一種基于多維表示的漢字識別方案
2024-08-06 00:00:00陳成姜明張旻
軟件工程 2024年8期




關鍵詞:漢字識別;特征提取;關鍵筆形;多任務網絡
中圖分類號:TP391 文獻標志碼:A
0 引言(Introduction)
漢字識別技術在圖像識別領域占據(jù)核心地位,尤其在單據(jù)處理和證件驗證等應用中發(fā)揮了至關重要的作用。然而,現(xiàn)有研究主要集中于背景清晰的圖像,而忽視了復雜環(huán)境下的識別挑戰(zhàn)。圖像模糊和噪聲顯著增大了特征提取的難度,影響了識別準確率。目前,主流方法是基于字符細粒度特征輔助漢字識別,但在復雜場景下提取有效特征仍然面臨挑戰(zhàn),暴露了現(xiàn)有方法的不足。因此,如何提升漢字的有效特征提取能力,并通過有限的特征實現(xiàn)字符準確識別,成為當務之急[1]。為此,本文提出一種融合空間信息的關鍵筆形特征提取方法,僅使用少量的關鍵特征即可準確識別漢字;同時,通過多任務網絡提取多維特征,包括字符、字根和關鍵筆形,并應用字符相似度算法減少特征噪聲,提升識別準確性。通過實驗證明,本方法顯著提升了漢字在復雜場景下的識別準確率。
1 相關研究(Related work)
目前,基于深度學習的漢字識別主流方法大致可分為基于字符和基于字根兩種。以下將詳細介紹這兩種方法相關技術的發(fā)展,以及復雜場景下漢字識別技術的發(fā)展情況。
1.1 基于字符的方法
早期的漢字光學字符識別(OCR)方法依賴于模板匹配和規(guī)則引擎[2],這在處理數(shù)量龐大且形態(tài)多樣的中文字符時,常面臨準確性和擴展性方面的挑戰(zhàn)。隨著深度學習技術的發(fā)展,卷積神經網絡(CNN)開始被廣泛應用于漢字的識別任務中。隨后,循環(huán)神經網絡(RNN)和長短時記憶網絡(LSTM)等模型被應用于建模和識別字符序列。循環(huán)卷積神經網絡(CRNN)[3]的出現(xiàn)進一步推動了字符識別技術的發(fā)展。MORAN(Multi-Object Rectified Attention Network)模型[4]將傳統(tǒng)特征與深度學習方法相結合,引入特定領域的知識以增強模型的性能。FANG 等[5] 提出ABINET (Autonomous,Bidirectional and Iterative Language Modeling for Scene TextRecognition)模型,采用端到端的訓練模式,結合語言模型捕獲文本的全局上下文信息,從而顯著提升文本識別的準確性和效率。由于基于字符的方法在某些情形下難以區(qū)分相似字符,因此開發(fā)更高效的特征提取方法對于提升漢字識別的準確性與魯棒性至關重要。
1.2 基于字根的方法
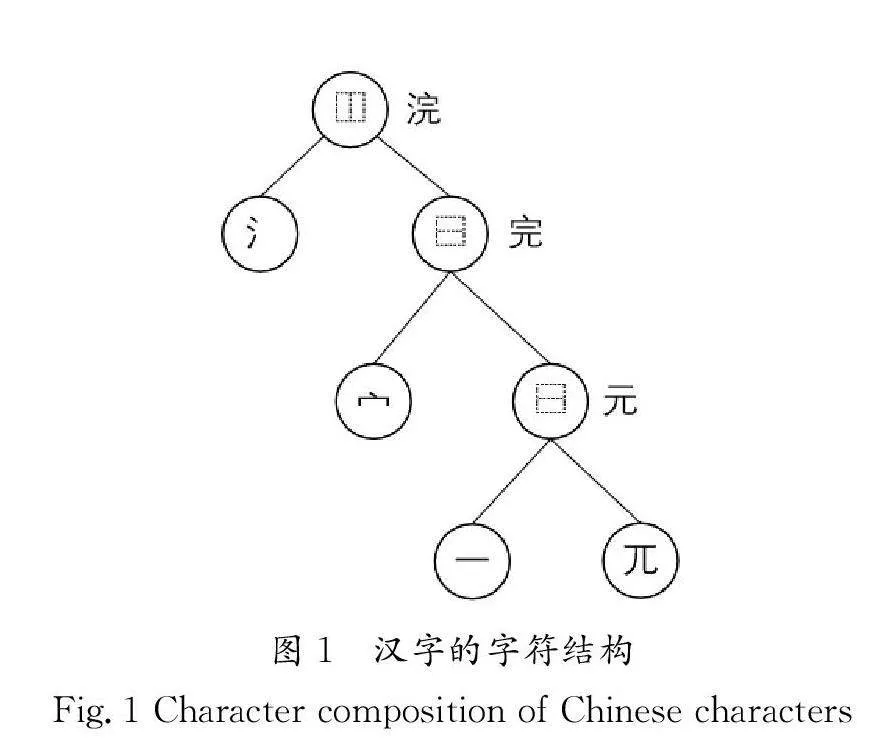
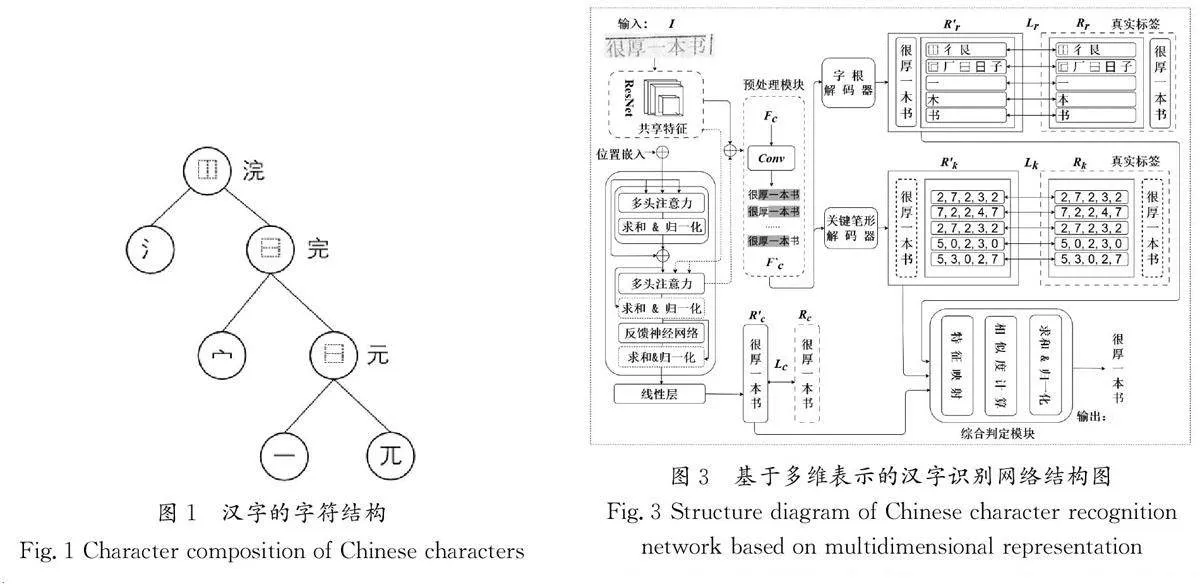
如圖1所示,漢字的字符結構遵循國家標準(GB 18030—2005)進行分類,采用遞歸分層方案對字符進行解析,可以將漢字解構為含有多個結構和字根的樹狀結構。具體來說,漢字結構可根據(jù)UTF-8(Unicode Transformation Format-8 bits)編碼標準進一步劃分為12個基本類別。漢字基本結構的詳細定義如圖2所示。
在傳統(tǒng)的漢字識別方法中,字根識別通常依賴于預先提取的筆畫信息。隨后,研究者基于字根的方法采用逐像素匹配算法,直接從漢字圖像中提取字根信息。然而,隨著深度學習技術的興起和其在漢字識別領域的廣泛應用,研究者開始將字根識別轉化為序列預測問題,并將其應用于字符識別,這種方式顯著提高了漢字的識別準確率。但是,復雜場景下的漢字識別仍面臨不少挑戰(zhàn)。
1.3 復雜場景中漢字識別方法
目前,針對復雜場景中文本識別的問題,基于空間變換的網絡被用于處理場景文本中的變形漢字[6],進一步增強了模型對復雜場景的適應性。隨后,SHI等[7]提出ASTER(Anattentional scene text recognizer with flexible rectification)模型,基于注意力機制創(chuàng)建了一個具有靈活校正能力的場景文本識別器,它融合了注意力機制和自適應文本校正技術,顯著提高了在具有復雜背景場景中文本的識別準確率。QIAO等[8]提出了SEED(Semantics enhanced encoder-decoder frameworkfor scene text recognition)模型,構建了一種語義增強的編解碼器框架,用于場景文本識別。該框架通過結合語義信息提升文本識別的準確性。LU 等[9]提出了一個多方面非局部網絡(MASTER),該網絡針對場景文本識別任務,通過融合多個視角的非局部特征提高識別精度和魯棒性。
2 實現(xiàn)細節(jié)(Implementation details)
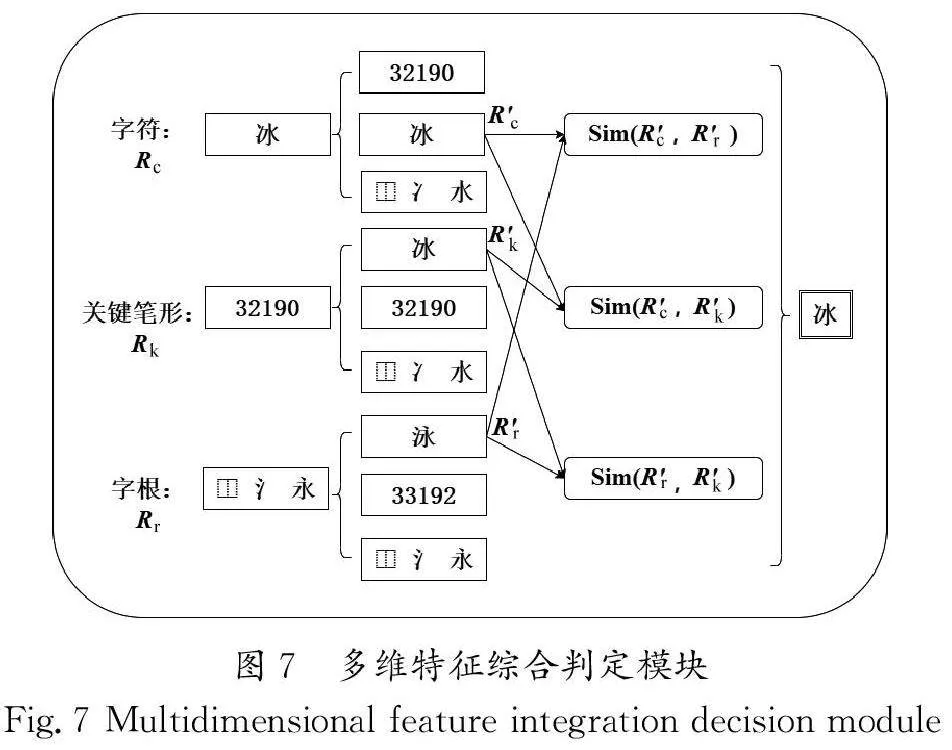
本文提出了一種融合字符、字根和關鍵筆形的多維表示漢字識別模型(MRCCR)。基于多維表示的漢字識別網絡結構圖如圖3所示,主要由3個部分組成:共享特征提取模塊、多任務特征提取網絡及多維特征綜合判定模塊。
首先,模型利用深度殘差網絡(ResNet)提取圖像的共享特征,為下一步的特征提取和識別任務打下堅實的基礎。其次,通過多任務學習策略,模型在特征提取網絡中并行提取字符、字根和關鍵筆形的多層次特征,旨在增強特征的表征性能。再次,通過反向傳播機制,模型持續(xù)優(yōu)化共享特征的提取過程,從而增強特征的表達能力和識別精度。最后,在多維特征綜合判定模塊中,模型對提取的多維特征進行評估和融合,使用相似度算法篩選出關聯(lián)性高的特征,剔除低相關性特征污染,實現(xiàn)特征的最優(yōu)融合。此方法有效提升了模型對復雜漢字識別的魯棒性和準確性。
2.1 融合空間信息的關鍵筆形特征提取方法
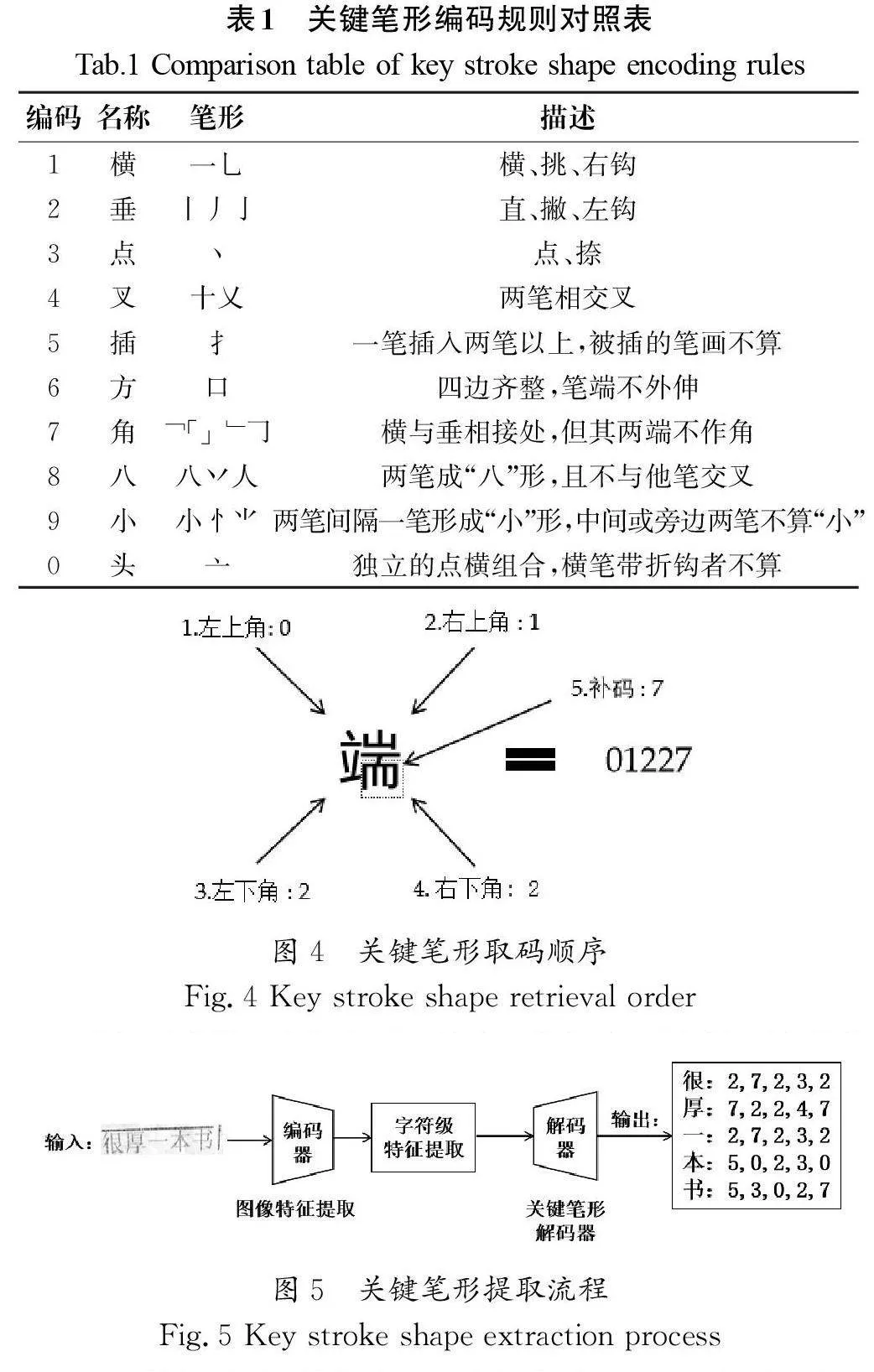
如表1所示,關鍵筆形的定義依據(jù)四角編碼標準(CY/T271—2023)進行劃分,該方法將漢字中的單筆形或復合筆形進行唯一編號。與傳統(tǒng)依賴筆順的編碼方式不同,四角編碼方式根據(jù)筆畫在空間中的位置順序,從漢字的左上角、右上角、左下角和右下角提取對應的單筆或復合筆畫進行編碼。為優(yōu)化編碼的唯一性并減少重復,編碼過程中會在靠近右下角(第四角)的上方額外選取一個筆畫作為補充編碼。若該補充筆畫與右上角的編碼相同,則此補充編碼記為0。以“端”字為例(圖4),按照四角編碼的規(guī)則,其左上角的筆畫編碼為“亠”,右上角的筆畫編碼為“丨”,左下角的筆畫編碼為“ ”,右下角的筆畫編碼為“亅”,并以“”作為補充編碼。綜上,通過對照筆畫標準,“端”字的四角編碼確定為“0,1,2,2,7”。
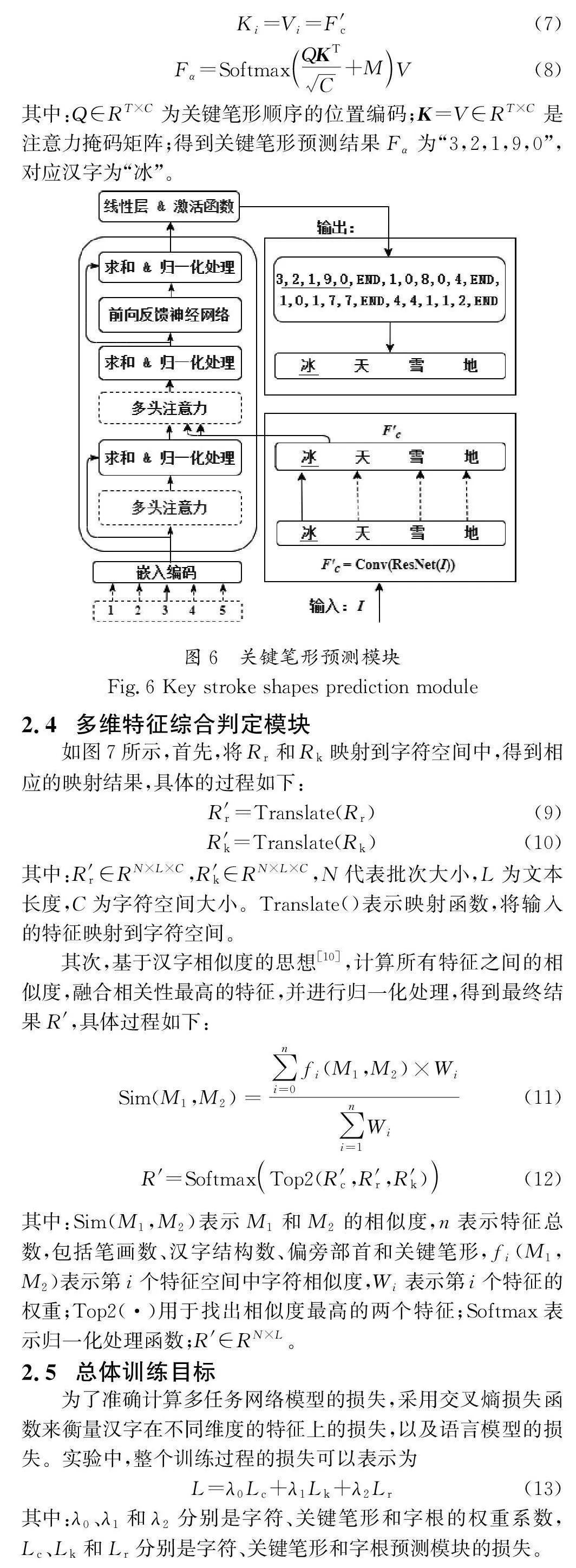
關鍵筆形提取流程如圖5所示。首先,將圖片輸入編碼器中提取初步字符特征及注意力矩陣。其次,將注意力矩陣與對應位置的卷積特征圖點乘,并采用1×1的卷積層進行特征壓縮,得到字符級別圖像特征。再次,將字符級特征輸入關鍵筆形解碼器中進行解碼。最后,輸出相應的關鍵筆形編碼。
基于關鍵筆形的特征提取方法在編碼過程中,不僅保留了特征序列的前后關系,還將筆形之間的空間關系融入特征序列中。傳統(tǒng)的漢字細粒度特征以特征序列的形式展開,僅包含了特征之間的前后關系,未能充分反映特征之間的空間關系。采用基于關鍵筆形的特征編碼方式,能夠為特征提取提供更豐富的空間特征,從而提升提取特征的信息量。
2.3 多維表征提取模塊
漢字的細粒度特征具有多種表示形式,例如字符、字根和關鍵筆形特征。表2展示了漢字“浣”涵蓋的多維特征。為了提取字符、字根和關鍵筆形3個維度的特征,設計了多維表征提取模塊。該模塊通過多任務的方式,利用字符、字根和關鍵筆形3個特征預測模塊,分別提取相應的特征。
通過合理設置權衡系數(shù),可以確保模型在各個方面的損失得到平衡,從而更好地優(yōu)化模型的性能。
3 實驗(Experiments)
3.1 數(shù)據(jù)集
為了更好地比較模型在中文數(shù)據(jù)集的性能,在中文文本識別通用數(shù)據(jù)集(CTR)[11]上比較當前基準模型。此外,為更好地適應復雜場景下的印刷文本識別需求,基于Text Render5創(chuàng)建了4個復雜場景印刷文本數(shù)據(jù)集。
通用數(shù)據(jù)集CTR的場景數(shù)據(jù)集包含背景復雜的、模糊的、字體不同的和遮擋的636 455個文本樣本。網頁數(shù)據(jù)集訓練集數(shù)據(jù)一共包含140 589張中英文網頁文本圖像。文本數(shù)據(jù)集是由Text Render5生成的文本樣式文本圖像。語料庫來自維基百科、電影、亞馬遜和百度。該數(shù)據(jù)集共包含500000個數(shù)據(jù)集。手寫數(shù)據(jù)集一共包含116 643張文本圖像。
對于復雜場景的數(shù)據(jù)集,按照影響因素劃分為以下4類。①遮擋(來自前景):描述前景物體或文字對目標文字的遮擋。②傾斜或彎曲(來自字符):對字符本身的傾斜或彎曲現(xiàn)象進行評估。③背景混淆(來自背景):背景中的其他元素或紋理可能對目標文字造成干擾。④圖片模糊(圖像來源,像素損失):涉及圖像采集、處理或傳輸過程中可能產生的模糊或像素損失。通過考量以上4類影響因素,研究人員能更全面地評估模型在復雜場景下印刷文本識別的性能和魯棒性。每個數(shù)據(jù)集分別包含10 000張圖片。
所有數(shù)據(jù)集的訓練集、測試集和驗證集的數(shù)據(jù)量均按照8∶1∶1的比例進行劃分,采用隨機操作的方式對這些樣本進行洗牌。
3.2 實現(xiàn)細節(jié)
在本次實驗中,采用PyTorch作為深度學習框架,并利用NVIDIA RTX 3090 GPU進行高效計算,內存容量為24 GB,為模型訓練提供了充足的資源。優(yōu)化器選用ADADELTA,初始學習率設定為1.0。同時,動量設為0.9,權重衰減為1e-4。
為確保模型對圖像細節(jié)的準確識別,將輸入文本圖像的分辨率固定為32×32。此外,每批訓練數(shù)據(jù)的數(shù)量設置為64,這一設置有助于提高識別的準確性。
3.3 實驗結果
3.3.1 模型評估指標
本研究選取度量精度(Accuracy, ACC)和歸一化編輯距離(Normalized Edit Distance, NED)作為評估模型性能的關鍵指標。通過結果的可視化分析,本文直觀地展示了算法在處理復雜場景下的識別能力。
在進行性能評估前,本研究實施了一系列的數(shù)據(jù)預處理步驟,包括刪除文本中所有的空格、將所有英文字符統(tǒng)一轉換為小寫字母,以及將繁體中文字符統(tǒng)一轉換為簡體中文字符,旨在消除不必要的變異性,為計算提供了標準化的數(shù)據(jù)基礎。
利用度量精度對模型的識別準確率進行量化評估。為了全面評估長文本圖像的識別性能,本研究還引入了歸一化編輯距離作為評估指標,以衡量模型對于長文本識別的綜合能力。ACC和NED的取值范圍均為[0,1],其中較高的值代表模型具有更好的性能表現(xiàn)。
3.3.2 應用于通用數(shù)據(jù)集的結果對比
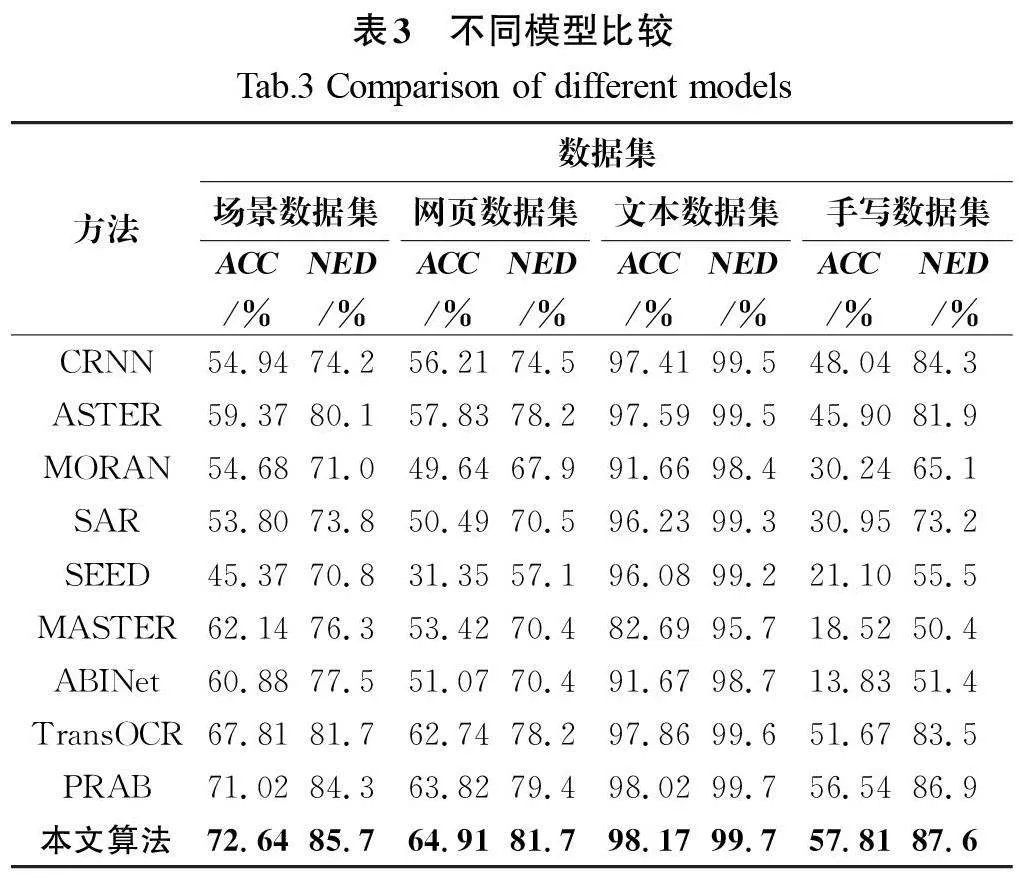
在場景數(shù)據(jù)集、網頁數(shù)據(jù)集、文本數(shù)據(jù)集、手寫數(shù)據(jù)集中,本文提出的MRCCR算法均優(yōu)于當前較先進的算法。使用字符精度(CACC)作為評估指標。
表3的對比結果表明,本研究提出的算法在文本數(shù)據(jù)集上達到了最高的準確率,超越了現(xiàn)有的PRAB模型。這一結果主要歸功于算法采用了多維表征模型,該模型通過提取多層次特征,顯著提高了識別的準確性。
在文本數(shù)據(jù)集中,約有1.20%的樣本未能被成功識別。這些失敗案例多涉及復雜情形,例如印刷文本的結構模糊或輪廓不清晰,這對算法中的關鍵筆形監(jiān)督模塊構成了挑戰(zhàn)。對于網頁數(shù)據(jù)集,由于數(shù)據(jù)量較小,所有模型的準確率普遍較低。然而,當從數(shù)據(jù)集中剔除非中文文本,僅針對中文字符進行準確率計算時,本研究提出的算法識別準確率高達91.56%。其中,中文字符僅占據(jù)所有字符的44.9%。復雜場景下的文本基準,因其包含復雜的現(xiàn)實背景及噪聲干擾(例如模糊和遮擋)而更具挑戰(zhàn)性。與基于Transformer的PRAB模型相比,本文提出的MRCCR算法在復雜場景文本識別方面取得了顯著提升,性能提高了1.62百分點。這一顯著提升可能源于MRCCR算法所采用的三層分解表征監(jiān)督,與現(xiàn)有技術相比,該算法對復雜背景和噪聲的抗干擾能力更強,展現(xiàn)出更強的魯棒性。在手寫數(shù)據(jù)集上,盡管手寫數(shù)據(jù)集因潦草書寫導致所有基準模型性能普遍欠佳,但引入基于關鍵筆形特征的算法后,性能仍有所提升。
3.3.3 復雜場景數(shù)據(jù)集實驗分析
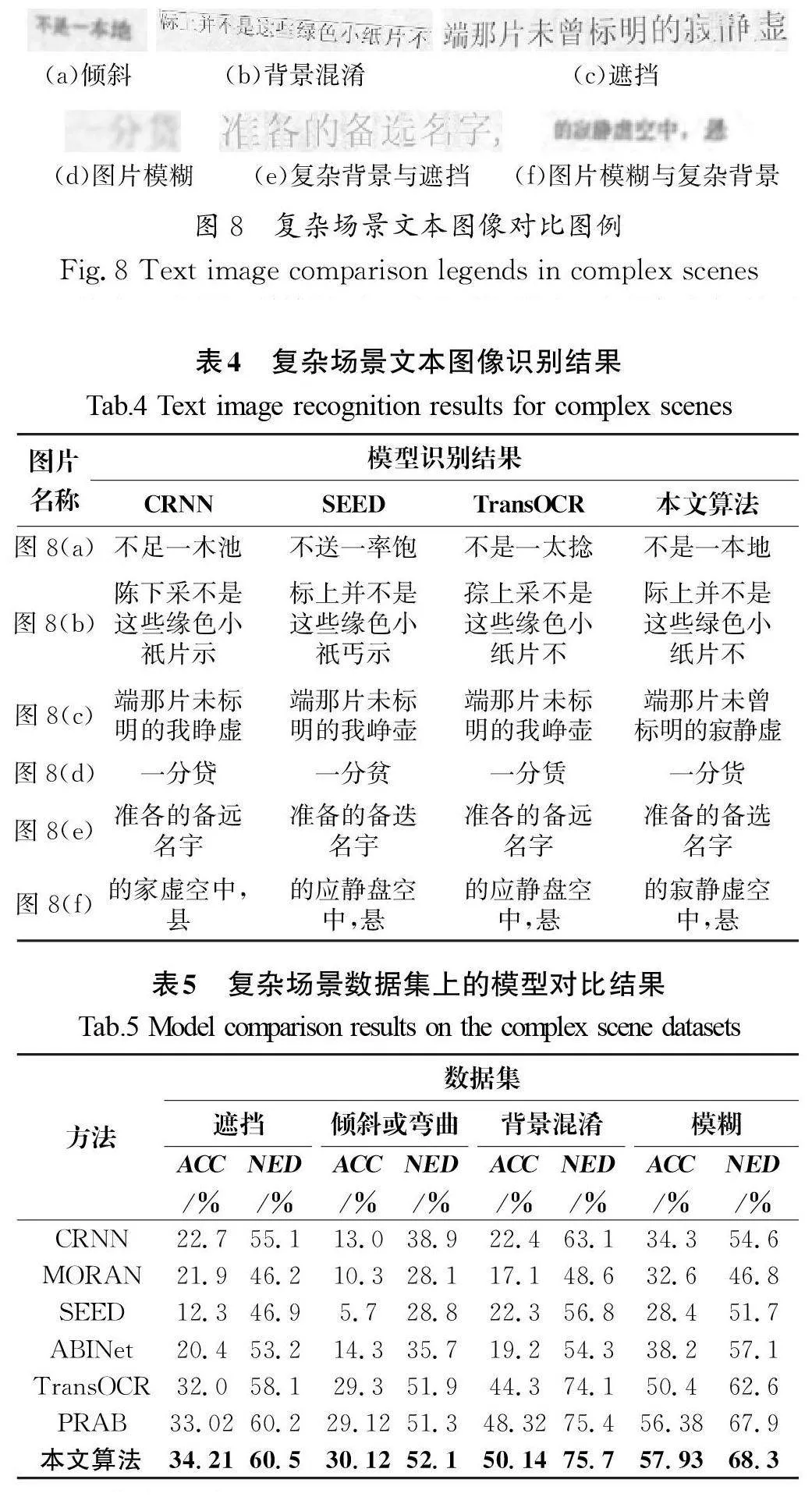
從Text Render5生成的文本數(shù)據(jù)集的測試集中,選取了一些傾斜、遮蓋、背景模糊、遮擋等復雜場景下的文本圖像(圖8),對比同一個圖片在4種不同模型下的識別結果。
從表4中的識別結果可以看出,針對圖8中的復雜場景下文本圖片的識別,本文算法相較于其他3種算法,在圖像缺失、字符扭曲及背景模糊的場景下具有較好識別效果。例如在對圖8(d)的識別中,由于圖片模糊,特征提取困難,CRNN、SEED及TransOCR模型均未正確識別出漢字“貸”,而本文提出的方法基于空間提取關鍵筆形,可以更好地提取文本圖像的特征,以少量關鍵特征表示漢字,進而正確識別出了該字符。
結合表4和表5的實驗結果可以看出,相較于其他算法,本文提出的算法在處理模糊場景數(shù)據(jù)集時展現(xiàn)出較強的適應性。這一優(yōu)勢主要歸功于應用了多維表征融合識別算法,它結合注意力機制,利用多層次信息提取特征,顯著提升識別器的處理能力。該算法能輕松應對不常見的文本布局,如傾斜、彎曲等復雜情況,同時有效降低了由前景遮擋或背景混亂引發(fā)的噪聲干擾。通過精確捕捉關鍵特征,本文提出的算法能顯著提高漢字識別的準確性。
3.4 消融實驗
為了驗證本文提出模型的有效性,在通用數(shù)據(jù)集上對關鍵筆形預測模塊和綜合判定模塊進行了消融實驗。首先,通過從多維表征識別模型中移除關鍵筆形預測模塊,并在沒有此模塊的情況下進行實驗,分析了該模塊的影響,以證明其對提高漢字識別的性能的貢獻。其次,在驗證綜合判定模塊的有效性時,采用了一種替代融合機制,即將特征通過平均融合并歸一化的方式。為了便于對比,將去除關鍵筆形預測模塊和綜合判定模塊的版本定義為基礎模型,同時為了方便比較,使用“-G”表示在模型中去除關鍵筆形特征模塊,使用“-Z”表示在模型中去除綜合判定模塊。
3.4.1 關鍵筆形消融實驗
如表6所示,在去除關鍵筆形表征模塊后,本文提出的模型在各類數(shù)據(jù)集上的性能均出現(xiàn)了下降趨勢。具體而言,在場景數(shù)據(jù)集、網頁數(shù)據(jù)集、文本數(shù)據(jù)集和手寫數(shù)據(jù)集上,性能分別降低了1.62百分點、1.09百分點、0.15百分點和1.27百分點。可以看出,手寫數(shù)據(jù)集和場景數(shù)據(jù)集的性能下降最為顯著,這主要是因為這兩個數(shù)據(jù)集包含的背景復雜性和遮蓋等挑戰(zhàn)性因素較多。關鍵筆形模塊旨在提升特征提取能力,去除該模塊后,特征提取的增益被取消,進而導致識別準確性降低。
3.4.2 綜合判定模塊消融實驗
表6中的測試結果表明,刪除綜合判定模塊后,模型的整體準確率略有下降,例如在文本數(shù)據(jù)集上識別字符的正確率從98.17%下降到97.99%,下降了0.18百分點。進一步可以判斷出綜合判定模塊可以去除特征噪聲,選取最佳字符,使預測精度略有提高。
實驗結果顯示,關鍵筆形模塊對于提升漢字識別的準確性起到了關鍵作用。通過采用多維表征融合的漢字識別策略,不僅整體提高了漢字識別能力,還增強了在復雜場景下的識別準確性。此外,消融實驗的結果也進一步印證了本文模型的有效性。
4 結論(Conclusion)
本研究致力于提升在復雜場景中漢字的有效特征提取能力,以提高漢字識別的準確性。首先,提出了一種基于空間的關鍵筆畫特征提取方法,將空間信息融合到特征序列中,實現(xiàn)了使用最少的關鍵特征對漢字進行準確標識。在此基礎上,本研究進一步提出了一種基于多維表示的漢字識別方案,該方案利用注意力機制結合多任務網絡,有效提取了漢字字符、字根及關鍵筆畫的多維度特征,從而提高了在復雜場景中的關鍵特征提取水平。此外,通過應用字符相似度算法去除特征中的噪聲,進一步提高了字符的識別準確率。實驗結果表明,基于多維表征的漢字識別方案在復雜場景中的漢字識別能力優(yōu)于基線模型。
作者簡介:
陳成(1997-),男,碩士。研究領域:自然語言處理,圖像識別。
姜明(1974-),男,博士,教授。研究領域:自然語言處理,圖像識別。本文通信作者。
張旻(1977-),男,博士,講師。研究領域:自然語言處理,圖像識別。
