面向智能駕駛的輕量化GwcNet立體匹配算法研究
2024-09-21 00:00:00面向智能駕駛的輕量化GwcNet立體匹配算法研究
現(xiàn)代電子技術 2024年16期



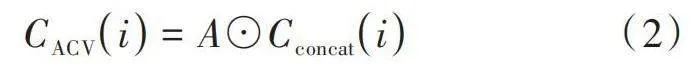
摘" 要: 智能駕駛技術作為新一代智能交通系統(tǒng)的核心之一,受到了廣泛關注。其中,感知融合技術在實現(xiàn)智能駕駛的精準定位和環(huán)境感知中起著至關重要的作用。在感知融合中使用的立體匹配算法更是關乎智能駕駛的安全性和準確性,是智能駕駛環(huán)境感知領域中重要的技術環(huán)節(jié)。針對智能駕駛汽車在硬件方面算力不足,但對立體匹配算法實時性和精度均有較高要求的問題,文章基于GwcNet,為智能駕駛環(huán)境感知模塊設計了一種輕量化的立體匹配算法。利用ACV模型替代GwcNet立體匹配算法中參數量、運算量最大的3D卷積模塊,使得算法的實時性和精度得到提升。為了進一步減少網絡復雜度,減小ACV模塊中的網絡參數,提出一個Fast?ACV模型。最后在KITTI 2015數據集中對立體匹配算法進行對比分析。結果表明,所提出的輕量化GwcNet立體匹配算法在精度和實時性上均優(yōu)于GwcNet算法。
關鍵詞: 智能駕駛; 輕量化GwcNet; 立體匹配算法; 環(huán)境感知; 感知融合; ACV模型
中圖分類號: TN915?34; U463.6; TP183" " " " " " " "文獻標識碼: A" " " " " " " "文章編號: 1004?373X(2024)16?0125?05
Research on lightweight GwcNet stereo matching algorithm for intelligent driving
ZHOU Hao, CAO Jingsheng, DONG Yining, LI Gang
(Automotive and Traffic Engineering, Liaoning University of Technology, Jinzhou 121001, China)
Abstract: As one of the core of the new generation of intelligent transportation system, intelligent driving technology has been widely concerned. The perception fusion technology plays a crucial role in realizing the accurate positioning and environment perception of intelligent driving. The stereo matching algorithm used in perception fusion is crucial for the safety and accuracy of intelligent driving, and is an important technical link in the environment perception field of the intelligent driving. In allusion to the problems that the intelligent driving vehicles have the insufficient computing power in hardware, but have high requirements for real?time performance and accuracy of stereo matching algorithm, a lightweight stereo matching algorithm for the intelligent driving environment perception module is designed based on GwcNet. The ACV (attention concatenation volume) is used to replace the 3D convolutional module with the maximum number of parameters and computation in GwcNet stereo matching algorithm, which can improve the real?time performance and accuracy of the algorithm. In order to further reduce the network complexity and minize the network parameters in the ACV module, a Fast?ACV model is proposed. The comparison analysis of the stereo matching algorithm is conducted in the KITTI 2015 dataset. The results show that the proposed lightweight GwcNet stereo matching algorithm is superior to the GwcNet algorithm in both accuracy and real?time performance.
Keywords: intelligent driving; lightweight GwcNet; stereo matching algorithm; environment perception; perceptual fusion; ACV model
0" 引" 言
立體視覺是機器感知環(huán)境的重要方法,而立體匹配技術[1?7]又是立體視覺技術中的關鍵環(huán)節(jié),近年來許多學者對這兩方面進行研究。
隨著時代的發(fā)展,智能駕駛技術已成為當今最熱門的研究領域[8?9],環(huán)境感知更是智能駕駛中的重要環(huán)節(jié)。但智能駕駛汽車上的移動端設備通常存在算力不足的缺點,而智能駕駛環(huán)境感知模塊對立體匹配算法的實時性要求又比較高,因此,設計精度高且實時性好的立體匹配算法對智能駕駛環(huán)境感知技術有重要的意義。深度學習的不斷發(fā)展使得立體匹配算法的準確性在不斷提升,如A. Kendall等人利用端到端的深度學習架構的GC?Net校正立體圖像回歸視差,使用幾何形狀知識和深度特征表示成本體積。但連接量忽略了相似性度量,因此需要使用大量3D卷積聚合上下文信息。此外,還提出了可微的soft argmin函數從代價體中回歸視差值,省去了額外的正則化或后處理步驟,相對提高了網絡運行速度[10]。PSM網絡引入的空間金字塔池化模塊(Spatial Pyramid Pooling, SPP)用于提高圖像中上下文信息的利用率,將像素級特征擴展至多尺度區(qū)域級特征;另外,使用3D卷積堆疊組成Encoder?Decoder結構來融合多通道信息,得到最終預測視差圖。GwcNet[11]中利用組間相關性對多通道的特征圖沿著通道分組,以計算代價量,即把左右圖像特征劃分為若干組,分別計算出相關圖,進而將得到的多個匹配代價打包到代價量中,同時改進PSM提出的3D沙漏堆疊結構,降低推理計算成本,提高性能。
上述提到的立體匹配方法雖然有不錯的精度,但都大量使用3D卷積完成特征運算,這種成本聚合方式會消耗大量的運算體積和內存,在智能汽車上并不適用。引導聚合網絡(GA?Net)中包含兩種新的卷積網絡結構,分別捕獲局部和全局的成本相關性,用以取代3D卷積。SGA模塊減小由于遮擋、平滑、反射、噪聲造成的錯誤匹配,LGA模塊處理采樣過程中造成的邊緣模糊或薄結構模糊。AANet[12]的主要目標是完全取代3D卷積,同時達到更快的推理速度和較高的精度。首先,提出一種基于稀疏點的自適應尺度內成本聚合(Adaptive Intra?Scale Aggregation, ISA)方法,用于解決在視差不連續(xù)區(qū)域情況下的邊緣模糊性問題。另外,通過神經網絡實現(xiàn)自適應跨尺度成本聚合(Adaptive Cross?Scale Aggregation, CSA),實現(xiàn)在低紋理或無紋理區(qū)域的精確視差預測。CFNet[13]中給出了一種提高網絡效率的方式,即在鄰域差異較大時,融合多個較低分辨率的密集的成本體積,然后讓網絡接收多種數據集不變的幾何場景信息來擴大捕獲圖像全局信息的接收域。另外,針對不平衡的視差分布,使用級聯(lián)成本體積表示,并采用基于方差的不確定性估計自適應地調整下一階段的視差搜索范圍。ACVNet[14]構建了一種高效cost volume計算方法,利用相關線索生成注意力權重從而抑制冗余信息,并增強與匹配相關的信息;加入多級自適應匹配方法提高匹配代價在不同視差下的區(qū)分程度。ACV模塊可以嵌入到大部分現(xiàn)有網絡中,實現(xiàn)聚合網絡的輕量化以及獲得更高精度。
基于上述研究,本文為智能駕駛環(huán)境感知模塊設計一種輕量化立體匹配算法。立體匹配算法基于GwcNet,采用ACV(Attention Concatenation Volume)模型替代GwcNet立體匹配算法中參數量、運算量最大的3D卷積模塊,最終實現(xiàn)算法的輕量化,大幅提升了算法的運行速度,并且達到了精度要求。
1" GwcNet立體匹配算法
GwcNet通過分組相關(Group?wish correlation)方法計算代價體,可以為特征相似度計算提供有效表示,在降低參數的同時提高網絡性能。GwcNet共分為四個部分,分別為一元特征提取、成本體積構建、3D卷積聚合以及視差預測,其網絡結構如圖1所示。
一元特征提取部分使用了PSMNet[15]中相同的具有半擴張設置且不適用SPP的殘差網絡,第1層級聯(lián)三個3×3卷積,在增大感受野的同時加深網絡深度,第2~4層是基本的殘差卷積模塊,并將其Concat連接為具有320個通道的一元特征圖,這部分網絡共享權值。
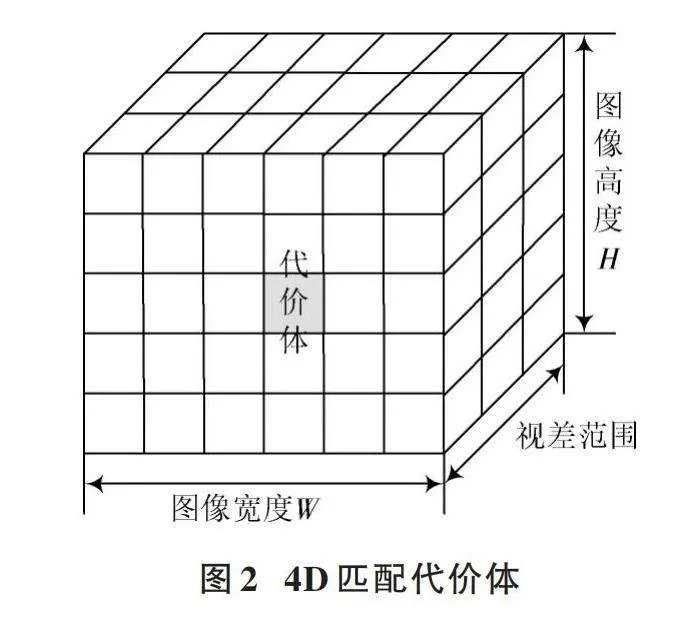
成本體積構建是立體匹配技術的重點和難點,經典的4D代價體主要由兩部分組成,一部分是串聯(lián)一元特征,另一部分是分組相關計算。串聯(lián)一元特征即將左右視圖壓縮為12個通道,然后進行Concat連接;分組相關計算是將左右特征圖分別分為40組,每組8個通道,按照向量內積的方式計算,減少信息丟失。將這兩個量concatenate起來,就可以組成一個4D匹配代價體(圖像高度H、圖像寬度W、圖像最大視差加1、圖像的特征圖數目F)作為3D聚合網絡的輸入,如圖2所示。
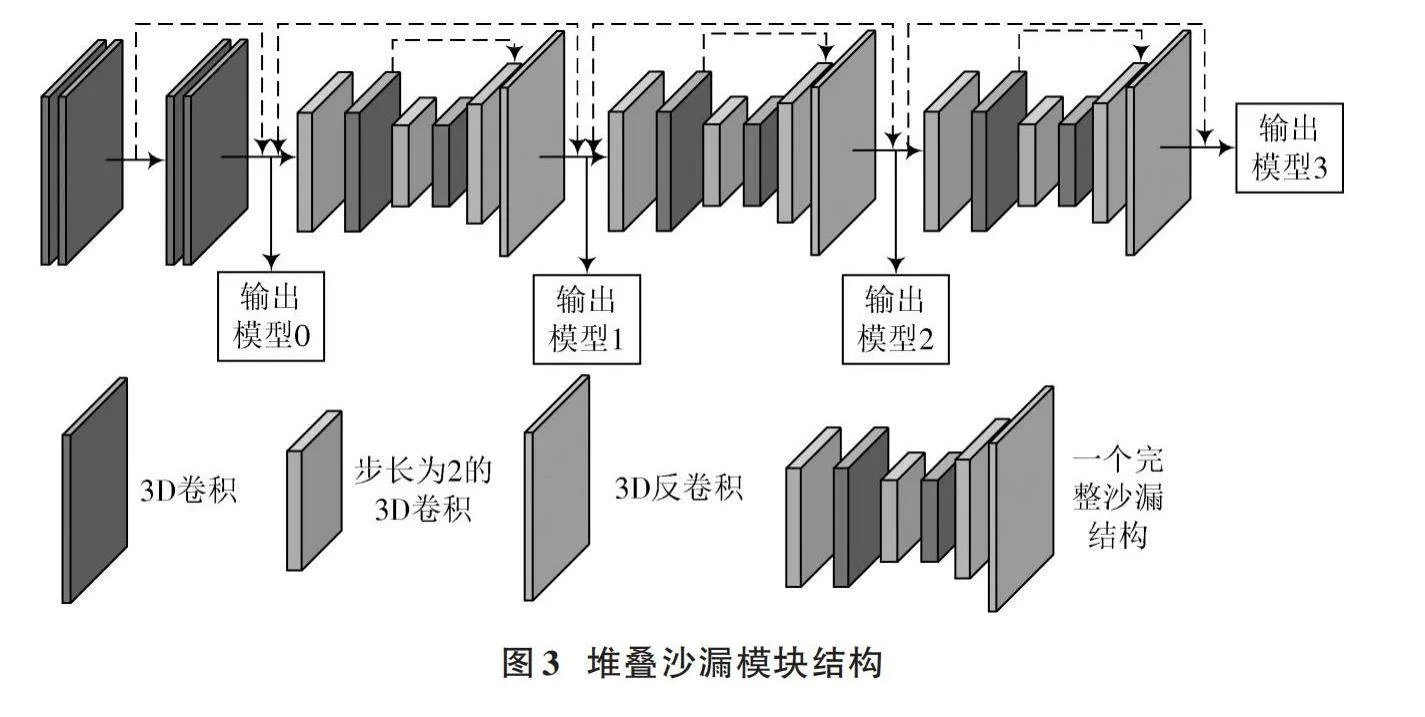
3D卷積聚合網絡由一個前置沙漏模塊和三個堆疊的3D沙漏網絡組成,其將相鄰視差和像素點得到的特征聚合起來,預測優(yōu)化后的代價量,且三個堆疊沙漏模塊都輸出一個預測視差圖。堆疊沙漏模塊結構如圖3所示,左側部分表示前置卷積模塊,后面三個為類似于沙漏形式的卷積模型。沙漏模型包括步長為2的3D卷積和步長為1的3D卷積,這兩個卷積步驟之后進行降維,緊接著是兩個降維后的3D卷積,然后是3D反卷積。文中使用兩個不同維度的3D反卷積模型恢復輸入特征圖形的長度、寬度和維度。另外,沙漏模型外部使用跳躍連接,增強模型特征屬性;內部也包含跳躍連接模式,復合長度、寬度相同的代價卷積,提高特征提取的準確性并增強穩(wěn)定性。最后,通過多次疊加獲取圖像更高層次的特征信息。
視差預測是對每個輸出模塊應用兩個3D卷積生成1通道的4D體積,然后對其進行上采樣,轉換為具有沿視差維度的softmax函數的概率體積,這種方法可以使得圖像特征更加清晰。對于整個網絡來說,提取左右圖像特征后是構建代價體,將Volume_g和Volume_c直接連接,接下來就是一系列卷積、相加、激活、反卷積操作,經過沙漏模型最終輸出結果。
2" 輕量化GwcNet立體匹配算法
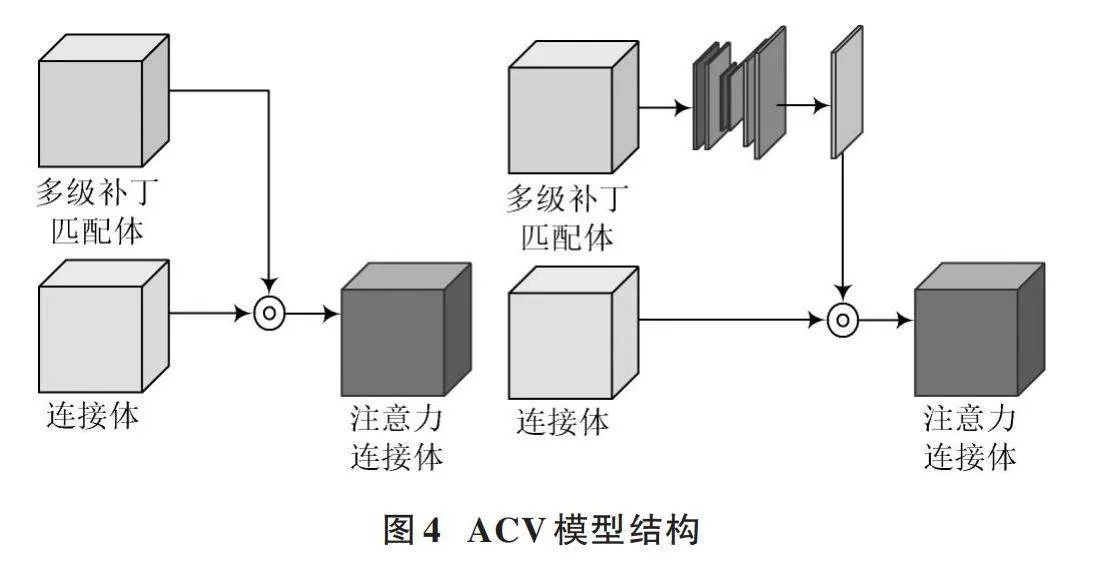
GwcNet立體匹配算法由于加入了構建4D代價體的方法,會使計算量和參數量急劇增加,雖然精度高,但是運行時間相對較慢。因此,可以優(yōu)化其中結構。本文引入ACV?Net中的代價體構建方法,使用ACV(Attention Concatenation Volume)模型替代參數量、運算量最大的3D卷積模塊。ACV模型結構如圖4所示。
構建代價體是立體匹配算法的關鍵問題,通常的方式有兩種:concat和correlation。研究發(fā)現(xiàn),concat方式可以保留相對豐富的信息,但是需要進行復雜的3D卷積聚合計算,并且容易丟掉內容的相似性;correlation方法可以通過相關性計算反映圖像中相鄰像素的關系,但是會損失一些特征信息。GwcNet是對這兩種方法的混用,取得了良好的表現(xiàn),但是其結構為直接連接兩種類型的代價體,沒有考慮各自的特性,導致兩種代價體參數之間的互補性降低,仍然需要使用沙漏結構堆疊3D卷積。
成本體積的構建和聚合是密切相關的模塊,可以借鑒ACV模塊中的構建方法,使用編碼在相關量中的相似性信息來正則化連接量。具體構建方法為:利用連接體生成注意力權重來濾波注意力連接體。為了得到可靠的連接體,使用多級補丁匹配體生成更精準的相似特征,該方法在不同特征層級使用不同大小的patch,使用具有預定義大小和自適應學習權重的atrous patch來計算匹配代價。
對GwcNet網絡引入的ACV模塊包括三個部分:初始連接體的構建(Initial Concatenation Volume Construction)模塊、注意力權重生成模塊和注意力過濾模塊。
1) 初始連接體的構建模塊
對于給定的一對立體圖像,假設尺寸均為H×W×3,則通過對每張圖像的特征提取得到一元特征映射fl和fr,fl(fr)特征圖尺寸為[N×H4×W4],其中N=32;然后將特征圖連接,公式如下:
[Cconcat(⊙,d,x,y)=concatflx,y,frx-d,y] (1)
式中:“⊙”表示元素的乘積;[flx,y]與[frx-d,y]表示像素坐標系中該點的特征值;d表示左右圖像的像素視差。將特征值進行concat運算,得到Cconcat尺寸是[2N×D4×H4×W4],其中D代表最大視差。
2) 注意力權重生成模塊
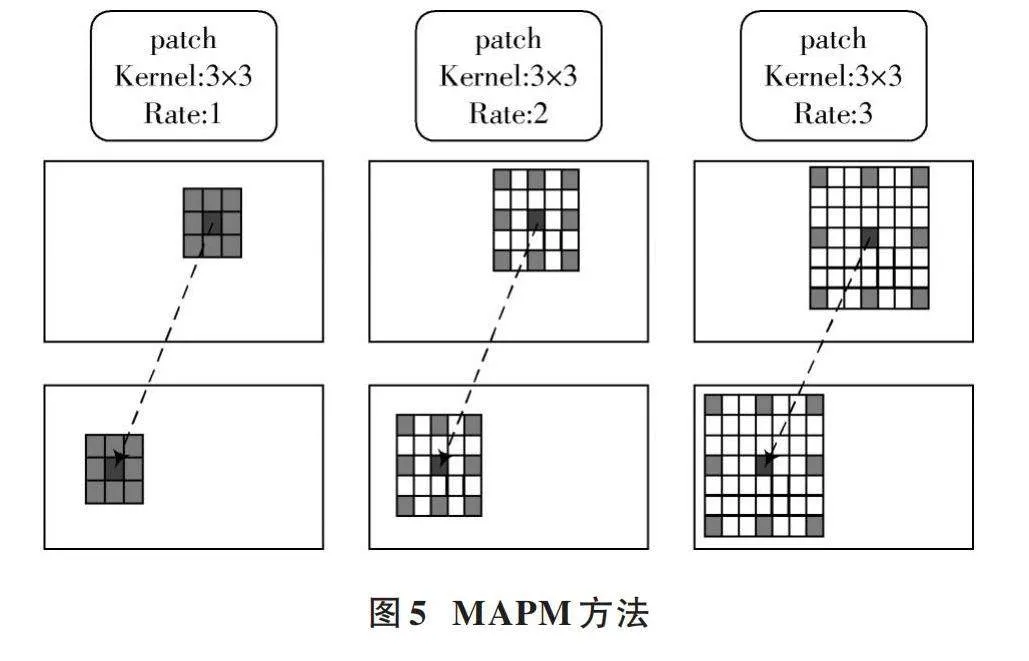
一般方法中連接體是通過計算每個像素相似性得到的,但是其在弱紋理區(qū)域表現(xiàn)不好,因此引入了一種MAPM(Multi?Level Adaptive Patch Matching)方法。首先從特征提取模塊得到三個層級的特征圖,其對應通道數分別為l1=64,l2=128,l3=128。對于每個層次的每個像素,使用具有預定義大小和自適應學習權重的atrous patch來計算匹配成本。MAPM方法如圖5所示,不同的尺寸適用于不同的目標,大尺寸可以包含更多上下文信息,區(qū)分高級別特征圖不同差異的匹配成本。
通過控制擴張率(Rate)可以保證patch范圍和特征圖級別相關,并且在中心像素的相似性計算時使得像素數量相同,進而使左右圖像中對應像素的相似度成為patch中對應像素之間相關性的加權和。本文中檢測的目標大小不一、形態(tài)各異,MAPM方法可以提高獲取特征的準確性。
3) 注意力過濾模塊
在上述MAPM方法最后,使用3D卷積將特征圖通道維度壓縮為1,就可以獲得注意力權重A,使用它來消除初始級聯(lián)體中的冗余信息,進而增強其表示能力。通道i處的注意力連接量[CACV]計算公式為:
[CACVi=A⊙Cconcati] (2)
式中,注意力權重A被應用于初始串聯(lián)體積的所有通道。
引入的ACV模塊可以替換一般立體匹配算法中4D成本體積的構建,本文轉換GwcNet中成本體積構建方法,提高算法整體效率,從而實現(xiàn)立體匹配網絡輕量化。
3" 實驗分析
智能駕駛汽車的移動端通常算力比較低,因此本文在GPU RTX 1080 Ti 11 GB環(huán)境下,采用PyTorch深度學習框架搭建模型。首先,將GwcNet網絡在Scene Flow數據集上的預訓練模型參數進行遷移,然后在KITTI 2015的立體匹配訓練數據集上進行微調,最后在KITTI 2015測試數據集上得到結果,驗證了GwcNet的可行性。此后,將ACV模塊引入GwcNet進行優(yōu)化,得到GwcNet+ACV模型進行訓練,以獲得更好的測試結果。同時,減少標準ACV模塊的卷積層數和視差預測模塊網絡參數,獲得GwcNet+Fast?ACV模型,再將優(yōu)化前后的模型運行結果進行分析。
3.1" 定量分析
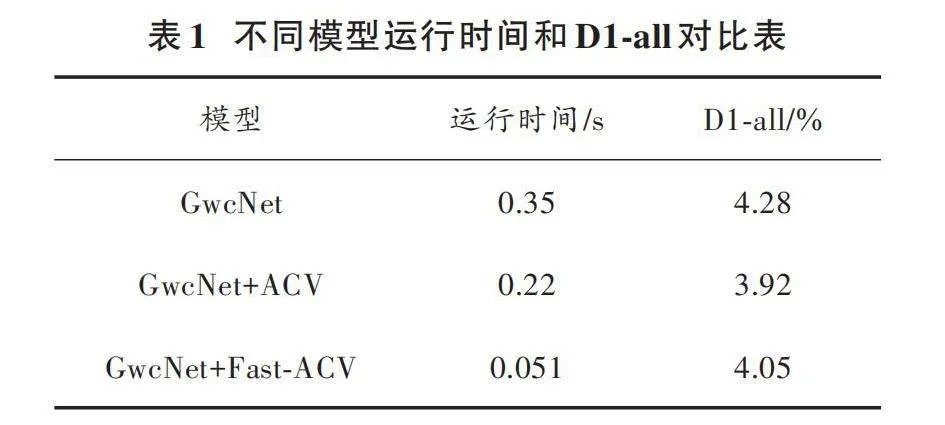
本次實驗主要對比內容為GwcNet原模型、引入ACV模塊后和引入Fast?ACV模塊后的網絡實驗結果,主要對比重點關注的運行時間以及對于第一幀圖像全部區(qū)域預測錯誤的像素比例(D1?all)。具體結果如表1所示。
結合表1可知,GwcNet精度表現(xiàn)不錯,整幅圖像中深度信息預測錯誤的占比為4.28%,但是運行時間比較長,而其運行速度約為2.86 f/s。在將代價匹配和成本聚合模塊采用ACV模塊替換后,運行時間減少了37.14%,運行速度得到一定提升而且預測錯誤率也降低了0.36%。Fast?ACV模型的引入使得運行時間迅速減少為0.051 s,與原模型相比運行時間降低了85.43%;運行速度為19.6 f/s,與原模型相比極大地提升了運行速度,深度信息預測錯誤的占比為4.05%,與原模型相比提升了0.23%。可以得出,在立體匹配算法中卷積運算層占據大量運行內存空間,這也是需要提高的地方。另外,由于使用的是卷積層堆疊方式,適當減少卷積層數會降低模型立體匹配的準確率,但運行速度會大大提升。綜上所述,本文所提出的輕量化GwcNet模型在精度與實時性上均比原模型有一定的提升,特別在實時性方面。
3.2" 定性分析
對實驗結果的定量分析可以看出運行時間和錯誤比例等信息,而定性分析可以直觀地了解深度估計模型具體表現(xiàn)的差異性。定性分析通過原圖與深度估計圖像的互相對比,即可以肉眼觀察出目標距離信息。本文中使用灰度圖的形式對深度圖加以區(qū)分,以0~255灰度值(白色為255、黑色為0)具體表達1.7~90 m的距離范圍,距離越近,灰度數值越大,圖片白色越明顯;距離越遠,顏色越深。圖6為數據集原圖和GwcNet+Fast?ACV的運行結果圖。
從圖6中可以看出,對于第一張圖像,對向來車擋風玻璃處有著強烈的反光,本文算法可以將這種干擾大大降低,并且清晰地表現(xiàn)出汽車輪廓;第二張圖像車輛密集排列,視差預測圖像能明顯地區(qū)分各個車輛;第三張圖像中較遠處有汽車以及交通標示牌,預測結果也可以表示;第四張圖像上方區(qū)域存在大量樹木,深度估計模型也能夠區(qū)分樹木輪廓。
4" 結" 論
本文針對智能駕駛環(huán)境感知模塊,設計了一種立體匹配算法。以精度較高的GwcNet為基礎,對網絡結構進行改進;引入ACV模塊替代GwcNet立體匹配算法中參數量、運算量最大的3D卷積模塊,使得網絡結構輕量化;并進一步優(yōu)化結構,使得精度和實時性均優(yōu)于原模型。本文提出的輕量化立體匹配算法對智能駕駛環(huán)境感知系統(tǒng)有一定的實用價值。
注:本文通訊作者為曹景勝。
參考文獻
[1] 胡志新,梅紫俊,王濤,等.基于自適應窗口和改進Census變換的半全局立體匹配算法[J].電光與控制,2023,30(3):33?37.
[2] 范亞博,王國祥,陳海軍,等.特征融合的雙目立體匹配算法加速研究與實現(xiàn)[J].導航定位與授時,2022,9(6):133?140.
[3] 黃怡潔,朱江平,楊善敏.基于注意力機制的立體匹配算法[J].計算機應用與軟件,2022,39(7):235?240.
[4] 李忠國,吳昊宸,陸軍,等.雙目視覺立體匹配算法的改進[J].機械設計與研究,2022,38(3):27?29.
[5] 楊戈,廖雨婷.基于AEDNet的雙目立體匹配算法[J].華中科技大學學報(自然科學版),2022,50(3):24?28.
[6] 王森,危輝,孟令江.基于控制點和RGB向量差聯(lián)合梯度Census變換的立體匹配算法[J].模式識別與人工智能,2022,35(1):37?50.
[7] 郭乾宇,武一,劉華賓,等.基于損失自注意力機制的立體匹配算法研究[J].計算機應用研究,2022,39(7):2236?2240.
[8] 陳曉冬,張佳琛,龐偉凇,等.智能駕駛車載激光雷達關鍵技術與應用算法[J].光電工程,2019,46(7):34?46.
[9] 申恩恩,胡玉梅,陳光,等.智能駕駛實時目標檢測的深度卷積神經網絡[J].汽車安全與節(jié)能學報,2020,11(1):111?116.
[10] KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End?to?end learning of geometry and context for deep stereo regression [C]// 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017: 66?75.
[11] GUO X, YANG K, YANG W, et al. Group?wise correlation stereo network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2019: 3273?3282.
[12] XU H, ZHANG J. AANet: adaptive aggregation network for efficient stereo matching [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 1959?1968.
[13] SHEN Z L, DAI Y C, RAO Z B. CFNet: cascade and fused cost volume for robust stereo matching [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA: IEEE, 2021: 13906?13915.
[14] XU G W, CHENG J D, GUO P, et al. Attention concatenation volume for accurate and efficient stereo matching [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 12971?12980.
[15] WANG H, HUTCHCROFT W, LI Y, et al. PSMNet: position?aware stereo merging network for room layout estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 8616?8625.
