
局部特征互補的遮擋行人重識別研究
2024-09-13 00:00:00張孟思
電腦知識與技術 2024年22期


摘要:本研究致力于解決行人重識別領域面臨的挑戰,特別是由于遮擋等問題導致的識別難題。現有方法通常在整體圖像上進行處理,容易忽略被遮擋的細節信息,從而可能導致錯誤的識別結果。為了應對這一問題,本研究提出了一種局部特征互補的遮擋行人重識別方法。該方法通過對局部特征提取、學習以及特征間互補,有效地減輕了背景干擾和遮擋對行人重識別準確性的負面影響。研究結果表明,該方法在提高行人重識別準確性方面表現出明顯的優勢,為解決遮擋問題提供了新的思路,具有重要的實際意義和應用前景。
關鍵詞:行人重識別;計算機視覺;遮擋;局部特征;特征互補
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)22-0007-04
開放科學(資源服務)標識碼(OSID)
0 引言
公共安全問題已成為社會高度關注的焦點,對于國家繁榮和社會和諧至關重要。在城市中,電子監控設備的廣泛應用使行人重識別成為監控和安防領域的主要任務。行人重識別在智能安防、智能尋人系統和智能分類系統等領域中發揮著重要作用,能夠快速定位犯罪嫌疑人、協助尋找走失人員,并對照片進行分類和聚類。在計算機視覺領域中,行人識別扮演著關鍵的角色。然而,行人重識別任務面臨著遮擋帶來的挑戰。遮擋導致查詢集圖像和候選集圖像同時被障礙物遮擋,增加了特征提取的難度,降低了識別的準確性。盡管針對單一攝像頭捕獲的行人圖像進行分析已相對成熟,但隨著監控力度增強、攝像頭數目增加以及拍攝環境的復雜多變,單一攝像頭下的分析處理已不再足夠,迫切需要關注多個攝像頭下捕獲同一行人的多張圖像。多攝像頭下的行人圖像提供了更豐富的信息,但也面臨著攝像頭視角、分辨率變化等挑戰,增加了行人重識別任務的復雜性。為了更好地應對遮擋的行人重識別問題,本文提出了一種局部特征互補的行人重識別方法,解決多公共攝像頭下遮擋行人識別問題,提取跨攝像頭共享特征,為公共安全和社會穩定做出積極貢獻。
1 相關工作
近年來,為了有效克服行人重識別過程中遮擋干擾帶來的挑戰,業界涌現出一系列杰出的研究成果。這些研究不僅專注于算法的優化和改進,還致力于創新技術的開發和應用,以期在提高識別精度和速度方面取得突破。目前,現有的遮擋行人重識別方法主要側重特征提取和對齊[1-2]。這些方法在一定程度上提高了識別準確性,但仍面臨一些挑戰。例如,特征融合可能會引入噪聲或干擾信息,從而影響最終的識別結果;局部特征匹配可能會受到遮擋部分的影響,導致提取的特征不夠完整或準確;缺乏對特征間復雜關系的建模,限制了在處理遮擋情況下的識別能力。為了克服這些挑戰,一些研究者開始探索基于深度學習的方法來提高遮擋行人重識別的效果,并在大規模數據集上進行端到端的訓練,從而可以更好地捕捉特征之間的復雜關系。一些最新的研究工作表明,基于深度學習[3-4]的方法在處理遮擋情況下能夠取得更好的識別效果,甚至超過傳統方法的表現。除了深度學習技術,一些研究者還嘗試結合多模態信息來提高遮擋行人重識別的性能。通過融合不同傳感器或模態的信息[5-6],可以更全面地捕捉行人的特征,從而提高識別的準確性和魯棒性。
2 本文方法
2.1 特征提取
為了提升行人重識別的性能,更好地識別和區分不同的行人,本文提出了基于姿態估計的局部特征提取方法。該方法通過提取姿態特征、識別遮擋區域以及保持姿態信息相似性,從而提高準確性和魯棒性。通過提取人體關鍵點的位置信息獲取局部特征,以識別遮擋區域。由于姿態信息在不同角度下具有相似性,有助于使模型聚焦于未被遮擋的顯著區域,突出人體部位的局部顯著特征。采用姿態引導的方法,聯合學習局部特征以探索更具區分性的特征,使模型更專注于行人的姿態信息,從而更好地區分不同行人的特征差異。通過學習局部特征的注意力權重,模型能更準確地捕捉關鍵的局部特征信息,進而提高行人重識別的準確性。這種方法即使在遇到遮擋情況下仍能構建出有效的特征表示,確保模型能在復雜環境下準確識別行人,為行人重識別領域帶來新的思路和方法。
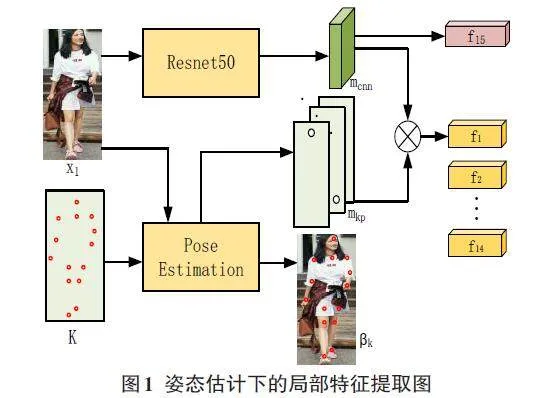
具體而言,在給定一個行人圖像x1的情況下,首先使用ResNet50作為卷積神經網絡(CNN) 的主干網絡,并在刪除全局平均池化層和全連接層后得到特征映射mcnn。隨后,利用姿態估計模型獲取行人的14個關鍵姿態點,生成去除遮擋的關鍵點熱度圖mkp和關鍵點置信度分數βk。在這里,熱度圖的值代表關鍵點位置的二維高斯分布,最大值為關鍵點的坐標,而置信度分數表示關鍵點的可見程度。因此,最終為輸入圖像生成14張h×w熱度圖和14個關鍵點置信度分數,如圖1所示。
通過對原始輸入得到的特征映射與關鍵點熱度圖進行乘法操作(U)和求和操作,可以得到特征提取階段關鍵點的單一信息特征Fl。其中,mkp經過Normalization和Softmax函數處理,旨在減少噪聲干擾和錯誤值的影響。通過對特征映射執行全局最大池化操作,可以得到包含整體信息的全局特征Fg,具體公式如下所示:
[Fl=fk14k=1=SUMmcnn?mkp] (1)
[Fg=fk+1=Fmax] (2)
損失函數LE涉及目標人圖像的真實標簽,用于學習人的表現,分別使用Lcls表示分類損失,Ltri表示三元組損失,k表示關鍵點特征,取值從1到15。βk表示第k個關鍵點特征的置信度,若k=15表示全局特征的置信度,即βk=1。具體公式如下所示:
[LE=1kβkLclsfk+Ltrifk] (3)
2.2 特征學習
姿態估計用于獲取局部特征信息,然而由于遮擋干擾,不可避免地會引入一些無意義甚至噪聲信息,從而降低行人重識別的準確性[7]。在某些情況下,不同攝像頭下的不同圖像,由于行人姿態和遮擋區域的相似性,使得人體姿態信息無法完全有效地區分行人身份。為了有效利用關鍵點信息,本文采用人體關鍵點的結構,將人體姿態信息和全局對比信息共同構建出行人的局部特征和全局特征表示。
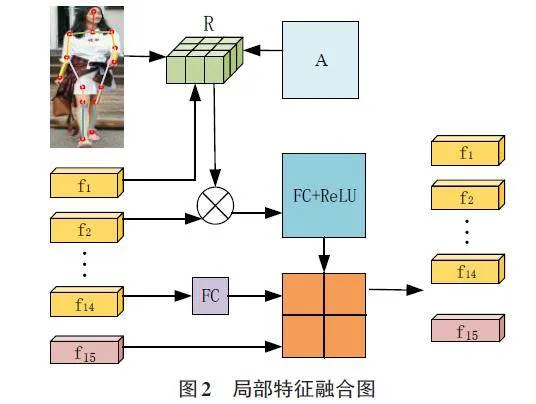
引入基于人體關鍵點結構的方法用于構建行人的有效局部特征和全局特征表示。在該方法中,每個姿態點的位置信息被看作節點的獨立特征,用于建立節點之間的關系。具體而言,若兩個節點之間存在連接,則連接值為1,否則為0。在建立身體各部位關系時,最初節點之間沒有連接,隨后無論如何學習更新節點關系,節點之間仍保持無連接狀態。通過全局特征、局部特征以及人體關鍵點結構的相互關聯,實現節點特征的匯聚和更新。這種方法不僅考慮了單一節點特征信息,還考慮了邊的特征信息,節點之間的連接基于姿態點之間的相對位置關系來確定鄰近關系R。通過學習和聚合相關節點特征,得到每個身體部位豐富的語義信息特征表示,如圖2所示。
本文在保留局部和全局上下文信息的同時對特征進行調整和更新,優化節點特征,使每個節點能更好地學習行人節點的特征信息,監督關系信息,學習更具區分性的特征信息,以提高識別精度。
一個簡單的圖卷積可以通過將輸入的局部特征Fl與特征矩陣R融合,得到最終的輸出特征FK。在這個過程中,使用全連接層FC1和FC2,它們之間的權重不共享。具體公式如下所示:
[FK=FC1R?Fl+FC2Fl,Fg ] (4)
損失函數([LBCE]) 用于確定提取的特征是否與真實的標簽屬于同一個人。其中,y表示真實標簽,p表示第K個特征屬于同一個身份標簽(即正樣本)的概率。如果第K個特征是一個正樣本,則y=1,否則為0。具體公式如下所示:
[LBCE=-1Kk=1Ky?logp+y'?logp'] (5)
2.3 特征互補
建立人體關鍵點聯系,關注特征的融合信息,更全面地了解目標人的特征和特點,以便更有效地抓取目標人的有利信息。然而,此過程并未解決行人圖片在匹配階段行人圖像空間不對齊的問題。傳統的對齊策略是匹配相同關鍵點的特征,但在遮擋嚴重的情況下效果較差。雖然圖匹配可以考慮人的高階拓撲信息,但只能進行簡單的一對一對齊,對異常值敏感,缺乏健壯性。
為了解決這個問題,本文提出了一種多對多的軟對齊方法,將一張圖片的特征對應到另一張圖片的各個特征,建立一組圖片中各個節點之間的聯系,不僅關注節點與節點之間的對齊,還關注邊與邊的對齊。這樣一組圖像之間的節點信息以及邊的信息可以相互傳遞,提高對齊的準確性,提高識別效率。
具體而言,首先,使用余弦距離函數提取三元組圖像,其中圖像x1是從一個圖像中提取的所有聯合特征的集合,圖像x3與x1屬于不同行人,圖像x2與x1屬于同一行人。在給定圖像匹配過程中的一組圖片x1和x2,其中,x1的圖為G1=(F1,E1),x2的圖為G2=(F2,E2)。其次,建立了匹配矩陣S,其中Sia是指F1i和F2a之間的匹配度。然后,根據一元和成對點特征建立了一個平方對稱正矩陣M,其中Mia,jb指的是E2與E1邊的匹配程度。對于不形成邊的對,它們在矩陣中的相應項被設置為0。對角線部分包含節點到節點的值,而非對角線部分包含節點到節點邊的值。最后,通過深度學習框架利用隨機梯度下降不斷優化最優匹配矩陣U。優化過程采用冪次迭代和雙隨機運算。
[U=argmaxSTMS] (6)
在關注邊的對齊后,可以通過比較兩幅圖像中相應位置來確定哪些區域被遮擋了。一旦確定了被遮擋的部分,可以利用另一幅圖像中對應位置的未被遮擋部分來填補這些缺失區域,實現互補。如圖3所示,一張圖像的左腿被遮擋,另一張圖片的右腿被遮擋,將左右腿部被遮擋的部分進行互補,每張圖片不僅擁有自身的鑒別信息,還擁有特征互補信息,從而減少遮擋干擾。這樣有效地減少遮擋帶來的影響,提高圖像的完整性和質量。
通過最小化L來訓練端到端的框架。首先,輸入一組圖片中提取到的特征F1和F2,將親和力矩陣與特征F1i和F2i進行乘法操作([?]) ,然后與另一張圖片的對應特征進行通道維度連接。其中,Con表示沿通道維度的連接操作,FC是一個全連接層。最后,連接的特征通過全連接層與原圖像特征相加,生成更具鑒別力的特征。具體公式如下所示:
[Fa=FCConF1,U?F2+F1] (7)
[Fp=FCConF2,U?F1+F2] (8)
損失函數(Lv) 用于測量兩個樣本圖像之間的關系,即圖像[x1]和圖像[x2]的輸入,可以是同一個人,也可以是不同的人。每對訓練圖像(x1,x2)都有一個標簽,表明它們是正樣本對還是負樣本對。如果兩張圖像為正樣本即屬于同一個人,則y=1,否則為0。Sx1,x2表示x1和x2之間的相似性。具體公式如下所示:
[LV=ylogsx1,x2+1-ylog1-sx1,x2] (9)
3 實驗分析
3.1 實驗環境設置
本次實驗的硬件環境包括Intel(R) Xeon(R) CPU E5-2670×2處理器、48GB DDR4內存、4塊Nvidia GeForce Titan X GPU、3塊4TB HDD和512GB SSD。軟件環境為Ubuntu18.04操作系統、Pytorch深度學習框架和Python3.7。訓練網絡時,批量大小為64,共有16個人,每人有4張256×128像素的圖像。在圖像預處理過程中,添加了隨機水平翻轉、隨機擦除、隨機裁剪,并進行填充10個像素。其中,隨機水平翻轉和隨機擦除的概率均設置為0.5,如圖4所示。訓練包括120個epochs,學習率從3.5e-4逐漸衰減至0.1,采用SGD優化器進行端到端學習。在測試含遮擋數據集時,采用額外的顏色抖動增強來減少域方差。
3.2 實驗數據集
本文利用三個公開的行人重識別數據集來驗證所提出的方法,分別為整體數據集 Market1501 和 DukeMTMC-ReID 以及遮擋數據集 Occluded_DukeMTMC。其中,Market1501 包含來自6個攝像機視角的1 501個身份,所有數據集中都包含很少被遮擋或部分遮擋的人物圖像。DukeMTMC-ReID 包含1 404個身份。而遮擋數據集 Occluded_DukeMTMC 是從 DukeMTMC-ReID 中提取而來,保留了含有遮擋的圖像,丟棄了重疊的圖像。該數據集包括以下內容:訓練圖像涵蓋702個人共計15 618幅圖片,圖庫圖像包含1 110個人共計1 7661幅圖片,而含有遮擋的查詢圖像有519個人共計2 210幅圖片。
3.3 實驗結果
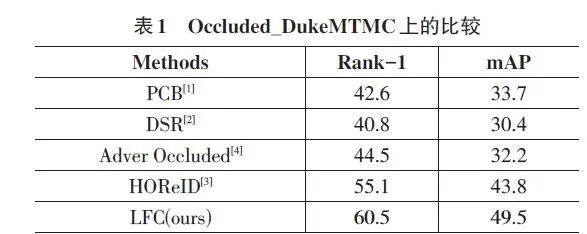
在遮擋數據集 Occluded_DukeMTMC 上進行評估,根據表1的結果顯示,本文所提出的方法在 Rank-1方面取得了60.5%的成績,mAP方面達到了49.5%。這顯示了該方法在處理數據遮擋方面的優越性,凸顯了模型在遮擋數據集上的高性能。
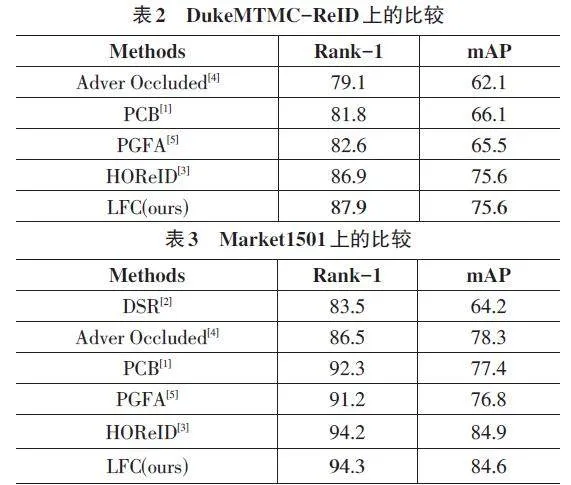
目前,一些遮擋 ReID 方法僅僅在遮擋或僅含身體部分的數據集上有改進,但它們在整體數據集上通常表現不盡如人意,這是由于特征學習和對準過程中的噪聲所致。為了展現模型的泛化能力,在整體數據集 DukeMTMC-ReID 上進行實驗。本模型在該數據集上取得了 Rank-1和mAP分別為87.9% 和75.6%的成績,在 Market1501上取得了Rank-1和mAP分別為94.3%和84.6%的成績,如表3所示。盡管本文的模型在整體數據集上并非最領先,但相較于大多數整體數據集上的模型,仍有更好的表現,表明本文方法具備較好的通用性和泛化能力。
4 結論
局部特征互補的遮擋行人重識別研究展現出巨大潛力。首先,通過姿態估計模型有效提取了含細節信息的局部特征,增強了模型的魯棒性和準確性。其次,結合人體關鍵點的連接結構,成功建立了節點之間的聯系并實現了特征信息的傳遞、融合及學習,從而顯著提升了特征的鑒別性和全局特征表示。最后,引入了多對多的軟對齊和特征互補,增強了對遮擋的感知能力,有效地處理了遮擋和干擾等問題。在實驗驗證方面,本文在多個數據集上進行了驗證實驗,結果表明所提出的框架在行人重識別任務中具有顯著的優勢和有效性。這些實驗結果為解決行人重識別中的遮擋和干擾等問題提供了新的思路和方法,有望推動行人重識別技術的進一步發展和應用。
參考文獻:
[1] SUN Y F,ZHENG L,YANG Y,et al.Beyond part models:person retrieval with refined part pooling (and A strong convolutional baseline)[C]//European Conference on Computer Vision.Cham:Springer,2018:501-518.
[2] LI W,ZHU X T,GONG S G.Harmonious attention network for person re-identification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:2285-2294.
[3] WANG G A,YANG S,LIU H Y,et al.High-order information matters:learning relation and topology for occluded person re-identification[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle,WA,USA.IEEE,2020:6448-6457.
[4] ZHANG S S,YANG J,SCHIELE B.Occluded pedestrian detection through guided attention in CNNs[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:6995-7003.
[5] HE L X,LIANG J,LI H Q,et al.Deep spatial feature reconstruction for partial person re-identification:alignment-free approach[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:7073-7082.
[6] 李爽,李華鋒,李凡.基于互預測學習的細粒度跨模態行人重識別[J].激光與光電子學進展,2022,59(10):1010010.
[7] 李枘,蔣敏.基于姿態估計與特征相似度的行人重識別算法[J].激光與光電子學進展,2023,60(6):3788/LOP212869.
【通聯編輯:唐一東】
