基于改進1DCNN的英語語音識別人機交互系統設計
2024-10-09 00:00:00王錦
電子產品世界 2024年9期
關鍵詞:卷積神經網絡;語音識別;人機交互系統
中圖分類號:TP273 文獻標識碼:A
0 引言
在互聯網時代背景下,機器人技術應運而生,并且在人機交互領域中發揮了重要應用優勢,使人機交互系統得到廣泛的推廣和普及[1]。但是,市面上的語音識別人機交互系統處理過程復雜,受到口音、語速、語調以及背景噪聲等多種因素的影響,增加了語音識別的難度。此外,當前技術尚未完全成熟,無法完全準確地捕捉和解讀所有語音信息 ,為解決以上問題,保證語音識別人機交互系統交互能力,本文應用基于改進一維向量卷積神經網絡(1-dimensional convolution neural network,1DCNN)的英語語音識別技術,對新型英語語音識別人機交互系統進行設計,有效提高了英語語音識別的精確度,滿足了用戶精確識別和處理英語語音的需求。
1 基于改進1DCNN的英語語音識別技術概述
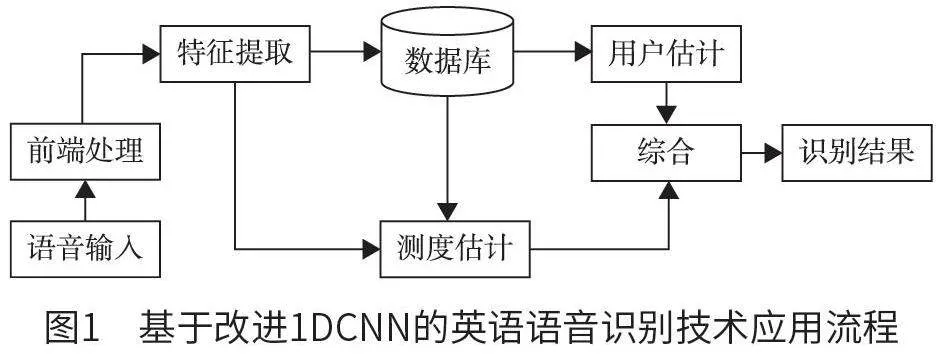
在信息時代背景下,隨著機器人不斷推廣和普及,市面上出現多種多樣的語音識別人機交互系統。現階段,語音識別人機交互系統主要采用對話交流的方式,為用戶提供人機交流互動服務,為幫助機器人智能化回復和應答用戶英語語音信息相關問題,本文應用基于改進1DCNN 的英語語音識別技術,研發和設計相應的英語語音識別人機交互系統。在圖像處理領域中,卷積神經網絡技術應用廣泛,因此該系統主要運用卷積神經網絡來保證系統語音識別功能的實現效果。在提取英語語音信號時,技術人員需借助本文系統提取的圖像參數,但這種操作容易增大最終提取結果的誤差。為避免這些問題的出現,技術人員在保留一維語音信號特征的基礎上,提出一種基于改進1DCNN 的英語語音識別技術。該語音識別技術應用流程如下:首先,技術人員借助話筒等語音采集設備,對所需要的英語語音信號進行采集和轉換,使其轉換為相應的電信號,并將該電信號直接發送和存儲至特定的識別系統中,由該識別系統運用前端處理技術對所接收的電信號進行統一化處理。其次,在前端處理結束之后,技術人員精確化提取所需要的語音信號特征,并且采用測度估計方法,估計和匯總相關特征參數,并結合最終特征參數結果來提出一種新模式。利用該新模式和用戶最終主觀估計結果,完成測度估計。最后,結合制定的識別方案,針對不同的新模式,計算和獲取最終的識別結果。基于改進1DCNN 的英語語音識別技術應用流程如圖1 所示。在本文系統對語音信號進行離散變換處理期間,通常會涉及語音信號取樣環節,通過執行該環節,可以為用戶提供完整、真實、可靠的語音信號,從而達到再現和還原真實信號的目的。在語音信號取樣處理結束后,技術人員需在降低語言信號幅值的基礎上,對原始信號進行預處理,使整個音頻具有較高的高頻分量值。
2 基于改進1DCNN的英語語音識別人機交互系統設計
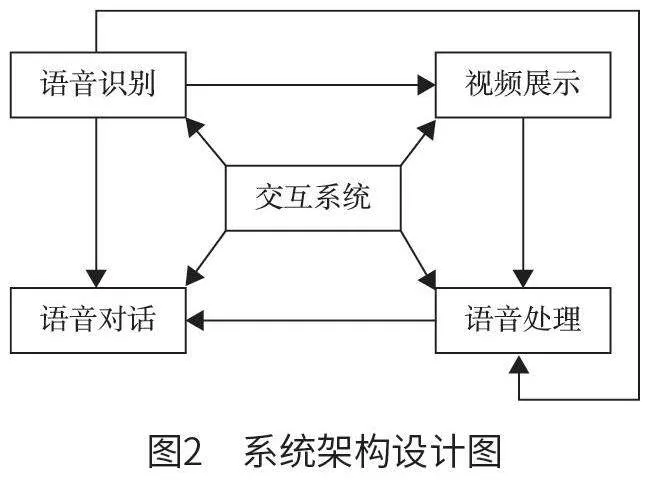
人機交互系統同時含有人臉、表情、文本、語音等多種模態信息。為提高人機交互系統的交互能力,本文基于改進1DCNN 的英語語音識別技術,以英語語音為輸入內容,以視頻、音頻為輸出結果,設計了一個英語語音識別人機交互系統[2]。系統架構設計圖如圖2 所示。
從圖2 中可以看出,系統主要包含以下模塊:①語音識別模塊。該模塊在具體設計時,需輸入用戶語音等數據,運用卷積神經網絡,對所需要的語音數據進行精確化提取、分幀等一系列預處理操作。②語音對話模塊。該模塊主要用于系統音頻模態的智能化采集和輸出。該模塊在具體設計時,主要應用語音合成技術對所需要的文本數據進行采集,并結合最終采集數據結果,生成相應的音頻。③視頻展示模塊。該模塊主要用于系統視頻模態的智能化輸出[3]。該模塊在具體設計時,需采用人臉表情動畫技術,精確化采集和輸出相關視頻信息,同時,從所生成的視頻信息中采集和整理人臉表情參數,完成對3D人臉網絡體系的構建[4]。④語音處理模塊。該模塊負責接收用戶的英語語音輸入,并對其進行預處理和特征提取,通過基于改進的1DCNN 模型進行語音識別,最終將識別結果轉換為文本輸出。
系統具體實現流程如下:首先,技術人員應用基于改進1DCNN 的英語語音識別技術,對特定用戶的關鍵語音信息進行智能化采集和獲取,并結合最終采集數據結果,強化對語音信息中聲學特征信息的提取。其次,為提高系統的運行性能,技術人員對所需要的音頻數據進行合成處理。最后,應用3D 動畫技術,結合所采集的語音情緒信息,有針對性地設計不同人臉表情,從而完成對人臉3D 模型的構建。借助人臉3D 模型,為用戶提供良好的視頻交互、音頻交互體驗。在設計系統時,環境變化會對語音數據最終采集結果產生直接影響,為保證語音數據采集的全面性和完整性,技術人員需結合用戶個性化使用需求,有針對性地設計一種功能強大的語音處理模塊,從而避免因環境引發的信號噪聲污染現象[5]。同時,技術人員運用小波變換方法,對語音信息進行采集、歸類和降噪處理,以保證語音效果。
3 基于改進1DCNN的英語語音識別人機交互系統測試
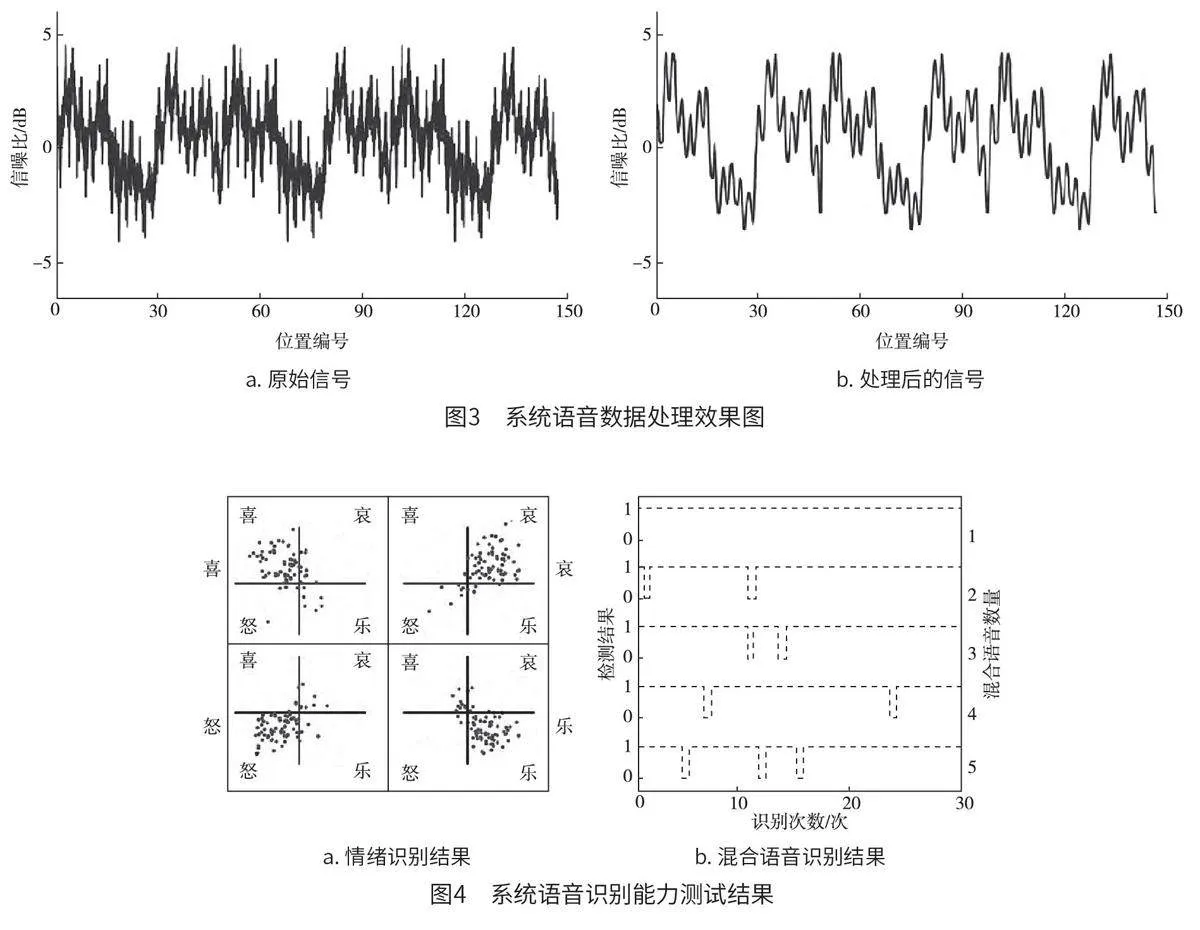
為研究和測試本文系統語音識別性能,并且驗證其有效性和可行性,技術人員重點分析和評價了系統的語音數據處理效果。系統語音數據處理效果圖如圖3 所示。從圖3a 中可以看出,在本次測試研究中,所選擇的原始信號呈現出明顯的變化狀態。同時,整個信號曲線中出現大量的毛刺信號,這說明原始信號存在嚴重的噪聲污染現象。圖3b中的波形圖存在少量的毛刺信號,曲線較為光滑,能夠為用戶呈現出清晰、全面的語音信息。這說明本文系統在精確識別語音信息的基礎上,可以保證降噪處理的質量和效率。
此外,運用混合語音法對本文系統的識別能力進行測試。系統語音識別能力測試結果如圖4所示。從圖4a 中可以看出,本文系統可以精確判斷和識別用戶語音中的喜、怒、哀、樂等多種情緒。圖4b中的1、0 分別代表識別成功、識別失敗,結合最終混合語音識別結果,可以發現,在30次系統測試中,當混合語音數量為1 時,本文系統識別成功率高達100%;當混合語音數量為2~4時,本文系統識別成功率達到93.33%;當混合語音數量為5時,本文系統識別成功率達到90.00%。由此可知,本文系統在識別用戶語音情緒方面具有較高的識別成功率,識別成功率高達90.00% 以上,滿足用戶精確識別和判斷多種語音信息的需求,有效提高了用戶的人機交互體驗。
4 結語
在人工智能背景下,英語語音識別人機交互系統的研發和應用雖然給人們的日常生活和工作提供了便利,但部分人機交互系統存在語音識別成功率低等問題。因此,本文研發和設計了一種基于改進1DCNN 的英語語音識別人機交互系統,并對該系統的性能進行測試。結果表明,該系統具有語音處理能力強、語音識別成功率高等特點,方便用戶將噪聲信號快速處理和轉換為具有高識別度的光滑信號。
