基于SENT改進的遠程監督關系抽取方法
2024-09-21 00:00:00趙明劉勝全岳柳
現代電子技術 2024年16期

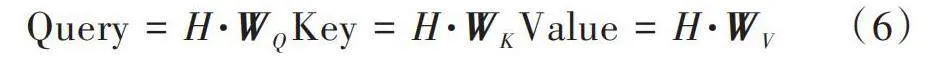

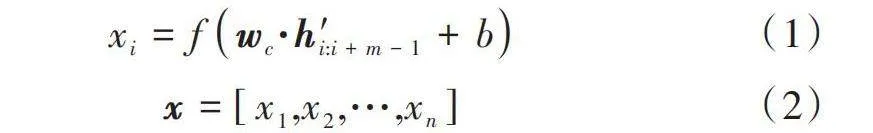
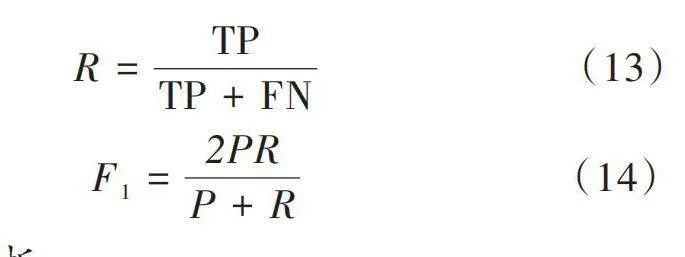
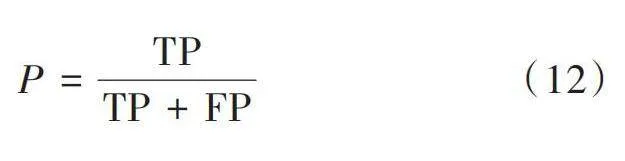

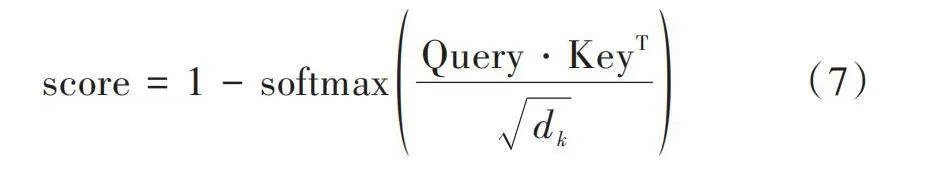
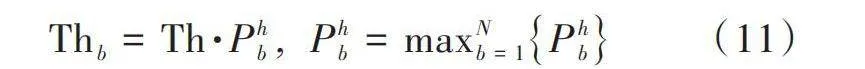
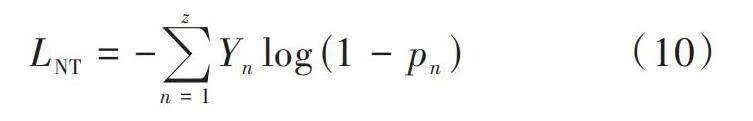


摘" 要: 遠程監督關系抽取可以在非人工標注條件下自動構建數據集,而基線模型SENT可以將負訓練思想引入到該場景進行關系抽取任務。但基線模型使用雙向長短期記憶網絡提取特征,主要注重長距離依賴關系的學習,在關注局部上下文中的特征方面存在不足,對于局部特征捕捉不夠充分;同時基線模型在負訓練訓練模型時,未能重點關注與互補標簽相關的特征,對互補標簽信息的學習不足,這影響了對噪聲數據的識別能力。為了解決這些問題,文中引入卷積神經網絡,通過卷積核在輸入關系序列上進行卷積操作,從而捕捉到輸入關系實例中的局部信息,提高模型對于輸入數據的局部特征學習能力。針對模型對互補標簽特征未能關注的問題,引入逆向注意力機制,通過調整與互補標簽相關的隱藏單元的權重,使模型能夠有選擇性地關注與互補標簽相關的信息,從而提高模型對基于互補標簽的噪聲數據的識別性能,進一步改善模型關系抽取性能。通過NYT10數據集對所設計的方法進行了驗證,結果表明,所提方法相較于基線模型在NYT10數據集關系抽取任務中F1值提高了4.84%,有效地提高了模型遠程監督關系的抽取能力。
關鍵詞: 遠程監督; 關系抽取; 基線模型SENT; 負訓練; 注意力機制; 互補標簽; 深度學習
中圖分類號: TN711?34" " " " " " " " " " " " " " "文獻標識碼: A" " " " " " " " " " " 文章編號: 1004?373X(2024)16?0051?07
Method of distantly supervised relation extraction based on improved SENT
ZHAO Ming1, LIU Shengquan2, YUE Liu1
(1. College of Software, Xinjiang University, Urumqi 830000, China; 2. College of Computer Science and Technology, Xinjiang University, Urumqi 830000, China)
Abstract: The distantly supervised relation extraction can automatically construct datasets under non manual annotation conditions. The baseline model SENT (sentence?level distant relation extraction via negative training) can introduce negative training ideas into the scene for relation extraction tasks. However, in the baseline model, BiLSTM (bi?directional long short?term memory) is used to extract features, mainly focusing on learning long?distance dependencies. There are shortcomings in focusing on features in local contexts, and local features are not captured adequately. The baseline model fails to focus on the features related to complementary labels during negative training, and the learning of complementary label information is insufficient, which affect the recognition ability of noisy data. On this basis, the convolutional neural network is introduced, and the convolutional operation is conducted on the input relation sequence by means of convolutional kernel, so as to capture local information in the input relation instance and improve the model′s local feature learn ability of the input data. In allusion to the problem that the model fails to pay attention to complementary label features, a reverse attention mechanism is introduced. By adjusting the weights of hidden units related to complementary labels, the model can selectively focus on information related to complementary labels, thereby improving the recognition performance of the model on noisy data based on complementary labels and further improving the relation extraction performance of the model. The designed method is verified by means of the NYT10 dataset, and the results show that, in comparison with the baseline model, the F1 value of the proposed method in the NYT10 dataset relation extraction task is increased by 4.84%, which can effectively improve the model′s ability of the distantly supervised relation extraction.
Keywords: distant supervision; relation extraction; baseline model SENT; negative training; attention mechanism; complementary label; deep learning
隨著信息科技的迅速進步,互聯網上的數據量急劇膨脹,這些數據大多以非結構化的形式出現,使得人們難以直接從中提取有價值的信息。在信息提取過程中,關系抽取屬于關鍵的環節,指的是基于特定的文本而提取實體之間的關系。有監督方法運用過程中依賴于大規模標注語料,然而實際中此類語料并不多,無法滿足算法的要求。人工標注語料的效率較低,成本較高,為了節省人工標注成本,緩解數據稀缺性問題,遠程監督技術被提出,并因其能夠自動生成大規模標注數據而越來越受歡迎。遠程監督[1]本質上需要將文本、知識圖譜實現實體對齊,基于后者所提供的實體關系即可進行標注。雖然這種方式大幅減少了手工標記的需求,但也引入許多不精確的數據即噪聲數據。
在關系抽取的特征提取方面,一些研究表明局部特征對噪聲數據識別具有重要性,局部特征在關系抽取任務中發揮著關鍵作用。例如,文獻[2]提出LPD?GCN,在圖卷積神經網絡中引入局部節點特征重建模塊,提高了模型的圖分類能力。在研究與互補標簽相關特征方面,文獻[3]提出了SelNLPL方法,通過使用互補標簽來訓練卷積神經網絡,對正訓練進行擴展,提高了模型的噪聲過濾性能。文獻[4]提出WCLL方法,該方法利用類不平衡互補標簽對加權經驗風險最小化損失進行建模,利用互補標簽來訓練分類器,以提高模型對正負樣本的識別能力。這些研究結果表明,與互補標簽相關的特征有助于提高模型噪聲過濾性能。
基線模型SENT[5]捕捉局部特征存在不足,同時未能重點關注與互補標簽相關的特征。考慮到上述問題,本文提出一種基于SENT改進的遠程監督關系抽取方法,主要有以下兩點貢獻。
1) 提出一種基于SENT改進的方法CRA?SENT(Convolutional Neural Network," Reverse Attention and Sentence?level Distant Relation Extraction via Negative Training)。在遠程監督公共數據集NYT10上進行實驗,并通過對比實驗和消融實驗驗證了所提方法的有效性。
2) 通過引入CNN對輸入序列數據進行特征提取,解決了局部特征捕捉能力不足的問題。引入逆向注意力,重點關注與互補標簽相關的特征,提高模型對互補標簽特征的關注,使模型能有效區分正負樣本。
1" 相關工作
雖然在語料擴展過程中可以采用遠程監督方法,但也容易降低標注的精度,導致一定的錯誤。不少學者針對上述問題進行了研究,提出了一些解決的對策。其中,文獻[6]構建了一個對噪聲標簽具有較好抗干擾性的損失函數。通過量化分析噪聲標簽及負樣本所帶來的不良影響,并運用線性規劃技巧將這些不良影響降至最低。文獻[7]創新地提出一種抽取方法,該方法融合了位置特征注意力和選擇性包注意力機制。該方法能夠篩選出噪聲程度各異的包,并將它們組合成包對進行訓練。其次,在包級別進行去噪處理,從而有效地平衡不同包對間的噪聲干擾。文獻[8]提出利用殘差和注意力機制來強化關鍵詞權重的方法,并保證語義信息的有效傳遞。這種方法不僅增強了模型對有效特征的識別能力,同時也提高了對噪聲標簽的魯棒性。除了上述研究之外,文獻[9]在設計的遠程監督關系抽取方法中引入了知識圖譜,利用圖注意力網絡對異構信息圖進行編碼,成功實現關系抽取。
文獻[10]將負訓練引入到遠程監督關系抽取中,并提出一個句子級的框架SENT。采取負訓練的方式改善模型的識別效果,并獲得了當時最優的噪聲識別效果,但該方法存在局部特征捕捉較弱的問題,同時在負訓練過程中未能重點關注與互補標簽相關的特征,以及對互補標簽信息學習不足的問題。針對以上問題,本文引入CNN進行局部特征的捕捉,同時引入逆向注意力,使模型在訓練過程中有選擇性地關注學習與互補標簽相關的特征。
2" 基于SENT改進的遠程監督關系抽取方法
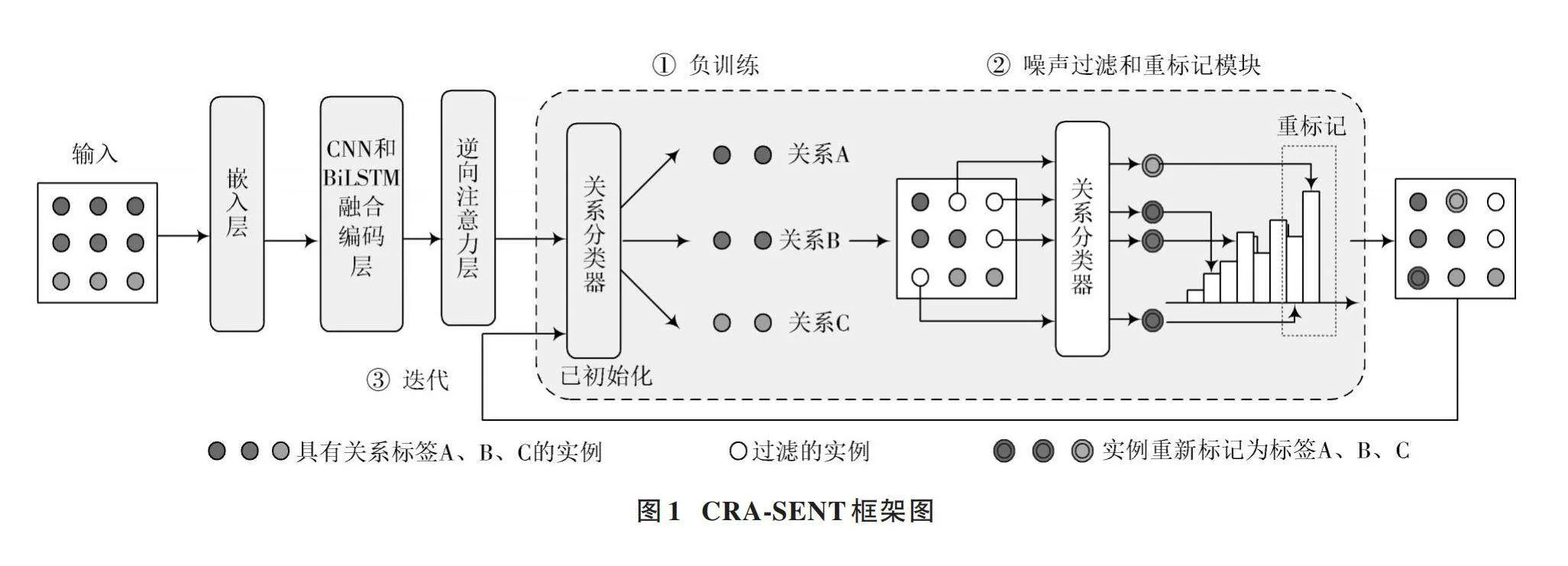
本文為解決SENT方法中存在的不足,提出了基于SENT改進的遠程監督關系抽取方法CRA?SENT。CRA?SENT框架圖如圖1所示。
首先,原始文本數據經過嵌入層后,將文本數據轉化為詞向量。這些詞向量表示文本中單詞的語義信息。接下來,將這些詞向量傳入卷積神經網絡(CNN)和雙向長短期記憶網絡(BiLSTM)融合編碼層。在這個編碼層中,CNN負責捕捉詞向量中的局部特征,而BiLSTM負責捕捉詞向量中的長期依賴關系和上下文信息,以便更全面地理解文本信息,CNN和BiLSTM融合編碼層的輸出(H)包含深層次的語義信息。引入逆向注意力對H進行處理,對與互補標簽相關的特征賦予較高的權重,通過負訓練損失函數訓練模型,降低模型對噪聲數據的預測值,采取動態閾值自適應函數進行過濾,并對部分存在錯誤標注的樣本進行重標記,最后對修改后的數據集進行關系抽取。
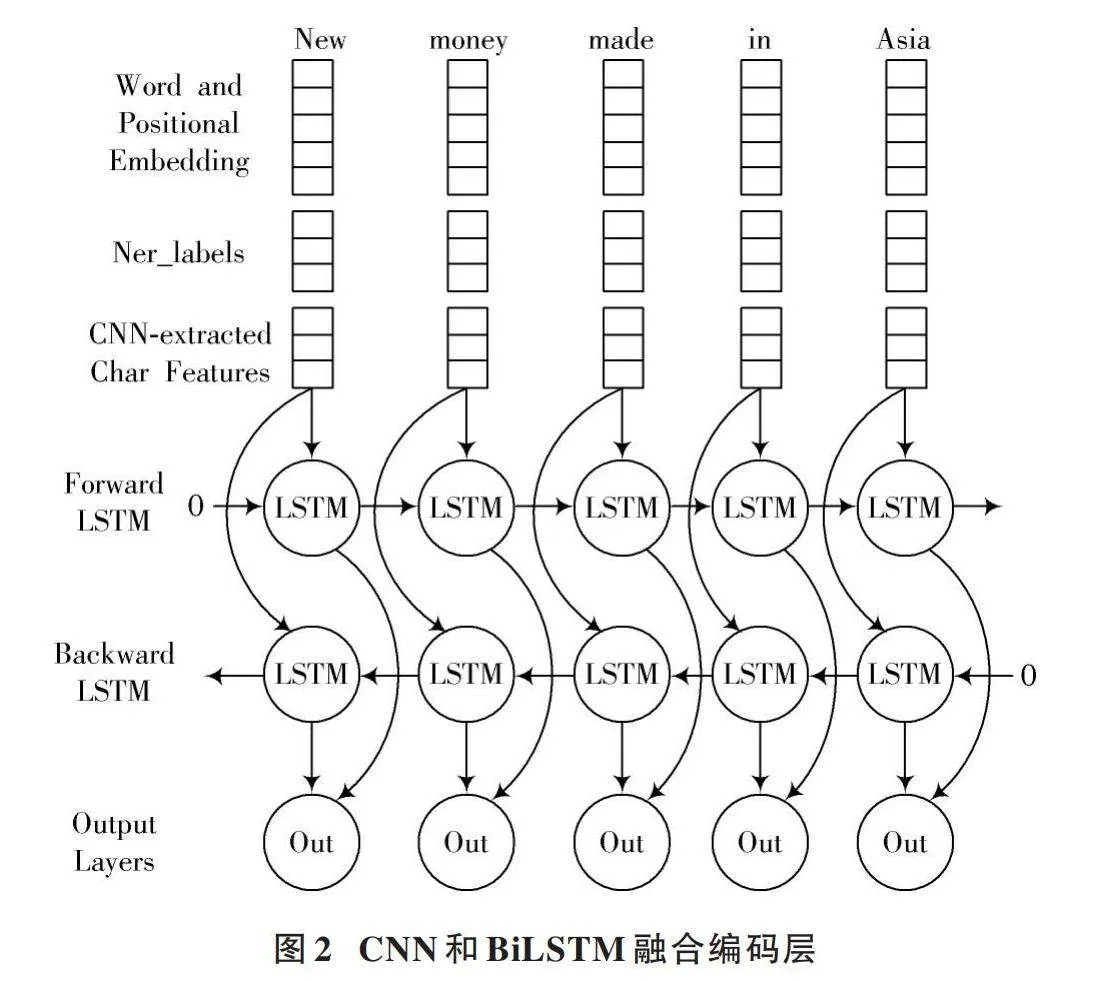
2.1" CNN和BiLSTM融合編碼層
在本文方法中,采用了一種融合CNN和BiLSTM的編碼層,用于對輸入文本序列進行特征提取和建模,如圖2所示。
首先,CNN被用于捕獲文本序列中的局部特征,通過卷積核在不同位置進行滑動以提取詞語之間的局部關系;然后,CNN提取的局部特征被輸入到BiLSTM中,BiLSTM能夠在已提取特征的基礎上進一步編碼全局信息,從而更好地理解整個文本序列的語義和結構。
在提取局部特征過程中,選擇了3個長度不同、寬和h(輸入數據h由詞嵌入、位置嵌入和命名實體嵌入組合得到)一致的卷積核,并采取了滑動窗口的方式,特征圖的形式如下所示:
[xi=fwc·h′i:i+m-1+b] (1)
[x=[x1,x2,…,xn]] " " " " "(2)
式中:wc表示權重矩陣;b、m分別表示偏差項、滑動步長;f(·)表示sigmoid函數;[h′i:i+m-1]表示自位置i移動m個詞向量得到的矩陣;xi表示位置i的卷積特征值。
其次,本文采用隱藏大小為256的單層BiLSTM對CNN提取的特征x進行進一步的特征提取,特征圖表示為:
[ht=LSTM(xt,ht-1,Ct-1)]" " " "(3)
[ht=LSTM(xt,ht-1,Ct-1)]" " " " (4)
[ht=[ht,ht]]" " " " " " "(5)
式中:[ht]是LSTM正向隱藏層狀態向量,其計算依賴于當前輸入[xt]、上一時刻的隱藏層狀態向量[ht-1]和上一時刻的記憶單元向量[Ct-1];[ht]是LSTM反向隱藏層狀態向量,其計算依賴于當前輸入[xt]、上一時刻的隱藏層狀態向量[ht-1]和上一時刻的記憶單元向量[Ct-1];最終的雙向隱藏狀態[ht]通過將正向和反向隱藏狀態進行拼接得到。
2.2" 逆向注意力層
在關系抽取任務中,輸入通常是包含實體對及其上下文的句子或文本。注意力機制通過計算每個單詞或子詞與實體對之間的關聯程度,自適應地為句子的不同部分分配不同的注意力權重。這種關聯程度可以基于不同的機制來計算。為了使模型適應負訓練的目標,本文引入逆向注意力[11],與傳統注意力機制通過softmax 操作獲得權重分布,強調輸入序列中與預測相關的部分不同。本文引入的逆向注意力機制通過1-softmax操作,調整CNN和BiLSTM融合編碼層的輸出權重,有選擇性地降低與當前句子標簽相關的隱藏單元的權重,并提高與互補標簽相關的隱藏單元的權重。
逆向注意力的計算過程如下。
1) 對輸入H的查詢、鍵和值進行線性變換:
[Query=H·WQKey=H·WKValue=H·WV] (6)
式中[WQ]、[WK]、[WV]是線性變換的權重矩陣。
2) 計算注意力分數:
[score=1-softmaxQuery?KeyTdk]" "(7)
式中[dk]是鍵的維度。與傳統的注意力不同,逆向注意力在此進行取反操作,使得模型關注與互補標簽相關的隱藏單元,從而提高該部分的權重。
3) 對得到的注意力分數與值進行加權求和,得到輸出O:
[O=score·Value]" " " "(8)
4) 將得到的輸出O與之前的H進行拼接,得到最終輸出M:
[M=O+H]" " " " "(9)
逆向注意力在特征處理過程中發揮關鍵作用。通過調整模型對輸入序列中不同部分的關注程度,逆向注意力使得模型更專注于學習與互補標簽相關的特征。這種調整對于負樣本的學習尤為重要。模型通過學習與互補標簽相關的特征,對于噪聲數據的預測更加精準,從而提高了噪聲過濾能力。
2.3" 負訓練
最初,在圖像處理研究中出現了負訓練方法,這種方法有助于改善算法的魯棒性。近些年也有學者進行研究與應用[12?13]。對于遠程監督關系抽取問題而言,假定有三元組(實體1、2,關系1),已知實體1、2均存在句子中,盡管不能確定關系1即為二者的真實關系,但是可以采用錯誤關系標簽進行訓練,通過這種方式驗證其他關系對應著更高的錯誤概率。負訓練的損失函數形式如下:
[LNT=-n=1zYnlog(1-pn)]" " (10)
式中:[Yn]表示樣本n的初始標簽,未必是正確的;z代表樣本總數目。目標是降低互補標簽的概率,模型通過損失函數訓練將錯誤標簽的預測概率pn逐漸降低,最終接近于0。
輸入數據為遠程監督所得的數據,這些數據中含有噪聲,在編碼層等處理完成之后即可進行負訓練。如果降低噪聲數據被預測為原標簽的概率,那么非噪聲數據有更高的概率被預測為原標簽。
根據上述標準對閾值進行合理的設置,將預測概率中超過閾值的、未超過閾值的分別作為非噪聲、噪聲數據。另外,由于并不能保證樣本始終處于均勻的分布狀態,在劃分過程中難以使用統一的閾值,本文設定了動態閾值。
2.4" 噪聲數據過濾
第2.3節設計的負訓練模型可以更好地識別噪聲數據,例如在圖3中,輸入樣本最初對應類別5,然而預測其屬于5的概率只有0.1,預測屬于類別2的概率反而更高,為0.5。
針對原標簽預測概率和閾值進行比較,即可確定樣本標記的準確性。假定概率值按照一定分布:噪聲數據傾向于聚集在較低概率區域,而干凈數據則位于中到高概率區域。為更精確地評估預測概率的大小,采用動態閾值函數,如式(11)所示。
[Thb=Th·Phb ," Phb=maxNb=1Phb] (11)
對于第i個實例在類別b的概率[Pib]∈(0,[Phb)],其中[Phb]是類b的最大概率,[Th]為全局閾值。該動態閾值函數會依據每個類別的收斂情況來動態調整閾值,以精確地篩選出各個關系類別的噪聲數據,并確定噪聲數據過濾時的閾值大小。
2.5" 噪聲樣本重標記
通過應用動態閾值函數進行噪聲數據的判斷,這類數據可被分為兩種情況:第一種是在已定義的關系類型內,此類數據的關系標簽是準確的,只需要重新進行標注,即可將其真正轉換為正確的數據;第二種是沒有任何已知關系類型內正確的關系標簽數據。如果噪聲數據存在正確關系類型,通過重新標注以正確的方式進行分類,可以提高數據集質量和模型關系抽取性能。
重標記策略描述為:已知α代表動態閾值函數所確定的閾值,如果數據預測為原有標簽的概率小于α,即可認為其屬于噪聲數據。假定有重標注閾值Threlabel,對于已確認的噪聲數據,預測為其他標簽的最大概率高于Threlabel,即可認為此數據具有對應的正確標簽,因此應將其重新標注為該最高概率所對應的標簽;若最高概率值低于Threlabel,則認為在已定義的關系類別中不存在該數據對應的關系,標簽標記為NA。
3" 實驗與結果分析
3.1" 數據集
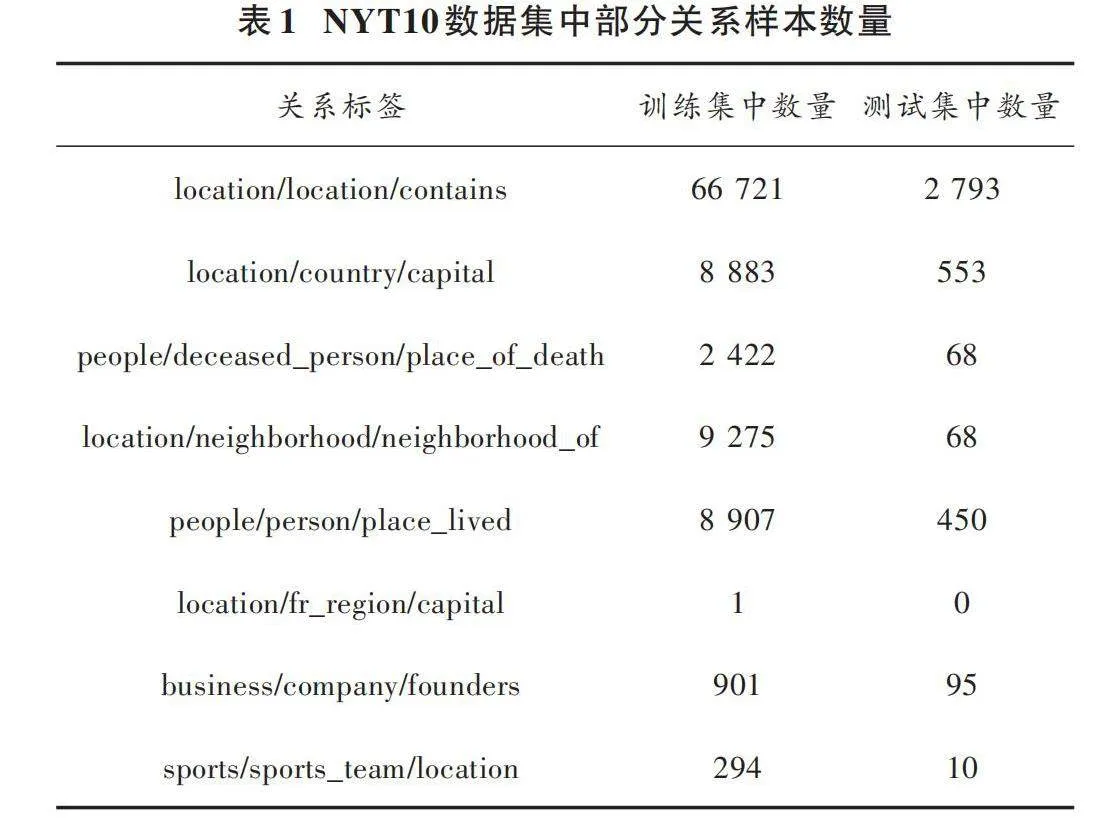
在實驗中主要采用了遠程監督關系抽取任務中廣泛使用的NYT10數據集。NYT10數據集是由NYTcorpus和Freebase遠程監督得到,對于給定的句子和兩個做了標注的名詞,可從給定的關系清單中選出最合適的關系。NYT10數據集中一共包含52+1(包括NA)個關系,數據集中包括了10個不同的關系類別,每個類別有大約1 200個正樣本和大量的負樣本。該數據集被廣泛用于自然語言處理研究,包括關系抽取模型的開發和評估、遷移學習等領域的研究。NYT10數據集中部分關系樣本數量如表1所示。
3.2" 基" 線
為驗證本文提出的CRA?SENT的有效性,將其與近幾年提出的降噪方法和模型進行了對比。
PCNN+RA_BAG_ATT[14]:一種包級模型,包含包內和包間的注意,以減輕噪聲影響。
ARNOR[15]:基于所選模式的注意力得分選擇可信實例的句子級關系抽取模型。這是句子水平上最先進的方法。
SENT[5]:在噪聲過濾過程中采用了負訓練,即通過這種方式進行降噪的關系抽取方法。
3.3" 實驗設置
本文提出的方法采用Glove訓練得到詞向量,使用Adam作為優化器,具體實驗參數如表2所示。
3.4" 實驗評估標準
在實驗中,本文選取了精確率、召回率和F1分數作為評估指標,來衡量提出的關系抽取模型的性能,計算方法如式(12)~式(14)所示。精確率代表在模型識別出的全部關系中,正確識別結果所占據的比例;召回率代表在全部真實關系中,模型正確識別的關系所占據的比重大小;F1分數是上述兩個指標的調和平均數,能夠綜合衡量模型的性能。
[P=TPTP+FP]" " " "(12)
[R=TPTP+FN]" " " "(13)
[F1=2PRP+R]" " " " "(14)
3.5" 實驗結果與分析
3.5.1" 對比實驗
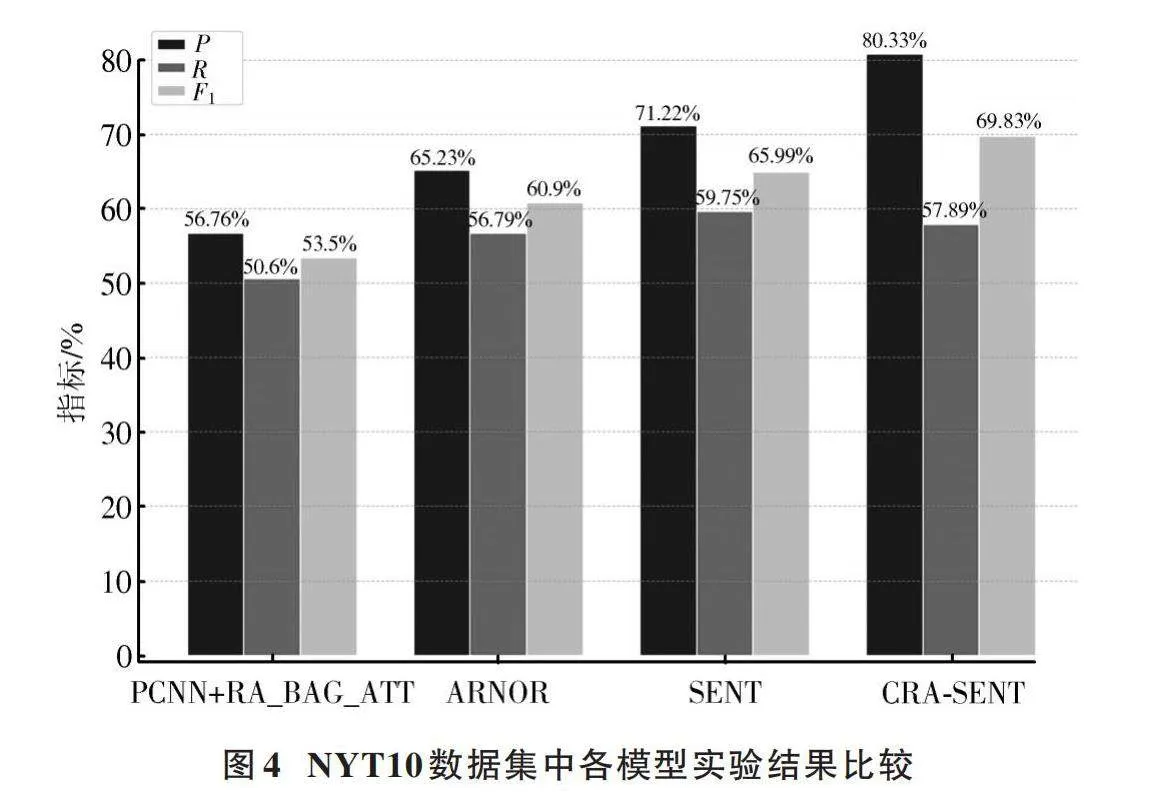
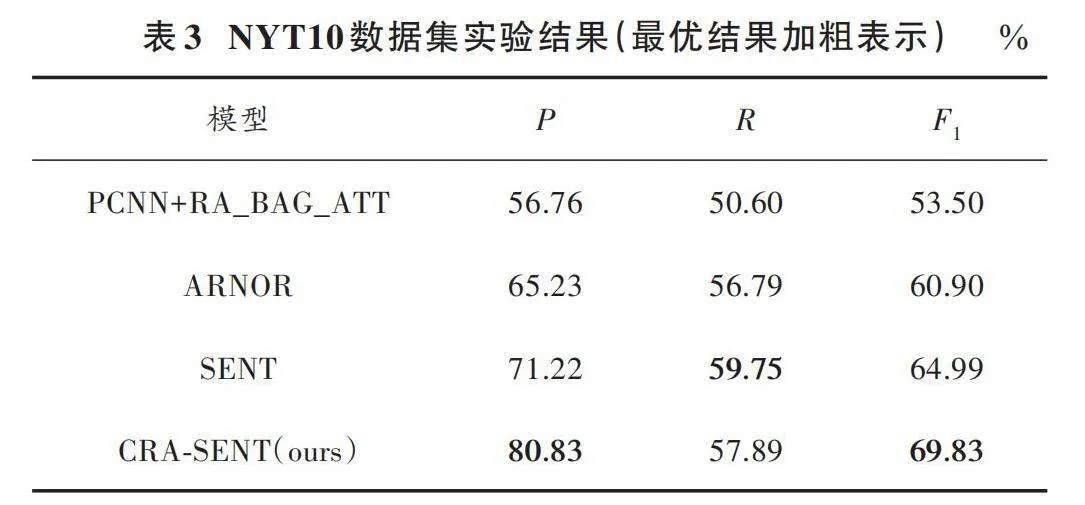
在NYT10數據集中進行對比實驗,實驗結果如表3所示。由表3可以看出,CRA?SENT在NYT10數據集上表現良好。
由表3可知,所提方法相較于基線模型在NYT10數據集關系抽取任務中F1值提高4.84%。
圖4所示為各個模型的實驗結果。由圖可以看出,CRA?SENT在精確率和F1值上與基線模型相比有明顯的提升。可以分析得出:相比于SENT方法,引入CNN提高模型對局部特征的捕捉能力,以及引入逆向注意力使模型在訓練中提高了與互補標簽相關的信息的關注,所以本文所提方法在NYT10數據集上獲得了更高的精確率和F1值。
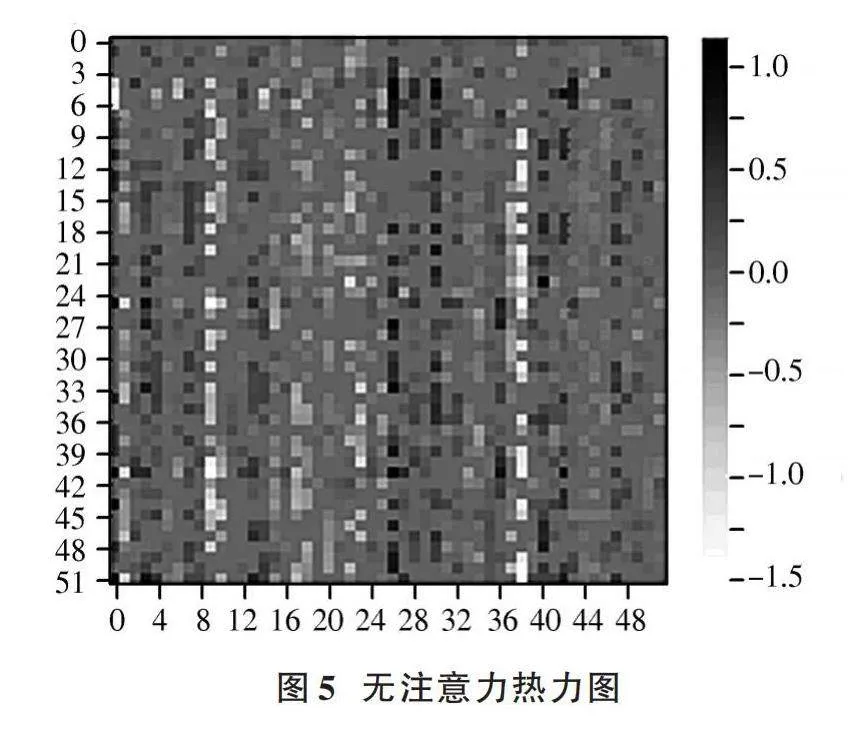
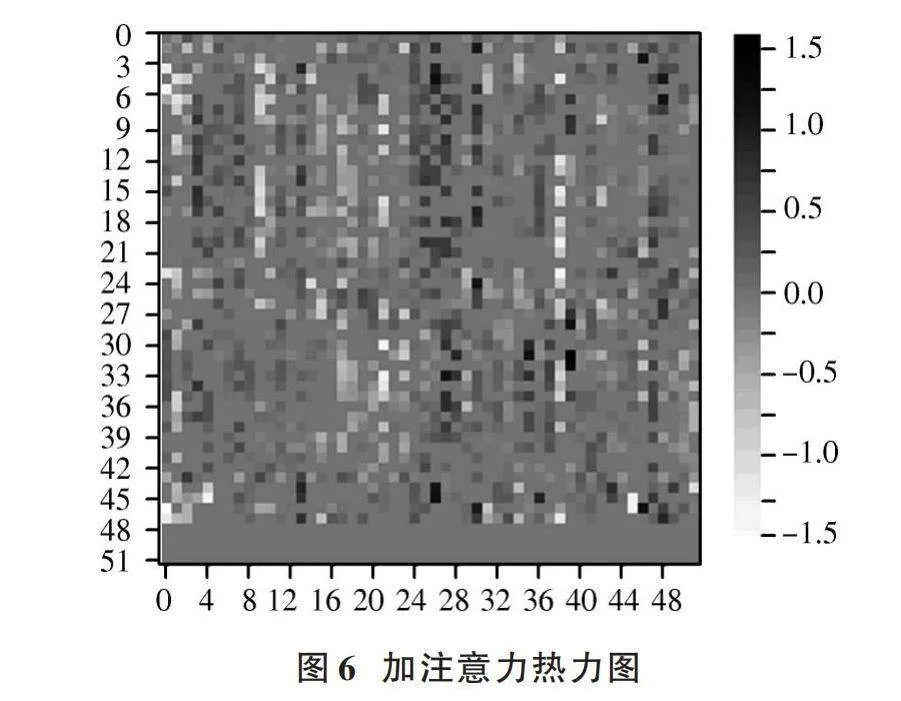
3.5.2" 注意力實驗
為直觀地看出逆向注意力對模型的影響,進行注意力實驗。本文分別對有無注意力得到的權重進行熱力圖繪制,如圖5、圖6所示。由圖5和圖6可以看出,在加入注意力之后,模型降低了當前標簽相關特征的權重,并對互補標簽賦予較高的權重。
同時通過表5的消融實驗可以看出,逆向注意力的引入對于模型的精確率和F1值均有顯著影響,由此可以分析得到逆向注意力的加入影響了模型對于特征的學習,通過逆向注意力模型將關注度放在與當前標簽相反的互補標簽的特征上,有助于提高模型對于基于互補標簽的噪聲數據識別能力,從而提高模型在遠程監督關系抽取任務上的性能。
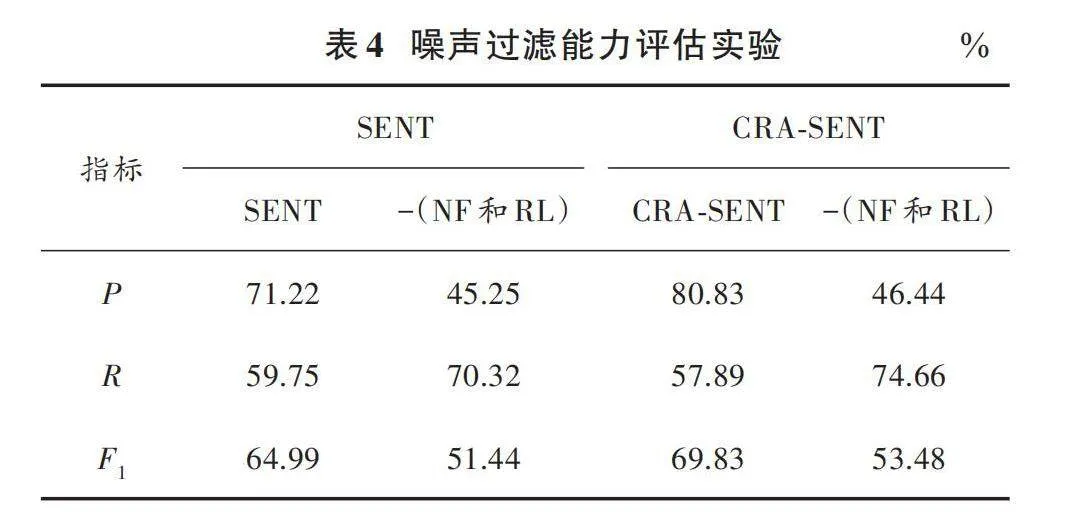
3.5.3" 噪聲過濾能力評估實驗
本文進行噪聲數據的過濾能力對于關系抽取性能的影響實驗,實驗結果如表4所示。表4中的-(NF和RL)表示在方法中去掉噪聲過濾和重標注方法。
通過表4實驗結果,分析得出以下結論。
1) 噪聲過濾和重標注部分對于模型關系抽取性能有較大的影響。噪聲過濾和重標注能幫助模型過濾掉錯誤標注的噪聲樣本,并能夠通過重新標注一部分樣本來提高數據集的質量,提高模型對于正例樣本的準確性,從而提高模型關系抽取的精確率。重標注可能導致一些樣本標簽的改變,從而影響了召回率的表現,但整體來說,噪聲過濾和重標注能有效地提高模型關系抽取性能。
2) 加入噪聲過濾和重標注后發現,相較于SENT方法,提出的CRA?SENT方法關系抽取性能較好。這是由于引入了CNN和逆向注意力,導致模型在噪聲過濾和重標注部分能更有效地識別噪聲數據并進行重標注,提高了模型對正負樣本的識別能力,從而提高了精確率和關系抽取性能。
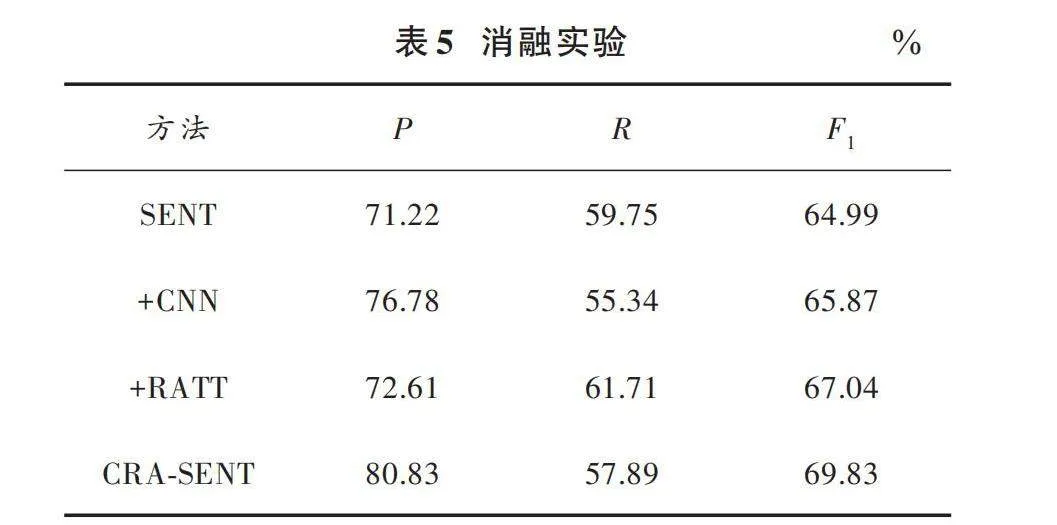
3.5.4" 消融實驗
為探究本文引入的卷積神經網絡和逆向注意力對CRA?SENT性能的影響,在NYT10上進行消融實驗,實驗結果如表5所示。表5中,+CNN和+RATT分別表示在基線模型SENT上引入卷積神經網絡和逆向注意力。
對消融實驗結果進行分析,所得結論如下。
1) +CNN。從實驗數據中可以看出,在SENT方法上引入CNN導致模型的精確率上升,是因為引入CNN增強了模型在捕獲輸入序列中的局部特征的能力,從而提高了模型對正樣本的識別能力。但相較于SENT方法,召回率有所下降,可能是因為模型的關注重點會偏向局部特征,導致在預測時會錯過一些全局上下文中的關鍵信息。而相較于SENT方法引入CNN后模型的F1值有所上升,說明了模型的總體性能有所提升。
2) +RATT。從實驗數據可以看出,在SENT方法上引入逆向注意力使得模型的精確率、召回率和F1均有所上升。可以分析得到,通過引入逆向注意力對編碼層的輸出進行處理,能使模型在訓練中更有針對性地關注與互補標簽相關的隱藏狀態,從而降低與正確標簽相關的隱藏狀態的權重,使得模型通過關注與互補標簽相關的信息,能有效識別出正負樣本。有針對性地關注與互補標簽相關的隱藏狀態,從而降低與正確標簽相關的隱藏狀態的權重,使得模型通過關注與互補標簽相關的信息,能有效識別出正負樣本。
4" 結" 語
本文提出一種基于SENT改進的遠程監督關系抽取方法,該方法能夠有效地辨識并過濾出噪聲數據,增強了模型在處理遠程監督產生的噪聲方面的能力,并提高了關系抽取任務的準確性。實驗結果顯示,本文方法在過濾噪聲數據方面和關系抽取任務中表現出了較好的效果,相對于傳統方法提升效果顯著。然而本文方法只是面向特定關系域范圍,后續仍然需要繼續研究用于開放域的方法。
注:本文通訊作者為劉勝全。
參考文獻
[1] 尚蘭蘭.基于遠程監督的關系抽取研究綜述[J].河北省科學院學報,2022,39(6):1?8.
[2] LIU W, GONG M, TANG Z, et al. Locality preserving dense graph convolutional networks with graph context?aware node representations [J]. Neural networks, 2021, 143: 108?120.
[3] KIM Y, YIM J, YUN J, et al. NLNL: negative learning for noisy labels [C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV)." Seoul, South Korea: IEEE, 2019: 101?110.
[4] WEI M, ZHOU Y, LI Z, et al. Class?imbalanced complementary?label learning via weighted loss [J]. Neural networks: the official journal of the international neural network society, 2023(2): 166.
[5] MA R, GUI T, LI L, et al. SENT: sentence?level distant relation extraction via negative training [EB/OL]. [2023?08?17]. https://www.researchgate.net/.
[6] DENG L, YANG B, KANG Z, et al. A noisy label and negative sample robust loss function for DNN?based distant supervised relation extraction [J]. Neural networks, 2021(139): 358?370.
[7] WANG J S, LIU Q X. Distant supervised relation extraction with position feature attention and selective bag attention [J]. Neurocomputing, 2021(461): 552?561.
[8] ZHENG Z, LIU Y, DUN L, et al. Distant supervised relation extraction based on residual attention [J]. Frontiers of computer, 2022, 16(6): 3.
[9] 趙晉斌,王琦,馬黎雨,等.基于知識圖譜的遠程監督關系抽取降噪方法[J].火力與指揮控制,2023,48(10):160?169.
[10] XIE C, LIANG J, LIU J, et al. Revisiting the negative data of distantly supervised relation extraction [C]// Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2021: 277.
[11] LI D, TIAN Z, XUE L, et al. Enhancing content preservation in text style transfer using reverse attention and conditional layer normalization [EB/OL]. [2023?08?17]. https://www.xueshufan.com/publication/3190069702.
[12] 陳克正,鐘勇.基于實體注意力和負訓練的遠程監督噪聲過濾方法[J].計算機應用,2022,42(z2):42?46.
[13] YU M, CHEN Y, ZHAO M, et al. Semantic piecewise convol?utional neural network with adaptive negative training for distantly supervised relation extraction [J]. Neurocomputing, 2023, 537: 12?21.
[14] YE Z X, LING Z H. Distant supervision relation extraction with intra?bag and inter?bag attentions [EB/OL]. [2023?04?18]. arxiv.org/pdf/1904.00143.
[15] JIA W, DAI D, XIAO X, et al. ARNOR: attention regulari?zation based noise reduction for distant supervision relation classification [C]// Meeting of the Association for Computational Linguistics. Association for Computational Linguistics. [S.l.]: ACL, 2019: 1399?1408.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
