基于淺層次規則模型的網絡威脅分析技術研究
2024-10-09 00:00:00王志鵬
電子產品世界 2024年9期


關鍵詞:淺層次規則;規則模型;網絡威脅;元數據
中圖分類號:TP393.08;TP311.13 文獻標識碼:A
0 引言
隨著網絡技術的飛速發展,網絡安全問題日益成為全球關注的焦點。網絡威脅主要包括惡意軟件、釣魚攻擊、拒絕服務攻擊等,對個人隱私、企業運營乃至國家安全構成了嚴重威脅。為了有效應對這些威脅,網絡威脅分析技術應運而生,成為網絡安全領域的關鍵技術之一。
在傳統網絡安全防御中,網絡管理者花費了大量的資源購買防火墻、入侵檢測系統和防病毒軟件等網絡安全工具,以保障網絡的安全。將網絡安全工具的告警日志、網絡設備的系統日志作為網絡安全數據,按照特定條件生成關聯規則,構建網絡安全事件分析模型[1]。但由于這些工具或設備產生的告警數據本身存在一定的誤報情況,這降低了關聯分析模型二次挖掘結論的可信度。
網絡威脅的多樣性和復雜性要求采用更為精細和靈活的分析方法。淺層次規則模型作為一種基于經驗規則的分析方法,以其實現簡單、響應快速的特點,在網絡威脅分析中發揮重要作用。然而,面對不斷演變的網絡攻擊手段,如何進一步提高淺層次規則模型的檢測能力和準確性,成為當前研究的重要課題。
本文旨在探討基于淺層次規則模型的網絡威脅分析技術,通過構建和優化規則集,提高對未知和已知威脅的識別能力。此外,本文還探索了如何將淺層次規則模型與其他分析技術相結合,以實現更全面的網絡安全防護。該技術可以為網絡威脅分析提供一種有效的技術手段,增強網絡安全防護能力,為相關領域的研究和實踐提供參考和指導。
1 基于淺層次規則模型的網絡威脅分析技術
淺層次規則模型是一種基于經驗規則的分析方法,它在網絡威脅分析、入侵檢測和其他網絡安全領域中得到廣泛應用。淺層次規則模型依賴于一系列預定義的規則,識別網絡流量或行為并進行分類,由于規則簡單明確,該模型通常易于實現和部署。該模型可以快速評估網絡行為是否違反了既定規則,實現對潛在威脅的快速響應,并且可以根據特定環境或需求制定規則,以適應不同的安全策略,而規則的制定通常依賴于安全專家的經驗和知識。
對于已知的攻擊模式和行為,通過收集大量的網絡攻擊事件的數據包,研究攻擊過程中網絡流量變化的趨勢和通聯關系,并且利用數據庫強大的關聯查詢能力設計結構化查詢語言(structured querylanguage,SQL)語句的規則模型。淺層次規則模型可以有效檢測威脅,盡管其主要基于人工制定的規則,但它也可以與機器學習技術結合,以提高檢測的準確性和適應性。由于其簡單、快速的特點,淺層次規則模型可以適用于實時網絡威脅分析。
1.1 建模數據處理
以旁路方式實時采集網絡流量,利用數據平面開發套件(data plane development kit,DPDK)技術對網絡中傳輸的各種協議和數據包進行解碼分析,生成元數據日志。數據清洗過濾是指數據的正篩輸出、反篩丟棄,以及利用任意規則的與或非邏輯組合過濾,甄選上層網絡安全威脅分析所需的元數據。網絡傳輸文件還原是指對超文本傳輸協議(hypertext transfer protocol,HTTP)、郵件、證書進行還原,從而獲取傳輸的文件。通過數據去重、規約化處理、錯誤數據丟棄等處理方式,對數據進行預處理和清洗,并將數據存儲在高性能的列式數據庫管理系統ClickHouse 上。元數據是網絡威脅分析中最優質和最具性價比的數據,馬赟等[2] 利用正常情況下對網絡流量的理想曲線描述,并且使用統計學方法創建大規模網絡流量數學模型,基于網絡流量元數據實現異常流量檢測。
ClickHouse 是一個高性能的列式數據庫管理系統,由俄羅斯的Yandex 公司開發,被設計用于在線分析處理場景,其能夠快速處理大量的數據查詢,特別是在數據倉庫和大數據分析領域表現出色。國內360 公司的360 態勢感知與安全運營平臺也內置了元數據專家分析組件,用戶直接在搜索框里輸入相關命令即可實現對海量日志的搜索、關聯、分析和可視化。
1.2 淺層次規則建模
通過搭建一些常見的攻擊模擬環境, 如WebShell(一種代碼執行環境)利用、命令與控制(command and control,C&C)、木馬后門等環境,在采集攻擊模擬的網絡流量并提取元數據后,將解析后的元數據導入分析平臺進行分析。基于Docker(一個開源平臺)搭建了漏洞環境,其包含大部分通用漏洞,也在外網搭建了部分常見的黑客工具,如Empire、Cobalt Strike 等常規工具,整理、收集機器學習訓練的攻擊流量,同時也可以通過網絡安全實戰、互聯網渠道等獲取真實網絡安全事件流量。
首先,需要通過正態分布數學模型,描述自然界中許多隨機變量的分布情況。在網絡流量異常檢測中,正態分布可以確定一個正常的流量水平,并識別出與其相比較為異常的流量。
將內網服務器間的源目標IP 會話記錄作為統計對象,將交互數據量作為對象屬性,時間時序性分為時間分桶(小時、分鐘、天)和時段分類(日間、夜間)并且作為維度定位,分析數據主要通過傳輸控制協議(transmission control protocol,TCP)會話中的序列號與確認號(synchronize and acknowledge,SYN-ACK)來同步和確認元數據日志。
在實驗過程中,24 h 內,每小時統計一次服務器A 和服務器B(x)總體網絡流量,其中x 為總數據量,代表單位小時內IP 會話產生的總數據量。根據服務器A 和服務器B(x)每個單位小時IP 會話產生的總數據量,求出正態分布的標準差σ。利用特定形式的誤差函數,求出正態分布的累積分布函數F(x)的數值,F(x)計算公式:
將模型在實際網絡流量中進行驗證,當F(x) <0.99 時,表示流量正常;當F(x)≥ 0.99 時,表示可能出現了因網絡威脅事件導致網絡流量陡增等情況。
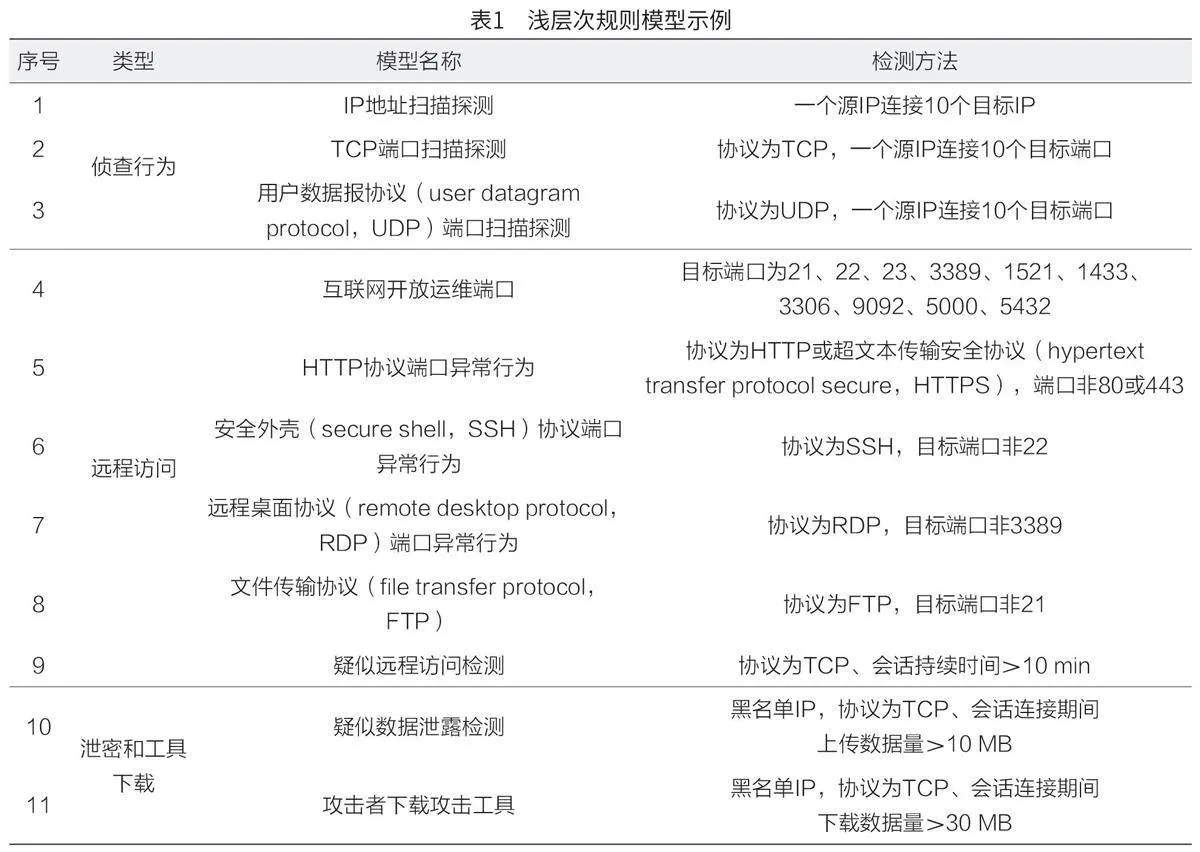
其次,從網絡信息安全保護的角度出發,科學分析網絡流量元數據背景下網絡流量分流平臺的構建過程與元數據的處理過程[3]。淺層次規則模型可以降低依賴于建立大量復雜規則的檢測方式產生的誤報率,因此其可以用于構建如掃描、爆破、WebShell 利用、C&C、木馬心跳等分析檢測模型。同時, 還可以針對域名服務系統(domain namesystem,DNS)、HTTP 等應用建立分析模型,如統計域名請求頻率、域名訪問時間。在此過程中,需要資深的安全分析工程師對淺層次規則模型進行人工干預和修正,以提高模型的檢出率和準確性,淺層次規則模型示例如表1 所示。
2 模型效果驗證
基于互聯網公開獲取的攻擊樣例,這些樣例包含網絡攻擊事件的詳細過程描述、截圖、數據包等。本文對樣例的攻擊過程和分析過程進行威脅建模和人工干預修正,形成檢測分析規則,元數據原始流量示意圖如圖1 所示。
步驟1:協議流量激增。通過聚合每日協議流量,對整體流量進行斜率對比,發現激增情況。如當日SSH 協議產生1 MB,次日SSH 協議產生11.7MB,斜率比值為11.7,存在激增可疑情況。
步驟2:定位可疑IP 地址。通過協議進行IP地址流量的聚合,再利用SSH 協議定位可疑IP 地址,修改模型中的起止時間,以境外會話時間大于6 h、境內會話時間大于8 h 的網絡流量作為分析對象,進一步判斷疑似長會話連接導致的流量激增。模型的部分關鍵代碼如下:
group by client_ip,client_country_id,server_ip,server_country_id,server_port
having total_payload_bytes <= 5*1024*1024*1024 and client_payload_bytes/total_payload_
bytes>0.5
and (client_country_id not in [0,48] or server_country_id not in [0,48]) and maxDurTime >= 6*360
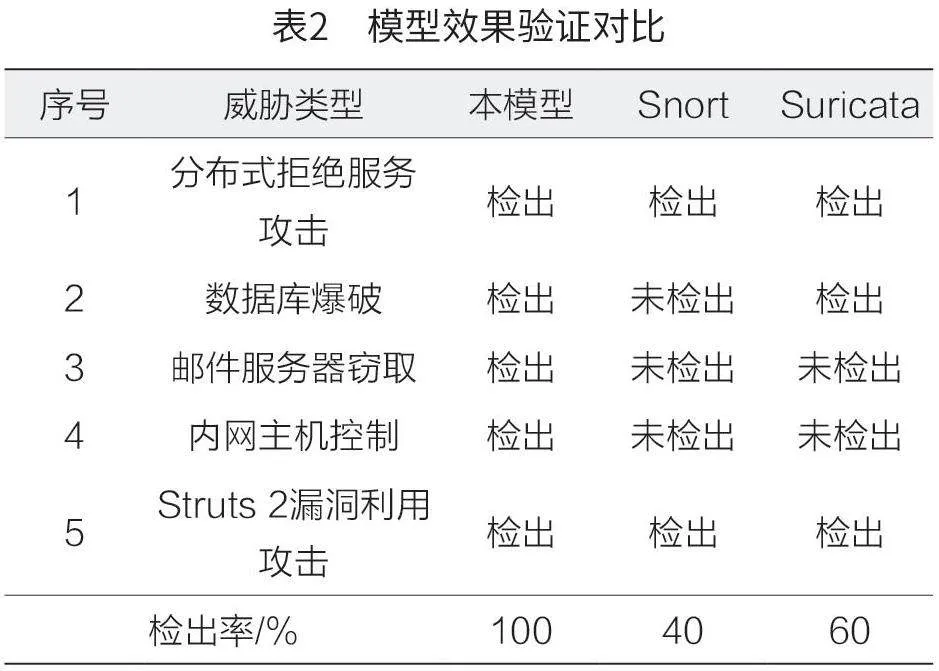
將通過互聯網公開獲取到的攻擊數據包進行效果驗證比對,數據包包含分布式拒絕服務攻擊、數據庫爆破、郵件服務器竊取、內網主機控制和Struts 2漏洞利用攻擊等5 種攻擊類型,利用數據包分析工具提取網絡元數據,通過淺層次規則模型進行網絡威脅分析。同時利用開源的網絡入侵檢測系統Snort 和Suricata 進行威脅檢測分析,基于回放數據包,網絡入侵檢測系統可以對威脅進行快速檢測,記錄檢測分析結果。模型效果驗證對比如表2所示,相較于入侵檢測系統Snort 和Suricata,本模型在網絡攻擊和威脅行為的檢測上具有明顯優勢。
3 結論與展望
本文成功構建并驗證了一種基于淺層次規則模型的網絡威脅分析技術。通過深入分析網絡流量元數據,開發了一種能夠有效識別和響應網絡威脅的模型。該模型利用半監督學習算法對正常流量模式進行建模,并通過實際網絡環境測試,證明其在檢測未知網絡威脅方面的高效性。研究表明,本文開發的模型以網絡流量元數據為數據基礎,分析內網或互聯網邊界網絡流量的網絡攻擊和竊取威脅事件時,相較于網絡入侵檢測系統Snort 和Suricata,本模型表現出高檢出率、低誤報率和較強適應性等特點。
淺層次規則模型仍有進一步改進和擴展的空間。一是淺層次規則模型依賴于經驗豐富的網絡安全分析師編寫規則模型、調優模型,限制了模型對于網絡威脅事件檢測類型的覆蓋度;二是淺層次規則模型由于需要對海量數據進行回溯分析,性能消耗較大。因此,提高模型的自動化水平,實現實時威脅檢測和響應,是未來研究的方向。本文為網絡安全領域提供了新的視角和解決方案,但網絡安全是一個不斷發展的領域,需要持續的技術創新和方法優化。
