
基于協同過濾和機器學習的新聞推薦
2024-09-13 00:00:00承孝敏
電腦知識與技術 2024年22期
摘要: 針對傳統基于內容的推薦、協同過濾和機器學習推薦存在的問題,如龐大數據的弱處理能力、時效性差以及缺乏可解釋性,提出了一種基于協同過濾和機器學習融合的新聞推薦算法。首先構建了用戶-新聞交互評分模型、新聞時效性評分模型和新聞內容評分模型,利用協同過濾相關算法預測用戶新聞推薦分數。然后通過構建用戶檔案和新聞檔案提取用戶特征和新聞特征,利用機器學習模型預測用戶-新聞評分。最后,通過軟投票機制將用戶-新聞對的協同過濾分數和機器學習分數融合,進行全面的新聞推薦。實驗結果表明,該算法能夠有效提高新聞推薦的準確性。
關鍵詞: 機器學習;協同過濾;用戶畫像;新聞畫像;融合推薦
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)22-0001-03
開放科學(資源服務)標識碼(OSID)
0 引言
隨著互聯網技術的迅猛發展和普及,新聞和信息的獲取與發布發生了深刻的變化。在信息爆炸的時代,從龐大的新聞中過濾出用戶感興趣的內容并準確推送給他們是一個重大挑戰。傳統的推薦方法依賴于瀏覽歷史和興趣偏好,但存在數據稀疏、冷啟動等問題,無法滿足個性化和準確的需求。
基于內容的推薦(CB) 是指基于物品相關信息、用戶相關信息以及用戶對物品的操作行為進行推薦。通常使用 TF-IDF、word2vec 以及語言模型等方法來處理新聞并生成用于推薦的標簽。推薦結果具有解釋性,但缺乏多樣性且難以提取特征。協同過濾(CF) 采用與用戶相似的用戶行為(評分、點擊次數等)來推斷用戶對特定產品的偏好,然后根據這些偏好做出相應的推薦[1]。通常使用 SVD[2]等算法對評分矩陣進行分解以解決矩陣問題,主要包括基于用戶[3]和基于產品[4]的兩種方式。作為經典的推薦算法,協同過濾無須對商品或用戶進行分類或標注,可以高效解決難以提取特征的問題。然而,在處理新聞推薦時,協同過濾算法面臨一些問題,例如新聞的時效性和用戶的動態變化。
另一方面,基于機器學習的推薦可以通過構建用戶畫像和新聞畫像來克服新聞時效性的變化和用戶興趣的動態變化等問題。然而,它通常在可解釋性方面表現較差,并對數據質量有較高的要求。文獻[5]提出了一種基于圖注意力和神經協同過濾的社會推薦模型 AGNN-SR,通過學習用戶項目交互圖和社交網絡圖上的用戶和項目潛在特征,以及利用神經協同過濾層編碼用戶項目交互的協作信號,實現了有效的社交推薦。然而其在冷啟動場景下的表現結果不佳。文獻[6]則從知識圖譜的角度出發,設計了一種融合社交關系和知識圖譜的推薦算法 MSAKR,通過圖卷積神經網絡提取用戶社交關系特征,并利用知識圖譜學習物品屬性信息,以緩解數據稀疏性并提升推薦性能。但是這種方法主要依靠用戶或物品之間的關聯關系,對用戶與物品之間的交互信息利用程度較低。
為了克服這些問題,本文提出了一種協同過濾和機器學習集成的新聞推薦算法,能夠有效利用用戶的歷史行為數據和時效性信息,提高推薦的準確性。本文的主要貢獻包括:1) 提出了一種基于協同過濾和機器學習融合的新聞推薦算法。通過協同過濾推薦分數和機器學習分數的融合,提高了推薦的準確性和用戶滿意度。2) 使用協同過濾相關算法預測用戶新聞推薦分數矩陣中的缺失值,即用戶新聞推薦分數的缺失值,有效解決了數據的稀疏問題。3) 通過構建用戶畫像和新聞畫像,并利用機器學習算法推薦新聞,提高了推薦的個性化程度。
1 方法
本文提出了一種基于協同過濾和機器學習融合的新聞推薦算法,主要包括三個部分:基于協同過濾的評分預測、基于機器學習的評分預測以及融合推薦。首先,構建了用戶-新聞互動評分模型、新聞時效性評分模型和新聞內容自身評分模型,并通過關聯算法-時間的協同過濾預測用戶的新聞推薦得分。然后,通過構建用戶畫像和新聞畫像提取用戶特征和新聞特征,利用機器學習模型預測用戶-新聞評分。最后,采用軟投票機制實現用戶-新聞對的協同過濾分數和機器學習分數的融合,進行全面的新聞推薦。
1.1 用戶新聞評分計算
1.1.1 行為因素評分
在行為因素評分計算模塊中,核心目標是計算由用戶與新聞的互動構建的互動分數。用戶對新聞內容的點贊、收藏、分享和評論可以代表用戶對新聞內容的興趣。單個點贊、收藏、分享和評論的分數分別如下[P,C,S,Comm]:用戶評論的分數是根據用戶行為累積得到的,通過使用sigmoid函數進行標準化:
[Tb=np×P+nc×C+ns×S+nComm×Comm] (1)
[Tbehaviour=11+e-Tb] (2)
式中:[np,nc,ns,nComm]分別表示用戶的點贊、收藏、分享和評論的數量。
互動內容得分由兩個得分組成:閱讀時間得分和評論內容得分。假設所有用戶對一則新聞的平均閱讀時間為[t0],某一則新聞的閱讀時間為[t],則閱讀時間得分如下:
[Treading=11+e-k(t-t0)] (3)
當用戶的閱讀時間長于平均閱讀時間時,閱讀時間得分接近1,表示用戶對新聞的興趣較高。
評論內容得分基于特定關鍵詞,構建了內容情感分析模型。首先,使用中文分詞工具將評論內容分詞成相應的分詞序列。然后,使用TextRank算法從評論內容中提取關鍵詞,并利用BERT預訓練語言模型表征關鍵詞序列,將關鍵詞序列映射到一系列高維向量。最后,通過計算和標準化與關鍵詞序列對應的高維向量的混亂度,得到相應的評論質量得分:
[Tc=exp(-log2softmax(wcomment)N)] (4)
[Tcomment=11+e-Tc] (5)
其中,[wcomment]表示與關鍵詞序列對應的向量編碼,[N]表示關鍵詞序列的長度。通過組合獲得的三個得分,得到與用戶行為因素對應的得分:
[T=whTbahaviour+wrTreading+wcTcomment] (6)
其中,[wh,wr,wc]為融合權重且[wh+wr+wc=1]。
1.1.2 時間衰減函數
為了更準確地反映用戶當前的興趣,本文引入了時間衰減函數以消除時間因素對評分的影響。通過在評分計算中給予最近用戶行為更多的權重:
[T=ek(T1-T0)T] (7)
其中,[T0,T1]表示新聞發布時間和當前時間,[k]代表時間衰減因子。
1.2 基于協同過濾的得分預測
協同過濾通過分析歷史行為數據來預測用戶未來的興趣和偏好。在本文提出的模型中,采用協同過濾技術,通過找到與用戶興趣相似的其他用戶喜歡的新聞來進行新聞推薦。
首先,基于用戶在新聞平臺上收集的歷史行為數據,計算基于行為因素的得分。用戶對歷史數據的評分被計算并轉換為二維矩陣。
接著,為了獲得與用戶和新聞對應的隱含因子向量,采用因子分解算法對構建的因子進行分解。利用歷史評分數據,并通過最小二乘法基于預測與實際評分之間的差距,訓練矩陣分解模型,將原始的用戶-新聞評分矩陣分解為兩個低秩矩陣的乘積,[userM]和[itemM]分別表示用戶興趣和新聞內容的隱藏向量。
完成矩陣分解模型的訓練后,對于給定的用戶[u]和新聞[i],計算其對應的隱含因子向量的點積,可作為用戶對新聞的整體評分向量:
[Tu,i=userMu?itemMi] (8)
其中,[userM]表示用戶隱含因子向量,[itemM]表示新聞隱含因子向量。之后,通過激活函數映射得分,將其轉換為在標準評分范圍內的預測得分:
[T′u,i=sigmoid(Tu,i)] (9)
最后,計算所有用戶對所有新聞的預測評分,生成完整的用戶-新聞預測評分矩陣,然后根據預測評分對所有候選新聞進行排序,選擇評分最高的前n條新聞作為用戶的推薦結果。
1.3 基于機器學習的得分預測
基于機器學習的得分預測需要使用用戶數據和新聞數據。因此,在本文中,對用戶數據和新聞數據進行處理,實現用戶畫像和新聞畫像的構建,這可以提供豐富的用戶和新聞特征,并為基于機器學習的推薦得分預測提供強有力的支持。
1.3.1 用戶畫像構建
用戶畫像是對用戶信息的綜合描述,包括用戶的基本信息、興趣偏好和行為特征。構建用戶畫像的過程可分為數據收集與處理、特征提取、畫像構建和畫像更新四個步驟。
數據收集與處理收集包括注冊信息、歷史行為記錄、社交網絡信息等在內的用戶各種數據,清理原始數據,去除噪聲和冗余,處理缺失值。從清理后的數據中提取特征,如基本信息和行為特征。根據特征標注用戶以構建畫像。定期更新畫像以反映用戶變化,使用時間窗口或增量學習。對提取的特征進行向量處理,使用不同的編碼方法處理不同標簽,生成用戶特征向量。
1.3.2 新聞畫像構建
新聞畫像構建包括數據收集與處理、特征提取、畫像構建和更新四個步驟。推薦系統需考慮多維信息,需獲取新聞文本和相關元數據,如發布時間、來源和作者,可從新聞網站、社交媒體等獲取。預處理包括去除停用詞、詞形變化、分詞等,有助于提取有效信息。從預處理后的文本中提取新聞特征,如標題、關鍵詞、命名實體識別結果、情感傾向、主題分類等。根據提取的特征對新聞進行標注,如領域標簽、情感標記。定期更新新聞畫像,可使用時間窗口或增量學習。需對新聞特征進行向量化處理作為模型輸入,類似于用戶標簽編碼,不同標簽使用不同編碼方式。
1.3.3 基于XGBoost的得分預測
在構建并將用戶畫像和新聞畫像編碼成特征向量后,可以為基于機器學習的推薦得分提供豐富的用戶和新聞特征,從而提高得分特征的準確性。
首先,將歷史用戶特征向量和用戶已閱讀新聞特征向量拼接,得到用戶-新聞特征向量,并將y標簽設為正向。然后,將歷史用戶特征向量和用戶未閱讀新聞特征向量拼接,得到用戶-新聞特征向量,并將y標簽設為負向。最后,基于構建的用戶-新聞正負樣本,采用XGBoost模型進行建模,并對所有用戶-新聞配對進行得分預測,從而得到所有用戶-新聞得分的矩陣。
1.4 綜合推薦
基于協同過濾和基于XGBoost模型計算的得分通過軟投票機制進行合并。即對于用戶[u]和新聞[i],假設它們的協同過濾得分為[Su,icf],XGBoost模型得分為[Su,ixgb],得分[S]的計算方法如下:
[S=λ1Su,icf+λ2Su,ixgb] (10)
其中,[λ1]和[λ2]為融合權重,[λ1+λ2=1]。
對所有用戶-新聞配對的得分進行融合,得到最終的用戶-新聞得分矩陣。對于任意用戶 [u],根據評分矩陣的結果,對用戶與所有由新聞構建的用戶-新聞配對進行得分和排序,然后根據排序結果進行新聞推薦。
2 實驗
2.1 數據集
為了評估本文推薦算法的性能,本文采用了一個大規模的真實新聞推薦數據集。該數據集包含了515 673個用戶與新聞的互動,包括點擊、瀏覽、點贊、評論等行為。數據集中的每條記錄包含userID、newsID以及用戶對新聞的具體行為。
2.2 基準模型
為驗證本文提出的推薦算法的有效性,選擇以下推薦算法作為比較實驗的基準模型:
· POP:根據歷史新聞的流行度進行推薦,即推薦集中關注歷史上最受歡迎的新聞。
· S-POP:根據當前時間段內新聞的流行度進行推薦,即在推薦訓練中根據時間集中推薦具有最高流行度的新聞。在推薦過程中,隨著項目獲得更多事件,推薦列表會發生變化。
· Item-KNN[7-8]:基于新聞相似性進行推薦,定義為其推薦向量的余弦相似度。
· BPR-MF[9]:通過SGD優化配對排序的目標函數,即通過矩陣分解算法處理用戶-新聞排序矩陣,得到用戶對新聞的排序結果進行推薦。
· SVD++:通過分析用戶的歷史行為數據,找到具有相似興趣的用戶群體或找到與用戶先前喜歡的新聞相似的新聞進行推薦。
2.3 對比實驗
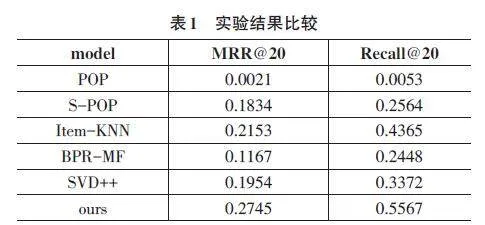
本文實驗采用MRR@20(即推薦列表前20條新聞的平均倒數排名)和Recall@20(即推薦列表前20條新聞的召回率)作為評價指標,本文提出的推薦算法與基準模型的對比實驗結果如表I所示。
實驗結果表明,本文提出的推薦算法在各種指標上均優于其他基準模型。具體而言,與其他基準模型相比,本文的算法在MRR@20上至少提高了6%,在Recall@20上提高了12%。通過比較實驗結果,可以看出本文提出的推薦算法在新聞推薦任務中具有更好的性能。
3 結論
本文提出了一種基于協同過濾和機器學習融合的新聞推薦算法。該算法首先結合了三個評分模型,即用戶-新聞互動評分、新聞時效性評分和新聞內容評分。使用協同過濾相關算法來估計用戶對新聞的推薦評分。然后,構建用戶畫像和新聞畫像,利用基于機器學習的模型預測用戶-新聞評分。最后,采用軟投票機制將協同過濾得分和機器學習得分整合,實現全面的推薦。實驗證明,本文的推薦算法能夠有效提高新聞推薦的準確性和用戶滿意度。
參考文獻:
[1] LIU Q,CHEN E H,XIONG H,et al.Enhancing collaborative filtering by user interest expansion via personalized ranking[J].IEEE Transactions on Systems,Man,and Cybernetics Part B,Cybernetics:a Publication of the IEEE Systems,Man,and Cybernetics Society,2012,42(1):218-233.
[2] PENG S W,SUGIYAMA K,MINE T.SVD-GCN:a simplified graph convolution paradigm for recommendation[C]//Proceedings of the 31st ACM International Conference on Information & Knowledge Management.Atlanta GA USA.ACM,2022:1625–1634.
[3] ADOMAVICIUS G,TUZHILIN A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[4] XUE F,HE X N,WANG X,et al.Deep item-based collaborative filtering for top-N recommendation[J].ACM Transactions on Information Systems,2019,37(3):1-25.
[5] 章琪,于雙元,尹鴻峰,等.基于圖注意力的神經協同過濾社會推薦算法[J].計算機科學,2023,50(2):115-122.
[6] 高仰,劉淵.融合社交關系和知識圖譜的推薦算法[J].計算機科學與探索,2023,17(1):238-250.
[7] LINDEN G,SMITH B,YORK J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[8] DAVIDSON J,LIEBALD B,LIU J N,et al.The YouTube video recommendation system[C]//Proceedings of the fourth ACM conference on Recommender systems.Barcelona Spain.ACM,2010.
[9] RENDLE S,FREUDENTHALER C,GANTNER Z,et al.BPR:Bayesian personalized ranking from implicit feedback[J].ArXiv e-Prints,2012:arXiv:1205.2618.
【通聯編輯:唐一東】
