基于改進YOLOv5的安全帽檢測算法
2024-09-12 00:00:00韓錕棟張濤彭玻鐘亮吳勝波
現代電子技術 2024年5期
關鍵詞:人工智能







摘" 要: 為解決安全帽佩戴檢測中密集小目標和目標受到遮擋場景下容易產生誤檢和漏檢的問題,提出基于改進YOLOv5安全帽佩戴檢測算法。首先,在安全帽的特征信息提取過程中引入微尺度檢測層,以進一步融合多尺度特征,從而獲得更為豐富的特征信息;然后,將坐標注意力機制插入到所提出的改進特征融合網絡中,用于提取目標的位置信息,并通過實驗驗證了該方法的有效性;最后利用EIOU代替CIOU損失函數,加快收斂并改善回歸精度和安全帽目標檢測準確性。根據實驗結果可以看出,改進的 YOLOv5算法對安全帽的平均檢測準確率(mAP)為90.89%,比標準YOLOv5算法提升了2.25%,明顯減少了誤檢、漏檢情況,在面對密集小目標、目標被遮擋等復雜場景時,檢測性能得到了有效的提升。除此之外,將改進后的YOLOv5安全帽檢測算法部署到施工現場,可以展現出在密集小目標、目標被遮擋場景下更加優異的檢測性能,具有很大的應用價值。
關鍵詞: 人工智能; 目標檢測; YOLOv5; 特征融合; 注意力機制; 損失函數
中圖分類號: TN911.73?34; TP183; TP391.4" " " " " "文獻標識碼: A" " " " " " " 文章編號: 1004?373X(2024)05?0085?08
Safety helmet detection algorithm based on improved YOLOv5
HAN Kundong, ZHANG Tao, PENG Bo, ZHONG Liang, WU Shengbo
(School of Software, Xinjiang University, Urumqi 830000, China)
Abstract: In view of the 1 detection and missed detection in safety helmet wearing detection when the objects are small and dense or the objects are occluded, a safety helmet wearing detection algorithm based on improved YOLOv5 is proposed. In the process of extracting feature information of safety helmets, a micro?scale detection layer is introduced to further fuse multi?scale features and obtain richer feature information. The coordinate attention (CA) mechanism is inserted into the proposed improved feature fusion network, so as to extract the position information of the object, and the effectiveness of the method is verified in experiments. The EIOU (efficient?IoU) is used to replace the CIOU (complete intersection over union) loss function, which accelerates the convergence and improves the regression accuracy and the accuracy of the safety helmet object detection. According to the experimental results, it can be seen that the improved YOLOv5 algorithm has a mean average precision (mAP) of 90.89% for safety helmets, which is 2.25% higher than that of the standard YOLOv5 algorithm, which reduces 1 detection and missed detection significantly. In the scenes of facing dense small objects or occluded objects, the detection performance of the proposed method has been improved effectively. In addition, when the proposed algorithm is applied to the construction site, it shows more excellent detection performance when detecting dense small objects or occluded objects, so it has great application value.
Keywords: artificial intelligence; object detection; YOLOv5; feature fusion; attention mechanism; loss function
0" 引" 言
中國作為基礎建設大國,生產建筑業是中國經濟發展必不可少的推動力。建筑安全事故會對國家和個人造成巨大損失,在這些事故中絕大部分是因為施工人員未遵守安全行為準則造成的。目前監督施工人員佩戴安全帽的方式主要是人工監督,但人工監督存在雇傭人員成本高,監督人員因主觀意識對實時情況缺乏客觀性的判斷等弊端。為了保證工地現場的施工安全,必需采取智能化的技術方式,減少施工現場中施工人員未佩戴安全帽施工這一違規現象的發生[1?3]。近年來,深度學習技術逐漸成為學者們研究的熱門方向之一,使用深度學習算法代替人力進行安全帽佩戴的檢測更加高效。
傳統目標檢測[4?5]一般通過滑動窗口的方法選擇候選區域,然后用SIFT(Scale Invariant Feature Transform,尺度不變特征變換)[6]或者是HOG(Histogram of Oriented Gradient,方向梯度直方圖)等方法提取特征[7],最后使用支持向量機(SVM)[8]等分類器進行分類處理。這些方法在對復雜背景下的運動圖像進行目標檢測時往往存在著漏檢率較高的問題。與傳統目標檢測算法相比較,深度學習框架下的目標檢測算法展現出較強的魯棒性,其利用卷積神經網絡自動提取目標特征,以代替傳統人工提取模式。這種方法可以在復雜場景中取得良好的檢測效果。深度學習框架中的目標檢測算法可以劃分為單階段和兩階段。在第一階段,采用了單步目標檢測算法,而在第二階段,則引入了多步驟融合目標檢測算法,以達到更高效的檢測效果。目標檢測算法分兩個階段進行,先為檢測目標產生若干候選區域,再把從全部候選區域提取出的特征圖送入分類器對目標進行分類,通過目標損失函數進一步準確地獲得邊界框,從而獲得最終檢測結果[9]。多步操作獲得的準確性一般較高,但是也由于步驟太多而降低了檢測速度。單階段目標檢測算法采用端到端的方法,在輸入端直接對圖片信息進行特征提取操作并預測獲取目標對象在圖片上的位置及類別信息,最后將算法檢測結果進行輸出,采用該端到端檢測方式使單階段目標檢測算法檢測速率顯著提高。相對于兩階段目標檢測算法,將一階段檢測算法應用到工業領域中考慮到精確度高、速度快等特點,更具有實用性。
在頭盔檢測方面,Vishnu等將CNN應用于摩托車駕駛員頭盔佩戴檢測中,而該方法不能進行多個目標的檢測與跟蹤。文獻[10?12]在原來Faster R?CNN模型的基礎上,運用多尺寸輸入圖像進行訓練,同時將錨點框(anchor box)數量增至12個,來增強模型對不同尺度目標的魯棒性,提高了模型的分類準確率,但是實時檢測的精確度仍然不能滿足要求。林俊基于YOLO,方明等基于YOLOv2,施輝等基于YOLOv3,通過不同角度的改進、壓縮網絡結構、極大抑制算法改進和多尺度檢測等,不斷提高安全帽檢測準確性和泛化能力[13?15]。但是在小目標、目標遮擋、密集人群這些復雜場景下,檢測結果并不是很理想[16]。
針對基于YOLOv5[17]的安全帽目標檢測算法存在的密集小目標、目標被遮擋場景下出現的誤檢、漏檢問題,本文提出一種基于改進YOLOv5的安全帽檢測算法。首先,在特征融合層添加微尺度檢測層,以提取更豐富的安全帽特征信息,增強對小目標的檢測能力;其次,在改進的特征融合層中嵌入坐標注意力機制(Coordinate Attention, CA)[18],提高模型的表達能力;最后,采用EIOU[19]損失函數替換CIOU[20](Complete Intersection over Union)損失函數解決了縱橫比的模糊定義,加速了收斂并且提高了回歸精度。經過在SHWD(Safety?Helmet?Wearing?Dataset)數據集中進行實驗,結果表明改進后的算法對安全帽檢測的平均精確度(mAP)比標準YOLOv5算法提升了2.25%,并且檢測精確度優于其他經典的目標檢測算法。
1" 算法介紹
1.1nbsp; YOLOv5算法原理
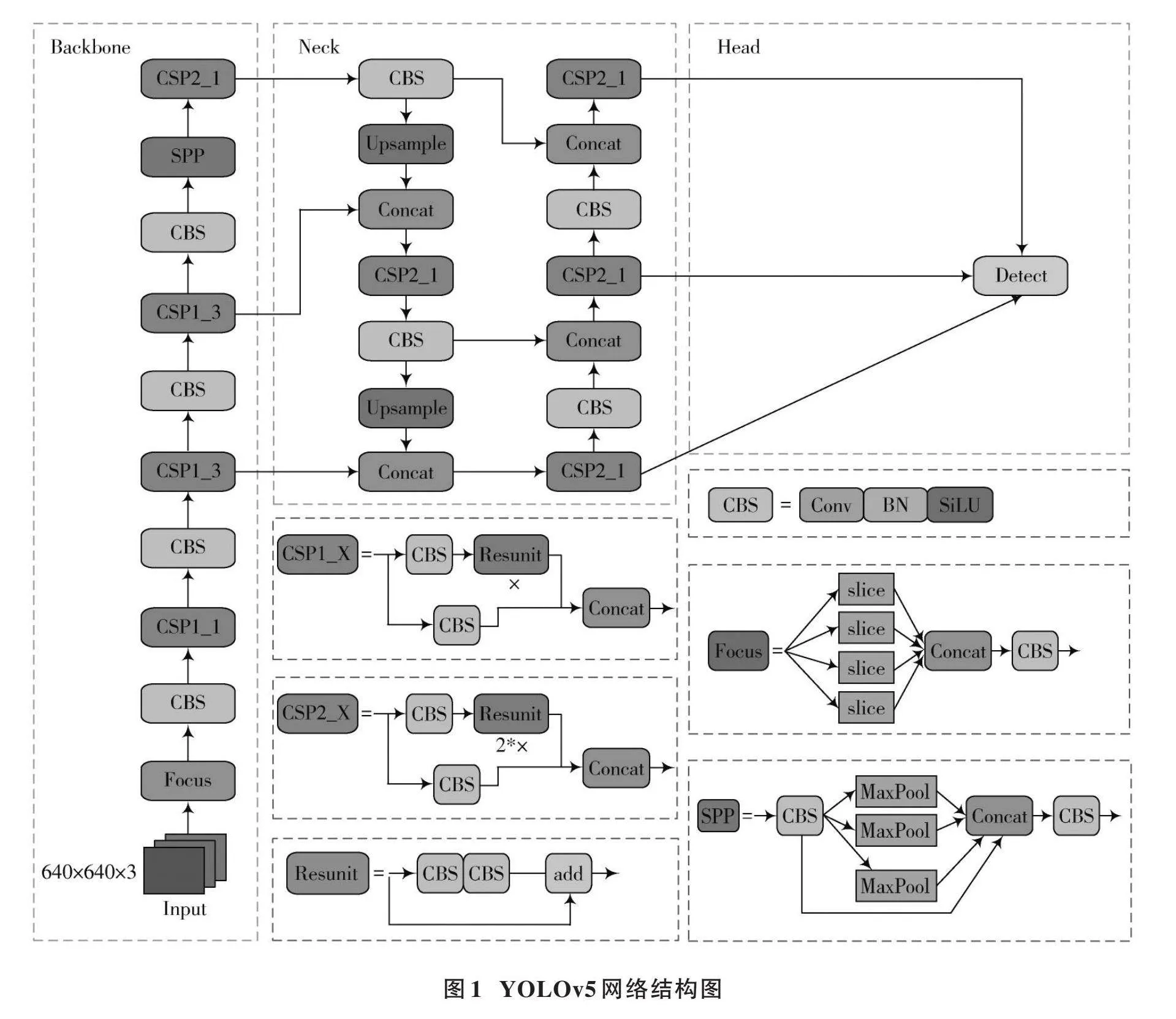
YOLOv5是一種一階段的目標檢測算法,采用單階段檢測器的思路,將整個檢測過程簡化為一個端到端的卷積神經網絡,具有檢測速度快、準確率高等優點。YOLOv5主要包含四種架構:YOLOv5?s、YOLOv5?m、YOLOv5?l和YOLOv5?x,該四種架構模型以深度來區分,參數數量依次增加。綜合考慮研究模型的參數規模與檢測效率,實驗基于YOLOv5?s架構對安全帽檢測的網絡進行改進。YOLOv5算法的網絡結構分為輸入端、主干網絡、頸部網絡和預測網絡。YOLOv5的整體結構如圖1所示。
1.1.1" 主干網絡
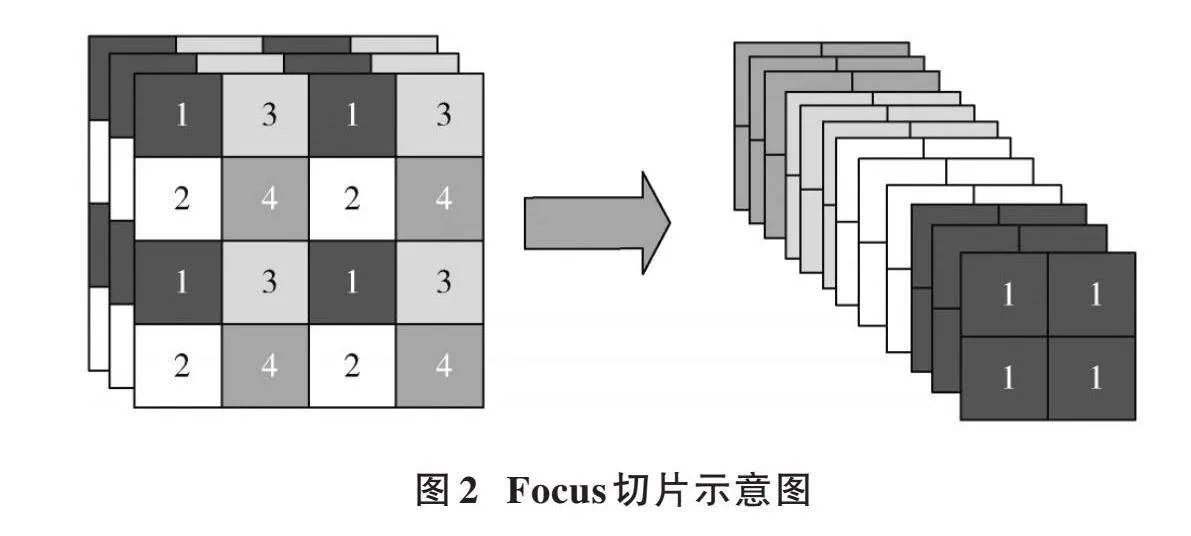
主干網絡主要由Focus、CBS和SPP[21]等模塊組成。如圖2所示,Focus模塊對輸入圖像進行切片,減少計算量并保證網絡層獲取更多特征信息,增大每個像素點的感受野,減少原始信息的丟失。CBS模塊由卷積、BN和SiLU組成,有利于加快模型推理速度。主干特征提取網絡采用SPP空間金字塔池化結構,通過池化核大小為5、9、13的卷積對輸入特征圖進行最大池化,避免圖像失真,節約計算量。
1.1.2" 頸部網絡
頸部網絡是由特征金字塔網絡(Feature Pyramid Network, FPN)[22]以及金字塔注意力網絡(Pyramid Attention Network, PAN)[23]組成,FPN結構從上到下傳遞了高級的語義特征;PAN結構通過向下傳遞低級空間特征,使得各種尺寸的特征圖均包含目標的語義信息和空間信息,從而實現了信息的全面覆蓋。通過對主干特征網絡提取的特征信息進行雙向融合,進一步提升了特征提取的能力,從而達到特征增強和上下層信息流融合的目的。
1.1.3" 預測網絡
預測網絡涵蓋了CIOU的損失和加權非極大值抑制,這兩個因素共同作用于網絡的穩定性和可靠性。本文提出了一種基于神經網絡模型的自適應預測算法,該系統能夠解決IOU(Intersection over Union)無法直接優化不重疊部分的問題,并在后期處理過程中保留最優框架,同時抑制這些冗余目標檢測,從而實現更高效的優化。
2" 算法改進
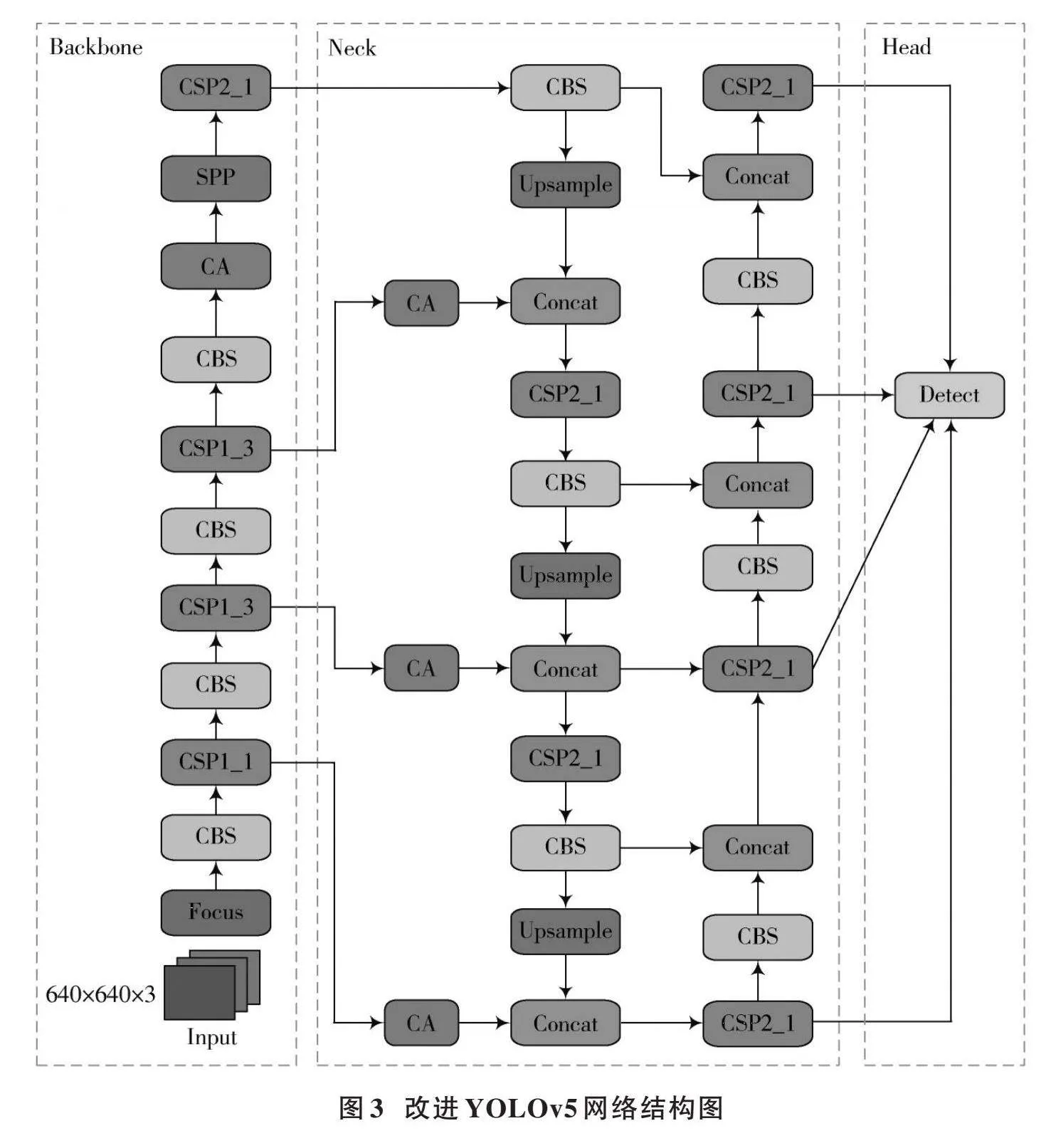
為解決安全帽佩戴圖像檢測中存在小目標、目標遮擋和密集人群而造成的漏檢問題,提高模型對安全帽佩戴檢測的性能以及魯棒性,本文對YOLOv5算法中的特征融合網絡、損失函數進行改進,并且加入注意力機制提高模型的表達能力。改進后的YOLOv5的整體結構如圖3所示。
2.1" 特征融合網絡的改進
YOLOv5模型結構設計了3個尺度特征檢測層,分別為降采樣得到的P3、P4、P5特征層,這三個特征層分別在主干特征提取網絡的中間部分、中下部分和底層部分,為特征提取提供了必要的支撐。針對輸入的640×640的圖像,進行了8倍、16倍和32倍的下采樣,得到了三個尺寸的特征圖。在安全帽檢測這項研究中,不同大小的目標可以在三個不同的尺度上被檢測。在網絡模型中低層特征圖分辨率更高,包含目標特征明顯,目標位置更準確;高層特征圖在多次卷積操作后,獲得了豐富的語義信息,但也會使特征圖分辨率降低。由于在實際環境獲取的圖像中安全帽尺寸大小不一,攝像頭與工人之間的距離較遠,導致待檢測的工人和安全帽的尺寸較小,從而造成漏檢和檢測效果差的情況。為緩解該現象,本文通過增加一個微尺度特征檢測層,低層特征圖與高層特征圖通過拼接的方式融合后進行檢測,可以有效提高檢測準確率。本文添加一個對輸入圖像進行4倍下采樣所得到的特征層P2,其對應的檢測頭具有感受野小、位置信息精確的優勢,能夠極大地提高小目標安全帽的檢測效果。利用4個有效特征層進行FPN層的構建,將自頂向下傳達高級語義特征和自底向上傳達低級空間特征進行雙向融合,極大地提升了檢測性能,適用于施工場景中圖像尺寸較小的安全帽檢測。
2.2" 添加注意力機制
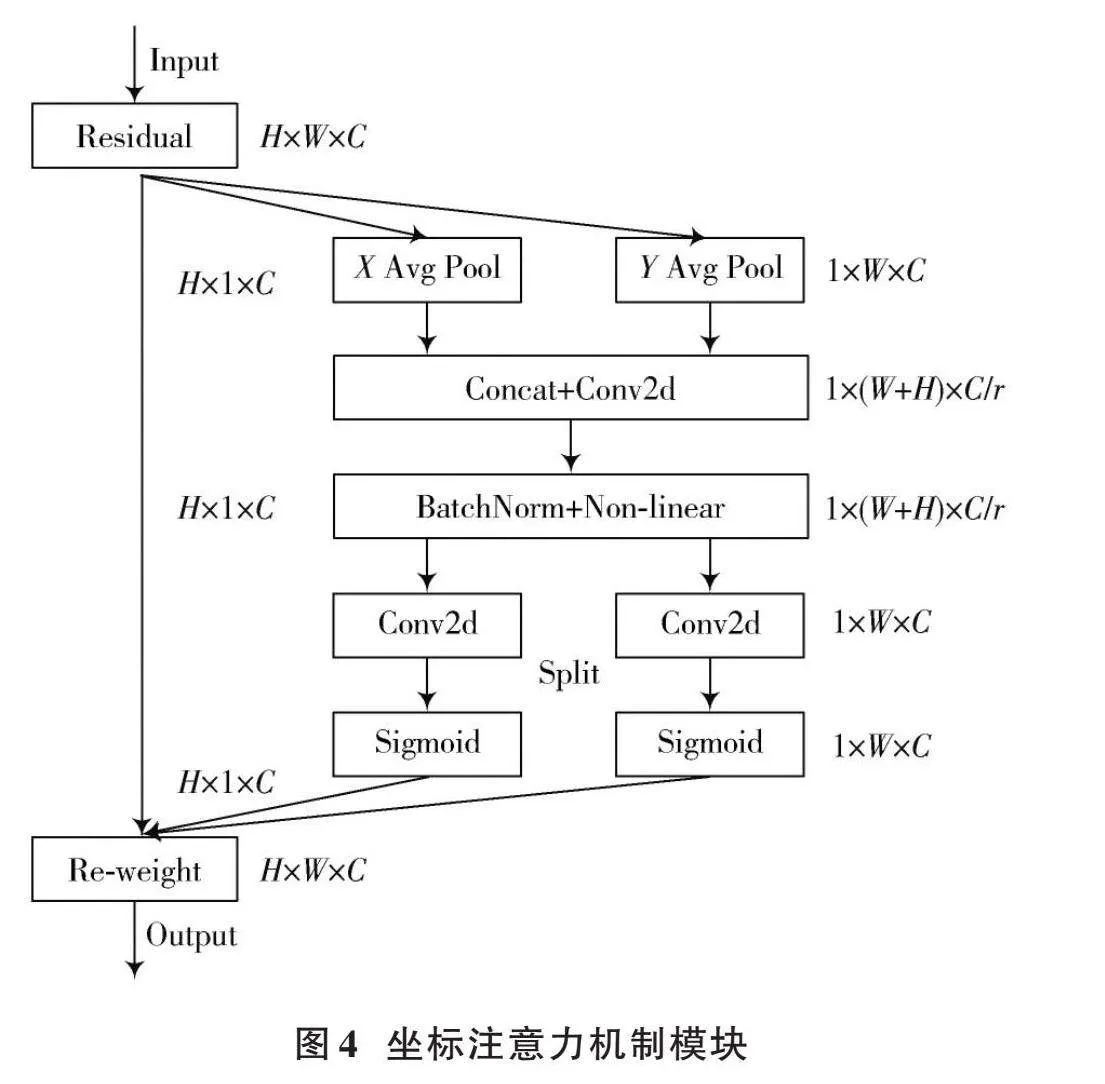
在深度神經網絡中,坐標注意力機制(CA)被廣泛運用于計算機視覺領域,以提高模型對特定內容和位置的關注度,從而優化模型性能。傳統的注意力機制采用池化的方式對通道進行處理,這種方法只考慮了通道之間的信息,而忽略了物體的位置信息,從而導致空間信息的損失。同時,由于圖像本身包含有大量冗余信息,因此無法有效地利用這些有用的特征。為了提高目標特征提取的準確性和抑制網絡中的無效特征,采用特征融合網絡中嵌入CA的策略,以達到更好的效果,并提出基于時空特性的圖像配準算法。CA采用了一種特征重新校準策略,將位置信息嵌入到通道注意力中,從而實現通道注意力機制和空間注意力機制的有機結合。根據圖像內容選擇不同類型的特征并加入其中。方向敏感的特征圖是由通道注意力機制在空間方向上形成的,而坐標敏感的特征圖則是由空間注意力機制在一個方向上保留位置信息所形成的。由于這兩個特性可以同時實現兩種不同性質的特征融合,所以能有效地解決傳統算法無法兼顧兩類特征之間互補性的問題。通過將安全帽的重要特征信息與次要特征信息相結合,以進一步提高模型對待檢測目標的檢測精度和準確性。由于該算法需要在整個訓練過程中自適應地更新權重值,導致計算量較大。因此,為了提高網絡的精度,引入了一種坐標注意力機制,該機制具有簡單靈活的特點,并且幾乎不會帶來任何額外的計算開銷。
圖4所呈現的是CA模塊的具體實現構造。
CA模塊的具體工作流程為:CA通過全局平均池化的方法將輸入特征圖分為寬度特征圖和高度特征圖兩個方向,來獲得圖像在此兩個方向的注意力,通過編碼精確位置信息來獲得高度特征圖和寬度特征圖。具體公式如下所示:
[zhc(h)=1W0≤ilt;Wxc(h,i)] (1)
[zwc(w)=1H0≤ilt;Hxc(j,w)] (2)
接著將獲得的寬度和高度兩個方向的特征圖拼接在一起,之后將它們送入共享的卷積核1×1卷積變換函數進行變換操作。
[" " " " " " " f=δ(F1([zh,zw]))]" (3)
生成的[f]是一張空間信息在水平和豎直方向上的中間特征圖,其中包含了一個非線性激活函數[δ],該函數被拆分為兩個獨立的張量,分別是[fh∈Rcr×h]和[fw∈Rcr×w],[r]以縮減率的形式呈現。
通過實驗驗證了算法可以得到較高準確率的圖像分割結果。采用[1×1]卷積函數進行特征轉換,將其轉化為張量,其通道數與輸入的[X]相同。
[gh=δFh(fh)] (4)
[gw=δFw(fw)]" (5)
通過以上計算后,本文會得到輸入特征圖中高度方向與寬度方向注意力權重的變化情況,從而為本文的研究工作提供了重要的參考依據。該方法獲得的局部結構能夠更好地描述原始紋理區域中的細節部分,并且可以有效減少冗余點。通過實驗驗證了算法可以得到較高準確率的圖像分割結果。最后將原始特征圖乘法加權計算得到具有注意力權重的特征圖,該特征圖表現出顯著的寬度與高度方向特征差異。
[yc(i,j)=xc(i,j)×ghc(i)×gwc(j)] (6)
本研究將CA嵌入到改進的特征融合網絡中,首先對于主干特征網絡生成的4個有效特征層,在進行FPN層構建之前,對4個有效的特征層嵌入CA模塊;其次,在進行FPN結構自頂向下傳達高級語義特征時,對每次上采樣后的結果嵌入CA模塊;最后,在進行PAN結構自底向上傳達低級空間特征時,對每次下采樣的結果嵌入CA模塊。
2.3" 改進YOLOv5算法的損失函數
YOLOv5算法采用預測框損失函數CIOU,但CIOU對預測框進行回歸時,其寬度和高度縱橫比一旦等于真實框寬度和高度時,預測框寬度和高度就不可能同時遞增或遞減,導致無法持續進行優化。
原始的CIOU損失函數如式(7)所示:
[LCIOU=1-IOU+ρ2(b,bgt)c2+αν] (7)
其中:
[α=ν(1-IOU)+ν] (8)
[ν=4π2arctanwgthgt-arctanwh2] (9)
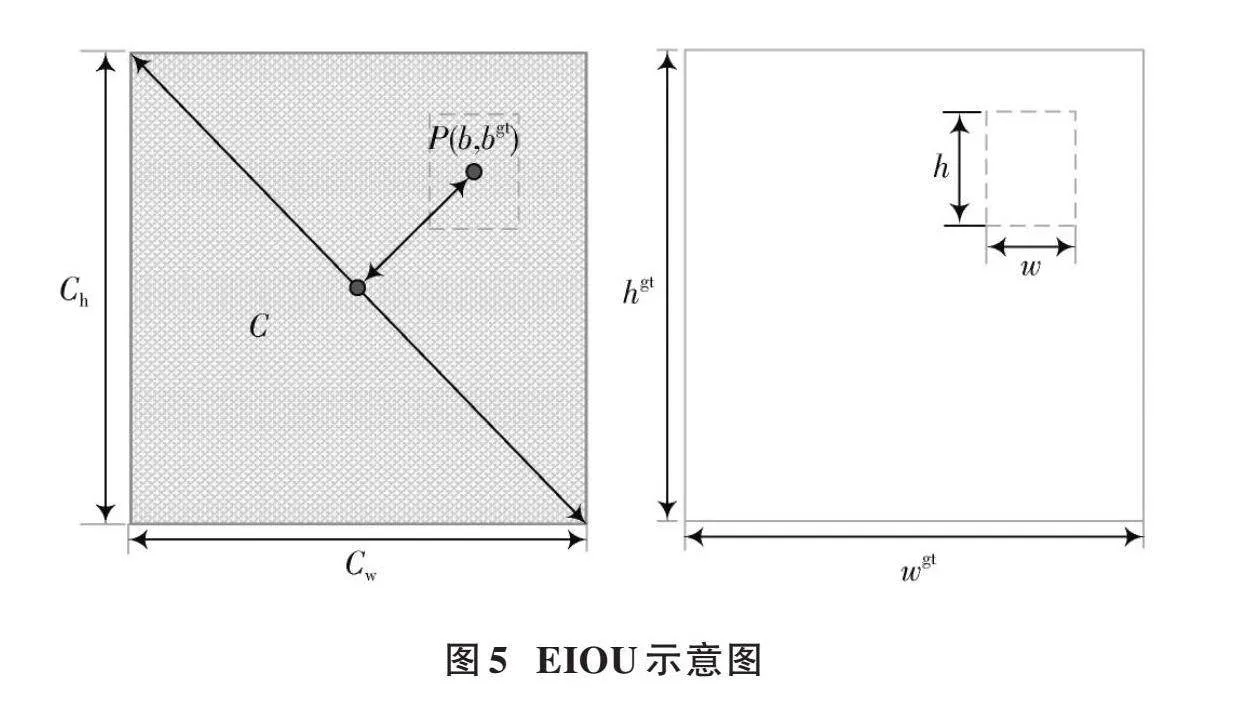
從上面的公式可以看出,CIOU將邊界框的縱橫比作為懲罰項加入到邊界框損失函數中,在一定程度上可以加快預測框的回歸收斂過程,但是一旦收斂到預測框和真實框的寬和高呈現出線性比例時,就會導致預測框回歸時的寬和高不能同時增大或者減少,其懲罰項就失去了原本的作用,這樣就無法有效地描述回歸目標,可能會導致收斂緩慢并且回歸不準確。為了解決這個問題,本文引入了EIOU(見圖5),采用直接對[w]和[h]的預測結果進行懲罰的損失函數表達式,如公式(10)所示:
[LEIOU=LIOU+Ldis+Lasp=1-IOU+ρ2(b,bgt)c2+ρ2(w,wgt)c2w+ρ2(h,hgt)c2h]" (10)
式中:[c]代表涵蓋預測框與真實框的最小外接框的對角線長度;[ch]和[cw]分別為其寬度和高度。在預測框與真實框中心點距離的計算中,將[ρ(w,wgt)]和[ρ(h,hgt)]分別視為橫向差值和縱向差值,[ρ(b,bgt)]為預測框與真實框中心點距離,具體如下所示:
[ρ(w,wgt)=w-wgt] (11)
[ρ(h,hgt)=h-hgt] (12)
[ρ(b,bgt)=b-bgt] (13)
由EIOU損失函數計算公式可見,EIOU損失函數延續了CIOU中的方法,EIOU懲罰項以此為基礎對縱橫比影響因子進行拆分,并分別對目標框及錨框長寬進行計算,加快收斂速度。將縱橫比中損失項分解成預測框寬高與最小外接框寬高之差,從而有效地增強收斂速度,回歸精度明顯提高。
3" 結果與分析
3.1" 實驗環境以及實驗參數
為了確保本文所提出的改進方法能夠得到有效的驗證,在實驗環境中進行了相關配置,具體內容詳見表1。
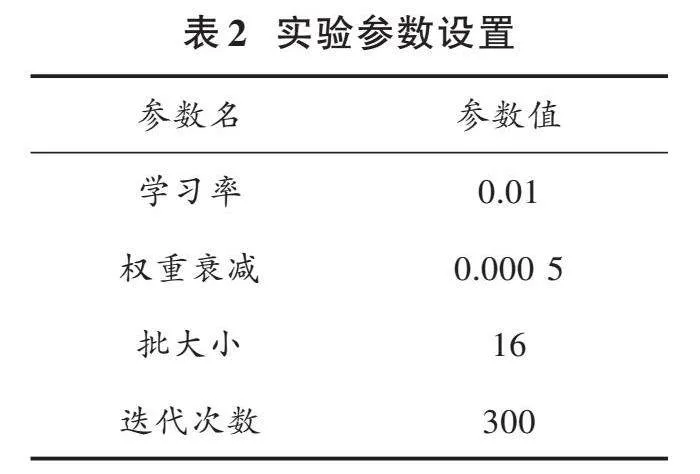
相關實驗參數設置如表2所示。
3.2" 實驗數據集
本文采用的數據集應包含不同季節和復雜天氣背景下的施工現場,從而滿足本文實驗的要求。本實驗采用的數據集是從公開的安全帽數據集SHWD(Safety?Helmet?Wearing?Dataset)中選擇其中符合實驗需求的一部分加上從網上爬蟲獲得的數據集,總共5 304張。該數據集包含不同尺度、不同場景、不同密集程度等各種情況,滿足本文實驗對環境復雜度的要求。該數據集分為兩個類別,分別是戴安全帽的人(Helmet)與未戴安全帽的人(Person)。首先使用LabelImg工具對圖像進行手動標注,然后按照8∶1∶1的隨機原則將數據集劃分為訓練集、驗證集和測試集,以便進行后續的數據處理和分析。部分數據如圖6所示。
3.3" 評價指標
為了對模型的性能和安全帽檢測的準確性進行評估,本文選用精確率(Precision, [P])、召回率(Recall, [R])和平均精度均值(mean Average Precision, mAP)這三個指標來衡量模型的表現,公式如式(14)~式(16)所示:
[P=TPTP+FP×100%] (14)
[R=TPTP+FN×100%] (15)
[mAP=01P(R)dRN] (16)
式中:TP(True Positive)為預測框和真實框相同的數量;FP(False Positive)為預測框和真實框不相同的數量;FN(False Negative)表示在預測過程中沒有被正確檢測到的圖像中所包含的物體數量;[N]是本文中所劃分類別的數量。
3.4" 實驗結果與分析
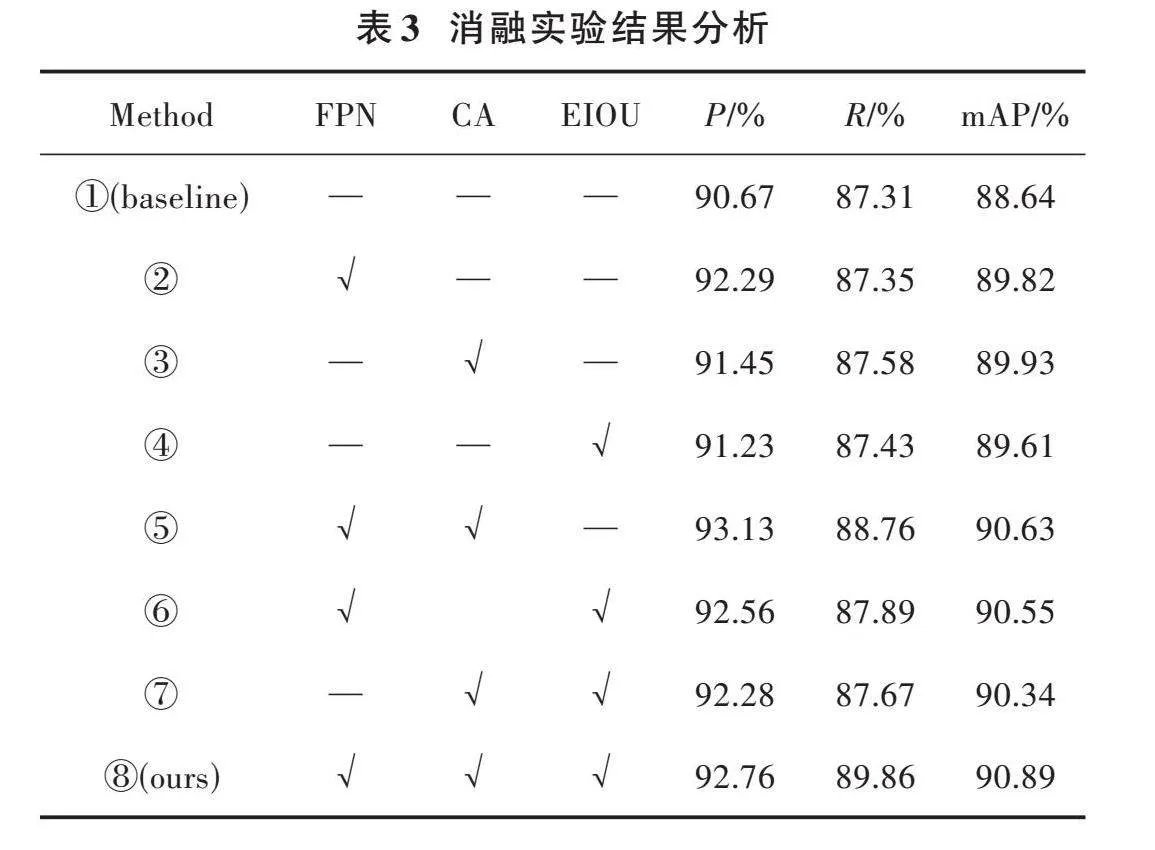
為了驗證本文算法改進策略的有效性,基于YOLOv5基線進行了8組消融實驗,各種實驗模型得到的實驗結果如表3所示。
表3中,FPN指在特征融合層添加微尺度檢測層,CA為嵌入CA模塊,EIOU為引入EIOU替換CIOU。通過實驗①、實驗②可以得知:引入FPN的目標檢測網絡相比于YOLOv5,mAP值提升了1.18%,說明特征融合層添加微尺度檢測層融入了更多的底層特征圖信息。通過實驗②、實驗⑤可以得知:引入CA的目標檢測網絡相對于YOLOv5+FPN,mAP值提升了0.81%,說明注意力機制可以有效地抑制無用信息,加強位置信息的提取,增強了特征提取能力。通過實驗⑧可以得知:YOLOv5+FPN+CA+EIOU的mAP值為90.89[%],相比于YOLOv5基線提升了2.25[%]。總體來看,經過改進后的算法精度相比YOLOv5算法檢測精度得到了較大的提升。
為了進一步驗證改進算法的目標檢測性能,在測試集上進行了一系列實驗,以確保其有效性和可靠性。圖7為原YOLOv5與改進算法在不同場景下的檢測結果對比圖,分為3個對照組。
圖7a)和圖7b)所呈現的是施工人員在復雜場景中佩戴安全帽的檢測結果。從圖7a)可以看出,原模型對于圖中的小目標信息出現了漏檢情況,而改進后的模型可以正常檢測到。
觀察圖7c)與圖7d)可以看出,拍攝密集人群時,本文算法檢測結果明顯更優,YOLOv5算法漏掉了右上角佩戴安全帽的目標。其根本原因是在卷積過程中模型會更偏向于關注圖像的紋理信息,而忽略背景信息,使得最終生成的特征圖信息不夠豐富。而改進模型生成的特征圖語義信息更加豐富,提高了精度,在一定程度上避免了漏檢、誤檢的發生。
圖7e)與圖7f)是施工場地場景的YOLOv5原模型和本文改進模型的測試結果。從圖7e)可以看出,部分被障礙物遮擋到的目標無法被識別出來從而導致漏檢。而從圖7f)中可以看出,改進后的YOLOv5模型網絡可以正確識別出被遮擋到的目標,將坐標注意力機制嵌入特征融合層中可以顯著提升重要特征信息的獲取能力,使得最終生成的特征圖信息更加豐富,提高了模型的表示能力,加強了模型對被遮擋目標的檢測能力。
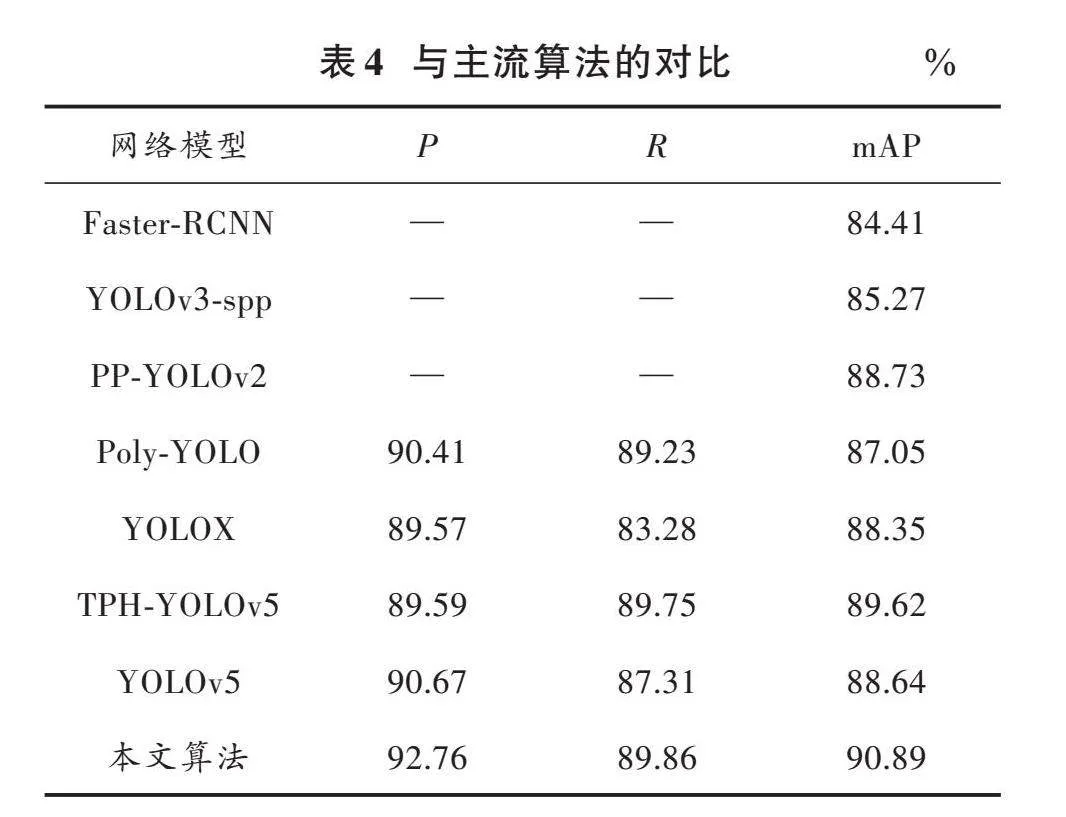
4" 與現有主流算法的對比實驗
選取當前具有代表性且性能優異的目標檢測算法分別訓練同一個安全帽數據集,比較模型的性能,實驗結果如表4所示。通過對比可知,本文基于YOLOv5改進后的算法在安全帽數據集中有更高的精度,在面對安全帽佩戴檢測問題上具有更高的針對性。相較于Faster?RCNN,其mAP的精度提高了6.48%,相比在小目標領域檢測精度比較高的TPH?YOLOv5提高1.27%。與改進前的原模型相比,mAP提高了2.25%,在多種不同模型的算法對比中表現出了一定的優越性。總體而言,本文所提出的優化方案具備相當的有效性。
5" 結" 語
本文提出一種基于改進YOLOv5的安全帽檢測算法。首先,在特征融合層添加微尺度檢測層,提取更豐富的安全帽特征信息,極大地提升了檢測性能;其次,在改進的特征融合層中嵌入CA,增強重要的特征信息,抑制無用的特征信息,提高模型的表達能力;最后,采用EIOU損失函數替換CIOU損失函數解決了縱橫比的模糊定義,加快了網絡收斂,有助于提高回歸精度。實驗結果表明,所提出的改進版YOLOv5算法用于安全帽檢測的平均精度值可以達到90.89%,對于安全帽的檢測這一方向的研究具有良好的成效。在未來的工作中,將擴展現有方法實現對安全帽語義的識別,提高安全帽檢測的實用性,并進一步優化安全帽檢測網絡的速度和檢測性能。
參考文獻
[1] WANG L, TANG J, LIAO Q. A study on radar target detection based on deep neural networks [J]. IEEE sensors letters, 2019, 3(3): 1?4.
[2] PATHAK A R, PANDEY M, RAUTARAY S. Application of deep learning for object detection [J]. Procedia computer science, 2018, 132: 1706?1717.
[3] JAMTSHO Y, RIYAMONGKOL P, WARANUSAST R. Real?time license plate detection for non?helmeted motorcyclist using YOLO [J]. ICT express, 2021, 7(1): 104?109.
[4] 徐守坤,王雅如,顧玉宛,等.基于改進Faster RCNN的安全帽佩戴檢測研究[J].計算機應用研究,2020,37(3):901?905.
[5] 吳雪,宋曉茹,高嵩,等.基于深度學習的目標檢測算法綜述[J].傳感器與微系統,2021,40(2):4?7.
[6] YING Z, HONGMEI G, WENGANG Y, et al. Earthquake?induced building damage recognition from unmanned aerial vehicle remote sensing using scale?invariant feature transform characteristics and support vector machine classification [J]. Earthquake spectra, 2023, 39(2): 962?984.
[7] AORUI G, HEMING S, CHAO L, et al. A novel fast intra algorithm for VVC based on histogram of oriented gradient [J]. Journal of visual communication and image representation, 2023, 95: 103888.
[8] 趙恒,胡勝男,徐進霞,等.基于DBN?SVM的電力智慧工地異常行為識別[J].自動化與儀器儀表,2023(5):92?95.
[9] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 580?587.
[10] XU X, ZHAO M, SHI P, et al. Crack detection and comparison study based on faster R?CNN and mask R?CNN [J]. Sensors, 2022, 22(3): 1215.
[11] CHEN Y, LI W, SAKARIDIS C, et al. Domain adaptive faster R?CNN for object detection in the wild [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 3339?3348.
[12] 徐守坤,王雅如,顧玉宛,等.基于改進FasterRCNN的安全帽佩戴檢測研究[J].計算機應用研究,2020,37(3):901?905.
[13] ZHOU F, ZHAO H, NIE Z. Safety helmet detection based on YOLOv5 [C]// 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA). New York: IEEE, 2021: 6?11.
[14] HUANG L, FU Q, HE M, et al. Detection algorithm of safety helmet wearing based on deep learning [J]. Concurrency and computation: Practice and experience, 2021, 33(13): e6234.
[15] LONG X, CUI W, ZHENG Z. Safety helmet wearing detection based on deep learning [C]// 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Con?ference (ITNEC). New York: IEEE, 2019: 2495?2499.
[16] 李航,朱明.基于深度卷積神經網絡的小目標檢測算法[J].計算機工程與科學,2020,42(4):649?657.
[17] AN Q, XU Y, YU J, et al. Research on safety helmet detection algorithm based on improved YOLOv5s [J]. Sensors, 2023, 23(13): 5824.
[18] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2021: 13713?13722.
[19] ZHANG Y F, REN W Q, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression [J]. Neurocomputing, 2022, 506: 146?157.
[20] ZHENG Z, WANG P, LIU W, et al. Distance?IoU loss: Faster and better learning for bounding box regression [J]. Procee?dings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993?13000.
[21] 周華平,鄧彬.融合多層次特征的deeplabV3+輕量級圖像分割算法[J/OL].計算機工程與應用,1?9[2023?08?31].http://kns.cnki.net/kcms/detail/11.2127.TP.20230831.1205.012.html.
[22] CENGGORO T W, ASLAMIAH A H, YUNANTO A. Feature pyramid networks for crowd counting [J]. Procedia computer science, 2019, 157: 175?182.
[23] LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 8759?8768.
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
