基于深度學習的集群系統故障預測方法
2024-08-13 00:00:00姬莉霞張慶開周洪鑫黨依萍張晗
鄭州大學學報(理學版) 2024年5期






摘要: 在面對集群系統故障預測時,長時間序列預測中存在因關鍵特征信息丟失而導致梯度消失或爆炸問題,從而影響了故障預測模型的準確性。基于此,提出一種新的基于深度學習的集群系統故障預測方法。該方法采用雙向門控循環網絡(bidirectional gate recurrent unit, BiGRU)來捕捉局部時序特征,同時采用Transformer來提高全局特征提取能力。通過BiGRU層中雙向的信息傳遞獲得集群系統日志上時序特征的動態變化,以獲取集群事件中的潛在因果關系和局部時間特征,使用Transformer層并行處理BiGRU層輸出的時間序列,得到全局的時間依賴性,繼而由全連接神經網絡層得到預測結果。通過由Blue Gene/L系統產生的真實日志所構建的公共數據集來驗證方法的有效性,結果表明,所提方法優于對比方法,其最佳正確率和F1值分別達到91.69%和92.74%。
關鍵詞: 故障預測; 集群系統; 特征提取; 循環神經網絡; Transformer; 深度學習
中圖分類號: TP391
文獻標志碼: A
文章編號: 1671-6841(2024)05-0071-09
DOI: 10.13705/j.issn.1671-6841.2023021
A Cluster System Failure Prediction Approach Based on Deep Learning
JI Lixia1,2, ZHANG Qingkai1, ZHOU Hongxin1, DANG Yiping1, ZHANG Han1
(1.School of Cyber Science and Engineering, Zhengzhou University, Zhengzhou 450002, China;
2.College of Computer Science, Sichuan University, Chengdu 610065, China)
Abstract: In the clustered system failure prediction, the long-time series prediction was accompanied by problem such as gradient disappearance or explosion, due to the loss of key feature information, which would affect the accuracy of the model for failure prediction. For this reason, a new model of cluster system fault prediction method based on deep learning was proposed. The method adopted bidirectional gate recurrent unit (BiGRU) to capture local timing features while employing Transformer to improve the global feature extraction capability. The dynamic changes of timing features on the cluster system logs were obtained through bidirectional information transfer in the BiGRU layer to capture the potential causality and local temporal features in the cluster events.The Transformer layer was used to process the time series output from the BiGRU layer in parallel to obtain the global temporal dependence, which followed by the fully connected neural network layer to obtain the prediction results. The effectiveness of the method was validated on a public dataset constructed from real logs generated by the Blue Gene/L system. The results showed that the proposed method outperformed the comparison methods with a best-correct rate and F1 value of 91.69% and 92.74%, respectively.
Key words: failure prediction; cluster system; feature extraction; recurrent neural network; Transformer; deep learning
0 引言
目前大多數針對集群系統的故障預測引擎是基于系統日志來構建的[1],這是由于其包含集群系統實時狀態的各種事件日志,可以較長時間且更準確地記錄系統行為。同時,日志中的事件之間存在明顯的相關性,并且系統的故障事件表現出明顯的時間相關性[2]。
隨著人工智能學科的興起,深度學習被應用于故障預測領域[3-4],該類方法通過神經網絡模型深度挖掘事件的時間關聯性,對系統行為和歷史狀態進行建模分析,從而預測系統未來是否會發生故障及可能出現的故障類型,實現對系統故障的精準預測。這些方法更加關注故障特征與故障趨勢的關系,雖然在特征提取能力方面有了進一步的提升,但隨著集群規模的日益擴大,集群故障預測序列長度增加,這些方法往往伴隨著梯度消失或爆炸問題[5],從而引起集群實時狀態或一些時間點等關鍵信息的丟失。
循環神經網絡(recurrent neural network,RNN)在提取時序中的時間相關性方面能力突出,但由于其自身順序結構的局限性,只能實現局部因果時間相關性的特征提取[6],在面對長時間序列預測時會遺忘部分信息,從而導致梯度消失或爆炸問題。隨著Transformer模型[7]在自然語言處理領域的深度應用,其展示出對長時序數據的強大建模能力,但其自注意力機制在處理局部特征時可能會因過于關注全局信息而忽視了局部細節,弱化了模型捕捉局部特征的能力[8]。
受此啟發,采用Transformer來學習長時間序列的全局特征,與RNN學習長時間序列的局部特征相互補,以解決長時間序列中的重要特征丟失問題。同時,雙向循環網絡模型對文本序列上下文特征的提取有著優越的性能表現,能夠進一步提升局部因果時間相關性的提取能力。因此,本文提出一種基于Transformer與BiGRU的集群故障預測方法,簡稱為TBGRU。該方法首先通過BiGRU和Transformer相結合的方式來獲取故障序列的局部時間特征和全局時間依賴性,然后通過全連接神經網絡層輸出預測結果。TBGRU不僅可以捕獲局部的時間依賴性和時序數據的因果關系,還可以捕獲整體時間內事件的時序關系,并抓取長時的依賴信息,從而解決了目前研究中普遍存在的在預測長時間序列時會發生的梯度爆炸或消失問題。在Blue Gene/L系統的真實日志數據集中,相比其他基線模型,TBGRU在集群故障預測中具有更好的性能表現。
1 相關工作
針對集群系統故障預測的研究主要分為兩類:一類是基于傳統的統計和規則基準的預測方法;另一類是基于人工智能技術的預測方法。其中第一類方法大多為基于系統日志的故障預測方法[9],通過跟蹤和分析反映系統狀態變化過程的系統日志來達到故障預測的目的。例如,王衛華等[10]提出一種基于頻繁日志事件序列聚類的故障預測方法。Fu等[11-12]使用Apriori-LIS和Apriori-simiLIS算法來挖掘日志事件之間的關系,并提出了事件關聯圖來表示事件之間的規則,進而預測可能發生的故障事件。但在數據特征挖掘階段,這些方法大部分并未全面考慮事件之間的時間相關性,忽略了故障之間的因果關系對預測能力的影響,在預測細粒度的故障時,往往因粗糙的提取特征而影響預測性能。
基于統計的機器學習和基于神經網絡的深度學習方法也被用于故障預測領域。Liang等[13]針對IBM的Blue Gene/L集群系統日志進行研究,采用基于規則挖掘的分類算法RIPPER、支持向量機、k-近鄰和自定義最近鄰方法分別構建了故障預測模型,進行二分類預測。王振華[14]在此基礎上增強了日志特征提取能力,并且選擇合適的分類器,使用貝葉斯網絡、隨機森林、AdaBoostSVM自適應提升算法等構建分類預測模型。Mohammed等[15]提出一種基于時間序列和機器學習的故障預測模型。
上述方法通過挖掘事件之間的時序特征,大大提高了模型對故障預測的精度。但在面對長時間序列時存在因部分關鍵信息丟失而導致梯度消失或爆炸等問題,降低了故障預測精度。Vaswani等[16]放棄了RNN和CNN,提出了完全基于全連接層和注意力機制的Transformer。注意力機制在解決長序列信息丟失的問題中是有效的,并且在許多領域的基本問題上取得了最先進的性能[17-18]。但Transformer通過位置編碼來實現序列特征的提取,這與RNN等自然序列特征提取器在特征提取能力上存在一定差距。因此,本文提出結合Transformer和BiGRU的TBGRU模型。在該模型中,Transformer的多頭自注意力機制和殘差連接能更好地處理長時間序列信息特征丟失的問題,同時,BiGRU的雙向疊加設計使得模型能夠更好地獲得當前時間點的上下文信息,并學習其中的因果關系,進而解決深層次的特征挖掘問題。
2 故障預測模型
2.1 問題定義
集群系統中的故障預測問題可以描述為:通過輸入時長為S的歷史時刻日志中事件的實時數據來預測接下來T時刻內的集群實時狀態。選擇一個長度為L的滑動窗口來定義原始向量序列X的特征序列,X=(x1,x2,…,xn)。歷史值或真實值由Y給出,Y=(y1,y2,…,yn-1),其中yi∈RdL。通過將時間序列特征X經過TBGRU模型的訓練來得到預測估計值Y^=(y^1, y^2,…, y^n)。這里的集群系統狀態包含故障、可恢復故障和非故障等一系列信息,使用系統日志中的實時狀態作為集群系統是否故障的一種表示方式。
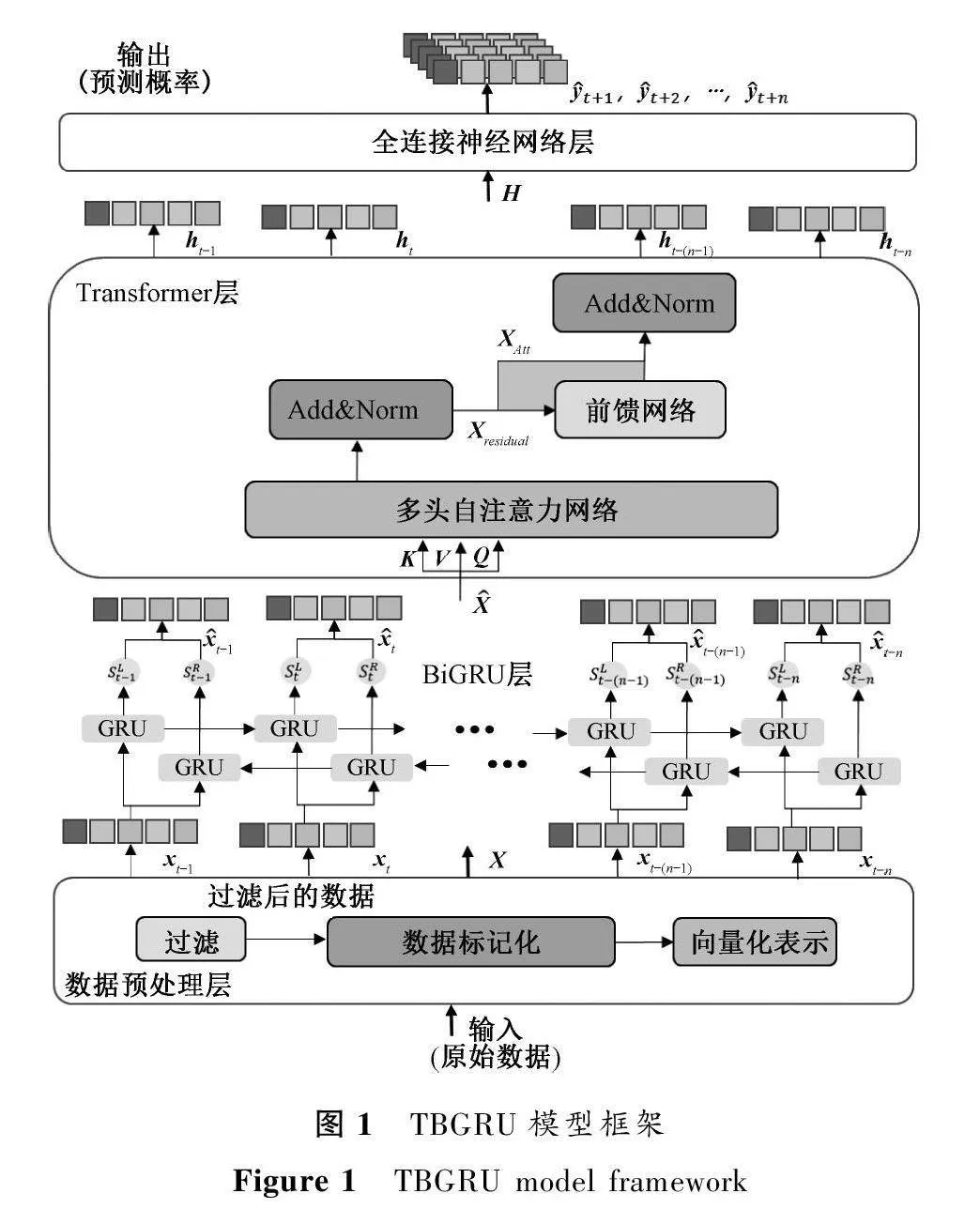
2.2 TBGRU模型框架
模型由數據預處理層、BiGRU層、Transformer層和故障預測層組成。首先通過數據預處理將原始數據的關鍵信息進行向量化,然后將序列數據輸入BiGRU中,捕獲日志事件中局部時間依賴性和時序數據的因果關系。由Transformer對經過BiGRU層處理后的特征序列信息進行再處理,使得處理后的序列獲得序列信息中的全局時序特征。最后,以Transformer層輸出的最終狀態作為分類的輸入,輸出到全連接神經網絡層繼而得到預測概率。TBGRU模型框架如圖1所示。
2.2.1 數據預處理層
在數據預處理階段,將原始數據的多元特征映射到向量序列X=(x1,x2,…,xn),其中:xi∈RdR,dR為特征在映射后的向量表示中的維數;n為數據數量。原始數據到特征向量主要由過濾、數據標記化和向量化表示三部分組成。
原始數據通常包含大量冗余的記錄以及與故障癥狀無關的正常系統記錄,會影響故障預測的效率和準確性。因此,在數據預處理階段主要完成以下任務。① 過濾冗余的數據信息。原始數據包含一些與故障預測無關的數據信息,如事件的描述、事件發生的地點等,只保留事件類型、故障級別和時間戳三個方面的信息。② 對原始數據進行標記化。由于復雜的集群環境和故障癥狀,將事件類型分為六類:APP(應用程序)、HARDWARE(硬件)、KERNEL(內核,一般與內存或網絡相關)、LINKCARD(中間件通信)、DISCOVERY(資源更新和初始配置)、MONITOR(電源、溫度等異常監控);將故障級別分為三類:無故障、可自愈的輕微故障、嚴重故障。并且,將事件類型和故障級別兩個維度的信息進行融合。③ 對處理好的數據進行向量化表示。分別用不同的向量表示在不同時間內每種事件的發生。
為了消除各項指標之間的量綱影響,需要通過數據標準化來解決數據指標之間的可比性。采用最大最小標準化方法對原始數據進行歸一化,使原始數據映射到[0,1],具體公式為
xi=xi-xminxmax-xmin,(1)
其中:xi為歸一化后的數據;xi為原始數據;xmax為原始數據中的最大值;xmin為原始數據中的最小值。將每種故障類型作為輸入,向量序列X=(x1,x2,…,xn)作為輸出。經過上述處理后,將原始數據轉換為矢量序列X,繼而輸出給BiGRU層提取時序特征信息。
2.2.2 BiGRU層
BiGRU是在傳統GRU網絡的基礎上擴展了第二隱藏層,通過對序列進行正向和反向掃描來獲取過去和未來的上下文信息。這種模型對輸入數據的依賴性小,具有復雜度低、響應時間快等優點。對于t時刻的輸入序列xt(xt∈X),經過BiGRU處理后可得到對應的輸出x^t,繼而組成輸出序列X^=(x^1,x^2,…,x^n),
ut=sigmoid(xtWz+ht-1Uz),(2)
rt=sigmoid(xtWr+ht-1Ur),(3)
ht=tanh(W·[rt×ht-1],xt),(4)
ht=(1-ut)ht-1+ut*tanh(xtWh+
(ht-1rt)*Uh),(5)
x^t=htht,(6)
其中:rt為復位門;ut為更新門;xt為t時刻的輸入向量;ht-1表示t-1時刻的狀態信息;ht表示候選隱藏狀態;ht表示隱藏狀態;W和U為需要訓練的權值矩陣。
2.2.3 Transformer層
將經過BiGRU處理后得到的特征向量序列X^作為Transformer模型的輸入,生成狀態序列H=(h1,h2,…,hn)。如圖1所示,變換編碼器主要分為多頭自注意力網絡和前饋網絡,計算公式為
multiHead(Q,K,V)=concat(Att1,Att2,…,Attn),(7)
Att1=softmax(QKTdk)V,(8)
其中:Q、K、V分別表示查詢、鍵和值,均為輸入矩陣;dk表示鍵的維數;在模型中n設置為2。這里使用從BiGRU層得到的特征向量序列X^作為Q、K、V,然后輸出X^Att,
X^Att=multiHead(X^, X^, X^),(9)
X^residual=norm(X^Att+X^),(10)
H=norm(X^residual+FFN(X^residual))。(11)
FFN由兩個線性變換和一個ReLU組成,
FFN(X^residual)=
Linear(max(0,Linear(X^residual)))。(12)
Transformer內部層的大小為2 048,最后生成狀態序列H=(h1,h2,…,hn)。使用最終狀態hn作為Transformer的輸出,然后輸入全連接神經網絡,實現故障預測分類。
2.2.4 故障預測層
為了實現多分類故障預測,使用全連接神經網絡對時間卷積層輸出的結果H∈RN×T進行線性變化處理,即將時間序列的維度轉換成需要預測的時間長度,
Y^=[y^t+1,y^t+2,…,y^t+T]=δ(WfH+bf),(13)
其中:T為預測的時間長度;Y^∈RN×T;δ(·)表示線性神經網絡的激活函數;Wf∈R2d×T,為全連接神經網絡的權重矩陣;bf為偏置項。
為了進一步優化預測結果,采用軟動態時間規整(Soft-DTW)[19]作為損失函數。簡單地說,軟動態時間規整算法可以根據兩個時間序列的特征找到合適的匹配來計算兩個序列的相似性,然后通過反向傳播不斷校正模型,最終達到最優的預測結果。
對于任意節點Xi的預測值Y^∈RT和真實標簽值Yi∈RT,損失值計算過程為
loss=dtwγ(Y^i,Yi)=minγ{(A,Δ(Y^i,Yi)),
A∈AT,T}=-γ(log(∑A∈T,Te-(A,Δ(Y^i,Yi),A∈T,T))),(14)
其中:γ(0,1]表示歐幾里得損失值的取值范圍;AT,T{0,1}T×T表示長度均為T序列上的校準矩陣集合,A∈AT,T代表一條路徑。此外,這里的分類由一個Linear層和logsoftmax組成。將Transformer層輸出的狀態序列H=(h1,h2,…,hn)作為輸入,最終輸出模型預測的接下來一段時間集群系統的狀態Y^=(y^1, y^2,…, y^n)。
2.3 模型訓練
由于神經網絡參數和超參數多種多樣,為了減少模型訓練時間,以便更好地進行驗證和模型預測,執行了在算法1中定義的類似網格的搜索機制。算法1的具體步驟如下。
算法1 TBGRU模型超參數的調優算法
輸入: 原始故障數據時間序列F,滑動窗口長度L,隱藏層層數H。
輸出: 優化的TBGRU模型Mt,訓練誤差t,驗證誤差v。
初始化: TBGRUnet的神經元數量、激活函數、批處理窗口大小、隱藏層數量、Epochs、優化器和損失函數初始化隨機值。
初始值: 滑動窗口范圍L←range(2, Lmax), H∈{H1, H2,…, Hn}, 誤差閾值 ∈min=CONSTANT
1: 劃分X為訓練集Xt和驗證集Xv;
2: 隨機排列Xt為(Xt);
3: 隨機排列Xv為(Xv);
4: 設置 flag←false;
5: for 每個時間窗口步長L∈{2, 3, …, Lmax}; do
6: for 每個隱藏層的數量H∈{H1, H2,…,Hn}標記為iterationH; do
7: assert: L≥2 and Lmaxlength F;
8: 設置Mt←TBGRUnet (XLt, XLv, seeds, η);
9: 計算Lt←trainingloss (Mt);
10: 計算Lv←validationloss (Mt);
11: if Lt≤∈min and Lv≤min then
12: flag←true
13: break loops
14: else
15: 重復直至收斂,并且設置flag←true;
16: end if
17: end for
18:end for
19: if flag←true then
20: 使用模型Mt進行TBGRUnet預測任務;
21: else
22: 重復使用不同的條件進行實驗,或者結束過程;
23: end if
算法1是一種實現雙目標的算法,即調整BiGRU和Transformer的隱藏層層數和搜索滑動窗口時間步長,以便更好地驗證和預測集群故障。其中第一層神經元數量N∈{16,32,64,128,256},隱藏層的層數H∈{16,32,64,128,256},學習率η∈{0.1,0.2,0.5,0.8,1.0}。同時,TBGRU模型采用的激活層函數為ReLU,損失函數為Soft-DTW,優化器函數為Adam,最后一層激活層為sigmoid,Batch size為64。
3 實驗與分析
3.1 實驗數據
實驗采用Blue Gene/L集群系統產生的系統日志數據,Blue Gene/L數據集是由從Lawrence Livermore 國家實驗室(LLNL)部署9759d2d921b6eb3e05dddc3cf831cee2的Blue Gene/LHPC系統中收集到的事件日志組成,日志記錄包括致命告警和非致命告警,是故障檢測和預測研究中常用的數據集。該數據集可以從公共計算機故障倉庫(computer failure data repository,CFDR)下載[20]。日志容量為708.8MB,共包括4 399 503條記錄。
將數據集分為訓練集與測試集,其中測試集占20%,訓練集占80%,進行參數優化和模型選擇,并評估模型的泛化能力,以提高模型的性能和預測效果。
3.2 評價指標和參數設置
3.2.1 評價指標
為了評估TBGRU方法的有效性,使用了3個性能指標:平均絕對誤差(MAE)、均方根誤差(RMSE)和平均絕對百分比誤差(MAPE)。數學表達式為
RMSE=1n∑nt=1e2T=1n∑nt=1(y^-y)2,(15)
MAE=1n∑nt=1eT=1n∑nt=1(y^-y),(16)
MAPE=100%n∑nt=1(y^-yy),(17)
式中:eT= y^-y。
同時,采用準確率(Accuracy)和F1值對故障預測結果進行綜合評估。數學表達式為
Accuracy=TP+TNTP+TN+FP+FN,(18)
F1=2·TP2×TP+FP+FN,(19)
其中:TP是預測正確的故障事件個數;TN是預測錯誤的故障事件個數;FP是預測發生但實際未發生的故障事件個數;FN是未預測出但實際發生的故障事件個數。
3.2.2 參數設置
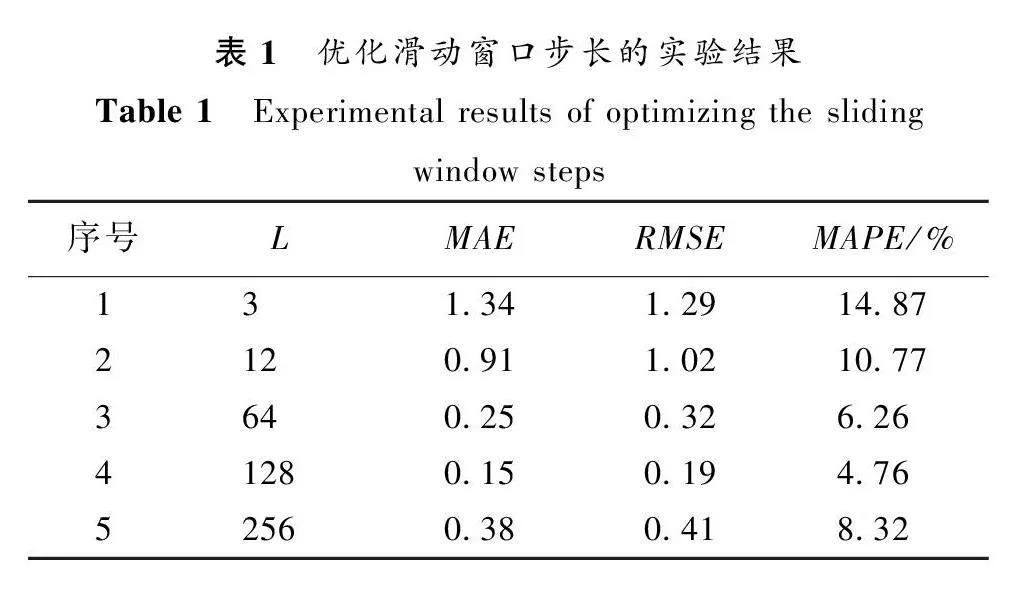
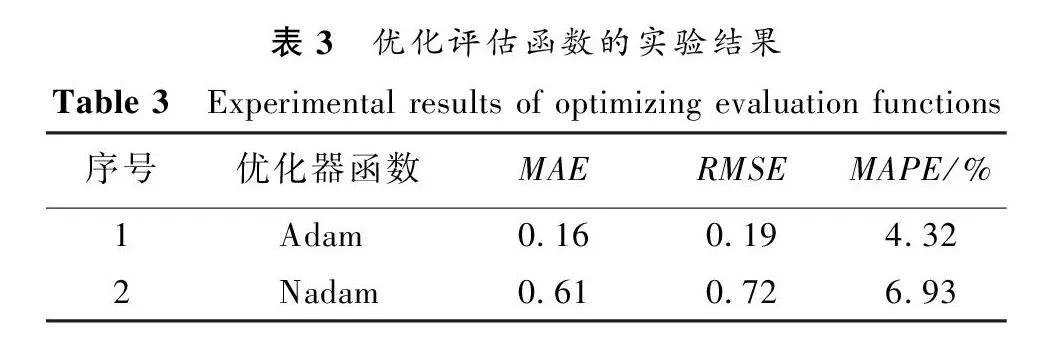
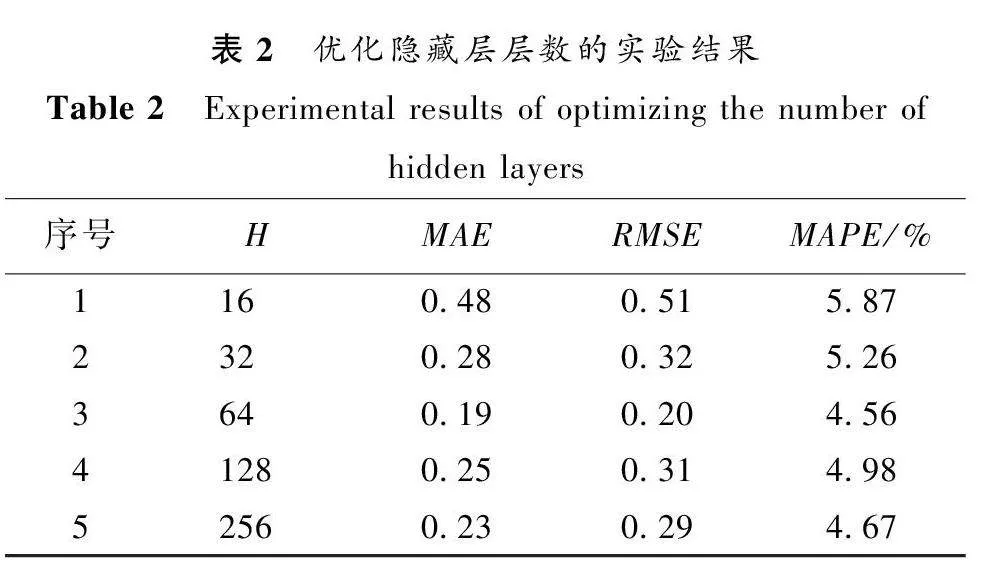
實驗環境配置如下:操作系統為Windows 10;GPU為NVIDIA RTX3090 24 GB顯存;內存64 GB;編程語言為Python 3.9;深度學習框架為Pytorch 1.3 穩定版。使用Python庫加載數據集,設置模型的各種參數。通過算法1進行了參數設置的實驗,實驗結果如表1~3所示。
在搜索最優配置的實驗中,設置L為每一行中向前滑動窗口的步長,L∈{3,12,64,128,256},保留一個參數作為變量,其他參數保持不變。從表1可以看出,當L為128時,實驗效果優于其他參數設定。
設置隱藏層層數H∈{16,32,64,128,256},從表2可以看出,當H為64時,結果較好。
從表3的優化評估函數的實驗結果可以看出,優化器函數Adam比Nadam表現得更好。
3.2.3 基線模型
主要包括以下基線模型。
1) RF[21]:隨機森林算法(random forest,RF)是基于決策樹的集成學習算法模型。
2) LR[15]:Logistic回歸算法(Logistic regression,LR)是用于不平衡樣本分類的回歸算法模型。
3) SVM[22]:支持向量機(support vector machine,SVM),多分類支持向量機算法進行回歸任務。
4) RNN[3]:循環神經網絡 (recurrent neural network,RNN)是處理序列數據的神經網絡。
5) LSTM[23]:長短期記憶網絡(long short-term memory, LSTM)是一種 RNN的特殊類型,通過門控機制學習長期依賴信息。
6) GRU[24]:門控循環單元(gated recurrent unit,GRU)是LSTM 的一個變體,GRU在保持了LSTM效果的同時又使結構更加簡單。
7) Transformer[16]:基于自注意力機制的神經網絡模型。
8) LogTrans[17]:Transformer變種模型,在自注意力模型中引入了稀疏偏差,提出卷積自注意力。
9) Informer[25]:修改了Transformer的結構,隱式地引入稀疏偏差的一種長期預測模型。
上述基線模型的實驗參數設置如下:將批處理大小和隱藏層層數分別設置為128和64,第一層神經元數量為256,序列滑動窗口步長為128,預測窗口步長為128,epoch為100,Batch size為64,學習率為0.8。對于結合雙向循環模型和注意力機制的模型,單個方向的隱藏層層數設置為128,學習率設置為0.8。在TBGRU上使用相同的設置,并將Transformer的dropout設置為0.3。
3.3 實驗結果和分析
3.3.1 模型性能評估
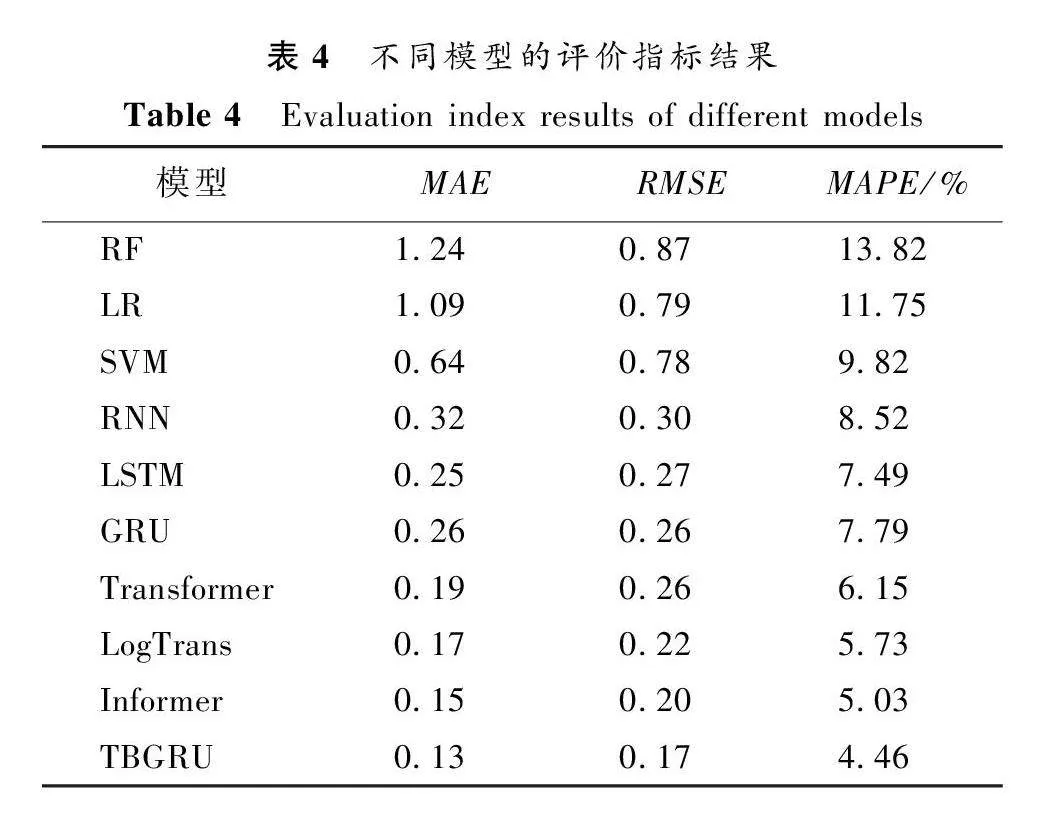
不同模型的評價指標結果如表4所示。可以看出,RF的預測性能在MAE、RMSE和MAPE指標上的表現不如其他模型。使用SVM和LR等傳統機器模型的結果雖然稍好于RF,但與其他基于深度學習的方法相比仍有較大的差距。在深度學習方法中,因為RNN、LSTM和GRU只捕獲了局部時間特征,在長期預測的過程中會造成部分信息遺忘,所以模型的預測性能不佳。Transformer引入了注意力機制,更加關注對關鍵特征信息的記憶,在長時間序列預測的3項評價指標
上優于RNN、LSTM和GRU模型,其MAE、RMSE和MAPE分別達到0.19、0.26和6.15%。引入了卷積自注意力機制的LogTrans,可以使局部上下文更好地聯系關鍵特征,模型的預測性能得到進一步提升。Informer通過修改Transformer內部結構和生成式解碼器來直接產生長期預測,提升了預測性能,其MAE、RMSE和MAPE分別達到0.15、0.20和5.03%。
本文的TBGRU是在BiGRU的基礎上引入了Transformer,不僅捕獲了數據序列的局部時間特征,并且通過Transformer層來捕獲全局時間依賴性,使得TBGRU堆疊了時間同步卷積層,可以很好地學習長程時間關系和異質性,其MAE、RMSE和MAPE分別達到0.13、0.17和4.46%。與其他模型的最優性能指標相比,分別提升13.34%、15.00%和11.33%。這證明了TBGRU模型可以準確地捕獲集群日志數據中的局部時間依賴性和全局時間依賴性,取得了優異的預測效果。
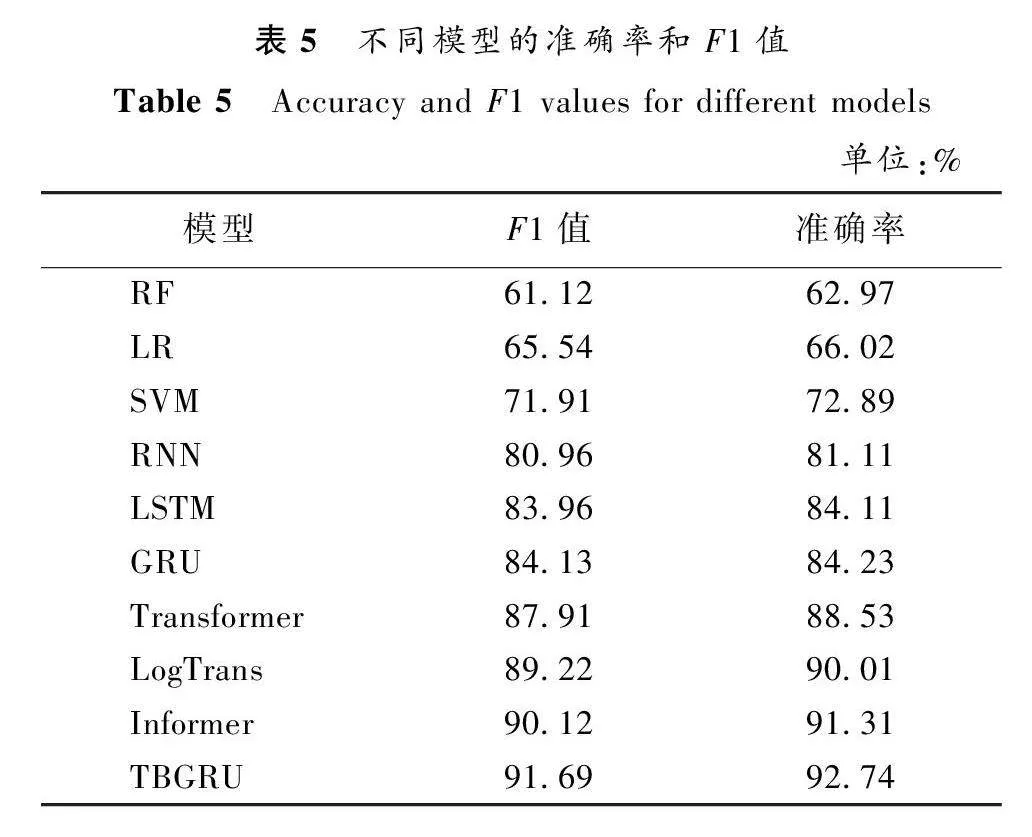
不同模型的準確率和F1值如表5所示。傳統方法中RF、LR和SVM的準確率分別達到62.97%、66.02%和72.89%,遠不如深度學習方法。深度學習基準模型RNN、LSTM和GRU中的最佳模型是GRU,其準確率達到84.23%。引入了注意力機制的Transformer模型,其準確率和F1值進一步提升。在先進的長時間序列預測模型中,Informer表現較好,其準確率和F1值分別達到91.31%和90.12%。TBGRU模型表現最佳,其準確率和F1值分別達到92.74%和91.69%。
3.3.2 模型有效性評估
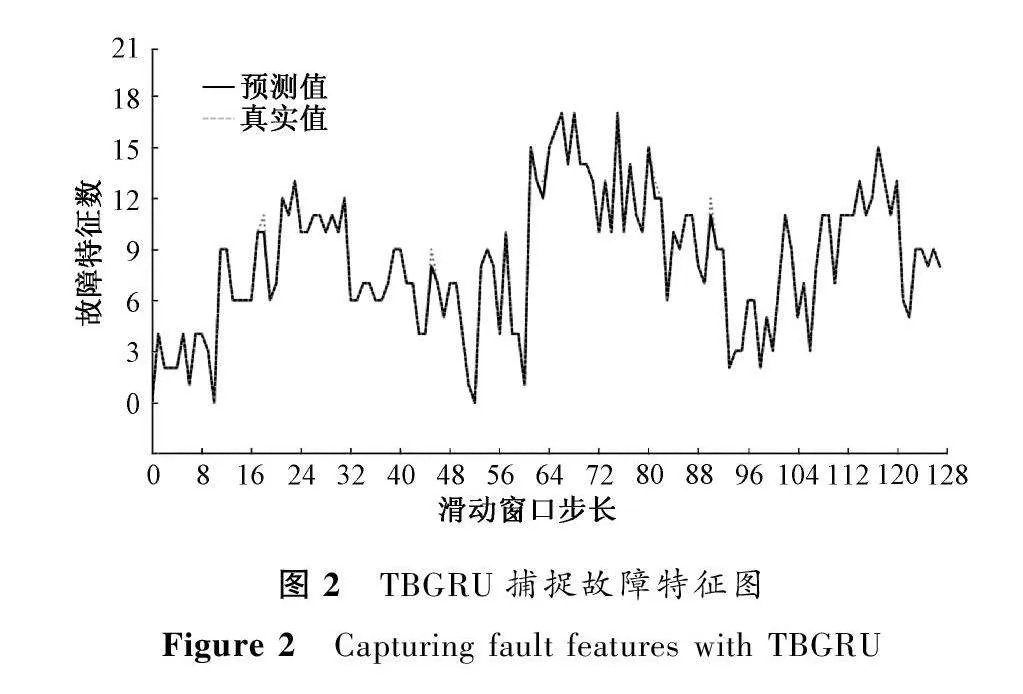
RNN的鏈式結構導致在處理長時間序列數據時,存在部分信息遺忘[11]。因此,使用TBGRU來獲取時序的局部時間依賴性和整體時間依賴性,從而解決了這個問題。TBGRU捕捉故障特征圖如圖2所示。可以看出,TBGRU的預測結果與實際標簽值吻合較好。
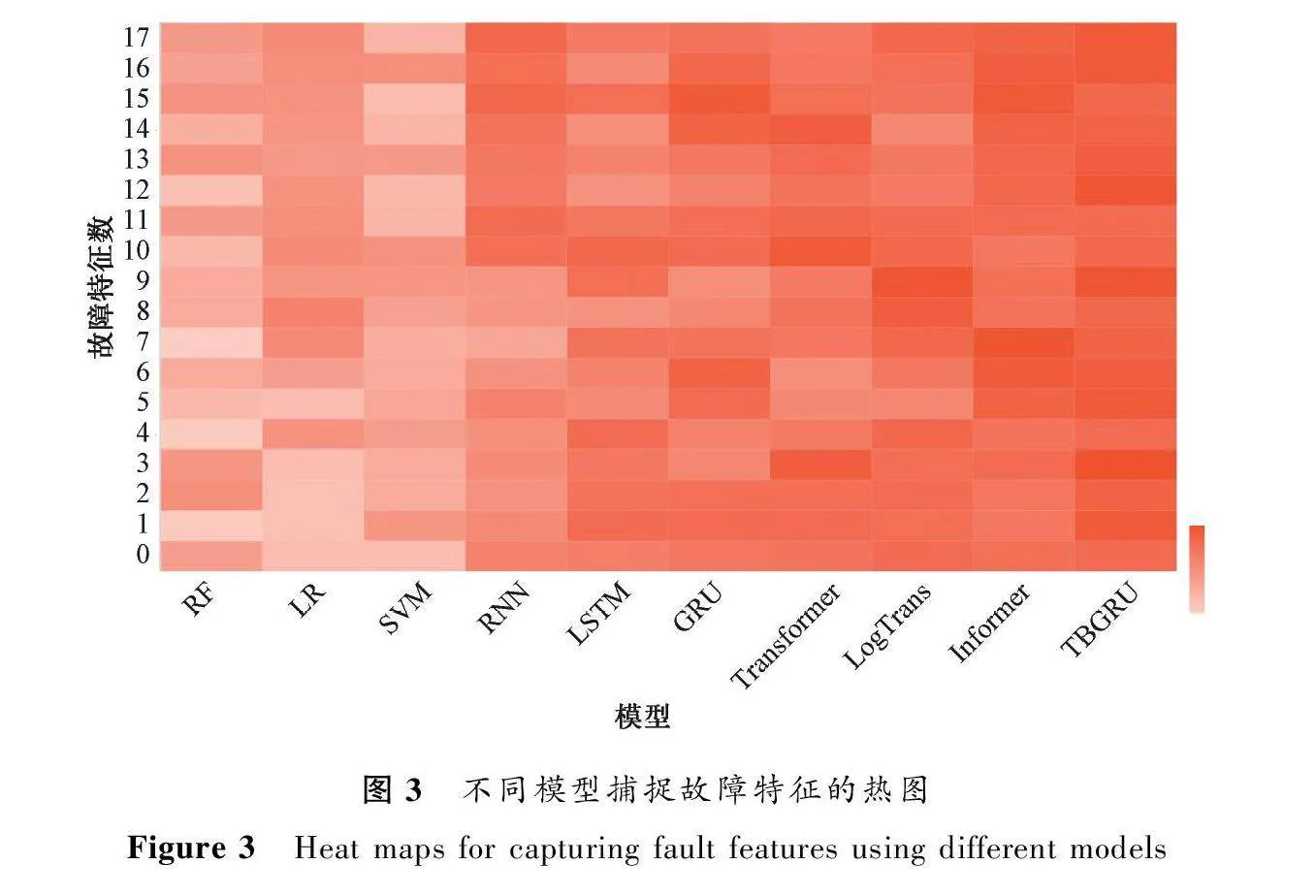
圖3以熱圖的形式顯示了不同模型在面對長時間序列時針對18個故障特征的抓取能力。顏色由淺到深代表模型抓取某一特征的能力由弱到強。可以看出,傳統方法中RF、LR和SVM抓取特征的熱力區域相對較“冷”,這是由于它們并沒有挖掘數據序列之間的深層次特征,弱化了模型提取故障特征的能力。在深度學習方法中,RNN、LSTM和GRU的表現不如引入了卷積自注意力機制的LogTrans。但表現更為出色的是Informer,這是由于該模型隱式地引入稀疏偏差,并設計一種生成式解碼器,可以對序列信息直接進行長期預測,從而避免了長期預測時出現的累積誤差,進而提升了預測性能,但在抓取某些特征時熱力區域表現較“冷”。TBGRU模型在這方面表現更好,熱力區域普遍較“熱”,這是由于該模型能夠有效地從復雜集群系統故障中挖掘潛在的日志事件因果關系、局部時間相關性和整體時間相關性。實驗證明,相比其他模型,TBGRU捕獲特征能力更為突出。
3.4 消融實驗
為了進一步研究不同模塊的影響,設計了4種模型變體,并與TBGRU模型進行了比較。4種模型變體如下。
1) Baseline:該模型使用GRU捕獲空間依賴性,使用MSELoss作為損失函數。
2) Replace_BiGRU:該模型在Baseline的基礎上,使用BiGRU代替GRU,捕獲日志事件之間的時間依賴性。
3) Baseline(L-S):該模型使用Soft-DTW代替MSELoss作為損失函數。
4) Add_Transformer:該模型在Baseline(L-S)的基礎上,在BiGRU后增加一個Transformer層處理BiGRU輸出的數據。
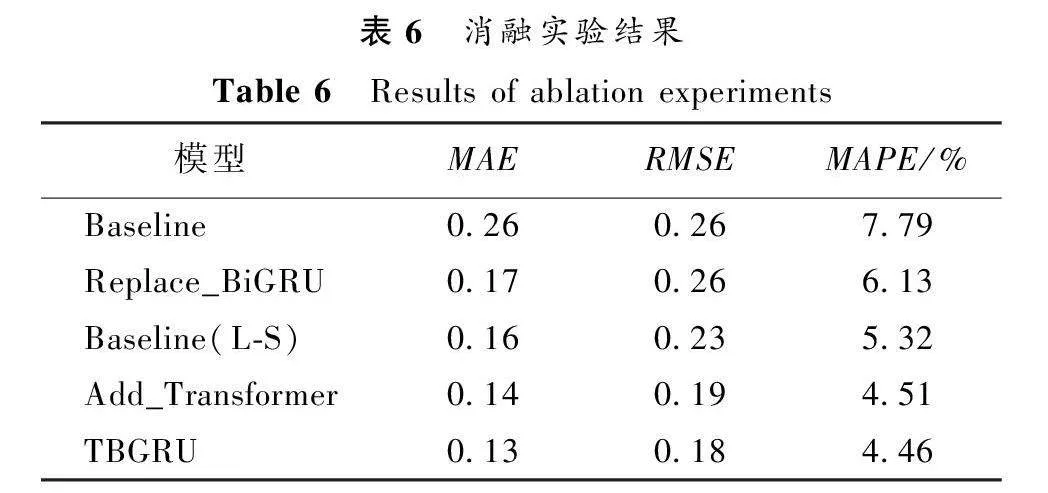
本文的TBGRU模型使用BiGRU獲取集群系統日志之間的局部時間依賴性,利用Transformer捕獲整體的時間依賴性,然后使用Soft-DTW作為模型的損失函數,最后通過全連接神經網絡進行預測。消融實驗結果如表6所示。
可以看出,使用BiGRU進行時序特征提取時要比單向GRU具有更好的性能,這是由于雙向疊加的設計可以序列地進行正向和反向掃描,獲取時間點過去和未來的上下文信息,提高了預測的準確度。與此同時,使用Soft-DTW作為損失函數比使用MSELoss要有明顯的性能提升。對于添加了Transformer層的Add_Transformer,其具有更好的長時依賴性捕獲能力,模型性能進一步提升。TBGRU模型綜合了這些優點,使得其具有優秀的故障預測能力。
4 結語
針對集群系統故障預測方法在面對長時間序列預測時遇到的梯度爆炸或消失問題,提出一種新的基于深度學習的集群系統故障預測方法。該方法主要集合了Transformer的全局特征提取能力和雙向循環模型BiGRU獲取局部時序特征能力,同時捕獲局部的時間依賴性和整體時間內事件的時序關系,并抓取長時的依賴信息,更適用于集群系統故障的長時間序列預測。使用Blue Gene/L集群系統日志數據對模型的有效性進行了驗證,結果表明,與其他模型的最佳效果相比,TBGRU模型具有更好的故障預測效果。
參考文獻:
[1] 鄭維維. 集群系統失效預測與資源重配置方法[D]. 北京: 北京郵電大學, 2017.
ZHENG W W. Approaches for failure prediction and resource re-allocation in cluster systems[D]. Beijing: Beijing University of Posts and Telecommunications, 2017.
[2] 董婧. 基于時空關聯分析的集群系統故障預測方法[D]. 北京: 北京郵電大學,2020.
DONG J. Failure prediction method of cluster system based on spatio-temporal correlation analysis[D]. Beijing: Beijing University of Posts and Telecommunications,2020.
[3] YANG Y, DONG J, FANG C, et al. FP-STE: a novel node failure prediction method based on spatio-temporal feature extraction in data centers[J]. Computer modeling in engineering and sciences, 2020, 123(3): 1015-1031.
[4] MA Y, WU S, GONG S, et al. Artificial intelligence-based cloud data center fault detection method[C]∥IEEE 9th Joint International Information Technology and Artificial Intelligence Conference. Piscataway:IEEE Press, 2021: 762-765.
[5] BENGIO Y, SIMARD P, FRASCONI P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE transactions on neural networks, 1994, 5(2): 157-166.
[6] WANG Z G, GAO L X, GU Y, et al. A fault-tolerant framework for asynchronous iterative computations in cloud environments[C]∥IEEE Transactions on Parallel and Distributed Systems. Piscataway:IEEE Press,2018: 1678-1692.
[7] KHAN S, NASEER M, HAYAT M, et al. Transformers in vision: a survey[J]. ACM computing surveys, 2022, 54(10):1-41.
[8] ZHOU T, MA Z Q, WEN Q S, et al. FEDformer: frequency enhanced decomposed transformer for long-term series forecasting[C]∥Proceedings of International Conference on Machine Learning. New York: ACM Press, 2022: 27268-27286.
[9] REN R, LI J H, YIN Y, et al. Failure prediction for large-scale clusters logs via mining frequent patterns[M]∥Communications in Computer and Information Science. Berlin: Springer Press,2021: 147-165.
[10]王衛華, 應時, 賈向陽, 等. 一種基于日志聚類的多類型故障預測方法[J]. 計算機工程, 2018, 44(7): 67-73.
WANG W H, YING S, JIA X Y, et al. A multi-type failure prediction method based on log clustering[J]. Computer engineering, 2018, 44(7): 67-73.
[11]FU X Y, REN R, ZHAN J F, et al. LogMaster: mining event correlations in logs of large-scale cluster systems[C]∥IEEE 31st Symposium on Reliable Distributed Systems. Piscataway:IEEE Press, 2013: 71-80.
[12]FU X Y, REN R, MCKEE S A, et al. Digging deeper into cluster system logs for failure prediction and root cause diagnosis[C]∥IEEE International Conference on Cluster Computing. Piscataway:IEEE Press, 2014: 103-112.
[13]LIANG Y, ZHANG Y Y, XIONG H, et al. Failure prediction in IBM Blue Gene/L event logs[C]∥Proceedings of the 7th IEEE International Conference on Data Mining. Piscataway:IEEE Press, 2008: 583-588.
[14]王振華. 基于日志分析的網絡設備故障預測研究[D]. 重慶: 重慶大學, 2015.
WANG Z H. Study on failure prediction for network equipment based on log analysis[D].Chongqing: Chongqing University, 2015.
[15]MOHAMMED B, AWAN I, UGAIL H, et al. Failure prediction using machine learning in a virtualised HPC system and application[J]. Cluster computing, 2019, 22(2): 471-485.
[16]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM Press,2017: 6000-6010.
[17]LI S Y, JIN X Y, XUAN Y, et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting[EB/OL]. (2019-06-29)[2022-12-21]. https:∥doi.org/10.48550/arXiv.1907.00235.
[18]WU H X, XU J H, WANG J M, et al. Autoformer: decomposition transformers with auto-correlation for long-term series forecasting[EB/OL]. (2022-01-01)[2022-12-21]. https:∥doi.org/10.48550/arXiv.2106.13008.
[19]CUTURI M, BLONDEL M. Soft-DTW: a differentiable loss function for time-series[C]∥Proceedings of the 34th International Conference on Machine Learning. New York: ACM Press, 2017: 894-903.
[20]Ultrascale Systems Research Center. CFDR data[EB/OL]. (2022-02-01) [2022-11-21]. https:∥www.usenix.org/cfdr-data.
[21]BOTEZATU M M, GIURGIU I, BOGOJESKA J, et al. Predicting disk replacement towards reliable data centers[C]∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 39-48.
[22]XU C, WANG G, LIU X G, et al. Health status assessment and failure prediction for hard drives with recurrent neural networks[J]. IEEE transactions on computers, 2016, 65(11): 3502-3508.
[23]王鑫, 吳際, 劉超, 等. 基于LSTM循環神經網絡的故障時間序列預測[J]. 北京航空航天大學學報, 2018, 44(4): 772-784.
WANG X, WU J, LIU C, et al. Exploring LSTM based recurrent neural network for failure time series prediction[J]. Journal of Beijing university of aeronautics and astronautics, 2018, 44(4): 772-784.
[24]HAI Q D, ZHANG S W, LIU C, et al. Hard disk drive failure prediction based on GRU neural network[C]∥IEEE/CIC International Conference on Communications in China. Piscataway:IEEE Press, 2022: 696-701.
[25]ZHOU H Y, ZHANG S H, PENG J Q, et al. Informer: beyond efficient transformer for long sequence time-series forecasting[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 11106-11115.
