融合GPT技術和用戶需求的文學類古籍資源關聯數據發布研究
2024-10-08 00:00:00范顏鑠周曉英王克平等
現代情報 2024年10期

關鍵詞: 文學類古籍; 數字人文; 知識組織; 關聯數據;Drupal;ChatGPT; 用戶需求
DOI:10.3969 / j.issn.1008-0821.2024.10.013
〔中圖分類號〕G255 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2024) 10-0154-14
文學類古籍作為古籍資源的一個重要門類, 兼具藝術性與文化性, 同時具有“存史” 的功能, 可突出展現某一特定時期的文化重心情況, 其題材、數量的豐富程度也在一定程度上反映了社會的安定程度與文化繁榮程度。此外, 文學類古籍包容性強、內容豐富, 極具地域屬性色彩, 與一般古籍相比,其蘊含的知識更為豐富, 知識群體之間存在的語義關系更為復雜, 挖掘潛力較大。
在文化與科技融合的數字化背景下, 數據可視化、虛擬現實、GPT(Generative Pre-trained Trans?former)等技術為古籍的數字化提供了新思路, 促使古籍知識組織向語義化方向發展, 也為文學類古籍的關聯組織提供全新的方法借鑒。然而, 現有的古籍數字化研究多集中于歷史、哲學、地方志、中醫藥等門類, 或關注書目等外部屬性特征, 文學類古籍數字化研究特別是應用實踐研究偏少, 相較于其他門類古籍關注度偏低。同時, 由于文學類古籍資源具有多重藝術形式, 涵蓋了題材、體裁等特征要素, 使用現有關聯數據發布思路時存在屬性揭示不足、領域描述不適配等問題。因此, 本文選取文學類古籍資源作為研究對象, 在現有的“本體模型+關聯數據實現平臺” 發布思路基礎上, 探究如何將GPT 技術、用戶需求分析與關聯數據技術相結合以提升文學類古籍資源關聯數據發布的效果。
1文獻綜述本節梳理分析
國內外關聯數據在古籍中的應用、發布方式、實體識別抽取方法與用戶需求分析的研究成果, 為后續模型的構建提供理論基礎。
1.1關聯數據在古籍研究中的應用
關聯數據是語義網的一個簡單應用, 利用RDF、URI 等技術可將Web 中的各類數據、信息和知識進行分布、共享和鏈接, 讓人們可以通過HTTP 協議來揭示和獲取這些數據, 因其自身具有自描述等優良特性, 現已成為語義Web 的一種輕量級解決方案[1] 。2006 年7 月, “萬維網之父” Tim Berners-Lee提出關聯數據的概念并指出了關聯數據的4 項基本準則[2] : ①用URI 來標記任何事物; ②使用HTTPURI 使任何人都可以查找和引用這些事物; ③當某個資源被訪問時, 應以開放標準的形式(如RDF、SPARQL等)提供有用的信息; ④盡可能給出相關的URI, 以便實現資源或者數據集的豐富化。
我國對古籍數字化的研究正處于不斷“升溫”的階段, 不少學者借助關聯數據技術對其展開研究。在古籍文本研究方面, 有學者總結了古文知識組織及關聯數據技術在古籍知識組織應用的現狀, 提出了基于關聯數據的古文知識組織模式并對核心問題及技術進行探討[3] ; 有學者通過分析關聯數據等信息技術在挖掘數字化古籍知識中的運用, 提出了數字化古籍知識管理模型[4] 。在古籍數據庫建設方面,數字媒介的不斷發展使關聯數據技術在古籍數據庫建設、古籍資源的組織與存儲等方面發揮著重要作用[5],歐盟數字圖書館(Europeana)借助關聯數據將散落在世界各地的文獻等資源進行整合, 構建了統一的網絡平臺[6] ; 有學者基于關聯數據, 在分析現有語義技術應用基礎上提出了語義技術驅動下的古籍互聯互通框架[7] 。在古籍外部特征研究方面,有學者借助語義網和關聯數據技術對古籍書目進行知識組織, 構建叢書古籍書目知識組織模型[8] ; 有學者對我國特有的, 以CNMARC 格式編目的古籍書目進行了關聯數據化與關聯化發布研究[9] 。也有不少學者對不同門類古籍展開研究, 如借助關聯數據技術研究史書類古籍《漢書·藝文志》中的人物知識關聯[10] 、構建地方志類古籍《方志物產》知識庫[11] 、設計地方詩詞資源關聯聚合模式并構建實例化應用平臺[12] 。作為較為成熟的技術, 關聯數據在古籍領域中的應用已涉及多個門類與多個方面,但知識組織及關聯數據技術在文學類古籍數字化探索中的應用研究十分有限, 僅涉及詩詞文字形式,整體研究程度與關注程度依舊偏低, 因此本文嘗試將關聯數據技術應用于文學類古籍資源領域, 提出文學類古籍資源關聯發布模型, 從多維度對文學類古籍資源知識進行全面、具體的呈現。
1.2關聯數據發布
現階段,我國學者主要借助D2RQ、Drupal 發布關聯數據集, D2RQ 是目前較為常用的RDF 映射平臺, 有學者借助該平臺實現了可移動文物的關聯數據存儲[13] ; 也有學者基于層級結構, 用D2R 模型實現家譜文化資源的語義關聯及可視化展示[14] 。Drupal 則具有更好的輕量級數據發布能力, 具有良好的可擴展性和靈活性, 其內容結構定義對關聯數據的支持適用性也較大[12] 。已有多位學者借助該平臺實現關聯數據集的發布, 如基于層級結構方式,從數據層、模式層以及應用層3 個層級結構對山水志史料資源進行語義化知識關聯與知識發布[15] ; 通過構建內容節點類型和屬性、節點與本體庫的關聯映射等步驟, 實現民國建筑知識庫關聯數據的組織與發布[16] ; 基于模塊匹配的方式, 以資源發布模塊、問題答疑模塊、實驗管理模塊、在線考試模塊搭建師生間的信息交流網絡平臺等[17] 。盡管目前圍繞關聯數據發布的相關成果顯著, 但由于文學類古籍資源的結構元素、內容具有一定特殊性, 仍有必要進一步結合文學類古籍資源的內容結構特征, 設計探討關聯數據發布新思路, 促進關聯數據技術在該領域的應用落地。
1.3實體識別抽取
基于自然語言處理技術、深度學習算法的挖掘、識別抽取方案雖可以取得良好的效果, 但操作門檻高、步驟復雜, 設計抽取模型需耗費大量時間與人力成本, 且傳統抽取方式多以“看到一類, 定義一類, 構建一類” 的模式構建知識庫, 手段效率低, 當包含多個中間子任務時, 抽取準確率急劇下降, ChatGPT 等大語言模型的發布對傳統自然語言核心任務產生了巨大的沖擊和影響, 不僅可以高質量完成任務且貼合用戶的實際需求[18] 。GPT 技術在語義理解、知識抽取、知識生成與推薦方面的出色表現使知識組織環境發生巨大變化[19] , 在數字任務研究過程中, 可提供研究過程中所需要的文本生成、跨語言處理、情感分析、語料庫建設等技術支持[20] , 在閱讀理解、情感分析等自然語言處理任務中獲得較優的性能[21] 。南京理工大學已有實驗結果表明, ChatGPT 在命名實體識別具有較好的表現, 但在關系抽取中的效果需進一步提高[22] 。
現階段,ChatGPT在知識抽取方面的研究主要集中于實驗分析階段, 大多數研究以直接向其輸入文本、分析其輸出結果的方式測試其識別抽取準確度, 也有學者通過給定關系的方式抽取關系[22] 。在ChatGPT 生成內容分析上, 有學者通過輸入樣例的方式, 讓其模仿樣例的語言風格進行寫作并分析實驗結果[23] 。基于以上實驗思維, 結合其強大的學習能力、操作的便捷性與良好的抽取效果等特性,本文將以輸入樣例、給定關系與識別抽取目標的形式識別抽取本文所需數據, 可在一定程度上提高知識組織與研究效率。
1.4用戶需求分析
目前,用戶需求分析常用方法有Kano模型、AHP層次分析法、AD理論等, 也有不少學者通過內容分析、訪談、問卷等方法收集用戶需求, 在知識服務支撐、服務水平提升、服務效果提升方面做了很多嘗試[24],如從用戶對資源的需求出發, 借助層次分析法、TF-IDF算法構建用戶畫像模型,為精準圖書推薦服務提供支撐[25] ; 或借助訪談、內容分析等方法, 完善數據可視化研究素養體系, 提高高校圖書館服務水平[26] 。也有學者從用戶需求角度優化醫療健康類APP[27] 、針對實際需求對家用火災類逃生作品進行創新設計等[28],進而提高現有產品的機能與服務效果。文學類古籍知識受眾群體較為廣泛, 本文通過訪談法收集不同年齡、身份的用戶知識需求并進行歸納分析, 據此設計、構建文學類古籍資源關聯數據發布模型, 提升其可用性與實用性。
綜上所述, 目前關聯數據技術在古籍領域的應用已有較為豐碩的成果, 但聚焦到文學類古籍資源尚存在一些不足: 一是數字化實踐研究偏少, 雖對文學作品文本等進行挖掘分析, 但仍缺少對其應用實踐方面的探索。二是已有的關聯數據發布模式與文學類古籍資源無法做到完全適配, 無法全面呈現其語義知識結構網絡。三是現階段將用戶需求多維度分析結果結合到關聯數據發布模型中的成果尚不多見。因此, 本文將從文學類古籍資源的特征和數字化實踐需求出發, 結合關聯數據集發布的典型流程, 將GPT 技術、用戶需求分析與關聯數據技術相結合, 創新性提出文學類古籍資源關聯數據發布模型。與傳統關聯發布模型相比, 該模型基于大語言模型時代背景改進現有數據層, 融合GPT 技術完成數據采集工作, 提高知識組織效率, 同時增設針對不同用戶群體分析其需求的應用層, 并通過文學類古籍關聯組織模型來實現其構建, 完善文學類古籍資源關聯化發布思路的同時增強本文提出模型的實用性。在實證方面, 選取《聊齋志異·司文郎》驗證模型的有效性及可用性。
2文學類古籍資源的結構要素與關聯發布需求分析
本節首先從時間、地點、人物、文章4 個角度出發梳理文學類古籍資源的結構要素, 其次歸納數字化時代背景下用戶對文學類古籍知識的需求, 為后續文學類古籍資源關聯數據發布模型的建立奠定基礎。
2.1文學類古籍資源結構要素分析
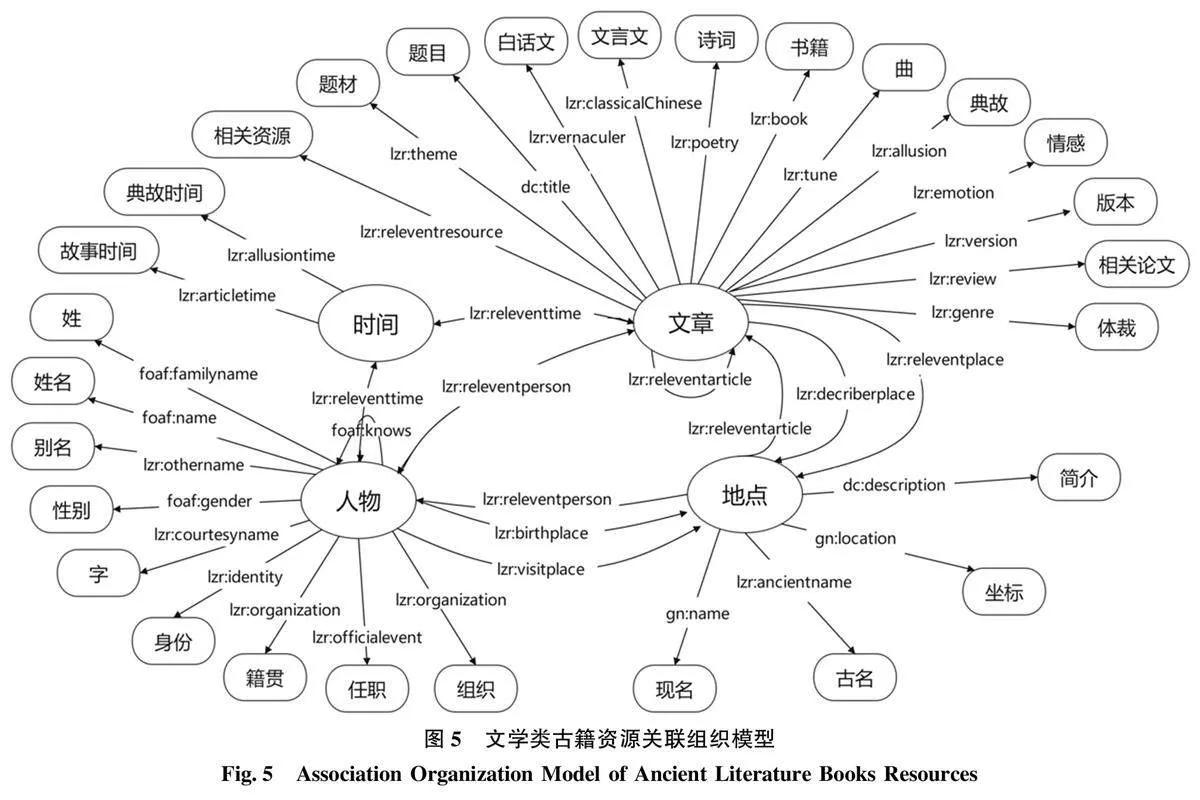
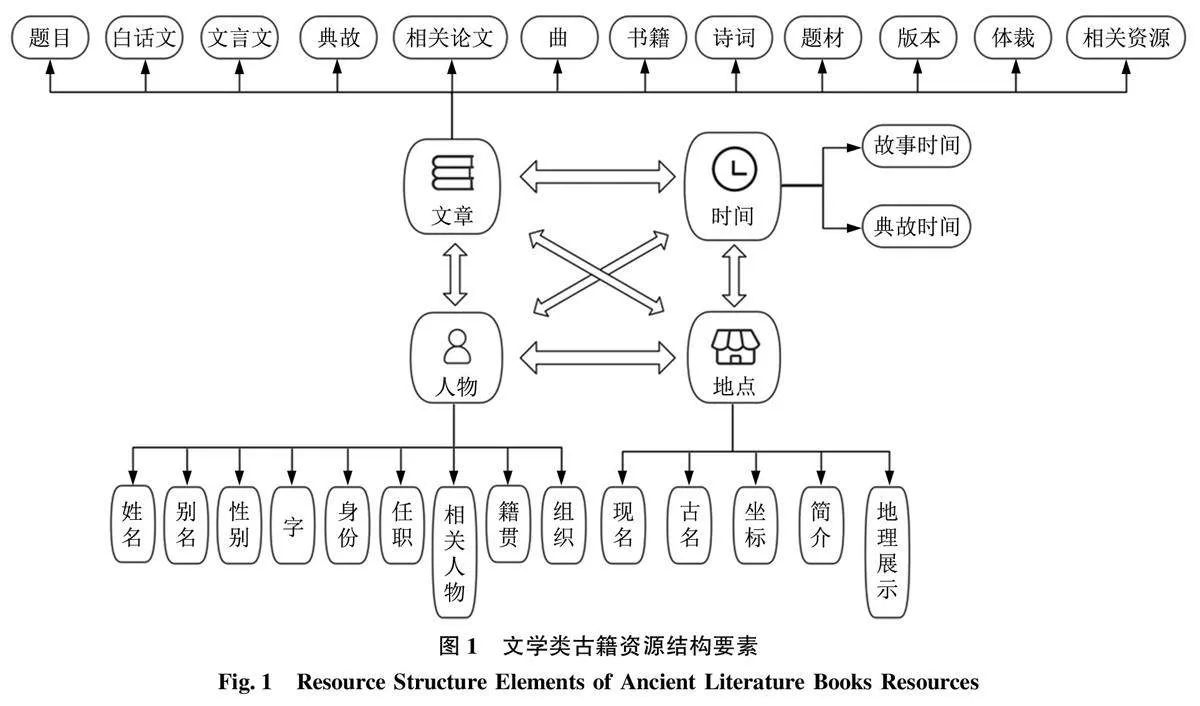
文學類作品通過詩歌、散文、小說等藝術形式來表達作者對生活的觀察和理想[29] , 通過語言塑造形象以反映人類社會生活[30] 。與其他類別作品相比, 除卻多個門類書籍包含的人物、地點、時間基本元素, 篇章題目是該類書籍的核心要素, 故事情節基本通過文章章節串聯, 體裁、題材等要素更是該類書籍重要的形式特征與要素。與現代文學作品相比, 文學類古籍不僅包含人物、時間、地點等基本結構要素, 還增加了文言文要素, 其晦澀性在考驗專業研究人員文學素養的同時, 也給大眾閱讀群體造成了一定的閱讀障礙。本文結合文學類古籍資源的結構與特征, 將結構要素劃分為時間、地點、人物、文章4 個基本組成部分, 將其具有代表性特征的體裁、題材與文言文要素放置文章類目下, 形成文學類古籍資源通用結構要素, 涵蓋了更深層次、更全面的實體和關系, 從而使所構建的文學類古籍資源關聯數據發布模型具有更高的兼容性與實用性,如圖1所示。
2.2文學類古籍資源cBkt/79jolSd7yfSSlU+dxG//qrcy72YE3ac2/goBjg=關聯組織和關聯發布需求
文學類古籍在教育實踐、價值觀指引等社會環節中具有固本培元的作用, 有助于在全民心中建立起真正的文化自信, 形成強大的社會凝聚力[31],對其展開數字化實踐研究具有重要的現實意義。信息技術的不斷發展使用戶對文學古籍知識化的需求不再停留于單純的知識獲取, 而轉為更為直觀、更富有語義內涵的知識展示與查詢, 主要表現為用戶的知識需求多元化、知識獲取便捷化、需求內容多樣化、需求連續化與動態化。
為了解用戶真實需求, 本文先后訪談了10名蒲松齡研究院相關專家、90名社會群眾與50 名高校學生, 訪談主要圍繞以下內容展開: 職業、對文學類古籍關注與熱愛程度等背景性問題、文學類古籍查閱與研究過程中遇到的問題、數字化背景下文學類古籍知識獲取途徑傾向與內容需求等, 根據對150名用戶的訪談結果, 按照用戶需求特征的不同將用戶分為專業用戶與普通用戶。前者為文學愛好者、研究人員或熱衷于文學研究的學者, 這類群體知識需求比較集中, 對知識的需求更為深入和專業化; 后者主要為學生、對文學感興趣的社會群眾,此類用戶的知識需求更加廣泛和多樣化。基于此,本文針對不同用戶需求對關聯數據發布平臺進行設計, 以便使用戶能更好地在平臺上根據自身需要獲取所需知識。
3融合GPT技術和用戶需求的文學類古籍資源關聯數據發布模型設計
為促進文學類古籍資源的有效傳播、利用與知識共享, 需對文學類古籍資源中的知識進行全面、充分的揭示, 借助關聯數據技術實現文學類古籍文本知識的鏈接與智能應用, 以可視化形式呈現此類古籍的知識語義網絡, 使關聯發布平臺能夠以更清晰、便捷的方式呈現文學類古籍資源的整體概貌。
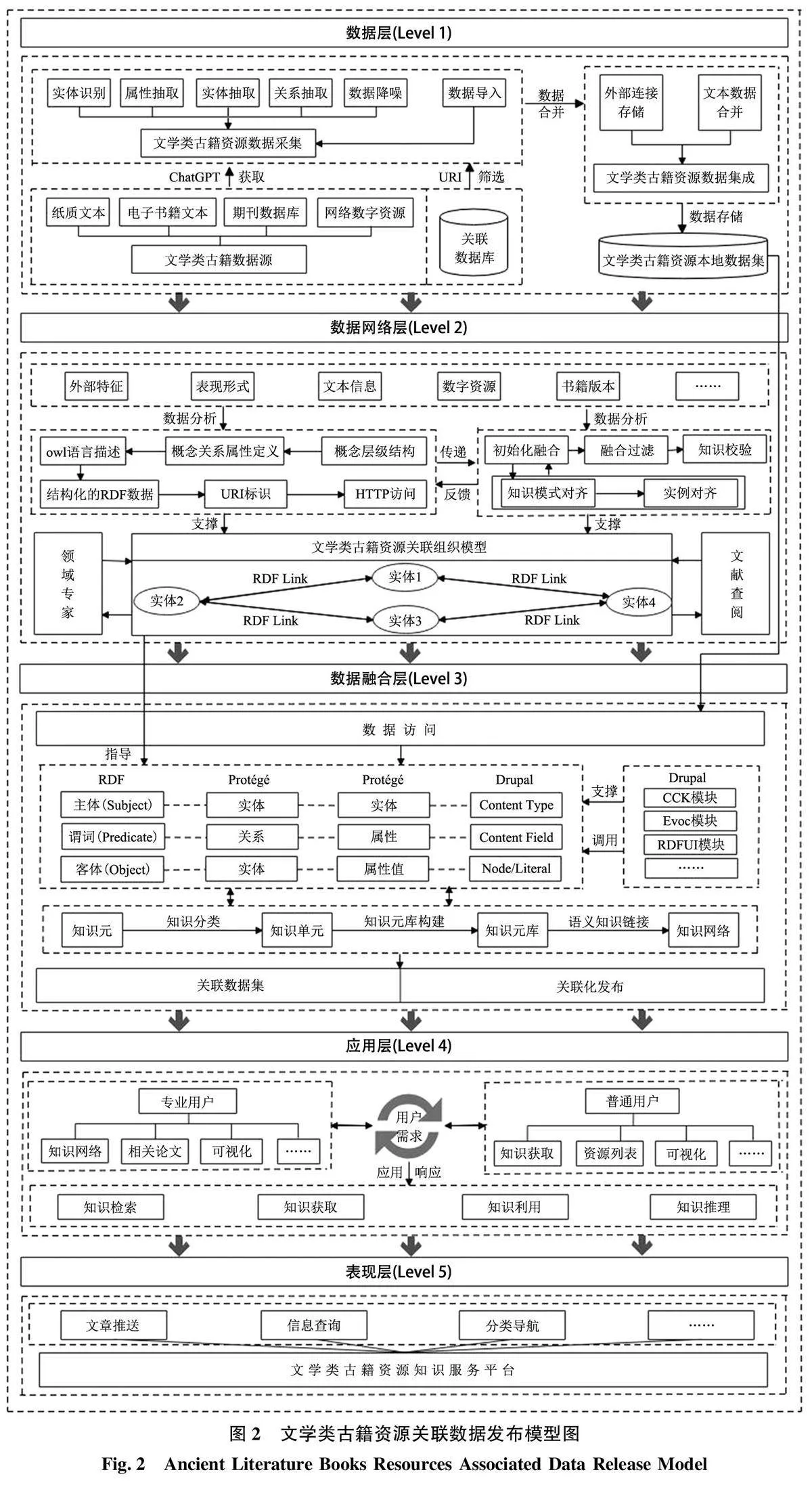
本文沿用了以層級結構實現關聯化發布的思路,同時結合前文分析的文學類古籍結構要素特征改進現有關聯發布框架, 添加文學類古籍資源關聯組織模型使關聯數據發布更貼合該領域特征, 設計文學類古籍關聯數據發布模型以實現知識語義化關聯,該模型主要包含數據層、數據網絡層、數據融合層、應用層及表現層5 個層面, 如圖2 所示。其中, 數據層嘗試借助GPT 技術完成數據采集工作, 基于前人抽取思維, 在數據層以輸入樣例、給定關系與識別抽取目標的形式識別抽取本文所需數據, 增設分析用戶需求的應用層, 并以用戶需求為導向完成表現層的構建, 提高本模型的實用性。
1) 數據層。數據層主要借助GPT類技術解決數據離散無序、屬性缺失等問題, 構建本地數據集為其他4 個層面提供數據支撐。根據不同數據選取相應數據源完成數據的獲取, 從地方、高校圖書館及檔案館收集紙質版古籍, 超星數字圖書館等數字圖書館、中國知網等期刊數據庫分別作為電子版古籍與期刊的主要數據源, 以網絡數字資源為補充,并對數據進行初步分類。在數據采集方面, 借助OCR、GPT 技術獲取文本數據, 根據ChatGPT 可通過語言模型任務“閱讀” 大量自然語言文本進而習得大量知識[20] 的優點, 以分批、多次輸入識別抽取實例的方式訓練ChatGPT, 依托其強大的學習能力使其不斷明確本文所需的抽取任務與抽取目標, 提高ChatGPT 對三元組的敏感程度, 借助ChatGPT實現文本數據的識別與抽取。相關論文數據則在中國知網等期刊數據庫利用“主題” “關鍵詞” 搜索相關研究論文, 以自定義的方式選擇“題目” “摘要” “關鍵詞” 等內容導出到Excel, 并以人工篩選的方式收集關聯數據庫的URI 鏈接。將從以上3 個方面采集到的數據進行人工校對與初步融合, 剔除掉重復數據, 結合網絡資源對數據進行補充, 最終形成文學類古籍資源數據集, 存儲到本地數據集中供后續訪問。
2)數據網絡層。數據網絡層的主要任務是將采集到的本地數據集轉化為機器可識別的RDF(Re?source Description Framework)格式并構建文學類關聯組織模型, 以實現對文學類古籍資源知識的語義揭示, 并為數據融合層提供指導。目前, 針對不同數據有多種RDF 轉換方式, 文學類古籍資源數據的主要組成部分為文本數據, 本體則具有較好的知識表示能力且有統一的描述標準, 因此在此層面可用本體技術對數據層中的本地數據集進行規范化描述,同時結合文學類古籍資源內容結構特征, 充分考慮現有本體復用的可能性, 通過owl 語言描述文學類古籍資源的對象及屬性, 實現實體的關聯、消歧、融合, 進而生成本文所需的RDF 數據, 為每個實體生成具有唯一標識的URI,以實現HTTP 訪問,避免實體ID 屬性沖突的問題。對知識單元進行有效組織形成知識網絡, 完成對文學類古籍資源知識的規范化組織, 實現文學類古籍資源關聯組織模型的g8usNwXcwIDoYFoZ38oPgQ==構建。
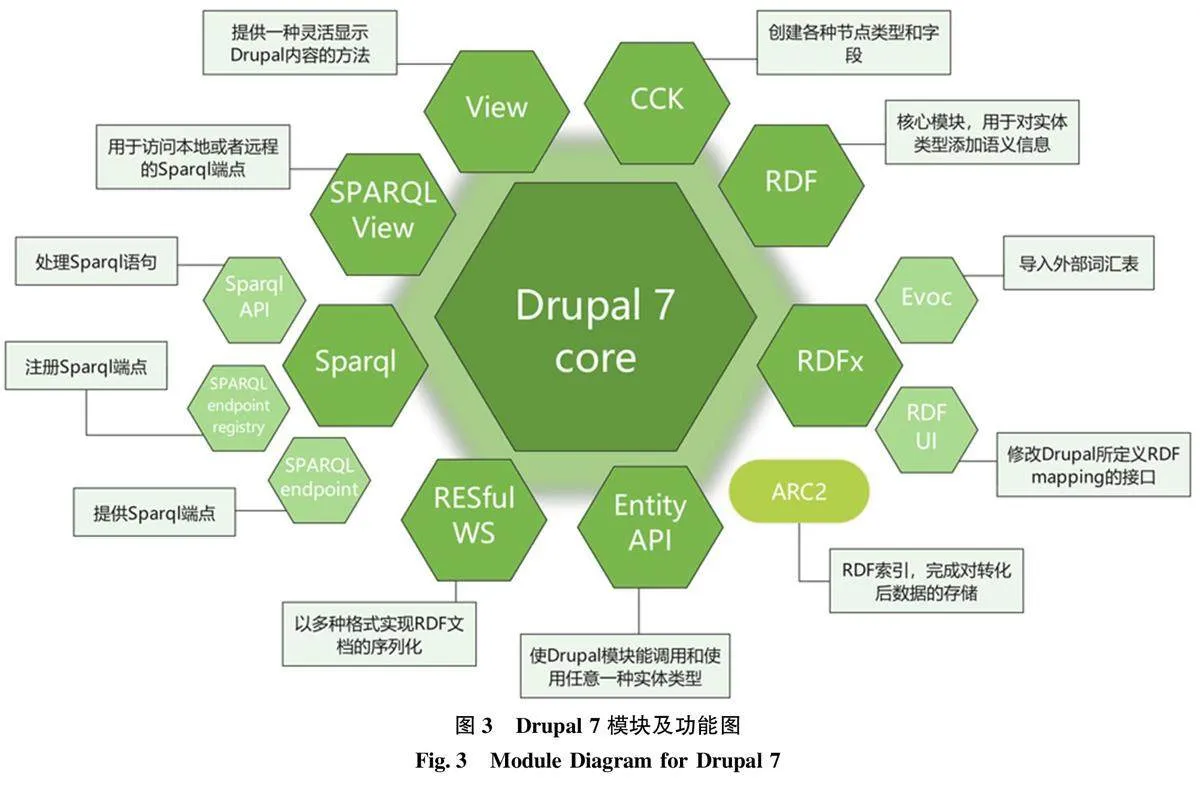
3) 數據融合層。鑒于Drupal 的兼容性與文學類古籍資源數據量大小, 本文選取Drupal 平臺實現文學類古籍資源的關聯數據發布, 因此數據融合層的主要任務是依托Drupal 的模塊化發布思維, 通過實體命名化、實體關聯化完成RDF 數據到Drupal 站點內容的存儲與映射, 將本地數據集轉化為機器可理解的關聯數據集, 具體使用模塊如圖3 所示。Drupal 的核心要素為內容類型、字段、節點3 種要素, 將3 種要素與文學類古籍本體模型中的類、屬性、實例一一對齊即可實現RDF 數據到Drupal 站點內容的存儲與映射[32] 。因此, 首先需要構建數據庫與關聯數據間的映射規則及關系,確保關聯組織模型在Drupal 平臺中內容類型、字段和節點等元素與本體中的實體、關系、實體與實體、屬性、屬性值之間建立一一對應關系, 提高文學類古籍資源的數據質量和可用性。同時, 在該層面需以TimBerners-Lee 提出的關聯數據4 項基本原則為理論基礎, 將數據網絡層中的知識元提取出來, 篩選出具有相似或相關關系的知識元后進行分類, 存儲在一個知識單元中, 封裝為一個知識元庫, 將站點內容轉為語義化數據, 整合文學類古籍資源的知識元素并使其相互關聯, 為用戶提供更豐富、更準確的信息, 此關聯化發布方式也有助于提升文學類古籍資源的數據可訪問性和互操作性。
4) 應用層。為向用戶提供更為清晰的知識語義脈絡, 應用層根據用戶對文學類古籍資源的知識需求, 提供以用戶需求為導向的知識服務, 進而提高文學類古籍資源知識服務平臺的利用效率, 拓展共享范圍。根據前文分析, 平臺應為專業用戶提供更為細致和全面的文學類古籍資源知識服務, 為普通用戶提供便捷和易于理解的文學類古籍資源知識服務, 以直觀的方式呈現文學類古籍資源的內容,使普通用戶能夠輕松獲得、理解并享受文學類古籍資源的知識。因此, 平臺在知識檢索方面需提供強大的搜索功能, 用戶可以使用多種關鍵詞進行查詢;在知識獲取方面需從多維度對文學類古籍資源知識進行呈現, 輔助以圖片形式促進理解, 并提供分類導航功能; 在知識推理方面需提供個性化的推薦功能, 幫助用戶發現新的知識; 在知識利用方面需支持用戶的互動和參與, 呈現文學類古籍知識的關聯關系和語義脈絡, 幫助用戶更好地理解和利用知識。
5)表現層。表現層在關聯技術基礎上實現了文學類古籍資源的關聯發布, 滿足用戶的人機交互需求, 作為整個模型中極為重要的一環, 表現層從知識檢索、知識獲取、知識推理和知識利用4 個方面實現了用戶對文學類古籍資源知識的檢索、概覽和利用。知識檢索方面, 通過語義關聯, 平臺能夠提供更準確、更相關的搜索結果, 幫助用戶快速找到所需的信息, 用戶可以通過關鍵詞、主題或其他查詢條件搜索相關的文學類古籍資源知識。在知識獲取方面, 表現層根據文學類古籍資源的內容結構設置相應的大類, 以滿足用戶在海量信息中的分類導航需求。通過將文學類古籍資源按照人物、時間、地點、文章基本組成進行分類, 用戶可以便捷地瀏覽并導航到感興趣的領域, 提供更好的信息發現和瀏覽體驗。在知識推理方面, 表現層根據用戶在文學類古籍資源知識服務平臺中的歷史記錄, 提供個性化的文章推送功能, 幫助用戶發現新的知識, 深入了解感興趣的古籍。在知識利用方面, 表現層利用數據網絡層和數據融合層形成的文學類古籍資源知識語義網, 為用戶提供信息查詢服務, 在一定程度對文學類古籍資源的內容進行全面、具體的呈現。通過信息查詢、個性化推送、分類導航和概念匹配等功能, 用戶可以更好地利用該平臺獲取文學類古籍資源的知識, 滿足用戶的需求, 促進文學類古籍資源的雙向、高效利用。
該模型中,數據層從不同數據源借助OCR、GPT等技術,獲取數據為關聯數據的發布提供支撐, 數據網絡層構建關聯組織模型實現知識的語義化鏈接,數據融合層將本地數據集轉化為機器可理解的關聯數據集, 應用層以用戶需求為導向設計關聯數據發布頁面,表現層則呈現最終的文學類古籍資源關聯數據發布平臺, 前一層面為后一層面的基礎, 依次構建完5 個層面后可將分散在文學類古籍資源中的知識進行收集、抽取與有效組織, 以簡單有效且系統化、關聯化的方式呈現給用戶。
4融合GPT 技術和用戶需求的文學類古籍資源關聯發布的實現
《聊齋志異》作為中國文言短篇小說的巔峰之作, 是博采歷代文言小說之精義與史傳文學之菁華的曠世佳作[33],其本體類及屬性涵蓋范圍廣,包含科舉、愛情、復仇、民俗、迷信、鬼神等眾多題材,同時也涉及多個人物及語言, 選取該古籍作為實例構建的本體模型涉及類目眾多, 具有普適性特點,其知識發布及可視化呈現也可凸顯文學類古籍包含的地域與文化屬性。《聊齋志異》中的科舉類文章具有較高的代表意義, 它們是蒲松齡生活經歷的折射, 也是他情感輸出的重要媒介[28] 。《聊齋志異·司文郎》在以科舉為題材的作品中具有典型的意義和價值[34] , 主人公王平子的青年才俊形象是作者原型在故事中的投射, 其科考經歷更是“蒲松齡的化身”[35] 。在文學類古籍資源關聯數據發布過程中, 《聊齋志異·司文郎》不僅涉面廣, 內涵也十分豐富[36] , 涵蓋本文所構建本體模型的基本類目,實體屬性較多, 可通過關聯數據的可視化呈現讓用戶對該篇目有大致的了解, 其作為文學類古籍的代表性較好, 因此選取《聊齋志異·司文郎》對本文提出的文學類古籍資源關聯數據發布模型進行實證研究。
4.1發布模型數據層構建——文學類古籍資源數據的采集和保存
目前《聊齋志異》文言文版與白話文版的版本較多, 為保證數據來源的質量, 本文結合蒲松齡研究院相關研究專家的意見, 研究商討后最終確定本文數據主要來源于北京華夏出版社2012 年版蒲松齡(清)所寫的《聊齋志異》、上海古籍出版社2012 年版丁如明等翻譯的《聊齋志異全譯》、上海古籍出版社2011 年版(清) 蒲松齡、張友鶴校的《聊齋志異會校會注會評本》等權威書籍。經采集后, 在文本識別抽取任務中ChatGPT 輸出69 條數據, 經人工核對后保留53 條數據, 準確度為768%,ChatGPT 在人物、地點、時間識別抽取任務中表現出色, 幾乎可精準識別輸入文字中的人物、地點、時間實體并進行相關三元組抽取, 但典故的識別與抽取效果不佳, 僅識別抽取到9 條數據, 與通過深度學習算法進行抽取操作相比耗費時間大大減少,抽取效率大幅提升。與相關文獻數據合并、校對后,實例《聊齋志異·司文郎》最終獲得149 條數據,包括題目數據1 條、文言版數據1 條、白話版數據1 條、體裁數據1 條、題材數據3 條、地點數據9條、人物數據19 條、職業數據1 條、任職事件數據3 條、書籍數據2 條、典故數據29 條(文學典故22 條、歷史典故4 條、神話典故3 條)、相關文獻數據77 條。將采集到的數據信息錄為CSV 格式,與采集到的關聯數據庫URI 同時保存到本地數據集, 完成數據層的構建, 為后續關聯數據發布提供數據支撐。
4.2發布模型的數據網絡層構建——文學類古籍資源關聯組織模型設計
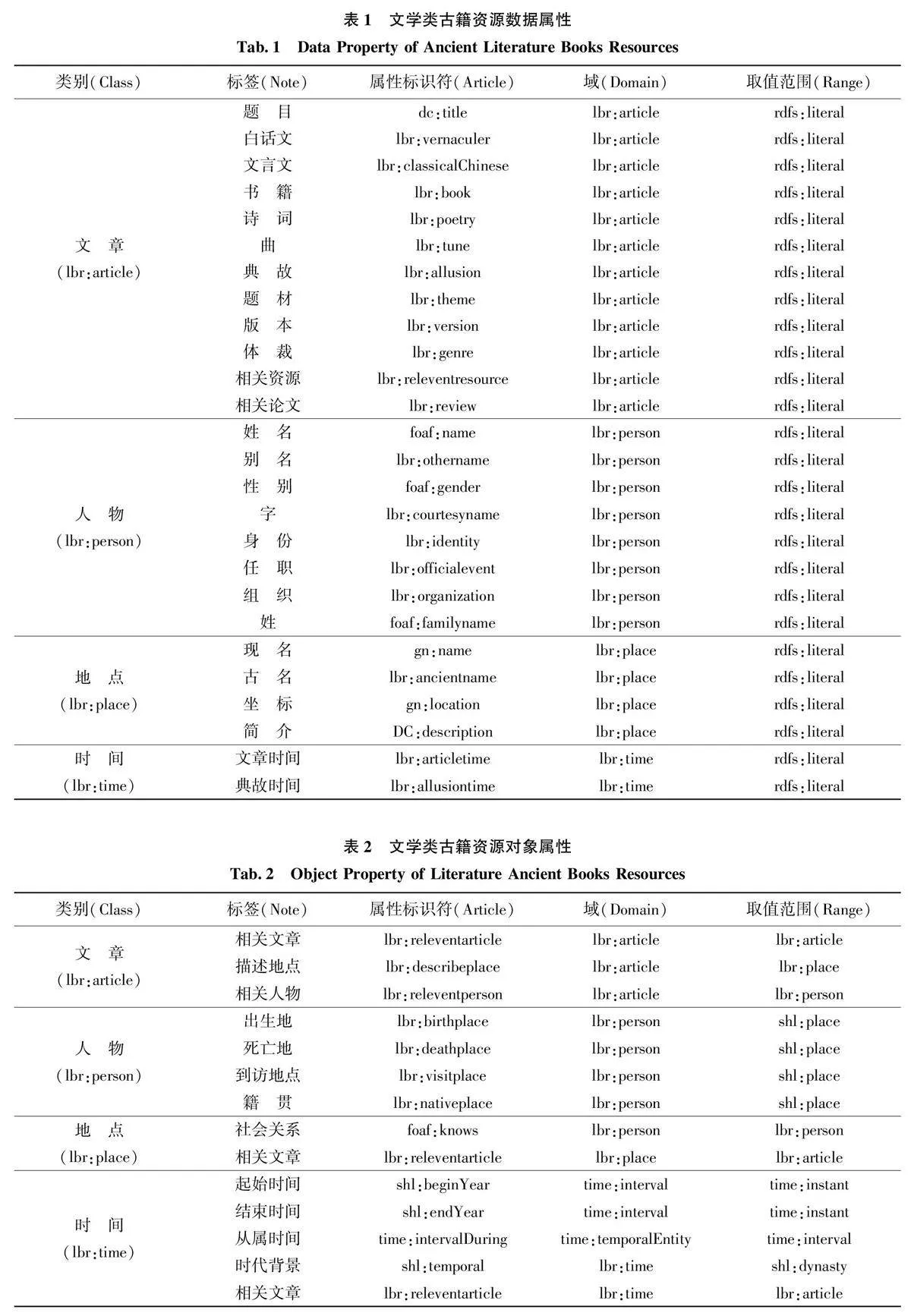
數據網絡層的核心為文學類古籍關聯組織模型的設計與構建, 從而使數據層中的數據轉為機器可識別的RDF 形式。目前本體構建常用方法有骨架法、七步法、TOVE 法等, 本文主要參照七步法構建文學類古籍資源本體模型, 以本體復用與自建詞表相結合的方式設計本體模型框架, 提高其描述能力和精確度, 進而描述文學類古籍資源概念、概念間的關系[37] 。本文復用的本體有都柏林核心元素集(Dublin Core Element Set, DC)[38] 、人物社交網絡本體詞表FOAF[39] 、GeoNames[40] 、上海圖書館開放數據平臺等。其中, 上海圖書館開放數據平臺中的中國歷史紀年表對我國歷史紀年的相關屬性進行較為詳細的描述與規范, 平臺中有成熟的古籍本體表, 因此本文主要在此本體表基礎上進行拓展, 參照前人處理方式, 將中國歷史紀年中的朝代與公元紀年中的具體時間節點視為包含與被包含關系[41] ,如“清” 包含“1687”。根據文學類古籍資源實體及屬性, 構建LBR(Literature Books Resource)詞表對實體屬性描述進行補充, 結合相關專家意見進行調整后, 最終確定4 個類與40 個屬性, 數據屬性與對象屬性如表1、表2 所示。
對文學類古籍資源中的實體設定符合自身特點的屬性后, 借助Protégé 軟件進行工程化建模, 形成標識為http:/ / www.w3.org/2002/07/ owl#的LBR關聯數據庫URI, 完成對文學類古籍資源知識的細粒度組織, 也是本文對于文學古籍資源數字化研究的創新點與特色。同時, 梳理文學類古籍知識間的邏輯結構, 進一步細化各知識單元的內在關聯, 最終構建了文學類古籍資源關聯組織模型, 該模型涵蓋了大部分文學類古籍資源中的實體及屬性要素,基本可以描述文學類古籍資源的共同屬性, 具有一定的通用性與普適性, 如圖5所示。
4.3發布模型的數據融合層構建——文學類古籍關聯數據的發布
為實現文學類古籍知識的可查找、可訪問、可交互與可再用(FAIR 原則)的目標[15] , 本文主要使用CCK 模塊、evoc 模塊與RDFUI 模塊完成數據融合層的構建。首先借助CCK 模塊新建“人物” “時間” “地點” “文章” 4 個內容類型并設置相應的字段。以時間內容類型為例, 添加“field_hasbegin?ning” “field_hasend” 等字段方便后續完成中國歷史紀年與中國公元紀年的映射。其次, 根據文學類古籍資源關聯組織模型中的數據屬性與對象屬性,借助Node Reference 模塊設置節點關聯字段, 其余字段類型根據其特點進行一一設置。Drupal 站點中已內化了content、dc、foaf 等元數據詞匯集, 因此在RDF 數據映射過程中只需通過evoc 模塊導入SHL、GeoNames、LBR 等本體URI,根據文學類古籍資源關聯組織模型, 通過RDFUI 模塊建立平臺內部屬性與外部詞表的映射關系, 將RDF 數據全部映射到Druapl 站點并存儲。
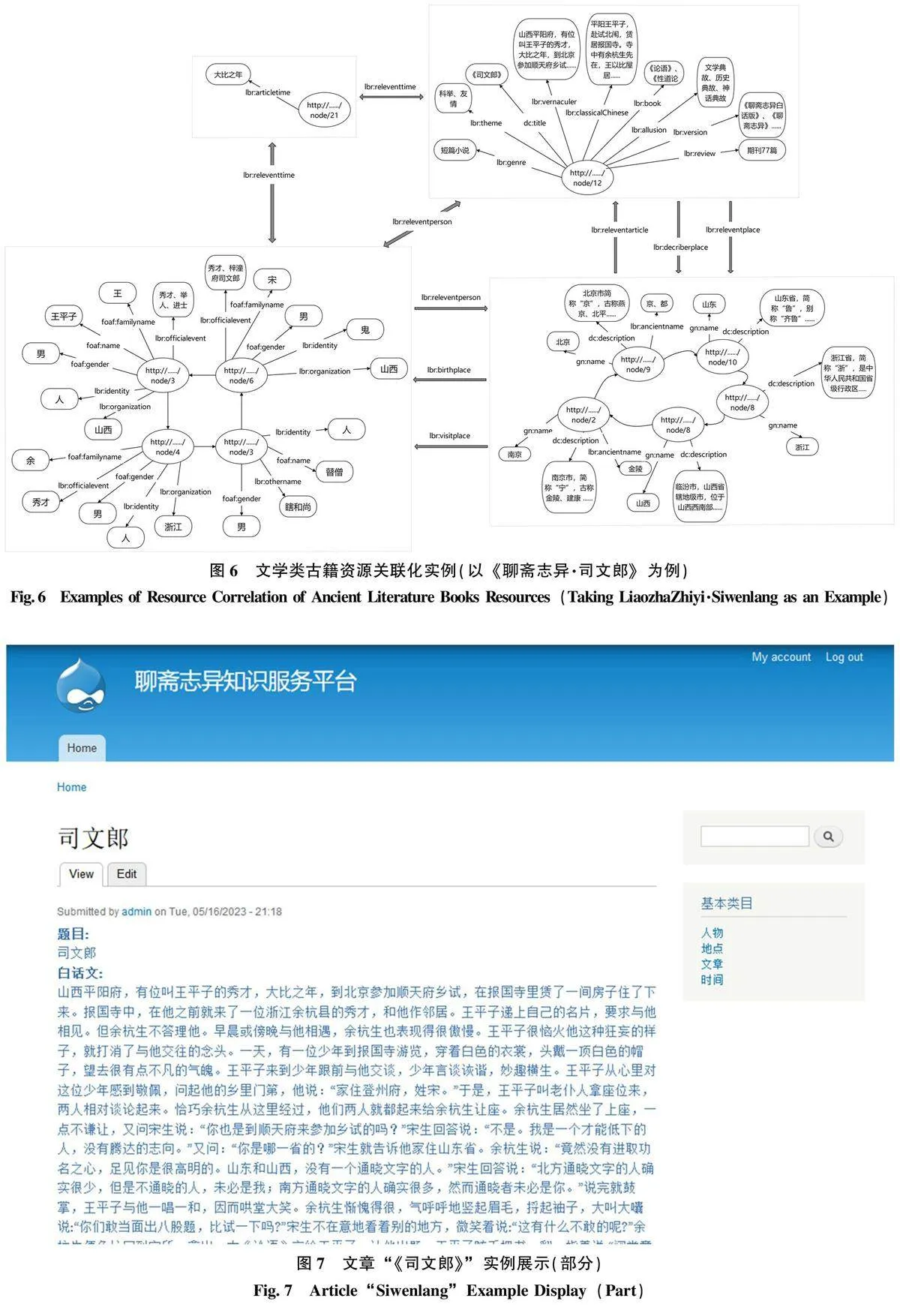
將《聊齋志異·司文郎》本地數據集導入平臺后, 形成如圖6 所示文學類古籍資源關聯化實例圖。從圖6 可以看出, 人物、時間、地點、文章部分實現了一定程度上的互聯互通, 其內部實體也存在相互間的關聯性, 通過對這4 個部分的數據信息整合,基本可以展現出一篇故事中的資源信息, 可對文學類古籍資源知識進行全面、具體的呈現。
4.4發布模型的應用層與表現層構建——文學類古籍關聯數據發布平臺的呈現
根據圖6所示的關聯化實例, 結合應用層對專業用戶與普通用戶的文學類古籍資源知識需求分析結果, 在關聯數據發布平臺頁面中添加搜索框、分類目錄等模塊完成表現層的構建, 實現實例化關聯數據發布平臺的呈現。
1) 在知識數據展示方面,平臺頁面中可直觀瀏覽此篇文章中的題目、版本等屬性信息, 將文言文與白話文數據同一頁面展現, 輔助以相關文章、相關人物等知識節點鏈接, 減少普通用戶閱讀障礙,快速概覽此篇文章包含知識。
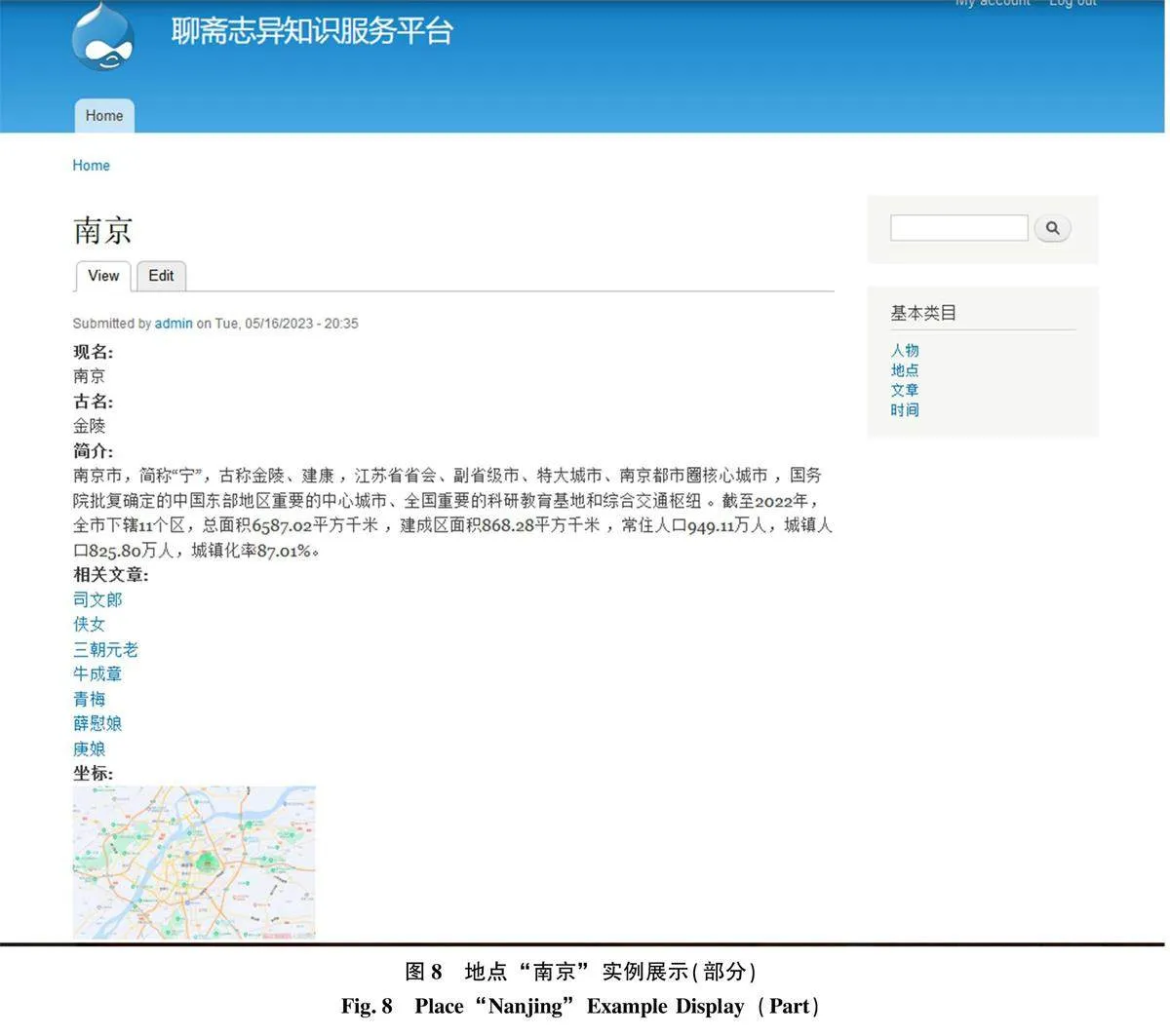
2) 在知識關聯化呈現方面, 用戶可以通過點擊某一頁面節點跳轉至相關頁面, 瀏覽此節點信息的相關知識, 如在文章內容類型“司文郎” 的可視化展示頁面點擊地點“南京” 可跳轉至地點內容類型“南京” 的可視化展示頁面, 在該頁面中展示南京的現名、古名等屬性信息, 同時也可直觀看到與“南京” 相關的人物與文章, 滿足專業用戶系統化獲取知識需要的同時方便普通用戶利用較短時間了解、獲取某一特定知識節點的知識網絡。
3) 在知識檢索方面, 平臺右側設置檢索欄與“人物”“地點”“文章”“時間”4個基本類目模塊, 專業用戶與普通用戶均可根據自身需求, 從某一特定屬性信息出發了解與該屬性信息相關的所有文學類古籍知識信息, 通過點擊任意基本類目模塊訪問該類目下的所有實體目錄, 可迅速掌握某一基本類目概貌, 滿足用戶的知識查詢需求。因網頁在電腦端呈現大小有限, 本文截取部分知識服務平臺內容, 可視化展示效果如圖7、圖8 所示。
通過此實例, 平臺在一定程度上實現了對文學類古籍資源知識的全面、直觀呈現, 揭示文學類古籍資源知識內涵的同時, 實現了各實體屬性信息之間的關聯互訪性, 驗證了本文提出的文學類古籍資源關聯數據發布模型的可行性, 完成了基于關聯數據技術對文學類古籍資源關聯組織與數字化實踐研究的實驗性探索, 為文學類古籍資源知識發現提供了潛在關聯關系發現、知識網絡化表達研究的新視角。
5研究結論
本文研究結果表明,以文學類古籍關聯組織模型為基礎, 以GPT 技術、用戶需求分析與關聯數據技術為支撐進行關聯數據發布的思路, 能夠滿足文學類古籍資源知識服務平臺的構建需求, 能夠在一定程度上支撐和引導文學類古籍資源向語義化、實用化方向進行組織。
本文主要有3個創新點: 一是選取文學類古籍資源作為研究對象, 運用大語言模型結合其結構要素特征對其數字化實踐研究做出探索, 通過實例進行驗證, 實現文學類古籍資源的關聯組織與關聯發布。二是改進、完善了現有的關聯發布框架, 提出包含數據層、數據網絡層、數據融合層、應用層以及表現層5個層面的文學類古籍資源關聯數據發布模型, 設計包含4 個基本類目的文學類古籍關聯組織模型, 增大文學類古籍資源關聯數據發布模型的適配性。三是提出將GPT 技術、用戶需求分析與關聯數據技術相結合以提高文學類古籍資源關聯數據發布效果, 使發布的實例平臺更貼合實際需求,促進應用落地。與已有的關聯數據發布成果相比,本模型在數據整合上更全面, 在跨文本關聯、多維關聯上更完整, 實用性更強。此外, 從多維度劃分文學類古籍資源知識對其他古籍知識聚合與數字化實踐有一定啟發意義, 能夠促進古籍的數字化服務模式, 滿足大眾對古籍文化的知識需求。
本文研究局限性和不足在于: 第一,Drupal平臺數據量較大時需借助其他軟件和工具實現自動連接, 且選擇的存儲模塊ARC2適用于小型的數據庫,若數據量偏大且數據類型復雜時, 需選用更為有效的轉換工具。第二, 本文的數據量偏小,以個案《聊齋志異·司文郎》進行實證研究, 數據采集范圍有待進一步擴大,以實現從個案向全案拓展。后續研究將對文學類古籍資源內部特征進行深入挖掘,引入技術驅動、人機結合的數據處理機制,多維度、細粒度地挖掘文學古籍人文性知識, 探索文學類古籍資源的數字化應用模式。
