深度掩膜布朗距離協方差小樣本分類方法
2024-08-17 00:00:00茍光磊朱東華李小菲韓巖奇
計算機應用研究 2024年7期

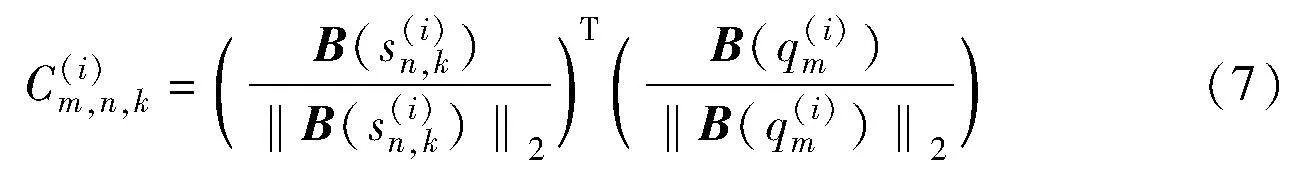


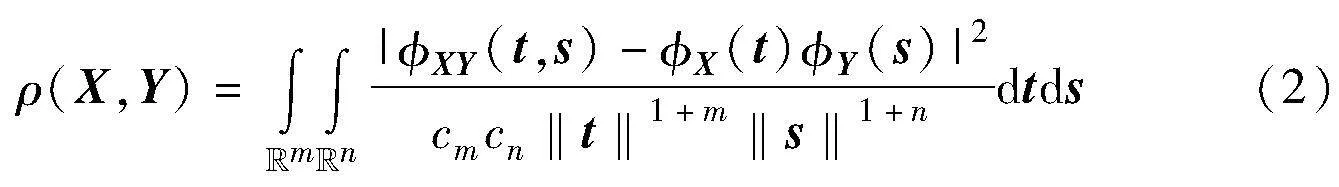

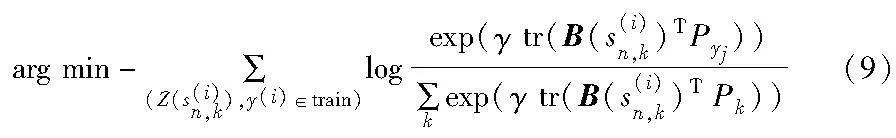


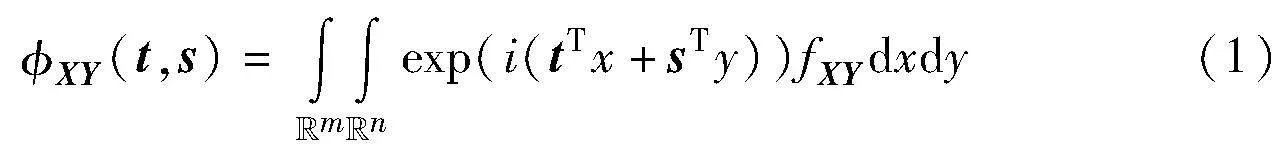



摘 要:針對小樣本學習中,布朗距離協方差通過改善特征嵌入提升分類精度,但未聚焦分類中樣本相關性特征的問題,提出了深度掩膜布朗距離協方差方法。該方法通過每對查詢集與支持集之間的高維語意關系,生成查詢引導掩膜,并將掩膜后的布朗距離協方差矩陣用作圖像特征表示。分別在5way-1shot和5way-5shot情形下,對CUB-200-211、Mini-ImageNet及Tiered-ImageNet數據集進行評估驗證,實驗表明,深度掩膜布朗距離協方差方法取得了更優的分類精度。
關鍵詞:小樣本學習;掩膜;布朗距離協方差;圖像識別
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2024)07-044-2229-06
doi: 10.19734/j.issn.1001-3695.2023.09.0514
Deep mask Brownian distance covariance for few-shot classification
Abstract: In few-shot learning, the Brownian distance covariance improves classification accuracy by enhancing feature embeddings, but it does not focus on the issue of sample-related features in classification. This paper proposed the deep masked Brownian distance covariance method that generated query-guided masks based on high-dimensional semantic relationships between each pair of query and support samples, and employed the masked Brownian distance covariance matrix as the image features. Under the 5way-1shot and 5way-5shot scenarios, it carried out validation and evaluation on CUB-200-211, Mini-ImageNet, and Tiered-ImageNet datasets. The experiments show that this method achieves superior classification accuracy.
Key words:few-shot learning; mask; Brownian distance covariance; image recognition
0 引言
人工智能技術飛速發展的當下,大數據的處理與運用正逐步成為衡量科技水平的一大重要標準。深度學習(deep lear-ning)作為人工智能技術中不可或缺的一環,被廣泛應用于自動駕駛、圖像識別、情感分析、文本辨識等領域,其借助海量數據支撐計算機學習,達到解決實際問題的目的,并取得了矚目的成果。這些優異的成績都要依托于蓬勃發展的算力資源,促進機器從大量的數據中學習知識信息,并應用于現實場景。然而并不是所有的問題都有與之適應的海量數據用作訓練。諸如,瀕危動物識別、軍事武器識別、罕見疾病識別等。由于其已知樣本稀少的缺點,傳統的深度學習方法在識別精度方面明顯捉襟見肘,所以小樣本學習(few-shot learning,FSL)[1,2]的概念應運而生。
小樣本學習的靈感源于實際生活,人類可以在只有少量學習數據或圖像的情況下習得相關知識,認識新事物。例如:資深的醫生能通過少數的癥狀來判斷患者是否患有某種罕見疾病。這不同于深度學習中圖像識別需要大量訓練代價,即對海量圖像數據訓練,且對訓練圖像的獲取及標注也有一定要求,從而耗費巨大的時間和人力成本。小樣本學習的出現,旨在通過極少量的樣本學習,高效地獲取知識,賦予機器快速學習的能力。
目前小樣本學習還面臨著諸多挑戰:由于只有極少量的樣本,提取的信息量有限;如何利用好暨有的樣本信息,避免過擬合,更加精準地進行識別顯得至關重要。當前較為有效的方法是基于遷移學習的方法,它包含基于度量的學習方法[3]和基于元學習的方法。遷移學習方法將數據集劃分為訓練集(training set)、支持集(support set)和查詢集(query set)三個部分。度量學習方法中,通常用歐氏距離或余弦距離衡量支持集和查詢集之間的相似性,以識別查詢集樣本。而元學習方法(meta-learning),亦稱學會學習(learning to learn),主要通過大量的先驗任務學習元知識,繼而指導模型在后續新的小樣本任務中更快地學習。兩者都采用了episodic training的訓練模式,將數據集細分為多個小的子任務進行訓練。
小樣本學習經過近些年的研究與發展,可應對不同的使用場景,萌生了諸多優秀的方法。Snell等人[4]提出了原型網絡(prototypical network,ProtoNet),通過將分類問題看作是尋找語義上的類中心點的方式,不斷擬合類別中心,提煉類原型,用作分類。隨后,Sung等人[5]提出了關系網絡(relation network,RN),利用4層的卷積神經網絡提取低維嵌入,并使用ReLU函數進行相似性度量。在此基礎上,Zhang等人[6]提出了深度比較網絡(deep comparison network,DCN),將關系模塊與嵌入學習模塊細分成多個子模塊,并一一對應建立聯系,各自打分并計算匹配度。Yu等人[7]提出了多任務聚類元學習方法,根據任務生成多個簇,每個簇具有相似的任務,模型參數由各簇的適應參數線性表示。Wang等人[8]提出了任務感知特征嵌入網絡(TAFE-Net),首次將標簽嵌入納入到網絡架構中來對圖像特征的權重進行預測,使得語義信息與圖像信息融合。Tian等人[9]提出了基于優秀嵌入的方法(good embedding),探討了特征嵌入表示在小樣本學習任務中的重要性,與傳統元學習方法比較,僅在微調(fine-tunning)階段就能達到與之相似的效果,為小樣本學習打開了一扇新的大門。Zhang等人[10]提出基于推土距離的小樣本學習方法(differentiable earth mover’s distance,EMD),借助差分EMD用于圖像區域間的最佳匹配運算,借助大量的計算獲得了不俗的性能。
現有統計學方法,將圖像特征看作高維空間中的隨機向量,并以概率分布衡量圖像之間的相似程度。通常使用原型網絡(ProtoNet)對圖像表征,輔以歐幾里德距離或余弦距離進行度量學習。Li等人[11]提出了協方差度量網絡(covariance metric network,CovaMNet),利用協方差矩陣的二階統計信息衡量查詢集樣本與支持集樣本間分布的一致性。由于缺乏對圖像局部特征的考量,Li等人[12]又提出了深度最近鄰神經網絡(DN4),在網絡的末層使用局部描述代替圖像特征,為每個查詢樣本的局部特征計算相似性,加和后得到查詢樣本的相似性。Xie等人[13]提出深度布朗距離協方差方法(deep Brownian distance covariance,DeepBDC),在二階矩陣(covariance matrix)協同Kullback-Leiberler(KL)散度度量方法的基礎上,綜合考量邊緣分布(marginal distribution)和聯合分布(joint distribution)生成BDC矩陣用作圖像表征,并將成對圖像之間的BDC矩陣內積用作類間相似度的衡量指標,進行分類任務。
掩膜最早應用于CNN池化層中的最大池化,通過引入掩膜標記最大池化位置,從而記錄最大池化前的位置信息,以解決最大池化可能導致的信息丟失問題。另一個重要的模型Transformer中的自注意力機制,通過計算輸入序列中不同位置之間的相關性來獲得每個位置的表示。為了處理可變長度的序,也采用掩膜來屏蔽無效位置。例如,在機器翻譯任務中,可以使用掩碼將當前位置之后的位置屏蔽掉,以防止模型在生成目標序列時能夠“看到”未來的信息。目前,掩膜被廣泛應用于圖像分割、目標檢測、圖像生成等任務中。
盡管DeepBDC方法在傳統方法與統計學方法中脫穎而出,取得了不俗的效果,但在特征的著重點上仍存在著注意力不集中的問題,使得某些相近類的重要特征權重占比不明顯,忽略了一些能夠對小樣本圖像分類起到重要作用的樣本信息,使得布朗距離協方差在衡量圖像上存在短板。基于上述問題,本文的工作如下:提出一種深度掩膜布朗距離協方差方法,針對不同類別的圖像具有的特征差異化問題,在生成的布朗距離協方差矩陣中引入了掩膜的方法,指導查詢樣本與支持樣本進行相似性度量時,將注意力側重在更能凸顯出某類圖像的表征上,進而取得更為精準的分類。
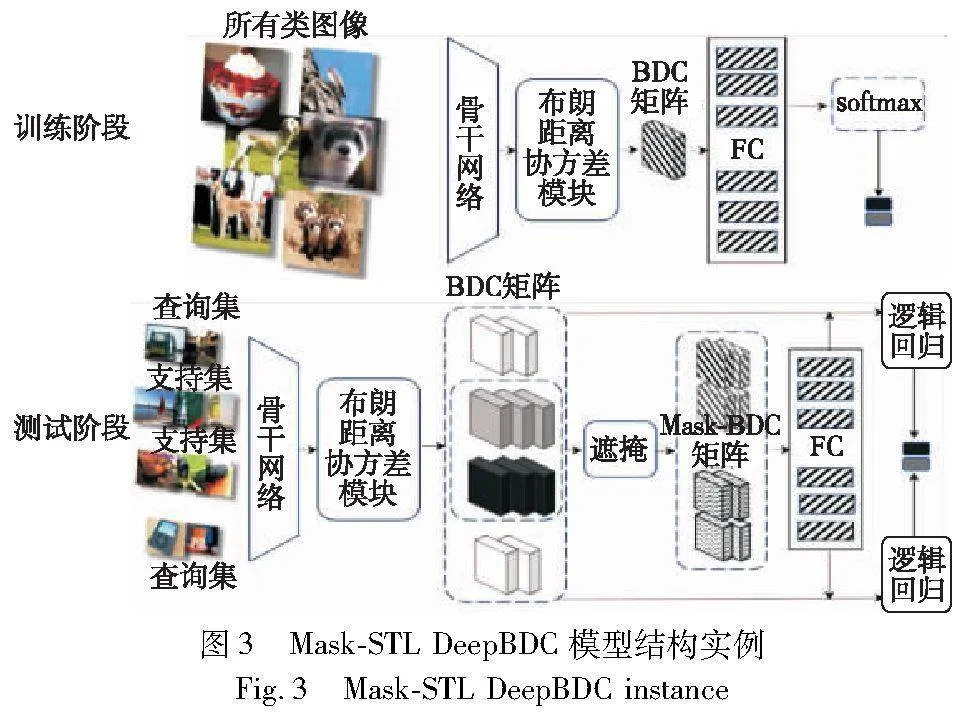
1 Deep Mask-BDC深度掩膜布朗距離協方差方法
1.1 布朗距離協方差
布朗距離協方差矩陣(BDC)[14]主要用于處理特征函數。設存在m維隨機向量X及n維隨機向量Y,使得X∈Euclid ExtraaBpm,Y∈Euclid ExtraaBpn,X與Y的概率分別定義為fX和fY,則聯合概率密度為fXY。此時,X和Y的聯合特征函數定義為
其中:i為虛單位;t和s為兩隨機向量。
令X、Y分別表示X和Y的特征函數,此時支持集或查詢集圖像的邊緣分布可寫為X(t)=XY(t,0)和Y(s)=XY(0,s)。當且僅當XY(t,s)=X(t)Y(s)時,獨立性成立。假設X和Y具有有限的一階矩,BDC度量定義為
其中:cm=π(1+m)/2/Γ((1+m)/2),Γ為伽馬函數;‖·‖表示歐氏距離。對于形如(x1,y1),…,(xk,yk)的k個x與y的觀測值集合,BDC度量一般可根據式(3)的經驗特征函數定義。
其中:a和b均為BDC矩陣A和B的上三角矩陣;ρ(X,Y)為衡量分類標準的BDC度量。
1.2 深度掩膜布朗距離協方差
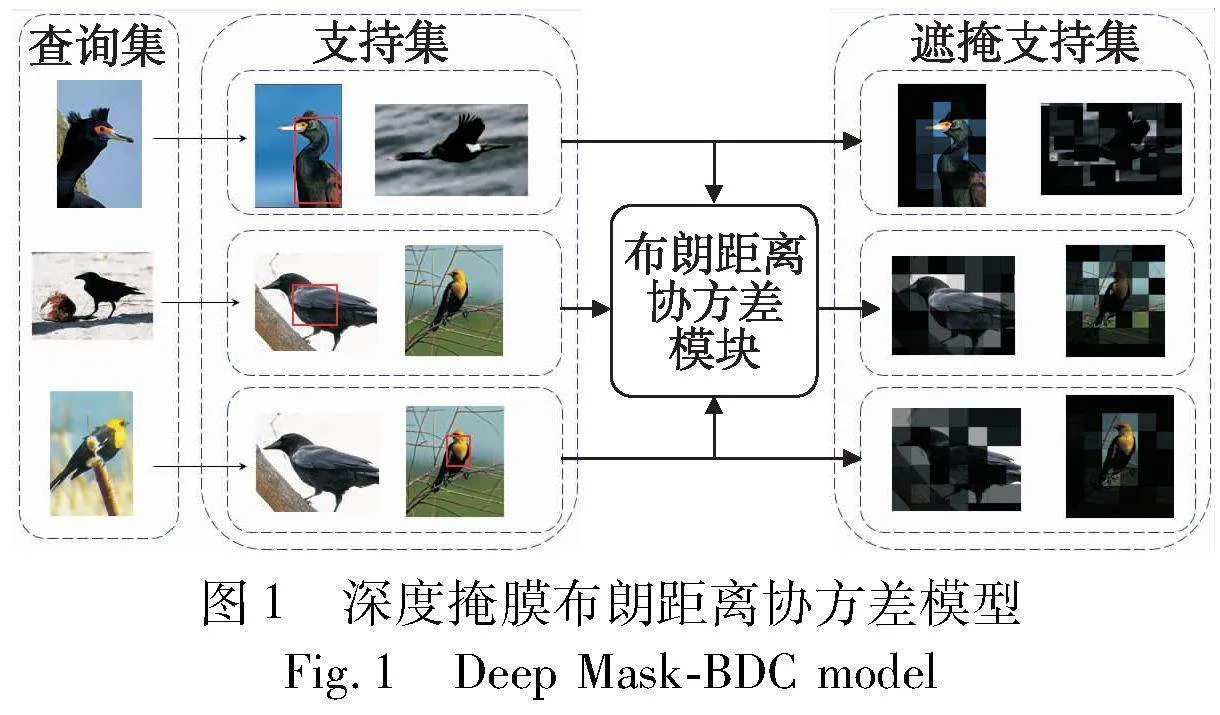
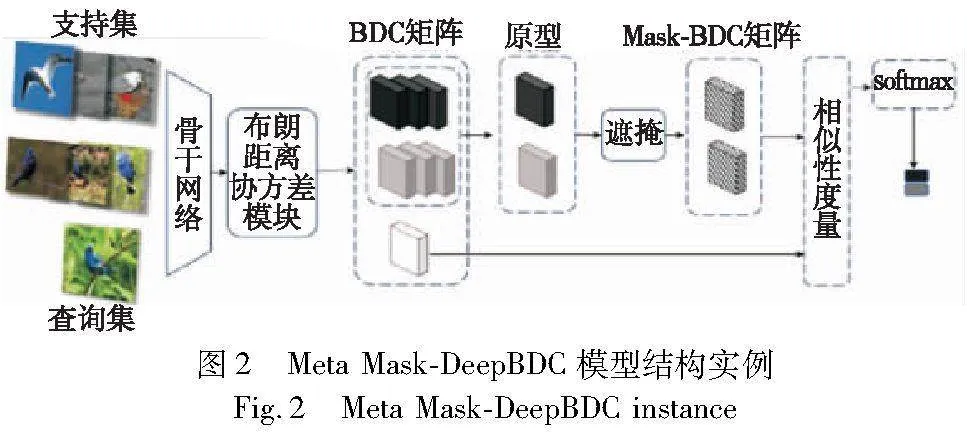
使用布朗距離協方差處理的圖像特征,雖然將聯合分布和邊緣分布進行了綜合考量,但未考慮成對支持樣本與查詢樣本間獨有的分布關系。對于每個分類任務采用統一的分布關系,這將導致大量類別差異明顯的圖像被正確分類,而差異較小的圖像分類存在難以分辨的情況。掩膜方法就是應用在成對圖像間進行區域像素信息標記的方法,可以通過掩膜將成對圖像間重要區域像素信息進行標記,解決差異化較小圖像間分類難以分辨的問題。因此本文提出一種深度掩膜布朗距離協方差方法Deep Mask-BDC,如圖1所示。
掩膜是對于同一支持樣本,通過成對查詢樣本和支持樣本間高維語義乘積關系矩陣,經多層感知機計算得到,并結合支持集布朗距離協方差矩陣進行相似性度量。以達到提升度量時各查詢樣本與支持樣本特征差異化的目的,即突出查詢樣本與當前支持樣本間更為明顯的特征,對樣本差異較小的圖像分類任務作出針對性的優化調整,并在元學習和簡單遷移學習情境下有著不同的實現方式。
其中:Sk為支持集圖像集合中一系列樣本。各類BDC原型矩陣與查詢集矩陣同時傳入掩膜模塊,并針對成對的支持集原型BDC矩陣和查詢集BDC矩陣采用余弦距離計算語義相關性。
基于到支持集原型類之間距離上的softmax,采用如下損失函數,其中γ為可學習尺度參數從海量的元訓練集中抽取類別數遠大于N的任務來訓練學習器,之后持續從元測試集中抽取任務來進行評估。
基于簡單遷移學習(simple transfer learning, STL)框架亦可增添掩膜操作提升分類精度。原始的STL方法通過在大量數據集上訓練深度網絡,形成已有的知識體系,并生成嵌入模型,用于提取下游任務的特征。
將包含所有類的整個元訓練集用作訓練圖像分類任務的基準,形成嵌入模型。使用預測值和真實值之間的交叉熵損失來訓練學習器。
算法1為深度掩膜布朗距離協方差方法的偽代碼實現過程,輸入為成對的支持樣本與查詢樣本,輸出為相似性得分結果。內部定義了三個模塊,分別為提取特征ResNet12的骨干網絡,計算布朗距離協方差的BDC模塊,以及通過高維語義遮掩支持樣本特征的mask模塊。
算法1 深度掩膜布朗距離協方差
2 實驗與分析
本文采用配置為 Intel Xeon CPU E5-2680 v4 @ 2.40 GHz,30 GB RAM,NVIDIA RTX3090 24 GB,Ubuntu 20.04系統的計算機進行實驗。
2.1 數據集
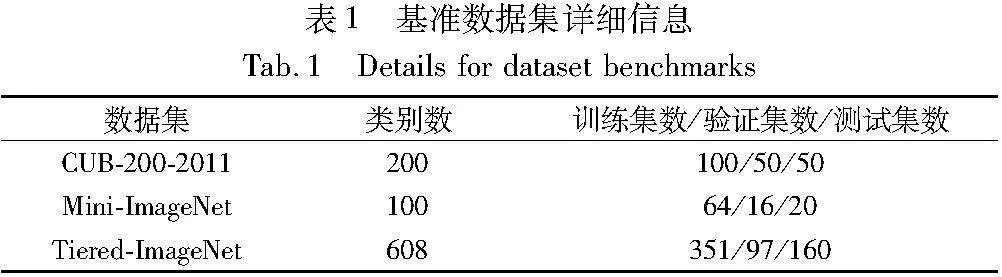
本文主要對Mini-ImageNet、Tiered-ImageNet及CUB-200-2011三個數據集進行對比實驗。前兩者為圖像分類任務中的常用數據集,后者為細粒度圖像分類中的數據集。其中Mini-ImageNet和Tiered-ImageNet均從ImageNet 1K(ILSVRC2012)中劃分得來。具體數據集細分如表1所示。
Mini-ImageNet有100個類別,每個類別下均有600張圖像,使用Vinyals等人[19]的數據集劃分方式,且沒有將圖像大小重新設置為84×84,而是保留原始圖像尺寸作為模型輸入。
Tiered-ImageNet較之Mini-ImageNet最大的不同在于,其包含了ImageNet 1K(ILSVRC2012)中更多的類別和更多的類內圖像。具體有34個父類,細分出608個子類,每個子類均有779 165張圖像,使得Tiered-ImageNet的類別層次結構更加優異,覆蓋面更廣泛。同時采用默認的84×84圖像大小。
CUB-200-2011為鳥類細粒度數據集,其圖像尺寸設為224×224,包含100個類,每類均有1 000張圖像。
一般數據集與細粒度數據集采取不同的圖像尺寸以適用不同層次的特征提取網絡,與既有方法保持一致,便于對比實驗結果。Mini-ImageNet及Tiered-ImageNet采用ResNet-12作為骨干網絡,而細粒度數據集CUB-200-2011則使用較深層次的ResNet-18。
2.2 實驗結果及分析
Meta Mask-DeepBDC模型采用預訓練的模型初始化權重參數,以原型網絡作為主要框架,與一般的元學習模型一致,沿用情景訓練的模式。每一輪episodic訓練都是5-way 1-shot或5-way 5-shot的小樣本分類任務。
特別指出的是,在計算布朗距離協方差矩陣時,各通道上的矩陣均為平方級矩陣,故采用1×1的卷積層降維,減少計算量。同時在掩膜模塊進行操作時,生成掩膜所使用的多層感知機要根據每類樣本中已知樣本數目的不同,靈活設置卷積參數,減少推演的計算量。度量方式上,5-way 1-shot采用內積方式度量,5-way 5-shot則采用更加普遍的歐氏距離度量。
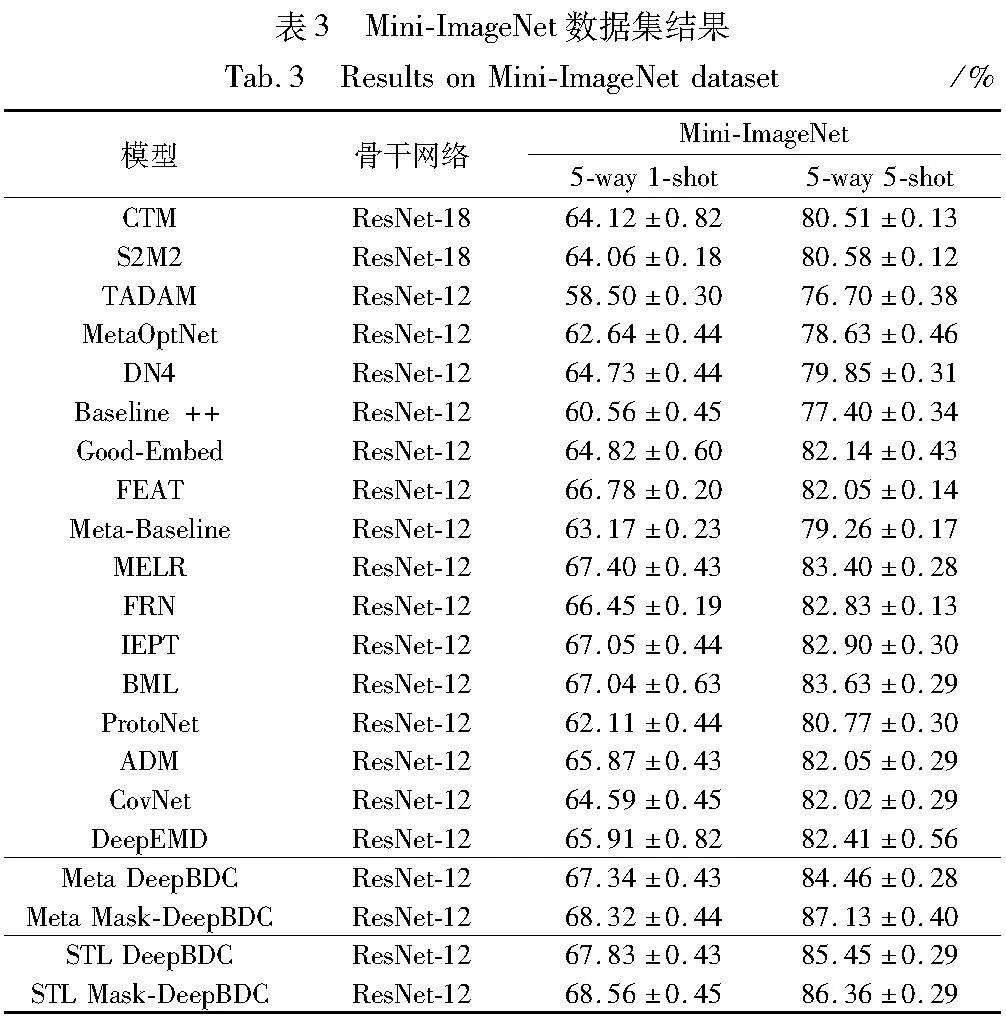
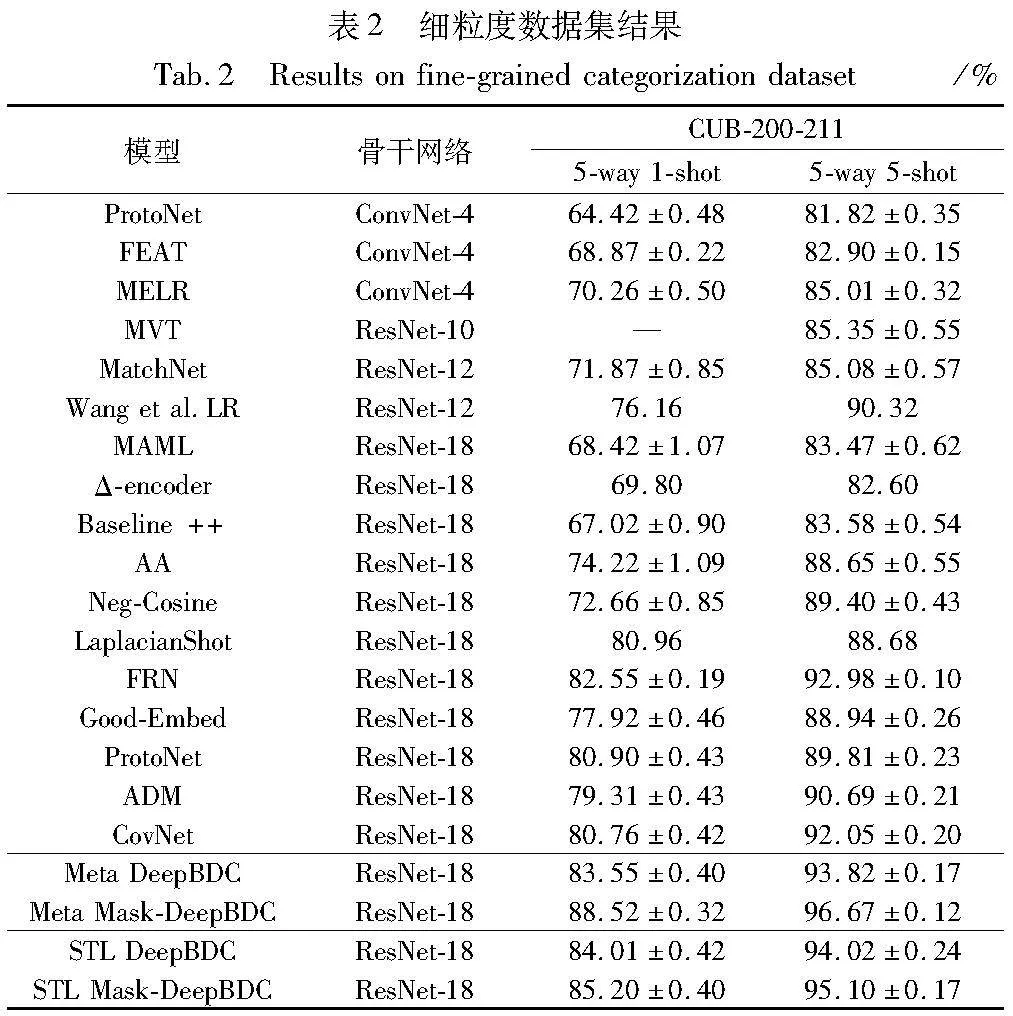
Mask-DeepBDC方法在元學習與簡單遷移學習上應用,并與當前較為經典及先進的元學習與度量學習方法進行了比較,其中CUB-200-2011數據集包括ProtoNet[4]、FEAT[16]、MELR[17]、MVT[18]、MatchNet[19]、LR[20]、MAML[21]、Δ-encoder[22]、Baseline++[23]、AA[24]、Neg-Cosine[25]、Laplacian-Shot[26]、FRN[27]、Good-Embed[9]、ADM[28]、CovNet[29]、Meta DeepBDC[13]、STL DeepBDC[13]。Mini-ImageNet和Tiered-ImageNet數據集包括CTM[30]、S2M2[31]、TADAM[32]、MetaOptNet[33]、DN4[12]、Baseline++、MELR、FRN、IEPT[35]、BML[36]、ProtoNet、ADM[28]、CovNet、DeepEMD[10]、Meta DeepBDC、STL DeepBDC。
從表2的CUB-200-211數據集實驗結果中可以發現,本文所提的基于掩膜的布朗距離協方差矩陣方法無論在5-way 1-shot還是5-way 5-shot情況下,較所有基準方法均有明顯提升,其中5-way 1-shot提升最為明顯。相同骨干網絡下,Meta Mask-DeepBDC方法與ProtoNet相比,準確率分別提升了7.62%和6.86%,與基準Meta DeepBDC相比準確率分別提升了4.97%和2.85%。Mask STL-DeepBDC方法與Good-Embed相比,準確率分別提高了7.28%和6.16%,與基準STL DeepBDC相比準確率分別提升了1.19%和1.08%。
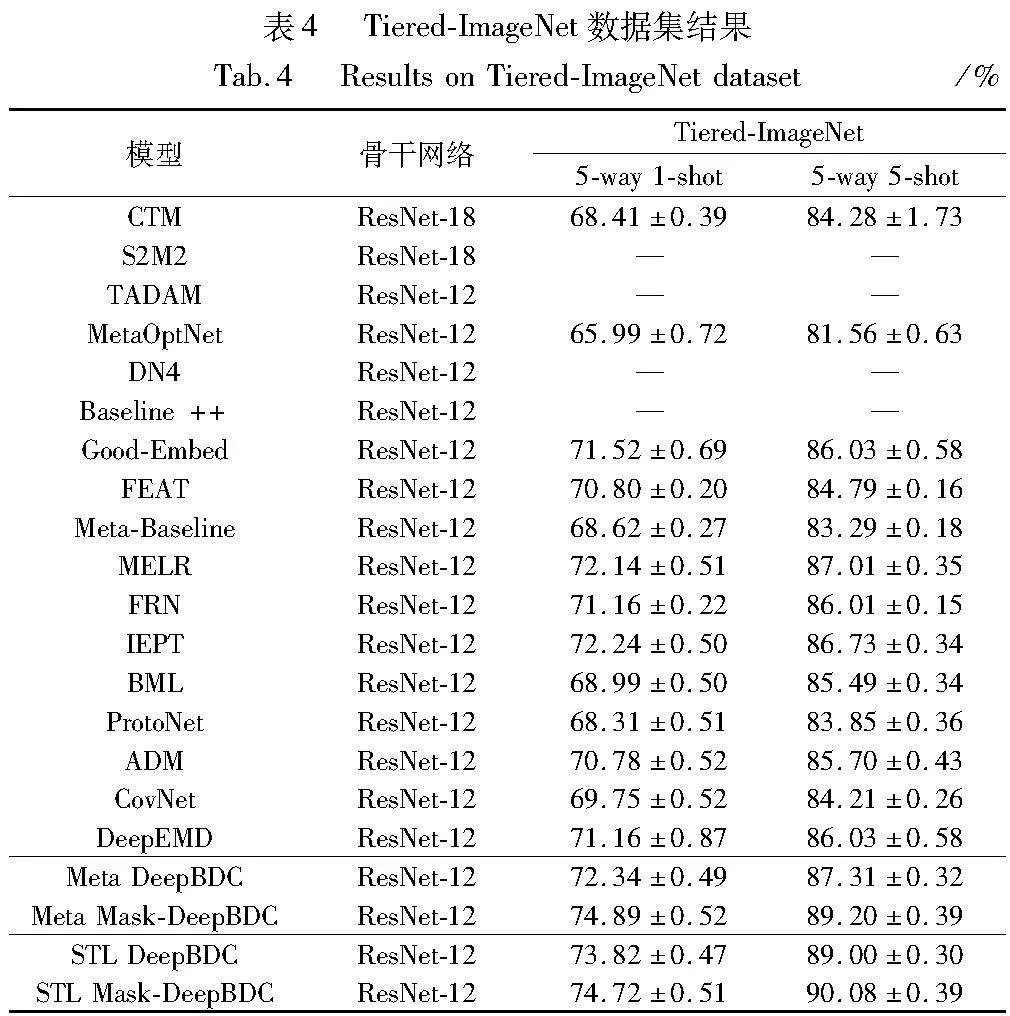
表3和4分別為Mini-ImageNet和Tiered-ImageNet數據集上的結果。其中Meta Mask-DeepBDC方法在Mini-ImageNet數據集下,Meta Mask-DeepBDC方法與ProtoNet相比,準確率分別提升了6.21%和6.36%,與基準Meta DeepBDC相比準確率分別提升了0.98%和2.67%。Tiered-ImageNet數據集下與ProtoNet相比,準確率分別提升了6.58%和5.35%,與基準Meta DeepBDC相比準確率分別提升了2.55%和1.89%。
STL Mask-DeepBDC方法在Mini-ImageNet數據集下與Good-Embed相比,準確率分別提升了3.74%和4.22%,與基準STL DeepBDC相比準確率分別提升了0.73%和0.91%。STL Mask-DeepBDC方法在Tiered-ImageNet數據集下與Good-Embed相比,準確率分別提升了3.2%和4.05%,與基準STL DeepBDC相比準確率分別提升了0.9%和1.08%。
圖4、5分別為本文方法在5-way 1-shot與5-way 5-shot上與原方法對比的精確度分析圖。通過分析可知,本文算法可在布朗距離協方差矩陣充分利用圖像的邊緣分布與聯合分布進行表征的前提下,根據查詢集樣本與支持集樣本間的語意相關性對支持集樣本附加掩膜,引導算法進一步明確圖像突出特征,使得分類結果更加精確。因此,本文所提基于掩膜的深度布朗距離協方差模型擁有更高的識別精度。
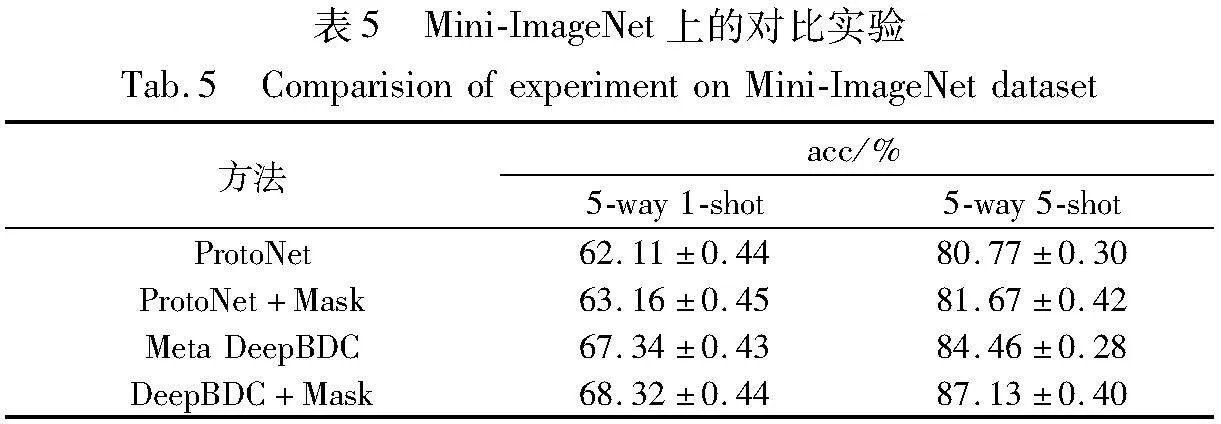
為了說明深度掩膜布朗距離協方差方法對成對小樣本分類的精度提升,針對Mini-ImageNet數據集進行了相應的對比實驗,具體結果如表5所示。
本文共進行了四組實驗,骨干網絡均為ResNet-12以達到相同層次的網絡特征提取。由實驗可知,ProtoNet初始在5-way 1-shot和5-way 5-shots上的精度分別為62.11%及80.77%,在引入Mask掩膜操作后,兩者均有1%左右的提升。
布朗距離協方差方法是在特征提取后,通過全連接提取原型(Proto)進而分類的方法。在單獨實驗過程中,精度在5-way 1-shot和5-way 5-shots上分別為67.34%與84.46%,較ProtoNet有明顯提升。在引入Mask掩膜后,精度分別又提升了0.98%和2.71%。說明掩膜布朗距離協方差能夠有效地使模型對小樣本分類作出優化。
如圖6所示,給出了本文方法在CUB-200-211數據集中的實例結果。針對某episode下,擁有5類樣本的查詢集和2類樣本的支持集在進行分類時,支持集1中的樣本由于與查詢集中其余樣本具有明顯的鳥類外形、顏色、鳥冠等差異,所以無論是布朗距離協方差還是深度掩膜布朗距離協方差都給出了正確的預測結果。支持集2中的黑色鳥類與查詢集中其余部YNkXxWc9aD8yCdDsUtuSVffjiKZG1tt2EBNRU6yKias=分樣本存在相似性高的問題,此時布朗距離協方差方法未能作出正確預測,而深度掩膜布朗距離協方差方法則借助掩膜將成對間樣本的特征突出化,作出了正確的預測。
2.3 消融研究及性能分析
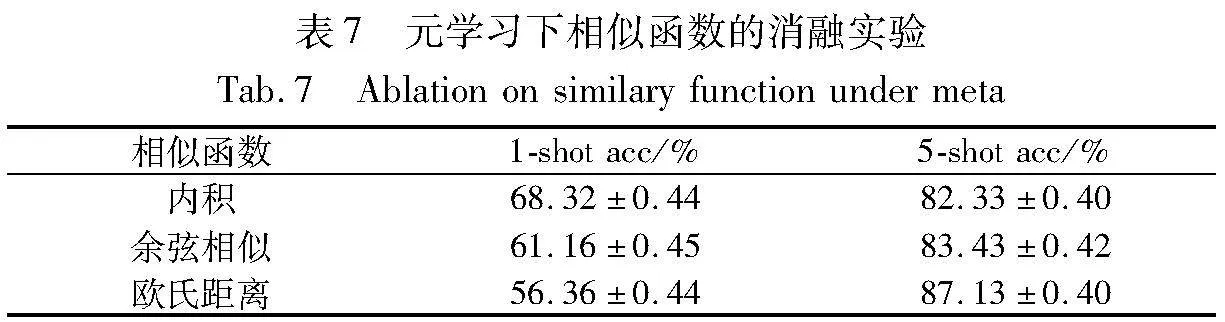
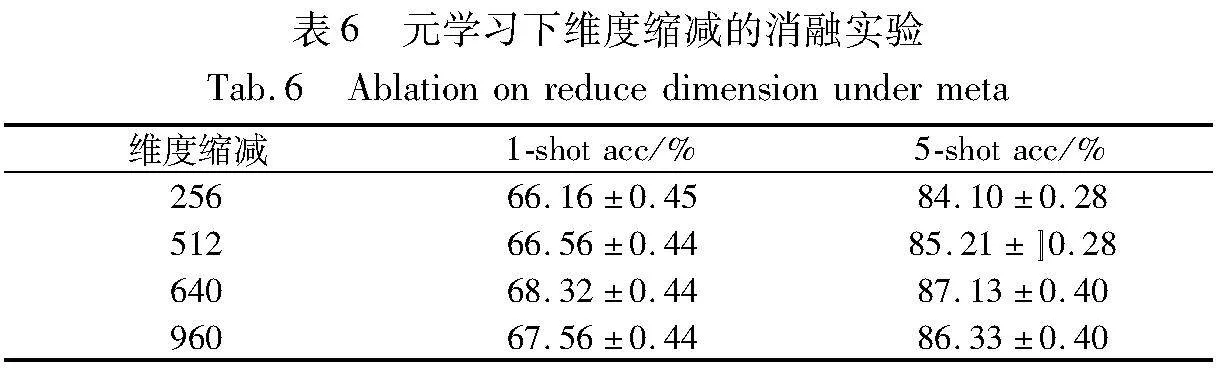
針對實驗的其他參數進行了相應的消融實驗,同樣是在ResNet-12骨干網絡下以Mini-ImageNet數據集作為參照,分別在元學習和簡單遷移學習下,對比了不同維度縮減(reduce_dim)、相似性度量及分類器對實驗結果的影響。
如表6和7所示,元學習情況下,模型的維度縮減在640時達到最佳的分類精度且相對穩定,采用的相似性度量函數在1-shot和5-shot情況下略有不同,分別在內積和歐氏距離的方法下取得最優精度。
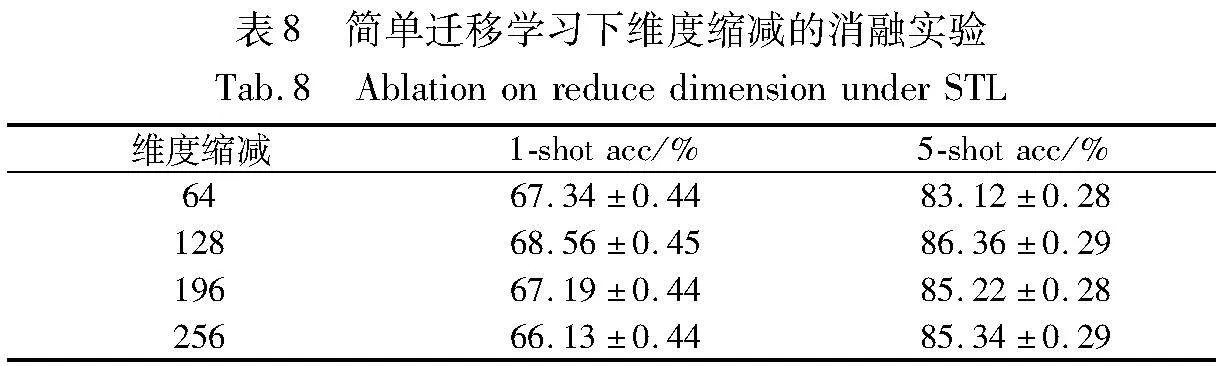
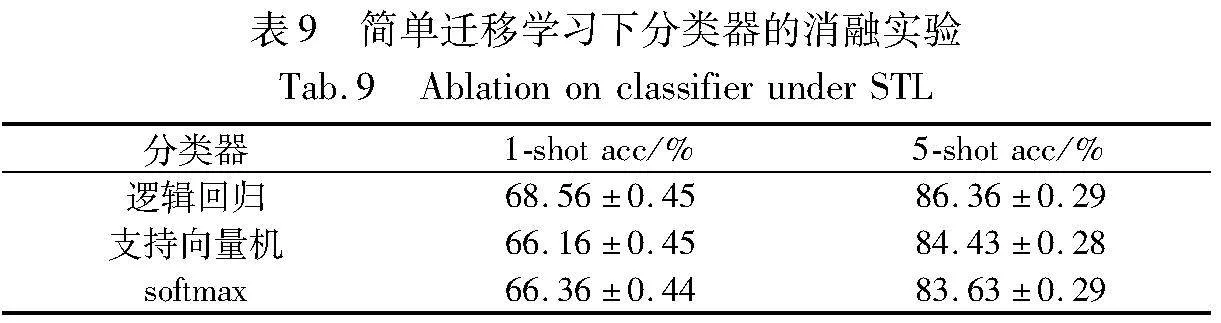
如表8和9所示,簡單遷移學習下,維度縮減在128時達到最佳分類精度且相對穩定,邏輯回歸在幾種分類中脫穎而出,取得了最優的分類精度。
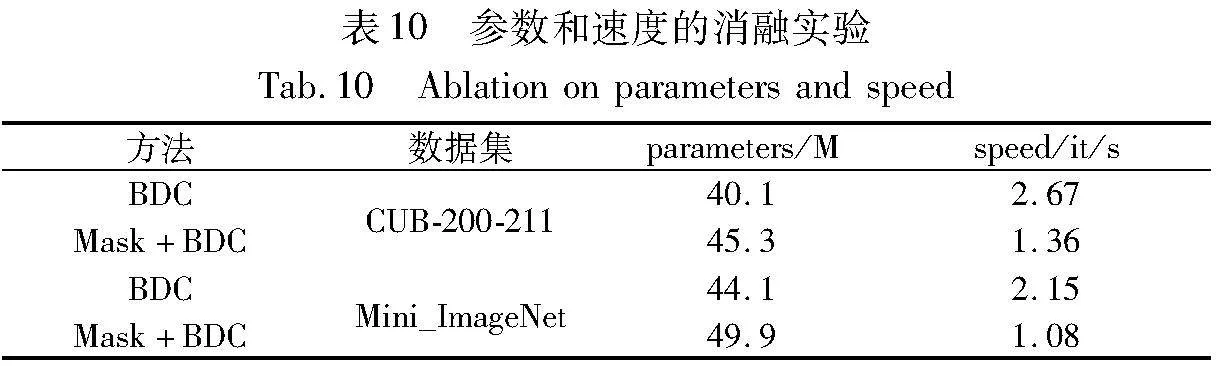
布朗距離協方差在計算時會消耗一定的時間成本,而Mask掩膜操作是成對的支持集與查詢集之間的關聯運算,也會加重運算的成本,提升復雜度。
如表10所示,分別在CUB-200-211和Mini-ImageNet兩個數據集上進行參數指標統計。結果顯示,掩膜布朗距離協方差運算會比單一方法的運算更加耗時,網絡參數量提升并不明顯。
3 結束語
本文提出了一種深度掩膜布朗距離協方差(Deep Mask-BDC)小樣本分類方法。通過成對查詢集樣本與支持集樣本間的語意相關性,協同一個帶有單隱藏層的多層感知機計算查詢掩膜,通過豐富布朗距離協方差矩陣下成對間圖像特征的重點區域信息,解決小樣本圖像分類任務中部分圖像類別相似性高、分布特征不明顯的問題,并在CUB-200-211、Mini-ImageNet和Tiered-ImageNet三個常見數據集上取得了很好的實驗效果。
實驗結果還表明本文方法在支持集樣本數量更低或細粒度圖像下,產生了更優異的分類精度,因此在未來的小樣本研究中,可拓展到細粒度圖像領域中或更少的1-shot小樣本分類任務中。
此外,本文方法尚存在以下不足之處:a)對于掩膜的計算是通過每一個成對查詢樣本和支持樣本得來的,在提升計算效率上還有改進的空間;b)實驗中,5way-1shot精確度提升幅度明顯高于5way-5shot,且在細粒度數據集CUB-200-211上提升更為明顯,說明本文方法在普適性上有待加強;c)簡單遷移學習的方法實例中,測試驗證階段采用邏輯回歸分類器,使得分類時所使用的掩膜支持樣本必須契合當前查詢樣本,因而存在計算成本過高的問題。
參考文獻:
[1]趙凱琳,靳小龍,王元卓. 小樣本學習研究綜述[J]. 軟件學報,2021,32(2): 349-369.(Zhao Kailin,Jin Xiaolong,Wang Yuanzhuo. Survey on few-shot learning[J]. Journal of Software,2021,32(2): 349-369.)
[2]張玲玲,陳一葦,吳文俊,等.基于對比約束的可解釋小樣本學習[J].計算機研究與發展,2021,58(12): 2573-2584.(Zhang Ling-ling,Chen Yiwei,Wu Wenjun,et al. Interpretable few-shot learning with contrastive constraint[J]. Journal of Computer Research and Development,2021,58(12): 2573-2584.)
[3]汪航,田晟兆,唐青,等.基于多尺度標簽傳播的小樣本圖像分類[J].計算機研究與發展,2022,59(7): 1486-1495.(Wang Hang,Tian Shengzhao,Tang Qing,et al. Few-shot image classification based on multi-scale label propagation[J]. Journal of Computer Research and Development,2022,59(7):1486-1495.)
[4]Snell J,Swersky K,Zemel R. Prototypical networks for few-shot lear-ning[C]// Proc of the 31st International Conference on Neural Information Processing System. Red Hook,NY: Curran Associates Inc.,2017:4080-4090.
[5]Sung F,Yang Yongxin,Zhang Li,et al. Learning to compare: relation network for few-shot learning[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2018: 1199-1208.
[6]Zhang Xueting,Sung F,Qiang Yuting,et al. Deep comparison: relation columns for few-shot learning[EB/OL].(2018).https://arxiv.org/abs/1811.07100.
[7]Yu Mo,Guo Xiaoxiao,Yi Jinfeng,et al. Diverse few-shot text classification with multiple metrics[EB/OL].(2018).https://arxiv.org/abs/1805.07513.
[8]Wang Xin,Yu F,Wang R,et al. TAFE-Net: task-aware feature embeddings for low shot learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 1831-1840.
[9]Tian Yonglong,Wang Yue,Krishnan D,et al. Rethinking few-shot ima-ge classification: a good embedding is all you need?[C]//Proc of European Conference on Computer Vision. Cham:Springer,2020: 266-282.
[10]Zhang Chi,Cai Yujun,Lin Guosheng,et al. DeepEMD: few-shot ima-ge classification with differentiable earth mover’s distance and structured classifiers[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12203-12213.
[11]Li Wenbin,Xu Jingjin,Huo Jing,et al. Distribution consistency based covariance metric networks for few-shot learning[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence and the 31st Innovative Applications of Artificial Intelligence Conference and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence. 2019: 8642-8649.
[12]Li Wenbin,Wang Lei,Xu Jingjin,et al. Revisiting local descriptor based image-to-class measure for few-shot learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 7253-7260.
[13]Xie Jiangtao,Long Fei,Lyu Jiaming,et al. Joint distribution matters: deep Brownian distance covariance for few-shot classification[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway,NJ:IEEE Press,2022: 7962-7971.
[14]Székely G J,Rizzo M L. Brownian distance covariance[J]. The Annals of Applied Statistics,2009,3(4): 1236-1265.
[15]Guo Yurong,Du Ruoyi,Li Xiaoxu,et al. Learning calibrated class centers for few-shot classification by pair-wise similarity[J]. IEEE Trans on Image Processing,2022,31: 4543-4555.
[16]Ye Hanjia,Hu Hexiang,Zhan Dechuan,et al. Few-shot learning via embedding adaptation with set-to-set functions[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway,NJ: IEEE Press,2020: 8808-8817.
[17]Fei Nanyi,Lu Zhiwu,Xiang Tao,et al. MELR: meta-learning via modeling episode-level relationships for few-shot learning[C]//Proc of International Conference on Learning Representations. 2020.
[18]Park S J,Han S,Baek J W,et al. Meta variance transfer: learning to augment from the others[C]//Proc of the 37th International Confe-rence on Machine Learning. [S.l.]: MLR.org,2020: 7510-7520.
[19]Vinyals O,Blundell C,Lillicrap T,et al. Matching networks for one shot learning[C]// Proc of the 30th International on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc.,2016: 3631-3645.
[20]Wang Yikai,Xu Chengming,Liu Chen,et al. Instance credibility inference for few-shot learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2020: 12836-12845.
[21]Finn C,Abbeel P,Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proc of the 34th International Conference on Machine Learning. [S.l.]: MLR.org,2017: 1126-1135.
[22]Schwartz E,Karlinsky L,Shtok J,et al. Δ-encoder: an effective sample synthesis method for few-shot object recognition[C]// Proc of the 32nd International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc.,2018: 2850-2860.
[23]Chen Weiyu,Liu Yencheng,Kira Z,et al. A closer look at few-shot classification[EB/OL].(2019). https://arxiv.org/abs/1904.04232.
[24]Afrasiyabi A,Lalonde J F,Gagné C. Associative alignment for few-shot image classification[C]//Proc of European Conference on Computer Vision. Cham:Springer,2020: 18-35.
[25]Liu Bin,Cao Yue,Lin Yutong,et al. Negative margin matters: understanding margin in few-shot classification[C]//Proc of European Conference on Computer Vision. Cham: Springer,2020: 438-455.
[26]Masud Z I,Dolz J,Granger E,et al. Laplacian regularized few-shot learning[EB/OL].(2020). https://arxiv.org/abs/2006.15486.
[27]Wertheimer D,Tang Luming,Hariharan B. Few-shot classification with feature map reconstruction networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021: 8012-8021.
[28]Li Wenbin,Wang Lei,Huo Jing,et al. Asymmetric distribution mea-sure for few-shot learning[EB/OL].(2020).https://arxiv.org/abs/2002.00153.
[29]Wertheimer D,Hariharan B. Few-shot learning with localization in realistic settings[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 6558-6567.
[30]Li Hongyang,Eigen D,Dodge S,et al. Finding task-relevant features for few-shot learning by category traversal[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 1-10.
[31]Mangla P,Kumari N,Sinha A,et al. Charting the right manifold: manifold mixup for few-shot learning[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ:IEEE Press,2020: 2218-2227.
[32]Oreshkin B N,Rodríguez P,Lacoste A. TADAM:task dependent adaptive metric for improved few-shot learning[C]//Proc of the 32nd International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc.,2018:719-729.
[33]Lee K,Maji S,Ravichandran A,et al. Meta-learning with differentiable convex optimization[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 10657-10665.
[34]Chen Yinbo,Liu Zhuang,Xu Huijuan,et al. Meta-baseline: exploring simple meta-learning for few-shot learning[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2021: 9062-9071.
[35]Zhang Manli,Zhang Jianhong,Lu Zhiwu,et al. IEPT: instance-level and episode-level pretext tasks for few-shot learning[C]//Proc of International Conference on Learning Representations. 2020.
[36]Zhou Ziqi,Qiu Xi,Xie Jianan,et al. Binocular mutual learning for improving few-shot classification[C]//Proc of IEEE/CVF International Conference on Computer Vision. 2021:8402-841
