基于深度學習和自注意力的光度立體方法方明權
2024-08-06 00:00:00宋瀅
軟件工程 2024年8期

關鍵詞:光度立體;深度學習;自注意力;殘差網絡
中圖分類號:TP389.1 文獻標志碼:A
0 引言(Introduction)
光度立體作為逆渲染鄰域的一個分支,一直是計算機圖形學中重要的研究方向,它廣泛地應用于虛擬現實、視頻游戲及影視制作等行業(yè)[1]。光度立體通過圖像與光照之間的聯系,推斷出物體表面的法向信息。未標定的光度立體(Uncalibrated Photometric Stereo)是光度立體的一個重要的研究方向,旨在解決實際場景中,當相機和光源參數未精確標定時,如何準確推斷物體表面法線的問題。在未標定的光度立體方法中,算法不要求事先知道相機和光源的內部參數,而是試圖通過觀察物體表面在不同光照條件下的亮度變化,還原物體的三維信息。這使得未標定的光度立體更具實用性,在現實應用中,準確地獲得標定參數頗具挑戰(zhàn),甚至有時并不現實。通過解決未標定的問題,實現從實際圖像中更加靈活地獲取實用的三維幾何信息。
本文設計了一個基于自注意力和多重最大池化的未標定光度立體算法模型。在估計光照信息階段,通過在網絡中加入自注意力模塊,幫助網絡能學習到長距離特征之間的聯系,從而提升其感知能力。在法線估計階段,本研究設計了一個多重特征提取和融合網絡,通過對不同深度特征的有效融合,提升網絡對多圖像輸入時的魯棒性。
1 相關工作(Related work)
在傳統(tǒng)的光度立體方法中[2],通常會假設物體的表面是基于朗伯反射模型(Lambertian Shading),這是一種理想的光照模型,然而現實中鮮有物體能完全符合其假設。后續(xù)提出的非朗伯模型光度立體方法更貼近現實物體表面特性,這些方法雖然更適用于現實的物體表面,但是均屬于傳統(tǒng)的計算方法,因此在可擴展性和使用效率上受到了限制。近年來,深度學習在計算機圖形學與計算機視覺領域的應用為光度立體研究提供了新的思路和路徑。
1.1 標定的光度立體方法
在深度學習中,標定的光度立體方法通常需要將光照信息作為網絡訓練的先驗知識。CHEN 等[3]設計了PS-FCN(Photometric Stereo Fully Convolutional Network)網絡用于估計表面法線,該方法將多張輸入圖片和其光照信息一起輸入網絡中,并使用一個最大池化層融合多張圖片的共同特征,同時他們也提出了一個名為LCNet(Lighting Calibration Network)的網絡用于估計光照的強度和方向。JU等[4]設計了一個多尺度的特征融合模塊,該模塊可以對高分辨率和深度的特征進行提取,將不同輸入的同一層次特征分別疊加并輸入下一層級的網絡中,并利用多個最大池化層融合結果,同時他們還設計了一個卷積模塊用于提高法線推斷的準確度。雖然這些方法可以很好地估計法線,但是需要先驗的光源信息,因此其實用性受到了限制。
1.2 未標定的光度立體方法
未標定的光度立體方法一般只使用圖像信息而不依賴具體的光照條件來估計物體法線信息。CHEN等[5]提出一個名為SDPS-Net(Selfcalibrating Deep Photometric Stereo Network)的網絡結構,其采用分段的方式分別估計光照和法線信息。LI等[6]提出了一種可以在常規(guī)光照作用下聯合優(yōu)化幾何物體形狀、光方向和光強度的方法。TIWARI等[7]提出了一個深度學習框架,分別將光照估計、圖片重照明及表面法線估計3個任務結合,通過輸入單張照片,該網絡可以提取圖片的全局和局部特征,并使用聯合訓練提高網絡的效果。CHEN等[8]提出了一個名為GCNet(Guided Calibration Network)的網絡結構,分別設計了一個光照估計網絡和法線估計網絡,采用獨立和聯合訓練的方式分別優(yōu)化網絡的參數。
2 光度立體網絡模型(The photometric stereonetwork model)
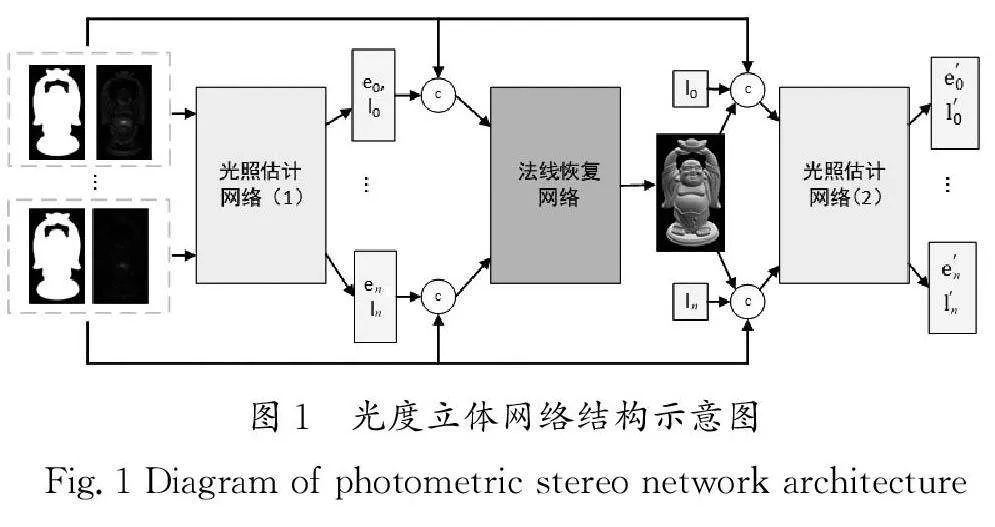
本文的網絡結構由兩個部分組成,分別是光照估計網絡和法線恢復網絡。網絡結構的整體組合方式借鑒了CHEN等[8]的方法(圖1),分別使用了兩個光照估計網絡和一個法線恢復網絡。網絡的輸入是若干張不同光源作用的目標圖像和物體遮罩圖,將遮罩圖和一張目標圖像組合作為一組輸入。通過利用不同光照下的圖像,可以為網絡提供充足的信息,實現光源和法向的準確估計。本文模型的訓練流程如下:首先,使用第一個光照估計網絡對輸入圖片的光源信息進行初步的預測;其次,法線恢復網絡根據初步預測的光源信息和輸入圖片恢復圖片的法線信息;最后,第二個光照估計網絡總結已有的信息,進而恢復更準確的光照方向和光照強度。
2.1 光照估計網絡
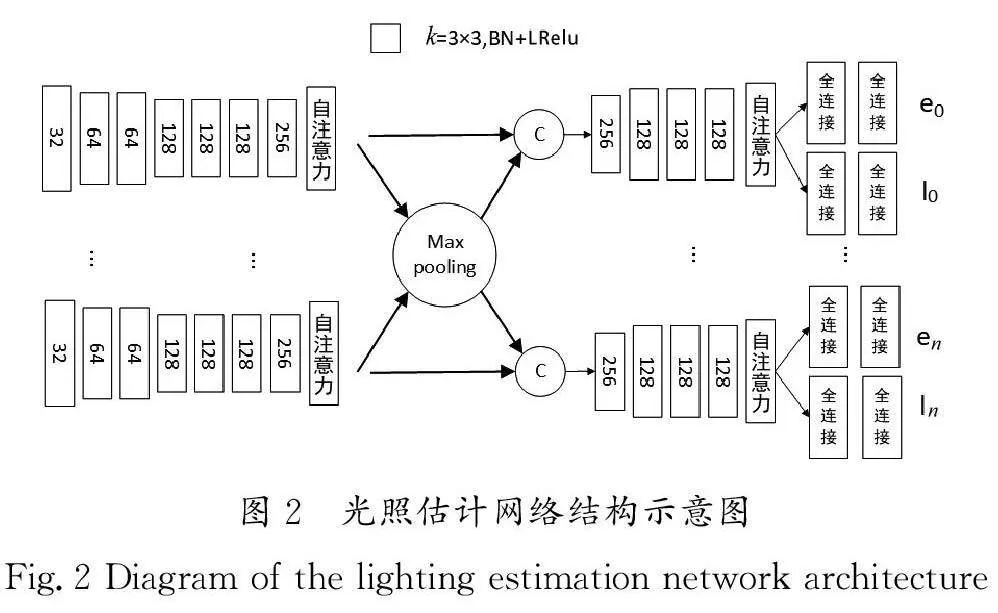
光照估計網絡結構示意圖如圖2所示。對于輸入的圖片,首先,經過了7個卷積層和一個自注意力模塊,每個卷積層后都加入了批歸一化層和Leaky Relu激活函數,用于提高網絡的性能、穩(wěn)定性及泛化能力。其中,每個卷積核的大小都是3×3,采用步長為1和步長為2的卷積核交替對特征進行提取。其次,通過一個最大池化層將來自不同輸入的特征進行融合,并拼接到各自原來的輸入中。最后,通過4個卷積層、1個自注意力模塊和2個全連接層,分別對光照方向和光照強度進行估計。其中,自注意力模塊的設計借鑒了ZHANG等[9]的方法。
2.2 法線恢復網絡
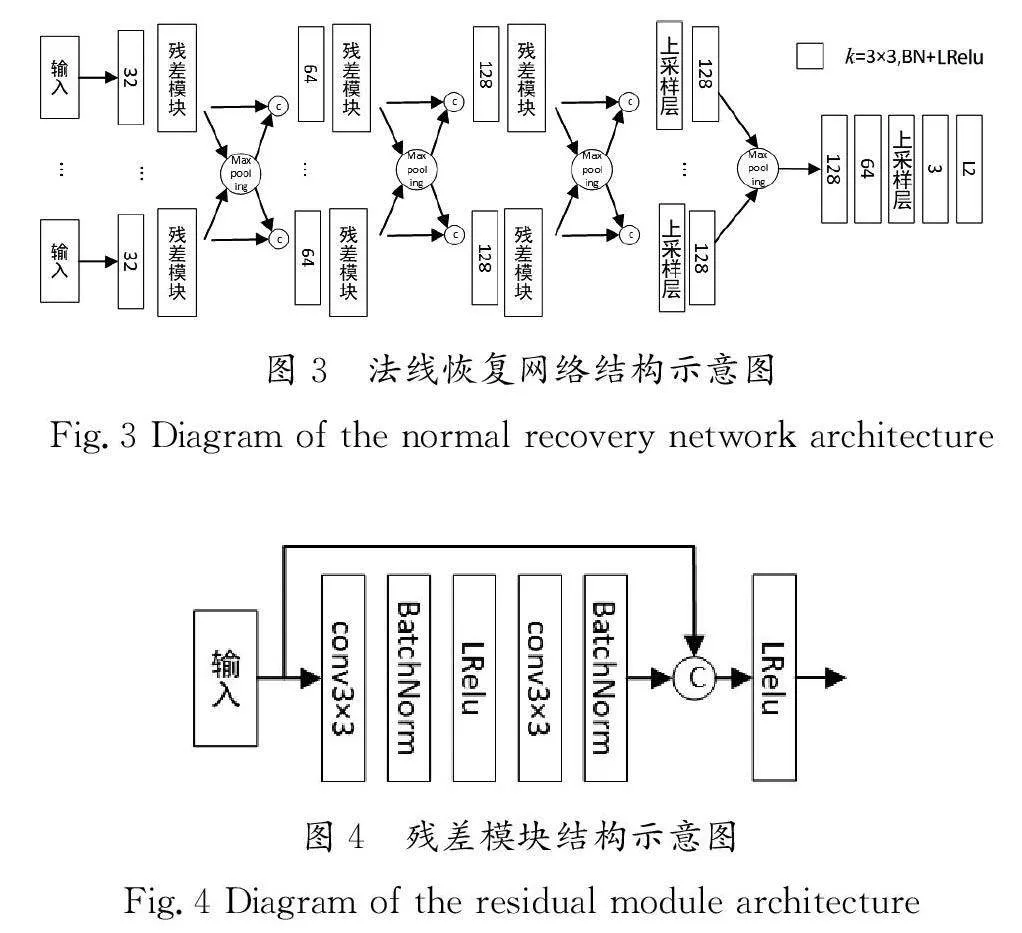
本文設計的法線恢復網絡結構示意圖如圖3所示,它將圖片和光源等信息作為輸入條件,因為要對多個不同輸入進行特征提取,所以該網絡整體上采用并行計算的方式。法線恢復網絡的前半部分總共有3組卷積層,由殘差模塊和最大池化層組成特征提取模塊,每個卷積層都包含了批歸一化層和LeakyRelu激活函數,使得非線性變換的結果更容易被學習。第一組的特征提取模塊的卷積層的卷積核大小為3×3,步長為1,主要是為了提取淺層特征。后兩組的卷積層的卷積核大小為3×3,步長為2,通過將步長設置為2,可以提升卷積核的感受野,并壓縮提取后特征圖的大小,從而起到減少計算量和避免過擬合的作用。
法線恢復網絡的后半部分通過一個上采樣層、卷積層及最大池化層,將所有輸入的特征融合后進行綜合性的卷積操作,其中上采樣層采用反卷積的結構可以學習到更多的參數。將融合后的特征通過多個卷積和一個上采樣層后,再通過L2激活函數將結果映射到真實的法向分布空間。
本文設計的殘差模塊結構示意圖如圖4所示,輸入特征經過一個卷積核大小為3×3,步長為1的卷積層,再依次經過批歸一化層、Leaky Relu激活函數、卷積層及批歸一化層后,通過跳躍連接,將最初的輸入和經過卷積后的輸出合并后,通過Leaky Relu激活函數進行非線性變換映射。通過引入跳躍連接,使得殘差模塊不再直接學習輸入到輸出的映射,而是學習輸入到輸出的殘差關系,從而更利于模型的學習,并減少過擬合和梯度消失等問題。
3 實驗結果與分析(Experimental results andanalysis)
3.1 數據集
本文訓練所使用的數據集來自CHEN等[10]提出的合成數據集,該數據集包含了blobby shape和sculpture shape兩個部分,其中blobby shape數據集包含25 920個樣本,sculptureshape數據集包含59 292個樣本,總共85 212個樣本。在訓練過程中按照99∶1的比例劃分訓練集和驗證集,并運用介于[-0.02,0.02]的噪聲對樣本進行數據增強,從而增強模型的泛化能力和魯棒性。
3.2 實驗環(huán)境
本文的實驗環(huán)境在Windows11系統(tǒng)下進行,使用的GPU為RTX4080-16GB,CPU為AMD 5600X。本文使用PyTorch1.13.1作為訓練用的框架,Python版本為3.8,使用Adam優(yōu)化器,在訓練過程中根據模型的特點動態(tài)調整了學習率和批量大小(BatchSize),從而加快模型的擬合速度。
3.3 結果分析
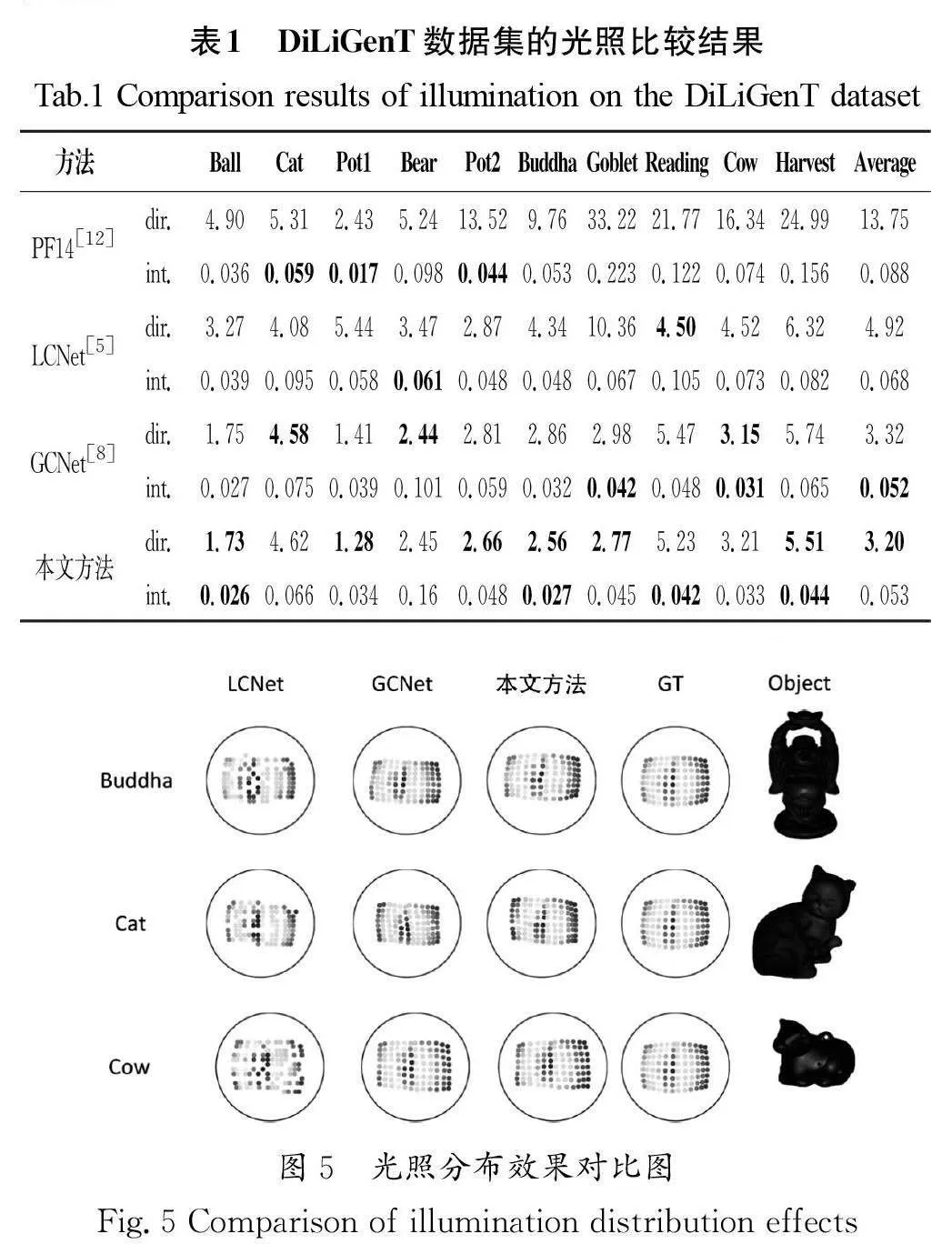
本文首先對光照估計網絡的效果進行結果分析。使用DiLiGenT[11]作為測試用的數據集,該測試數據集總共有10個不同類型的樣本,每個樣本各包含96份光度圖和法向信息圖。在評價光照方向和法向時,使用平均角度誤差(Mean AngularError,MAE)作為評價標準。在評價光照強度時,使用尺度恒定相對誤差作為評價標準。
本文分別選擇PF14[12]、LCNet和GCNet作為光照結果的比較對象,比較結果如表1所示,其中最好的數值以粗體形式標出。從表1中的數據可以發(fā)現,本文方法在光源法向的平均角度上有更低的誤差,而光源強度也與表現最好的GCNet十分接近。
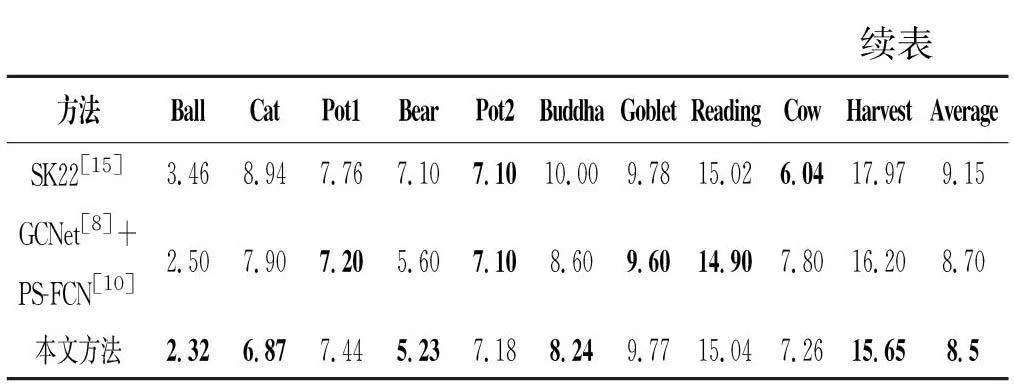
本文選取了部分光照分布效果對比圖,這些樣本均來自DiLiGenT數據集,如圖5所示,在Buddha、Cat和Cow三個樣本上,本文方法模擬的光照分布效果與真實光照分布更加接近,這從側面印證了本文方法對提升光照分布的正面作用。
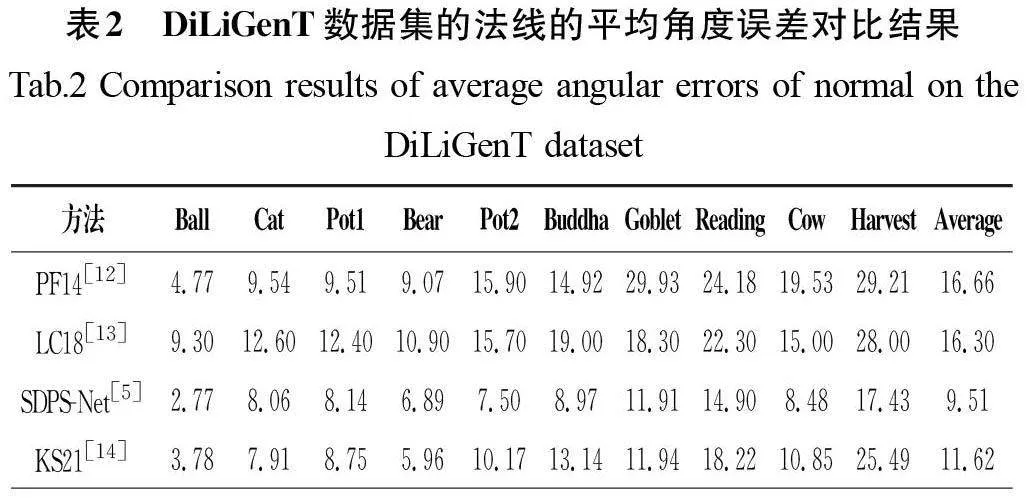
在分析對比法向網絡的效果時,本文選取了目前效果最好的非標定光度立體方法作為對比對象,包括PF14(A RobustSolution to Uncalibrated Photometric Stereo Via Local DiffuseReflectance Maxima)[12]、LC18[13]、SDPS-Net[5]、KS21(InverseRendering for Photometric Stereo)[14]和SK22(Neural ArchitectureSearch for Uncalibrated Deep Photometric Stereo)[15]。除此之外,本文還將GCNet[8]的光照預測結果作為PS-FCN[10]的輸入,將兩者組合作為其中一個對比對象。DiLiGenT數據集的法線的平均角度誤差對比結果如表2所示,本文方法在平均角度誤差上取得了更好的表現,說明本文對法線恢復網絡功能設計的有效性。
4 結論(Conclusion)
本文提出了一種基于深度學習和殘差網絡的光度立體方法。該方法采用分段的方式分別對輸入圖像的光源信息和法線進行估計,通過結合使用多重池化和殘差網絡的方式,提升了網絡的擬合性能。在光源估計網絡中,通過在特征融合前后加入自注意力模塊使得網絡可以學習到長距離的像素特征關系,從而提高網絡對圖像分解與信息的利用能力。在法線恢復網絡中,通過設計由淺入深的特征融合層,使得網絡可以更充分融合多圖像輸入的信息,同時在卷積過程中使用殘差塊的方式,可以加快網絡反向傳播的進程,從而提高特征的利用效率。
本文提出的基于深度學習和殘差網絡的光度立體方法雖然有助于提升對光源和法線估計的準確度,但是該方法存在一定的局限性,究其原因是本文方法采用先估計光照后估計法向的方式,這種分段式的網絡設計雖然可以顯著減少模型訓練和擬合所需的時間,但是估計法線依賴估計光源的準確度,所以不可避免地存在誤差。為了更好地解決這一問題,可以引入更多約束的方式,例如將輸入圖像分解為更全面的材質屬性,將這些材質屬性綜合的渲染結果作為訓練網絡的約束方式,從而減小誤差,提升準確度,但也會擴大模型的規(guī)模,因此需要做好兼顧與平衡。
作者簡介:
方明權(1997-),男,碩士生。研究領域:計算機圖形學,深度學習。
宋 瀅(1981-),女,博士,副教授。研究領域:計算機圖形學。
