基于改進YOLOv7的無人機圖像目標檢測算法
2024-07-17 00:00:00梁秀滿賈梓涵于海峰劉振東
無線電工程 2024年4期
關鍵詞:無人機


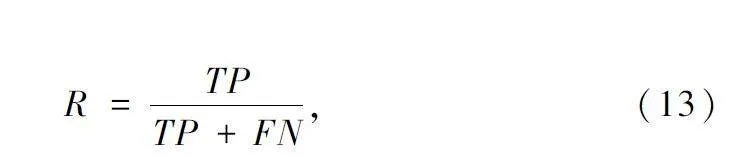



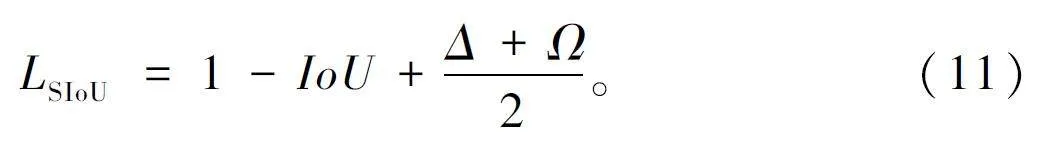
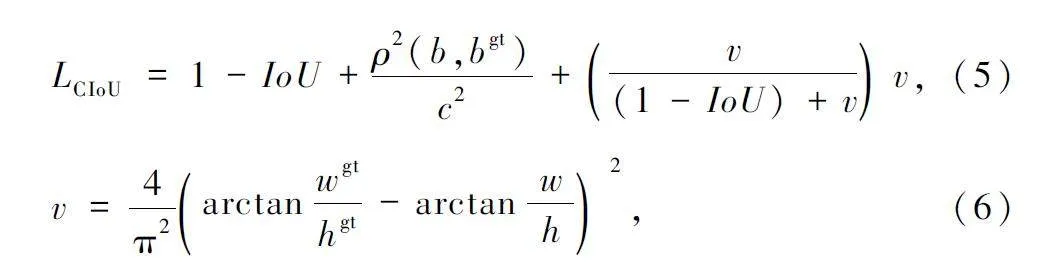

摘 要:針對無人機圖像中由于目標微小且相互遮擋、特征信息少導致檢測精度低的問題,提出一種基于改進YOLOv7的無人機圖像目標檢測算法。在頸部和檢測頭中加入了坐標卷積,能更好地感受特征圖中目標的位置信息;增加P2 檢測層,減少小目標特征丟失、提高小目標檢測能力;提出多信息流融合注意力機制———Spatial and Channel Attention Mechanism(SCA),動態調整注意力對空間信息流和語義信息流的關注,獲得更豐富的特征信息以提高捕獲目標的能力;更換損失函數為SIoU,加快模型收斂速度。在公開數據集VisDrone2019 上進行對比實驗,改進后算法的mAP50 值相比YOLOv7 提高了4% ,達到了52. 4% ,FPS 為37,消融實驗驗證了每個模塊均提升了檢測精度。實驗表明,改進后的算法能較好地檢測無人機圖像中的目標。
關鍵詞:無人機;小目標檢測;多信息流融合注意力機制;YOLOv7;損失函數
中圖分類號:TP391. 4 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)04-0937-10
0 引言
隨著技術的進步和不斷創新,無人機的應用正逐漸融入到日常生活中,例如農業、電力能源、攝影和地質勘探等。由于無人機飛行在一定高度,拍攝的圖像存在大量小尺寸目標以及目標之間相互遮擋的現象,從而導致檢測的準確度下降。這一問題在對無人機圖像進行目標檢測時帶來了一定的挑戰。因此,設計一種能夠精準地檢測無人機圖像目標的網絡結構變得尤為重要。卷積神經網絡(Convolutional NeuralNetwork,CNN)的出現,使得基于深度學習的目標檢測技術迅速發展[1]。目前基于深度學習的目標檢測算法根據有無候選區域分為2 類:兩階段算法和單階段算法。兩階段算法以Fast R-CNN[2]、Faster R-CNN[3]為代表。單階段算法中的典型算法為SSD[4]和YOLO 系列YOLOv1[5]、YOLOv3[6]、YOLOv4[7]、YOLOv7[8]等,單階段算法因在檢測精度和計算效率之間能夠取得平衡,已成為目標檢測任務中一個具有吸引力的選擇。
為提高對無人機圖像的檢測精度,趙耘徹等[9]使用輕量級網絡MobileNetv3 替換YOLOv4 的主干網絡,并使用Kmeans++算法重新生成錨框,減少模型的參數量的同時提升了檢測精度。雷幫軍等[10]在檢測模型中引入自適應校準模塊,融合來自不同空間的特征信息,使輸出特征圖的感受野變大,并引入注意力機制使其更加關注局部信息,檢測精度有了顯著提升。王恒濤等[11]提出一種基于YOLOv5的輕量化網絡結構,通過對檢測層和感受野進行調整,使淺層特征的權重變大,提高了對小目標的檢測能力。張上等[12]重新設計了YOLOv5 中的特征提取網絡和特征融合網絡,大大降低了網絡模型參數,使用EIoU 加速模型收斂,能滿足無人機對小目標的實時檢測需求。劉展威等[13]在主干網絡中加入了CA 注意力機制,用于提高網絡對目標位置信息的關注度,在頸部加入了BiFPN 結構,能有效融合不同層次之間的特征信息,檢測精度相比基線大幅提高。Li 等[14] 引入Bi-PAN-FPN 的思想,改進了YOLOv8 的頸部網絡,在保證模型參數量可控的情況下,能使網絡更好地進行特征融合,將主干中部分C2f 模塊變成了GhostblockV2 結構,保證特征在長距離傳輸中不丟失信息,具有較強的魯棒性。齊向明等[15]將YOLOv7 中SPPCSPC 結構中的2 個CBS層改為了SimAM 注意力機制,同時縮小了池化層中的池化核,可以提高網絡對密集區域的關注程度,捕獲相互遮擋目標的特征。張徐等[16]基于YOLOv7算法,將主干網絡的EELAN 模塊替換成使用余弦注意機制和后正則化方法改進后的SwinTransformer(STR)模塊,能夠更好地捕捉圖像中的上下文信息,理解目標與背景之間的關系,并且具有較好的實時性和魯棒性。
盡管上述工作對提高無人機圖像檢測精度做出了有效改進,但無人機圖像中小目標繁多且呈現密集的趨勢,仍容易出現漏檢、誤檢等情況,并且對于目標的特征提取能力不足,導致檢測精度不高。針對上述問題,本文考慮無人機圖像的特點,提出一種基于YOLOv7 的無人機圖像目標檢測算法,主要工作如下:
① 將CoordConv 引入網絡的頸部和頭部,使卷積具備空間感知能力,能在提取的特征中更好地定位目標。
② 添加P2 檢測層,與其他3 個檢測層相結合獲取更多小目標的特征,能顯著提升小目標的檢測精度。利用Kmeans 聚類算法重新生成先驗框。
③ 提出一種新穎的多信息流融合注意力機制———Spatial and Channel Attention Mechanism(SCA),將不同層次的全局信息和局部信息結合起來,有助于不同尺度的特征提取,提高多尺度表達能力,捕獲小目標的能力顯著提高。
④ 將邊界框損失函數替換為SIoU,考慮了預測框和真實框之間的角度差異,進而加快模型訓練速度。
1 YOLOv7 算法
YOLOv7 是一個兼具速度與精度的檢測模型,在YOLOv5 的基礎上改進得到。YOLOv7 由輸入端(Input)、主干網絡(Backbone)、頸部網絡(Neck)和頭部(Head)組成。首先將輸入端處理好的圖片送入主干網絡進行特征提取,然后進入頸部網絡進行特征融合,得到3 種不同尺寸的特征,最后將這3 種特征送入檢測頭,得到預測結果。
輸入端:對輸入圖像進行數據增強、自適應錨框計算和自適應圖像縮放等處理,豐富數據集的同時能加快網絡訓練速度。
主干網絡:對輸入端傳來的圖像進行特征提取,主干由若干個ELAN、CBS 和MPConv 模塊組成,使主干網絡具備優秀的特征提取能力。ELAN 由多個CBS 構成,使網絡能夠學習到豐富的特征。
頸部網絡:包含SPPCSPC、ELANW、CBS 和MPConv 模塊。SPPCSPC 用來增大感受野,ELANW 比ELAN 多了2 個輸出進行拼接操作。與YOLOv5 相同,頸部網絡也使用FPN 和PAN 進行特征融合,得到3 種不同尺寸的特征。
頭部:根據頸部3 個不同尺度的特征輸出來預測物體的位置和類別。
2 改進的YOLOv7 算法
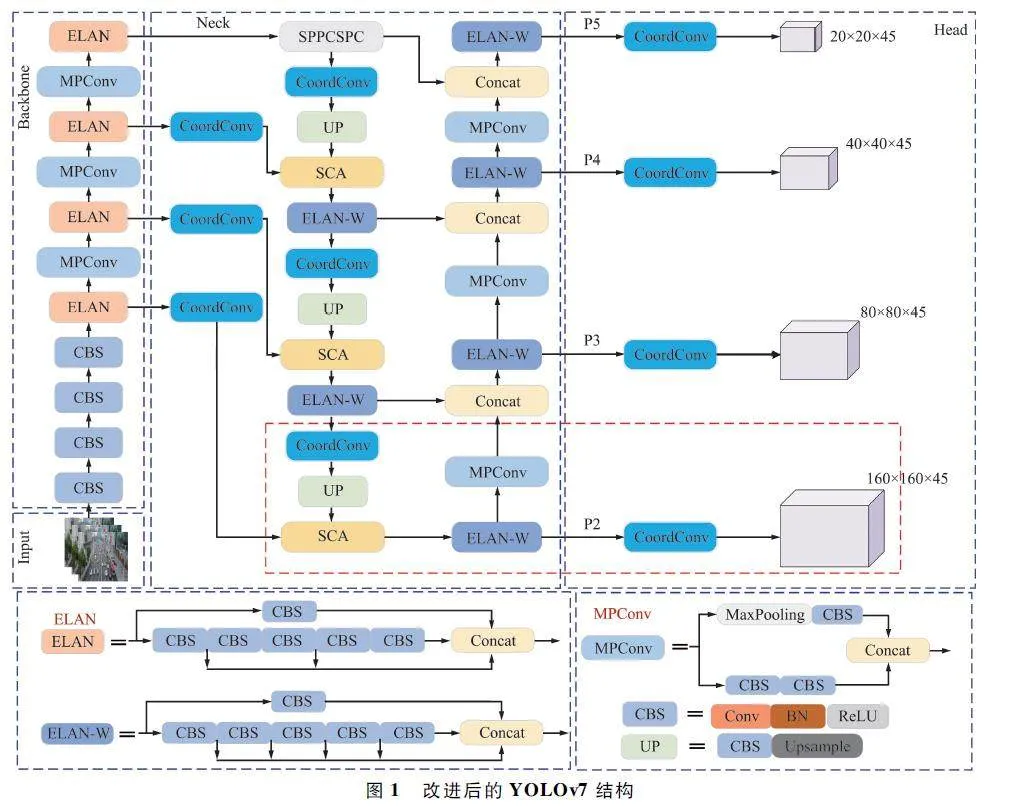
本文以YOLOv7 為基線模型,添加坐標卷積、P2檢測層和SCA,并將SIoU 作為邊界框損失函數。改進后的網絡結構如圖1 所示。
2. 1 CoordConv 模塊
深度學習中的卷積運算有平移等變形,允許在圖像的不同位置共享參數,從而有效地捕捉特征。然而,這種方式也帶來了一個限制:在卷積的學習過程中,網絡無法感知當前特征在圖像中的具體坐標位置。因此,本文將頸部網絡中的卷積模塊和檢測頭中的卷積模塊替換為CoordConv[17]模塊。
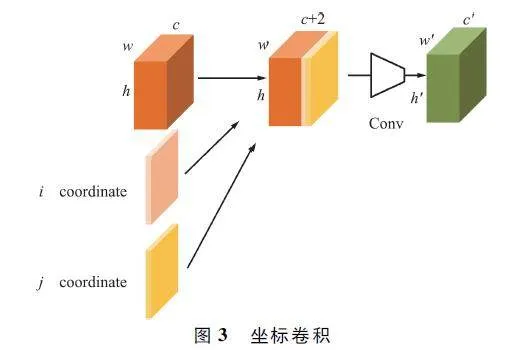
為了使卷積具備感知空間信息的能力,在特征圖后加入了2 個坐標通道,代表原始輸入的i 和j 坐標,然后再進行傳統卷積操作,使卷積能夠感受特征圖的空間信息。如果坐標通道學習了一定的信息,那么CoordConv 就具備了平移依賴性,當沒有學習到信息時,等同于傳統卷積具備平移不變性。傳統卷積如圖2 所示,坐標卷積如圖3 所示。
2. 2 增加小目標檢測層
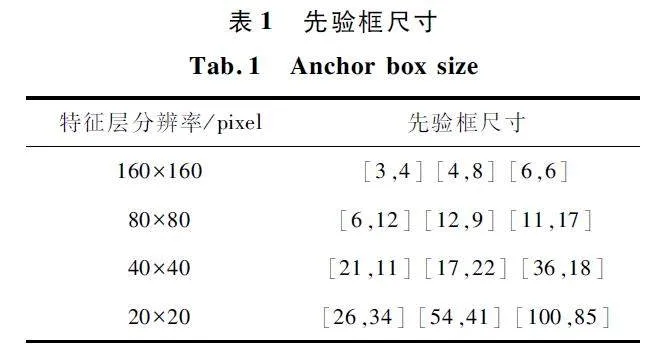
無人機從一定高度采集圖像,目標在圖像中占據較小的像素,同時YOLOv7 算法在多次進行下采樣過程中會丟失小目標的特征信息,導致小目標的檢測精度不盡人意。為了增加小目標的特征提取能力,進而有效提高小目標的檢測精度,本文在不改變其他特征圖尺度的基礎上,在頸部網絡添加一個分辨率為160 pixel×160 pixel 的P2 檢測層。該層位于原有頸部網絡上采樣過程中的最后一個ELANW模塊之后,該層的輸入包含部分:一部分是主干網絡中第一個ELAN 模塊進行卷積之后的特征圖;另一部分是經過卷積和上采樣操作的擴展特征圖。將來自兩部分的特征圖由ELANW 模塊進行融合,得到包含豐富位置信息的特征圖。P2、P3、P4、P5 檢測層分別對應了4 倍、8 倍、16 倍、32 倍下采樣特征圖,4 倍下采樣特征圖感受野較小,位置信息更加豐富,因此其特征圖包含大量小目標的紋理特征及更多的細節信息,在特征圖的傳遞過程中,能最大程度地保留小目標的特征,進而提升小目標檢測精度。增加的小目標檢測層如圖1 中紅色虛線框所示。由于本文數據集中小目標眾多,寬高尺寸都比較小,不宜使用原來的先驗框,因此利用Kmeans 聚類算法生成一組更加匹配數據集的先驗框,如表1 所示。
2. 3 多信息流融合注意力機制
特征融合是把不同層之間的特征進行結合,低層的特征圖有較多的空間信息,高層的特征圖有較多的語義信息。目前的注意力機制大多是對單層和單個信息流中傳遞來的特征進行處理,可能會丟失某些特征信息。為了得到更全面的特征信息,使模型更加關注應該注意的目標,本文提出SCA。相比傳統注意力,本文注意力擴展到多個信息流,可以動態調整注意力對空間信息流和語義信息流的關注,將不同層次的全局信息和局部信息結合起來,獲取更多更全面的特征。
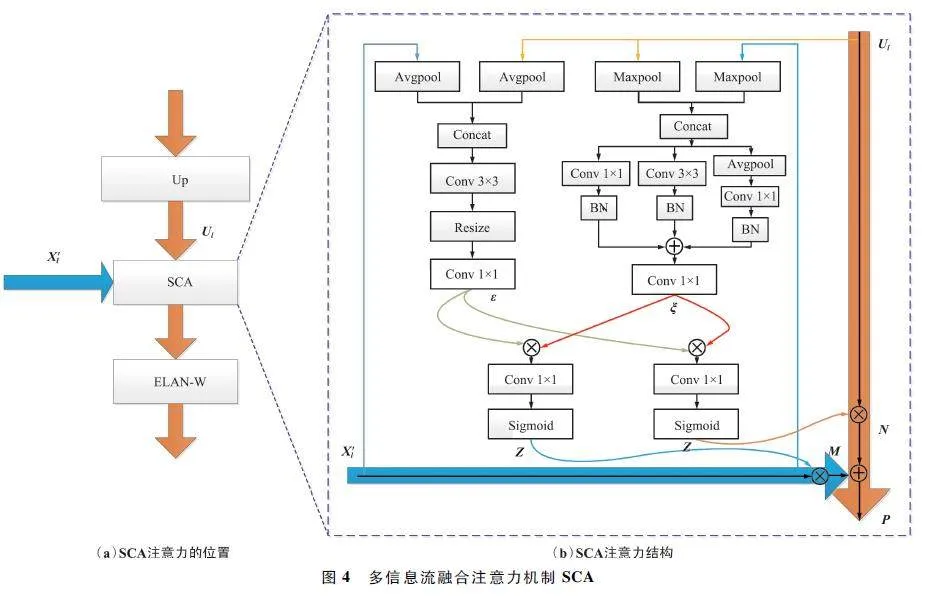
多信息流融合注意力機制SCA 如圖4 所示。圖4(a)表示注意力所添加的位置,圖4(b)左側為空間注意力,右側為通道注意力。
Ul 代表語義信息流,X′l 代表空間信息流。在空間注意力中更關注位置信息,更加關注特征圖中含有有效信息的區域。將Ul 和X′l 分別通過平均池化層進行壓縮操作,將2 個輸出拼接后通過3×3 卷積提取更豐富的特征,調整雙線性層的大小,再經過一個1 ×1 調整通道數后得到ε。通道注意力同樣使Ul 和X′l 通過最大池化層,使其在空間維度上整合全局空間信息并縮小特征圖。將其結果進行拼接后,分別通過1 ×1、3 ×3 以及平均池化后的1 ×1卷積操作,得到包含不同信息的特征圖。
將上述操作結果相加經過1 ×1 卷積調整通道數后得到ξ。將ε 和ξ 拼接后通過1×1 的卷積,經過Sigmoid 激活函數得到權重Z,平衡了語義信息和空間信息之間的關系。計算如下:
Z = Sigmoid(Conv(ε,ξ))。(1)
上述空間注意力和通道注意力結合就構成了多信息流注意力機制。將權重分別與空間信息流和語義信息流相乘得到M 和N:
M = Z × X′l , (2)
N = Z × Ul。(3)
最后將M 和N 進行加和操作,結合通道與空間2 個維度的特征。加和后經過Sigmoid 激活函數得到融合空間和通道注意力的權重,定義如下:
P = Sigmoid(M + N)。(4)
本文所提出的多信息流注意力機制可以結合不同層次的語義信息和空間信息,在不同尺度上提取更全面的特征,減少背景信息的干擾,提升檢測精度。
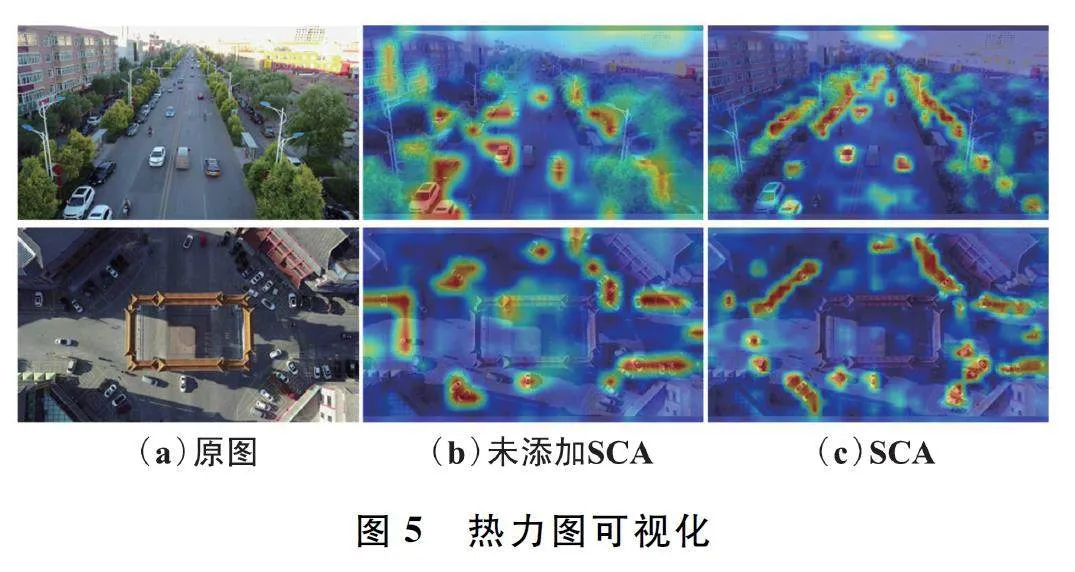
為了更直觀地驗證多信息流融合注意力SCA的有效性,圖5 展示了添加SCA 注意力前后的熱力圖。圖5(a)為原始輸入圖片,圖5(b)為基線模型的熱力圖,圖5(c)為基線基礎上添加SCA 注意力后的熱力圖。可以看出添加SCA 注意力后模型對圖片中的目標定位更加準確,更有效地關注圖片中的重要信息,過濾背景信息。
2. 4 改進損失函數
YOLOv7 采用的損失函數包括邊界損失、置信度損失和分類損失。邊界損失和置信度損失由交叉熵損失函數進行計算,而邊界框損失函數使用CIoU損失函數計算:
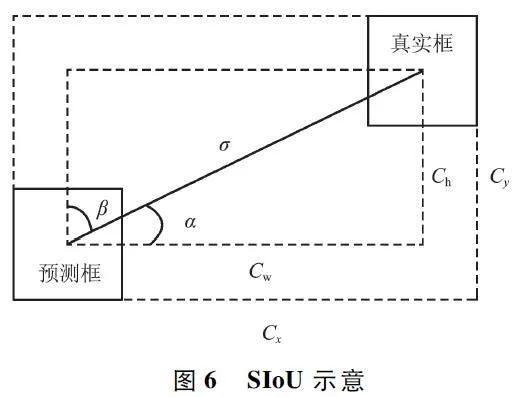
式中:b 和bgt 分別表示預測框和真實框的中心點,ρ表示2 個框中心點之間的歐氏距離,c 表示包含2個框的最小方框的對角線距離,wgt、hgt 表示真實框的寬度和高度,w、h 表示預測框的寬度和高度。可以看出,CIoU 基于預測框和真實框的寬高相對比例進行計算,二者寬高比例一致時其懲罰項就失效了。為此,本文使用SIoU[18]替換原來的CIoU,其包含的參數和示意如圖6 所示。SIoU 損失函數包括角度成本、距離成本和形狀成本三部分。具體的計算如下:
(1)角度成本
若α 的角度小于45° ,則直接帶入下述公式計算,否則使用α 的互補角β 代替,角度成本的計算如下:
式中:x 為α 的正弦值,σ 為兩框中點之間的距離,ch為兩框之間的高度差。
(2)距離成本
距離成本定義如下:
Δ = Σt = x,y(1 - e-γρt) = 2 - e-γρx - e-γρy , (9)
式中:γ = 2-Λ,ρx 表示Cw 和Cx 之比的平方,ρy 表示Ch 和Cy 之比的平方。
(3)形狀成本
形狀成本定義如下:
Ω = (1 - e-ωw) θ + (1 - e-ωh) θ , (10)
式中:θ 的值定義了形狀成本的權重,控制著應該將多少注意力放在形狀成本上,本文中θ 值為1。ωw表示兩框寬度差的絕對值與最大值之比,ωh 表示兩框高度差的絕對值與最大值之比。最后,SIoU 的定義如下:
相比其他損失函數,SIoU 考慮了角度因素,使預測框能更快地向真實框靠近,加快損失函數的收斂速度。SIoU 在計算真實框和預測框的寬高關系時,采用分別計算的方法,而不是計算其相對比例,避免了預測框和真實框寬高比相同時懲罰項為0 的情況。
3 實驗與結果分析
3. 1 實驗環境與數據集
網絡訓練基于深度學習框架PyTorch1. 11. 0 實現,并使用CUDA11. 3 進行訓練。實驗在Ubuntu20. 04 環境下進行,RTXA5000 顯卡,24 GB 顯存,Intel(R )Xeon (R ) Platinum 8358P @ 2. 60 GHzCPU。輸入圖像大小為640 pixel × 640 pixel,訓練300 輪,batchsize 設為8,初始學習率為0. 01。
本文采用天津大學機器學習與數據挖掘實驗室AiskYeye 團隊收集的VisDrone2019 數據集[19],由288 個視頻片段、261 908 幀和10 209 幅靜態圖像組成,共6 471 幅圖像用以訓練,548 幅圖像用以驗證,1 610 幅圖像用以測試。該數據為日常生活中的場景,總共包含10 個類別,分別為行人、人、自行車、汽車、面包車、卡車、三輪車、遮陽篷三輪車、公共汽車和摩托車。數據集中,類別比例不均衡,并且圖片中大多以小目標的形式存在,給檢測帶來了極大的挑戰。
3. 2 評價指標
本文所用到的評價指標有精準率(Precision,P)、召回率(Recall,R)、平均精度均值(mAP)、模型參數量、每秒檢測幀數(FPS)和浮點運算次數(GFLOPs)。P 指預測為正樣本中實際正樣本的比例,計算如下:
式中:TP 為正確預測出正樣本的檢測框數量,FP 為負樣本被預測成正類的數量。
Recall 代表正確預測的樣本數占總樣本數的比例,計算如下:
式中:FN 為被預測成負類的正樣本數。
mAP 代表平均精度均值,是所有類別檢測精度的平均值,計算如下:
式中:n 為檢測的類別數量,AP 為PR 曲線下面的面積。mAP50 是IoU 為0. 5 時所有類別的平均檢測精度;mAP50:95 是IoU 以0. 05 為步長、0. 5 ~ 0. 95的全部平均檢測精度。
FPS 為模型每秒處理的圖片數量,用來衡量檢測速度;GFLOPs 為網絡模型的浮點運算次數。
3. 3 消融實驗
為了驗證所提出的方法對無人機圖像檢測性能的有效性,本文進行了消融實驗,以YOLOv7 為基線,逐步加入所提出的改進方法,實驗結果如表2 所示。
分析表2 結果可知,引入CoordConv、加入小目標檢測層、加入SCA 注意力、損失函數更換為SIoU都提升了檢測性能。改進1 使用CoordConv 替代了頸部和頭部中卷積核為1 的卷積,具備了空間感知能力,可以有效地定位目標,mAP50 提高了0. 6% 的同時參數量降低了0. 6 M,檢測速度也由原來的48提高到了52,驗證了改進1 的有效性。改進2 添加了小目標檢測層,由于多了ELANW 模塊、上采樣、額外的卷積操作和檢測頭,導致模型的復雜度增加,計算量增加在可接受范圍之內,但是能最大程度保留小目標位置信息,檢測精度有了極大的提升,小目標檢測層的加入使檢測精度相比基線提升了2. 1% ,達到了50. 5% 。改進3 在基線模型添加了SCA。SCA 注意力的加入,使不同尺度的特征融合,補充上下文信息,獲得了更全面的特征,從而提高了檢測精度,同時也帶來了一定的參數量,FPS 也有所下降,但是檢測精度提升了1. 7% 。改進4 替換了損失函數,SIoU 考慮了角度成本和距離成本,在沒有增加參數量和計算量的情況下,檢測精度提升了1. 1% ,相比基線,檢測速度也有所提升。改進5 將改進1 和改進2 相結合,雖然僅比改進2 的精度提升了0. 2% ,但是參數量有所下降。改進6 在改進5的基礎上添加了SCA,檢測精度再次提升了0. 2% 。改進7 將所有改進方法融合在一起,mAP50 的值相比基線模型提高了4% ,達到了52. 4% 。通過消融實驗可以看到,本文所提出的每個改進都提升了模型的檢測性能,雖然改進的模塊帶來了一定的計算量和參數量,但是檢測精度得到了提升,能滿足實時性檢測的需求。
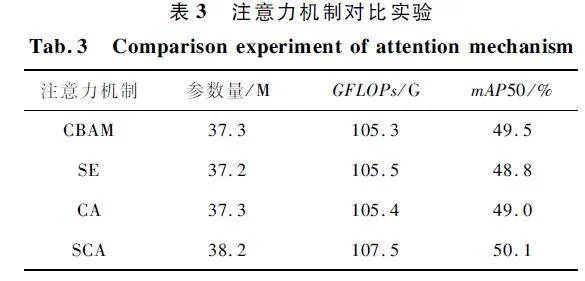
3. 4 注意力對比實驗
為了驗證本文所提出注意力的有效性,將目前主流的SE[20]、CBAM[21]、CA[22]注意力機制與本文注意力機制進行對比實驗。在YOLOv7 的基礎上,在相同的位置添加注意力機制,設置相同參數。實驗結果如表3 所示,可以看出,本文所提出的注意力機制相比其他3 個注意力機制帶來了額外的參數量,但是檢測精度高于其他3 個注意力機制,提升了1. 7% ,證明了模型中添加SCA 注意力的有效性。加入SCA 注意力,可以使模型更加關注有效區域,提高對目標的關注度,減輕背景信息對檢測的干擾,從而提升檢測精度。
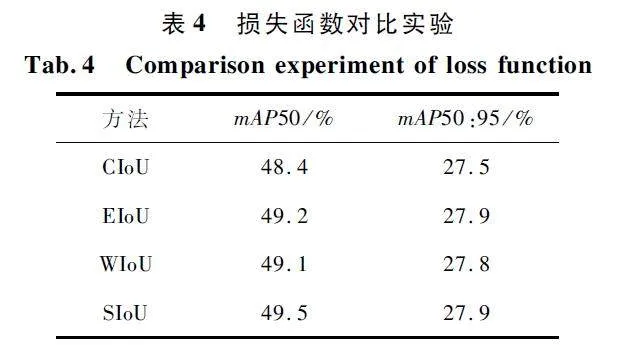
3. 5 損失函數對比實驗
表4 展示了本文所用的損失函數SIoU 與CIoU、EIoU[23]和WIoU[24]在VisDrone2019 數據集上的對比實驗結果,以mAP50 和mAP50:95 為評價指標,從結果中可以看出SIoU 與EIoU 有著相同的mAP50:95,但mAP50 高于EIoU。相比其他損失函數,SIoU 具有更良好的性能表現和更快的收斂速度。
3. 6 對比實驗
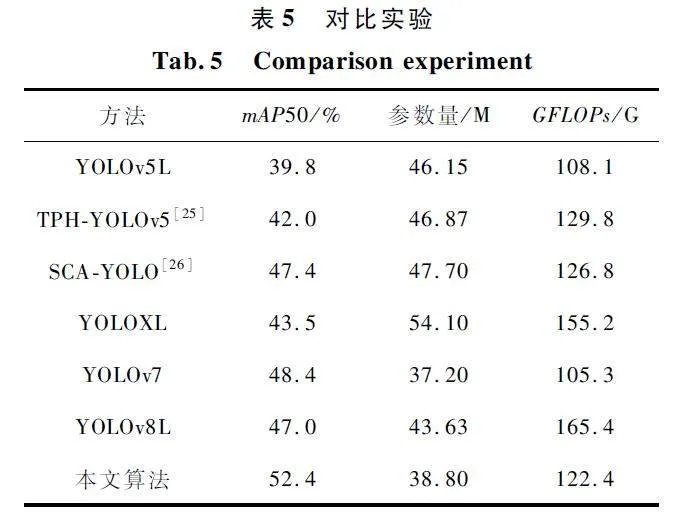
為了進一步驗證本文算法的性能優勢,本文采用YOLO 系列中具有代表性的算法YOLOv5L、TPHYOLOv5、SCAYOLO、YOLOXL、YOLOv7 和YOLOv8L在公開數據集VisDrone2019 上與本文算法進行對比實驗,實驗結果如表5 所示。
由表5 可知,YOLOv5L 比本文算法的mAP50值低了12. 6% ,并且參數量多出了7. 35 M,對該數據集的檢測效果不佳。TPHYOLOv5 比YOLOv5L的mAP50 值高了2. 2% ,同時帶來了額外的計算量。SCAYOLO 是在YOLOv5L 的基礎上進行改進的,相比YOLOv5L 精度提高明顯,但仍然低于本文算法。YOLOXL 相比本文算法在參數量和計算量上都有大幅度增加,且檢測精度相差8. 9% 。YOLOv8 是目前最先進的檢測算法,計算量和參數量分別比本文算法多了35% 和12% ,并且檢測精度低了5% 。
分析得知,盡管本文算法在參數量和計算量上都有小幅增長,但仍然低于同量級的其他主流檢測算法,并且本文算法在檢測精度上占據優勢,檢測精度達到了52. 4% ,能夠滿足實時性檢測的需求。因此本文算法綜合表現最好,驗證了改進的有效性,對復雜場景下的目標具有更強的辨識能力。
3. 7 可視化分析
在VisDrone2019 的測試集中選取了密集、模糊、遮擋和高空場景下具有代表性的圖片進行檢測,用于更直觀地評估本文算法。檢測效果如圖7 所示。圖7(a)是密集場景下的檢測圖,可以看到圖片中有較多種類的小目標且目標之間相互重疊比例較大,尤其是人群相互重疊的現象十分嚴重,但本文算法依然可以檢測出行人這一類別。圖7(b)是模糊場景下的檢測圖,由于無人機移動速度較快導致拍攝的圖像出現了模糊的情況,但仍然可以檢測出車輛、行人等類別;下方的圖片受昏暗和部分光照的影響,圖片質量不高,同樣可以較為全面地檢測出圖像的目標。圖7(c)展示了遮擋情況下的檢測圖,圖像中存在大量樹木遮蓋住了部分物體,使小目標更加不明顯,圖中可以看出,改進后的算法仍然可以檢測出被樹木遮擋住的汽車。圖7(d)是高空場景的檢測圖,與其他3 組場景相比,高空場景的圖片中車輛變得非常微小,并且背景占了圖片的大部分內容,背景噪聲給檢測帶來了一定的挑戰,但改進的算法仍然檢測出了微小車輛的存在。
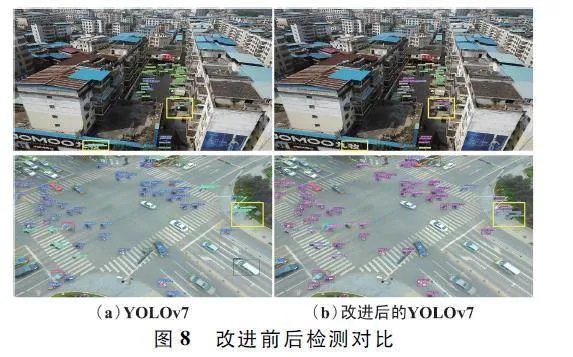
將基線模型和改進后的算法進行對比,檢測效果對比如圖8 所示。圖8(a)為YOLOv7 的檢測圖,圖8(b)為改進后的YOLOv7 檢測圖,為更方便地看出差異,將不同的地方用黃色框標注出來。從第一行可以看出,YOLOv7 將廣告牌上的字誤檢成了行人類別,并且樓房旁邊的重疊摩托車沒有檢測出來,而改進后的算法將其檢測了出來。從第二行中看出,YOLOv7 沒有檢測出重疊的人群。改進后的算法較YOLOv7 相比,有更高檢測精度的同時減少了漏檢、誤檢的現象。
4 結論
本文提出了一種基于YOLOv7 改進的無人機圖像目標檢測算法,主要工作和結論如下:
① 在頸部和檢測頭中加入了坐標卷積,網絡能夠感受特征圖中物體的位置信息,提高了空間感知能力,進一步定位目標從而提升了檢測精度。
② 針對圖像中小目標占比大的問題,生成一組新的錨框,同時在頸部增加較淺的P2 檢測層,使網絡在特征提取時獲得更多小目標的信息,從而提高了小目標的檢測精度。
③ 針對檢測密集場景中出現誤檢漏檢的現象,提出了SCA,將不同層次的全局信息和局部信息結合,獲得更加全面的特征信息,降低了漏檢誤檢現象的發生,mAP50 值提升了1. 7% 。
④ 使用SIoU 替換CIoU,加快模型收斂速度同時提高了檢測精度。
在VisDrone2019 數據集上的實驗結果表明,改進后算法的mAP50 值為52. 4% ,提高了4% ,FPS為37。消融實驗中,逐一驗證了每一個改進模塊對提升檢測精度的有效性。本文改進的算法優于目前主流的目標檢測算法,能較好地檢測出無人機圖像中的目標。改進后的模型在檢測精度上有更大優勢,同時也能滿足實時性檢測的需求。接下來將繼續深入研究,降低模型的計算復雜度和參數量,使模型整體更加輕量化,并用不同的數據集驗證模型的泛化性。
參考文獻
[1] ZOU Z X,CHEN K Y,SHI Z W,et al. Object Detection in20 Years:A Survey[J]. Proceedings of the IEEE,2023,111(3):257-276.
[2] GIRSHICK R. Fast RCNN[C]∥2015 IEEE InternationalConference on Computer Vision. Santiago:IEEE,2015:1440-1448.
[3] REN S Q,HE K M,GIRSHICK R,et al. Faster RCNN:Towards Realtime Object Detection with Region ProposalNetworks[J]. IEEE Transactions on Pattern Analysis andMachine Intelligence,2017,39(6):1137-1149.
[4] LIU W,ANGUELOV D,ERHAN D,et al. SSD:SingleShot Multibox Detector [C ]∥ Computer VisionECCV2016:14th European Conference. Amsterdam:Springer,2016:21-37.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al. You OnlyLook Once:Unified,Realtime Object Detection [C]∥2016 IEEE Conference on Computer Vision and PatternRecognition (CVPR). Las Vegas:IEEE,2016:779-788.
[6] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement[EB / OL]. (2018 - 04 - 08)[2023 - 06 - 07].https:∥arxiv. org / abs / 1804. 02767.
[7] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection [EB /OL]. (2020 - 04 - 23)[2023 - 06 - 07]. https:∥ arxiv.org / abs / 2004. 10934.
[8] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. YOLOv7:Trainable Bagoffreebies Sets New Stateoftheart forRealtime Object Detectors[C]∥2023 IEEE / CVF Conference on Computer Vision and Pattern Recognition(CVPR). Vancouver:IEEE,2023:7464-7475.
[9] 趙耘徹,張文勝,劉世偉. 基于改進YOLOv4 的無人機航拍目標檢測算法[J]. 電子測量技術,2023,46(8):169-175.
[10] 雷幫軍,耿紅彬,吳正平. 基于自適應校準和多分支注意力的遙感目標檢測[J]. 電子測量技術,2022,45(22):106-111.
[11] 王恒濤,張上,陳想,等. 輕量化無人機航拍目標檢測算法[J]. 電子測量技術,2022,45(19):167-174.
[12] 張上,張岳,王恒濤,等. 輕量化無人機遙感圖像小目標檢測算法[J]. 無線電工程,2023,53(10):2329-2336.
[13] 劉展威,陳慈發,董方敏. 基于YOLOv5s 的航拍小目標檢測改進算法研究[J]. 無線電工程,2023,53 (10):2286-2294.
[14] LI Y T,FAN Q S,HUANG H S,et al. A ModifiedYOLOv8 Detection Network for UAV Aerial Image Recognition[J]. Drones,2023,7(5):304.
[15] 齊向明,柴蕊,高一萌. 重構SPPCSPC 與優化下采樣的小目標檢測算法[J]. 計算機工程與應用,2023,59(20):158-166.
[16] 張徐,朱正為,郭玉英,等. 基于cosSTRYOLOv7 的多尺度遙感小目標檢測[J / OL ]. 電光與控制:1 - 9[2023-06 -24]. http:∥ kns. cnki. net / kcms / detail / 41.1227. tn. 20230615. 1017. 002. html.
[17] LIU R,LEHMAN J,MOLINO P,et al. An IntriguingFailing of Convolutional Neural Networks and the Coordconv Solution [EB / OL]. (2018 - 07 - 09 )[2023 - 06 -24]. https:∥arxiv. org / abs / 1807. 03247.
[18] GEVORGYAN Z. SIoU Loss:More Powerful Learning forBounding Box Regression [EB / OL ]. (2022 - 05 - 25 )[2023-06-24]. https:∥arxiv. org / abs / 2205. 12740.
[19] ZHU P F,WEN L Y,DU D W,et al. Detection and Tracking Meet Drones Challenge [J]. IEEE Transactions onPattern Analysis and Machine Intelligence,2021,44(11):7380-7399.
[20] HU J,SHEN L,SUN G. SqueezeandExcitation Networks[C]∥2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:7132-7141.
[21] WOO S,PARK J,LEE J Y,et al. CBAM:ConvolutionalBlock Attention Module [C ]∥ Proceedings of theEuropean Conference on Computer Vision (ECCV2018). Munich:Springer,2018:3-19.
[22] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attentionfor Efficient Mobile Network Design [C]∥ 2021 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE,2021:13708-13717.
[23] ZHANG Y F,REN W Q,ZHANG Z,et al. Focal and Efficient IOU Loss for Accurate Bounding Box Regression[J]. Neurocomputing,2022,506:146-157.
[24] TONG Z J,CHEN Y H,XU Z W,et al. WiseIoU:Bounding Box Regression Loss with Dynamic FocusingMechanism[EB / OL]. (2023 -01 -24)[2023 -06 -26].https:∥arxiv. org / abs / 2301. 10051.
[25] ZHU X K,LYU S C,WANG X,et al. TPHYOLOv5:Improved YOLOv5 Based on Transformer Prediction Headfor Object Detection on Dronecaptured Scenarios[C]∥2021 IEEE / CVF International Conference on ComputerVision Workshops (ICCVW ). Montreal:IEEE,2021:2778-2788.
[26] ZENG S,YANG W Z,JIAO Y Y,et al. SCAYOLO:ANew Small Object Detection Model for UAV Images[J].The Visual Computer,2024,40:1787-1803.
作者簡介
梁秀滿 女,(1973—),碩士,副教授,碩士生導師。主要研究方向:檢測技術及智能裝置、人工智能與模式識別。
賈梓涵 男,(2000—),碩士研究生。主要研究方向:深度學習與圖像處理。
(*通信作者)于海峰 男,(1990—),博士,講師。主要研究方向:深度學習與圖像處理。
劉振東 男,(1973—),碩士,副高級工程師。主要研究方向:深度學習與圖像處理。
基金項目:河北省自然科學基金(F2018209289)
猜你喜歡
電腦知識與技術(2016年28期)2016-12-21 12:21:32
電子技術與軟件工程(2016年19期)2016-12-19 18:28:28
新教育時代·教師版(2016年27期)2016-12-06 18:14:59
中國科技縱橫(2016年17期)2016-11-30 11:51:57
農機使用與維修(2016年10期)2016-11-10 09:45:55
人間(2016年26期)2016-11-03 17:52:40
中國科技博覽(2016年22期)2016-11-01 18:10:31
科技視界(2016年22期)2016-10-18 14:30:27
企業導報(2016年9期)2016-05-26 20:58:26
