheamountofmodelparameters.Second,theattentionmechanismisaddedtothemodeltoenhanceitsfeatureextractionabilityfrombothchanneldimensionandspatialdimensiontoensurethemodelsaccuracy.Then,themixeddataisusedtoenhanceandenrichthedatasetsamplesthusimprovethedetectionperformanceincomplexbackgrounds,andEIoUisselectedasthelossfunctiontoimprovethemodelspositioningperformance.ExperimentsshowthatthemeanaccuracyoftheimprovedYOLOv5modelreaches91.35%,whichis1.01percentagepointshigherthanthatoftheoriginalYOLOv5s,andthenumberofparametersisreducedby35.79%.Finally,theimprovedYOLOv5modeliscombinedwiththeraymethod,whichcanreachreal-timeinspectionspeedof28framespersecondontheembeddedplatformofJetsonXavierNX.
Keywordsillegalparkingdetection;YOLOv5;Ghostconvolution;attentionmechanism;raymethod
