
大語言模型在電網企業的應用前景研究
2024-08-03 00:00:00左星宇
科技創新與應用 2024年22期

摘 要:大語言模型是自然語言處理領域的重要研究方向之一,廣泛應用于包括電力在內的諸多行業。該文首先從大語言模型的發展歷程出發,在大規模預訓練語言模型和發展趨勢2個方面闡述相關研究發展;然后探討大語言模型在電網企業電力營銷、電力運檢、電力調度和輿情風險識別等方面的應用前景和研究成果;最后提出電力大語言模型需解決的安全和技術問題,為進一步推動大語言模型在電網企業的應用提供參考。
關鍵詞:大語言模型;自然語言處理;人工智能;電力營銷;電力運維;電力調度
中圖分類號:TP18 文獻標志碼:A 文章編號:2095-2945(2024)22-0009-05
Abstract: Large language model is one of the important research directions in the field of natural language processing, which is widely used in many industries, including electric power. Starting with the development process of large language model, this paper expounds the related research and development in two aspects of large-scale pre-training language model and development trend, and then discusses the application prospect and research results of large language model in power grid enterprise power marketing, power operation and inspection, power dispatching, public opinion risk identification and so on. Finally, this paper puts forward the security and technical problems that need to be solved in the power large language model, which provides a reference for further promoting the application of the large language model in power grid enterprises.
Keywords: large language model; natural language processing; artificial intelligence(AI); power marketing; power operation and maintenance; power dispatching
20世紀90年代以來,互聯網技術的發展加速了人工智能的創新研究,推動了人工智能技術的實用和落地。當前,人工智能領域的大量研究集中在深度學習技術,而自然語言處理是重要研究方向之一。隨著深度學習技術的發展及預訓練模型的流行,大規模預訓練語言模型又稱大語言模型(Large Language Model,LLM)成為自然語言處理領域關注的焦點[1-2]。大語言模型是通過大規模的無監督訓練來理解、處理、生成自然語言的一種人工智能模型。與傳統的自然語言處理模型相比,LLM可以更好地處理復雜語義解析,并表現出一定的邏輯思維和推理能力。以ChatGPT、GPT-3為代表,LLM帶動互聯網行業快速發展并掀起研發浪潮,國內科技公司百度的“文心一言”,華為的“盤古”系列,阿里云的“通義”也隨之發布。
電力行業是人工智能的主戰場之一。國家電網公司推出“國網云平臺”企業中臺、中國大唐建立“智能燃料管控平臺”等,電力信息化總體呈現向數字化和智能化發展的趨勢[3]。隨著電力行業數字化和信息化步伐不斷加快,電網企業已積累了各業務領域的海量數據,這也為深度學習技術尤其是自然語言處理模型的研究與應用提供了新的機遇與發展。
1 大語言模型發展歷程
1.1 大規模預訓練語言模型
隨著深度學習技術的興起,基于神經網絡的自然語言處理(NLP)模型開始取得突破性進展。其中,循環神經網絡(RNN)和卷積神經網絡(CNN)是最早的神經網絡架構之一,但RNN和CNN在長期保存狀態信息、處理長序列等問題方面存在局限性[4]。
為了解決上述問題,Google在2017年提出了基于自注意力機制的深度學習架構Transformer模型[5]。
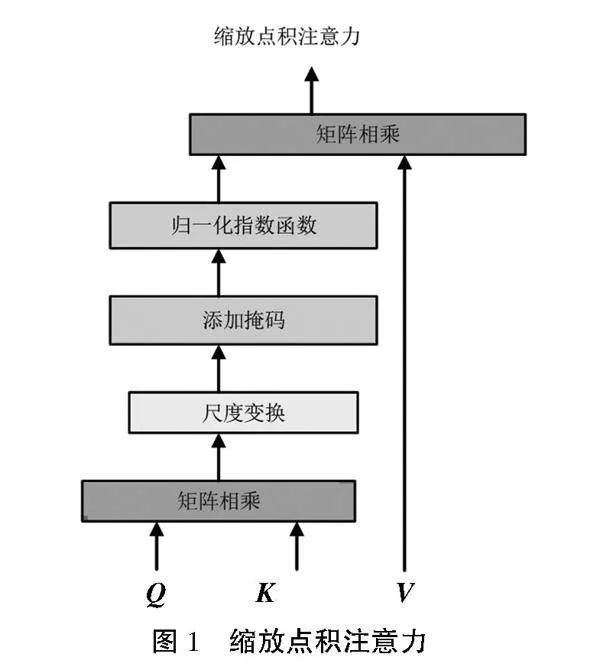
Transformer使用的綻放點積注意力的原理如圖1所示,將矩陣Q和K通過點積相乘來計算每個位置的注意力權重,再通過尺度變換、添加掩碼、歸一化操作(SoftMax)處理,得到矩陣,最后與V進行點乘計算,計算規則表示為
式中:Q為query查詢矩陣;K為key鍵矩陣;V為value值矩陣,均來自輸入的同一線性變換;dk為Q、K、V的維度;為尺度標度。
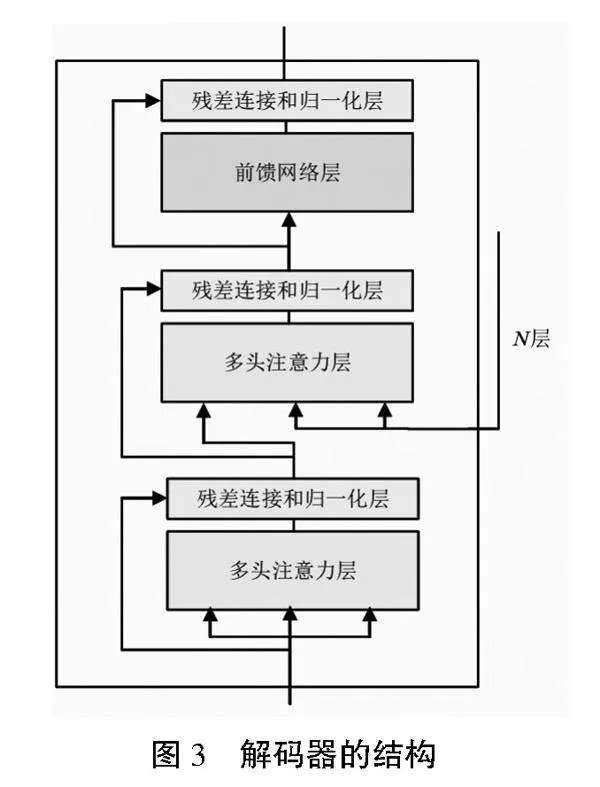
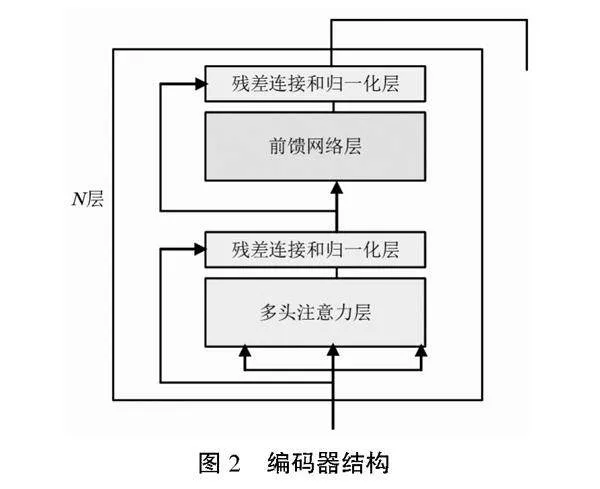
Transformer由Encoder和Decoder組成。Encoder即編碼,用于對輸入進行指定的特征提取過程,由N個完全一樣的網絡層組成,每個網絡層都包含一個多頭自注意力子層和全連接前向神經網絡子層,如圖2所示。Decoder即解碼,根據編碼器的結果及上一次預測的結果, 對下一次可能出現的值進行特征表示,相比Encoder存在一個多頭自注意力子層。為了更好地優化深度網絡,每個子層都加了殘差連接并歸一化處理,如圖3所示。
基于注意力機制的Transformer模型并行計算能力強,在處理大規模數據集時非常高效地捕捉到豐富的上下文信息,可以更好地處理復雜的自然語言任務,因此衍生出了一系列基于Transformer的預訓練模型。根據預訓練架構可以分為三大類別,基于Encoder的模型、基于Decoder的模型、基于Encoder-Decoder的模型。
1.1.1 基于Encoder的模型
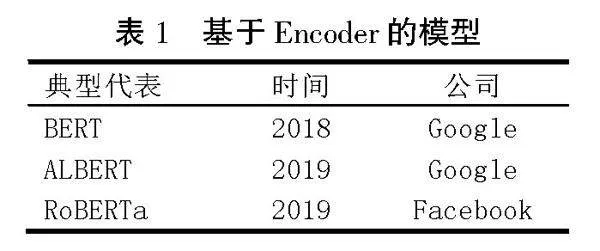
表1為基于Encoder模型的典型代表。2018年Google Brain提出的基于雙向Transformer的自然語言表示框架BERT(Bidirectional Encoder Representations from Transformers)[6]是基于Encoder模型的典型代表,其采取Pre-training + Fine-tuning的訓練方式,通過雙向上下文信息來學習語言表示,在分類、標注等任務下都獲得了更好的效果。在2019年,Google又提出ALBERT(A Lite BERT)[7],繼承了BERT的雙向上下文理解能力,同時具備輕量級、跨層參數共享、句子順序預測等優勢。同年,Facebook AI提出了基于BERT模型的改進模型RoBERTa(Robustly Optimized Bert Approach)[8],從模型規模、訓練時間、訓練策略等多方面進行了改進,從而提高了模型的泛化能力、訓練效率及穩定性。
1.1.2 基于Decoder的模型
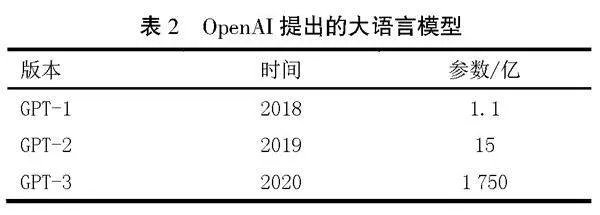
2018年,OpenAI團隊提出了GPT (Generative Pre-trained Transformer),是一種基于單相Transformer Decoder 的生成式語言模型,可以生成流暢、連貫的文本[9]。在GPT之后,OpenAI團隊對Transformer模型進行了改進和擴展,提出了GPT-2和GPT-3更高級的版本,見表2[10-11]。GPT-2繼續利用單向Transformer的優勢,通過大容量、無監督訓練,在生成文本的質量和連貫性方面有了很大的提高,同時可以應用于更多的自然語言處理任務。GPT-3則引入了更多的新特性和能力,針對特定任務進行微調,在許多自然語言處理任務及基準測試中性能獲得顯著提升,實現用更少的特定領域數據且不經過精調步驟來解決目標問題的目的。引起廣泛關注的ChatGPT是基于GPT-3架構進行改進開發的完整的Web聊天機器人產品,可以用于各種自然語言處理任務,如問答、對話生成、文本摘要和機器翻譯等。
1.1.3 基于Encoder-Decoder的模型
BART(Bidirectional and Auto-Regressive Transformers)和T5 (Text-to-Text Transfer Transformer)是基于Encoder-Decoder的典型代表。BART和T5都是在2019年發表,兩者都采用了Transformers原始結構,BART由Facebook提出,T5由Google提出[12-13]。BART的預訓練任務中對輸入加各種類型的噪聲,模型能夠學習到不同的語言表達方式,以及句子的結構和語法,其在自然語言理解任務上和RoBERTa差不多,但在摘要、翻譯、對話等自然語言生成的任務上表現更好。T5的預訓練任務中把所有的自然語言理解和自然語言生成任務都轉化為文本生成任務,可以更加靈活地適應不同的任務。因為使用了龐大的預訓練庫,在大規模語言處理時效果顯著。
1.2 大語言模型的發展趨勢
大語言模型的未來發展趨勢主要體現在以下幾個方面。
1.2.1 跨語言
跨語言模型正處于高速發展時期,不僅是狹義上的機器翻譯,還包括支持上百種語言的自然語言處理任務模型。但對于語料貧乏的許多小語言,尤其是雙語平行數據的缺乏,效果仍然不是很好,未來研究的重點在于如何把大語言豐富的語料知識遷移到小語言上。
1.2.2 多模態
語言模型將越來越趨向于多模態學習,將文本、圖像、音頻和視頻等不同模態的數據進行融合,以實現更加全面和多樣化的信息處理和分析,更好地適應各種應用場景。
1.2.3 常識和推理
在小范圍、閉域及具體的特定領域,人工智能具有一定的常識和推理能力,但在開放領域人工智能的未來發展需要與腦科學、心理學、神經學多個學科進行深度融合。
2 大語言模型在電網企業的應用前景
大語言模型作為一種先進的自然語言處理技術,在電網企業營銷、運檢、調度及輿情風險識別等方面展現出了良好的應用前景。
2.1 電力營銷
電力營銷業務以滿足客戶電力消費需求為目的,是電網企業的核心業務,其工作質量直接關系到電網企業的前途與命運。在電力營銷服務方面,可以利用分析電力營銷中采集系統、客戶視圖、業務流程和電費賬單等模塊或業務中的大量數據,深度學習輸電、售電過程中營銷數據的知識和語言規律,實現對不同業務需求進行綜合預測處理。一方面可以應用于供電企業收費管理、線損管理等業務,實現電力營銷數據的智能化查詢、分析、統計工作,提升企業市場競爭力和供電服務能力。另一方面可以建立客戶精準畫像,為客戶個性化需求定制專屬方案,實現從“保供電”到“個性化供電”。文獻[14]提出了結合BERT和BiGRU-AT的電力營銷客服工單分類模型,利用BERT進行工單文本特征表示,用BiGRU-AT模型進行二次語義特征學習,解決傳統深度學習模型特征提取能力弱及詞向量無法表示多義詞等問題。該文獻對安全隱患、停電、停電未送電及供電故障等7個工單類別進行測試,結果表明,相比于傳統的Word2Vec-BiGRU和Elmo-BiGRU分類方法,BERT、BiGRU-AT模型分類準確率分別提升了3.31%和2.20%。
2.2 電力運檢
電力設備的運維和檢修是保障電力系統安全穩定運行的關鍵環節,關系著經濟社會的發展和人民用電的穩定性與安全。由于存在信息壁壘,傳統運維檢修方法往往需要耗費大量時間和人力,大語言模型憑借其自然語言處理技術和知識圖譜構建能力,通過學習歷史維修記錄、設備故障數據、設備參數等信息,建立設備的故障模式識別模型。當設備出現故障時,根據實時采集的設備運行數據,對故障現象進行分析和描述,并與知識圖譜中的設備信息、故障案例等進行匹配,識別出設備的故障模式,快速定位故障原因,根據故障的特點和程度,提供相應的故障診斷和維修方案。文獻[15]結合BERT預訓練模型、自注意力模型、雙向長短記憶網絡,提出了一種BE-SAT-BT的電力變壓器故障診斷模型。在該模型中BERT預訓練模型替代常規嵌入模型進行數據嵌入分析,利用自注意力模型和雙向長短記憶網絡共同對特征信息進行提取。實驗結果表明,相比常用的電力變壓器故障診斷模型,該BE-SAT-BT模型具有更高的預測準確率,能有效提高電力變壓器故障預測能力。
2.3 電力調度
電力調度是確保電力系統安全、穩定、經濟運行的核心任務,它涉及輸電、配電等多個環節,關乎社會經濟的發展和人民的用電需求。然而,傳統的電力調度方法面臨著流程復雜、數據處理量大等問題,導致調度效率和準確性受到挑戰。基于大語言模型的智能調度與優化可以實時監控電力系統的運行狀態,通過學習歷史調度數據、電網結構信息、發電和負荷預測數據等,建立電網運行狀態的識別模型。當電網運行狀態發生變化時,實時采集電網運行數據,對運行狀態進行分析和描述,并與知識圖譜中的電網結構、調度規則等進行匹配,快速識別出電網的運行狀態,及時發現潛在問題和風險,自動預警,以便調度人員及時采取措施,可極大提高電力調度的效率。文獻[16]提出了一種基于 Bert 模型的序列標注方法,用于電網調度及電網故障處置預案中關鍵信息的抽取。該方法解決了一詞多義問題,提高了模型處理復雜數據集的能力,實現電網故障處置預案的關鍵信息自動、高效抽取,更好地輔助調度員進行故障自動處置。
2.4 電網企業輿情風險識別
電網企業面臨著輿情多樣化、信息龐大、傳播速度快的挑戰。傳統的輿情監測方法往往難以滿足實時性和準確性的要求。在此背景下,大語言模型可以通過輿情識別、信息提取、風險預警的方式進行輿情識別,提高輿情識別的效率和準確度,有利于提升電力企業對外部信息的感知能力,及時發現并應對負面輿情,從而保護企業聲譽和業務穩定。文獻[17]將視角放置于社交媒體平臺,將情感分析與危機事件輿情進行結合,基于微博評論數據,采用BERT模型進行情感訓練,對危機事件下微博評價進行情感分類預測,以此探究情感在信息輿情中的影響和危機事件下的詞頻關系,從而對危機事件的輿情管控提出建議。
綜上所述,目前電力大語言模型的應用研究以“規模小、場景少、特征提取有限”為主要特點,尚處在起步階段,未來大規模大語言模型的應用泛化能力更強,具有更廣泛的適用場景,提取特征的能力更強,能夠更好地理解和處理復雜的電力數據,在電網企業具有良好應用前景。
3 電力大語言模型需解決的問題
3.1 安全層面,存在數據隱私泄露風險
電力大語言模型需要處理大量的電力數據,如何保障如客戶的個人信息、設備的運行數據等敏感信息,避免數據泄露和濫用是亟待解決的問題。另一方面,電力大語言模型主要依賴科技巨頭提供的基礎模型“預訓練+微調”和調用對外開放服務接口, 難以避免由此帶來安全方面的風險和問題。
3.2 技術層面,基本數據集存在缺陷
大語言模型本身屬于生成式語言模型,更注重生成而非準確,其數據集主要來源于網頁、社交媒體等公共互聯網,盡管應用過濾技術剔除低質量及錯誤內容,但輸出內容仍然存在偏見和錯誤,與電力系統運行要求指令精準、信息明確相違背,需要過濾技術的不斷發展和進步。
4 結束語
電網企業目前正朝著數字化、智能化方向發展,目前大語言模型作為深度學習技術的重點研究技術已經在電網企業電力營銷、電力運檢、電力調度和輿情風險識別等方面具有良好的應用效果。大規模大語言模型具有更強的數據處理能力、更廣泛的適用場景,在電網企業具有良好的應用前景,但如何保障電網企業和電力客戶的隱私,防止信息泄露,以及如何提高大語言模型生成內容的準確度和可靠性是目前亟待解決的問題。
參考文獻:
[1] 趙鐵軍,許木璠,陳安東.自然語言處理研究綜述[J/OL].新疆師范大學學報(哲學社會科學版),1-23[2024-07-10].https://doi.org/10.14100/j.cnki.65-1039/g4.20230804.001.
[2] 王昀,胡珉,塔娜,等.大語言模型及其在政務領域的應用[J].清華大學學報(自然科學版),2024,64(4):649-658.
[3] 辛保安.國家電網:搶抓數字新基建機遇推動電網數字化轉型[EB/OL].(2020-12-03)[2024-01-06].http://www.sasac.gov.cn/n4470048/n13461446/n15927611/n15927638/n16135038/c16135143/content.html.
[4] 米碩,孫瑞彬,李欣,等.基于循環神經網絡(RNN)和卷積神經網絡(CNN)對電子郵件的作者識別[J].科技創新與應用,2018(10):24-25.
[5] ASHISH V, NOAM S, NIKI P, et al. Attention Is All You Need[J/OL]. arXiv. (2017-06-12)[2024-01-06].https://arxiv.org/abs/1706.03762.
[6] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding [C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2018: 4171-4186.
[7] LAN Z Z, CHEN M D, GOODMAN S, et al. ALBERT: A lite BERT for self-supervised learning of language representations [J/OL]. arXiv. (2019-09-26) [2024-01-06]. https://arxiv.org/abs/1909.11942.
[8] LIU Y H, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized BERT pretraining approach [J/OL]. arXiv. (2019-07-26) [2024-01-06]. https://arxiv.org/abs/1907.11692.
[9] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving Language Understanding by Generative Pre-Training [J/OL].OpenAI.(2018-06-11) [2024-01-06].https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[10] RADFORD A, WU J, CHILD 0QvNaSIYevT3fRiKSC2YRA==R, et al. Language models are unsupervised multitask learners [J/OL]. OpenAI. (2019-02-14)[2024-01-06]. https://paperswithcode.com/paper/language-models-are-unsupervised-multitask.
[11] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]//Proceedings of the 34th International Conference on Neural Information Processing Systems, 2020: 1877-1901.
[12] LEWIS M, LIU Y H, GOYAL N, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation,and comprehension[J/OL].arXiv. (2019-10-29)[2024-01-06].https://arxiv.org/abs/1910.13461.
[13] RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J].The Journal of Machine Learning Research, 2020,21(1):140.
[14] 蔡穎凱,曹世龍,張冶,等.應用BERT和BiGRU-AT的電力營銷客服工單分類模型[J].微型電腦應用,2023,39(4):6-9.
[15] 黃錦波,周榮生,羅龍波,等.基于BERT預訓練的電力變壓器故障預測[J].制造業自動化,2023,45(9):89-93.
[16] 肖大軍,張逸茹,徐遐齡,等.基于Bert的電網故障處置預案信息抽取研究與實現[J].電力信息與通信技術,2023,21(3):26-32.
[17] 朱子賢.基于BERT的危機事件微博評價情感分析及聚類研究[D].哈爾濱:黑龍江大學,2023.
作者簡介:左星宇(1995-),女,碩士。研究方向為電力營銷。
