基于深度強(qiáng)化學(xué)習(xí)的虛擬電廠優(yōu)化調(diào)度研究
2024-09-18 00:00:00趙慶瑾
消費(fèi)電子 2024年8期
【關(guān)鍵詞】虛擬電廠;經(jīng)濟(jì)調(diào)度;深度強(qiáng)化學(xué)習(xí)
引言
分布式電源出力的隨機(jī)性與波動(dòng)性會(huì)給電力系統(tǒng)帶來電壓閃變、線路阻塞等穩(wěn)定性問題。在此背景下,虛擬電廠通過聚合配網(wǎng)側(cè)的分布式資源,使其成為一個(gè)具有一定程度可控的聚合體,有助于電力系統(tǒng)的安全穩(wěn)定運(yùn)行。
在模型優(yōu)化研究中,常采用數(shù)學(xué)規(guī)劃法、啟發(fā)式算法來求解目標(biāo)函數(shù)。由于虛擬電廠考慮實(shí)時(shí)調(diào)度,傳統(tǒng)的啟發(fā)式方法需要對每個(gè)決策重新運(yùn)行優(yōu)化過程,計(jì)算復(fù)雜度較高。強(qiáng)化學(xué)習(xí)(reinforcement learning,RL)作為一種數(shù)據(jù)驅(qū)動(dòng)的人工智能技術(shù),在智能體與環(huán)境交互過程中學(xué)習(xí)策略達(dá)成回報(bào)最大化,在電力系統(tǒng)決策領(lǐng)域得到了廣泛應(yīng)用。文獻(xiàn)[1]將電動(dòng)汽車充放電過程建模為馬爾可夫決策過程,應(yīng)用DRL算法確定充電策略,平衡了需求響應(yīng)收益與用戶滿意度。文獻(xiàn)[2]提出了一種基于分層深度強(qiáng)化學(xué)習(xí)的社區(qū)能源交易方案,顯著降低了產(chǎn)銷者的日常成本。文獻(xiàn)[3]利用無模型DRL方法優(yōu)化壓縮空氣儲(chǔ)能(CAES)與光伏聯(lián)合運(yùn)行系統(tǒng),實(shí)現(xiàn)穩(wěn)定的能量套利。文獻(xiàn)[4]利用深度強(qiáng)化學(xué)習(xí)方法來解決復(fù)合儲(chǔ)能系統(tǒng)的序列決策問題,訓(xùn)練完成后能夠根據(jù)環(huán)境場景選擇充放電動(dòng)作,實(shí)現(xiàn)實(shí)時(shí)優(yōu)化調(diào)度。[1-4]
針對虛擬電廠的實(shí)時(shí)優(yōu)化問題,本文提出了基于深度確定性策略梯度算法的虛擬電廠優(yōu)化調(diào)度方法,通過仿真驗(yàn)證了所提方法的有效性。
一、虛擬電廠優(yōu)化問題建模
(一)目標(biāo)函數(shù)
虛擬電廠經(jīng)濟(jì)調(diào)度的目標(biāo)是最大化虛擬電廠的凈收益。目標(biāo)函數(shù)如式(1):
max f=RRT+RLoad-CMT-CESS-CDR(1)
(1)市場交易收益
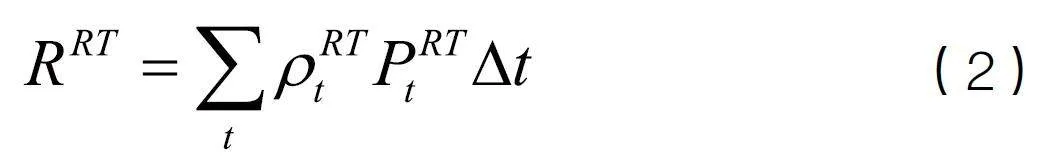
(2)內(nèi)部負(fù)荷收益

式中,ρRE"為終端電價(jià)。
(3)微型燃?xì)鈾C(jī)組成本
微型燃?xì)廨啓C(jī)成本可以通過一次函數(shù)來近似估算[5]:

式中,a 、b為燃?xì)鈾C(jī)組的成本系數(shù)。
(4)儲(chǔ)能設(shè)備成本
儲(chǔ)能的損耗成本可以通過一次函數(shù)近似估算[6]:

式中, kESS為儲(chǔ)能的損耗成本系數(shù)。
(5)需求響應(yīng)成本

式中,KdDR、KuDR"分別為削負(fù)荷和增負(fù)荷的補(bǔ)貼單價(jià);PdDR t、PuDR t"分別為在t時(shí)刻進(jìn)行削負(fù)荷和增負(fù)荷的響應(yīng)功率。
(二)約束條件
(1)系統(tǒng)功率平衡約束
PRT t+PW t+PV t+PMT t=PL t +PDR t+PESS t(7)
(2)儲(chǔ)能運(yùn)行狀態(tài)約束
SOCmin≤SOCt≤SOCmax(8)
PESS min≤PESS t≤PESS max(9)
(3)需求響應(yīng)相關(guān)約束

(4)微型燃?xì)廨啓C(jī)功率約束
PMT min≤PMT t≤PMT max(11)
二、深度強(qiáng)化學(xué)習(xí)算法
(一)算法簡介
深度確定性策略梯度(Deep Deterministic PolicyGradient,DDPG)算法是一種結(jié)合了策略梯度方法和深度學(xué)習(xí)的強(qiáng)化學(xué)習(xí)算法[7]。 DDPG在DQN算法基礎(chǔ)上進(jìn)行改進(jìn)并結(jié)合了AC框架,利用深度神經(jīng)網(wǎng)絡(luò)來近似策略函數(shù)(Actor)和價(jià)值函數(shù)(Critic),使得算法能夠在高維連續(xù)動(dòng)作空間中有效學(xué)習(xí)策略。
由于輸出的是確定性的動(dòng)作,為了兼顧訓(xùn)練過程中的探索和利用,通常對動(dòng)作增加一定的噪聲,防止算法過早地收斂到局部最優(yōu)。最終執(zhí)行的動(dòng)作的表達(dá)式為:
a=μ(s;θ)+N(12)
高斯分布噪聲和Ornstein-Uhlenbeck(OU)過程是兩種常用的動(dòng)作探索噪聲。本文采用了一種基于高斯分布噪聲的邊界逆向探索機(jī)制,其主要思想是在能量邊界進(jìn)行探索時(shí),若動(dòng)作使得能量越界,立即對動(dòng)作添加反向探索,引導(dǎo)智能體探索的方向,加速收斂。具體過程如下所示:
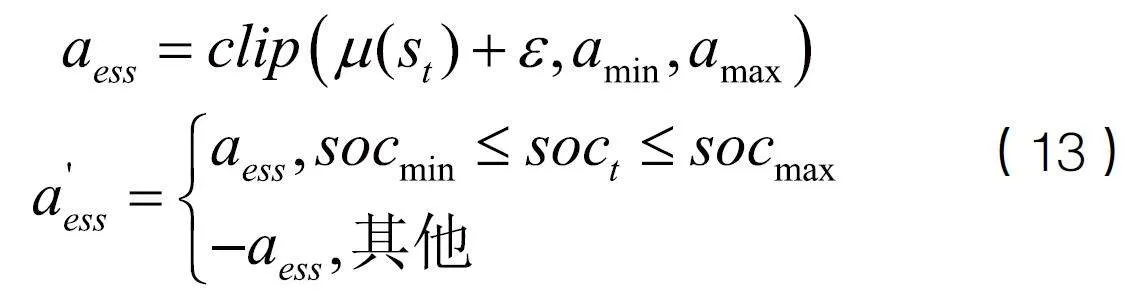
式中,clip函數(shù)確保儲(chǔ)能動(dòng)作在添加噪聲后不會(huì)超出上下界, a' ess為最終選擇執(zhí)行的儲(chǔ)能動(dòng)作。
(二)構(gòu)建馬爾可夫決策過程
(1)狀態(tài)空間
(二)構(gòu)建馬爾可夫決策過程
(1)狀態(tài)空間
狀態(tài)空間參數(shù)包括光伏實(shí)時(shí)發(fā)電功率、風(fēng)力實(shí)時(shí)發(fā)電功率、實(shí)時(shí)負(fù)荷功率、實(shí)時(shí)市場電價(jià)、儲(chǔ)能的荷電狀態(tài)。定義為:

(2)動(dòng)作空間
動(dòng)作空間參數(shù)包括儲(chǔ)能單元充放電功率、微型燃?xì)廨啓C(jī)輸出功率、需求響應(yīng)比例。定義為:
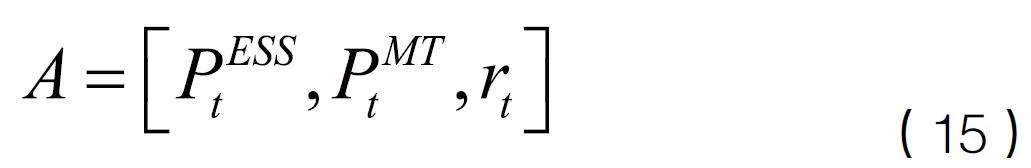
智能體在每一輪優(yōu)化過程中決策的變量為、和,購售電功率可以由功率平衡約束式(7)計(jì)算出來。
(3)獎(jiǎng)勵(lì)函數(shù)
優(yōu)化目標(biāo)是在滿足約束的前提下使虛擬電廠凈收益最大,因此獎(jiǎng)勵(lì)函數(shù)定義為:

其中,F(xiàn)為式(1)中的凈收益,ω1、ω2為權(quán)重系數(shù),用于將獎(jiǎng)勵(lì)函數(shù)標(biāo)準(zhǔn)化到同一數(shù)量級,Penalty為儲(chǔ)能荷電狀態(tài)越界懲罰。
三、算例分析
(一)運(yùn)行數(shù)據(jù)及參數(shù)設(shè)置
本文所使用的光伏發(fā)電、風(fēng)力發(fā)電和負(fù)載數(shù)據(jù)來自開源數(shù)據(jù)平臺(tái)Open Power System Date[8],以一小時(shí)為時(shí)間步長。本文的24小時(shí)電價(jià)是基于國內(nèi)某省夏季分時(shí)電價(jià),加入高斯分布噪聲形成的電價(jià)曲線,虛擬電廠對內(nèi)終端零售電價(jià)取1元/kWh。
(二)模型訓(xùn)練
本文的虛擬電廠優(yōu)化調(diào)度訓(xùn)練任務(wù)在Python3.9環(huán)境下運(yùn)行。在使用DDPG算法進(jìn)行訓(xùn)練時(shí),先將狀態(tài)輸入的各個(gè)變量歸一化到同一數(shù)量級,以避免訓(xùn)練過程中出現(xiàn)梯度消失的現(xiàn)象。在每回合開始時(shí),儲(chǔ)能單元SOC會(huì)初始化至40%。
獎(jiǎng)勵(lì)的收斂過程如圖所示:
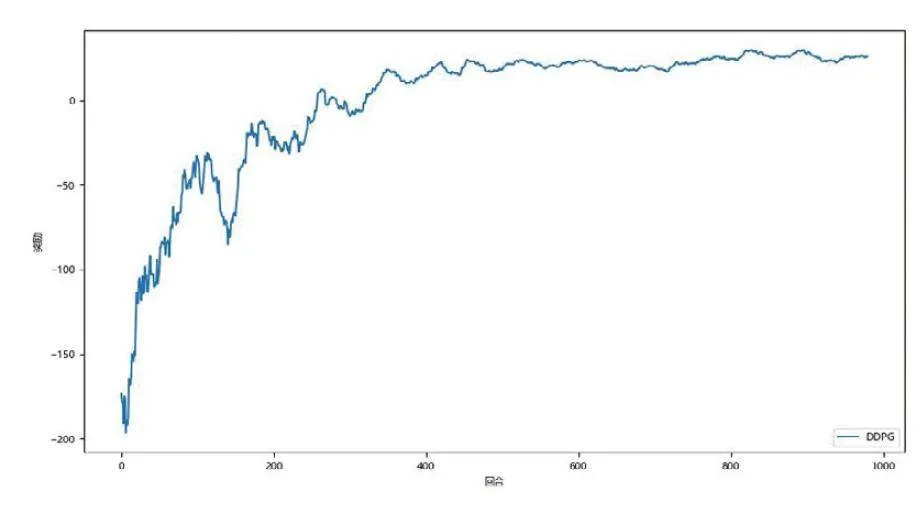
可以看出,在訓(xùn)練的初期越界的情況不可避免,隨著訓(xùn)練的進(jìn)行獲得的獎(jiǎng)勵(lì)震蕩上升,逐漸收斂到一個(gè)穩(wěn)定的值附近。
(三)結(jié)果分析
將訓(xùn)練好的模型保存,選取某典型日進(jìn)行在線決策。

從優(yōu)化的結(jié)果來看,儲(chǔ)能單元在電價(jià)較低的3:00-10:00選擇充電動(dòng)作,在電價(jià)較高的16:00-24:00選擇放電動(dòng)作,基本實(shí)現(xiàn)了低充高放的套利策略。微型燃?xì)廨啓C(jī)選擇在電價(jià)較低的時(shí)段選擇以最小發(fā)電功率運(yùn)行,電價(jià)較高時(shí)選擇高功率運(yùn)行。這是因?yàn)樵陔妰r(jià)高于微型燃?xì)廨啓C(jī)邊際發(fā)電成本時(shí),此時(shí)發(fā)電取得正向的收益,當(dāng)電價(jià)低于微型燃?xì)廨啓C(jī)邊際發(fā)電成本時(shí),則僅保持最低發(fā)電功率,電力缺口由市場購電補(bǔ)充。結(jié)合電價(jià)和終端電價(jià)的關(guān)系,可以看出需求響應(yīng)計(jì)劃與兩者的差額有關(guān),在電價(jià)較低的時(shí)段,此時(shí)選擇增加負(fù)荷,在減去補(bǔ)貼成本后,以內(nèi)部終端電價(jià)向用戶收取增負(fù)荷部分的電費(fèi)時(shí)仍能從中獲利。在電價(jià)較高的時(shí)段,選擇發(fā)布削減負(fù)荷的指令,將節(jié)約下來的負(fù)荷部分的等效出力以高電價(jià)在市場售出套利。
結(jié)語
本文提出了一種基于深度強(qiáng)化學(xué)習(xí)DDPG算法的虛擬電廠優(yōu)化調(diào)度策略。實(shí)驗(yàn)結(jié)果顯示,所提出的基于DRL的模型可以有效識(shí)別環(huán)境中狀態(tài)信息并做出合理的調(diào)度安排以提高虛擬電廠的凈收益。此外,本文的模型未考慮分布式資源接入配網(wǎng)時(shí)的系統(tǒng)潮流約束,兼顧經(jīng)濟(jì)和安全調(diào)度將是下一步研究的重點(diǎn)。
參考文獻(xiàn):
[1] JIN, RUIYANG, ZHOU, YUKE, LU, CHAO, et al. Deep reinforcement learning-based strategy for charging"station participating in demand response[J]. Applied energy,2022,328(Dec.15):1-13.
[2] L. Yan, X. Chen, Y. Chen and J. Wen. A Hierarchical Deep Reinforcement Learning-Based Community"Energy Trading Scheme for a Neighborhood of Smart Households[J].in IEEE Transactions on Smart Grid,2022,13(6):4747-4758.
[3] AMIRHOSSEIN DOLATABADI, HUSSEIN ABDELTAWAB, YASSER ABDEL-RADY I. MOHAMED. Deep Reinforcement"Learning-Based Self-Scheduling Strategy for a CAES-PV System Using Accurate Sky Images-Based Forecasting[J].IEEE Transactions on Power Systems: A Publication of the Power Engineering Society,2023,38(2):1608-1618.
[4] 張自東, 邱才明, 張東霞, 等. 基于深度強(qiáng)化學(xué)習(xí)的微電網(wǎng)復(fù)合儲(chǔ)能 協(xié)調(diào)控制方法[J]. 電網(wǎng)技術(shù),2019,43(6):1914-1921.
[5] 張虹, 馬鴻君, 閆賀, 等. 計(jì)及WCVaR 評估的微電網(wǎng)供需協(xié)同兩階段日前優(yōu)化調(diào)度[J]. 電力系統(tǒng)自動(dòng)化,2021,45(2):55-63.
[6] Hongseok K ,Joohee L ,Shahab B , et al.Direct Energy Trading of Microgrids in Distribution Energy"Market[J].IEEE Transactions on Power Systems,2020,35(1):639-651.
[7] Lillicrap P T ,Hunt J J ,Pritzel A , et al.Continuous control with deep reinforcement learning.[J].CoRR,2015,abs/1509.02971
[8] Wiese F ,Schlecht I ,Bunke W , et al.Open Power System Data – Frictionless data for electricity"system modelling[J].Applied Energy,2019,236401-409.
