具有性能感知排序的深度監(jiān)督哈希用于多標簽圖像檢索
2024-08-17 00:00:00張志升曲懷敬謝明張漢元
計算機應(yīng)用研究 2024年7期


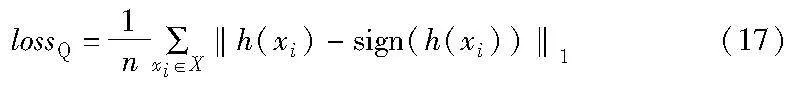


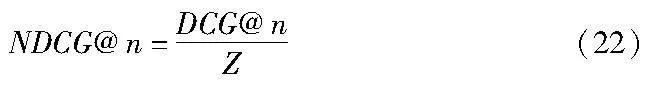
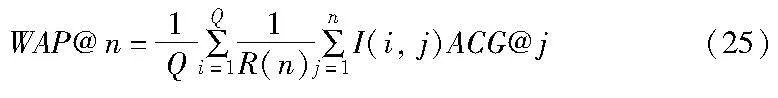


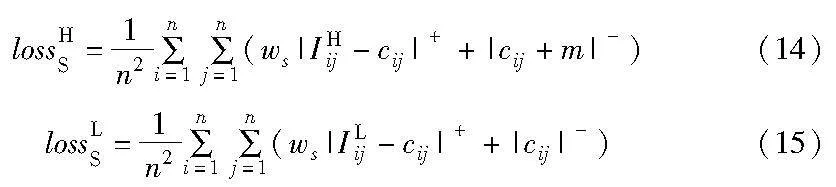


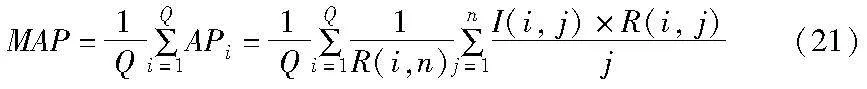
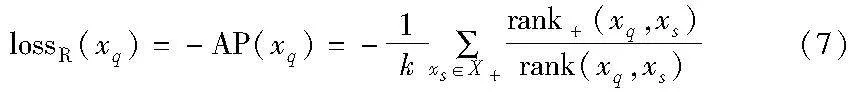
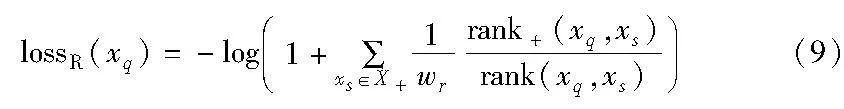

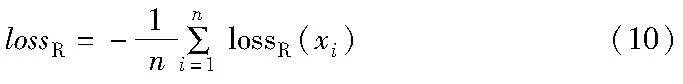

摘 要:現(xiàn)實生活中的圖像大多具有多種標簽屬性。對于多標簽圖像,理想情況下檢索到的圖像應(yīng)該按照與查詢圖像相似的程度降序排列,即與查詢圖像共享的標簽數(shù)量依次遞減。然而,大多數(shù)哈希算法主要針對單標簽圖像檢索而設(shè)計,而且現(xiàn)有用于多標簽圖像檢索的深度監(jiān)督哈希算法忽略了哈希碼的排序性能且沒有充分地利用標簽類別信息。針對此問題,提出了一種具有性能感知排序的深度監(jiān)督哈希方法(deep supervised hashing with performance-aware ranking,PRDH),它能夠有效地感知和優(yōu)化模型的性能,改善多標簽圖像檢索的效果。在哈希學(xué)習(xí)部分,設(shè)計了一種排序優(yōu)化損失函數(shù),以改善哈希碼的排序性能;同時,還加入了一種空間劃分損失函數(shù),將具有不同數(shù)量的共享標簽的圖像劃分到相應(yīng)的漢明空間中;為了充分地利用標簽信息,還鮮明地提出將預(yù)測標簽用于檢索階段的漢明距離計算,并設(shè)計了一種用于多標簽分類的損失函數(shù),以實現(xiàn)對漢明距離排序的監(jiān)督及優(yōu)化。在三個多標簽基準數(shù)據(jù)集上進行的大量檢索實驗結(jié)果表明,PRDH的各項評估指標均優(yōu)于現(xiàn)有先進的深度哈希方法。
關(guān)鍵詞:深度監(jiān)督哈希;多標簽圖像檢索;排序;標簽信息
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2024)07-043-2221-08
doi: 10.19734/j.issn.1001-3695.2023.09.0511
Deep supervised hashing with performance-aware ranking formulti-label image retrieval
Abstract: Most images in real life have multi-label attributes. For multi-label images, ideally, the retrieved images should be ranked in descending order of similarity to the query image, namely their numbers of labels shared with the query image decrease sequentially. However, most hashing algorithms are mainly designed for the single label image retrieval, and the exis-ting deep supervised hashing algorithms for multi-label image retrieval ignore the ranking performance of hash codes and do not fully utilize the label category information. To solve this problem, this paper proposed a deep supervised hashing with performance-aware ranking method(PRDH), which could effectively perceive and optimize the performance of the model and improve the effect of the multi-label image retrieval. In the hash learning part, this paper designed a ranking optimization loss function to improve the ranking performance of hash codes. At the same time, this paper adopted a spatial partition loss function to divide images with different numbers of shared labels into corresponding Hamming spaces. In order to fully utilize label information, this paper also explicitly proposed using predictive label for Hamming distance calculation in the retrieval stage, and designed a loss function for multi-label classification to achieve supervision and optimization of Hamming distance ranking. A large number of results of the retrieval experiments conducted in three multi-label benchmark datasets show that the evaluation metrics of PRDH outperform the state-of-the-art hashing approaches.
Key words:deep supervised hashing; multi-label image retrieval; ranking; label information
0 引言
在數(shù)字化時代,如何快速且準確地從海量圖像中檢索到目標圖像,是圖像處理和計算機視覺領(lǐng)域研究的重點與難點任務(wù)之一[1]。為此,早期研究者們提出了一種用于圖像檢索的哈希算法,該算法將圖像從原始空間映射到漢明空間,并以二值碼的形式存儲。該方法具有存儲空間小、檢索速度快的優(yōu)點。在眾多檢索性能優(yōu)良的傳統(tǒng)哈希方法中,最典型的有局部敏感哈希(locality sensitive hashing,LSH)[2]、迭代量化哈希(iterative quantization, ITQ)[3]、最小損失哈希(minimal loss hashing,MLH)[4]、二值重構(gòu)嵌入(binary reconstructive embedding,BRE)[5]、核監(jiān)督哈希(kernel-based supervised hashing,KSH)[6]以及監(jiān)督漢明哈希(supervised Hamming hashing,SHH)[7]等方法。然而,傳統(tǒng)的哈希方法由于采用手工設(shè)計,通常具有一定的局限性,尤其在提取更加復(fù)雜的語義信息方面,相比于基于深度學(xué)習(xí)的哈希方法效果較差。深度哈希方法不僅能夠自動提取更加抽象的特征信息,而且在大規(guī)模圖像檢索領(lǐng)域中也有廣泛應(yīng)用。在深度監(jiān)督哈希方法中,具有代表性的有卷積神經(jīng)網(wǎng)絡(luò)哈希(convolutional neural network hashing,CNNH)[8]、深度監(jiān)督哈希(deep supervised hashing,DSH)[9]、深度平衡離散哈希(deep balanced discrete hashing,DBDH)[10]、中心相似性量化(central similarity quantization,CSQ)[11]、正交哈希(orthogonal hashing,OrthoHash)[12]和深度哈希蒸餾(deep hash distillation,DHD)[13]方法等。
目前,基于深度監(jiān)督哈希的圖像檢索方法得到了廣泛而深入的研究。然而,在深度監(jiān)督哈希方法中通常存在如下三個問題:a)現(xiàn)實生活中的圖像大多數(shù)具有多種標簽屬性,而大多數(shù)深度監(jiān)督哈希方法主要針對單標簽圖像檢索而設(shè)計,因而在多標簽圖像檢索中效果不佳;b)大多數(shù)深度監(jiān)督哈希方法忽略了哈希碼的排序特性;c)良好的類別信息有助于哈希碼排序特性的學(xué)習(xí),然而,這并沒有被大多數(shù)深度監(jiān)督哈希方法所充分利用。這三個問題的存在使得多標簽圖像檢索研究有著進一步的改進空間,也日益得到研究者的廣泛關(guān)注。其中,針對前兩個問題,大多數(shù)方法是在成對或三元組損失函數(shù)的基礎(chǔ)上改進為多級相似性損失函數(shù)來指導(dǎo)哈希函數(shù)的學(xué)習(xí)[14~19],使學(xué)習(xí)到的哈希碼更具有排序特性。同時,針對第三個問題,一些哈希方法在損失函數(shù)中加入分類損失[14,15,17,18,20],以使哈希碼學(xué)習(xí)到更多的類別信息。但是它們往往只能在哈希函數(shù)中學(xué)習(xí)類別信息,這是遠遠不夠的。因此,本文希望通過充分利用類別信息來學(xué)習(xí)到更具有排序特性的哈希碼。
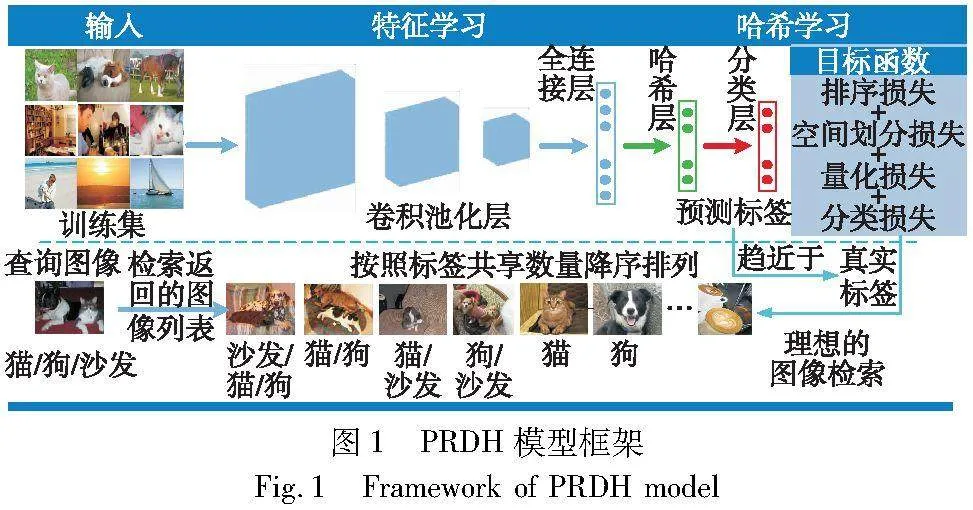
通常,對于多標簽圖像檢索,理想情況下檢索到的圖像應(yīng)該按照與查詢圖像的相似程度降序排列,即與查詢圖像相同的標簽數(shù)量依次遞減。這既符合人類的認知,也是人們查詢時的需求。例如,如圖1中的理想圖像檢索狀態(tài)所示,查詢圖像是一幅具有“貓”“狗”和“沙發(fā)”三個標簽屬性的圖像,理想情況下檢索到的相似圖像排序列表如下:首先,與查詢圖像有三個標簽相同的圖像在第一區(qū)間;其次,三個標簽中任意兩個相同的圖像在第二區(qū)間;再次,三個標簽中任意一個相同的圖像在第三區(qū)間;最后,不具有相同標簽的圖像在第四區(qū)間;同時,在以上每區(qū)間內(nèi)的圖像均分別按照與查詢圖像的相似程度進行降序排列。因此,為了能夠以最大可能實現(xiàn)理想的多標簽圖像檢索,針對上述問題,本文提出了一種具有性能感知排序的深度監(jiān)督哈希算法(deep supervised hashing with performance-aware ranking,PRDH)。圖1概括了PRDH模型框架。該框架將多標簽圖像的特征學(xué)習(xí)和哈希學(xué)習(xí)結(jié)合在一起進行聯(lián)合學(xué)習(xí),其中,哈希學(xué)習(xí)部分由排序損失、空間劃分損失、量化損失和分類損失函數(shù)組成,以使學(xué)習(xí)到的哈希碼具有良好的排序特性。同時,為了充分利用標簽信息,鮮明地將預(yù)測標簽用于檢索階段的漢明距離計算上,以監(jiān)督和優(yōu)化漢明距離的排序。如果預(yù)測標簽越接近真實標簽,且哈希函數(shù)能學(xué)習(xí)到具有良好排序特性的哈希碼,那么漢明距離的排序越接近于按照共享標簽數(shù)量大小的排序,從而較好地接近、甚至實現(xiàn)理想情況下的多標簽圖像檢索。本文的主要貢獻可以概括為以下四個方面:
a)提出了一種具有性能感知排序的深度監(jiān)督哈希算法,它可以將原始空間與漢明空間統(tǒng)一起來,有效地感知和優(yōu)化模型的性能,提高了多標簽圖像檢索的性能。
b)設(shè)計了一種排序優(yōu)化損失函數(shù),以改善哈希碼的排序特性。還加入了一種空間劃分損失函數(shù),以將具有不同數(shù)量的共享標簽的圖像劃分到相應(yīng)的漢明空間中。同時,在量化損失函數(shù)的約束下,使得學(xué)習(xí)到的哈希碼更加具有離散特性。
c)鮮明地提出了一種將預(yù)測標簽用于檢索階段的漢明距離計算的策略,并設(shè)計了一種用于多標簽分類的損失函數(shù),從而利用標簽信息實現(xiàn)對漢明距離排序的監(jiān)督與優(yōu)化。
d)在三個多標簽基準數(shù)據(jù)集上的實驗結(jié)果表明,本文方法的各項評估指標均優(yōu)于現(xiàn)有先進的深度監(jiān)督哈希方法。
1 相關(guān)工作
目前,由于大多數(shù)深度監(jiān)督哈希方法主要針對單標簽圖像檢索而設(shè)計,所以在多標簽圖像檢索中往往性能不佳。為了有效地提高多標簽圖像檢索的性能,已有研究者提出了一些可行的方法。其中,大多數(shù)深度監(jiān)督哈希方法主要在成對或三元組損失函數(shù)的基礎(chǔ)上進行改進,學(xué)習(xí)具有排序特性的哈希函數(shù)。例如,Zhao等人[21]提出了一種深度語義排序哈希算法DSRH(deep semantic ranking based hashing),該方法采用NDCG(normalized discounted cumulative gain)指標作為三元組損失的權(quán)重,來指導(dǎo)哈希函數(shù)的學(xué)習(xí),使學(xué)習(xí)到的哈希碼具有排序特性。Zhang等人[16]提出了一種改進的深度哈希網(wǎng)絡(luò)IDHN(improved deep hashing network),該方法將成對相似性分為硬相似性和軟相似性兩種情況來指導(dǎo)哈希函數(shù)的學(xué)習(xí),使學(xué)習(xí)到的哈希碼具有較好的排序特性。類似地,Dai等人[18]提出了特征分離與交互學(xué)習(xí)方法,該方法設(shè)計了一種標簽引導(dǎo)的相似性損失函數(shù)以保持圖像間的相似性。為了使哈希碼具有更好的排序特性,Ma等人[19]提出了一種排序一致性深度哈希算法RCDH(rank-consistency deep hashing),該方法設(shè)計了一種排序一致性哈希函數(shù),以對齊原始空間和漢明空間的相似順序。為了充分地利用多個標簽之間的相關(guān)性,Shen等人[20]提出了深度協(xié)同圖像標簽的哈希方法DCILH(deep co-image-label hashing)來利用標簽相關(guān)性,該方法將圖像和標簽映射到一個公共的深度漢明空間,以保持圖像、標簽和標簽原型之間的相似性。特別地,為了有效地利用圖像的語義信息和標簽信息,Chen等人[22]提出了一種基于深度多實例排序的哈希方法DMIRH(deep multiple-instance ranking based hashing),該方法通過具有多標簽的圖像識別出其中的不同標簽實例,并對不同的實例進行分類和特征提取,然后將屬于該圖像的所有特征信息再聚合起來編碼為二值哈希碼。類似地,Qin等人[23]提出了一種具有類損失的深度頂端相似性哈希算法DTSHCW(deep top similarity hashing with class-wise loss),該方法直接利用類標簽,并引入基于高斯分布的三次約束來優(yōu)化目標函數(shù),以保持不同類的語義變化。另一方面,還有一些用于多標簽圖像檢索的深度哈希方法,它們?yōu)榱顺浞值乩脠D像的標簽信息,根據(jù)圖像的標簽內(nèi)容生成描述圖像的簡單文本信息,并將提取的文本信息和提取的圖像語義信息相結(jié)合,從而有效地提高了模型的多標簽圖像檢索性能,如標簽參與哈希[24]、深度語義感知排序保持哈希[25]和具有語義感知保持的深度多相似性哈希[26]等。盡管上述這些多標簽深度哈希方法均取得了較好的檢索性能,但是它們僅僅在哈希函數(shù)中學(xué)習(xí)類別信息。相比較地,本文方法則希望在哈希學(xué)習(xí)之外,在檢索階段也可以利用標簽信息,以監(jiān)督和優(yōu)化漢明距離的排序。
2 所提方法
對于多標簽圖像數(shù)據(jù)集,本文希望檢索到的圖像不僅正確,而且對應(yīng)的共享標簽數(shù)量也應(yīng)該是依次遞減的。為此,本文提出了一種具有性能感知排序的深度監(jiān)督哈希方法。該方法能夠有效地實現(xiàn)深度哈希學(xué)習(xí)和多標簽分類,其采用的目標函數(shù)為
loss=lossR+αlossS+βlossQ+γlossC(1)
其中:lossR為排序優(yōu)化損失函數(shù);α、β和γ分別為控制空間劃分損失函數(shù)lossS、量化損失函數(shù)lossQ和多標簽分類損失函數(shù)lossC的參數(shù)。
2.1 哈希學(xué)習(xí)
為了獲得高質(zhì)量的哈希碼,在哈希學(xué)習(xí)過程中,本文設(shè)計了排序優(yōu)化損失函數(shù)、空間劃分損失函數(shù)和量化損失函數(shù)。
2.1.1 排序優(yōu)化損失函數(shù)
為了最大化AP(xq),并使訓(xùn)練過程中損失最小,xq的排序優(yōu)化損失函數(shù)定義為
此外,為了便于反向傳播更新參數(shù),忽略了式(7)中的1/k。同時,對式(7)取對數(shù),并考慮穩(wěn)定性,則xq的排序優(yōu)化損失函數(shù)為
另一方面,為了使lossR更好地適用于多標簽圖像檢索,本文為每個相似樣本集X+中相似樣本的相似性排名添加了相應(yīng)的共享標簽歸一化權(quán)重wr,可表示為wr=lqs/lmax,q,s∈[1,n],其中,lqs=yqyTs表示xq和xs之間的共享真實標簽數(shù),lmax為最大的共享標簽數(shù)。顯然,相似樣本之間的共享標簽數(shù)越多,wr越大,對應(yīng)的排序優(yōu)化損失懲罰就越大,使學(xué)習(xí)到的對應(yīng)哈希碼間更具相似性。相應(yīng)地,式(8)可改寫為
最終,當(dāng)前批次的樣本集的排序優(yōu)化損失函數(shù)為
2.1.2 空間劃分損失函數(shù)
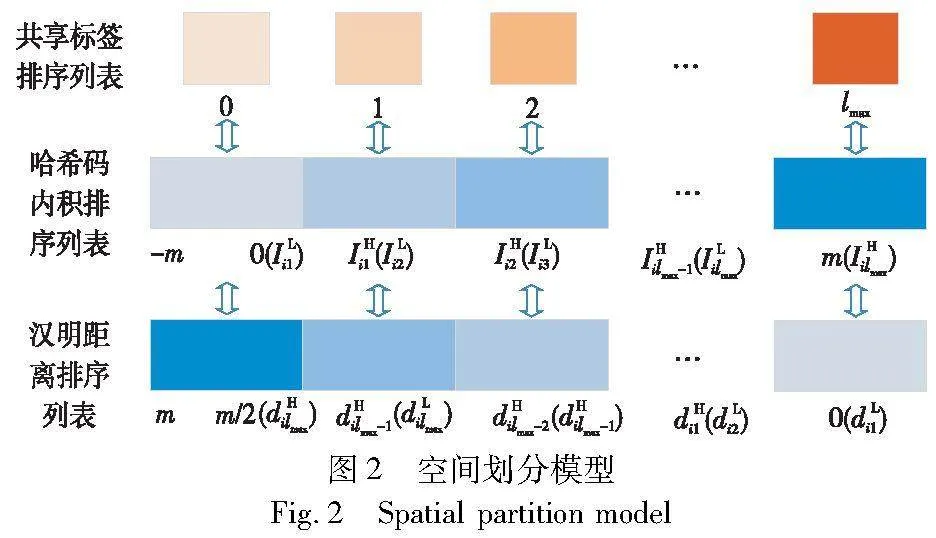
在lossR的基礎(chǔ)之上,本文加入了空間劃分損失lossS以增強具有多標簽的哈希碼的排序性能。Ma等人[19]曾根據(jù)圖像之間共享標簽的數(shù)量對漢明空間進行劃分,并指出圖像之間共享標簽的數(shù)量與對應(yīng)的漢明距離成正比(漢明距離可表示為dij=(m-cij)/2,其中,i, j∈[1,n],m為哈希碼長,cij=bibTj表示第i和j個哈希碼間的內(nèi)積)。可以推斷,此時圖像之間共享標簽數(shù)量與對應(yīng)的哈希碼內(nèi)積成反比。然而,通常認為圖像之間共享的標簽數(shù)量越多,對應(yīng)的哈希碼內(nèi)積就越大。為此,本文提出了一種新的空間劃分模型,如圖2所示。它通過絕對值約束使得每一對圖像的共享標簽數(shù)都對應(yīng)一個區(qū)間的哈希碼內(nèi)積,且共享標簽的數(shù)量與對應(yīng)的哈希碼內(nèi)積成正比,與對應(yīng)的漢明距離成反比。
在式(12)(13)中,等式右邊第一項分別表示計算相似樣本的空間劃分上界損失和下界損失,以使每個相似樣本根據(jù)相似性程度的大小學(xué)習(xí)到相應(yīng)大小的哈希碼內(nèi)積;第二項分別表示計算不相似樣本的空間劃分上界損失和下界損失,以使每個不相似樣本學(xué)習(xí)到的哈希碼內(nèi)積盡可能在-m~0。此外,為了緩解相似樣本和不相似樣本的不均衡問題,在式(12)(13)中為正樣本加入權(quán)重ws,它是不相似樣本數(shù)量和相似樣本數(shù)量的比值,即
同時,為了便于配合lossR,同樣對lossHS和lossLS分別取對數(shù),即
lossS=log(1+lossHS)+log(1+lossLS)(16)
2.1.3 量化損失函數(shù)
通常,理想的哈希碼是緊湊且離散的二值碼。在式(10)(16)中,由于哈希碼的離散性,使得模型在訓(xùn)練時,梯度無法進行有效的反向傳播。鑒于此問題,使用輸入圖像x在深度網(wǎng)絡(luò)哈希層輸出的實值h來替換其對應(yīng)的哈希碼b。同時,為了使h的值接近于+1或-1,加入如式(17)所示的量化損失函數(shù),以減少哈希函數(shù)學(xué)習(xí)過程中造成的量化損失。
2.2 多標簽分類損失函數(shù)
針對多標簽圖像,在分類層中采用sigmoid激活函數(shù),并對每一個類別進行二分類。通常,對應(yīng)的分類損失函數(shù)采用交叉熵損失,即
2.3 標簽強監(jiān)督
以往的監(jiān)督哈希方法主要注重在哈希學(xué)習(xí)過程中采用標簽進行監(jiān)督。然而,對于多標簽圖像,這種監(jiān)督不夠全面,因為它沒有充分挖掘標簽信息。此外,在檢索階段,按漢明距離排序時的排序質(zhì)量往往只依賴于強大的哈希函數(shù)去學(xué)習(xí)一個高質(zhì)量的哈希碼,而本文則希望標簽信息也能參與漢明距離的計算,從而優(yōu)化漢明距離的排序質(zhì)量,提高模型的檢索性能。具體地,在漢明距離計算時,將查詢圖像的真實標簽yt和數(shù)據(jù)庫圖像的真實標簽yd之間的共享標簽數(shù)量l=ytyTd作為權(quán)重,若它們哈希碼之間的內(nèi)積為c,則其漢明距離計算如下:
3 實驗
3.1 數(shù)據(jù)集
實驗采用了MIRFLICKR-25K、VOC2012、NUS-WIDE和MS-COCO四個廣泛使用的多標簽數(shù)據(jù)集。
a)MIRFLICKR-25K是一個包含有38個標簽的多標簽彩色圖像數(shù)據(jù)集。它總共有25 000幅圖像,平均每幅圖像大約有4.7個標簽。同文獻[23],本文選擇2 000幅圖像作為測試集和查詢數(shù)據(jù)集,剩余的作為訓(xùn)練集和數(shù)據(jù)庫。
b)VOC2012是一個包含有20個標簽的多標簽彩色圖像數(shù)據(jù)集。本文實驗中僅使用其訓(xùn)練和驗證數(shù)據(jù)集(共11 540幅圖像)。同文獻[23],本文隨機選擇2 000幅圖像作為測試集和查詢數(shù)據(jù)集,剩余的作為訓(xùn)練集和數(shù)據(jù)庫。
c)NUS-WIDE是一種包含195 834幅彩色圖像的大規(guī)模多標簽數(shù)據(jù)集,它有21個類別,每個類別至少包含5 000幅圖像。同文獻[20],本文采用2 100幅圖像(每類100幅)作為測試集和查詢集,其余的作為數(shù)據(jù)庫,并從數(shù)據(jù)庫中隨機抽取10 500幅圖像作為訓(xùn)練集(每類500幅)。
d)MS-COCO數(shù)據(jù)集是一種包含122 218幅彩色圖像的大規(guī)模多標簽數(shù)據(jù)集,它有80個類別。同文獻[13],本文隨機挑選5 000幅圖像作為測試集和查詢集,其余的作為數(shù)據(jù)庫,并從數(shù)據(jù)庫中隨機抽取10 000幅圖像作為訓(xùn)練集。
3.2 實驗設(shè)置和評估指標
所有實驗均在一臺配置為Geforce RTX 2060 6GB GPU和8 GB RAM的計算機中實現(xiàn)。使用具有預(yù)訓(xùn)練權(quán)重的AlexNet[28]作為本文模型的骨干網(wǎng)絡(luò)(也可替換為其他骨干網(wǎng)絡(luò)),并將上述三個數(shù)據(jù)集的圖像均縮放到224×224像素大小作為網(wǎng)絡(luò)輸入。訓(xùn)練總共進行300個epoch,學(xué)習(xí)率為0.000 01。根據(jù)經(jīng)驗,超參數(shù)α、β和γ分別設(shè)置為0.1、0.001和0.01;由于分類層采用sigmoid激活函數(shù),所以閾值T設(shè)置為0.5。
為了評估本文方法的性能,采用平均精度均值(MAP)、歸一化折損累積增益(NDCG)、平均累積增益(ACG)和加權(quán)平均精度(WAP)四個常用的檢索評估指標。其中,對于NUS-WIDE和MS-COCO數(shù)據(jù)集,使用返回的前5 000幅圖像計算MAP值。
MAP描述的是所有查詢圖像的平均精度AP的均值,其中,AP是準確率(precision)的均值。通常,檢索得到的正確結(jié)果排名越靠前,檢索系統(tǒng)的MAP就越高。若Q為查詢圖像數(shù)量,為前n個檢索結(jié)果中與第i幅查詢圖像相關(guān)的圖像數(shù)量,MAP的計算公式為
其中:I(i, j)為指示性函數(shù),如果第i幅查詢圖像與第j幅圖像共享一些標簽,則I(i, j)=1,否則I(i, j)=0。
NDCG被廣泛用于評估信息檢索任務(wù)中排名結(jié)果的質(zhì)量,它關(guān)注相似度更高的圖像。與MAP類似,更相似的正確結(jié)果排名越靠前,該指標就越大。檢索得到前n個圖像的NDCG計算公式為
其中:Z為DCG@n的最大值,它是根據(jù)檢索返回結(jié)果的正確排名列表計算的,DCG的計算公式為
其中:ci表示查詢圖像與第i幅檢索圖像之間的共享標簽數(shù)。
ACG描述的是查詢圖像和前n個檢索圖像之間的平均相似度,計算公式為
WAP是MAP的一種變體,它可以根據(jù)ACG來計算,對于評估模型的檢索性能更為準確和科學(xué)。檢索得到前n個圖像的WAP計算公式為
3.3 不同方法檢索性能的對比
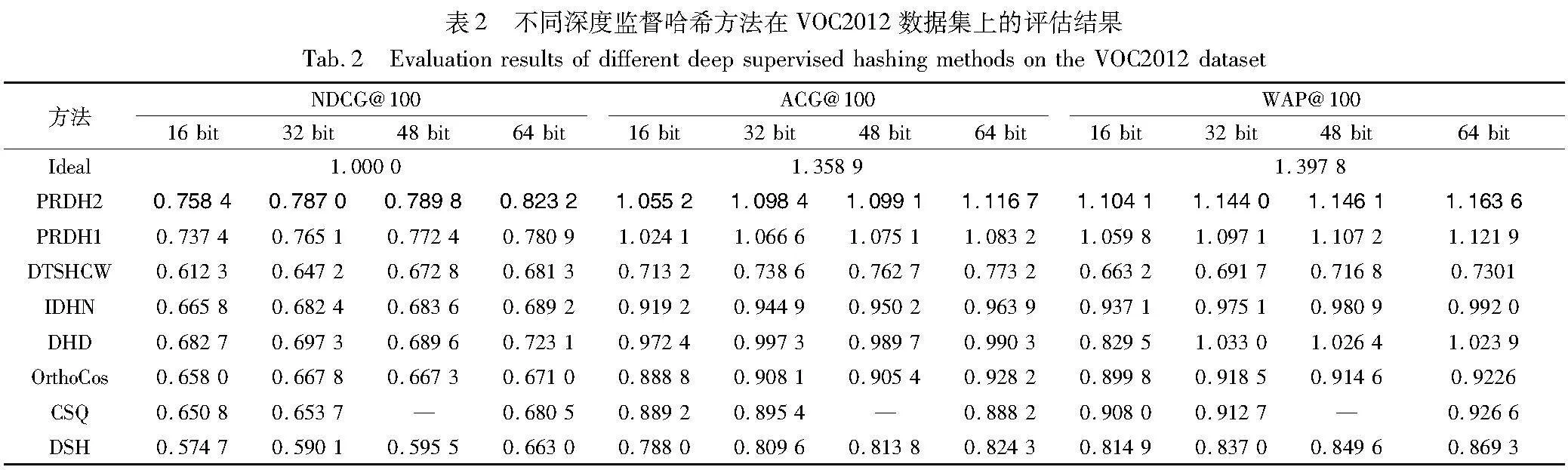
為了有效地評估PRDH1和PRDH2(參見2.3節(jié))的有效性,本文選擇參與對比的深度監(jiān)督哈希方法有DHD[13] 、OrthoCos[12]、CSQ[11]、DHEH[29]、DSH[9]、IDHN[16]、RCDH[19]、DTSHCW[23]、DCILH[20]、HyP2[30]和MCRD[31]十一種典型方法,另外還加入了理想情況下的圖像檢索“Ideal”方法用于對比。其中,后六種深度哈希方法主要是針對多標簽圖像檢索而設(shè)計的。表1~3分別對比了不同的深度監(jiān)督哈希方法在不同數(shù)據(jù)集上針對NDCG@100、ACG@100、WAP@100三種評價指標的檢索結(jié)果,其中,“—”表示對應(yīng)的方法中沒有此結(jié)果;黑色加粗字體表示當(dāng)前對比方法中評價指標最好(“Ideal”方法除外)。通過觀察表1~3中的數(shù)據(jù),有以下四點發(fā)現(xiàn):
a)綜合所有指標考慮,雖然用于多標簽圖像檢索的深度哈希方法優(yōu)于主要針對單標簽圖像檢索而設(shè)計的深度哈希方法,但是后者中少數(shù)方法在某些數(shù)據(jù)集或者某些評估指標上優(yōu)于前者。例如,在VOC2012數(shù)據(jù)集上,后者中的DHD方法在三個評估指標中均好于前者,OrthoCos方法在部分評估指標中也僅次于DHD方法。這主要是由于DHD和OrthoCos這兩種方法在其哈希函數(shù)的學(xué)習(xí)中分別針對性地設(shè)計了一種學(xué)習(xí)類標簽相似性的損失函數(shù)和多標簽分類損失函數(shù),從而使其學(xué)習(xí)到的哈希碼具有更多的類別信息。
b)本文方法在三個數(shù)據(jù)集上的三個評估指標均優(yōu)于所對比的深度哈希方法。例如在MIRFLICKR-25K數(shù)據(jù)集上,當(dāng)碼長為48 bit時,PRDH1方法相較于DTSHCW方法的NDCG@100指標提升了6.51%、相較于RCDH方法的ACG@100指標提升了8.20%、相較于DHD方法的WAP@100指標提升了12.03%。
c)PRDH2是所對比方法中較為接近于理想圖像檢索的一種深度監(jiān)督哈希方法。前述中,PRDH1方法在各項指標上均優(yōu)于其他深度監(jiān)督哈希方法。而在數(shù)據(jù)庫的標簽信息已知的情況下,PRDH2相對更加接近于“Ideal”方法的理想指標。以檢索任務(wù)難度最大的NUS-WIDE數(shù)據(jù)集為例,當(dāng)碼長為48 bit時,PRDH2的三個評價指標NDCG@100、ACG@100和WAP@100達到了“Ideal”方法的71.12%、83.35%、83.51%,而相較于PRDH1也顯著提升了62.96%、35.99%、37.12%。
d)實驗還在更具有挑戰(zhàn)性的NU-SWIDE和MS-COCO數(shù)據(jù)集上對目前較為先進的深度監(jiān)督哈希方法的MAP值進行評估,評估結(jié)果如表4所示。從表4可以看出,本文方法不論是在NUS-WIDE上,還是在MS-COCO上,不同哈希碼長對應(yīng)的MAP值均優(yōu)于目前較為先進的深度哈希方法。
為了從可視化的角度說明本文方法良好的排序性能,實驗以MIRFLICKR-25K數(shù)據(jù)集為例,從測試集中隨機挑選三幅查詢圖像,在哈希碼長為48 bit時,將PRDH1和PRDH2方法與深度哈希模型中檢索性能較好的DHD方法進行對比,圖3可視化了三個哈希方法檢索返回的前10幅最相似圖像。圖中左邊第1列為查詢圖像,第2~11列為檢索返回的前10幅圖像;返回圖像上方的“/”兩側(cè)標注的數(shù)字分別表示與查詢圖像共享的真實標簽數(shù)和理論情況下的標簽數(shù)。
從圖3可知,PRDH1和PRDH2相比DHD方法,檢索返回的圖像更加相似且共享標簽數(shù)更多;尤其是PRDH2的檢索結(jié)果幾乎全部正確,檢索結(jié)果更接近于理想的圖像檢索。這表明,本文方法具有良好的排序性能。需要指出的是,本文方法檢索返回的部分圖像列表中,也存在共享標簽數(shù)排序不理想的情況,例如圖3(b)中第二個查詢圖像的檢索返回結(jié)果的共享標簽數(shù)并未完全按照倒序排列,該現(xiàn)象說明本文方法還有進一步的完善空間。
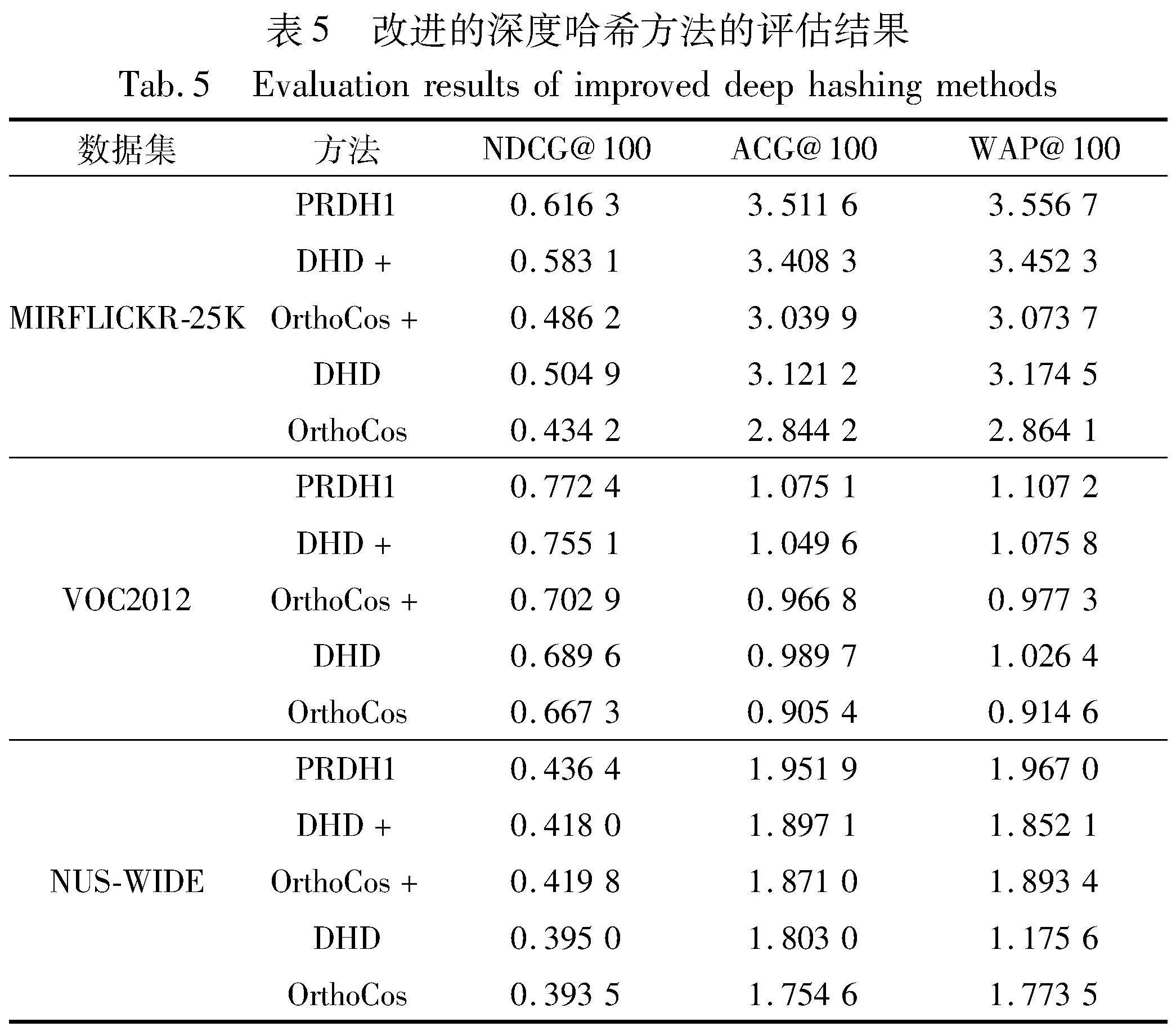
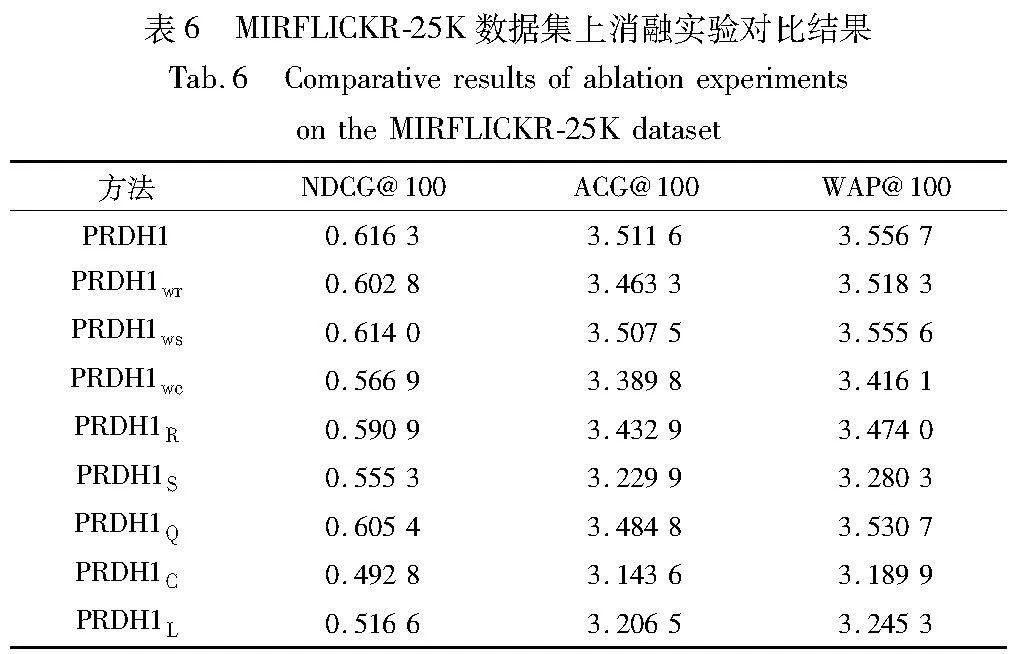
為了進一步說明本文方法的有效性,實驗將提出方法中“預(yù)測標簽用于檢索階段的漢明距離計算上”這一策略用于其他深度哈希方法。以表1~4中深度哈希方法檢索性能較為突出的DHD和OrthoCos為例,采用這一策略的這兩種深度哈希方法被分別命名為DHD+和OrthoCos+。將改進的兩種方法與其原方法在三種數(shù)據(jù)集上進行不同評估指標的對比實驗,其中,碼長為48 bit時的評估結(jié)果如表5所示。從表5的數(shù)據(jù)可以看出,改進的這兩種深度哈希方法相較其原方法均有明顯的提升,這表明標簽信息參與漢明距離的計算與排序非常有助于改善多標簽圖像檢索的性能;同時可以看到,本文方法的檢索性能仍優(yōu)于這兩種改進方法,驗證了本文方法的有效性和優(yōu)越性。
3.4 參數(shù)敏感性
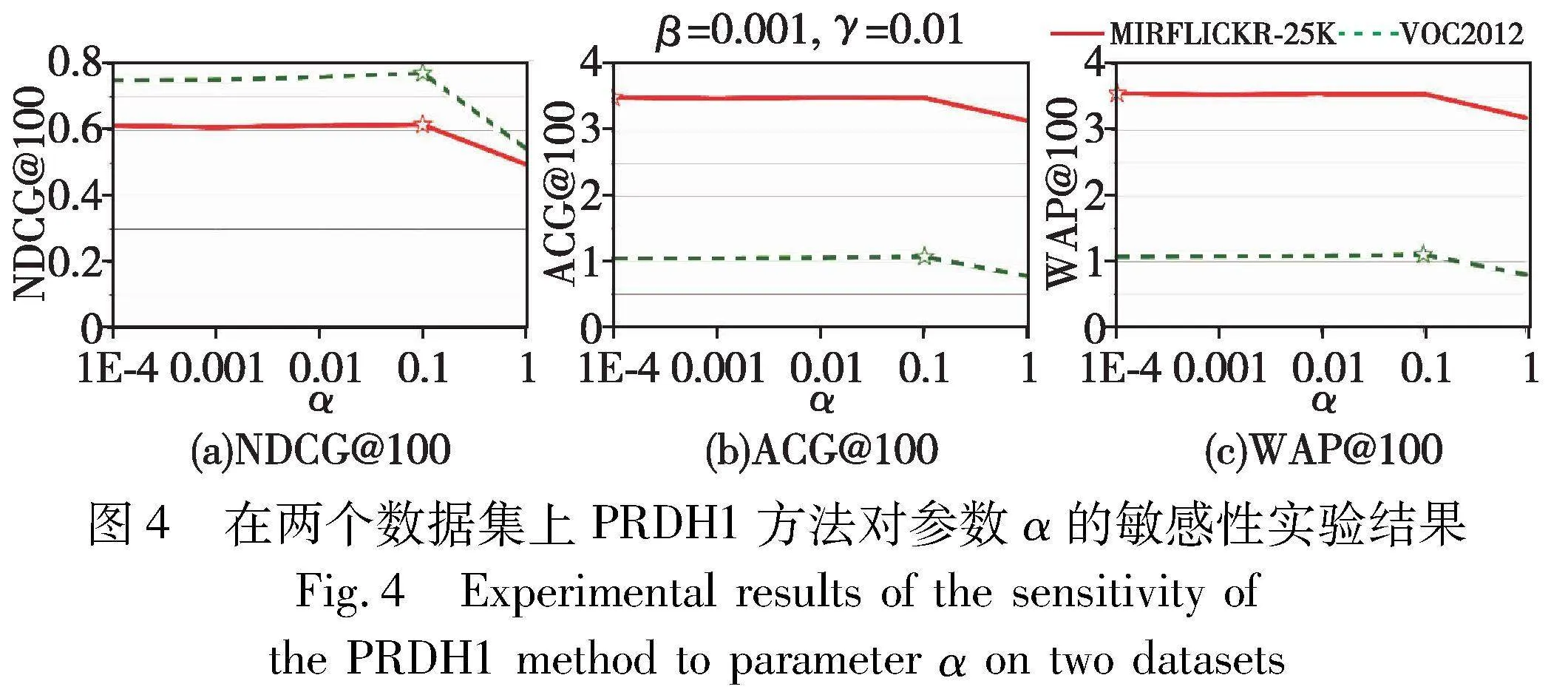
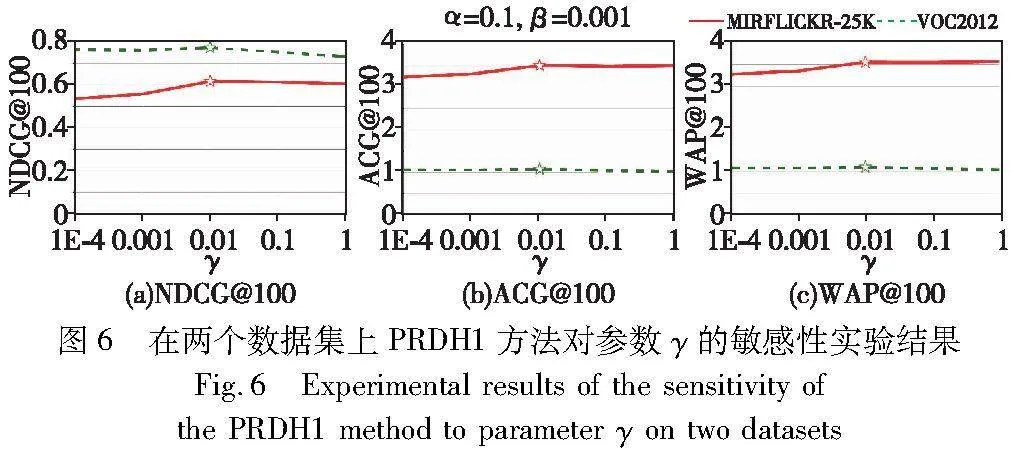
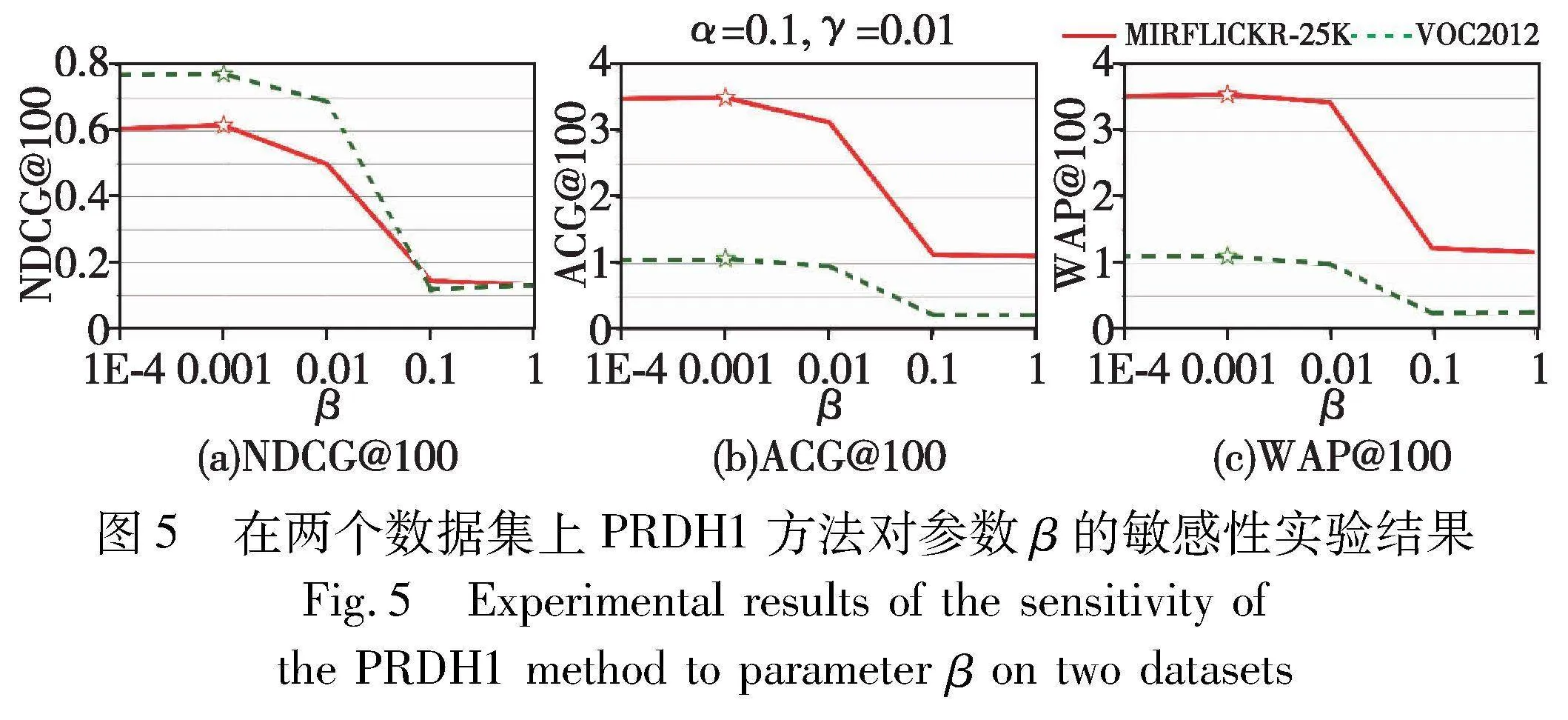
為了評估本文方法對超參數(shù)α、β和γ的敏感程度,以PRDH1為例,在MIRFLICKR-25K和VOOC2012數(shù)據(jù)集上進行實驗分析。其中:哈希碼長取為48 bit;α、β和γ分別在{1, 0.1, 0.01, 0.001, 0.000 1}取值,且對其中一個參數(shù)變量進行實驗時,其他參數(shù)均保持為最優(yōu)參數(shù)值。PRDH1在不同超參數(shù)取不同值時所對應(yīng)的檢索結(jié)果(指標分別為NDCG@100、ACG@100和WAP@100)如圖4~6所示,其中“☆”標注點表示在對應(yīng)數(shù)據(jù)集上,該參數(shù)設(shè)置使得當(dāng)前評估指標達到最優(yōu)。
從圖5(a)~(c)中的折線變化趨勢可見,當(dāng)α=0.1和γ=0.01時,β在兩個數(shù)據(jù)集上均取值為0.001,PRDH1方法取得最優(yōu)的結(jié)果。同樣地,在圖6(a)~(c)中,當(dāng)α=0.1和β=0.001時,γ在兩個數(shù)據(jù)集上取值為0.01時可使得PRDH1方法取得最優(yōu)的結(jié)果。然而,在圖4(a)~(c)中,當(dāng)β=0.001和γ=0.01時,α在VOOC2012數(shù)據(jù)集上取值為0.1時,PRDH1方法得到最優(yōu)的結(jié)果;而在MIRFLICKR-25K數(shù)據(jù)集上,當(dāng)α=0.1時,雖然只有NDCG@100指標取得最優(yōu)的結(jié)果,但從圖4(b)和(c)中也可以看到,對應(yīng)的評估指標和最優(yōu)指標變化不明顯,這表明PRDH1方法對參數(shù)α取值的敏感性相對較低。因此,本文的超參數(shù)α、β和γ分別設(shè)置為0.1、0.001和0.01。
3.5 消融實驗
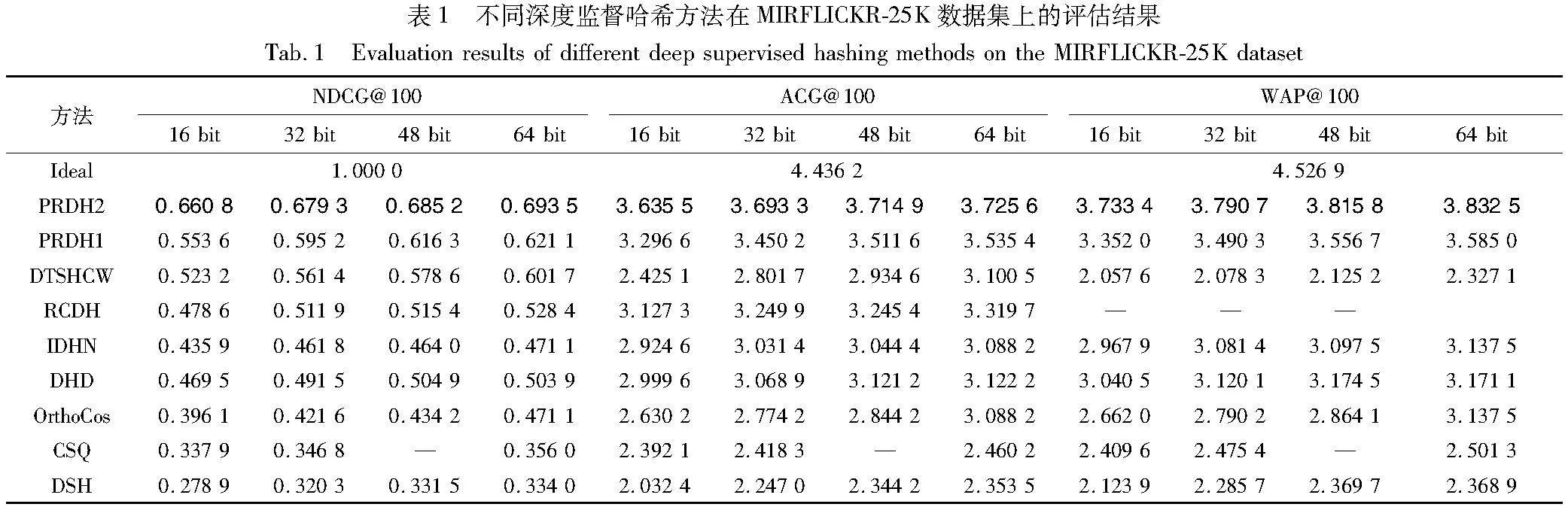
為了評估目標函數(shù)中各個部分對于圖像檢索性能的貢獻,以MIRFLICKR-25K和VOOC2012數(shù)據(jù)集為例,對PRDH1方法進行消融實驗分析。首先,在PRDH1方法的排序優(yōu)化損失函數(shù)lossR中不使用權(quán)重wr、空間劃分損失函數(shù)lossS中不使用權(quán)重ws或分類損失函數(shù)lossC中不使用權(quán)重wc的模型這三個方法的實驗屬于損失函數(shù)內(nèi)的消融實驗。然后,將PRDH1方法中不使用lossR、lossS、lossC或lossQ以及在檢索階段不使用預(yù)測標簽的方法分別命名為PRDH1R、PRDH1S、PRDH1Q、PRDH1C和PRDH1L,這五種方法的實驗屬于損失函數(shù)間的消融實驗。
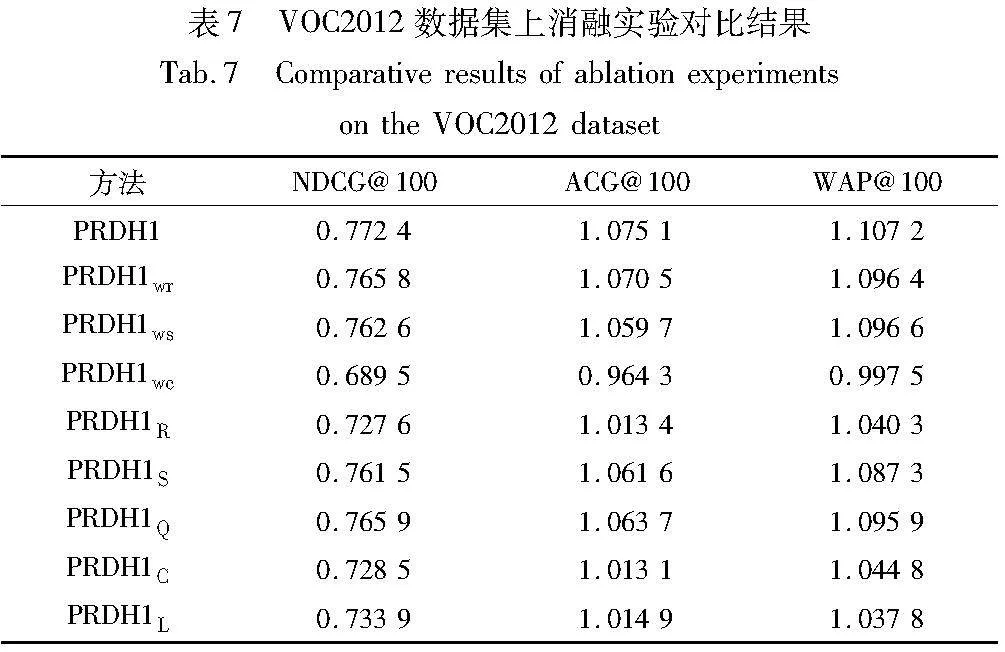
表6、7分別給出了哈希碼長為48 bit時,在MIRFLICKR-25K和VOOC2012數(shù)據(jù)集上的不同評價指標對應(yīng)的消融實驗對比結(jié)果。根據(jù)表6、7中的數(shù)據(jù)對比,可以觀察到以下三個結(jié)論。
a)在損失函數(shù)內(nèi)的消融實驗中,針對VOC2012數(shù)據(jù)集,PRDH1wr、PRDH1ws和PRDH1wc方法與PRDH1方法相比,NDCG@100指標分別降低了0.85%、1.26%和10.73%。因此可以看出,相比于權(quán)重wr和ws,權(quán)重wc對PRDH1性能的提升較大。這表明,權(quán)重wc可以有效地提高預(yù)測標簽的準確率,進而有助于提升PRDH1的檢索性能。同理,針對VOC2012數(shù)據(jù)集,在損失函數(shù)間的消融實驗中,PRDH1R、PRDH1S、PRDH1C、PRDH1L和PRDH1Q與PRDH1相比,其NDCG@100指標分別降低了5.80%、1.41%、5.68%、4.98%和0.84%。由此可以看出,lossR、lossS、lossC和在檢索階段使用預(yù)測標簽對PRDH1檢索性能的提升相對于lossQ貢獻較大。同時,消融實驗數(shù)據(jù)還表明,每一個權(quán)重參數(shù)以及每一部分損失函數(shù),在提出的方法中都發(fā)揮著重要的作用,它們是一個有機的整體。
b)該消融實驗也證明了在檢索階段使用預(yù)測標簽可以有效地提升多標簽圖像檢索的性能。例如在MIRFLICKR-25K數(shù)據(jù)集上,PRDH1C和PRDH1L相比于PRDH1,NDCG@100指標分別降低了20.03%和16.17%,可知,lossC對PRDH1方法的檢索性能的貢獻僅為3.86%,遠小于在檢索階段使用預(yù)測標簽的16.17%。
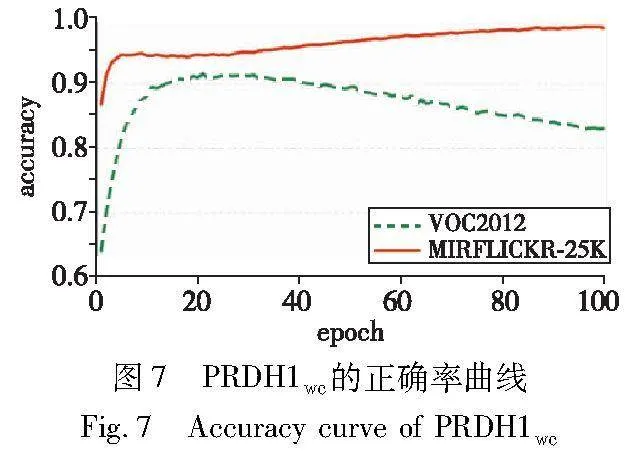
c)有一個異常的現(xiàn)象值得注意,正常而言,由于PRDH1C或PRDH1L方法相對于PRDH1wc方法沒有使用lossC或在檢索階段未使用預(yù)測標簽,所以PRDH1wc的檢索結(jié)果應(yīng)該好于前兩者(例如在MIRFLICKR-25K數(shù)據(jù)集上的檢索結(jié)果)。然而,在VOC2012數(shù)據(jù)集上的檢索結(jié)果卻相反,實驗分析認為這與在檢索階段使用預(yù)測標簽有關(guān)。為了進一步驗證,在圖7中繪畫出了PRDH1wc在MIRFLICKR-25K和VOOC2012數(shù)據(jù)集上前100輪的分類正確率曲線。從圖7可以明顯觀察到,在MIRFLICKR-25K數(shù)據(jù)集上,正確率曲線隨著訓(xùn)練輪數(shù)增加而逐漸接近于1,而在VOOC2012數(shù)據(jù)集上,正確率曲線隨著訓(xùn)練輪數(shù)增加卻是先增加后減少。通常,分類正確率越低,標簽的預(yù)測效果就越差,從而導(dǎo)致了在檢索階段的排序結(jié)果也較差。這就是PRDH1wc的檢索結(jié)果在MIRFLICKR-25K上檢索性能正常,而在VOC2012上不佳的原因。
4 結(jié)束語
為了使學(xué)習(xí)到的哈希碼具有良好的排序特性,并能將標簽類別信息有效地用于圖像檢索,本文提出了一種具有性能感知排序的深度監(jiān)督哈希方法(PRDH)。該方法主要在深度哈希學(xué)習(xí)部分設(shè)計了一個目標函數(shù),同時鮮明地將預(yù)測標簽用于檢索階段的漢明距離計算和排序上。為了驗證本文方法的有效性和可行性,在三個基準多標簽數(shù)據(jù)集中進行了大量的檢索實驗,并從不同深度哈希方法對比、檢索結(jié)果可視化、參數(shù)敏感性和消融實驗等方面對本文方法進行評估和分析。實驗結(jié)果表明,本文方法能有效地感知和優(yōu)化模型的檢索性能,具有良好的排序特性,在各項評價指標中均優(yōu)于現(xiàn)有先進的深度哈希方法。特別地,實驗環(huán)節(jié)驗證了標簽信息參與漢明距離的計算與排序?qū)Χ鄻撕瀳D像檢索性能有著重要的影響,因此如何設(shè)計一個更加有效的分類損失函數(shù),以及如何使哈希碼學(xué)習(xí)到更有效的類別標簽信息,都將是需要進一步深入研究的內(nèi)容。
參考文獻:
[1]Li Xiaoqing,Yang Jiansheng,Ma Jinwen. Recent developments of content-based image retrieval[J]. Neurocomputing,2021,452: 675-689.
[2]Gionis A,Indyk P,Motwani R. Similarity search in high dimensions via hashing[C]// Proc of the 25th International Conference on Very Large Data Bases. New York: ACM Press,1999: 518-529.
[3]Gong Yunchao,Lazebnik S. Iterative quantization: a procrustean approach to learning binary codes[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2011: 817-824.
[4]Norouzi M,F(xiàn)leet D J. Minimal loss hashing for compact binary codes[C]// Proc of the 28th International Conference on Machine Lear-ning.[S.l.]: Omnipress,2011: 353-360.
[5]Kulis B,Darrell T. Learning to hash with binary reconstructive embeddings[C]// Proc of the 22nd International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2009: 1042-1050.
[6]Liu Wei,Wang Jun,Ji Rongrong,et al. Supervised hashing with kernels[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2012: 2074-2081.
[7]Wang Shaohua,Kang Xiao,Liu Fasheng,et al. Supervised discrete hashing for Hamming space retrieval[J]. Pattern Recognition Letters,2022,154: 16-21.
[8]Xia Rongkai,Pan Yan,Lai Hanjiang,et al. Supervised hashing for image retrieval via image representation learning[C]// Proc of the 28th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2014: 2156-2162.
[9]Liu Haomiao,Wang Ruiping,Shan Shiguang,et al. Deep supervised hashing for fast image retrieval[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 2064-2072.
[10]Zheng Xiangtao,Zhang Yichao,Lu Xiaoqiang. Deep balanced discrete hashing for image retrieval[J]. Neurocomputing,2020,403: 224-236.
[11]Yuan Li,Wang Tao,Zhang Xiaopeng,et al. Central similarity quantization for efficient image and video retrieval[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 3083-3092.
[12]Hoe J T,Ng K W,Zhang Tianyu,et al. One loss for all: deep hashing with a single cosine similarity based learning objective[C]// Advances in Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2021: 24286-24298.
[13]Jang Y K,Gu G,Ko B,et al. Deep hash distillation for image retrieval[C]// Proc of the 17th European Conference on Computer Vision. Cham: Springer,2022: 354-371.
[14]張志升,曲懷敬,徐佳,等. 稀疏差分網(wǎng)絡(luò)和多監(jiān)督哈希用于高效圖像檢索[J]. 計算機應(yīng)用研究,2022,39(7): 2217-2223.(Zhang Zhisheng,Qu Huaijing,Xu Jia,et al. Sparse differential network and multi-supervised hashing for efficient image retrieval[J]. Application Research of Computers,2022,39(7): 2217-2223.)
[15]Lai Hanjiang,Yan Pan,Shu Xiangbo,et al. Instance-aware hashing for multi-label image retrieval[J]. IEEE Trans on Image Proces-sing,2016,25(6): 2469-2479.
[16]Zhang Zheng,Zou Qin,Lin Yuewei,et al. Improved deep hashing with soft pairwise similarity for multi-label image retrieval[J]. IEEE Trans on Multimedia,2019,22(2): 540-553.
[17]Song Ge,Tan Xiaoyang. Deep code operation network for multi-label image retrieval[J]. Computer Vision and Image Understanding,2020,193: 102916.
[18]Dai Yong,Song Weiwei,Li Yi,et al. Feature disentangling and reciprocal learning with label-guided similarity for multi-label image retrieval[J]. Neurocomputing,2022,511: 353-365.
[19]Ma Cheng,Lu Jiwen,Zhou Jie. Rank-consistency deep hashing for scalable multi-label image search[J]. IEEE Trans on Multimedia,2020,23: 3943-3956.
[20]Shen Xiaobo,Dong Guohua,Zheng Yuhui,et al. Deep co-image-label hashing for multi-label image retrieval[J]. IEEE Trans on Multimedia,2021,24: 1116-1126.
[21]Zhao Fang,Huang Yongzhen,Wang Liang,et al. Deep semantic ran-king based hashing for multi-label image retrieval[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 1556-1564.
[22]Chen Gang,Cheng Xiang,Su Sen,et al. Multiple-instance ranking based deep hashing for multi-label image retrieval[J]. Neurocomputing,2020,402: 89-99.
[23]Qin Qibing,Wei Zhiqiang,Huang Lei,et al. Deep top similarity ha-shing with class-wise loss for multi-label image retrieval[J]. Neurocomputing,2021,439: 302-315.
[24]Xie Yanzhao,Liu Yu,Wang Yangtao,et al. Label-attended hashing for multi-label image retrieval[C]// Proc of the 29th International Joint Conference on Artificial Intelligence. [S.l.]: International Joint Conferences on Artificial Intelligence Organization,2020: 955-962.
[25]Shen Yiming,F(xiàn)eng Yong,F(xiàn)ang Bin,et al. DSRPH: deep semantic-aware ranking preserving hashing for efficient multi-label image retrieval[J]. Information Sciences,2020,539: 145-156.
[26]Qin Qibing,Xian Lintao,Xie Kezhen,et al. Deep multi-similarity ha-shing with semantic-aware preservation for multi-label image retrieval[J]. Expert Systems with Applications,2022,205: 117674.
[27]Brown A,Xie Weidi,Kalogeiton V,et al. Smooth-AP: smoothing the path towards large-scale image retrieval[C]// Proc of the 16th European Conference on Computer Vision. Cham:
Springer,2020: 677-694.
[28]Krizhevsky A,Sutskever I,Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6): 84-90.
[29]林計文,劉華文,鄭忠龍. 面向圖像檢索的深度漢明嵌入哈希[J]. 模式識別與人工智能,2020,33(6): 542-550.(Lin Jiwen,Liu Huawen,Zheng Zhonglong. Deep Hamming embedding based ha-shing for image retrieval[J]. Pattern Recognition and Artificial Intelligence,2020,33(6): 542-550.)
[30]Xu Chengyin,Chai Zenghao,Xu Zhengzhuo,et al. HyP2 loss: beyond hypersphere metric space for multi-label image retrieval[C]// Proc of the 30th ACM International Conference on Multimedia. New York: ACM Press,2022: 3173-3184.
[31]Cui Can,Huo Hong,F(xiàn)ang Tao. Deep hashing with multi-central ran-king loss for multi-label image retrieval[J]. IEEE Signal Proces-sing Letters,2023,30: 135-139.
